Volcano
Architecture
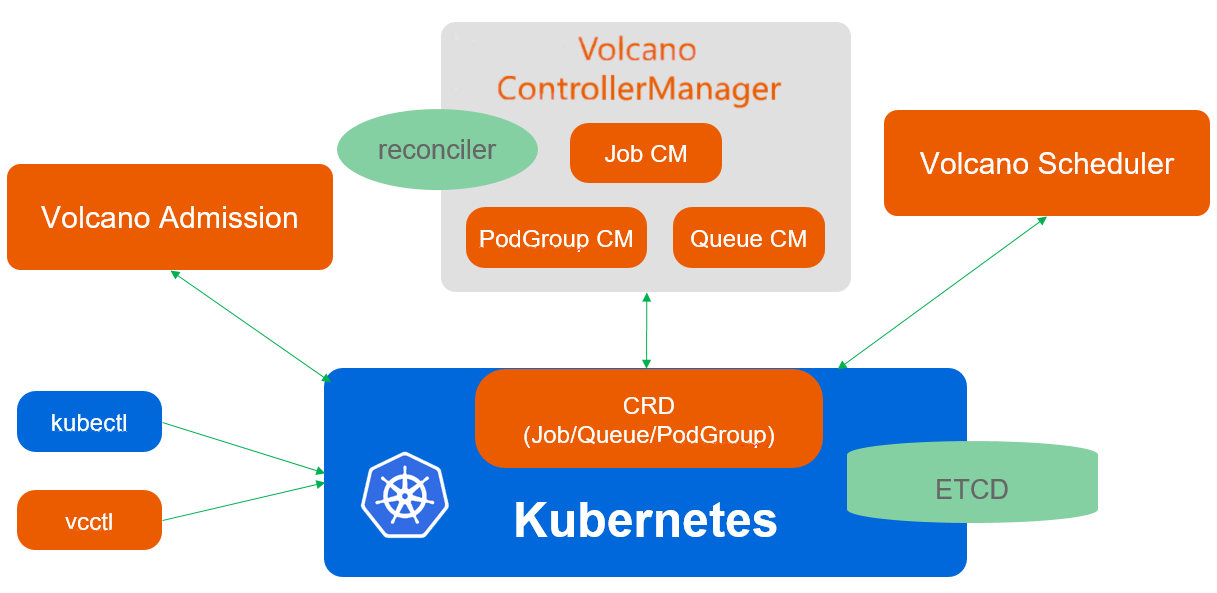
Implemetation
SchedulerCache
SchedulerCache 将调度所需的数据缓存起来,并保持与 apiserver 同步。Cache 模块还封装了对 API server 接口的调用。比如 Cache.Bind 接口,会调用 API Server 的 Bind 接口,将容器绑定到指定节点上。在 kube-batch/volcano 中,只有 cache 模块需要和 API Server 交互,其他模块只需要调用 Cache 模块接口。
|
|
SchedulerCache 会持有很多 informer, 初始化的 informer 注册各个 eventHandler,然后 pod/podgroup 等变动会被同步在 Jobs, Nodes, Queues, PriorityClasses 等几个 map 中。pg 加入 jobInfo,pod 加入 taskInfo。
Session
Session 模块是将 action/plugin/cache 三个模块串联起来的模块。Kube-batch 在每个调度周期开始时,都会新建一个 Session 对象,这个 Session 初始化时会做以下操作:
- 调用 Cache.Snapshot 接口,将 Cache 中节点、任务和队列信息拷贝一份副本,之后在这个调度周期中使用这份副本进行调度。因为 Cache 的数据会不断变化,为了保持同个调度周期中的数据一致性,在一开始就拷贝一份副本。PS:在一个调度周期,基于 snapshot 数据,找到当前资源可以运行的最高优先级的 pod,优先调度。全局决策,也是批量调度的一个内涵。
- 将配置中的各个 plugin 初始化,然后调用 plugin 的 OnSessionOpen 接口。plugin 在 OnSessionOpen 中,会初始化自己需要的数据,并将一些回调函数注册到 session 中。
plugin 会根据自己的语义注册相关的函数到 Session 中,在 Action.Execute 中被调用。
|
|
Action 只有一个 Session 一个入参,从 Session.jobs 等拿到数据,处理完成后写回 Session.jobs 等,Session 既是数据载体,也是 action 之间的信息传递渠道。比如 Enqueue action 将session.Jobs 中符合条件的 job 状态从 pending 改为非 pending,allocate/backfill action 不处理 pending 状态的 job。 allocate 不处理 request resource 为空的 task,backfill 会处理。
|
|
Session 一共有两类方法:
- session_plugins,与 plugin 相关的各种 Function 注入与调用;
- 真正操作 Pod 的 Allocate/Pipeline/Evict。 Action.Execute 中,Action 依次遍历 pending 状态的 task,根据 session_plugins 方法判断 task 和 job 状态,最终调用 Pod 的 Allocate/Pipeline/Evict。这或许是 Action 和 Plugin ,机制和策略分离的一种解释。
Gang Scheduler
gang-scheduler 非常类似分布式事务/tcc,tcc 有一个预留的动作,要实现 gang-scheduler 的效果,Pod 自带的 Pending/Running/Succeeded/Failed/Unknown 是不够的,为此 Pod 对应 struct TaskInfo 定义了 Pending/Allocated/Pipelined/Binding/Bound/Running/Releasing/Succeeded/Failed/Unknown 状态,其中 Allocated 用来标记 pod 已分配资源但未实际运行的状态。
当需要进行 gang-scheduler 时,上层 operator/controller 会将 pod 的 schedulerName 设置为 kube-batch 或 volcano,并带上 annotation scheduling.k8s.io/group-name,创建 name= scheduling.k8s.io/group-name 的 podgroup,即 podgroup 和 pod 通过scheduling.k8s.io/group-name 关联。
一个 podGroup 对应一个 JobInfo,kube-batch 将 pod 转换为 taskInfo,每一个 node 对应 NodeInfo,所谓为 pod 分配 Node:taskInfo.NodeName=nodeName,NodeInfo 减去 pod 标定的资源。当发现 JobInfo 下的 taskInfo 符合 minMember,即真正为 pod 赋值 nodeName。具体代码还要再捋捋。
Controller
Job
job-controller 中主要 list-watch 的是Job和Pod,同时也会 watchCommand资源的 add、PodGroup的 update 和PriorityClasses的 add 和 delete。job controller 中有两个特别重要的成员,分别是queueList和cache:
|
|
queueList 的本质是一个队列,队列的元素是自定义的一个 Request 对象,可以看到 Request 中主要包含的是跟 Job 相关的 key 信息,这也符合一般的队列模型,queue 中存放 key,cache 中存放实际的数据:
|
|
cache 的本质是一个 Job 资源的 map,key 是 namespace/name:
|
|
value 中既包含了 Job 的信息,也包含了这个 job 对应的 Pods 的信息
|
|
知道了 controller 中的关键的数据结构,我们也就能猜测 controller 的 reconcile 的逻辑了:生产者通过 list-watch 将 Job 的 key 信息加入到 queueList 中,将 Job 的实体信息保存到 jobCache 中缓存,消费者从 queueList 中获取数据并进行处理。其主要代码在 processNextReq 函数中:
|
|
不同 Action 和 State 对应的处理逻辑(空白的为 KillJob):
http://yost.top/2020/08/04/volcano-code-review/
通过以上过程我们可以看到 Job 的 reconcile 中存在比较多的状态,因此代码中使用了 Action 和 State 两个状态来进行状态机的转移,不过最终处理的逻辑主要就是 SyncJob 和 KillJob 两种,因此我们主要分析这两部分的逻辑。
SyncJob
KillJob
PodGroup
Queue
Scheduler
scheduler 是 volcano 的核心,它是以 PodGroup 为基本单位来进行调度的。
在设计之初我们就把 job和podgroup两个概念分开。所有跟作业相关的信息,都是放在 job里面;所有跟调度相关的信息都放在podgroup里面,这个设计与Kubernetes非常相像。
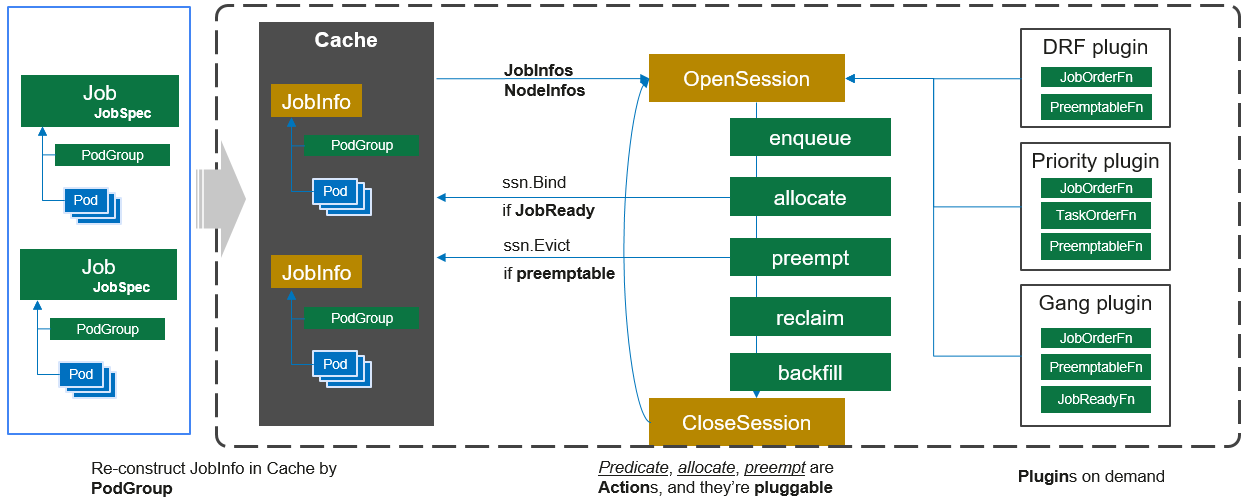
scheduler的架构可以参考下图:
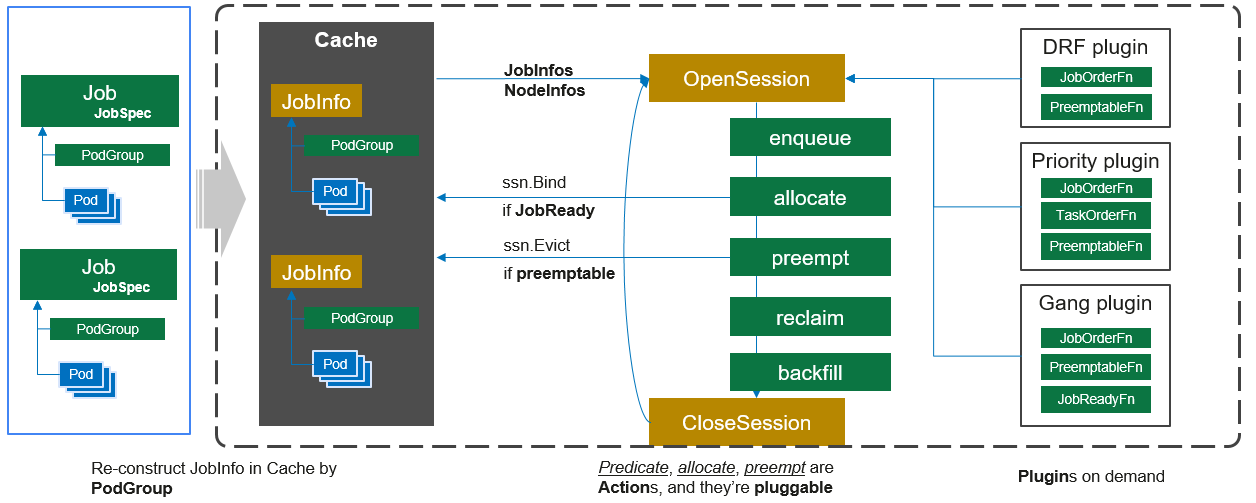
调度器的本质还是给所有没有绑定到节点上的pod找到合适的节点并绑定上去,但是为了实现gang调度、抢占、资源预留等功能,不能跟k8s的调度器一样通过watch到的pod事件来触发调度(大多数情况下,每一个pod的调度都是单pod最优),所以volcano的调度器采用的是周期性全局调度的方式。我们在看volcano的调度器代码时也能够看到调度逻辑也是这样的思路:
- list-watch的是PodGroup和Node
- 周期性创建一个全局调度的Session,对集群做一次快照
- 在每一个 Session 中,根据配置的调度算法和策略对快照中的所有 PodGroup 进行调度
|
|
一个默认的配置文件如下:
|
|
可以看到其中 Action 的顺序是 enqueue、allocate 和 backfill,调度器分成两层,一层是 priority 和 gang 调度,另一层是 drf、predicates、proportion 和 nodeorder 调度。
|
|
在 volcano 的调度器中,当前实现的 Action 有五个:
-
enqueue(入队):入队主要就是过滤出需要处理的Job,先通过
QueueOrderFn根据优先级将所有要处理的Queue加入到一个队列中,同时每一个Queue上的Job也通过JobOrderFn根据优先级将所有要处理的Job加入到这个Queue的队列中,然后根据Queue和Job的优先级来对每一个Job进行jobEnqueueableFn预判断(当前资源是否满足Job的需求) -
allocate(分配):分配其实就是给每一个Task绑定节点,是调度的核心,其处理逻辑主要分以下6步,主要逻辑就是每次选择一个优先级最高的Task,并找到打分最高的节点bind过去,直到所有的Task都处理完
- 通过
NamespaceOrderFn根据优先级选择一个需要去处理的namespace - 通过
QueueOrderFn根据优先级选择一个需要去处理的Queue - 通过
JobOrderFn根据优先级选择一个需要去处理的Job - 通过
TaskOrderFn根据优先级选择一个需要去处理的Task - 通过
predicateFn过滤去除不满足要求的节点 - 通过
NodeOrderFn来给节点进行打分,并将分数最高的节点bind给这个Task
- 通过
-
backfill(回填):volcano中为了避免饥饿而有条件地为大作业保留了一些资源,回填是对剩下来未调度小Task进行bind的过程,对于每一个未调度的Task:
- 遍历所有节点,通过
predicateFn滤除不满足要求的node - 尝试将该Task调度到满足要求的节点上
- 遍历所有节点,通过
-
preempt(抢占):抢占是一种特殊的Action,它主要处理的场景是当一个高优先级的Task进入调度器但是当前环境中的资源已经无法满足这个Task的时候,需要能将已经调度的任务中驱逐一部分优先级低的Task,以便这个高优先级的Task能够正常运行,因此其处理过程包含选择优先级低的Task并驱逐的逻辑。其处理流程为,对于PodGroup状态不为Pending的Job
- 通过
jobValidFn和jobPipelinedFn进行过滤 - 通过
JobOrderFn和TaskOrderFn对集群中的Job和Task进行优先级队列的初始化 - 对于每一个需要进行抢占调度的Task:
- 通过
predicateFn对所有节点进行过滤,通过batchNodeOrderFn、nodeOrderFn、nodeReduceFn对所有节点进行打分和排序 - 按照分数排序对每个节点上的Task调用
preemptableFns判断该Task是否可以抢占(也就是这个Task是否可以驱逐用来腾出资源给待调度的Task),指导找到节点并且可以驱逐的Task腾出来的资源满足待调度的Task为止 - 对于抢占而言,该Action中同时考虑了跨Queue和Queue内部跨Job之间的抢占
- 通过
- 通过
-
reclaim(回收):在volcano中,集群的资源是根据权重给每一个Queue分配的,当有一个新的Queue创建出来时,第一个Job的Task进行资源调度的时候就会触发回收,也就是对之前创建的Queue中的Task进行驱逐,腾出对应比例的资源给这个新Queue。其处理流程为:
- 通过
queueOrderFn对当前集群中的Queue进行优先级排序 - 通过
JobOrderFn和TaskOrderFn对集群中的Job和Task进行优先级队列的初始化 - 通过
overusedFn过滤掉超配额的Queue - 对于每一个Task,通过
reclaimableFn来判断是否需要触发回收 - 对于每一个需要触发回收的Task,执行驱逐操作(其实就是把要驱逐的Pod删掉)
- 通过
通过以上的归纳其实也可以得到function和action之间的关系(表格中的数字表示调用 顺序):
Plugins
Gang scheduling
Fair-share scheduling
Queue scheduling
Preemption scheduling
Reclain
Backfill
Resource reservation
Issues
Volcano 与机器学习的结合
https://github.com/kubeflow/training-operator
Reference
- https://qiankunli.github.io/2021/09/30/volcano.html
- https://mp.weixin.qq.com/s?__biz=MzIzNzU5NTYzMA==&mid=2247490455&idx=1&sn=963da74b48bfd7c6a3fa1c8158ac4095&chksm=e8c76516dfb0ec00898e0498e1bd00e1c95ddc096ce09d05bd05400b80c5a835c17264a1c6b6&scene=21#wechat_redirect
- https://zhuanlan.zhihu.com/p/344443485
- https://kccncna2022.sched.com/event/182HX/efficient-scheduling-of-high-performance-batch-computing-for-analytics-workloads-with-volcano-krzysztof-adamski-tinco-boekestijn-ing
-
No backlinks found.