RL Scaling 系统设计:从数学原理出发
在 2024 年经历了以 OpenAI o11 和 DeepSeek R12 为代表 test-time scaling 技术范式转移后,时间进入 2025 年下半年, Agent 成为各大模型厂商的重点发力方向。在这个过程中,强化学习正在发挥越来越多重要的作用,本文作为强化学习系列笔记的开端,从数学原理出发,详细理解其背后的主要思想,进而更好地理解强化学习系统设计与优化。
Notations
以下是本文中涉及到的数学表达式及其含义:
| Symbol | Meaning |
|---|---|
| $s \in S$ | States 状态 |
| $a \in A$ | Actions 动作 |
| $r \in R$ | Rewards 奖励 |
| $s_t, a_t, r_t$ | 在一个 trajectory 中时刻 $t$ 的 State, action, and reward |
| $\gamma$ | Discount factor 折扣因子 |
| $G_t$ | Return 回报 |
| $P(s’\vert s, a)$ | 在状态 $s$ 执行动作 $a$ 之后状态转移到 $s’$ 的概率 |
| $\pi(a \vert s)$ | 策略 policy,如果用 $\theta$ 表示策略的参数,某个具体参数的策略记作 $\pi_{\theta}$ |
| $V(s)$ | 状态 $s$ 所对应的状态价值函数 State-value function |
| $V_\pi(s)$ | 当执行 policy $\pi$ 时对应的 state value function $\pi$ |
| $Q(s,a)$ | 状态 $s$ 和动作 $a$ 所对应的动作 Action-value function |
| $Q_\pi(s,a)$ | 当执行 policy $\pi$ 时对应的 action value function |
| $A(s,a$) | Advantage function 优势函数 |
Basic Concepts
在现实世界中有一大类的问题可以被抽象成序列决策 Sequential Decision Making 问题,其核心特点是 决策的时序依赖性 —— 当前动作不仅影响即时结果,还会改变未来的环境状态,进而影响后续决策的有效性。
Sequential Decision Making

强化学习是一类通过试错学习 Trial-and-Error 优化策略,以解决序列决策问题的机器学习方法,其核心思想是智能体 Agent 在与环境 Environment 的交互 Action 中,通过获得的奖励 Reward 调整行为策略 Policy,最终实现长期累积奖励最大化。
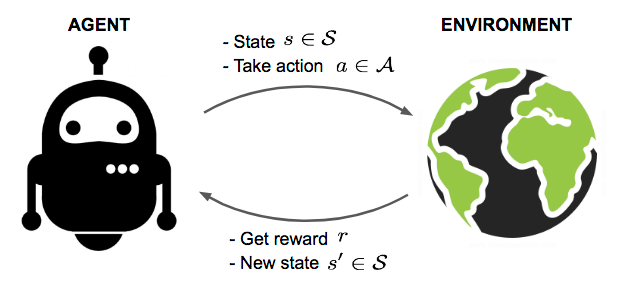
详细介绍下其主要元素:
- Agent:智能体,即执行动作的主体,如机器人、游戏 AI
- Environment:智能体所处的外部场景,如物理世界、游戏地图
- State:描述环境当前状况的变量(如机器人的位置、游戏的得分),上图中在时刻 $t$ 当前对应的状态为 $s_{t}$,通常用集合 $S$ 表示所有可能状态
- Action:Agent 在当前状态 $S$ 下可执行的操作(如机器人的移动方向、游戏的按键),上图中在时刻 $t$ 当前对应可执行的动作为 $a_{t}$,用集合 $A$ 表示所有可能动作
- Reward:环境对智能体动作的即时反馈(如游戏得分增加为正奖励,碰撞惩罚为负奖励),比如 $s_t$ 下采取动作 $a_t$ 之后,对应的奖励为 $r_t$,状态转换为 $s_{t+1}$
Policy
Policy 策略是智能体的行为模型,它规定了在某个状态下应该采取什么动作,通常用 $\pi$ 表示策略。
确定性策略:Agent 在状态 $s_t$ 下,根据策略 $\pi$ 会确定性地执行动作 $a_t$ $$a_t=\pi(s_t)$$ 随机性策略 :Agent 在状态 $s_t$ 下,根据策略 $\pi$ 会概率性地执行动作 $a_t$。也就是说,给定对应的状态和策略,Agent 会符合一定概率分布的从动作空间中选择执行对应的动作 $$a_t \sim \pi(\cdot \mid s_t)$$ 后面的讨论都以随机性策略为前提进行。
Trajectory and State Transition
在强化学习的交互流程中,智能体在状态 $s_t$ 按策略 $\pi$ 选择动作 $a_t$,环境接收动作后转移到新状态 $s_{t+1}$,并返回奖励 $r_t$,形成序列
$$\tau=(s_0,a_0,r_0,s_1,a_1,r_1,…s_{T-1}, a_{T-1}, r_{T-1})$$
我们称 $\tau$ 为轨迹 Trajectory,获取 trajectory 的过程叫做 rollout。
$s_0$ 是初始时智能体所处的状态,只和环境有关。我们假设一个环境中的状态服从分布 $\rho_0$ ,则有 $s_0 \sim \rho_0(.)$
Agent 在某个 $s_t$ 下采取某个动作 $a_t$ 时,它转移到某个状态 $s_{t+1}$ 可以是确定的,也可以是随机的:
- 确定的状态转移: $s_{t+1}=f(s_t,a_t)$ ,表示的含义是当 Agent 在某个 $s_t$ 下采取某个动作 $a_t$ 时,环境的状态确定性地转移到 $s_{t+1}$
- 随机的状态转移: $s_{t+1}∼P(\cdot|s_t,a_t)$
在接下来的讨论中,都假设环境采用的是随机状态转移
Reward
单步奖励:与策略无关,由当前状态 $s_t$、已经执行的行动 $a_t$ 和下一步的状态 $s_{t+1}$ 共同决定。
$$ r_t = R(s_t, a_t, s_{t+1}) $$
T 步累计奖励:为一个 trajectory 中多个单步奖励的累积
$$ R(\tau) = \sum_{t=0}^{t=T-1} r_t $$
折扣累积奖励:考虑到 时间价值(远期利益具有一定不确定性,未来奖励的权重低于即时奖励),通常用折扣累积奖励
$$R(\tau) = \sum_{t=0}^{\infty} \gamma^t r_t$$
其中 $\gamma \in [0,1]$ 为折扣因子,控制未来奖励的权重
- $\gamma=0$ 智能体是
短视的,只关心即时奖励 - $\gamma=1$ 智能体是
有远见的,认为未来奖励和即时奖励几乎同等重要
这里折扣因子 $\gamma$ 除了用于平衡近期和远期的权重,对于 trajectory 是无限的 (即 continuing task, Agent 永远不会结束),可以控制 reward 在有界的范围内。
如果 Agent 进入某个 terminal state 之后结束,这个任务则是 episodic task,比如 RLHF 中大模型碰到 EOS 或者到 max response length 之后停止吐字,对应的 $\gamma=1$ 。
Markov Decision Process
在前面的状态转移中,我们提到,$s_{t+1}∼P(\cdot|s_t,a_t)$,这其实是建立在马尔可夫决策过程 Markov Decision Process, MDP 之上,它是对序列决策问题的数学建模。
具体来说,MDP 满足马尔可夫性:未来状态仅依赖于当前状态和动作,与历史无关,即 $$P(s_{t+1}|s_t,a_t,s_{t-1},a_{t-1},…) = P(s_{t+1}|s_t,a_t)$$一个 MDP 通常由以下五元组定义:$(S,A,P,R,\gamma)$,分别对应于上面的元素:
- $S$:状态空间,所有可能的环境状态 $s$ 的集合
- $A$:动作空间,智能体所有状态下可能采取的动作 $a$ 的集合。
- $P$:状态转移概率,$P(s’|s,a) = P(s_{t+1}=s’ | s_t=s, a_t=a)$,表示在状态 $s$ 执行动作 $a$ 后转移到 $s’$ 的概率
- $R$:奖励函数 $R(s,a,s’)$ 表示在状态 $s$ 执行动作 $a$ 并转移到状态 $s’$ 后,智能体获得的即时奖励
- $\gamma$:折扣因子
根据随机过程的定义,给定一个马尔可夫过程,我们就可以从某个状态出发,根据它的状态转移矩阵生成一个状态序列 trajectory,这个过程就叫做采样 sampling。
在一个马尔可夫决策过程中,从第 $t$ 时刻状态开始,直到终止状态时,所有奖励的衰减之和称为回报 $G_t$(Return),公式如下: $$G_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + … = \sum_{k=0}^{\infty} \gamma^k r_{t+k}$$ 在本文后续所有讨论的场景,都是基于 马尔可夫决策过程 的框架进行讨论。
State-Value Function: V
状态值函数 State-Value Function, $V_{\pi}(s_t)$ : 衡量一个状态的长期价值 ,表示从状态 $s_t$ 开始,始终遵循策略 $\pi$ 所能获得的期望回报。
$$ V_{\pi}(s_t)=\mathbb{E}_{\pi}[G_t∣s_t] $$
注意,这里的 $s_t$ 不是一个随机变量,而是一个确定值。$G_t$ 则是一个随机变量,因为同样从 $s_t$ 出发,因为 $\pi (\cdot|s_t)$ 和环境状态转移 $P (\cdot|s_t, a_t)$ 都是随机的,可能得到很多不同的轨迹,分别对应不同的 $G_t$,因此这里 $V_\pi (s_t)$ 是 $G_t$ 的期望。
Action-Value Function: Q
动作值函数 Action-Value Function, $Q_{\pi}(s_t,a_t)$ : 衡量在某个状态下采取某个动作的长期价值 。表示在状态 $s_t$ 下执行动作 $a_t$,之后一直遵循策略 $\pi$ 所能获得的期望回报 。 $$Q_{\pi}(s_t,a_t)=\mathbb{E}_{\pi}[G_t∣s_t,a_t]$$ 状态价值函数和动作价值函数之间的关系
在使用策略 $\pi$ 中,状态 $s_t$ 的价值等于在该状态下基于策略 $\pi$ 采取所有动作的概率与相应的价值相乘再求和的结果:
$$ V_\pi(s_t) = \sum_{a_t \in A} \pi(a_t|s_t) Q_\pi(s_t, a_t) $$
也就是说,每一个状态 $s_t$ 的状态价值 $V_\pi (s_t)$ 等于这个状态下动作价值 $Q_\pi (s_t, a_t)$ 的期望。
Bellman Equation
根据定义
$$ \begin{align*} V_\pi(s_t) &= \mathbb{E}\pi \left[ G_t \mid s_t \right] \ &= \mathbb{E}\pi \left[ r_t + \gamma G_{t+1} \mid s_t \right] \ &= \mathbb{E}\pi \left[ r_t \mid s_t \right] + \gamma \mathbb{E}\pi \left[ G_{t+1} \mid s_t \right] \end{align*} $$
左边的一项可以展开为,对应为即时奖励的期望
$$ \mathbb{E}\pi \left[ r_t \mid s_t \right] = \sum{a_t \in A} \pi(a_t \mid s_t) \sum_{s_{t+1} \in S} p(s_{t+1} \mid s_t, a_t) r(s_t, a_t, s_{t+1}) $$
右边的 $\mathbb{E}\pi \left[ G{t+1} \mid s_t \right]$ 可以展开为,对应为未来奖励的期望
$$ \begin{align*} \mathbb{E}\pi \left[ G{t+1} \mid s_t \right] &= \sum_{a_t \in A} \pi(a_t \mid s_t) \sum_{s_{t+1} \in S} p(s_{t+1} \mid s_t, a_t) \color{red}\mathbb{E} \left[ G_{t+1} \mid s_t, s_{t+1} \right] \ &= \sum_{a_t \in A} \pi(a_t \mid s_t) \sum_{s_{t+1} \in S} p(s_{t+1} \mid s_t, a_t) {\color{red}\underbrace{\mathbb{E} \left[ G_{t+1} \mid s_{t+1} \right]}{\text{memoryless Markov property}}} \ &= \sum{a_t \in A} \pi(a_t \mid s_t) \sum_{s_{t+1} \in S} p(s_{t+1} \mid s_t, a_t) V_\pi(s_{t+1}) \end{align*} $$
因此,我们可以把一个「无限」累加公式,变成了一个「有限」的递归公式。我们进而可以用迭代的方式,去求解这个状态方程,这即是 $V_\pi (s_t)$ 的 bellman equation。
$$ \begin{align*} V_\pi(s_t) &= \sum_{a_t \in A} \pi(a_t \mid s_t) \sum_{s_{t+1} \in S} p(s_{t+1} \mid s_t, a_t) \left{ r(s_t, a_t, s_{t+1}) + \gamma V_\pi(s_{t+1}) \right} \ &= \mathbb{E}{a_t \sim \pi(\cdot|s_t)} \left[ \mathbb{E}{s_{t+1} \sim P(\cdot|s_t,a_t) } \left[ r_t + \gamma V_{\pi}(s_{t+1}) \right] \right] \end{align*} $$
这意味着,一个状态的价值,是由它直接的即时奖励,加上下一状态的价值 所共同决定的。
同样的,我们也可以推出 $Q_\pi (s_t, a_t)$ 的 bellman equation: $$ \begin{align*} Q_\pi(s_t, a_t) &= \mathbb{E}{s{t+1} \sim P(\cdot|s_t,a_t) } \left[ r_t + \gamma \mathbb{E}{a{t+1} \sim \pi(\cdot|s_{t+1}) } Q_{\pi}(s_{t+1}, a_{t+1}) \right] \end{align*} $$ 关于 $Q_\pi (s_t, a_t)$ 和 $V_\pi (s_{t})$ 的关系: $$ \begin{align*} Q_{\pi}(s_t, a_t) &= \mathbb{E}{\pi}[G_t | s_t, a_t] \ &= \mathbb{E}{\pi}\left[\sum_{t=0}^{T-t} \gamma^t r_t | s_t, a_t\right] \ &= \mathbb{E}{\pi}[r_t + \gamma G{t+1}| s_t, a_t] \ &= \mathbb{E}{\pi}[r_t | s_t, a_t] + E{\pi}[\gamma V_{\pi}(s_{t+1}) | s_t, a_t] \ &= \sum_{s_{t+1} \in \mathcal{S}} p(s_{t+1} | s_t, a_t) r(s_t, a_t, s_{t+1}) + \gamma \sum_{s_{t+1} \in \mathcal{S}} p(s_{t+1} | s_t, a_t) V_{\pi}(s_{t+1}) \ &= \mathbb{E}{s{t+1} \sim P(\cdot | s_t, a_t)} \left[ r_t + \gamma V_{\pi}(s_{t+1}) \right] \end{align*} $$
反过来看
$$ \begin{align*} V_{\pi}(s_t) &= \mathbb{E}{a_t \sim \pi(\cdot|s_t)} \left[ \mathbb{E}{s_{t+1} \sim P(\cdot|s_t,a_t)} \left[ r_t + \gamma V_{\pi}(s_{t+1}) \right] \right] \ &= \mathbb{E}{a_t \sim \pi(\cdot|s_t)} \left[ Q{\pi}(s_t, a_t) \right] \ &= \sum_{a_t \in A} \pi(a_t|s_t) Q_{\pi}(s_t, a_t) \end{align*} $$
Optimization Target
强化学习的目标是找到一个最优策略 $\pi^*$,使得 从任意初始状态出发,Agent 获得的长期累积奖励最大。
$$ \pi^* = \arg\max_{\pi} J(\pi) = \mathbb{E}{\tau \sim \pi} [R(\tau)] = \sum{\tau} R(\tau) P(\tau \vert \pi) $$
RL Algos Overview
强化学习领域的不同算法都是对「如何找到最优策略」的不同思考,按照 Agent 是否试图学习一个关于环境的模型 ,可以分为 Model-based 和 Model-free 两种方法。
这里的模型指的是与 Agent 交互的环境模型。一个完整的 环境模型 通常包含两个关键部分:
- 转移函数(Transition Function):预测在给定状态 $s$ 和动作 $a$ 下,下一个状态 $s′$ 会是什么。即 $P(s’∣s,a)$。
- 奖励函数(Reward Function):预测在给定状态 $s$、动作 $a$ 和下一个状态 $s’$ 下,能获得多大的即时奖励。即 $R(s,a,s’)$
Model-based RL vs Model-free RL
Model-based RL
Model-based RL 的方法,首先学习环境模型,然后利用学到的模型进行策略规划。这样通常具有更高的样本效率,因为可以通过模型进行模拟和预测,从而减少与真实环境的交互次数。实践中,通常将模型学习和策略规划阶段交替进行。部分学习到的策略,可以用于指导数据的收集,从而帮助学习到更好的模型。
Model-based RL 的算法中,环境模型可以是事先知道的(比如动态规划算法),也可以是根据智能体与环境交互采样到的数据学习得到的(比如 Dyna-Q 算法),然后用这个模型帮助策略提升或者价值估计。
现实世界中的环境模型一般很难学习到,目前用的更多的是 Model-free RL,本文后续介绍的都是 Model-free RL 方法。
Model-based RL
Model-free RL 核心思想是,智能体不试图去学习或理解环境是如何运作的。它直接通过大量的试错 Trial-and-Error 来学习一个策略 Policy 或 价值函数 Value Function。这些方法直接从经验数据中学习,而不需要一个中间模型。
Value-based RL vs Policy-based RL
在强化学习中,Model-free RL 的算法主要分为两个方向:
- 基于值函数
value-based的方法主要是学习值函数 Value Function,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略,典型算法包括- Q-learning,可以处理有限状态
- DQN 及 DQN 改进算法,可以用来解决连续状态的问题
- 基于策略
policy-based的方法则是直接显式地学习一个目标策略 Policy- Policy-based 的方法可以更好的处理「连续动作空间」
- 策略梯度 Policy Gradient 是基于策略的方法的基础
On-Policy vs Off-Policy
首先说下另外两个易混淆的概念,Online-RL 和 Offline-RL 。
Online-RL 和 Offline-RL 的区别在于 Agent 在训练过程中是否能持续与环境交互,实时收集新数据?
- Online RL:Agent 可以 持续与环境交互,边收集新数据边学习
- Offline-RL:Agent 不能再与环境交互,只能从一个固定的、预先收集好的数据集里学习。
本文所讨论的 RL 方法都需要 Agent 与环境交互,属于 Online-RL 方法,暂时不考虑 Offline-RL。

另外两个概念是,On-Policy 和 Off-Policy。它们的区别在于,用来收集数据的策略 behavior policy 和用来学习更新的策略 target policy 是不是同一个?
On-Policy: Agent 用来更新其策略 $\pi$ 的数据,必须由当前正在学习和优化的目标策略 $\pi$ 自己生成。如果策略发生改变 $\pi’$,需要用更新后的策略 $\pi’$ 重新 rollout 收集数据。
On-Policy 算法的好处在于由于数据来源与目标策略一致,梯度计算通常更直接,无需重要性采样 Importance Sampling 这种复杂的校正机制。但是缺点在于,一旦策略更新,旧数据就「作废」了,不能直接用于新策略的更新,必须重新 rollout。这导致了大量的环境交互。而往往在训练过程中,rollout 所花费的时间往往是最多的。
Off-Policy: Agent 用来更新其策略 $\pi$ 的数据,可以由其他策略 $\mu$ 做 rollout 生成,也可以用本策略更新之前的策略 $\pi_{old}$ rollout 的旧数据。
Off-Policy 算法的好处自然是数据样本效率高,可以重复利用历史数据,极大地减少了与环境的交互次数。缺点在于,由于数据来源与目标策略不一致,直接使用会导致偏差,需要重要性采样 Importance Sampling 或者 Q-learning 等方法来校正这种分布差异,以保证学习的正确性。如果校正不当可能导致高方差或不收敛。
Policy Gradient
策略梯度 Policy Gradient 是一类直接参数化策略 $\pi_\theta(a|s)$,用参数 $\theta$ 表示策略,比如可以用一个神经网络为这个策略函数建模,输入某个状态,然后输出一个动作的概率分布。
Policy Gradient 的优化目标是找到一个最优的策略 $\pi_{\theta}$ 使得累积奖励最大化,相比于之前的优化目标,这里的 Policy $\pi$ 都已经用 $\theta$ 参数化
$$ \arg\max_{\pi_\theta} J(\pi_\theta) = \mathbb{E}{\tau \sim \pi\theta} [R(\tau)] = \sum_{\tau} R(\tau) P(\tau \vert \pi_\theta) $$
其中 $J(\pi_\theta)$ 是策略 $\pi_\theta$ 的期望累积奖励(目标函数),$\tau$ 是轨迹,$R(\tau)$ 是折扣累积奖励。要最大化 这个函数,可以用梯度上升 gradient ascent 的方法,也就是让参数沿着梯度的方向更新:
$$ \theta_{t+1} = \theta_t + \alpha \nabla_\theta J(\pi_\theta) $$
这里的轨迹 $\tau$ 本身是一个随机变量,是由智能体的策略 $\pi_\theta(a|s)$ 和环境的动态变化共同决定的,而且一条轨迹 $\tau$ 中往往有很多点,直接计算十分复杂。为了计算累积奖励的梯度,Policy Gradient 引入策略梯度定理 Policy Gradient Theorem:
$$\nabla_{\theta} J(\pi_\theta) = \mathbb{E}{\tau \sim \pi{\theta}} \left[ \sum_{t=0}^{T} \nabla_{\theta} \log \pi_{\theta}(a_t \mid s_t) \cdot R(\tau) \right]$$
具体推导并不复杂:
$$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \sum_{\tau} R(\tau) \nabla_{\theta} P(\tau \vert \pi_\theta) \ &= \sum_{\tau} R(\tau) P(\tau \vert \pi_\theta) \nabla_{\theta} \log(P(\tau \vert \pi_\theta)) \ &= \mathbb{E}{\tau \sim \pi\theta} \left[ R(\tau) \nabla_{\theta} \log(P(\tau \vert \pi_\theta)) \right] \end{align*} $$
其中第 1 行到第 2 行用到了 Log-Derivative Trick:
$$ \nabla_x \log f(x) = \frac{\nabla_x f(x)}{f(x)} \implies \nabla_x f(x) = f(x) \nabla_x \log f(x) $$
展开 $P(\tau|\pi_\theta)$ 可以得到:
$$ P(\tau|\pi_\theta) = \rho_0(s_0) \prod_{t=0}^{T-1} P(s_{t+1}|s_t, a_t) \pi_\theta(a_t|s_t) $$
代入到对应的梯度计算:
$$ \begin{align*} \nabla_{\theta} \log(P(\tau|\pi_\theta)) &= \nabla_{\theta} \left[ \log \rho_0(s_0) + \sum_{t=0}^{T-1} \log P(s_{t+1}|s_t, a_t) + \sum_{t=0}^{T-1} \log \pi_\theta(a_t|s_t) \right] \ &= \sum_{t=0}^{T-1} \nabla_{\theta} \log \pi_\theta(a_t|s_t) \end{align*} $$
前两项对应的概率函数因为只和环境有关,而与策略无关,因此对策略求梯度时都是 0。
到这里,我们推导出了策略梯度定理:
$$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{\tau \sim \pi\theta} \left[ R(\tau) \nabla_{\theta} \log(P(\tau|\pi_\theta)) \right] \ &= \mathbb{E}{\tau \sim \pi\theta} \left[ R(\tau) \sum_{t=0}^{T-1} \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$
策略梯度算法中,我们的直觉是:如果一个动作导致了高回报,就增加这个动作的概率;如果一个动作导致了低回报,就降低这个动作的概率。对应到策略梯度定理,$\nabla_{\theta} \log \pi_\theta(a_t|s_t)$ 是一个梯度方向向量,它的方向指向增加动作 $a_t$ 在状态 $s_t$ 下的概率:
- 如果 $R (\tau) > 0$ ,则策略梯度 $\nabla_{\theta} J(\pi_\theta)$ 的方向就会和所有增加动作概率的向量方向一致。换句话说,我们会鼓励这条失败轨迹中所有动作的概率。
- 如果 $R (\tau) < 0$ ,则策略梯度 $\nabla_{\theta} J(\pi_\theta)$ 的方向就会和所有增加动作概率的向量方向相反。换句话说,我们会降低这条失败轨迹中所有动作的概率。
对数概率的梯度:在深度学习中,当我们对一个概率分布的对数求梯度时,得到的结果是一个向量,这个向量会指向增加该事件发生概率的方向。
通过奖励这个标量值,来缩放和引导我们应该如何改变策略参数的方向。这就是策略梯度定理的核心思想,它巧妙地将一个无微分的奖励信号,转化为一个可用于梯度下降的更新方向。
策略梯度定理要求我们对于所有的轨迹求期望,在实际应用中,我们不能遍历所有可能的轨迹,因此只能进行估算。而进行采样估算,这就引入蒙特卡洛 Monte Carlo 算法,根据蒙特卡洛采样算法,我们可以通过局部采样来估计整体的方法,那么我们可以采样一部分轨迹,用来估计这个期望。
假设采样 $N$ 条轨迹,$N$ 足够大,每条轨迹涵盖 $T_n$ 步,则上述梯度可以被写成: $$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{\tau \sim \pi\theta} \left[ R(\tau) \sum_{t=0}^{T-1} \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \ &\approx \frac{1}{N} \sum_{i=0}^{N-1} R(\tau_n)\sum_{t=0}^{T_n - 1} \nabla_{\theta} \log \pi_\theta(a_t|s_t) \end{align*} $$
Advantage Function
原始 Policy Gradient 算法的一个主要问题是,它使用了不相关的奖励信息。在上述的梯度计算中,是整个轨迹总的奖励,$\pi_\theta(a_t|s_t)$ 是轨迹中时刻的单步决策,用整条轨迹的总回报 $R(\tau)$ 作为权重,去调整这条轨迹中每一个动作的概率。如果 $R(\tau)$ 是正的,就增加所有动作的概率;如果是负的,就减少所有动作的概率。这是不是合理的呢?
举个例子,假设一个智能体玩一个游戏,轨迹如下:
- 时刻 $t=1$: 做出一个绝妙的动作 $a_1$ ,获得奖励 +5。
- 时刻 $t=2$: 做出一个普通动作 $a_2$ ,获得奖励 +1。
- 时刻 $t=3$: 做出一个糟糕的动作 $a_3$ ,导致游戏提前结束,获得奖励 -10。
这条轨迹的总回报 $R(\tau) =5+1−10=−4$。
根据基础 Policy Gradient 算法,因为总回报是负的,算法会认为这条轨迹是 坏 的。因此,它会去降低所有动作 $a_1,a_2,a_3$ 的概率。
问题就在这里:动作 $a_1$ 是一个非常好的动作,我们本应该鼓励它,但算法却因为后续的失误而 惩罚 了它。这显然是不公平且低效的。
但是我们也不能不考虑整体轨迹回报,因为我们的目标就是让整体轨迹的回报最优。
因此,我们需要合理的选择奖励信号,在
整体轨迹回报和单步回报之间平衡,更好地引导策略的更新
将这里的奖励信号记作 $\Psi_t$ ,我们可以将梯度记作以下形式:
$$ \nabla_{\theta} J(\pi_\theta) = \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} \Psi_t \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] $$
对应的 $\Psi_t$ 可以有以下不同的选择,下面将对各种不同的选择依次讨论。
- $\sum_{t=0}^{\infty} \gamma^t r_t$ :整个序列的所有奖励
- $\sum_{t=t’}^{\infty} \gamma^{t-t’} r_t$ :整个序列的在 $a_t$ 之后的所有奖励,reward to go
- $\sum_{t=t’}^{\infty} \gamma^{t-t’} r_t - b(s_t)$ :引入 baseline 之后,整个序列的在 $a_t$ 之后的所有奖励
- $Q_{\pi}(s_t, a_t)$:state-action value function
- $A_{\pi}(s_t, a_t)$:advantage function
- $r_t + \gamma V_{\pi}(s_{t+1}) - V_{\pi}(s_t)$:TD residual
Rewards to go
一个朴素的直觉是,当前时刻的动作选择,只应该考虑当前以及未来的奖励,而不应该考虑过去的奖励。为了解决这个问题,REINFORCE 算法使用回报 $G_t$ 来代替 $R (\tau)$
$$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} G_t \cdot \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$
其中 $G_t$ 在前面已经定义过: $$G_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + … = \sum_{k=0}^{T-1-t} \gamma^k r_{t+k}$$
从数学和优化的角度看,使用 Reward-to-Go 的一个巨大好处是显著降低了梯度的方差 Variance。
- 方差的来源:在 REINFORCE 中,梯度是随机采样的估计。如果权重的波动性太大,梯度的估计就会非常不稳定,导致训练过程像“过山车”一样,难以收敛。
- Reward-to-Go 如何降低方差:在时刻 $t$ 之前的奖励 $r_1,…,r_{t-1}$ 对于动作 $a_t$ 来说是随机的噪声,它们与 $a_t$ 的选择无关,但却会影响总回报 $R(\tau)$ 的值。将这些与当前决策无关的随机项从权重中移除,相当于去掉了梯度估计中的一部分噪声,从而使得梯度估计更加稳定。
Introducing a Baseline
即使引入了 Reward-to-Go,仍然会存在高方差的问题。想象一个游戏,无论怎么玩,每一步获得的奖励都在 [100, 110] 这个区间内。
- 轨迹 A: 智能体采取了一系列动作,每个时间步的 $G_t$ 值都在
[105, 110]之间。 - 轨迹 B: 智能体采取了另一系列动作,每个时间步的 $G_t$ 值都在
[100, 105]之间。
根据 Reward-to-Go 的更新规则 $G_t \cdot \sum_{t=0}^{T-1} \nabla_{\theta} \log \pi_\theta(a_t|s_t)$,因为所有的 $G_t$ 都是很大的正数,所以这两条轨迹中的所有动作都会被“鼓励”。
但实际上,轨迹 A 的动作要明显优于轨迹 B 的动作。我们真正关心的是一个动作带来的回报是否比平均水平好,而不是回报的绝对值。在上面这个例子中,我们希望轨迹 A 的动作被鼓励,而轨迹 B 的动作被抑制(或者至少不被那么强烈地鼓励)。
为了解决这个问题,我们可以引入基线 Baseline 的概念,将奖励信号从“绝对好坏”转变为 相对好坏。这个基线 $b(s_t)$ 和动作无关,只和状态 $s_t$ 有关。其核心思想是,通过减去一个预测值来减少方差,但不改变期望值。
具体来说,我们可以使用 $\Psi_t = G_t −b(s_t)$ 作为奖励信号。
$$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} (G_t - b(s_t)) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$
- 如果 $G_t>b(s_t)$ (优势为正):意味着在 $s_t$ 状态下采取动作 $a_t$ 后,实际得到的未来回报比期望的要高。这是一个“惊喜”,是好的信号,我们应该增加这个动作的概率。
- 如果 $G_t<b(s_t)$ (优势为负):意味着实际回报比期望的要低。这是一个“失望”,是坏的信号,我们应该降低这个动作的概率。
引入基线之后,有以下优点:
- 显著降低方差。它消除了回报中与动作无关的部分,只保留了动作带来的
优势,从而使梯度估计更稳定。 - 梯度保持无偏。数学上可以证明,只要基线 $b$ 是一个不依赖于动作 $a_t$ 的函数(通常只依赖于状态 $s_t$ ),那么它就不会给梯度引入偏差。
数据证明引入基线能够保持无偏,即是证明 $\mathbb{E}{\tau \sim \pi\theta} \left [ b(s_t)\sum_{t=0}^{T-1}\nabla_{\theta}log\pi_{\theta}(a_t∣s_t) \right ] = 0$
证明如下:
$$ \begin{align*} &\mathbb{E}{\tau \sim \pi{\theta}} \left[ \left( \sum_{t=0}^{T-1} b(s_t) \right) \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) \right] \ &= \sum_{t=0}^{T-1} \mathbb{E}{\tau \sim \pi{\theta}} \left[ b(s_t) \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) \right] \ &= \sum_{t=0}^{T-1} \mathbb{E}{s_t \sim \pi{\theta}} \left[ b(s_t) \mathbb{E}{a_t \sim \pi{\theta}} \left[ \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) \right] \right] \ &= \sum_{t=0}^{T-1} \mathbb{E}{s_t \sim \pi{\theta}} \left[ b(s_t) \sum_{a_t \sim \pi_{\theta}} \left[ \color{red}{\pi_{\theta}(a_t | s_t)\nabla_{\theta} log\pi_{\theta}(a_t | s_t)} \right] \right] \ &= \sum_{t=0}^{T-1} \mathbb{E}{s_t \sim \pi{\theta}} \left[ b(s_t) \sum_{a_t \sim \pi_{\theta}} \left[ \color{blue}{\nabla_{\theta} \pi_{\theta}(a_t | s_t)} \right] \right] \ &= \sum_{t=0}^{T-1} \mathbb{E}{s_t \sim \pi{\theta}} \left[ b(s_t) \nabla_{\theta} \sum_{a_t \sim \pi_{\theta}} \left[ \pi_{\theta}(a_t | s_t) \right] \right] \ &= \sum_{t=0}^{T-1} \mathbb{E}{s_t \sim \pi{\theta}} \left[ b(s_t) \nabla_{\theta} \sum_{a_t \sim \pi_{\theta}} 1 \right] \ &= \sum_{t=0}^{T-1} \mathbb{E}{s_t \sim \pi{\theta}} \left[ b(s_t) * 0\right] \ &= 0 \end{align*} $$
减少方差也可以类似证明,此处不再赘述。
Introducing $Q$ and $V$
回顾之前对于 Q-function 的定义: $Q_\pi (s_t, a_t)$ 代表在状态 $s_t$ 下采取动作 $a_t$ 所能获得的期望回报: $$Q_{\pi}(s_t,a_t)=\mathbb{E}{\pi}[G_t∣s_t,a_t]$$ 即 $Q\pi (s_t, a_t)$ 是 $G_t$ 在给定状态 $s_t$ 和动作 $a_t$ 时的期望值,换句话说,$G_t$ 是对 $Q_\pi (s_t, a_t)$ 的一次无偏的蒙特卡洛采样。
这就是说,在 REINFORCE 算法中,我们实际上是在用 $Q_\pi (s_t, a_t)$ 的一个 (高方差) 的样本 $G_t$ 来更新策略。
因此,我们可以将优化目标的策略梯度写成如下方式,对应为之前总结的方式 4: $$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} Q(s_t, a_t) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$
引入基线之后,梯度公式为: $$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} (G_t - b(s_t)) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$
这个基线函数 $b (s_t)$ 要怎么选择呢?使用状态价值函数 $V_\pi(s_t)$ 作为是很常见的选择
这里选择 $V_\pi(s_t)$ 并不是最优选择,但已经足够好了,最优选择的推导参考3 18~19 页的推导
因为 $V_\pi (s_t)$ 表示在状态 $s_t$ 下期望的回报,可以被认为是对当前状态 $s_t$ 下「好坏」程度的评估。并且,它只与状态 $s_t$ 有关,而与 $a_t$ 无关,因此引入基线 $V_\pi(s_t)$ 之后梯度仍然是无偏差的,这即是 REINFORCE with baseline 算法。 $$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} (G_t - V_{\pi}(s_t)) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$
注意,这里的 $V_\pi (s_t)$ 通常并不实际存在,我们通过神经网络来模拟它
引入 $Q_\pi (s_t, a_t)$ 和基线 $V_\pi (s_t)$ 之后,我们将这里引导策略更新的奖励信号叫作优势函数: $$ A_\pi(s_t, a_t) = Q_\pi(s_t, a_t) - V_\pi(s_t) $$ 而之前的 $G_t - V_\pi (s_t)$ 则是优势函数 $A_\pi(s_t, a_t)$ 的一个蒙特卡洛估计,他是无偏的。
这个公式的直观意义和 $G_t−V(s_t)$ 完全一样:一个动作的优势就是它带来的期望回报 减去 该状态的平均期望回报。优势函数完美地捕捉了 比平均水平好多少 的核心思想。
引入优势函数之后,原来的优化目标和梯度写成如下格式,对应为之前总结的方式 5: $$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} A_\pi(s_t, a_t) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$
One-Step Advantage: TD error
到目前为止,虽然 $G_t−V_\pi(s_t)$ 作为对优势函数 $A_\pi (s_t, a_t)$ 的蒙特卡洛估计已经很有效,但它仍然依赖于完整的轨迹数据来计算 $G_t$ ,蒙特卡洛方法依然存在一些问题:
- 高方差依然存在:baseline 减少了部分噪声,每个 $G_t$ 仍然包含整条未来轨迹的随机性,方差高
- 学习效率低:REINFORCE 需要完整 episode 才能计算 $G_t$ ,这在长 episode 情形下非常低效
为了摆脱对于整条轨迹的依赖,引入 Bootstrapping 自举 的思想,这也是时序差分 temporal difference 学习的核心,通过单步优势来估计真正的优势 $A_{\pi}(s_t, a_t)$,而不是等整条轨迹收集完毕之后。
理论出发点:优势函数的精确数学定义是 $$ A_\pi(s_t, a_t) = Q_\pi(s_t, a_t) - V_\pi(s_t) $$ 根据 $Q_\pi (s_t, a_t)$ 的 Bellman 公式 $$ Q_{\pi}(s_t,a_t) = \mathbb{E}{s{t+1} \sim P(\cdot | s_t, a_t)} \left[ r_t + \gamma V_{\pi}(s_{t+1}) \right] $$
按照同样求期望的方式展开 $V_\pi (s_t)$,有
$$ V_\pi(s_t) = \mathbb{E}{s{t+1} \sim P(\cdot|s_t,a_t) } \left[ V_{\pi}(s_{t}) \right] $$
可以得到 $$ \begin{align*} A_{\pi}(s_t, a_t) &= Q_{\pi}(s_t, a_t) - V_{\pi}(s_t) \ &= E_{s_{t+1} \sim P(\cdot|s_t,a_t)} \left[ r_t + \gamma V_{\pi}(s_{t+1}) \right] - E_{s_{t+1} \sim P(\cdot|s_t,a_t)} \left[ V_{\pi}(s_t) \right] \ &= E_{s_{t+1} \sim P(\cdot|s_t,a_t)} \left[ r_t + \gamma V_{\pi}(s_{t+1}) - V_{\pi}(s_t) \right] \end{align*} $$ 这个公式告诉我们,状态 $s_t$ 下采取动作 $a_t$ 的真实优势,等于单步优势 TD 误差 $\delta_t$ 的期望。而这里的 $\delta_t$ 等于 进入 $s_{t+1}$ 状态后获得的单步奖励 $r_t$ (这里的 $r_t$ 是确定值,而不是随机变量),加上下一步 $s_{t+1}$ 的平均价值估计,减去当前状态 $s_t$ 的平均价值估计。 $$ \delta_t = r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t) $$ 根据这个公式,我们可以用只往前看一步的方式来估计优势,而不再需要必须采集完整的轨迹数据后才能计算优势。也就是说,我们用单步优势 TD 误差 $\delta_t$ 作为真实优势的估计,而不再采用 $G_t - V_\pi (t)$ 这种蒙特卡洛优势估计。
再理解下,原来 $G_t - V_\pi (t)$ 这种蒙特卡洛优势估计时,策略梯度计算为: $$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} (G_t - V_{\pi}(s_t)) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$ 改为单步优势 TD 误差 $\delta_t$ 估计之后,可以直接用单步优势算出来的策略梯度来更新策略: $$ \nabla_{\theta} J(\pi_\theta) \text{ 的单步贡献} \approx \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) \cdot \delta_t $$ 对应的策略梯度公式 $$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{t} \left[ \delta_t \nabla{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$ 这里的 $\mathbb{E}{t}$ 表示对时间步 $t$ 上采样到的 $(s_t, a_t)$ 状态对取期望,通常等价于对状态分布 $d^{\pi}(s)$ 和动作采样分布 $a ~ \pi$ 的联合分布。也就是: $$ \begin{align*} \nabla{\theta} J(\pi_\theta) &= \mathbb{E}{s_t ~ d^{\pi}(s), a_t~\pi(s_t)} \left[ \delta_t \nabla{\theta} \log \pi_\theta(a_t|s_t) \right] \ &= \sum_{s_t \in S} d^{\pi}(s) \sum_{a_t \in A} \left[ \delta_t \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \end{align*} $$
总结一下单步优势 TD 误差 $\delta_t$ 估计的好处:
- 单步更新。我们不再需要等待整个轨迹结束,而是每走一步就可以更新一次策略。这使得训练更加高效,特别是对于长轨迹任务。
- 同时解决了方差和偏差的权衡。TD 方法通常比蒙特卡洛方法方差更低,但因为使用了对 $V_\pi(s_{t+1})$ 的估计,引入了少量的偏差。
问题:为什么 TD 方法使用了对 $V_\pi(s_{t+1})$ 的估计,导致引入了少量偏差,而 REINFORCE with baseline 是用了 $V_\pi (s_t)$ 的估计仍然是无偏估计?
回想一下,我们现在是通过一个神经网络 $V_\pi$ 来估计状态价值函数,在 REINFORCE with baseline 算法中,我们依然是通过 $G_t$ 的蒙特卡洛方法来估计优势,$V_\pi (s_t)$ 只是作为 baseline,只要 $V_\pi (s_t)$ 只与 $s_t$ 有关,则仍然是无偏估计。
但是在 TD 方法中,我们是通过单步奖励 $r_t$ 加上对于下一状态 $s_{t+1}$ 的价值 $V_\pi(s_{t+1})$ 来估计优势,真正的有效信息只有 $r_t$,如果神经网络预测不准,则是有偏的。
Actor-Critic
到目前为止,其实我们已经介绍了 Policy Gradient 的经典算法,包括 REINFORCE 和 Actor-Critic 等,总结一下之前所介绍的内容。
Policy Gradient 算法的核心思想是通过优化策略使得优化目标 $J (\theta)$ 累积期望激励最大。 $$ \begin{align*} \theta_{t+1} &= \theta_t + \alpha \nabla_\theta J(\pi_\theta) \ &= \theta_t + \alpha \mathbb{E}{s_t ~ d^{\pi}(s), a_t~\pi{\theta}(s_t)} \left[Q_\pi(s_t, a_t) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \ \end{align*} $$ 因为真实的梯度并不知道,我们用一个随机梯度来预测它: $$ \begin{align*} \theta_{t+1} &= \theta_t + \alpha \left[\hat{Q}(s_t, a_t) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \ \end{align*} $$
如果这里的 $\hat{Q} (s_t, a_t)$ 是通过蒙特卡洛方法来估计的,则被称作 REINFORCE 算法。
对应的算法流程如下:

如果这里的 $\hat{Q} (s_t, a_t)$ 是通过 TD 方法来估计的,则被称作 Q Actor-Critic (QAC)算法。 $$ \begin{align*} \hat{Q}(s_t, a_t) &= r_t + \gamma Q_\pi(s_{t+1}) - Q_\pi(s_t) \end{align*} $$
注意,前面并没有介绍这里的 QAC 算法,这里作为补充将这几种算法同意在在一个框架下。这个时候使用另外一个神经网络 $Q$ Network 来估计 $\hat{Q} (s_t, a_t)$。
QAC 对应的算法流程如下:

接下来我们通过引入 baseline 从而来更好的减少方差
$$
\begin{align*}
\theta_{t+1}
&= \theta_t + \alpha \nabla_\theta J(\pi_\theta) \
&= \theta_t + \alpha \mathbb{E}{s_t ~ d^{\pi}(s), a_t~\pi{\theta}(s_t)} \left[[Q_\pi(s_t, a_t)-V_\pi(s_t)] \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \
&= \theta_t + \alpha \mathbb{E}{s_t ~ d^{\pi}(s), a_t~\pi{\theta}(s_t)} \left[A_\pi(s_t, a_t) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \
\end{align*}
$$
同样,我们也不知道这里的优势函数,因此用随机梯度来估计它
$$
\begin{align*}
\theta_{t+1}
&= \theta_t + \alpha \left[ [\hat{A}(s_t, a_t)] \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \
\end{align*}
$$
如果这里的 $\hat{A}(s_t, a_t)$ 是通过蒙特卡洛方法来估计的,则被称作 REINFORCE with baseline 算法。具体的,$\hat{Q}(s_t, a_t) = G_t$ ,$\hat{V}(s_t)$ 通过一个神经网络来估计。对应的算法流程如下:

如果这里的 $\hat{A}(s_t, a_t)$ 是通过 TD 方法来估计的,则被称作 Advantage Actor-Critic 算法。 $$ \begin{align*} \hat{A}(s_t, a_t) &= r_t + \gamma V_\pi(s_{t+1}) - V_\pi(s_t) \end{align*} $$ 对应的算法流程如下:

Generalized Advantage Estimate
Bias Variance Trade-off
回顾下我们在 Actor-Critic 算法中对于 Advantage 函数的估计: $$ \hat{A}t^{TD} = r_t + \gamma V\pi(s_{t+1}) - V_\pi(s_t) = \delta_t $$ 因为 TD 单步估计只用了一步采样的数据,方差很低。但是因为其依赖于神经网络估计的 $V_\pi(s_{t+1})$ ,所以是有偏的。
另一种估计方法是上面讨论过的蒙特卡洛 MC 估计: $$ \hat{A}t^{MC} = G_t - V(s_t), G_t = \sum{k=0}^{\infty} \gamma^k r_{t+k} $$ MC 方法是无偏的,但是利用了 $t$ 时刻之后所有的回报值,方差更大。
这就是强化学习中讨论的 bias-variance trade-off 问题。

N-step TD error
为了解决因为 $V_\pi (s_{t+1})$ 不准导致的偏差问题,我们可以在 MC 和 1-step TD 之间,定义 n-step TD,如下所示: $$ \begin{align} % 单步优势 (k=1) \hat{A}t^{(1)} &= \delta_t^V = -V(s_t) + r_t + \gamma V(s{t+1}) \ % 两步优势 (k=2) \hat{A}t^{(2)} &= \delta_t^V + \gamma \delta{t+1}^V = -V(s_t) + r_t + \gamma r_{t+1} + \gamma^2 V(s_{t+2}) \ % 三步优势 (k=3) \hat{A}t^{(3)} &= \delta_t^V + \gamma \delta{t+1}^V + \gamma^2 \delta_{t+2}^V = -V(s_t) + r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \gamma^3 V(s_{t+3}) \ % k步优势的通用形式 \hat{A}t^{(k)} &= \sum{l=0}^{k-1} \gamma^l \delta_{t+l}^V = -V(s_t) + r_t + \gamma r_{t+1} + \dots + \gamma^{k-1} r_{t+k-1} + \gamma^k V(s_{t+k}) \ % 无穷步优势 (k→∞) \hat{A}t^{(\infty)} &= \sum{l=0}^\infty \gamma^l \delta_{t+l}^V = -V(s_t) + \sum_{l=0}^\infty \gamma^l r_{t+l} \end{align} $$
在上面的公式中,随着 $k$ 增加,偏差会减少,方差会增大。直观的解释是,随着 $k$ 增加,我们更多的利用了多步的奖励信息,更少的信任了神经网络 $V_\pi (s)$ 的估计,因此偏差更小。而同时因为引入了更多的信息,所以方差也会更大。当 $k$ 趋于无穷时,n-step TD error 实际上对应的就是蒙特卡洛估计。
$\lambda$ return
GAE 优势估计则是系统化地把 n-step 方法融合,形成一个平衡偏差和方差的估计。它引入一个加权平均的参数 $\lambda$ ,这 $n$ 个 $k$ 步估计量($k$ 从 1 到 $n$)进行加权平均,平衡了 TD 方法和 MC 方法,同时也平衡了偏差和方差。 $$ \begin{align*} \hat{A}t^{\text{GAE}(\gamma,\lambda)} &:= (1 - \lambda) \left( \hat{A}t^{(1)} + \lambda \hat{A}t^{(2)} + \lambda^2 \hat{A}t^{(3)} + \dots \right) \ &= (1 - \lambda) \left( \delta_t^V + \lambda (\delta_t^V + \gamma \delta{t+1}^V) + \lambda^2 (\delta_t^V + \gamma \delta{t+1}^V + \gamma^2 \delta{t+2}^V) + \dots \right) \ &= (1 - \lambda) \left( \delta_t^V (1 + \lambda + \lambda^2 + \dots) + \gamma \delta{t+1}^V (\lambda + \lambda^2 + \lambda^3 + \dots) \right. \ &\quad\quad\quad\quad \left. + \gamma^2 \delta_{t+2}^V (\lambda^2 + \lambda^3 + \lambda^4 + \dots) + \dots \right) \ &= (1 - \lambda) \left( \delta_t^V \left( \frac{1}{1 - \lambda} \right) + \gamma \delta_{t+1}^V \left( \frac{\lambda}{1 - \lambda} \right) + \gamma^2 \delta_{t+2}^V \left( \frac{\lambda^2}{1 - \lambda} \right) + \dots \right) \ &= \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l}^V \end{align*} $$
- 当 $\lambda = 0$ 时,$\hat{GAE}(\gamma, 0): A_t = \delta_t^V = -V(s_t) + r_t + \gamma V(s_{t+1})$
- 这就是 1 步 TD 估计,方差小,但是有偏差
- 当 $\lambda = 1$ 时,$GAE(\gamma, 1): A_t = \sum_{l=0}^{\infty} \gamma^l \delta_{t+l}^V = \hat{A}t^{(\infty)} = -V(s_t) + \sum{l=0}^{\infty} \gamma^l r_{t+l}$
- 这就是 MC 估计,是无偏估计,但是方差大
在代码实现中,GAE 估计通常写作迭代形式: $$ \hat{A}t = \delta_t + \gamma \lambda \hat{A}{t+1} $$
参考代码如下,基本就是按照公式的实现,从后往前计算:
|
|
PPO
Surrogate Objective
经过前面的介绍,我们离 PPO 算法已经很近了。在进一步介绍 PPO 算法之前,我们先介绍下 Surrogate Objective 代理目标。
策略梯度的原始优化目标: $$ \arg\max_{\pi_\theta} J(\pi_\theta) = \mathbb{E}{\tau \sim \pi\theta} [R(\tau)] = \sum_{\tau} R(\tau) P(\tau \vert \pi_\theta) $$ 根据策略梯度定理, $$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{s_t ~ d^{\pi}, a_t~\pi\theta} \left[ A_\pi(s_t, a_t) \nabla_{\theta} \log \pi_\theta(a_t|s_t) \right] \ \end{align*} $$ 因为原始需要对每个步骤的状态和动作求积分或求和,这是非常困难的,因此可以引入代理目标函数 $\mathcal{L}^{PG}(\pi_\theta)$ $$ \mathcal{L}^{PG}(\pi_\theta) = \mathbb{E}{s_t \sim d^\pi, a_t \sim \pi\theta} \left[ \log \pi_{\theta}(a_t \mid s_t) \cdot A_{\pi}(s_t, a_t) \right] $$ 这里可以确保代理目标函数 $\mathcal{L}^{PG}(\theta)$ 的梯度和原始策略优化目标的一致: $$ \nabla_\theta \mathcal{L}^{PG}(\theta) = \nabla_\theta J(\pi_\theta) $$ 通过引入 Surrogate Objective,我们可以灵活设计目标函数,只要确保该目标函数的梯度和策略梯度定理一致即可。
Importance Sampling
从策略梯度开始到现在,我们所有的策略梯度算法,不管是 REINFORCE 还是 A2C 算法,都是 on-policy 的。也就是说,rollout 的 behavior policy 和训练的 target policy 是同一个。
之前提到过 on-policy 的一个问题在于样本效率低,为了复用旧策略采样的数据(无需重新采样),引入了重要性采样 Importance Sampling。
对于函数 $f (x)$,符合目标概率分布 $p (x)$ ,如果要求解 $f (x)$ 的期望,则有
$$
\mathbb{E}{x \sim p} [f(x)] = \int f(x) , p(x) , dx
$$
如果我们不太好从 $p (x)$ 中采样,而只能从另一个提议分布 $q (x)$ 采样,那么 $f (x)$ 的期望则可以计算为:
$$
\mathbb{E}{x \sim p} [f(x)] = \int f(x) , p(x) , dx = \int f(x) , \frac{p(x)}{q(x)} , q(x) , dx = \mathbb{E}_{x \sim q} \left[ f(x) , \frac{p(x)}{q(x)} \right]
$$
这里的 $\frac {p (x)}{q (x)}$ 被称为 重要性权重 Importance Weight。
Importance sampling 要求分布 $p(x)$ 和 $q(x)$ 不能差距过大,否则在采样数目比较小的情况下,估计会发生严重偏移。
如下图所示,在 $x$ 服从 $p(x)$ 分布时,$f(x)$ 的期望为负。
- 此时我们从 $q (x)$ 中来采样少数的 $x$,那么我们采样到的 $x$ 很有可能都分布在右半部分,此时 $f(x)$ 大于0,我们很容易得到 $f(x)$ 的期望为正的结论,这就会出现问题,因此需要进行大量的采样。
- 当终于在 $q (x)$ 采样到左半部分的点 $x_1$ 时,因为 $q (x_1)$ 比较小,$p (x_a)$ 比较大,从而会导致 $\frac {p (x_a)}{q (x_a)}$,因此我们会给点 $x_1$ 的 $f (x_1)$ 这个负值以很大的权重,从而实现最终期望为负,与目标期望一致。

换句话说,如果分布 $p(x)$ 和 $q(x)$ 差距过大,会导致 $\frac {p (x)}{q (x)}$ 爆炸,从而导致采样估计的时候方差高,不稳定。为了减少方差,一个直接的思路就是 Truncated Importance Sampling,也就是用 $min (c, \frac{p}{q})$ 限制比例,比如 PPO 中的 CLIP。
回到策略梯度算法,我们想要去估计难采样的新策略分布 $\pi_\theta$ 下累积奖励的期望,但是实际轨迹数据是从旧策略分布 $\pi_{\theta_{\text{old}}}$ 采样的,我们需要通过 Importance Weight 消除分布差异。
根据重要性采样,我们可以推导出 off policy 的 policy gradient 定理为,具体推导可以参考强化学习的数学原理:
$$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{s_t ~ d^{\pi}, a_t~\pi{\theta_{old}}} \left[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} \nabla_{\theta} \log \pi_\theta(a_t|s_t) A_{\pi_{old}}(s_t, a_t) \right] \ \end{align*} $$
同样可以得到对应的 Surrogate Objective 为: $$ \mathcal{L}^{PG_{off}}(\pi_\theta) = \mathbb{E}{s_t \sim d^\pi, a_t \sim \pi{\theta_{old}}} \left[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} A_{\pi_{old}}(s_t, a_t) \right] $$ 这里推导 Surrogate Objective 的过程为,应用 Log-Derivative Trick,off policy 的策略梯度可以写成 $$ \begin{align*} \nabla_{\theta} J(\pi_\theta) &= \mathbb{E}{s_t ~ d^{\pi}, a_t~\pi{\theta_{old}}} \left[ \frac{\nabla_{\theta}\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} A_{\pi_{old}}(s_t, a_t) \right] \ \end{align*} $$ 因此积分策略梯度就可以得到上面的 Surrogate Objective。
如果用 GAE 优势估计 $A_{\pi_{old}} (s_t, a_t)$ ,对应优化目标写为
$$ \underset{\pi_\theta}{\arg\max} J(\pi_\theta) = \underset{\tau \sim \pi_{\theta_{\text{old}}}}{E_t} \left[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} A_{\pi_{\theta_{old}}}^{\text{GAE}}(s_t, a_t) \right] $$
TRPO
TRPO 的核心思想是:每次策略更新,都必须保证新策略与旧策略之间的差异在一个信赖域 Trust Region 之内。这个差异通常用 KL 散度来衡量,它量化了两个概率分布之间的距离。
TRPO 的 surrogate objective 为 $$ \begin{align} \arg\max_{\pi_\theta} J(\pi_\theta) &= \underset{\tau \sim \pi_{\theta_{\text{old}}}}{E_t} \left[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} A_{\pi_{\theta_{old}}}^{\text{GAE}}(s_t, a_t) \right] \ \text{subject to } & E_t\left[ KL\left( \pi_{\theta_{\text{old}}}(\cdot|s_t), \pi_\theta(\cdot|s_t) \right) \right] \leq \delta \end{align} $$ TRPO 的理论非常优雅,它保证了每次更新都能提升策略性能,并且不会出现灾难性的性能下降。
然而,TRPO 有一个致命的缺点:实现起来非常复杂。它需要计算二阶导数(Hessian 矩阵),或者使用共轭梯度法(Conjugate Gradient)来近似求解,这在计算上非常昂贵,而且难以与深度学习框架(如 PyTorch)的自动微分机制完美结合。
PPO 是 TRPO 的一种简化版本,它的基本思想和 TRPO 一致,即保证新策略与旧策略之间的差异在一个信赖域 Trust Region 之内。PPO 包括两种实现方式,PPO-CLIP 和 PPO- KL Penalty。
PPO-CLIP
不像 TRPO 那样通过 KL 散度来严格约束,PPO-CLIP 直接通过剪裁Clipping,来限制新旧策略之间的比率。
PPO 引入的目标函数如下: $$ \begin{align} J^{\text{PPO-CLIP}}(\pi_\theta) &= \underset{\tau \sim \pi_{\theta_{\text{old}}}}{E_t} \left[ \min\left{ r_t(\theta) A_{\pi_{\theta_{old}}}^{\text{GAE}}(s_t, a_t), \text{clip}\left(r_t(\theta), 1 - \epsilon, 1 + \epsilon\right) A_{\pi_{\theta_{old}}}^{\text{GAE}}(s_t, a_t) \right} \right] \end{align} $$
其中 $r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)}$ 是策略比率 Probability Ratio,$\epsilon$ 是预先设置的超参 Clip Ratio,通常设置在 0.2 左右。通过引入裁剪项,可以保证策略比例 $r_t(\theta)$ 始终在 $[1-\epsilon, 1+\epsilon]$ 范围内。
对于这个目标函数,我们分两种情况讨论其实现的效果。
当 $A_{\pi_{\theta_{old}}}^{\text{GAE}}(s_t, a_t) > 0$ 时,说明我们当前执行的动作 $a_t$ 相较于别的动作更好,因此我们要提升 $\pi_\theta(a_t|s_t)$,也就是 $r_t(\theta)$ 增大 。但考虑到采样不足时,$\pi_\theta$ 和 $\pi_{\theta \text{old}}$ 的分布差异不能太大,因此 $\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta \text{old}}(a_t|s_t)}$ 有上限——不能一味轻信 $A_{\pi_{\theta_{old}}}^{\text{GAE}}(s_t, a_t)$ 而持续提升 $\pi_\theta(a_t|s_t)$,需保证 $\pi_\theta$ 在 $\pi_{\theta \text{old}}$ 的信任阈内。假设当该比值 $\geq 1 + \epsilon$ 时,对其做 clip,固定在 $1 + \epsilon$。
当 $A_{\pi_{\theta_{old}}}^{\text{GAE}}(s_t, a_t) < 0$ 时,说明当前执行的动作 $a_t$ 相较于别的动作更差,因此要降低 $\pi_\theta(a_t|s_t)$,也就是 $r_t(\theta)$ 减小。考虑到 $\pi_\theta$ 和 $\pi_{\theta \text{old}}$ 的分布差异不能太大,$\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta \text{old}}(a_t|s_t)}$ 有下限——不能一味轻信 $A_{\pi_{\theta_{old}}}^{\text{GAE}}(s_t, a_t)0$ 而持续降低 $\pi_\theta(a_t|s_t)$。假设当该比值 $\leq 1 - \epsilon$ 时,对其做 clip,固定在 $1 - \epsilon$。

PPO-Penalty
PPO-Penalty 的实现方式则是通过将 KL 散度约束以惩罚项的形式加入目标函数中,来达到限制策略更新幅度的目的。
$$ J^{PPO-Penalty}(\pi_\theta) = \underset{\tau \sim \pi_{\theta_{\text{old}}}}{E_t} \left[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} A_{\pi_{\theta_{old}}}^{\text{GAE}}(s_t, a_t) - \beta KL\left( \pi_{\theta_{\text{old}}}(\cdot|s_t), \pi_\theta(\cdot|s_t) \right) \right] $$
GRPO

Placeholder
-
No backlinks found.