PyTorch Native Tensor Parallel
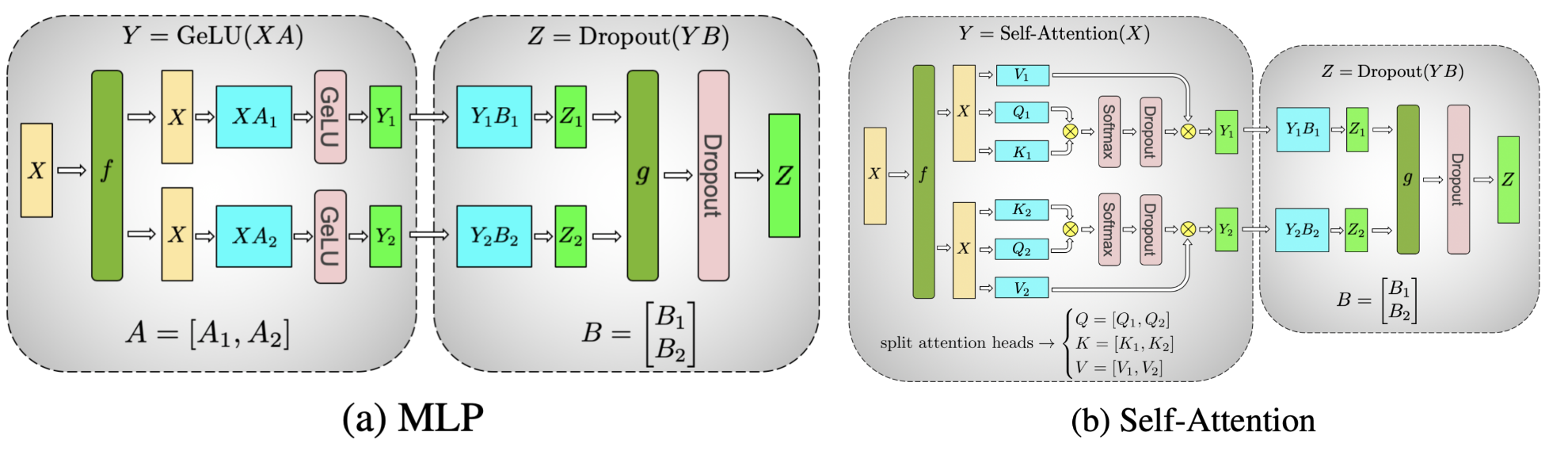
现在 MLP 一般采用 swiglu 风格的 MLP,如下所示:

那么对应的 torch native 的切分为:
|
|
|
|
|
|
实际 apply 切分
|
|
Linked Mentions
-
No backlinks found.