LM 击败 Diffusion Model:聊聊 Sora 与 Tokenizer
https://openai.com/research/generative-models It’s easy to forget just how much you know about the world: you understand that it is made up of 3D environments, objects that move, collide, interact; people who walk, talk, and think; animals who graze, fly, run, or bark; monitors that display information encoded in language about the weather, who won a basketball game, or what happened in 1970.
This tremendous amount of information is out there and to a large extent easily accessible—either in the physical world of atoms or the digital world of bits. The only tricky part is to develop models and algorithms that can analyze and understand this treasure trove of data.
Generative models are one of the most promising approaches towards this goal. To train a generative model we first collect a large amount of data in some domain (e.g., think millions of images, sentences, or sounds, etc.) and then train a model to generate data like it. The intuition behind this approach follows a famous quote from Richard Feynman:
Technical Terms
在真正开始之前,这里先简单介绍下本文可能会碰到的技术缩略语,现在不需要深刻理解其含义,只需要有初步印象即可。
| 英文 | 缩写 | 中文释义 |
|---|---|---|
| ViT | Vision Transformers | |
| CLIP | Contrastive Language-Image Pre-training | |
| DDPM | Denoising Diffusion Probabilistic Models | |
| DiT | Diffusion Transformers | |
| VAE | Variational AutoEncoder | |
| MAE | Masked AutoEncoder | |
| GAN | Generative Adversarial Networks | |
| U-Nets | ||
| BLIP | Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation | |
| CoCa | Contrastive Captioners are Image-Text Foundation Models | |
| LLaVA | ||
| GLIP | ||
| FID | Frechet Inception Distance | |
https://huggingface.co/blog/zh/text-to-video
Multimodal Foundation Models: From Specialists to General-Purpose Assistants https://arxiv.org/pdf/2309.10020.pdf
mm-llms recent advances in multimodal large language models
这篇文章将会主要参照 Multimodal Foundation Models 这篇文章的思路,阐述经过学习之后的 MultiModal 的整个链路的理解
问题的关键在于:
- 图像生成 Diffusion Model
- 图像理解 CLIP 等
谷歌博客的综述,很多图片很赞,逻辑也很详细 https://blog.research.google/2023/01/google-research-2022-beyond-language.html#MultimodalModels
图片理解
https://deepmind.google/discover/blog/tackling-multiple-tasks-with-a-single-visual-language-model/
ViT
https://arxiv.org/abs/2010.11929 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

CLIP
https://openai.com/research/clip Learning Transferable Visual Models From Natural Language Supervision https://arxiv.org/abs/2103.00020

BEiT
https://huggingface.co/docs/transformers/en/model_doc/beit BEiT: BERT Pre-Training of Image Transformers https://arxiv.org/abs/2106.08254

Stable Diffusion
原理 The Illustrated Stable Diffusion https://jalammar.github.io/illustrated-stable-diffusion/
High-Resolution Image Synthesis with Latent Diffusion Models https://arxiv.org/pdf/2112.10752.pdf

DiT
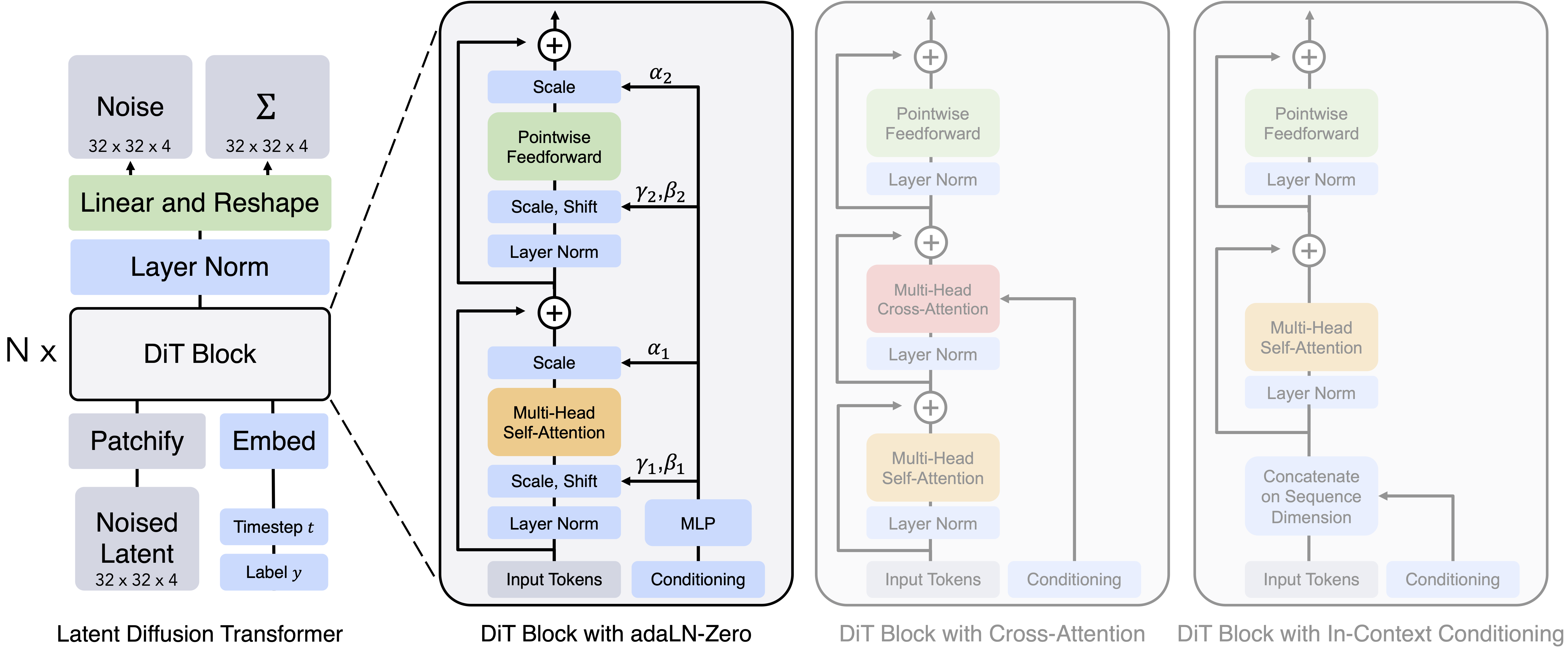
https://www.zhangzhenhu.com/aigc/%E5%8F%98%E5%88%86%E8%87%AA%E7%BC%96%E7%A0%81%E5%99%A8.html
VAE
ViViT
https://arxiv.org/pdf/2103.15691.pdf

Whisper
原理 https://github.com/openai/whisper
Robust Speech Recognition via Large-Scale Weak Supervision https://cdn.openai.com/papers/whisper.pdf
https://openai.com/research/whisper

音乐生成
DALLE
- https://openai.com/research/dall-e
- https://openai.com/dall-e-3
- Improving Image Generation with Better Captions https://cdn.openai.com/papers/dall-e-3.pdf
视频生成
VideoPoet

- https://sites.research.google/videopoet/
- https://arxiv.org/pdf/2312.14125.pdf VideoPoet: A Large Language Model for Zero-Shot Video Generation
-
No backlinks found.