Spark
Spark History

Spark EcoSystem
Spark 生态系统以 Spark Core 为核心,数据源可以来自 HDFS、S3、Alluxio 和 NoSQL 等数据源,可以通过 Standalone、 YARN 或者 Kubernetes 等实现资源调度管理,完成应用程序分析与处理。
其上应用可以为 Spark Streaming 的实时流处理应用,Spark SQL 的 AdHoc 查询,或者是 MLbase/MLlib 的机器学习应用,GraphX 的图处理和 SparkR 的数学计算。

Spark Core
Spark Core 是整个 Spark 系统的核心组件,是一个分布式大数据处理框架,其主要特性如下:
- 多种运行模式
- 基于内存计算
- 基于 DAG 处理
- 基于 RDD 的数据抽象

Spark Streaming
Spark Streaming 是一个对实时数据流进行高吞吐、高容错的流逝处理系统,可以对多种数据源(如 Kafka 等)进行类似 Map、Reduce 和 Join 等复杂操作,并将结果保存到外部文件系统、数据库或者应用到实时仪表盘。
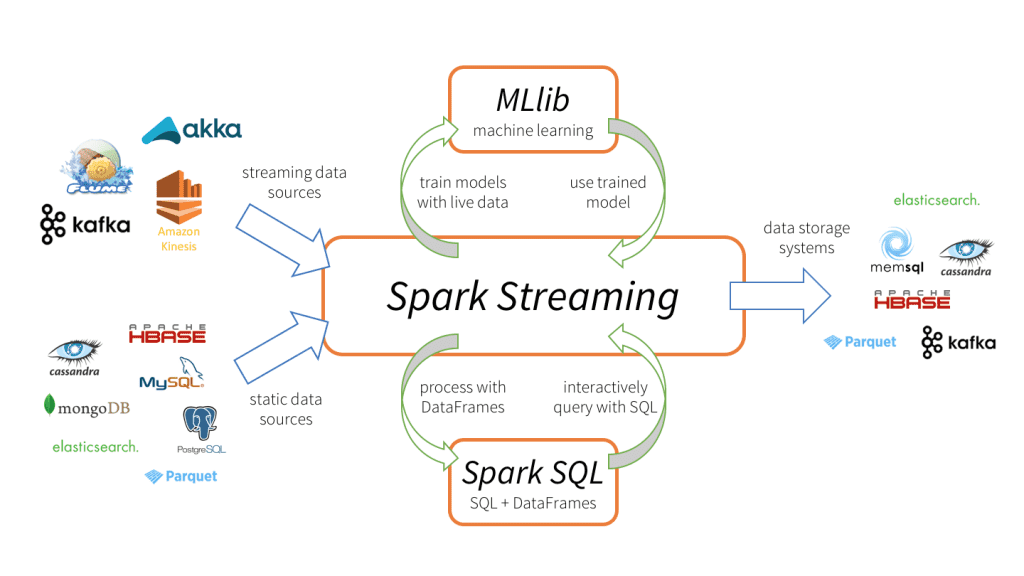
Spark Streaming 的特点如下:
- 动态负载均衡
- 快速故障恢复机制
- 批处理、流处理一体化:Spark Streaming 是讲流式计算分解成一系列短小的批处理作业
Spark SQL
Spark SQL 的特点如下:
- 引入了新的 RDD 类型 Schema RDD,可以像传统数据库定义表一样来定义 SchemaRDD。SchemeRDD 有定义了列数据类型的行对象构成。
- 内嵌了 Catalyst 查询优化框架,在把 SQL 解析成逻辑执行单元之后,利用 Catalyst 包里的一些类和接口,执行了一些简单的执行计划优化,最后变成 RDD 的计算。
- 在应用程序中可以混合使用不同来源的数据,如可以讲来自 HiveQL 的数据和来自 SQL 的数据进行 Join 操作。


MLlib
MLlib 是 Spark 生态中提供机器学习的 library。
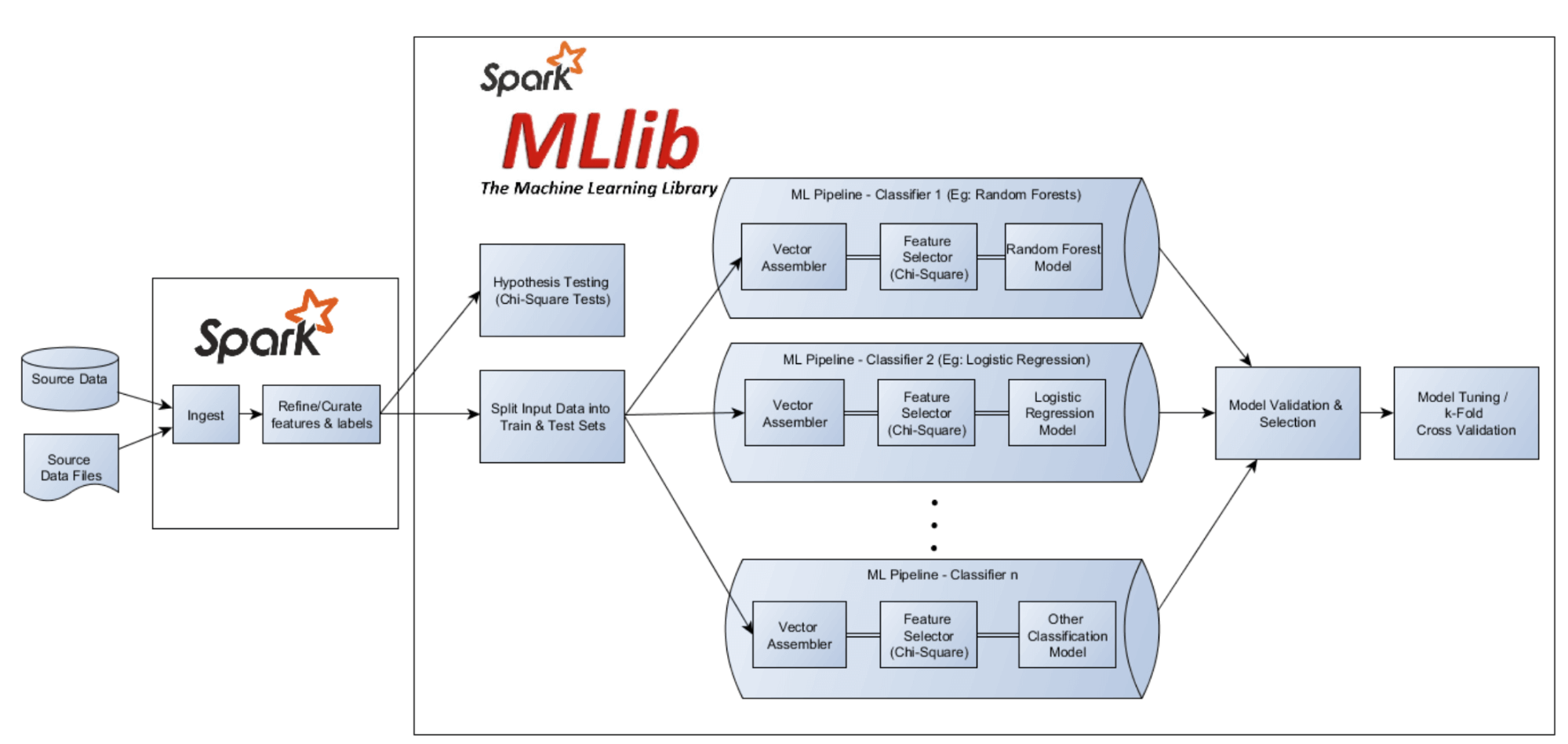
GraphX
GraphX 最初是 Berkeley AMP 实验室的一个分布式图计算框架项目,后来整合到 Spark 中成为一个核心组件,用于提供图和图并行计算的 API。
GraphX 讲图计算和数据计算集成到一起,数据不仅可以作为 Graph 进行操作,同样可以作为 Table 进行操作。这样可以解决传统的图计算往往需要不同的系统支持不同的 View,例如在 Table View 这种视图下可能需要 Spark 的支持或者 Hadoop 的支持,而在 GraphView 这种事图下可能需要 Pregel 或者 GraphLab 的支持。
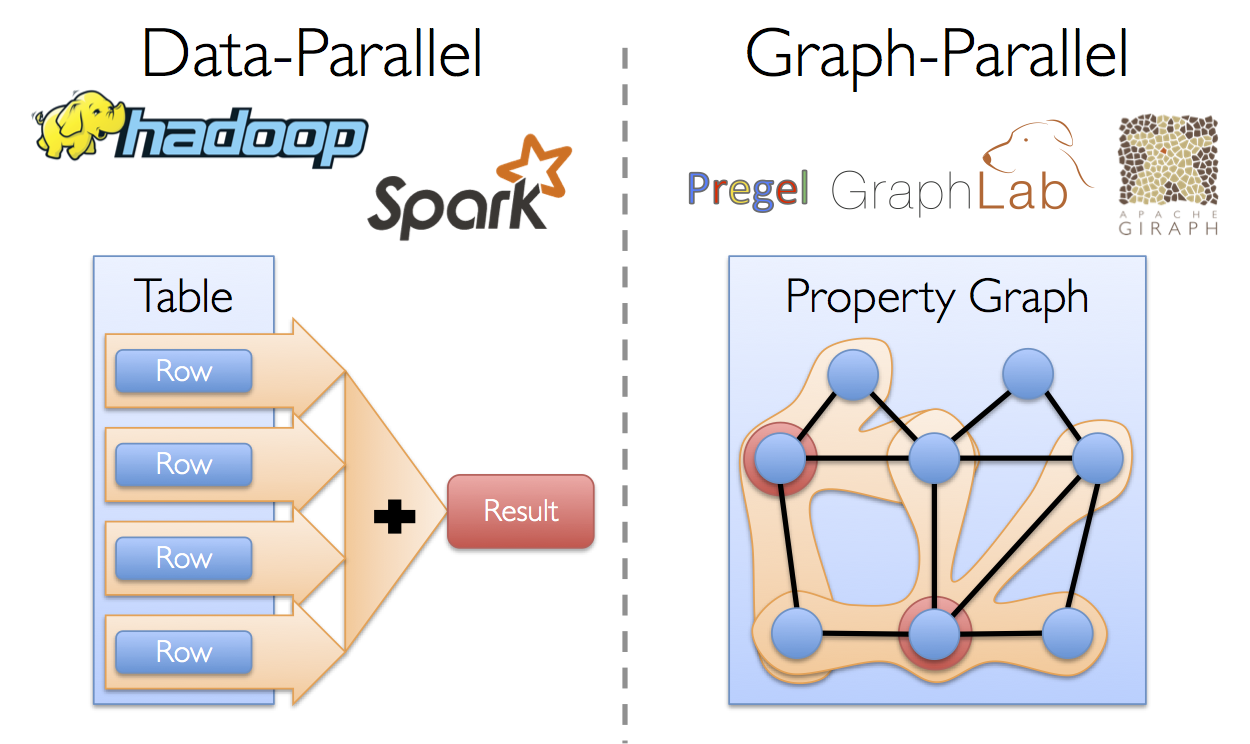
不同的系统不仅带来了学习、部署和管理的成本,最重要的还是效率问题。因为在不同的转换中间每步都要落地的话,数据转换和复制带来的开销也非常大,包括序列化带来的开销。GraphX 实现了 Unified Representation,统一了 TableView 和 GraphView,基于 Spark 可以非常轻松地进行 pipeline 的操作。
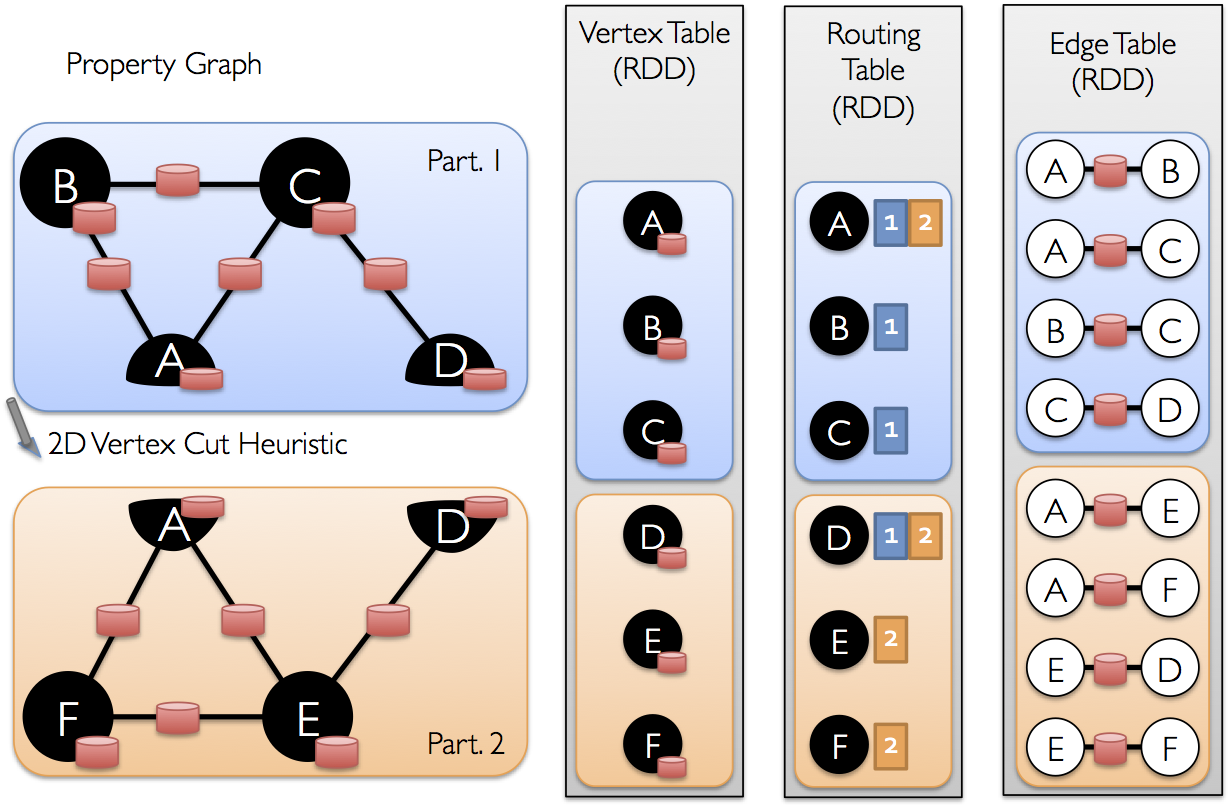
SparkR
R 是遵循 GNU 协议的一款开源、免费软件,广泛应用于统计计算和统计制图,但是它只能单机运行。为了能够使用 R 语言分析大规模分布式的数据,Spark 在 1.4 版本中加入了 SparkR。通过 SparkR 可以分析大规模的数据集,并通过 R shell 交互式地在 SparkR 上运行作业。

Spark Programming Model
计算机的普遍应用和移动互联网的兴起导致了数据量爆发式的增长,为了处理大批量的数据,最早 Google 提出了 MapReduce 这一批处理计算模型,后续有发展出了 Storm 流处理系统、Impala 交互式 SQL 查询系统等。这些模型都需要 高效的数据共享,比如:
- 迭代算法(PageRank,K-means 聚类和逻辑回归),都需要进行多次访问相同的数据集
- 流式应用需要随着时间对状态进行共享和维护
尽管这些框架支持大量的计算操作运算,但是它们 缺少针对数据共享的高效元语,这些框架中,实现计算之间共享数据只有一个办法,就是把数据写入到外部存储系统,比如 HDFS。这样会引入数据备份、磁盘 I/O 以及序列化等开销,从而占据大部分的执行时间。
Spark 的思路恰恰相反,设计了统一的编程抽象 —— RDD,即 弹性数据集 Resilient Distributed Datasets。RDD 既是 Spark 面向开发者的编程模型,又是 Spark 自身架构的核心元素。RDD 模型可以令用户直接控制数据的共享,使得用户可以指定数据存储到硬盘还是内存、控制数据的分区方法和数据集上进行的操作。
RDD Overview
RDD 是 MapReduce 模型的扩展和延伸,但它解决了 MapReduce 的缺陷:在并行计算阶段高效地进行数据共享。
RDD 是一个抽象的数据集,并不是用来装真正要计算的数据,而装的是处理数据的描述信息(即,对哪个文件进行计算,该怎么计算),任何数据在 Spark 中都被表示为 RDD,从编程角度来看,RDD 可以简单的看成一个数组,和普通的数组的区别是,RDD 中的数据是分布式存储的,这样不同分区的数据就可以分布在不同的机器上,同时可以被并行化处理。因此,Spark 应用程序所做的无非是把需要处理的数据转换成 RDD,然后 RDD 进行一系列的变换和操作从而得到结果。
Spark 中的操作大致可以分为四类:
- Creation Operation:用于 RDD 创建工作,RDD 的创建操作是惰性操作,只有两种途径:
- 来自于内存集合和外部存储集合
- 通过转换操作生成的 RDD
- Transformation Operation
- 将 RDD 通过一定的操作变换成新的 RDD
- RDD 的转换操作是惰性操作,它只是定义了一个新的 RDDs,并没有立即执行
- Control Operation
- 进行 RDD 持久化,可以让 RDD 按照不同的存储策略保存在磁盘或者内存中
- 比如
cache接口默认将 RDD 缓存在内存中
- Action Operation
- 能够触发 Spark 运行的操作
RDD 典型的执行过程如下:
RDD读入外部数据源进行创建,利于使用textFile函数加载本地数据;RDD经过一系列的Transformation操作,每一次都会产生不同的RDD,供给狭义转换作使用,这里的Transformation操作就是filter函数;- 最后一个
RDD经过Action操作进行转换,并输出到外部数据源。

Spark 采用 RDD以后能够实现高效计算的原因主要在于:
- 高效的容错性。
- 传统方式:现在的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输,这对于数据密集型应用而言会带来很大的开销。
RDD方式:在RDD的设计中,数据只读,不可修改,如果要修改数据,必须从父RDD转换到子RDD,由此在不同的RDD之间建立了血缘关系。所以,RDD是一种天生具有具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需要通过RDD父子依赖(血缘)关系重算计算得到丢失的分区来实现容错,无须回滚整个系统,这样就避免了数据复制的高开销,而且重算过程可以在不同节点并行进行,实现了高效的容错。- 此外:
RDD提供的转换操作都是一些粗粒度的操作(比如 map、filter 和 join),RDD依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志,这就大大降低了数据密集型应用中容错开销。
- 中间结果持久化到内存,数据在内存中的多个
RDD操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销。 - 存放的数据可以是 Java 对象,避免了不必要的对象序列化和反序列化。
Programming Interface
一个 RDD 就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个 RDD 可分成多个分区,每个分区就是一个数据集片段,并且一个 RDD 的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD 提供了一种高度受限的共享内存模型,即 RDD 是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建 RDD,或者通过在其他 RDD 上执行确定的转换操作(如 map、join 和 group by)而创建得到新的 RDD。
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel. This class contains the basic operations available on all RDDs, such as map, filter, and persist. In addition, PairRDDFunctions contains operations available only on RDDs of key-value pairs, such as groupByKey and join; DoubleRDDFunctions contains operations available only on RDDs of Doubles; and SequenceFileRDDFunctions contains operations available on RDDs that can be saved as SequenceFiles. These operations are automatically available on any RDD of the right type (e.g. RDD[(Int, Int)] through implicit conversions when you import spark.SparkContext._.
Internally, each RDD is characterized by five main properties:
- A list of splits (partitions)
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
All of the scheduling and execution in Spark is done based on these methods, allowing each RDD to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for reading data from a new storage system) by overriding these functions. Please refer to the Spark paper for more details on RDD internals.
Partitions
RDD 划分成很多的 Partition 分布在集群的节点中,分区的多少涉及对这个 RDD 进行并行计算的粒度。Partition 是一个逻辑概念,变换前后对新旧分区在物理上可能是同一块内存或者存储,这种优化防止函数式不变性导致的内存需求无限扩张。
|
|
PreferredLocaltions
在 Spark 形成任务有向无环图 DAG 时,会尽可能把计算分配到靠近数据的位置,减少数据网络传输。当 RDD 产生的时候存在首选位置,如 HadoopRDD 分区的首选位置就是 HDFS 所在的节点。
Dependencies
RDD 之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。简单的区分,可以看一下父 RDD 中的数据是否进入不同的子 RDD,如果只进入到一个子 RDD 则是窄依赖,否则就是宽依赖。如下图

窄依赖( narrow dependencies )
- 子 RDD 的每个分区依赖于常数个父分区(即与数据规模无关)
- 输入输出一对一的算子,且结果 RDD 的分区结构不变,主要是 map 、flatMap
- 输入输出一对一,但结果 RDD 的分区结构发生了变化,如 union 、coalesce
- 从输入中选择部分元素的算子,如 filter 、distinct 、subtract 、sample
宽依赖( wide dependencies )
- 子 RDD 的每个分区依赖于所有父 RDD 分区
- 对单个 RDD 基于 key 进行重组和 reduce ,如 groupByKey 、reduceByKey ;
- 对两个 RDD 基于 key 进行 join 和重组,如 join
Spark 任务会根据 RDD 之间的依赖关系,形成一个 DAG 有向无环图,DAG 会提交给 DAGScheduler,DAGScheduler 会把 DAG 划分相互依赖的多个 stage,划分 stage 的依据就是 RDD 之间的宽窄依赖。遇到宽依赖就划分 stage,每个 stage 包含一个或多个 task 任务。然后将这些 task 以 taskSet 的形式提交给 TaskScheduler 运行。 stage 是由一组并行的 task 组成。
切割规则:
- 在
DAG中进行反向解析,遇到宽依赖就断开 - 遇到窄依赖就把当前的
RDD加入到Stage中 - 将窄依赖尽量划分在同一个
Stage中,可以实现流水线计算

Iterator
Spark 中 RDD 计算是以分区为单位的,而且计算函数都是在对迭代器复合,不需要保存每次计算的结果。分区计算一般使用 mapPartitions 等操作进行,mapPartitions 的输入函数是应用于每个分区,也就是把每个分区中的内容作为整体来处理的。
Partitioner
分区划分对于 Shuffle 类操作很关键,它决定了该操作的父 RDD 和子 RDD 之间的依赖类型。
Creation
目前有两种类型的基础 RDD:
- 一种是并行集合
Parallelized Collections:接收一个已经存在的 Scala 集合,然后进行各种并行计算 - 一种是从外部存储创建的 RDD
并行化集合创建操作
|
|
外部存储创建操作
|
|
Transformation
主要做的是就是将一个已有的 RDD 生成另外一个 RDD。Transformation 具有 lazy 特性(延迟加载)。Transformation 算子的代码不会真正被执行。只有当我们的程序里面遇到一个 action 算子的时候,代码才会真正的被执行。这种设计让 Spark 更加有效率地运行。
常用的 Transformation:
| 动作 | 说明 | 示例 |
|---|---|---|
| map(func) | 返回一个新的 RDD,该 RDD 由每一个输入元素经过 func 函数转换后组成 (每一个输入元素只能被映射为一个) | |
| filter(func) | 返回一个新的 RDD,该 RDD 由经过 func 函数计算后返回值为 true 的输入元素组成 | |
| flatMap(func) | 类似于 map,但是每一个输入元素可以被映射为 0 或多个输出元素(所以 func 应该返回一个序列,而不是单一元素) | |
| sample(withReplacement, fraction, seed) | 根据 fraction 指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed 用于指定随机数生成器种子 | |
| groupByKey([numTasks]) | 在一个(K,V)的 RDD 上调用,返回一个(K, Iterator[V])的 RDD | |
| sample(withReplacement, fraction, seed) | 根据 fraction 指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed 用于指定随机数生成器种子 | |
| combineByKey | 合并相同的 key 的值 rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) | jake 80.0 jake 90.0 jake 85.0 mike 86.0 mike 90 求分数的平均值 |
单 Value 类型算子补充:
- mapPartitions: 将待处理的数据以分区为单位发送到计算节点进行处理;
- glom: 将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变 ;
- groupBy: 将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合 ;
- distinct: 将数据集中重复的数据去重 ;
- coalesce: 根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率
- 当 spark 程序中存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本 ;
- repartition: 该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。
- sortBy: 该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照** f 函数处理的结果进行排序,默认为升序排列
双 Value 类型算子补充
- intersection: 对源 RDD 和参数 RDD 求交集后返回一个新的 RDD
- union: 对源 RDD 和参数 RDD 求并集后返回一个新的 RDD
- subtract: 以一个 RDD 元素为主, 去除两个 RDD 中重复元素,将其他元素保留下来
Action
触发代码的运行,我们一段 spark 代码里面至少需要有一个 action 操作。
常用的 Action:
| 动作 | 含义 | 示例 |
|---|---|---|
| reduce(func) | 通过 func 函数聚集 RDD 中的所有元素,可以实现,RDD 中元素的累加,计数和其他类型的聚集操作 | 
|
| reduceByKey(func) | 按 key 进行 reduce,让 key 合并 | 
|
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 | |
| count() | 返回 RDD 的元素个数 | |
| first() | 返回 RDD 的第一个元素(类似于 take(1)) | |
| take(n) | 返回一个由数据集的前 n 个元素组成的数组 | |
| saveAsTextFile(path) | 将数据集的元素以 textfile 的形式保存到 HDFS 文件系统或者其他支持的文件系统,对于每个元素,Spark 将会调用 toString 方法,将它装换为文件中的文本 | rdd.saveAsTextFile("/user/jd_ad/ads_platform/outergd/0124/demo2.csv") |
| foreach(func) | 在数据集的每一个元素上,运行函数 func 进行更新。 | |
| takeSample | 抽样返回一个 dateset 中的 num 个元素 | var rdd = sc.parallelize(1 to 10)``rdd.takeSample(false,10) |
Control
Spark 可以将 RDD 持久化到内存或磁盘文件中,把 RDD 持久化到内存中可以极大地提高迭代计算以及各计算模型之间的数据共享,一般情况下执行节点 60% 用于缓存数据,剩下 40% 用于运行任务。spark 使用 persist 和 cache 操作进行持久化,其中 cache 是 persist 的特例。、
- cache 和 persist 都是用于将一个 RDD 进行缓存,这样在之后使用的过程中就不需要重新计算,可以大大节省程序运行时间。
- cache 和 persist 的区别:cache 只有一个默认的缓存级别
MEMORY_ONLY,而 persist 可以根据情况设置其它的缓存级别。 - checkpoint 接口是将 RDD 持久化到 HDFS 中,与 persist 的区别是 checkpoint 会切断此 RDD 之前的依赖关系,而 persist 会保留依赖关系。
RDD 持久化级别
| 持久化级别 | 含义解释 |
|---|---|
| MEMORY_ONLY | 使用未序列化的 Java 对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个 RDD 执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用 cache()方法时,实际就是使用的这种持久化策略。 |
| DISK_ONLY | 使用未序列化的 Java 对象格式,将数据全部写入磁盘文件中。 |
| MEMORY_ONLY_SER | 基本含义同 MEMORY_ONLY。唯一的区别是,会将 RDD 中的数据进行序列化,RDD 的每个 partition 会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁 GC。 |
| MEMORY_AND_DISK | 使用未序列化的 Java 对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个 RDD 执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_AND_DISK_SER | 基本含义同 MEMORY_AND_DISK。唯一的区别是,会将 RDD 中的数据进行序列化,RDD 的每个 partition 会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁 GC。 |
Spark 核心原理
消息通信原理
作业执行原理
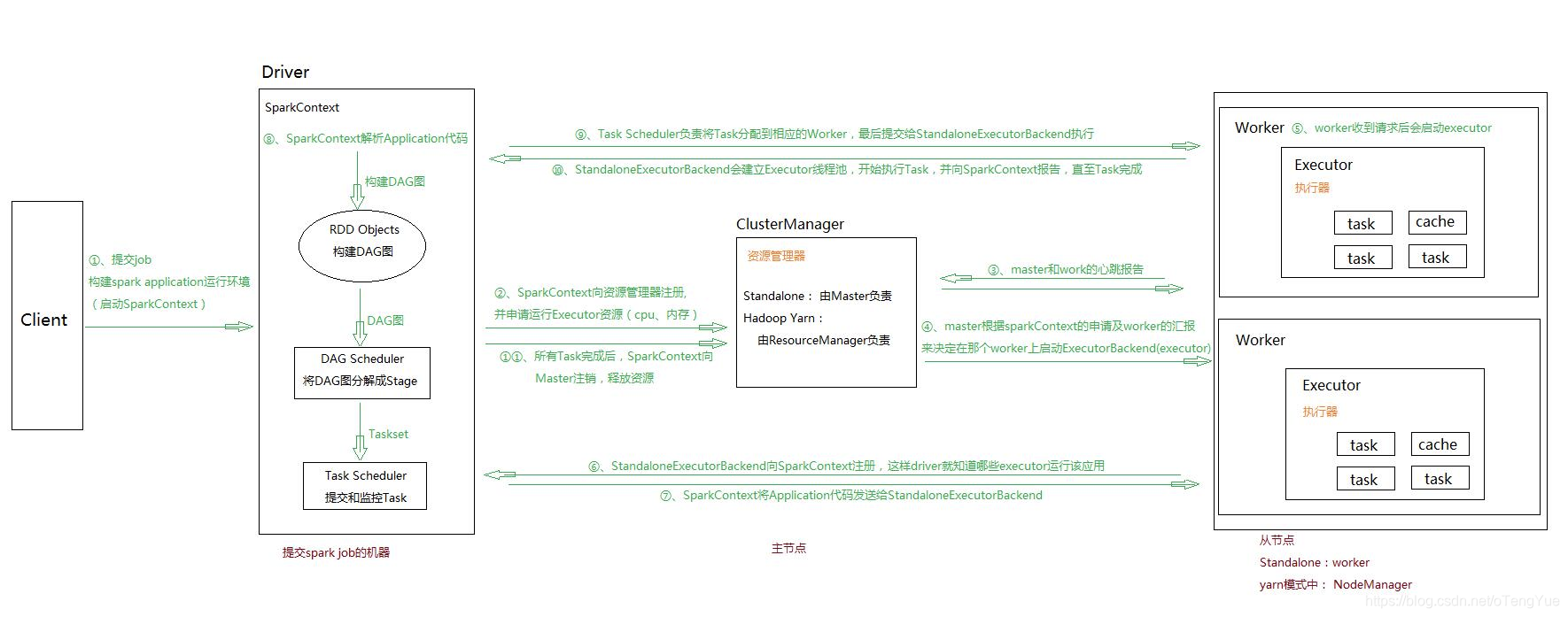
- 通过 SparkSubmit 提交 job 后,Client 就开始构建 spark context,即 application 的运行环境(使用本地的 Client 类的 main 函数来创建 spark context 并初始化它)
- yarn client 提交任务,Driver 在客户端本地运行;yarn cluster 提交任务的时候,Driver 是运行在集群上
- SparkContext 连接到 ClusterManager(Master),向资源管理器注册并申请运行 Executor 的资源(内核和内存)
- Master 根据 SparkContext 提出的申请,根据 worker 的心跳报告,来决定到底在那个 worker 上启动 executor
- Worker 节点收到请求后会启动 executor
- executor 向 SparkContext 注册,这样 driver 就知道哪些 executor 运行该应用
- SparkContext 将 Application 代码发送给 executor(如果是 standalone 模式就是 StandaloneExecutorBackend)
- 同时 SparkContext 解析 Application 代码,构建 DAG 图,提交给 DAGScheduler 进行分解成 stage,stage 被发送到 TaskScheduler。
- TaskScheduler 负责将 Task 分配到相应的 worker 上,最后提交给 executor 执行
- executor 会建立 Executor 线程池,开始执行 Task,并向 SparkContext 汇报,直到所有的 task 执行完成
- 所有 Task 完成后,SparkContext 向 Master 注销
调度算法
RDD在 Spark 架构中的运行过程:
DriverProgram即用户提交的程序定义并创建了SparkContext的实例- SparkContext 会根据 RDD 对象构建 DAG 图,然后将 job 提交(runJob)给 DAGScheduler
DAGScheduler对作业的 DAG 图 进行切分成不同的 stage- 每个 stage 都是任务的集合(taskset) 并以 taskset 为单位提交(submitTasks)给 TaskScheduler。
TaskScheduler通过TaskSetManager管理 task 并通过集群中的Cluster Manager把 task 发给集群中 Worker 的 Executor,- 期间如果某个 task 失败, TaskScheduler 会重试
- TaskScheduler 发现某个 task 一直未运行完成,有可能在不同机器启动一个推测执行任务(与原任务一样),哪个 task 先运行完就用哪个 task 的结果
- 无论 task 运行成功或者失败,TaskScheduler 都会向 DAGScheduler 汇报当前状态
- 如果某个 stage 运行失败,TaskScheduler 会通知 DAGScheduler 可能会重新提交任务
- Worker 接收到的是 task,执行 task 的是进程中的线程
- 一个进程中可以有多个线程工作进而可以处理多个数据分片,执行任务 task、读取或存储数据

容错和 HA
监控管理
Spark 存储原理
存储分析
Shuffle 分析
序列化和压缩
共享变量
Spark 运行架构
Spark 支持多种部署方案(Standalone、Yarn、Mesos、Kubernetes 等),不同的部署方案核心功能和运行流程基本一样,只是不同组件角色命名不同。

- Driver 进程。
Driver调用SparkContext初始化执行配置和输入数据,然后SparkContext启动DAGScheduler构造执行的 DAG 图,切分成计算任务这样最小的执行单位。 - Driver 向 Cluster Manager 请求计算资源,用于 DAG 的分布式计算。ClusterManager 收到请求以后,将 Driver 的主机地址等信息通知给集群的所有计算节点 Worker。
- Worker 收到信息后,根据 Driver 的主机地址,向 Driver 通信并注册,然后根据自己的空闲资源向 Driver 通报可以领用的任务数。Driver 根据 DAG 图向注册的 Worker 分配任务。
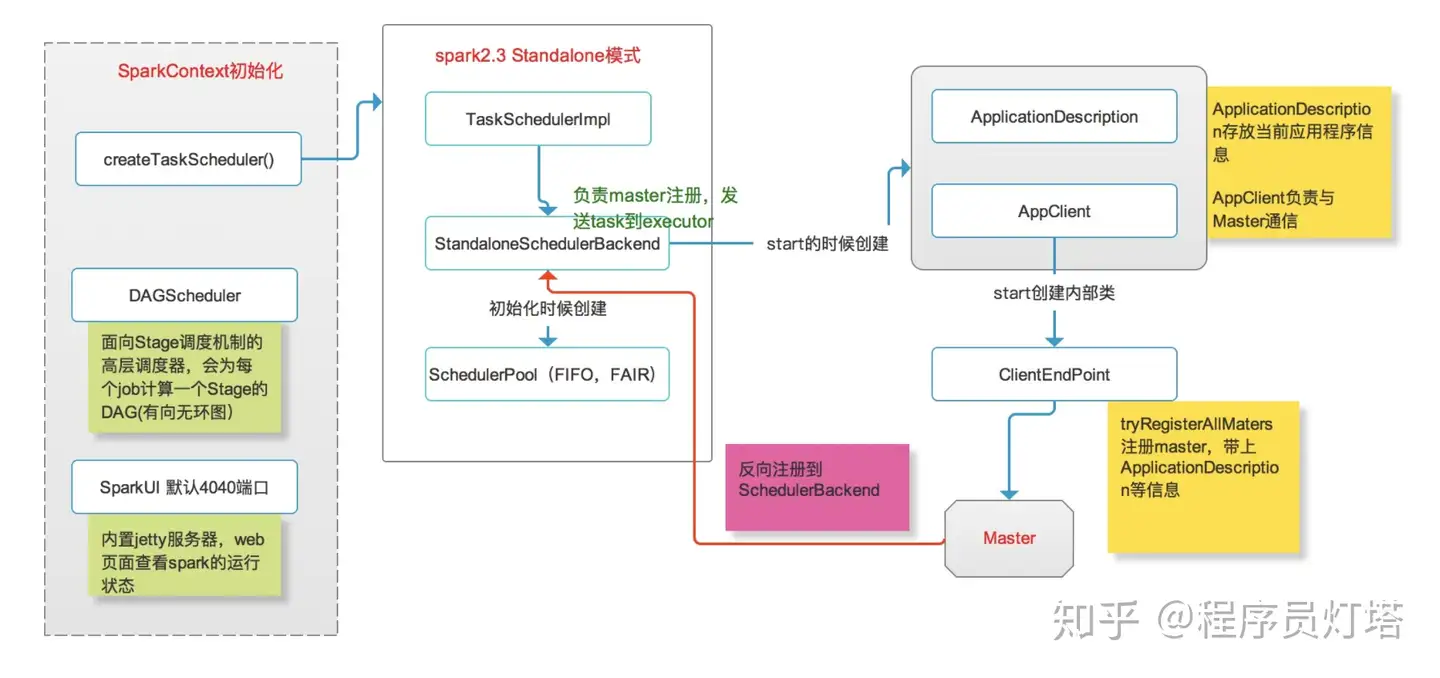
Spark Driver 将用户的代码转换成集群中真正运行的 Job,包括以下组成部分:

- SparkContext
- SparkContext 代表 Application 与 Cluster 的一个 connection,每个 SparkApplication 都需要先创建 SparkContext
- DAGScheduler
- 面向 Stage 调度机制的高层调度器
- 将 Job 划分成一个或者多个 Stage,并把 Stage 分成一个或者多个 Task
- 当 DAGScheduler 完成 Task 的创建后,就会把 Task 按 TaskSet 的方式交给 TaskScheduler
- TaskScheduler
- SchedulerBackend
- BlockManager
调度流程
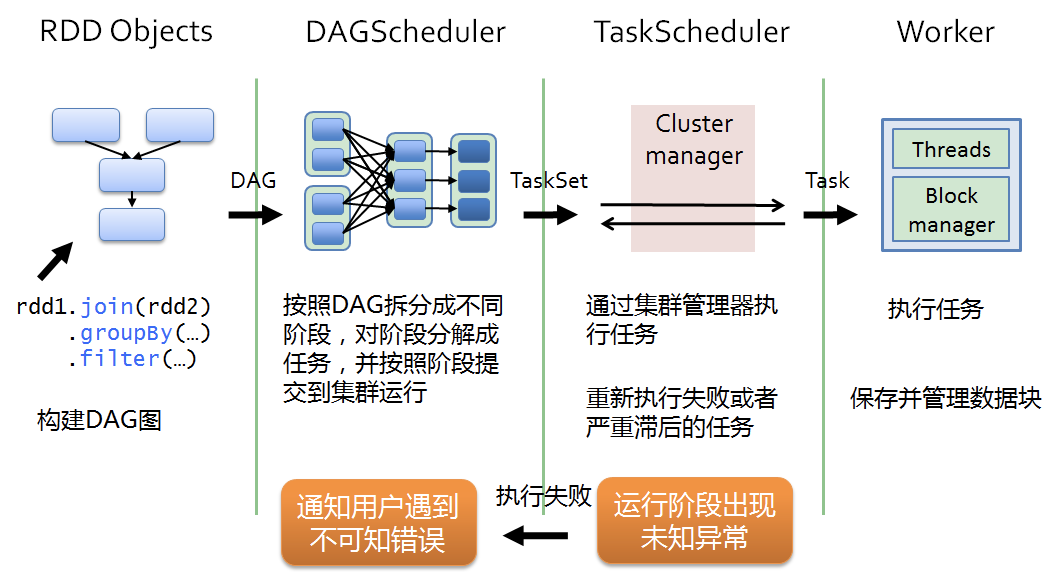
- DriverProgram 即用户提交的程序定义并创建了 SparkContext 的实例,SparkContext 会根据 RDD 对象构建 DAG 图,然后将作业(job)提交(runJob)给 DAGScheduler。
- DAGScheduler 对作业的 DAG 图进行切分成不同的 stage[stage 是根据 shuffle 为单位进行划分],每个 stage 都是任务的集合(taskset)并以 taskset 为单位提交(submitTasks)给 TaskScheduler。
- TaskScheduler 通过 TaskSetManager 管理任务(task)并通过集群中的资源管理器(Cluster Manager)[standalone 模式下是 Master,yarn 模式下是 ResourceManager]把任务(task)发给集群中的 Worker 的 Executor, 期间如果某个任务(task)失败, TaskScheduler 会重试,TaskScheduler 发现某个任务(task)一直未运行完成,有可能在不同机器启动一个推测执行任务(与原任务一样),哪个任务(task)先运行完就用哪个任务(task)的结果。无论任务(task)运行成功或者失败,TaskScheduler 都会向 DAGScheduler 汇报当前状态,如果某个 stage 运行失败,TaskScheduler 会通知 DAGScheduler 可能会重新提交任务。
- Worker 接收到的是任务(task),执行任务(task)的是进程中的线程,一个进程中可以有多个线程工作进而可以处理多个数据分片,执行任务(task)、读取或存储数据。
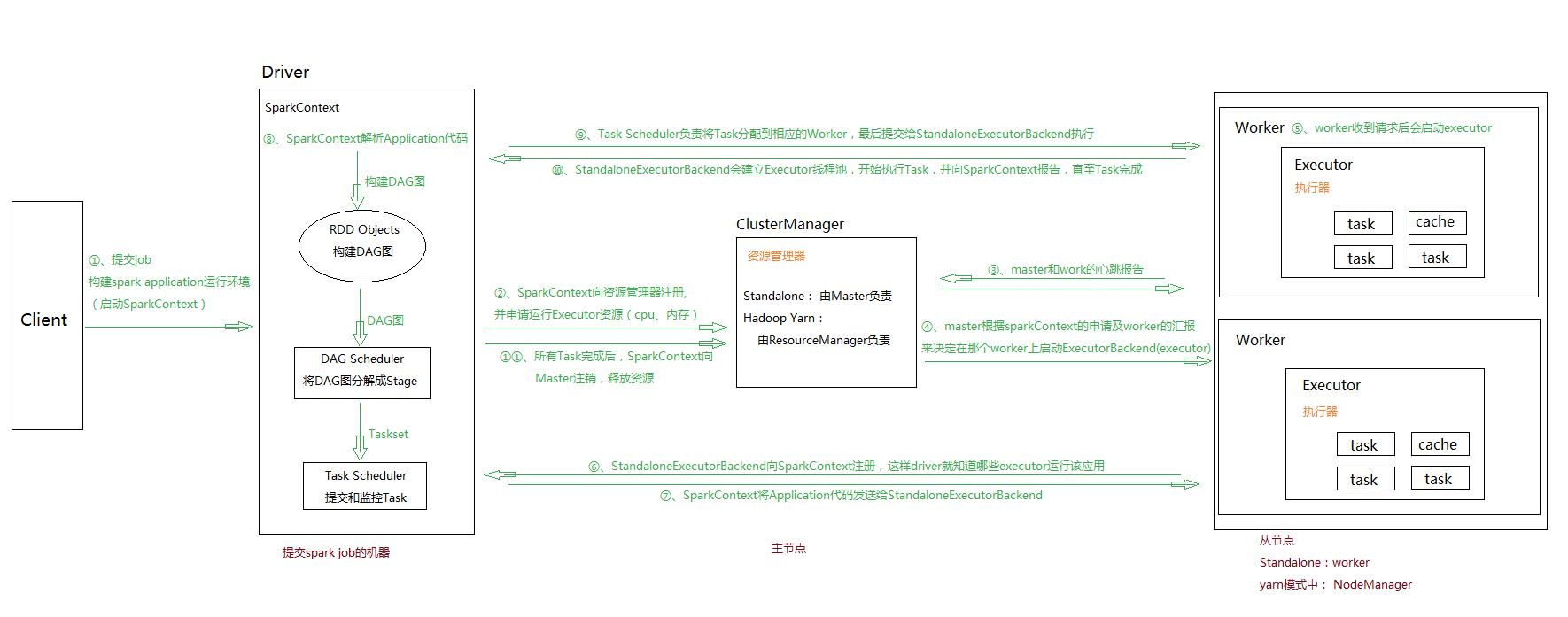
- 通过 SparkSubmit 提交 job 后,Client 就开始构建 spark context,即 application 的运行环境(使用本地的 Client 类的 main 函数来创建 spark context 并初始化它)
- yarn client 提交任务,Driver 在客户端本地运行;yarn cluster 提交任务的时候,Driver 是运行在集群上
- SparkContext 连接到 ClusterManager(Master),向资源管理器注册并申请运行 Executor 的资源(内核和内存)
- Master 根据 SparkContext 提出的申请,根据 worker 的心跳报告,来决定到底在那个 worker 上启动 executor
- Worker 节点收到请求后会启动 executor
- executor 向 SparkContext 注册,这样 driver 就知道哪些 executor 运行该应用
- SparkContext 将 Application 代码发送给 executor(如果是 standalone 模式就是 StandaloneExecutorBackend)
- 同时 SparkContext 解析 Application 代码,构建 DAG 图,提交给 DAGScheduler 进行分解成 stage,stage 被发送到 TaskScheduler。
- TaskScheduler 负责将 Task 分配到相应的 worker 上,最后提交给 executor 执行
- executor 会建立 Executor 线程池,开始执行 Task,并向 SparkContext 汇报,直到所有的 task 执行完成
- 所有 Task 完成后,SparkContext 向 Master 注销
Standalone
独立运行模式是 Spark 自身实现的资源调度框架,由客户端、Master 节点和多个 Worker 节点组成。其中 SparkContext 既可以运行在 Master 节点上,也可以运行在客户端。
Worker 节点可以通过 ExecutorRunner 运行在当前节点上的 CoarseGrainedExecutorBackend 进程,每个 Worker 节点上存在一个或多个 CoarseGrainedExecutorBackend 进程,每个进程包含一个 Executor 对象。 该对象持有一个线程池,每个线程可以执行一个 task。
独立模式运行流程图所示:
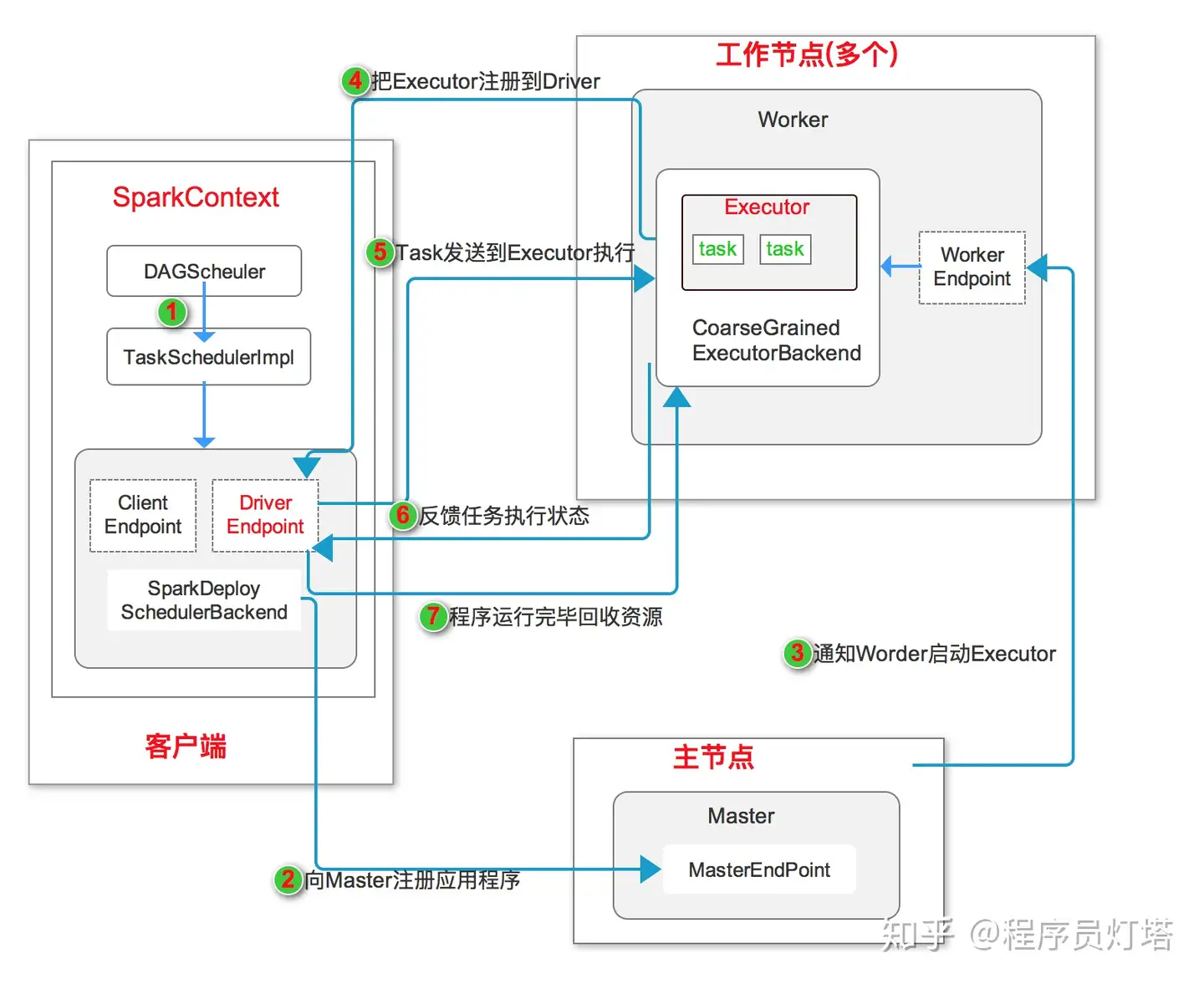
- 启动应用程序,在 SparkContext 启动过程中,先初始化 DAGScheduler 和 TaskSchedulerImpl 两个调度器, 同时初始化 SparkDeploySchedulerBackend,并在其内部启动 DriverEndpoint 和 ClientEndpoint
- ClientEndpoint 向 Master 注册应用程序。Master 收到注册消息后把应用放到待运行应用列表,使用自己的资源调度算法分配 Worker 资源给应用程序。
- 应用程序获得 Worker 时,Master 会通知 Worker 中的 WorkerEndpoint 创建 CoarseGrainedExecutorBackend 进程,在该进程中创建执行容器 Executor。
- Executor 创建完毕后发送消息到 Master 和 DriverEndpoint。在 SparkContext 创建成功后, 等待 Driver 端发过来的任务。
- SparkContext 分配任务给 CoarseGrainedExecutorBackend 执行,在 Executor 上按照一定调度执行任务(这些任务就是自己写的代码)
- CoarseGrainedExecutorBackend 在处理任务的过程中把任务状态发送给 SparkContext,SparkContext 根据任务不同的结果进行处理。如果任务集处理完毕后,则继续发送其他任务集。
- 应用程序运行完成后,SparkContext 会进行资源回收。
Yarn
Yarn-Cluster 工作流程如上图所示:
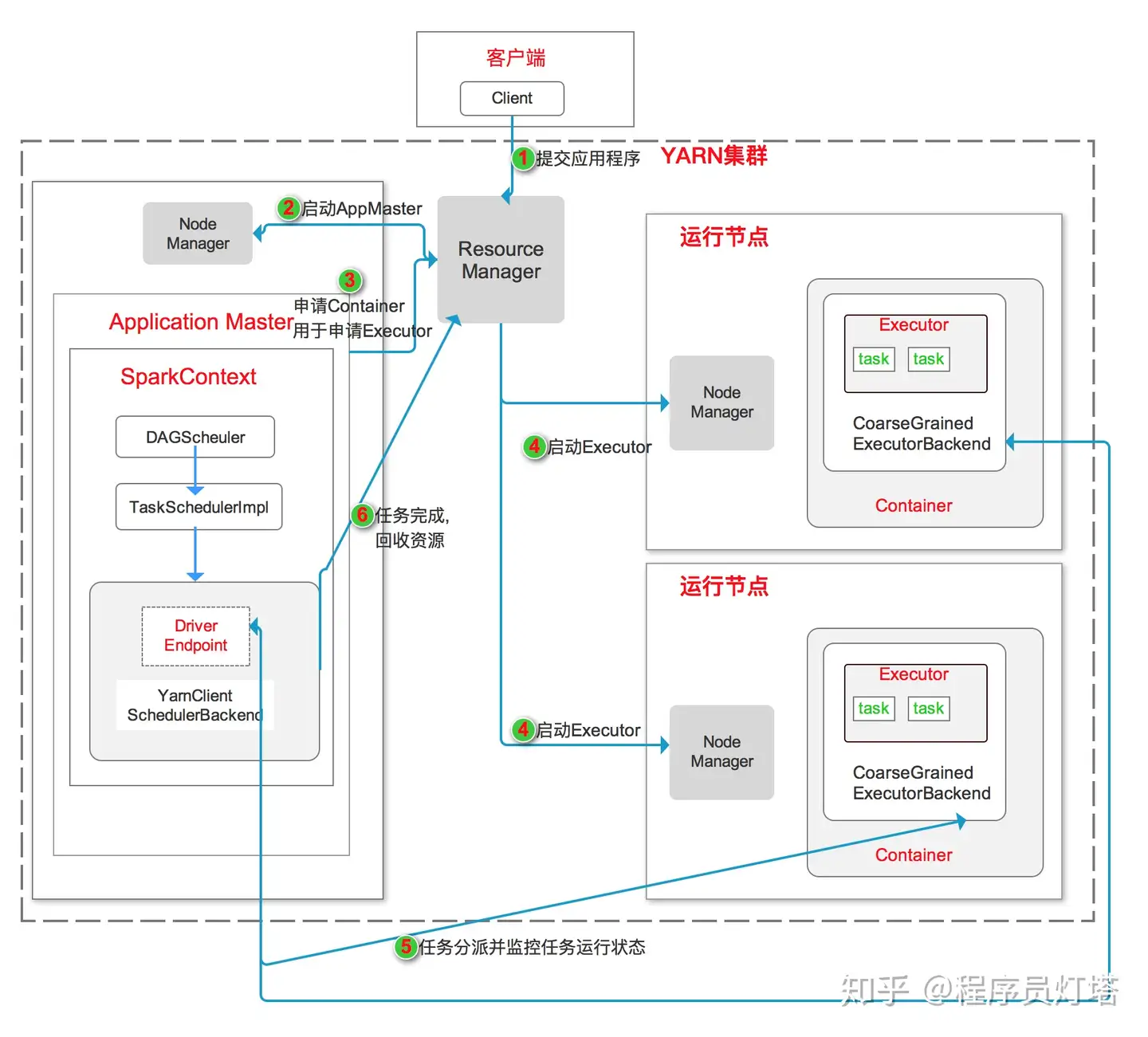
- 客户端启动 Client 项 YARN 集群提交应用程序。
- ResourceManager 收到请求后,再集群中选一个 NodeManger,为此应用申请一个 Container, 并在其中启动 Application Master。在 Application Master 中进行 SparkContext 的初始化操作
- Application Master 向 ResourceManager 注册,为各个任务申请资源,并监控任务的运行状态直到结束
- Application Master 申请到资源后,与 NodeManager 通信,在 Container 中启动 CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend 向客户端中的 SparkContext 注册并申请 taskset。
- CoarseGrainedExecutorBackend 运行任务并向 Application Master 汇报运行的状态和进度.
- 应用程序运行完成后,SparkContext 向 ResourceManager 申请注销并关闭。
Kubernetes

Reference
- https://github.com/japila-books/apache-spark-internals
- https://datawhalechina.github.io/juicy-bigdata/#/ch7%20Spark
- https://datastrophic.io/core-concepts-architecture-and-internals-of-apache-spark/
- https://zhuanlan.zhihu.com/p/69889714
- https://www.cnblogs.com/skaarl/p/13960639.html
- https://mallikarjuna_g.gitbooks.io/spark/content/spark-submit.html