Distributed Machine Learning
Why distributed
传统的模型训练中,迭代计算只能利用当前进程所在主机上的所有硬件资源,可是单机扩展性始终有限。而目前的机器学习有如下特点:
- 样本数量大。目前训练数据越来越多,在大型互联网场景下,每天的样本量可以达到百亿级别。
- 特征维度多。因为巨大样本量导致机器学习模型参数越来越多,特征维度可以达到千亿或者万亿级别。
- 训练性能要求高。虽然样本量和模型参数巨大,但是业务需要我们在短期内训练出一个优秀的模型来验证。
- 模型实时上线。对于推荐资讯类应用,往往要求根据用户最新行为及时调整模型进行预测。
因此,单机面对海量数据和巨大模型时是无能为力的,有必要把数据或者模型分割成为多分,在多个机器上借助不同主机上的硬件资源进行训练加速。
本文所说的训练,指的是利用训练数据通过计算梯度下降的方式迭代地去优化神经网络参数,并最终输出网络模型的过程。在单次模型训练迭代中,会有如下操作:
- 首先利用数据对模型进行前向的计算。所谓的前向计算,就是将模型上一层的输出作为下一层的输入,并计算下一层的输出,从输入层一直算到输出层为止。
- 其次会根据目标函数,我们将反向计算模型中每个参数的导数,并且结合学习率来更新模型的参数。
而并行梯度下降的基本思想便是:多个处理器分别利用自己的数据来计算梯度,最后通过聚合或其他方式来实现并行计算梯度下降以加速模型训练过程。比如两个处理器分别处理一半数据计算梯度 g_1, g_2,然后把两个梯度结果进行聚合更新,这样就实现了并行梯度下降。
并行机制
由于使用小批量算法,可以把宽度(∝W)和深度(∝D)的前向传播和反向传播分发到并行的处理器上。

Model Parallelism
当神经网络模型很大时,由于显存限制,它是难以完整地跑在单个 GPU 上,这个时候就需要把模型分割成更小的部分,不同部分跑在不同的设备上。
模型并行被划分的是模型,即把模型的网络结构拆了,放到不同的 GPU 上进行运算,对于卷积神经网络来说就是把对应的矩阵运算做了分块处理。可以将模型的不同网络层被分配到不同的机器,或者同一层内部的不同参数被分配到不同机器。
模型并行允许支持更大的模型,所有工作节点针对相同数据进行训练,每个 GPU 上分布着并运行模型的一部分,需要在 GPU 之间交换神经网络的输出激活部分(activation)。
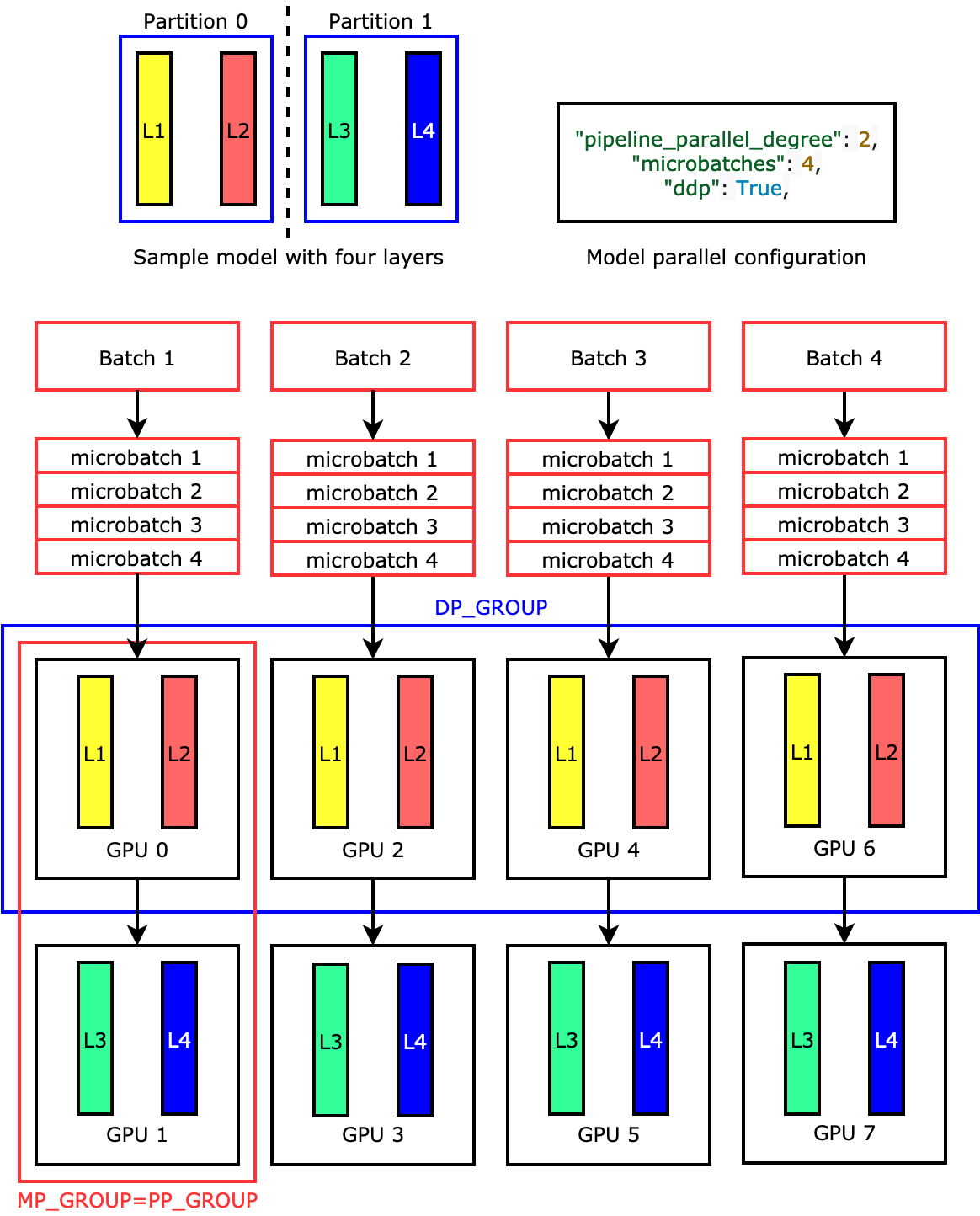
关于 Model Parallelism 可以更具体的划分有 Pipeline Parallelism, Tensor Parallelism,可以参考 Hugging Face 的教程 1 和 Amazon 的相关文档 2。
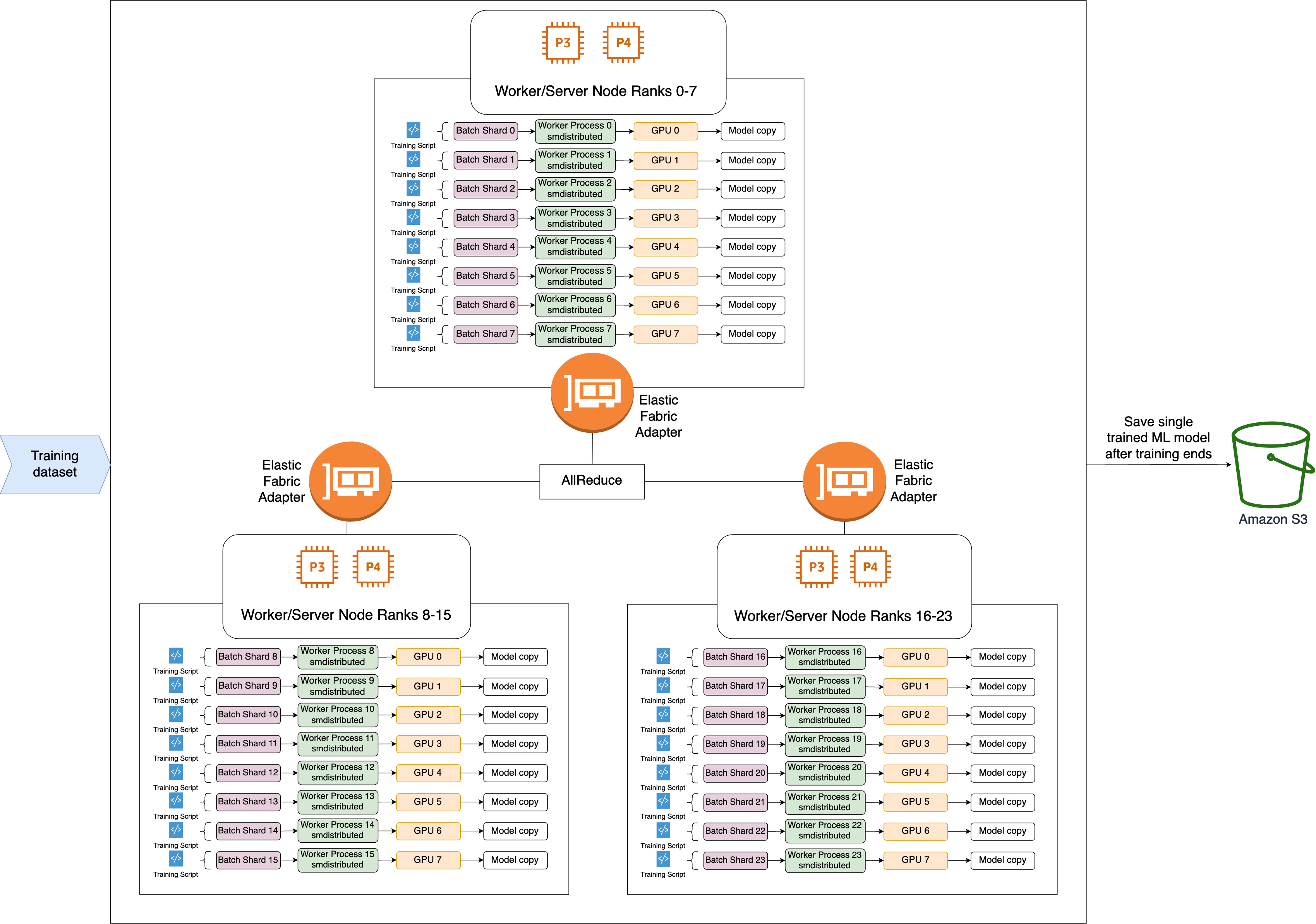
Data Parallelism
数据并行中被划分的是数据,模型可以被放到一张单独的 GPU 卡上,每张 GPU 卡处理不同分区的数据来并行训练。可以通过参数平均(model averageing)算法更新各个节点模型中的参数。
数据并行在多个设备上放置相同的模型,各个设备采用不同的训练样本对模型训练。每个 Worker 拥有模型的完整副本并且进行各自单独的训练。
假设机器上有 $k$ 个 GPU。给定要训练的模型,每个 GPU 将独立地维护一组完整的模型参数,尽管 GPU 上的参数值是相同且同步的。例如,下图演示了在 $k = 2$ 时使用数据并行的训练。

一般来说,训练过程如下:
- 在训练的任何迭代中,给定一个随机的小批量,我们将该小批量中的样本分成 $k$ 个部分,并将它们均匀地分在多个 GPU 上。
- 每个 GPU 根据分配给它的小批量子集计算模型参数的损失和梯度。
- 将 $k$ 个 GPU 中每个 GPU 的局部梯度聚合以获得当前的小批量随机梯度。
- 聚合梯度被重新分配到每个 GPU。
- 每个 GPU 使用这个小批量随机梯度来更新它维护的完整的模型参数集。
相比较模型并行,数据并行方式能够支持更大的训练规模,提供更好的扩展性,因此数据并行是深度学习最常采用的分布式训练策略。现在大模型训练往往是多种并行模式一起使用,而不只是简单的一维并行,更多内容可以参考 Hugging Face 的教程 1 和 Amazon 的相关文档 3。
Summarize
数据的并行往往意味着计算性能的可扩展,而模型的并行往往意味着内存使用的可扩展。
需要注意的是:数据并行和模型并行也并不冲突,两者可以同时存在,而流水线机制也可以和模型并行一起混用。比如,DistBelief 分布式深度学习系统结合了三种并行策略。训练在同时复制的多个模型上训练,每个模型副本在不同的样本上训练(数据并行),每个副本上,依据同一层的神经元(模型并行性)和不同层(流水线)上划分任务,进行分布训练。
通信与架构
Share Memory vs Message Passing-
- Share memory 就是所有处理器共享同一块内存,这样通信很容易,但是同一个节点内的处理器之间才可以共享内存,不同节点处理器之间无法共享内存。
- Message passing 就是不同节点之间用消息(比如基于 TCP/IP 或者 RDMA)进行传递/通信,这样容易扩展,可以进行大规模训练。
因此我们知道,Message passing 才是解决方案,于是带来了问题:如何协调这些节点之间的通讯。
有两种架构:
- Client-Server 架构: 一个 server 节点协调其他节点工作,其他节点是用来执行计算任务的 worker。
- Peer-to-Peer 架构:每个节点都有邻居,邻居之间可以互相通信。
异步 vs 同步
在数据并行训练之中,各个计算设备分别根据各自获得的 batch,前向计算获得损失,进而反向传播计算梯度。计算好梯度后,就涉及到一个梯度同步的问题:每个计算设备都有根据自己的数据计算的梯度,如何在不同 GPU 之间维护模型的不同副本之间的一致性。如果不同的模型以某种方式最终获得不同的权重,则权重更新将变得不一致,并且模型训练将有所不同。
怎么做这个同步就是设计分布式机器学习系统的一个核心问题。
分布式训练的梯度同步策略可分为异步(asynchronous)梯度更新 和 同步(synchronous)梯度更新机制。
- 同步指的是所有的设备都是采用相同的模型参数来训练,等待所有设备的 mini-batch 训练完成后,收集它们的梯度然后取均值,然后执行模型的一次参数更新。
- 同步训练相当于通过聚合很多设备上的 mini-batch 形成一个很大的 batch 来训练模型,Facebook 就是这样做的,但是他们发现当 batch 大小增加时,同时线性增加学习速率会取得不错的效果。
- 同步训练看起来很不错,但是实际上需要各个设备的计算能力要均衡,而且要求集群的通信也要均衡。
- 因为每一轮结束时算得快的节点都需等待算得慢的节点算完,再进行下一轮迭代。类似于木桶效应,一个拖油瓶会严重拖慢训练进度,所以同步训练方式相对来说训练速度会慢一些。这个拖油瓶一般就叫做 straggler。
- 异步训练中,各个设备完成一个 mini-batch 训练之后,不需要等待其它节点,直接去更新模型的参数,这样总体会训练速度会快很多。
- 异步训练的一个很严重的问题是梯度失效问题(stale gradients),刚开始所有设备采用相同的参数来训练,但是异步情况下,某个设备完成一步训练后,可能发现模型参数其实已经被其它设备更新过了,此时这个梯度就过期了,因为现在的模型参数和训练前采用的参数是不一样的。由于梯度失效问题,异步训练虽然速度快,但是可能陷入次优解(sub-optimal training performance)。
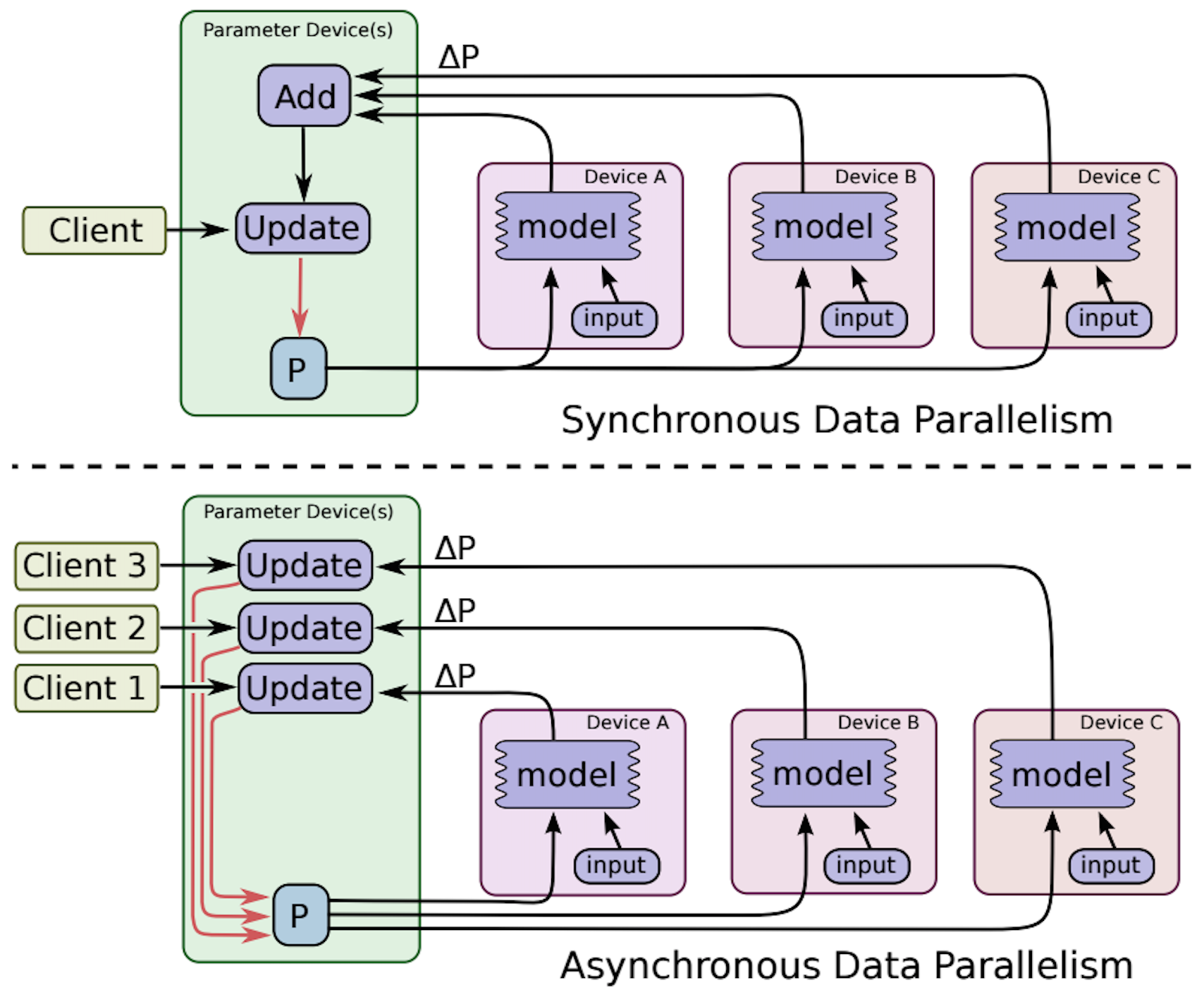
这两种更新方式各有优缺点:
- 异步更新可能会更快速地完成整个梯度计算。
- 同步更新 可以更快地进行一个收敛。
选择哪种方式取决于实际的应用场景。
分布式训练架构
Parameter Server
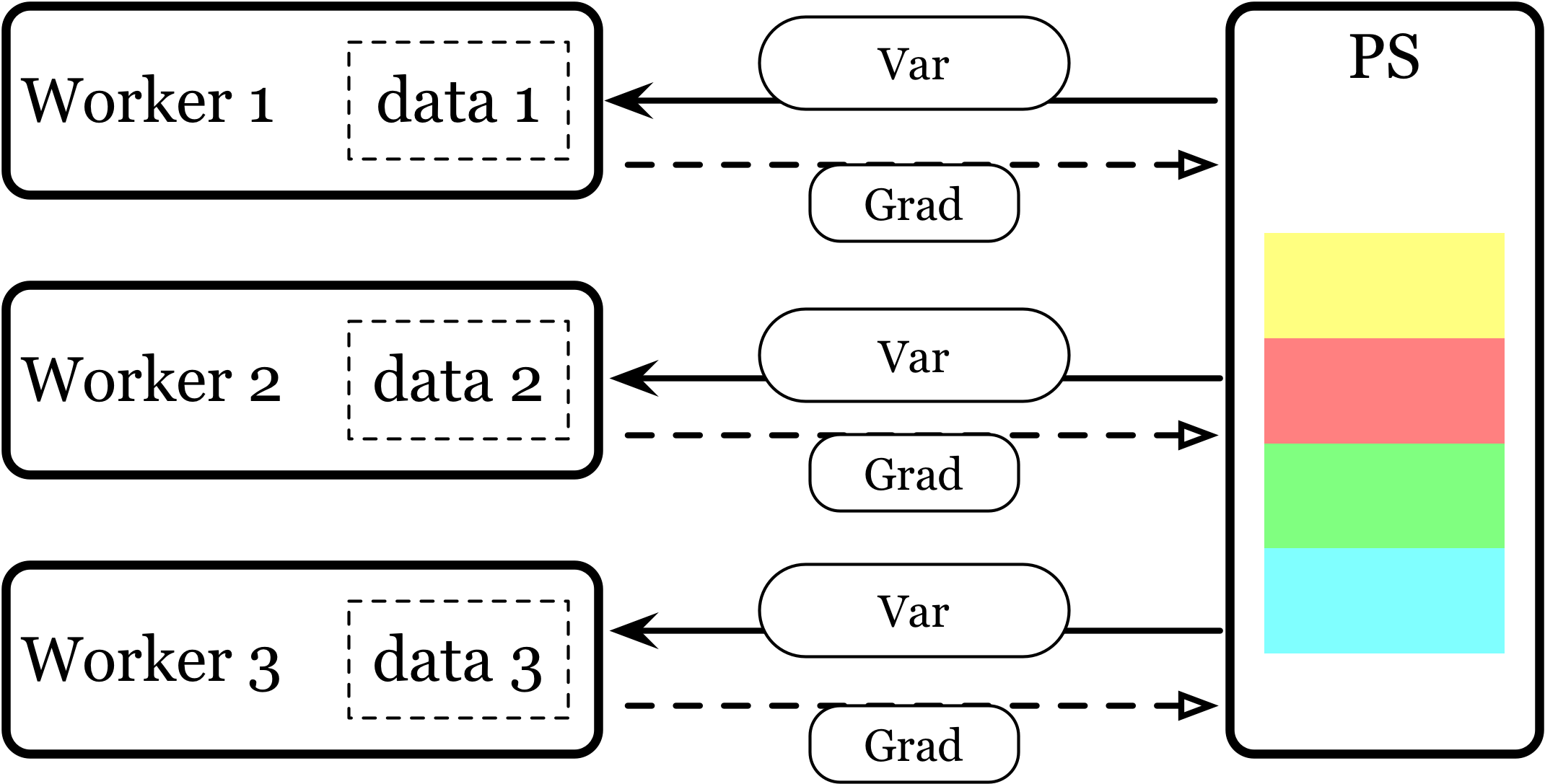
Parameter Server 架构是深度学习最常采用的分布式训练架构。在 PS 架构中,集群中的节点被分为两类:
- parameter server:中心化的组件,主要是负责模型参数的存储,平均梯度和交换更新。参数服务器可以按照不同比例的参数服务器和工作线程进行配置,每个参数服务器都有着不同的配置数据。
- worker:每个工作节点会负责它领域内的数据分片所对应模型参数的更新计算(比如前向和反向传播这类计算密集的运算),同时它们又会向参数服务器去传递它所计算的梯度,由参数服务器来汇总所有的梯度,再进一步反馈到所有节点。
在每个迭代过程,
- 所有的参数都存储在参数服务器中,而工作节点(worker) 是万年打工仔。
- worker 只负责计算梯度,从 parameter sever 中获得参数,然后将计算的梯度返回给 parameter server
- parameter server 聚合从 worker 传回的梯度,然后更新参数,并将新的参数广播给 worker

- Variable placement 策略,常用的 replica_device_setter 的策略是 round-robin over all ps tasks,这种策略并没有考虑 Variable 大小,会导致参数分配不均衡,某些 ps 上分配的 Variable size 大就会成为通信瓶颈;
- 多个 Worker 访问同一个 PS 节点时,受 PS 节点带宽限制和 TCP 的拥塞窗口控制,会导致通信效率大幅降低,并且规模越大,效率越差;
- 分布式扩展后,模型需要精细调参才能收敛,需要用户有丰富的调参经验。
- 确定工作者与参数服务器的正确比例:如果使用一个参数服务器,它可能会成为网络或计算瓶颈。 如果使用多个参数服务器,则通信模式变为“All-to-All”,这可能使网络饱和。
更多关于 Parameter Server 的详细内容,可以参考 parameter-server。
Ring AllReduce
除了 Parameter Server 这种同步梯度的方式,人们发现 MPI_AllReduce 这种语义也可以很好的满足同步梯度的需要。关于 MPI_AllReduce 的语义,可以参考 mpi > AllReduce 。
我们可以把每个 Worker 看作是 MPI 概念中的一个进程,4 个 Worker 组成了一个 4 个进程组成的组。我们在这四个进程中对梯度进行一次 MPI_AllReduce。根据 MPI_AllReduce 的语义,所有参与计算的进程都有结果,所以梯度就完成了分发。只要在初始化的时候,我们可以保证每个 Worker 的参数是一致的,那在后续的迭代计算中,参数会一直保持一致,因为梯度信息是一致的。
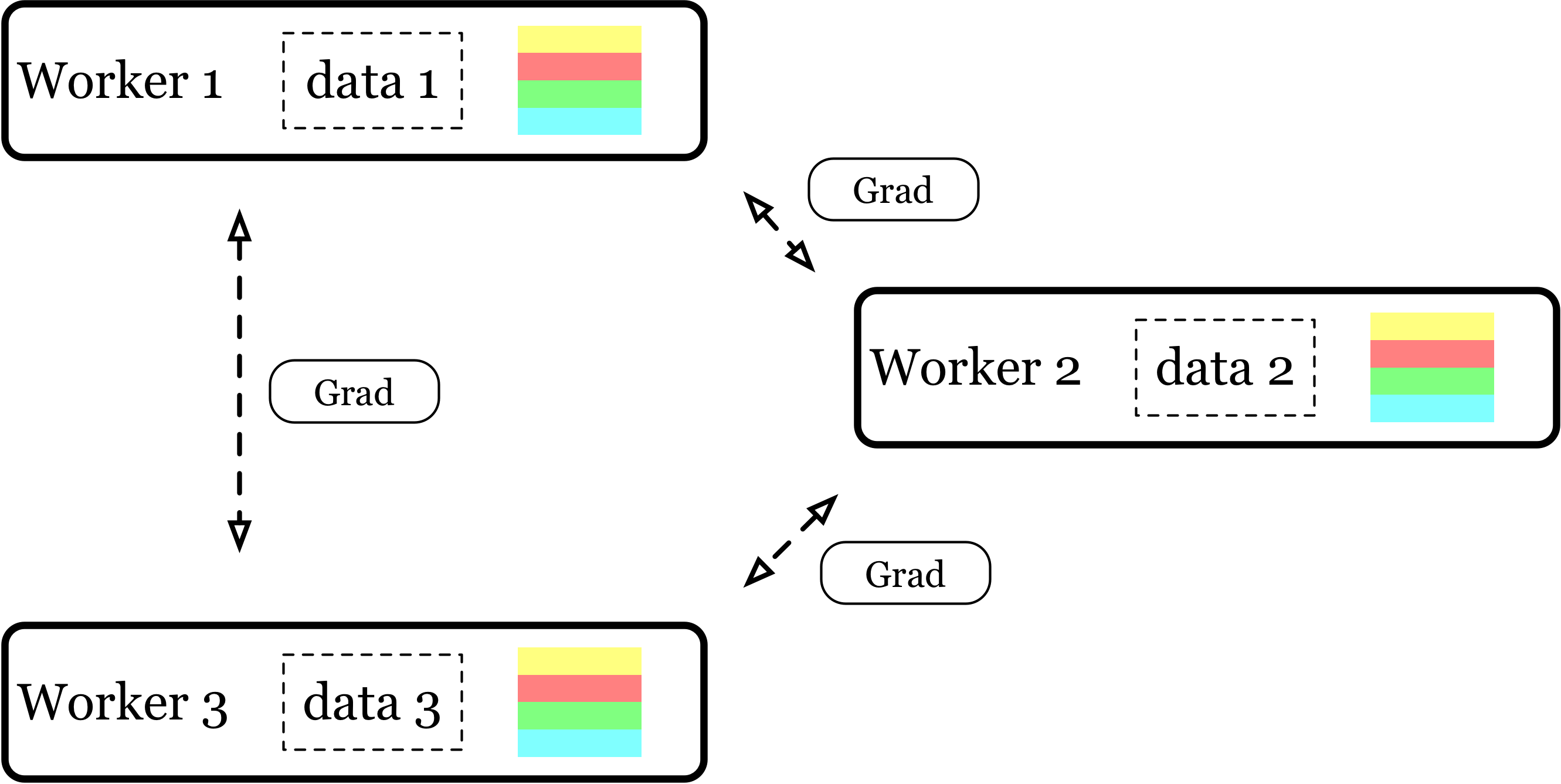
Ring-Allreduce 特点如下:
- Ring Allreduce 算法使用定义良好的成对消息传递步骤序列在一组进程之间同步状态(在这种情况下为张量)。
- Ring-Allreduce 的命名中 Ring 意味着设备之间的拓扑结构为一个逻辑环形,每个设备都应该有一个左邻和一个右邻居,且本设备只会向它右邻居发送数据,并且从它的左邻居接受数据。
- Ring-Allreduce 的命名中的 Allreduce 则代表着没有中心节点,架构中的每个节点都是梯度的汇总计算节点。
- 此种算法各个节点之间只与相邻的两个节点通信,并不需要参数服务器。因此,所有节点都参与计算也参与存储,也避免产生中心化的通信瓶颈。
- 相比PS架构,Ring-Allreduce 架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。
- 在 ring-allreduce 算法中,每个 N 节点与其他两个节点进行 2 * (N-1) 次通信。在这个通信过程中,一个节点发送并接收数据缓冲区传来的块。在第一个 N - 1 迭代中,接收的值被添加到节点缓冲区中的值。在第二个 N - 1 迭代中,接收的值代替节点缓冲区中保存的值。百度的文章证明了这种算法是带宽上最优的,这意味着如果缓冲区足够大,它将最大化地利用可用的网络。
- 在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于后面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。
- Ring架构下的同步算法将参数在通信环中依次传递,往往需要多步才能完成一次参数同步。在大规模训练时会引入很大的通信开销,并且对小尺寸张量(tensor)不够友好。对于小尺寸张量,可以采用批量操作(batch)的方法来减小通信开销。
综上所述,Ring-based AllReduce 架构的网络通讯量如果处理适当,不会随着机器增加而增加,而仅仅和模型 & 网络带宽有关,这针对参数服务器是个巨大的提升。
更多关于 Ring AllReduce 的详细内容,可以参考 ring-all-reduce。
具体实践
参考资料
-
No backlinks found.