State of GPT 2
讲完结构之后,大概会讲讲怎么训练的,会介绍 DeepSpeed,Megatron 的基本原来,从而引出各种并行原理,Tensor/PipeLine/ZeRO/3 D Parallel
参考资料:
这个是微软的介绍 ZeRO 和 DeepSpeed 的文章
- https://www.cnblogs.com/jiangxinyang/p/17334076.html
- https://www.cnblogs.com/jiangxinyang/p/17330352.html
- https://www.cnblogs.com/jiangxinyang/p/17330352.html
- https://www.cnblogs.com/jiangxinyang/p/17353431.html
- https://www.cnblogs.com/jiangxinyang/p/17353431.html
关于各种并行原理的解读:
- https://www.youtube.com/watch?v=p-e0uP0I0xw&list=PLuufbYGcg3p4cv3QJdZEw08EM0SP00B_1&index=13
- https://huggingface.co/docs/transformers/v4.15.0/parallelism#parallelism-overview
DeepSpeed
Megatron-LM
GPipe
ZeRO
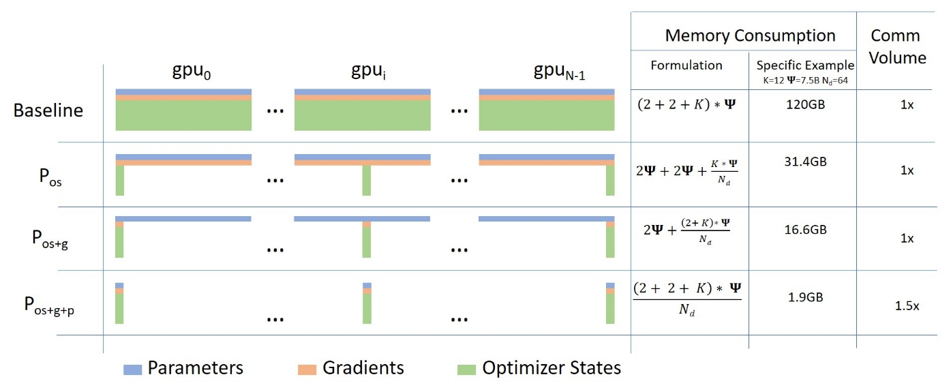
Colossal
- Ray
OpenAI kubernetes 集群 7500 节点 Ray Cluster stack
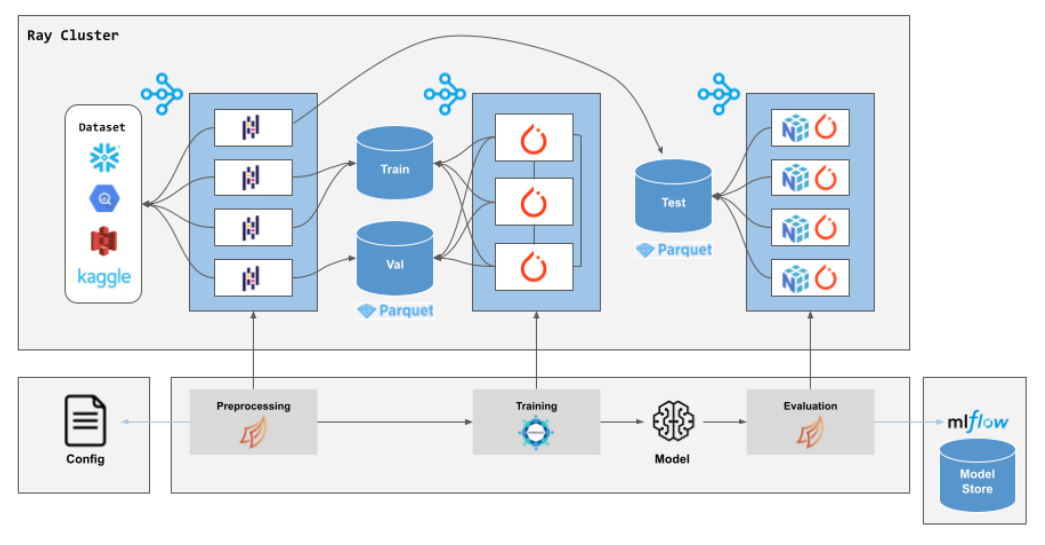
- https://www.anyscale.com/blog/ray-common-production-challenges-for-generative-ai-infrastructure
- https://www.anyscale.com/blog/training-175b-parameter-language-models-at-1000-gpu-scale-with-alpa-and-ray
- https://www.anyscale.com/blog/faster-stable-diffusion-fine-tuning-with-ray-air
- https://www.anyscale.com/blog/how-to-fine-tune-and-serve-llms
OpenAI 使用 ray
Linked Mentions
-
No backlinks found.