Flink

- Concept
- Flink Timely Stream Processing
- Stateful Stream Processing
- Flink Architecture
- Flink Runtime
- Flink Deployment
- Flink Libraries
- Flink Connectors
- Fault Tolerance
- Flink on k8s
本文整体介绍 Apache Flink 流计算框架的特性、概念、组件栈、架构及原理分析。
Flink Overview
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台。它能够基于同一个 Flink Runtime,提供支持流处理和批处理两种类型应用的功能。
现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为他们它们所提供的 SLA 是完全不相同的:
- 流处理一般需要支持低延迟、Exactly-once 保证
- Samza、Storm
- 批处理需要支持高吞吐、高效处理
- MapReduce、Tez、Crunch、Spark
所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。
Flink 在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:
- Flink 是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的
- 批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的
- 基于同一个 Flink Runtime,分别提供了流处理和批处理 API,而这两种 API 也是实现上层面向流处理、批处理类型应用框架的基础
基本特性
关于 Flink 所支持的特性,我这里只是通过分类的方式简单做一下梳理,涉及到具体的一些概念及其原理会在后面的部分做详细说明。
流处理特性
- 支持高吞吐、低延迟、高性能的流处理
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的 Exactly-once 语义
- 支持高度灵活的窗口(Window)操作,支持基于 time、count、session,以及 data-driven 的窗口操作
- 支持具有 Backpressure 功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
- Flink 在 JVM 内部实现了自己的内存管理
- 支持迭代计算
- 支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存
API 支持
- 对 Streaming 数据类应用,提供 DataStream API
- 对批处理类应用,提供 DataSet API(支持 Java/Scala)
Libraries 支持
相关上层 Library 支持情况如下:
- 支持机器学习 FlinkML
- 支持图分析 Gelly
- 支持关系数据处理 Table
- 支持复杂事件处理 CEP
与其他外部系统对接支持如下:
- 支持 Flink on YARN
- 支持 HDFS
- 支持来自 Kafka 的输入数据
- 支持 Apache HBase
- 支持 Hadoop 程序
- 支持 Alluxio
- 支持 ElasticSearch
- 支持 RabbitMQ
- 支持 Apache Storm
- 支持 S3
- 支持 XtreemFS
基本架构
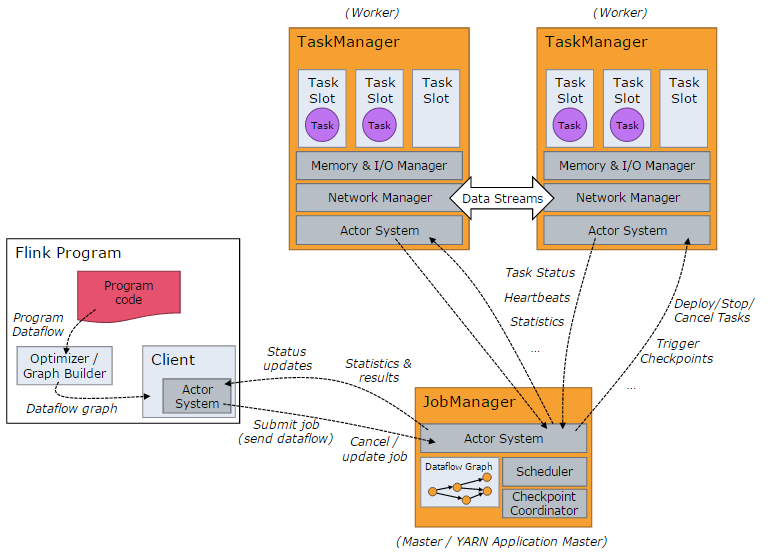
Flink 集群启动时,会启动一个 JobManager 进程、至少一个 TaskManager 进程。
在 Local 模式下,会在同一个 JVM 内部启动一个 JobManager 进程和 TaskManager 进程。
当 Flink 程序提交后,会创建一个 Client 来进行预处理,并转换为一个并行数据流,这是对应着一个 Flink Job,从而可以被 JobManager 和 TaskManager 执行。
在实现上,Flink 基于 Actor 实现了 JobManager 和 TaskManager,所以 JobManager 与 TaskManager 之间的信息交换,都是通过事件的方式来进行处理。
如上图所示,Flink 系统主要包含如下 3 个主要的进程:
内部原理
调度机制
在 JobManager 端,会接收到 Client 提交的 JobGraph 形式的 Flink Job。
JobManager 会将一个 JobGraph 转换映射为一个 ExecutionGraph,如下图所示:
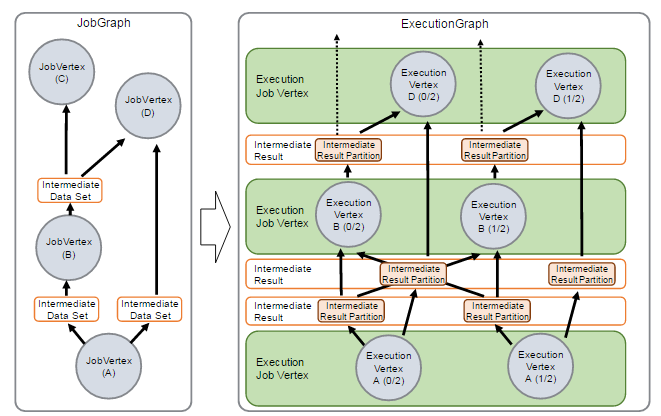
通过上图可以看出:
- JobGraph 是一个 Job 的用户逻辑视图表示,将一个用户要对数据流进行的处理表示为单个 DAG 图(对应于 JobGraph)
- DAG 图由顶点(JobVertex)和中间结果集(IntermediateDataSet)组成,
- 其中 JobVertex 表示了对数据流进行的转换操作,比如 map、flatMap、filter、keyBy 等操作,而 IntermediateDataSet 是由上游的 JobVertex 所生成,同时作为下游的 JobVertex 的输入。
而 ExecutionGraph 是 JobGraph 的并行表示,也就是实际 JobManager 调度一个 Job 在 TaskManager 上运行的逻辑视图。
它也是一个 DAG 图,是由 ExecutionJobVertex、IntermediateResult(或 IntermediateResultPartition)组成
ExecutionJobVertex 实际对应于 JobGraph 图中的 JobVertex,只不过在 ExecutionJobVertex 内部是一种并行表示,由多个并行的 ExecutionVertex 所组成。
另外,这里还有一个重要的概念,就是 Execution,它是一个 ExecutionVertex 的一次运行 Attempt。
也就是说,一个 ExecutionVertex 可能对应多个运行状态的 Execution。
比如,一个 ExecutionVertex 运行产生了一个失败的 Execution,然后还会创建一个新的 Execution 来运行,这时就对应这个 2 次运行 Attempt。
每个 Execution 通过 ExecutionAttemptID 来唯一标识,在 TaskManager 和 JobManager 之间进行 Task 状态的交换都是通过 ExecutionAttemptID 来实现的。
下面看一下,在物理上进行调度,基于资源的分配与使用的一个例子,来自官网,如下图所示:
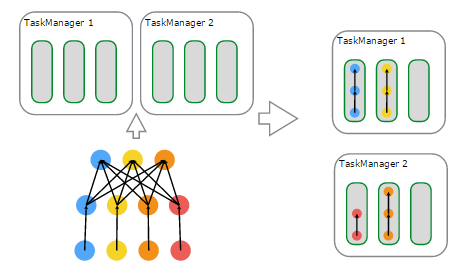
说明如下:
- 左上子图:有 2 个 TaskManager,每个 TaskManager 有 3 个 Task Slot
- 左下子图:一个 Flink Job,逻辑上包含了 1 个 data source、1 个 MapFunction、1 个 ReduceFunction,对应一个 JobGraph
- 左下子图:用户提交的 Flink Job 对各个 Operator 进行的配置——data source 的并行度设置为 4,MapFunction 的并行度也为 4,ReduceFunction 的并行度为 3,在 JobManager 端对应于 ExecutionGraph
- 右上子图:TaskManager 1 上,有 2 个并行的 ExecutionVertex 组成的 DAG 图,它们各占用一个 Task Slot
- 右下子图:TaskManager 2 上,也有 2 个并行的 ExecutionVertex 组成的 DAG 图,它们也各占用一个 Task Slot
在 2 个 TaskManager 上运行的 4 个 Execution 是并行执行的
迭代机制
机器学习和图计算应用,都会使用到迭代计算。
Flink 通过在迭代 Operator 中定义 Step 函数来实现迭代算法,这种迭代算法包括 Iterate 和 Delta Iterate 两种类型,在实现上它们反复地在当前迭代状态上调用 Step 函数,直到满足给定的条件才会停止迭代。
下面,对 Iterate 和 Delta Iterate 两种类型的迭代算法原理进行说明:
Iterate
Iterate Operator 是一种简单的迭代形式:
- 每一轮迭代,Step 函数的输入或者是输入的整个数据集,或者是上一轮迭代的结果,通过该轮迭代计算出下一轮计算所需要的输入(也称为 Next Partial Solution)
- 满足迭代的终止条件后,会输出最终迭代结果,具体执行流程如下图所示:
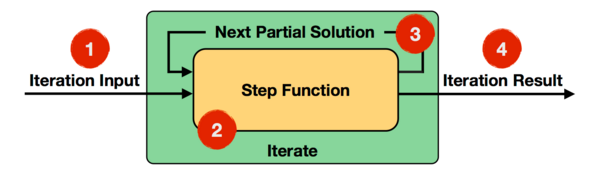
Step 函数在每一轮迭代中都会被执行,它可以是由 map、reduce、join 等 Operator 组成的数据流。
下面通过官网给出的一个例子来说明 Iterate Operator,非常简单直观,如下图所示:
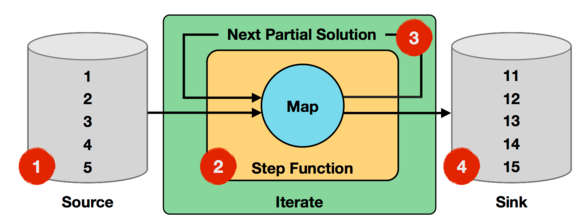
上面迭代过程中,输入数据为 1 到 5 的数字,Step 函数就是一个简单的 map 函数,会对每个输入的数字进行加 1 处理,而 Next Partial Solution 对应于经过 map 函数处理后的结果。
比如第一轮迭代,对输入的数字 1 加 1 后结果为 2,对输入的数字 2 加 1 后结果为 3,直到对输入数字 5 加 1 后结果为变为 6,这些新生成结果数字 2~6 会作为第二轮迭代的输入。
迭代终止条件为进行 10 轮迭代,则最终的结果为 11~15。
Delta Iterate
Delta Iterate Operator 实现了增量迭代,它的实现原理如下图所示:
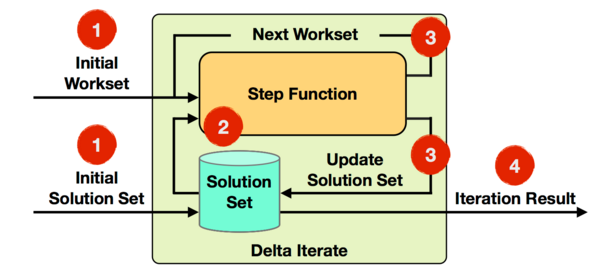
基于 Delta Iterate Operator 实现增量迭代,它有 2 个输入:
- 其中一个是初始 Workset,表示输入待处理的增量 Stream 数据
- 另一个是初始 Solution Set,它是经过 Stream 方向上 Operator 处理过的结果。
第一轮迭代会将 Step 函数作用在初始 Workset 上,得到的计算结果 Workset 作为下一轮迭代的输入,同时还要增量更新初始 Solution Set。
如果反复迭代知道满足迭代终止条件,最后会根据 Solution Set 的结果,输出最终迭代结果。
比如,我们现在已知一个 Solution 集合中保存的是,已有的商品分类大类中购买量最多的商品。
而 Workset 输入的是来自线上实时交易中最新达成购买的商品的人数,经过计算会生成新的商品分类大类中商品购买量最多的结果。
如果某些大类中商品购买量突然增长,它需要更新 Solution Set 中的结果(原来购买量最多的商品,经过增量迭代计算,可能已经不是最多),最后会输出最终商品分类大类中购买量最多的商品结果集合。
更详细的例子,可以参考官网给出的“Propagate Minimum in Graph”,这里不再累述。
Backpressure 监控机制
Backpressure 在流式计算系统中会比较受到关注。
因为在一个 Stream 上进行处理的多个 Operator 之间,它们处理速度和方式可能非常不同,所以就存在上游 Operator 如果处理速度过快,下游 Operator 处可能机会堆积 Stream 记录,严重会造成处理延迟或下游 Operator 负载过重而崩溃(有些系统可能会丢失数据)。
因此,对下游 Operator 处理速度跟不上的情况,如果下游 Operator 能够将自己处理状态传播给上游 Operator,使得上游 Operator 处理速度慢下来就会缓解上述问题,比如通过告警的方式通知现有流处理系统存在的问题。
Flink Web 界面上提供了对运行 Job 的 Backpressure 行为的监控,它通过使用 Sampling 线程对正在运行的 Task 进行堆栈跟踪采样来实现,具体实现方式如下图所示:
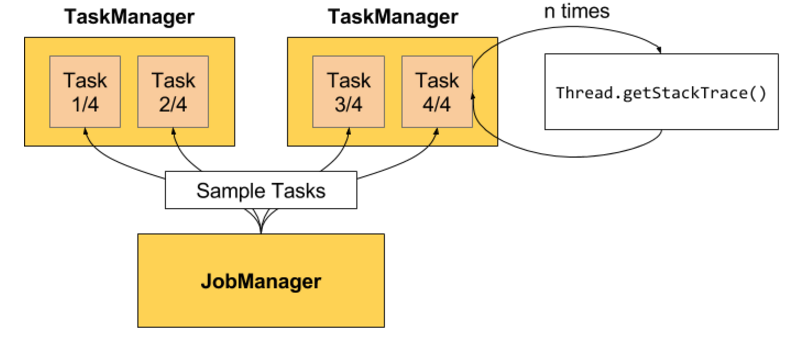
JobManager 会反复调用一个 Job 的 Task 运行所在线程的 Thread.getStackTrace()。
默认情况下,JobManager 会每间隔 50ms 触发对一个 Job 的每个 Task 依次进行 100 次堆栈跟踪调用,根据调用调用结果来确定 Backpressure,Flink 是通过计算得到一个比值(Radio)来确定当前运行 Job 的 Backpressure 状态。
在 Web 界面上可以看到这个 Radio 值,它表示在一个内部方法调用中阻塞(Stuck)的堆栈跟踪次数,例如,radio=0.01,表示 100 次中仅有 1 次方法调用阻塞。
Flink 目前定义了如下 Backpressure 状态:
- OK: 0 <= Ratio <= 0.10
- LOW: 0.10 < Ratio <= 0.5
- HIGH: 0.5 < Ratio <= 1
另外,Flink 还提供了 3 个参数来配置 Backpressure 监控行为:
| 参数名称 | 默认值 | 说明 |
|---|---|---|
| jobmanager.web.backpressure.refresh-interval | 60000 | 默认 1 分钟,表示采样统计结果刷新时间间隔 |
| jobmanager.web.backpressure.num-samples | 100 | 评估 Backpressure 状态,所使用的堆栈跟踪调用次数 |
| jobmanager.web.backpressure.delay-between-samples | 50 | 默认 50 毫秒,表示对一个 Job 的每个 Task 依次调用的时间间隔 |
通过上面个定义的 Backpressure 状态,以及调整相应的参数,可以确定当前运行的 Job 的状态是否正常,并且保证不影响 JobManager 提供服务。