Ring AllReduce
AllReduce

Ring AllReduce
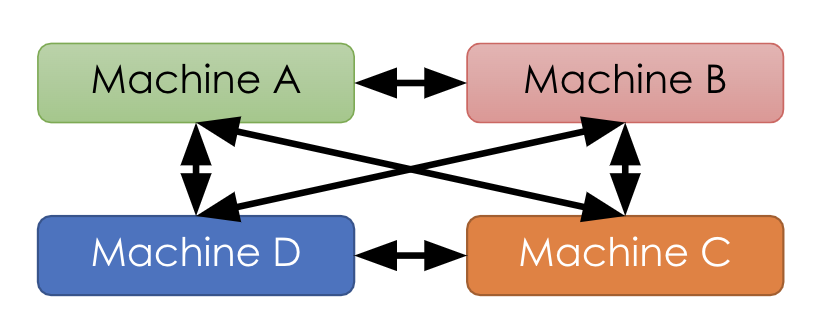
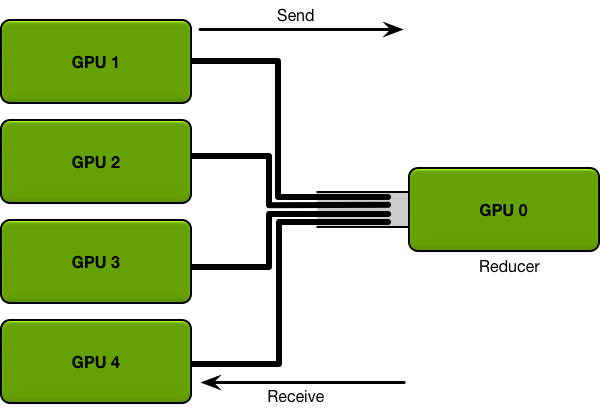
于是 GPU 分布式计算的具体形式就比较清晰了,以上图为例。GPU 1~4 卡负责网络参数的训练,每个卡上都布置了相同的深度学习网络,每个卡都分配到不同的数据的 minibatch。每张卡训练结束后将网络参数同步到 GPU 0,也就是 Reducer 这张卡上,然后再求参数变换的平均下发到每张计算卡,整个流程有点像 mapreduce 的原理。
这里面就涉及到了两个个问题:
问题一,每一轮的训练迭代都需要所有卡都将数据同步完做一次 Reduce 才算结束。如果卡数比较少的情况下,其实影响不大,但是如果并行的卡很多的时候,就涉及到计算快的卡需要去等待计算慢的卡的情况,造成计算资源的浪费。
问题二,每次迭代所有的计算 GPU 卡多需要针对全部的模型参数跟 Reduce 卡进行通信,如果参数的数据量大的时候,那么这种通信开销也是非常庞大,而且这种开销会随着卡数的增加而线性增长。
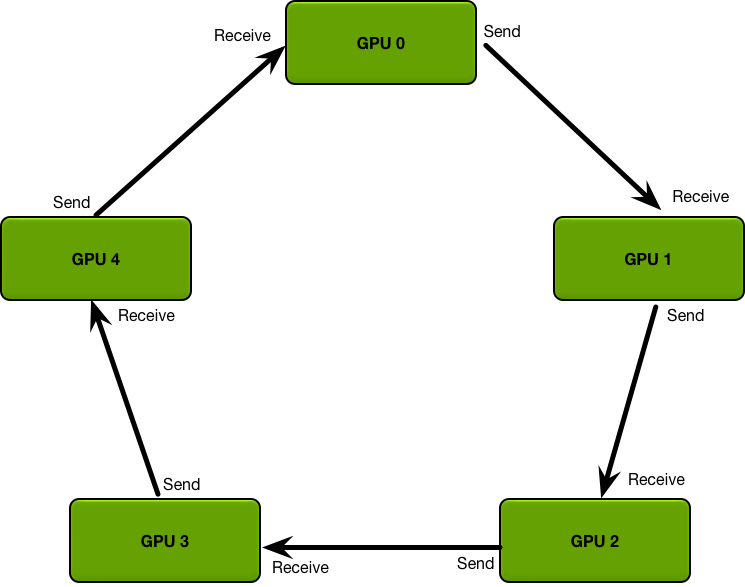
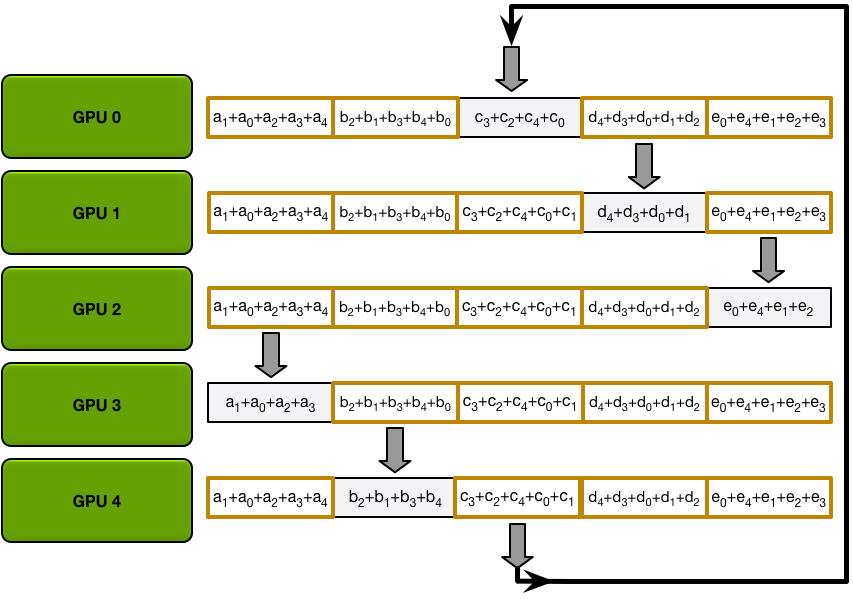
环形结构如下,每个 GPU 应该有一个左邻居和一个右邻居;它只会向其右侧邻居发送数据,并从其左侧邻居接收数据。:
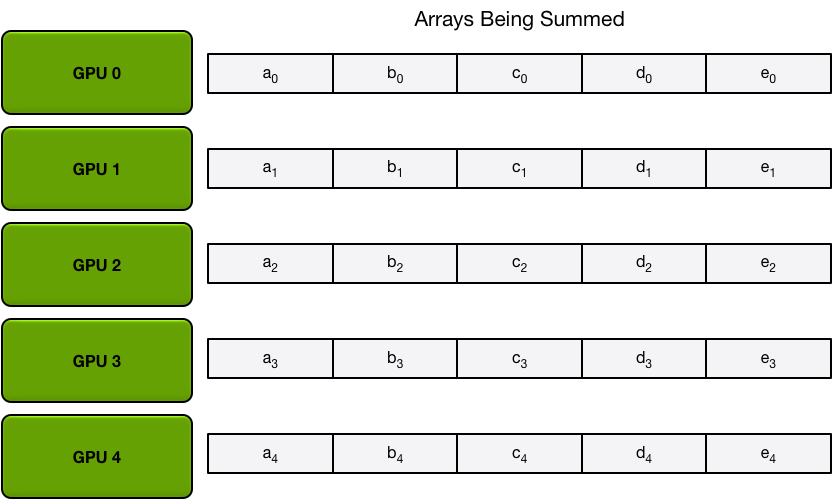
The Scatter-Reduce
Scatter-Reduce:会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分。
为简单起见,我们假设目标是按元素对单个大型浮点数数组的所有元素求和;系统中有 N 个 GPU,每个 GPU 都有一个相同大小的数组,在 allreduce 的最后环节,每个 GPU 都应该有一个相同大小的数组,其中包含原始数组中数字的总和。
首先,GPU 将阵列划分为 N 个较小的块(其中 N 是环中的 GPU 数量)。
接下来,GPU 将进行 N-1 次 scatter-reduce 迭代。
在每次迭代中,GPU 会将其一个块发送到其右邻居,并将从其左邻居接收一个块并累积到该块中。每个 GPU 发送和接收的数据块每次迭代都不同。第 n 个 GPU 通过发送块 n 和接收块 n – 1 开始,然后逐步向后进行,每次迭代发送它在前一次迭代中接收到的块。
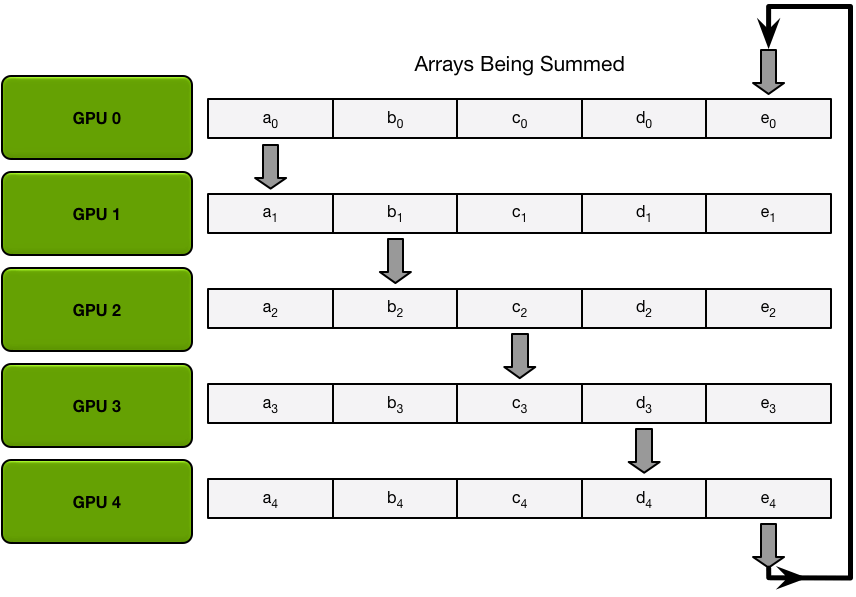
第一次发送和接收完成后,每个 GPU 都会有一个块,该块由两个不同 GPU 上相同块的总和组成。例如,第二个 GPU 上的第一个块将是该块中来自第二个 GPU 和第一个 GPU 的值的总和。
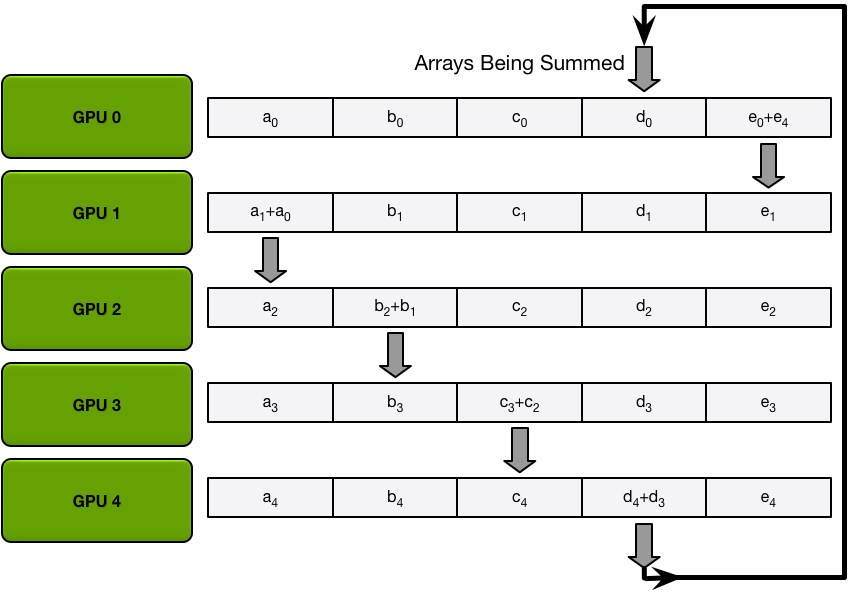
第三次迭代
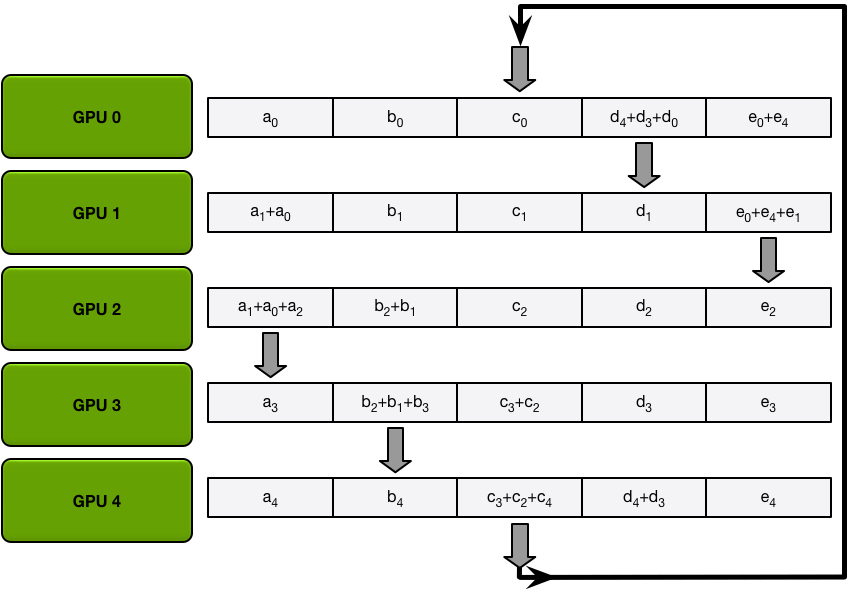
第四次迭代
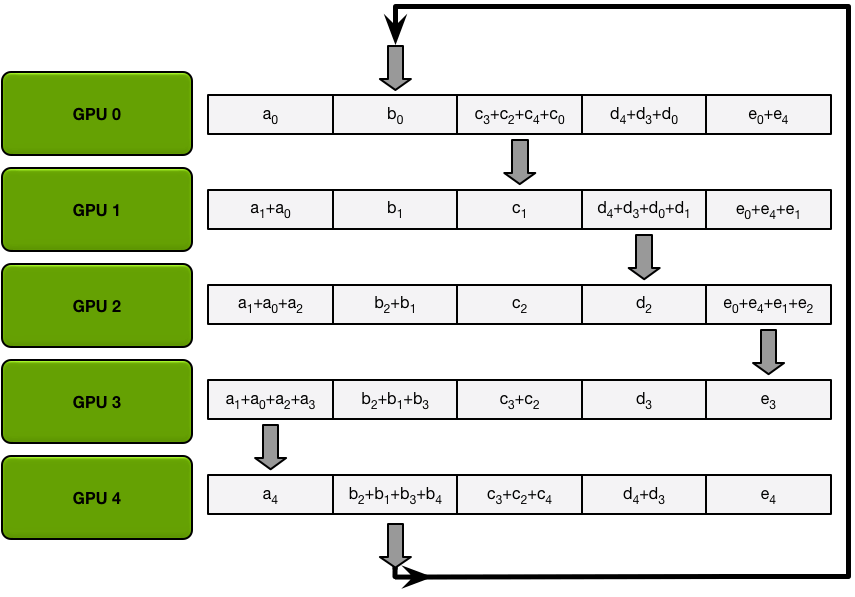
所有 Scatter-Reduce 传输后的最终状态:最终每个 GPU 将有一个块,这个块包含所有 GPU 中该块中所有值的总和。
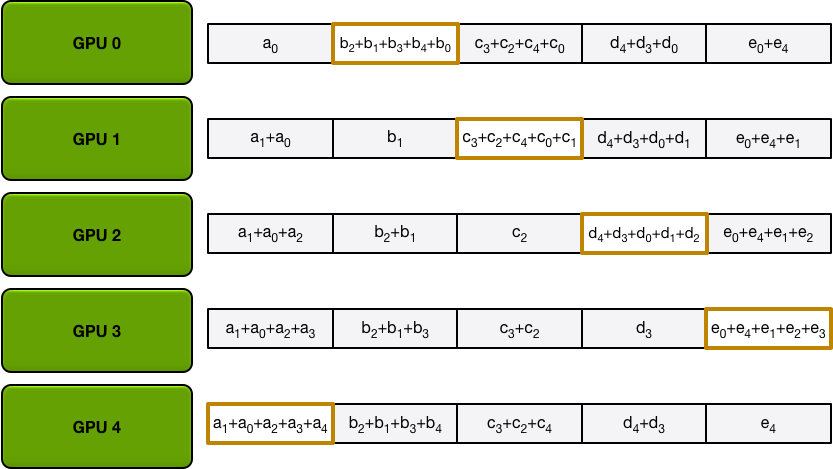
The AllGather
在 Scatter-Reduce 步骤完成后,在每个 GPU 的数组中都有某一些值(每个 GPU 有一个块)是最终值,其中包括来自所有 GPU 的贡献。为了完成 AllReduce,GPU 必须接下来交换这些块,以便所有 GPU 都具有最终所需的值。
Ring Allgather 与 Scatter-Reduce 进行相同的处理(发送和接收的 N-1 次迭代),但是他们这次不是累积 GPU 接收的值,而只是简单地覆盖块。第 n 个 GPU 开始发送第 n+1 个块并接收第 n 个块,然后在以后的迭代中始终发送它刚刚接收到的块。
第一次迭代
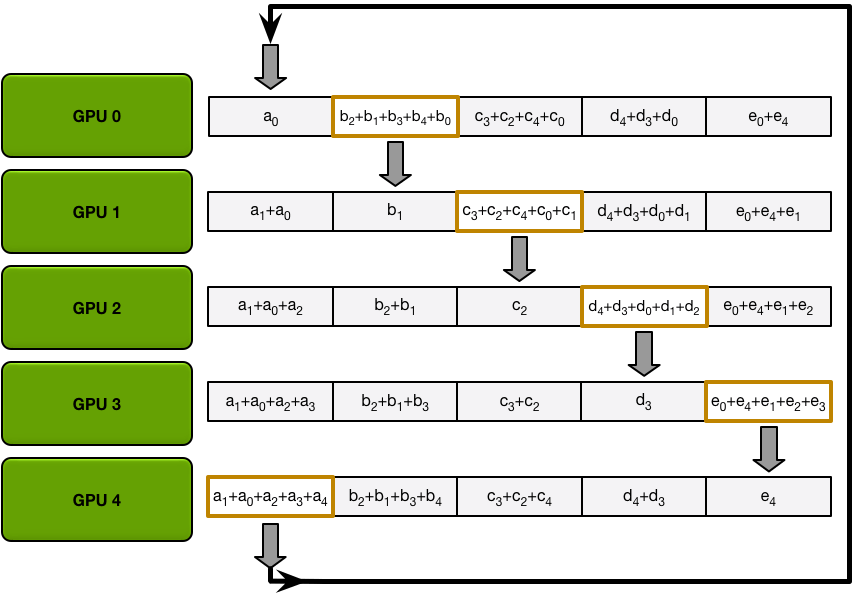
第二次迭代
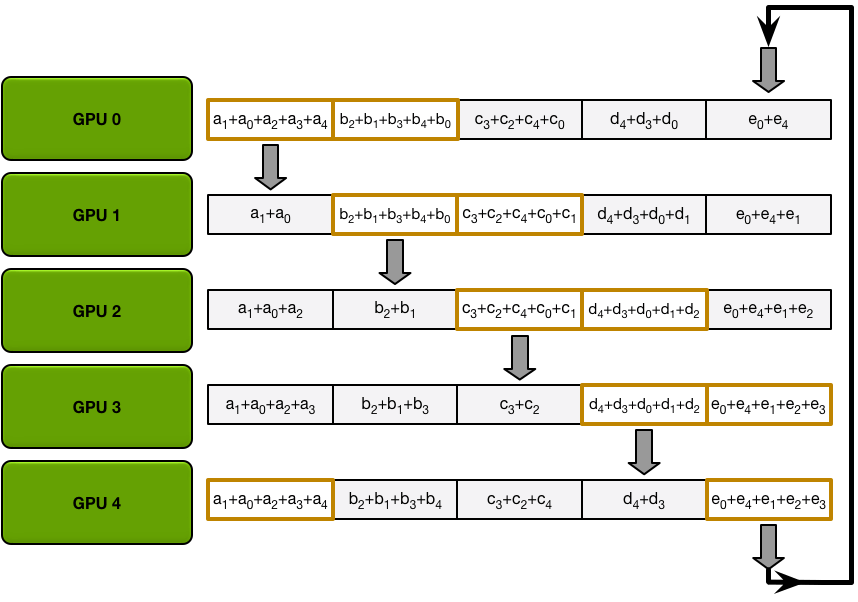
第三次迭代
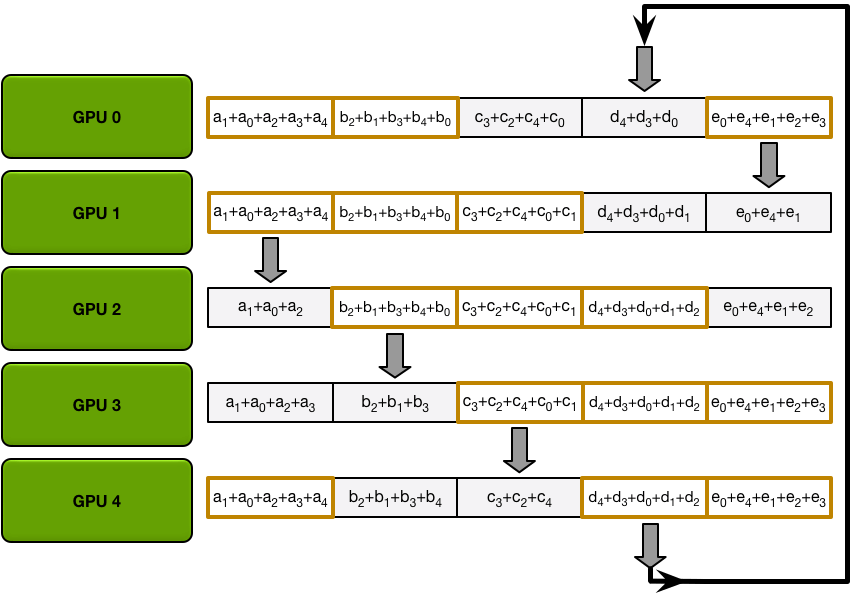
第四次迭代
所有全部转移后的最终状态

Communication Cost
$$Data Transferred=2(N−1) \frac{K}{N}$$
- 每 N 个 GPU 都会因为 Scatter-Reduce 而发送接收 N-1 次值,还为 AllGather 接收 N-1 次值。
- 每一次,GPU 都会发送 $K/N$ 个值,其中 K 是指数组中值的总数量,这是在不同 GPU 上相加得到的。因此,每个 GPU 的传入和传出数据总量为:被传输的数据=2 (N−1) /N⋅K。其独立于 GPU 的数量。
OpenMPI Implementation
在 OpenMPI 的实现中,MPI_AllReduce 主要有 7 种算法,具体可以参考 ompi/mca/coll/tuned/coll_tuned_allreduce_decision. C1
|
|
我们可以静态地指定算法,也可以让 OpenMPI 来决定2。当然,这不是这篇文章的重点。
在深度学习这一场景下,被最为广泛应用的是 RingAllReduce 这一实现。在 OpenMPI 中,这一实现在 ompi/mca/coll/base/coll_base_allreduce.c3。它的注释非常简洁明了地介绍了实现原理,建议阅读。简单来说,它利用了 MPI 的端到端通信的原语,实现了 RingAllReduce 的功能。将 RingAllReduce 分为了两个阶段。
- 第一个阶段等价于 MPI_ReduceScatter 的语义,是将结果计算到不同的进程。
- 第二个阶段等价于 MPI_AllGather 语义,将计算结果聚合到所有进程。
|
|
MPI_ReduceScatter
MPI_ReduceScatter 这一接口,本身也对应着非常多的实现。如果先做一次 MPI_Reduce 再做一次 MPI_Scatter(对应 ompi_coll_base_reduce_scatter_intra_nonoverlapping4),性能一定无法接受。所以这里的实现使用的是 ompi_coll_base_reduce_scatter_intra_ring5。通过 N-1 步,我们可以实现 MPI_ReduceScatter 的语义。其中每步中每个进程的上下行通信量都是 M/N。其中个 M 是数组的长度,N 是进程的数量。数组会被分为 N 等分,所以每次通信量是 M/N。
MPI_AllGather
MPI_AllGather 本身也有非常多的算法实现。RingAllReduce 使用的是 ompi_coll_base_allgather_intra_ring6。这一实现一共需要 N-1 步。在第 i 步的时候,Rank r 进程会收到来自 r-1 进程的信息,这一信息中包括了 r-i-1 进程的数据。同时,r 进程会给 r+1 进程发送包含 r-i 进程的数据。所以每步中每个进程的上下行通信量同样都是 M/N。
|
|
所以整体来看,单步中每个进程的上下行通信量为 M/N,而在整个过程中,每个进程的上下行通信量都是 2 (N-1)*M/N。所以我们认为 RingAllReduce 对带宽特别友好,能很好地解决参数服务器架构中的带宽瓶颈问题。其实 MPI_AllGather 除了 Ring 之外还有很多更高效的实现,但由于 MPI_RingAllReduce 中对带宽的要求至少是 M/N,因此 ompi_coll_base_allgather_intra_ring 的实现已经完全够用,在任意时刻都占满 M/N 的上下行。
Baidu Tensorflow AllReduce
将 RingAllReduce 引入深度学习,是百度的工作,这一工作开源在 baidu-research/tensorflow-allreduce7。百度利用了 MPI 端到端通信的原语,重新实现了 ompi_coll_base_allgather_intra_ring 和 ompi_coll_base_reduce_scatter_intra_ring。至于不直接使用 MPI_AllReduce 的原语,猜测应该是为了兼容更多的 MPI 实现,同时避免动态选择算法导致没有启用 RingAllReduce 的可能(尽管 OpenMPI 可以静态选择算法,但可能其他实现不支持)。
百度的这一实现非常易懂,总共只有 3000 行不到的代码,其中相当部分是测试。百度提供了一个自己的 Optimizer,重载了 compute_gradients 的实现。
|
|
所以整体来看,单步中每个进程的上下行通信量为 M/N,而在整个过程中,每个进程的上下行通信量都是 2 (N-1)*M/N。所以我们认为 RingAllReduce 对带宽特别友好,能很好地解决参数服务器架构中的带宽瓶颈问题。其实 MPI_AllGather 除了 Ring 之外还有很多更高效的实现,但由于 MPI_RingAllReduce 中对带宽的要求至少是 M/N,因此 ompi_coll_base_allgather_intra_ring 的实现已经完全够用,在任意时刻都占满 M/N 的上下行。
Baidu Tensorflow AllReduce
将 RingAllReduce 引入深度学习,是百度的工作,这一工作开源在 baidu-research/tensorflow-allreduce7。百度利用了 MPI 端到端通信的原语,重新实现了 ompi_coll_base_allgather_intra_ring 和 ompi_coll_base_reduce_scatter_intra_ring。至于不直接使用 MPI_AllReduce 的原语,猜测应该是为了兼容更多的 MPI 实现,同时避免动态选择算法导致没有启用 RingAllReduce 的可能(尽管 OpenMPI 可以静态选择算法,但可能其他实现不支持)。
百度的这一实现非常易懂,总共只有 3000 行不到的代码,其中相当部分是测试。百度提供了一个自己的 Optimizer,重载了 compute_gradients 的实现。
|
|
在初始化 optimizer,和使用 session 的时候,语句如下:
|
|
在 optimizer 调用 compute_gradients 的时候,首先会利用 TF 自己的 optimizer 计算出本地梯度,然后利用 AllReduce 来得到各个进程平均后的梯度。而在 Session 初始化的时候会预先执行 MPI_Init 进行 MPI 环境的初始化。
在底层,AllReduce 被注册为 Op,在 ComputeAsync 中,计算请求被入队到一个队列中。这一队列会被一个统一的后台线程处理。之所以引入这样一个后台线程,在注释8中有详细的介绍。
在百度的实现中,不同 Rank 的角色是不一样的,Rank 0 会充当 coordinator 的角色。它会协调来自其他 Rank 的 MPI 请求,起到一个调度协调的作用。这是一个工程上的考量,具体可以参考注释。顺便一提,百度的这个工作注释非常详尽,真乃学术界的典范。这一设计也被后来的 Horovod 采用。
百度也同时提供了 C 语言的 baidu-allreduce9,实现也非常简洁。
Horovod Implementation
References
-
No backlinks found.