RL Scaling: 异步采样与流水线并行优化
在 LLM 的强化学习 RL 训练流程中,rollout 阶段存在的长尾分布问题 long-tail skewness,会导致大量 GPU 处于空闲状态,严重制约训练效率。针对这一核心痛点,业界与学界已提出诸多异步 RL 训练优化方案,本文将对这些方案进行系统梳理与总结。
RL 范式
当前 LLM 的强化学习中主要采用 Policy Gradient 的方法,特别是 PPO 和 GRPO 等算法。训练中一般包含以下角色:
- Policy Model:即 actor
- Rollout 时,actor 和环境交互,根据输入的 prompt,生成 response
- 训练时,actor 根据 advantage 优化自身权重,使得累计奖励更大
- Value Model:即 critic,用于估计
value function- 在 GRPO 算法中,value model 被省略,通过 Group 内平均奖励作为 baseline 来计算 advantage
- Reference Model:用于确保 actor 不会过度偏离其初始状态
- 通常从 actor 模型初始化,训练中参数固定
- Reward Model:用于提供
reward signal,引导模型向特定方向优化- 在 RLHF 中,reward model 是通过是对人类标注偏好数据训练得到的模型
- 在 RLVR 中,reward model 是一个可以直接验证的 reward function,而不是一个具体的模型。比如数学任务中,基于规则直接判断模型答案是否正确;代码任务中,通过 sandbox 编译测试执行模型输出的代码判断结果是否正确

在 LLM 的 RL 训练的 workflow 中,每个 iteration 一般分为以下三个 stage:
- Generation Stage:也就是 rollout 阶段,生成 trajectory 作为训练的样本
- 单轮场景下,Actor 模型基于输入 Prompt 自回归生成 Response
- 在 Agent 场景下,Actor 与环境交互生成多轮行动轨迹 trajectory,比如 search 场景和 Search/VisitPage 工具
- 一般通过 vLLM 或者 SGLang 等推理引擎实现 Rollout
- Inference Stage:根据已经生成的样本计算训练优化所需要的监督信号
- Reference Model 计算 KL 散度约束所需的
ref_log_prob - Reward Model(或 Reward Function)打分得到
reward - Critic Model 在 PPO 中输出 value,进而结合 GAE 计算 advantage
- Reference Model 计算 KL 散度约束所需的
- Training Stage:更新模型参数以优化策略
- 参数更新:一般通过 FSDP 或者 Megatron 等训练引擎实现训练
- Actor 模型基于 “奖励信号 + KL 约束” 调整生成策略(最大化累计奖励)
- Critic 模型基于 “价值估计误差” 优化价值预测能力(提升后续监督信号的准确性)
- 参数同步:更新后的 Actor 参数需同步到生成阶段的 Actor 实例中,确保下一轮生成使用最新策略,也就是要将训练引擎的参数同步到推理引擎
- 参数更新:一般通过 FSDP 或者 Megatron 等训练引擎实现训练
整个过程可以用伪代码表示如下:
|
|
长尾问题的本质
现象观测
在 LRM (Large Reasoning Model) 的 RL 训练里,rollout 阶段消耗的训练时间占比通常在 70%–90% 之间123,远超 inference 与 training 阶段之和。其根本原因是 rollout 输出长度服从严重的 长尾分布:
- 长度分布偏斜:在 LMSYS-Chat-1M 等数据集上,不同模型的 P99.9 输出长度往往是中位数的 10 倍以上2;在 reasoning 任务中,最长 trajectory 的长度甚至可以达到中位数的 25–32 倍43。
- batch 内 straggler 主导步时:同步 RL 中训练步必须等待 batch 内最慢的样本完成,因此一个 batch 的 step time 由极少数 straggler 决定。
- GPU 利用率塌陷:随着大部分样本提前完成,剩下的少数长尾样本无法充满 batch,导致解码 batch size 不断收缩,进入 memory-bound 的低效区间,GPU SM 利用率甚至会跌破 20%。

Left: The output length CDF of models in the LMSYS-Chat-1M dataset. The vertical dotted line indicates the P99.9 output length. Right: The RLHF training iteration breakdown on the internal model and datasets under different maximum output lengths.
形成机理
长尾问题不是单一原因造成的,而是 算法语义 与 系统执行模型 共同作用的结果:
- 算法侧:on-policy PPO/GRPO 要求 batch 内所有样本来自同一版本(或差距极小)的 policy,这就要求 generation → inference → training 三阶段必须串行同步,形成天然的 batch barrier。
- 数据侧:reasoning 任务中 prompt 难度差异极大,简单 prompt 几百 token 即可结束,而难题可能需要数万 token 的 CoT;reward signal 的稀疏性进一步驱使模型探索更长的链路。
- 系统侧:传统 colocate 架构下 generation 与 training 时分复用同一组 GPU,长尾导致的 generation 时间膨胀直接转化为 training 资源的等待。
- 解码特性:autoregressive decoding 是 memory-bandwidth-bound 的,需要大 batch 摊薄 KV cache 与权重读取开销;长尾末端的 batch size 极小,算力被严重浪费。
如果将一个 RL step 的总时间记为 $T_{step}$,rollout 时间记为 $T_{rollout}$,则在同步系统中: $$ T_{step} \approx T_{rollout}^{(\max)} + T_{infer} + T_{train} + T_{sync} $$
其中 $T_{rollout}^{(\max)}$ 由 batch 中最长的 trajectory 决定,几乎所有优化的核心都是在围绕这一项做文章。
分类视角
针对长尾问题,最近 3 年业界提出的优化方案可以归纳为 5 个正交方向,多数实际系统是若干方向的组合:
| 维度 | 关键思想 | 代表系统 |
|---|---|---|
| A. Pipeline / Stage Fusion | 通过 sub-task 级解耦,让 generation/inference/training 三阶段在 sample 或 micro-batch 粒度上重叠执行 | RLHFuse, HybridFlow/VeRL, ReaLHF |
| B. Off-policy 异步 | 放松 on-policy 约束,让 rollout 与 train 真正并行执行;用算法手段补偿 staleness | AReaL, Magistral, LlamaRL, StreamRL-Async, AsyncFlow, VeRL fully_async, ROLL Flash, slime |
| C. Partial Rollout / Interruptible Generation | 将长尾 trajectory 切片,跨 step 续接生成,避免单步被长尾阻塞 | Kimi k1.5, APRIL, VeRL partial rollout |
| D. Disaggregation 资源分离 | 将 generation 与 training 物理拆分到不同的 GPU pool,按 workload 特性匹配硬件 | StreamRL, RollMux, RollArc, RLBoost |
| E. 长尾专项调度 / 解码加速 | 不改变同步语义,针对长尾样本本身做调度或解码加速 | RollPacker, DAS, SPEC-RL, TLT |
下文按照 A→E 的顺序,逐一梳理每个方向上的代表性工作。
A. 同步范式下的 Stage Fusion
同步范式严格保留 on-policy 语义,不引入 staleness,优化的空间主要集中在 执行流水编排 上。
A.1 Minibatch Pipelining
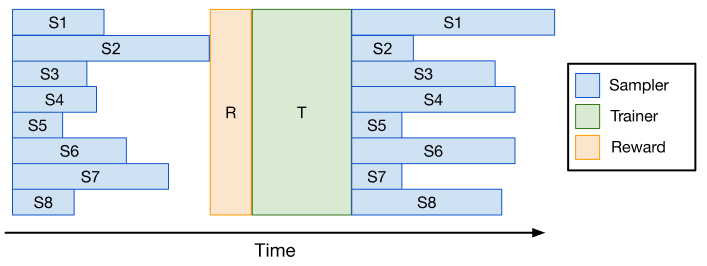
最朴素的优化是在同步 RL 内部对单步做流水化:将整个 batch 拆成若干 minibatch,在 generation 阶段一边解码一边把已完成 minibatch 送入 inference/training,三阶段在时间轴上交叠。
这种做法对 minibatch 内长度差异不敏感,可以缓解一部分 generation/inference 之间的同步等待,但仍然要求每个 minibatch 内的最长样本完成才能流转,因此对 极端长尾(少数样本远长于其余样本)效果有限。该模式被 verl-pipeline、DeepCoder 早期实现等采用,通常带来 1.5×–2× 的加速1。
A.2 RLHFuse: 子任务级 Inter / Intra-Stage Fusion
RLHFuse(北大 + StepFun, 2024)首次提出从 task-level → subtask-level 的视角重构 RLHF 工作流,将每个阶段拆成 sample 或 micro-batch 粒度的子任务进行融合调度2。

Inter-Stage Fusion (生成 ↔ 推理):核心观察是 generation 与 inference 之间的依赖是 样本级 的——单个 sample 一旦解码完成就可以进入 reference / reward / critic 的 forward。RLHFuse 引入 迁移阈值 $R_t$:当 generation 阶段剩余样本数低于 $R_t$ 时(实测 ~20% 时最优),将剩余长尾样本迁移到少数 dedicated 实例上继续解码,腾出的 GPU 立即用于启动 inference 任务,从而让长尾解码与 inference 完全重叠。迁移采用 KV cache 网络传输的方式,依赖 RDMA 完成。
Intra-Stage Fusion (Actor ↔ Critic 训练):训练阶段 PP 1F1B 调度的 bubble 比例为 $(N-1)/(N-1+M)$,N 接近 M 时高达 50%。RLHFuse 借鉴 Chimera 的 bidirectional pipeline,把 Actor 与 Critic 当作天然的双向流水线副本,但因二者异构(不同尺寸 + 不同最优并行策略),引入 模拟退火算法 自动搜索调度,最终能让 33B Critic 的训练时间被 65B Actor 的 1F1B 完全覆盖。
效果:相对 DSChat 提升 2.5–3.7×,相对 ReaLHF 提升 1.4–2.4×,融合本身贡献了 1.2–1.4× 的加速。
A.3 HybridFlow / VeRL & ReaLHF: 灵活并行策略
HybridFlow(字节,2024)以 single-controller + multi-controller hybrid 的编程模型,让 RLHF 数据流图(dataflow)中每个 task 可独立选择 3D 并行策略,配合 hybrid_engine 在同一组 GPU 上实现 generation/training 的资源复用,通过 NCCL all-to-all 高效完成 weight resharding5。
ReaLHF(清华 + 蚂蚁, 2024)则把这一思路推到极致:提出 parameter reallocation,根据每个 task 的最优执行 plan 动态在 GPU 之间重分布参数;用 cost estimator + search 自动找到 execution plan,相对 baseline 实现 2.0–10.6× 加速,在 70B LLaMA-2 + 128 GPU 规模上验证6。
这两类工作并未直接攻击长尾分布,但通过为不同阶段定制最优并行策略,显著降低了非长尾部分的执行时间,从而让长尾在总体占比中暴露得更充分,是后续异步系统的基础设施。
B. 异步范式: 解耦 Generation 与 Training
B.1 One-step Off-Policy
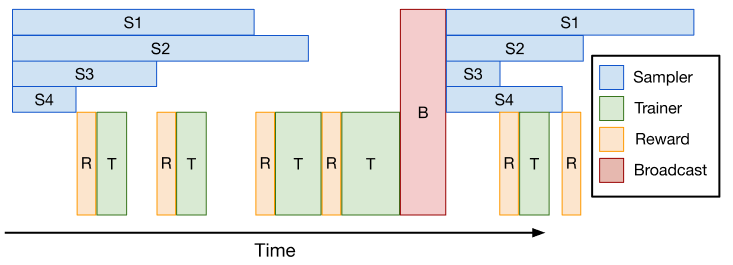
最早的异步实践——把 step ( k ) 的 rollout 与 step ( k-1 ) 的 train 重叠:训练总是使用上一步生成的样本,generation 与 training 的总时间被压缩为两者的最大值。
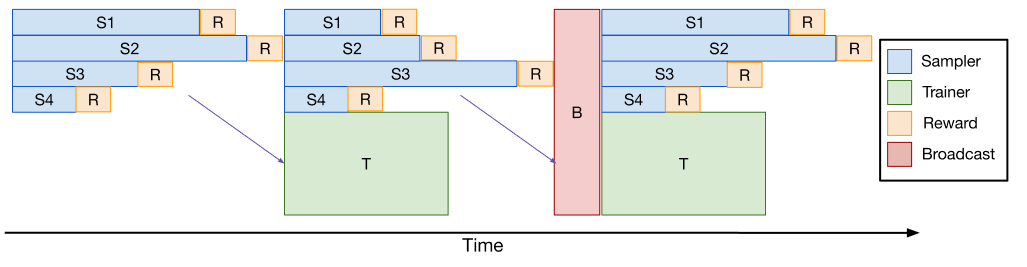
这一模式被 VeRL、DeepCoder、Intellect-2 等多个开源项目采用:
- VeRL one-step-off7:PR #2231 引入显式的 rollout/trainer 资源隔离,通过
rollout.n_gpus配置 generation 专用 GPU;用 NCCL 同步参数,延迟 < 300 ms。在 Qwen2.5-Math-7B 上:- vLLM + FSDP2: 19h18m → 15h34m,提速 23%
- vLLM + Megatron: 18h21m → 13h06m,提速 40%
- DeepCoder (Together AI + Agentica)1:在 DAPO 32B 训练中观测到长尾时间占整步 ~70%,one-step-off 之后端到端提速接近 2×;最终在 32 H100 上 2.5 周训出 LiveCodeBench Pass@1 60.6% 的 14B coder。
One-step off 的局限在于:仍是 batched generation,batch 内长尾依然存在;只能 1 步异步,无法吸收波动较大的长尾分布。
B.2 AReaL: Fully Asynchronous + Staleness-aware PPO
AReaL(清华 IIIS + 蚂蚁 + HKUST,2025.05)是第一个把异步彻底做到 streaming sample-level 的开源系统8。

架构:rollout worker 持续不断地生成 sample 并写入共享 buffer;trainer 每攒够一个 batch 即更新参数;新参数通过 NCCL 推送给所有 rollout worker。每个 batch 内的样本可能来自多个不同版本的 policy,最大 staleness 受参数 $\eta$ 控制。

关键设计:
- Interruptible Rollout:与 Kimi k1.5 的 partial rollout 思路相似,但不设固定长度预算——参数同步时直接打断当前 trajectory,剩余 token 在新参数下继续生成,由 buffer 维护一致的 batch size。
- Dynamic Batching:rollout worker 内部按 token 数而非 sample 数组 batch,吸收长度波动。
- Decoupled / Staleness-Enhanced PPO:将 behavior policy(rollout 时刻)、proximal policy(用于 IS 修正的近似 on-policy 副本)、target policy(当前 trainer)三者解耦,分别承担采样与梯度计算职责,可以容忍 $\eta$ 高达 4 的 staleness 仍保持收敛。

效果:在 1.5B/7B/32B 数学+代码 reasoning 任务上,相对同步系统提速 2.57×–2.77×,512 GPU 近似线性扩展,最终精度持平甚至略升。
B.3 Magistral: NCCL In-Flight Weight Update
Magistral(Mistral, 2025.06)是 Mistral 第一个 reasoning 模型,公开了一套自研的异步 RL infra9。
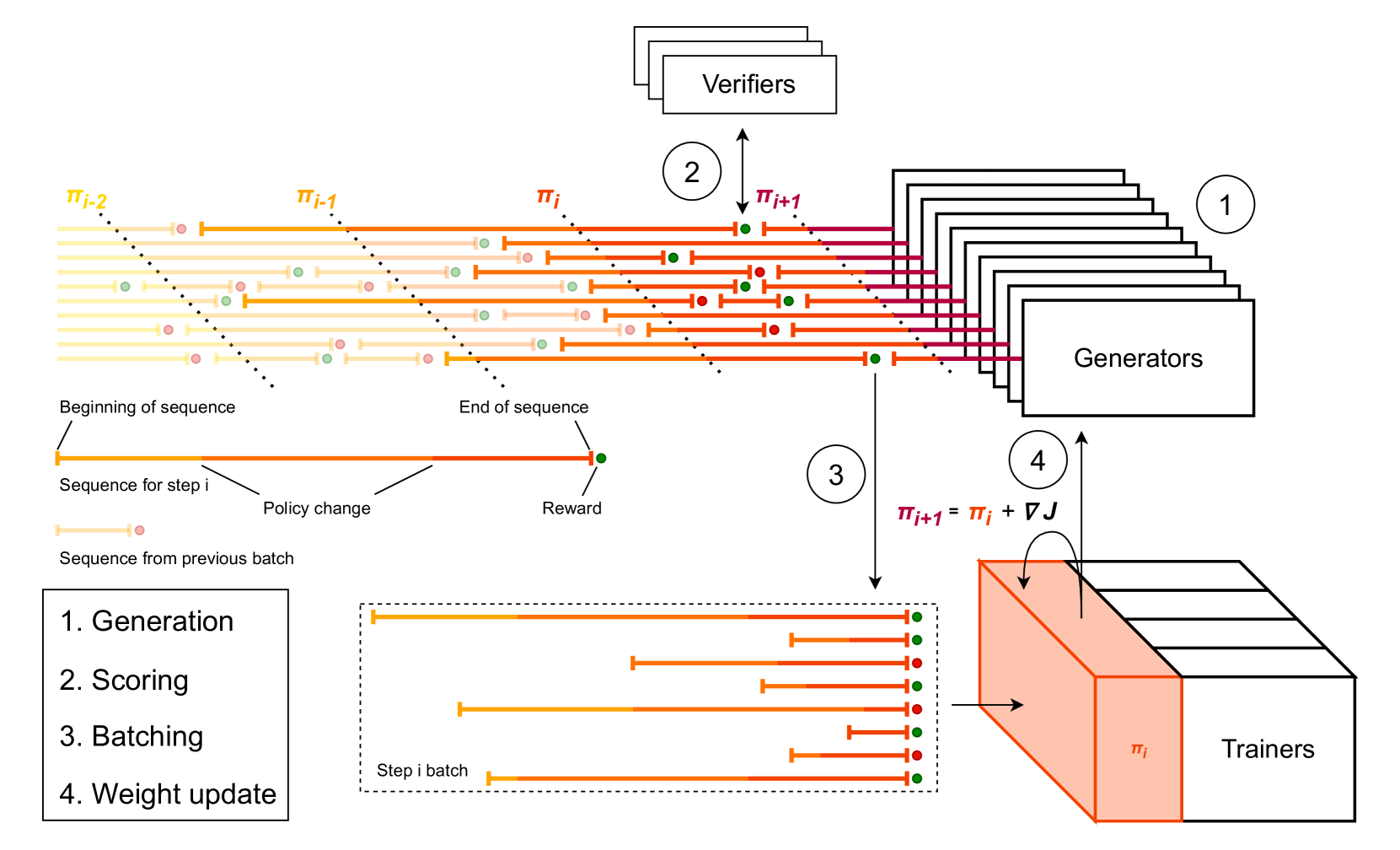
核心机制:generator 与 trainer 完全解耦,generator 在 rollout 过程中通过 NCCL 接收实时权重推送——已经解码到一半的 trajectory 在新参数下继续解码(mid-rollout weight update),从而避免任何同步等待。
算法侧改造:基于 GRPO,移除 KL penalty、放宽上裁剪 $\epsilon_{high}$ 防止 entropy collapse、对 generation group 做 token-length 归一化、minibatch 内做序列级 advantage 归一化,配合上述 in-flight 更新,实现 AIME-24 +50% 的提升(相对 base Mistral Medium 3)。
B.4 LlamaRL: Distributed Asynchronous + DDMA
LlamaRL(Meta GenAI, 2025.05)是 Meta 内部用于训练 8B–405B 参数模型的全分布式异步框架10。
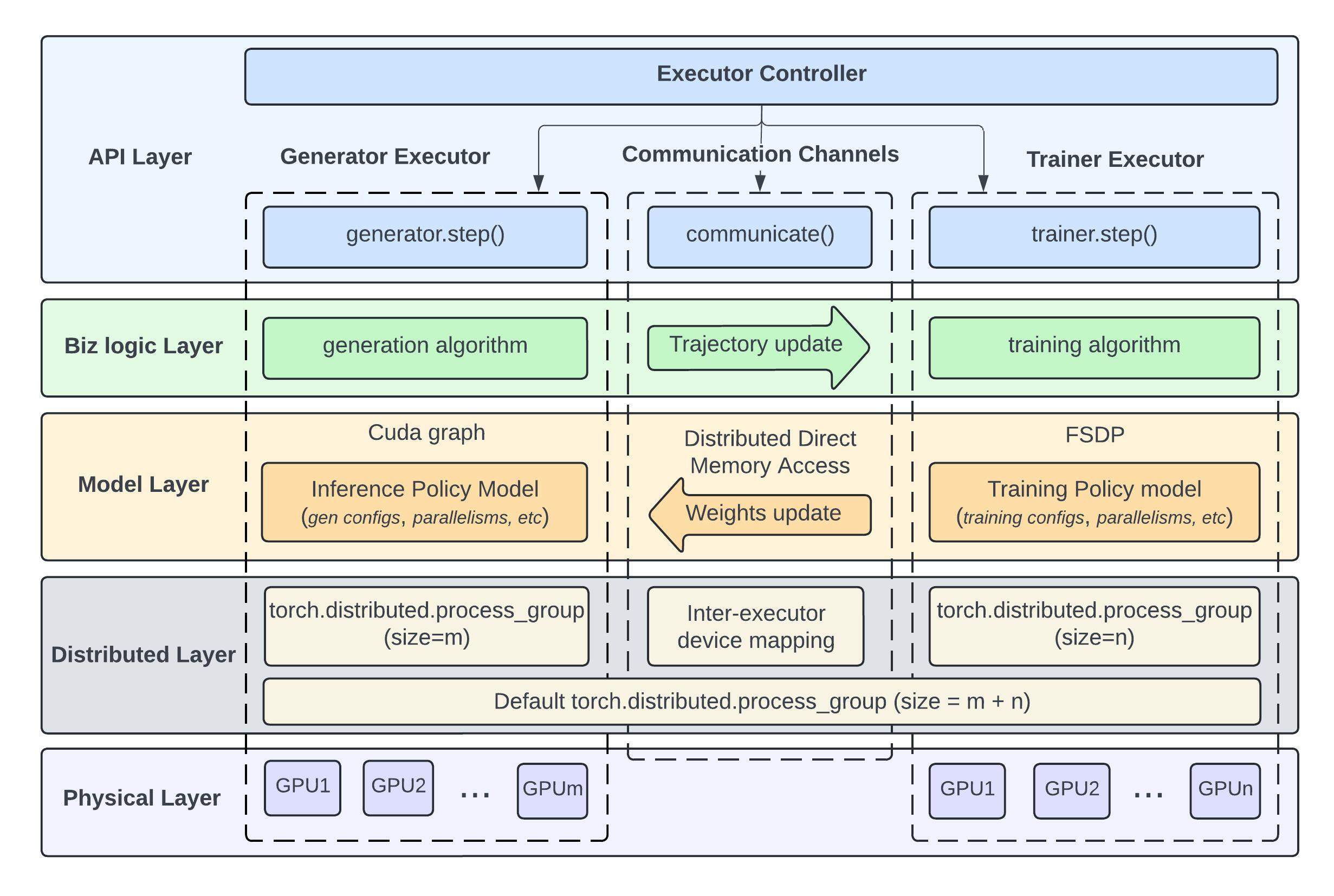
关键技术:
- Single-controller 设计,纯 PyTorch 实现,模块化扩展容易;
- Co-located model offloading:训练态与推理态共享同一组 GPU,通过 offload 复用;
- Distributed Direct Memory Access (DDMA):在多机间用 RDMA 实现 weight 的 zero-copy 同步,避免 NCCL 的 all-reduce 开销。
理论上证明了异步设计带来的 strict speed-up,在 405B 模型上相对 DeepSpeed-Chat-like 系统加速 10.7×。
B.5 StreamRL-Async: Streaming + Disaggregated
StreamRL(Alibaba + 清华, 2025.04)的异步模式同时引入 streaming 与 disaggregation,同时攻击 pipeline bubble 与 skewness bubble11。


Stream Generation Service (SGS):generator 不再等所有样本完成,而是 sample-by-sample 流式推送给 trainer;trainer 一边 dynamic-batch 一边训练,weight transfer 走异步 channel,从关键路径上消除。

Skewness-aware Dispatching:训练一个轻量 output-length ranker model,rollout 之前先按 prompt 难度对长度做 ranking(rank 比绝对长度更稳定可学),然后把预测的 long-tail prompts 分发到 dedicated instance 上以更小的 batch size 加速解码,其它 prompts 则按大 batch 高效执行。Within-instance 用 LPT (Longest-Processing-Time-first) 贪心进一步减少 makespan。

效果:相对 colocated VeRL 提升 2.66× 吞吐;在异构跨机房(H800 训练 + H20 推理)场景下提升 1.33× 性价比。
B.6 AsyncFlow: TransferQueue 抽象
AsyncFlow(华为,2025.07)以 producer-consumer + 分布式队列 的范式重写异步 RL workflow12。
四层架构:Resource (Ray) → Backend (FSDP/DeepSpeed/vLLM/MindSpeed adapter) → Optimization (TransferQueue) → Interface (service-oriented API)。
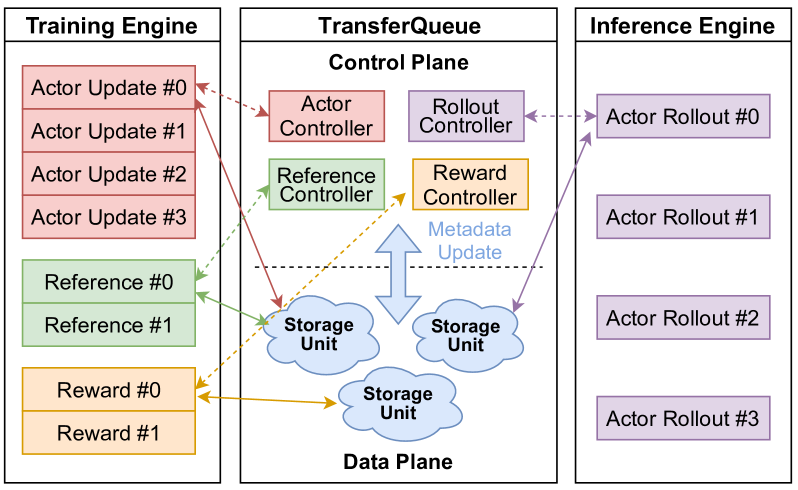
TransferQueue 是核心抽象:所有中间数据(rollout sample、reward、log_prob)都进出这个分布式队列,子任务作为 producer/consumer 异步消费,自动形成 pipeline 并行。相对最先进 baseline 平均吞吐 +1.59×、峰值 +2.03×。
B.7 VeRL fully_async (Meituan)
VeRL fully_async_policy(美团,2025)综合 AReaL / Magistral / StreamRL / AsyncFlow 的设计,在 VeRL 上实现了 多步异步 + streaming + partial rollout 的统一 recipe7。

四个核心组件:Rollouter ⇄ MessageQueue ⇄ Trainer ⇄ ParameterSynchronizer。通过三个关键参数控制行为:
staleness_threshold:允许的 stale 样本比例(0=on-policy;>0 异步;=1 ≈ one-step-off);trigger_parameter_sync_step:trainer 多少次 local update 后触发同步;partial_rollout:参数同步时是否 sleep/resume 保留进行中的 rollout。

在 Qwen2.5-7B + 128 GPU 上,端到端提速 2.35×–2.67×。

B.8 OpenRLHF Async Pipeline
OpenRLHF 基于 Ray + vLLM + DeepSpeed,提供 hybrid engine(同步)与 async pipeline(异步)两套模式,async 路径上支持 dynamic batch、tool-integrated reasoning、partial rollout。相对 DeepSpeed-Chat 优化版获得 3–4× 提速13。
B.9 ROLL / ROLL Flash (Alibaba)
ROLL(阿里,2025)是基于 Ray 的 RL scaling 库,整合 Megatron-Core / SGLang / vLLM。其 Async Training 通过 async_generation_ratio 控制 inference 预生成的批数;2025.10 推出的 ROLL Flash 进一步加入:
- Queue Scheduling:独立任务调度最大化 GPU 利用率;
- Environment-Level Async Rollout:解耦 env 交互延迟;
- Off-policy 算法支持:Decoupled PPO、TOPR、CISPO;
在 RLVR 任务上 2.24×、Agentic 任务上 2.72× 加速;8× GPU 实现 7.6× 等效,近似线性扩展14。
B.10 slime: Megatron + SGLang 异步
slime(清华 + Bilibili,2025)以 train_async.py 为入口,把 Megatron 训练与 SGLang 推理在 sample 粒度上 pipeline。后续在此基础上继续推进 staleness control / partial rollout 等 off-policy 能力,同时也是 APRIL 工作的实验载体。
C. Partial Rollout / Interruptible Generation
C.1 Kimi k1.5: Partial Rollout 起源
Kimi k1.5(Moonshot AI, 2025.01)首次在大规模 RL 中提出 partial rollout:将单步 rollout 设置一个固定 token 预算,未在预算内完成的 trajectory 被 挂起,在下一步用新参数继续生成;通过 KV cache 传递实现状态续接15。
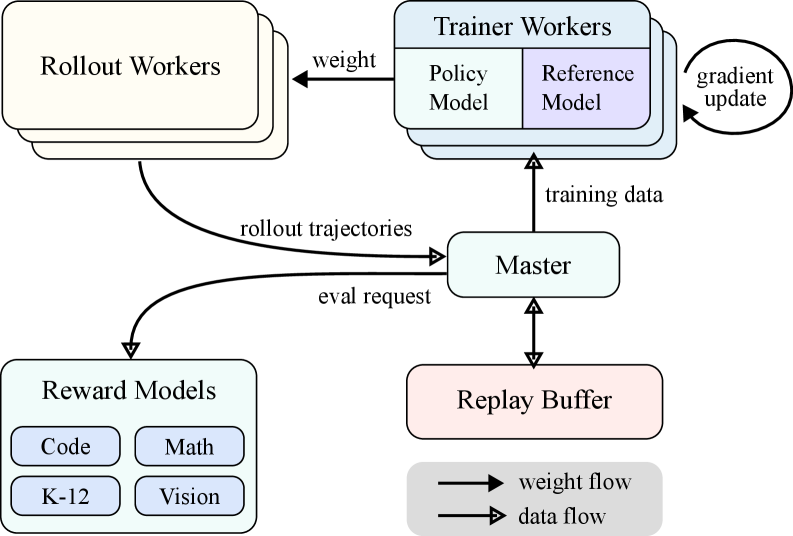
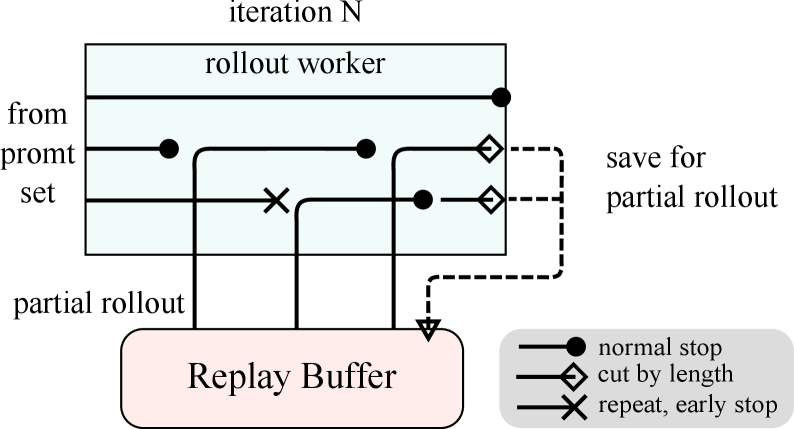
效果:把单步 rollout 时间钉死在预算内,使长尾不再阻塞 batch;同时整条 trajectory 跨多个 policy 版本生成,需要做 importance sampling 修正。
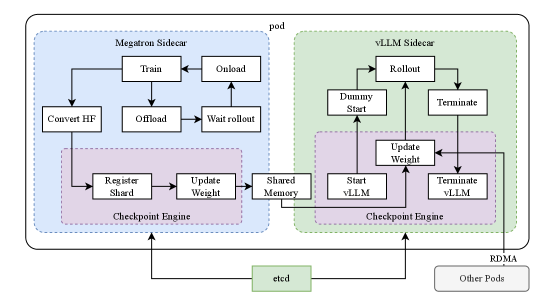
C.2 APRIL: Active Partial Rollouts
APRIL(2025.09)从工程上把 partial rollout 做成 algorithm-agnostic 的优化器3:
Active Over-provisioning + Early Termination:
- 一次 dispatch $N + k$ 个 rollout 请求(over-provision);
- 一旦最快的 $N$ 个完成立即终止 batch;
- 剩余的 $k$ 个在途 trajectory 被保存,下一步用新参数续接生成。
效果:在 GRPO / DAPO / GSPO 上平均提升 rollout throughput 22.5%(最高 49.5%),最终精度反而提升 2.1%–12.8%(因为 over-provision 实际带来更丰富的探索);已集成进 slime,同时支持 NVIDIA 与 AMD GPU。
C.3 VeRL Partial Rollout
VeRL PR #2200 把 partial rollout 加入 fully_async recipe:在 trigger sync 时调用 vLLM 的 sleep()/resume() 钩子保留 KV cache,新参数加载完成后续接生成,避免长尾被强制截断重算。
D. 资源分离架构(Disaggregation)
D.1 StreamRL: 跨机房分离
StreamRL 的核心立场是:当模型规模与集群规模继续扩大,colocate 必然让位于 disaggregation。理由是 generation 是 memory-bandwidth-bound(适合 H20/L40S),training 是 compute-bound(适合 H100/H800),二者 workload 完全错配;分离架构同时支持跨机房部署(generation/training 之间通信量极小,仅为 rollout sample + 点对点 weight 推送)。
D.2 RollMux: Phase-Level Multiplexing
RollMux(2025.12)观察到分离架构下 strict on-policy 同步会让两个 cluster 反复 idle,提出 co-execution group 抽象将 cluster 划分为多个 locality domain,配合 warm-start context switching 让各阶段紧凑切换。在 328 H20 + 328 H800 上相对 baseline disaggregation 提升 1.84× 性价比16。
D.3 RollArc: 异构 Agentic RL
RollArc(2025.12)针对 agentic RL 中 prefill/decoding/env-simulation 多种异构负载混杂的场景,使用 hardware-affinity workload mapping、trajectory 级别 fine-grained async、把 reward model 等 stateless 组件 offload 到 serverless 上,端到端提速 1.35–2.05×。
D.4 RLBoost: Preemptible GPU 混合
RLBoost(2025.10)提出在 reserved GPU 之外,引入 preemptible(竞价/spot)GPU 作为 rollout 弹性资源,配合 adaptive rollout offload + pull-based weight transfer + token-level response migration,吞吐提升 1.51–1.97×、性价比提升 28–49%。
E. 长尾专项调度与解码加速
这一类工作不改变 generation/train 的同步语义,而是直接攻击 长尾样本本身——要么把它们重新调度到对的位置,要么通过 speculative decoding 直接缩短解码时间。
E.1 RollPacker: Tail Batching
RollPacker(2025.09)针对同步RL post-training 提出 tail batching4:
- Speculative Short Round:大部分 step 设置较小的 token 预算,对预计产生长响应的 prompt 直接 abort;
- Dedicated Long Round:把所有 abort 的 prompt 集中到少数专门的 long round 中以完整长度执行;
- 跨 Stage 联动:rollout 阶段 elastic 并行、reward 阶段 dynamic 资源分配、training 阶段 stream-based。
在 Qwen2.5 family + 128 H800 上相对 VeRL 提速 2.03×–2.56×,相对 RLHFuse 提速 2.24×。
E.2 DAS: Distribution-Aware Speculative Decoding
DAS(Together AI, 2025.11)首次系统地把 speculative decoding 引入 RL rollout 来攻击长尾17:
Adaptive Suffix Tree Drafter:用近期 rollout trajectory 维护一棵 可增量更新的 suffix tree 作为 drafter,prefix-match 后按子树 token 频率打分选择 draft;不需要单独训练 drafter,自动随 policy 演化保持对齐。
Length-aware Scheduling:
- Inter-GPU 平衡:长 trajectory 在多 rank 之间 interleave;
- 早期 speculation:长 trajectory 从 rollout 一开始就启用 speculative decoding(因为 late-stage decoding batch size 极小、memory-bound 严重);
- Intra-GPU 预算分配:根据历史长度统计动态分类 long / medium / short,long 给最多 draft token,short 直接关闭以避免开销。
效果:math RL(DeepSeek-R1-Distill-Qwen-7B)rollout 时间减少 >50%,code RL 减少 ~25%;reward 曲线与 baseline 完全重合,lossless。
E.3 SPEC-RL & TLT
- SPEC-RL18:将历史 trajectory 片段作为 speculative prefix,draft-and-verify 后续生成,rollout 时间减少 2–3×;

- TLT (Taming the Long-Tail)19:在长尾解码进行时,复用空闲的 GPU 在线训练一个 adaptive drafter,端到端提速 1.7×。
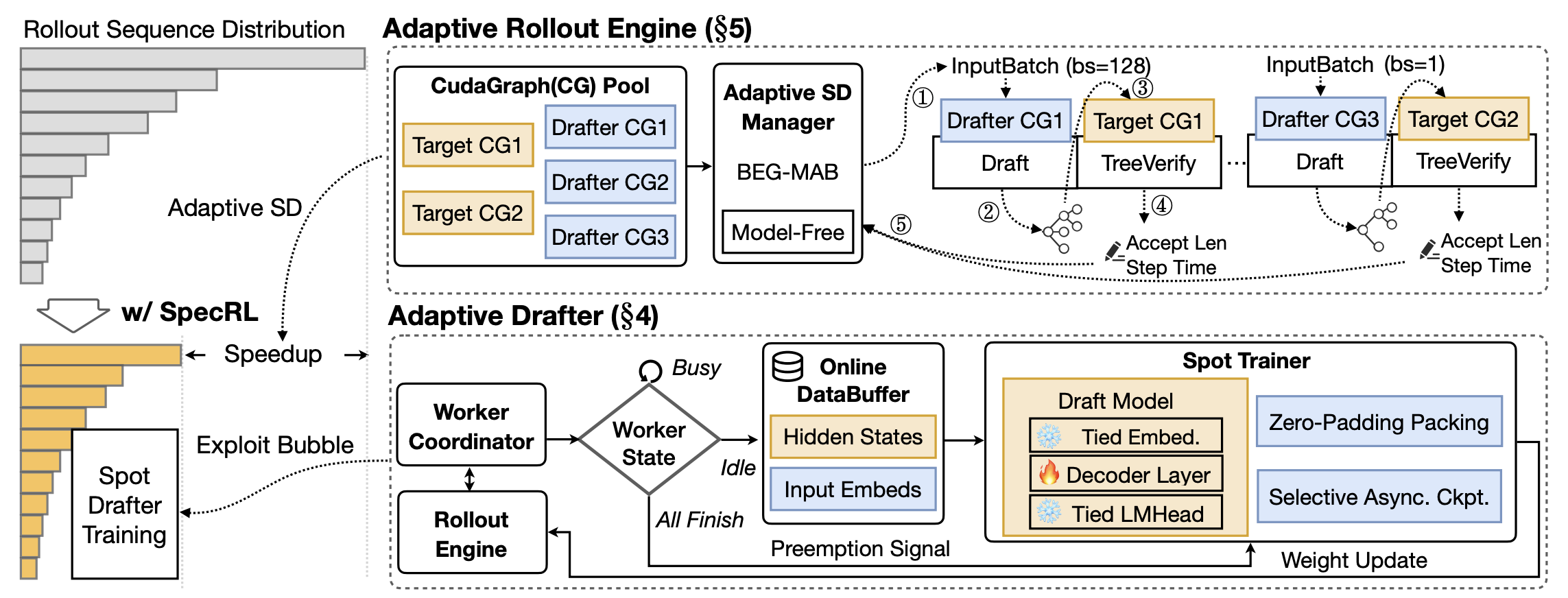
F. 算法-系统协同:Staleness 控制
异步与 partial rollout 引入了 off-policyness,必须在算法侧做修正才能不损失最终精度。
F.1 重要性采样与 Decoupled PPO
设 sample 由 behavior policy $\pi_b$(rollout 时刻参数)产生,trainer 当前为 $\pi_\theta$,标准 PPO 损失中 importance ratio:
$r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_b(a_t|s_t)}$
随着 staleness 增大,$r_t$ 方差爆炸。AReaL 引入 Decoupled PPO:再引入一个 proximal policy $\pi_p$ 作为 IS 的 anchor,把 ratio 拆成两段—— $\pi_p / \pi_b$ 用于校正历史样本、$\pi_\theta / \pi_p$ 用于当前梯度,配合 ratio clipping 与 ESS 监控,将可承受的 staleness 推到 $\eta=4$。
VeRL 的 Rollout Correction 模块进一步抽象出 三层 policy 框架(rollout / proximal / target),同时在 token-level 与 sequence-level 提供 IS + Rejection Sampling 双重过滤,配合 χ² 散度、ESS、reject rate 等监控指标使用。
F.2 关键算法改造
| 算法 | 关键改造 | 用途 |
|---|---|---|
| DAPO20 | Clip-Higher、Dynamic Sampling、Token-Level Loss、Overlong Reward Shaping | 长 CoT、async 容忍 |
| GSPO | Sequence-level IS 修正 | 长序列、async |
| TOPR / CISPO | Truncated Off-Policy Ratio | 高 staleness 训练 |
| Decoupled PPO | 三 policy 解耦 | AReaL / ROLL Flash |
| Magistral GRPO 变种 | 移除 KL、放宽 $\epsilon_{high}$、token-length 归一化 | in-flight weight update |
系统对比与选型
| 系统 | 时间 | 异步层级 | 长尾策略 | Staleness | 典型加速 |
|---|---|---|---|---|---|
| HybridFlow / VeRL hybrid | 2024.09 | 同步 | 灵活 3D 并行 | 0 | 1× baseline |
| ReaLHF | 2024.06 | 同步 | Param reallocation | 0 | 2.0–10.6× vs DSChat |
| RLHFuse | 2024.09 | 同步 + sub-task | Inter/Intra fusion | 0 | 3.7× vs DSChat |
| Kimi k1.5 | 2025.01 | 同步 + partial | Partial rollout | 0 (跨步 IS) | 长 CoT 可行 |
| DeepCoder / verl one-step-off | 2025.04 | 1 step 异步 | Pipelined gen+train | 1 step | ~2× |
| StreamRL | 2025.04 | streaming + 分离 | Length ranker + LPT | 0 / 1 | 2.66× vs VeRL |
| AReaL | 2025.05 | fully async | Interruptible + Decoupled PPO | up to 4 | 2.57–2.77× |
| LlamaRL | 2025.05 | fully async | DDMA + offload | flexible | 10.7× vs DSChat |
| Magistral | 2025.06 | fully async | In-flight weight | continuous | AIME +50% |
| AsyncFlow | 2025.07 | fully async | TransferQueue | flexible | 2.03× peak |
| APRIL | 2025.09 | active partial | Over-provision + recycle | 0–1 | +22.5% throughput |
| RollPacker | 2025.09 | 同步 | Tail batching | 0 | 2.03–2.56× |
| ROLL Flash | 2025.10 | fully async | Queue + Decoupled PPO | flexible | 2.24–2.72× |
| DAS | 2025.11 | 同步 | Speculative decoding | 0 | rollout −50% |
| RollMux | 2025.12 | 分离 | Phase multiplexing | 0 | 1.84× cost-eff |
| RollArc | 2025.12 | agentic 分离 | Trajectory-level async | flexible | 1.35–2.05× |
| VeRL fully_async | 2025–2026 | fully async | Streaming + partial + IS | flexible | 2.35–2.67× |
选型建议
- 小规模(< 32 GPU)/ 短上下文 RLHF:HybridFlow/VeRL hybrid 或 RLHFuse 已足够,长尾不严重时同步训练在算法上更稳;
- Reasoning RL(长 CoT, 32B+):优先考虑 partial rollout(Kimi/APRIL 思路)+ 1-step 或多步 off-policy,DAPO/GSPO 等算法配合;
- 超大规模(256+ GPU)/ 复杂 agent:fully async(AReaL / VeRL fully_async / ROLL Flash)+ 分离架构(StreamRL/RollMux)是必然选择,同时引入 Decoupled PPO 控制 staleness;
- 极致性价比 / 跨机房:disaggregated + 异构硬件(StreamRL / RollMux / RollBoost),把 rollout 放到 H20/L40 之类的 inference-friendly 硬件;
- 不愿改算法语义:同步范式下用 RollPacker(重调度)或 DAS(speculative decoding)做长尾专项加速,对训练曲线零侵入。
总结
RL rollout 长尾问题本质上是 batch 级 barrier × 长度极偏分布 的产物。最近 3 年业界沿着 5 条主线展开优化:
- Stage Fusion 把 task 拆为 sub-task,在同步语义下重叠执行;
- Off-policy 异步 直接打破 barrier,用算法侧 IS / Decoupled PPO 补偿 staleness;
- Partial Rollout 把长尾切片跨步续接,避免单步被阻塞;
- Disaggregation 在物理资源上分离 rollout 与 training,按 workload 选型硬件;
- 长尾专项(tail batching / speculative decoding)在不改语义的前提下精确加速 straggler。
未来 1–2 年值得关注的方向:
- 算法-系统协同设计:staleness 容忍度的理论边界、Decoupled PPO 的多种变体;
- agentic RL 的长尾:多轮 + 工具调用让 trajectory 更长更不可预测,需要新的调度与 KV cache 管理;
- 跨机房与异构混合:把 spot GPU、跨数据中心、CPU offload 联合起来逼近极限性价比;
- Speculative + Async 融合:DAS 类工作还基本是同步系统的 add-on,与 streaming 异步组合的潜力尚未完全释放。
-
DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level, https://www.together.ai/blog/deepcoder ↩︎ ↩︎ ↩︎
-
RLHFuse: Efficient RLHF Training for Large Language Models with Inter- and Intra-Stage Fusion, https://arxiv.org/abs/2409.13221 ↩︎ ↩︎ ↩︎
-
APRIL: Active Partial Rollouts in Reinforcement Learning to Tame Long-Tail Generation, https://arxiv.org/abs/2509.18521 ↩︎ ↩︎ ↩︎
-
RollPacker: Mitigating Long-Tail Rollouts for Fast, Synchronous RL Post-Training, https://arxiv.org/abs/2509.21009 ↩︎ ↩︎
-
HybridFlow: A Flexible and Efficient RLHF Framework, https://arxiv.org/abs/2409.19256 ↩︎
-
ReaLHF: Optimized RLHF Training for Large Language Models through Parameter Reallocation, https://arxiv.org/abs/2406.14088 ↩︎
-
VeRL one-step-off & partial rollout, https://github.com/volcengine/verl/pull/2231 ; https://github.com/volcengine/verl/pull/2200 ↩︎ ↩︎
-
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning, https://arxiv.org/abs/2505.24298 ↩︎
-
Magistral, https://arxiv.org/abs/2506.10910 ; https://mistral.ai/static/research/magistral.pdf ↩︎
-
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework for Efficient Large-scale LLM Training, https://arxiv.org/abs/2505.24034 ↩︎
-
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation, https://arxiv.org/abs/2504.15930 ↩︎
-
AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training, https://arxiv.org/abs/2507.01663 ↩︎
-
OpenRLHF: vLLM-based RLHF Best Practice, https://vllm-project.github.io/2025/04/23/openrlhf-vllm.html ↩︎
-
ROLL & ROLL Flash, https://github.com/alibaba/ROLL ; https://github.com/alibaba/ROLL/issues/207 ↩︎
-
Kimi k1.5: Scaling Reinforcement Learning with LLMs, https://arxiv.org/abs/2501.12599 ↩︎
-
RollMux: Phase-Level Multiplexing for Disaggregated RL Post-Training, https://arxiv.org/abs/2512.11306 ↩︎
-
Beat the Long Tail: Distribution-Aware Speculative Decoding for RL Training (DAS), https://arxiv.org/abs/2511.13841 ↩︎
-
SPEC-RL: Accelerating On-Policy Reinforcement Learning via Speculative Rollouts, https://arxiv.org/abs/2509.23232 ↩︎
-
TLT: Taming the Long-Tail with Adaptive Drafter, https://hanlab.mit.edu/projects/tlt ↩︎
-
DAPO: An Open-Source LLM Reinforcement Learning System at Scale, https://seed.bytedance.com/en/public_papers/dapo-an-open-source-llm-reinforcement-learning-system-at-scale ↩︎
-
No backlinks found.