SwiGLU
Google 的 PaLM 和 Meta 的 LLaMA 都使用了 SwiGLU 来增强 Transformer 架构中的 FFN 层 的性能。SwiGLU 是 Gated Linear Units(GLU)激活函数的一种变体,由 Noam Shazeer 在论文《GLU Variants Improve Transformer》的论文中提出。本文主要介绍不同激活函数(如 ReLU、GELU 和 Swish)在 FFN 层中的应用。
使用 ReLU 激活的 FFN
Transformer 模型通过 MHA 和 FFN 层交替工作。FFN 层存在于 Transformer 架构的编码器和解码器部分中。例如,下方的编码器块由多头注意力层和一个 FFN 层组成。
FFN 层包括两个线性变换,中间插入一个非线性激活函数。最初的 Transformer 架构采用了 ReLU 激活函数。
$$ FFN(x, W_1, W_2, b_1, b_2) = ReLU(xW_1 + b_1)W_2 + b_2 $$
其中 ReLU 的定义为 $ReLU (x) = max (0, x)$
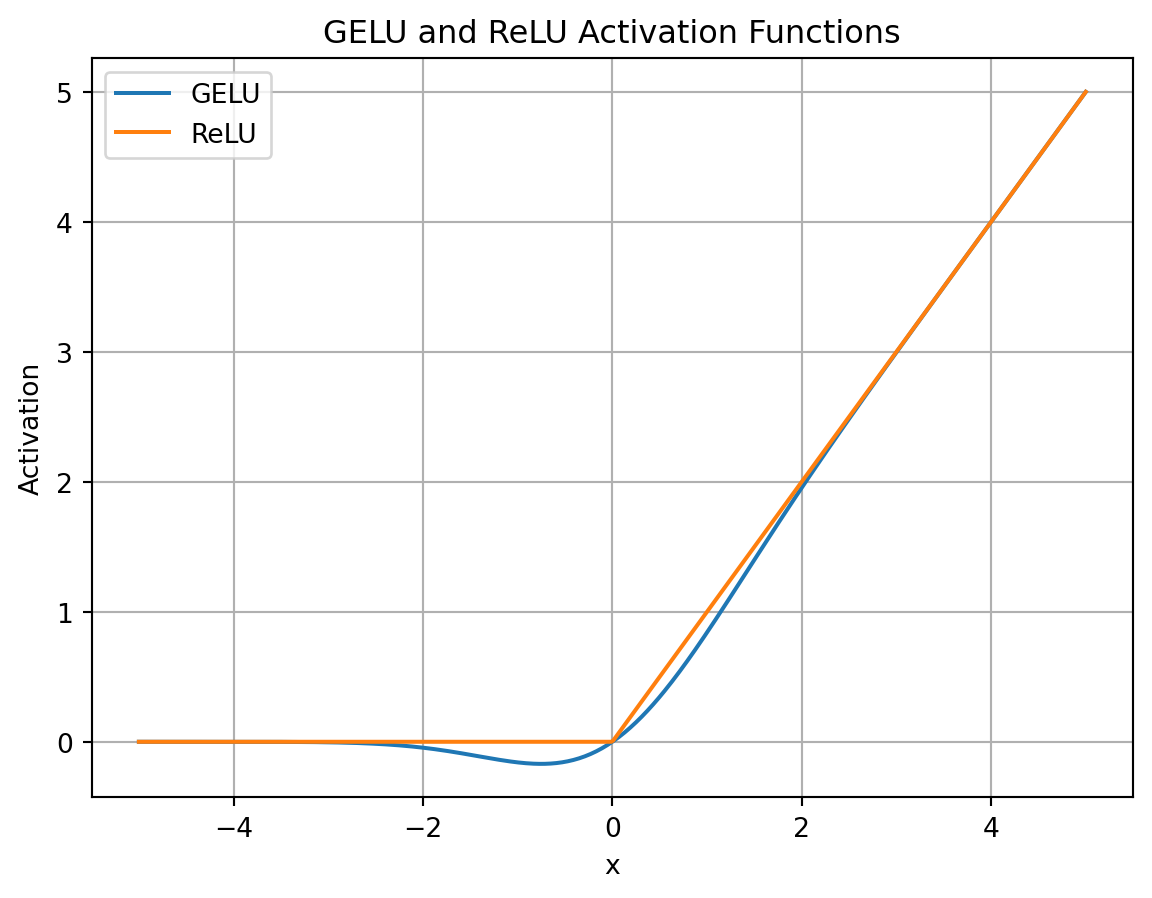
使用 GELU 激活的 FFN
论文《Gaussian Error Linear Units(GELUs)》提出了GELU,这是ReLU的平滑版本。
|
|
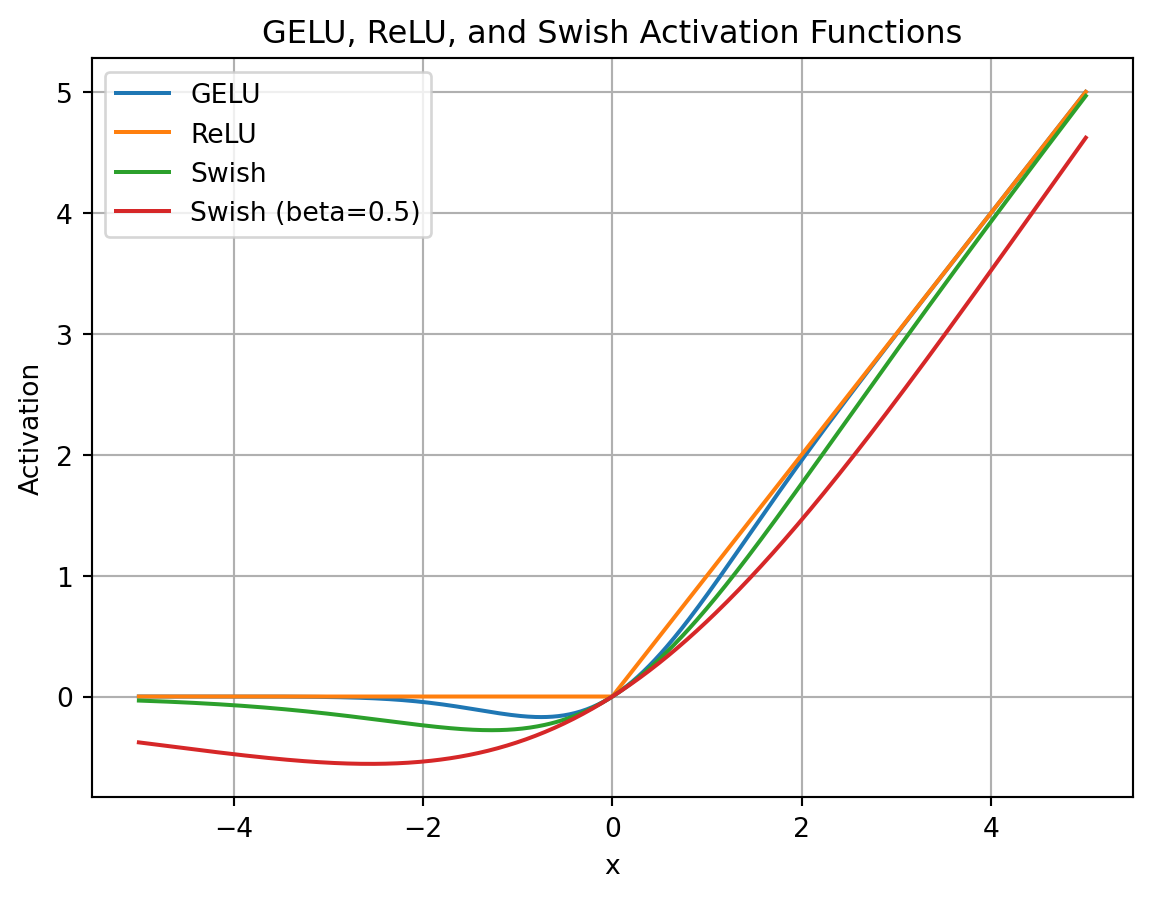
使用 Swish 激活的 FFN
论文《Swish: a Self-Gated Activation Function》提出了 Swish,这也是对带有非零负值梯度的 ReLU 平滑版本。
|
|
GLU 及其变体
GLU(Gated Linear Units)其实不算是一种激活函数,而是一种神经网络层。它是一个线性变换后面接门控机制的结构。其中门控机制是一个 sigmoid 函数用来控制信息能够通过多少。
$$ GLU(w, W, V, b, c) = \sigma(xW+b)\otimes(xV+c) $$
其中 $\sigma$ 为 sigmoid 函数,$\otimes$ 为逐元素乘。通过使用其他的激活函数我们就能够得到 GLU 的各种变体了。
比如说现在 LLM 中常用的 SwiGLU 其实就是采用 Swish 作为激活函数的 GLU 变体 $$ GLU(w, W, V, b, c) = Swish_1(xW+b)\otimes(xV+c) $$ 由于引入了更多的权重矩阵,通常会对隐藏层的大小做一个缩放,从而保证整体的参数量不变。
代码的实现如下
|
|

|
|
参考资料
- https://www.cnblogs.com/rossiXYZ/p/18765884
- GLU 论文链接: https://arxiv.org/pdf/1612.08083.pdf
- SwiGLU 论文链接: https://arxiv.org/pdf/2002.05202.pdf
- PaLM 论文链接: https://arxiv.org/pdf/2204.02311.pdf
- LLaMA论文链接: https://arxiv.org/pdf/2302.13971.pdf
-
No backlinks found.