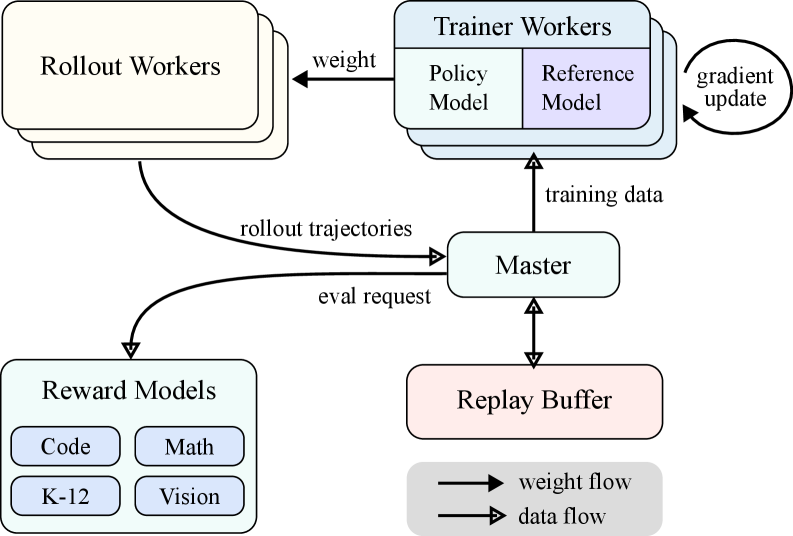
RL Scaling: 异步采样与流水线并行优化
在 LLM 的强化学习 RL 训练流程中,rollout 阶段存在的长尾分布问题 long-tail skewness,会导致大量 GPU 处于空闲状态,严重制约训练效率。针对这一核心痛点,业界与学界已提出诸多异步 RL 训练优化方案,本文将对这些方案进行系统梳理与总结。
RL 范式
当前 LLM 的强化学习中主要采用 Policy Gradient 的方法,特别是 PPO 和 GRPO 等算法。训练中一般包含以下角色:
- Policy Model:即 actor
- Rollout 时,actor 和环境交互,根据输入的 prompt,生成 response
- 训练时,actor 根据 advantage 优化自身权重,使得累计奖励更大
- Value Model:即 critic,用于估计
value function- 在 GRPO 算法中,value model 被省略,通过 Group 内平均奖励作为 baseline 来计算 advantage
- Reference Model:用于确保 actor 不会过度偏离其初始状态
- 通常从 actor 模型初始化,训练中参数固定
- Reward Model:用于提供
reward signal,引导模型向特定方向优化- 在 RLHF 中,reward model 是通过是对人类标注偏好数据训练得到的模型
- 在 RLVR 中,reward model 是一个可以直接验证的 reward function,而不是一个具体的模型。比如数学任务中,基于规则直接判断模型答案是否正确;代码任务中,通过 sandbox 编译测试执行模型输出的代码判断结果是否正确

在 LLM 的 RL 训练的 workflow 中,每个 iteration 一般分为以下三个 stage:
- Generation Stage:也就是 rollout 阶段,生成 trajectory 作为训练的样本
- 单轮场景下,Actor 模型基于输入 Prompt 自回归生成 Response
- 在 Agent 场景下,Actor 与环境交互生成多轮行动轨迹 trajectory,比如 search 场景和 Search/VisitPage 工具
- 一般通过 vLLM 或者 SGLang 等推理引擎实现 Rollout
- Inference Stage:根据已经生成的样本计算训练优化所需要的监督信号
- 对于 ref model,
- Training Stage:更新模型参数以优化策略
- 参数更新:一般通过 FSDP 或者 Megatron 等训练引擎实现训练
- Actor 模型基于 “奖励信号 + KL 约束” 调整生成策略(最大化累计奖励)
- Critic 模型基于 “价值估计误差” 优化价值预测能力(提升后续监督信号的准确性)
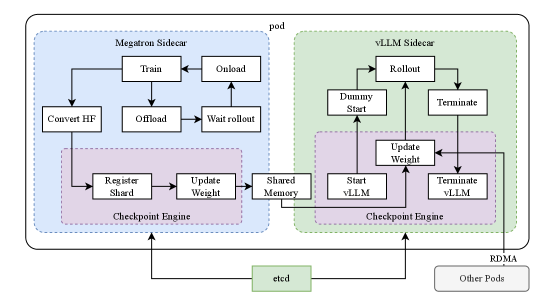
- 参数同步:更新后的 Actor 参数需同步到生成阶段的 Actor 实例中,确保下一轮生成使用最新策略,也就是要将训练引擎的参数同步到推理殷勤。
- 参数更新:一般通过 FSDP 或者 Megatron 等训练引擎实现训练
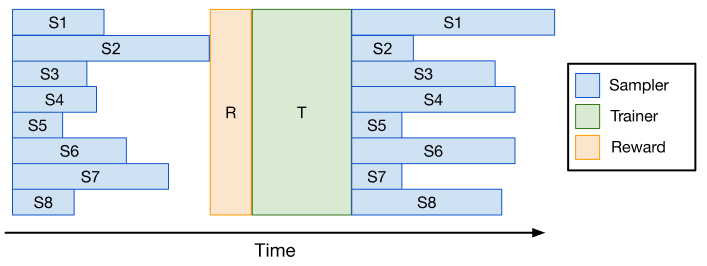
整个过程可以用伪代码表示如下:
|
|
Minibatch Pipelining
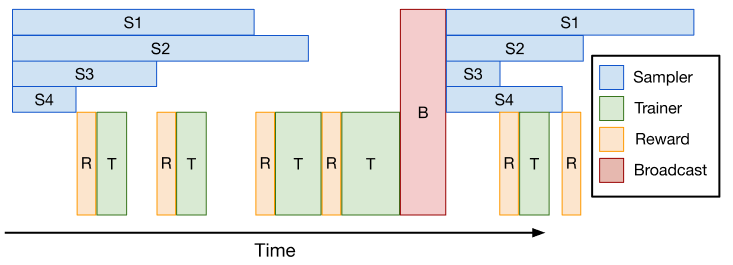
One-step off-policy
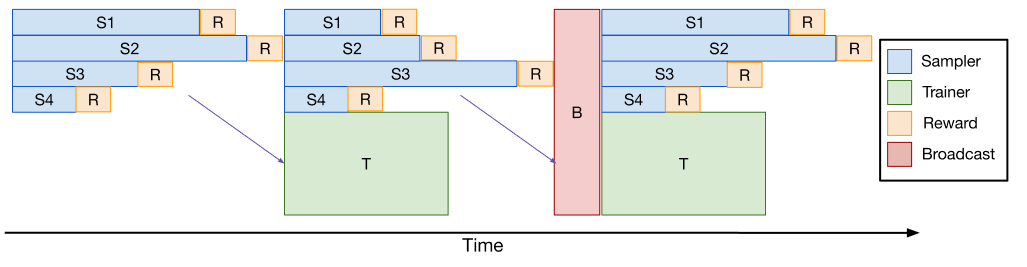
VeRL:
- One-step off https://github.com/volcengine/verl/pull/2231
- Partial rollout: https://github.com/volcengine/verl/pull/2200
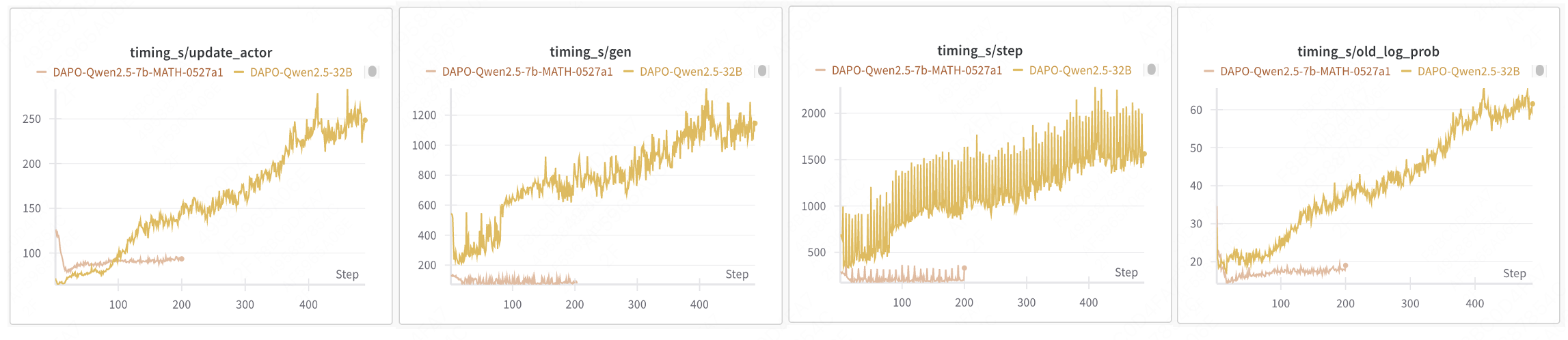
AReal



StreamRL





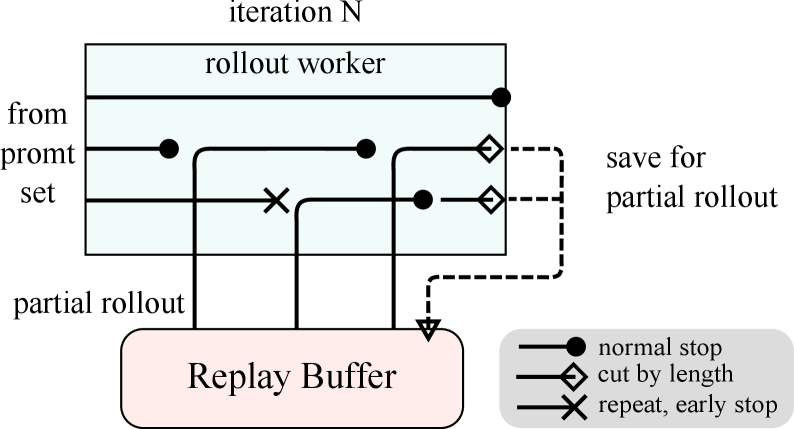
Partial Rollout
Linked Mentions
-
No backlinks found.