NCCL Advanced
在 nccl > NCCL Examples 中我们可以看到 nccl 编程中首先需要创建 nccl communicator。在调用 ncclCommInitRank 前首先需要申请到 UniqId,我们将根据此分析 NCCL 代码。本文分析代码采用的是 NCLL v2.7.8-1 版本。
总的来说,NCCL 的工作流程如下:
- 首先,每个要参与数据传输的 GPU 都要调用
ncclCommInitRank创建一个与其rank对应的 Communicator,同一个 communication group 中的每个 communicator 具有相同的 unique ID。- 当每个设备调用
ncclCommInitRank时,设备之间会交换一些信息,例如各自的 IP,bus ID 等。然后检测整个系统中的网络拓扑结构。- 有了网络拓扑结构,NCCL 会进一步搜索当前网络中最佳的 RING、TREE、COLLNET 图结构。
- 有了设备之间的图结构信息,就可以在存在通路的设备之间建立点对点的连接。主要有三种连接方式:p2p,shared memory 以及 network。采用哪种方式取决于这两个节点之间支持怎样的连接方式。
以上就是初始化阶段的所有准备工作。
- 初始化完成后,就可以调用集合通信原语。例如
ncclAllReduce。集合通信函数会被 enqueue 到一个 CUDA stream 上,在 GPU 上异步执行- 接下来在 CPU 上启动 Proxy 线程,作为 GPU 上集合通信 kernel 的代理,与 GPU kernel 协同完成与其他设备之间的数据传输。GPU kernel 负责计算所需传输的数据的地址以及数据量大小,而 Proxy 线程负责完成实际的数据传输。对于采用 p2pTransport 以及 shmTransport 的设备,在建立连接后可以直接传输数据,对于采用 netTransport 的设备,则需要通过 socket 进行数据传输。
ncclGetUniqueId
|
|
ncclInit
ncclInit 首先执行 initEnv,设置环境变量
然后执行 initNet,用来初始化 nccl 所需要的网络,包括两个,一个是 bootstrap 网络,另外一个是数据通信网络,bootstrap 网络主要用于初始化时交换一些简单的信息,比如每个机器的 ip 端口,由于数据量很小,而且主要是在初始化阶段执行一次,因此 bootstrap 使用的是 tcp;而通信网络是用于实际数据的传输,因此会优先使用 rdma(支持 gdr 的话会优先使用 gdr)
|
|
initNet
|
|
对应日志:
|
|
ncclNet_t
ncclNet_t 结构体是一系列的函数指针,比如初始化,发送,接收等;socket,IB 等通信方式都实现了自己的 ncclNet_t,如 ncclNetSocket,ncclNetIb,初始化通信网络的过程就是依次看哪个通信模式可用,然后赋值给全局的 ncclNet
|
|
|
|
bootstrapNetInit
|
|
BootstrapNetInit 就是 bootstrap 网络的初始化,主要就是通过 findInterfaces 遍历机器上所有的网卡信息,通过 prefixList 匹配选择使用哪些网卡,将可用网卡的信息保存下来,将 ifa_name 保存到全局的 bootstrapNetIfNames,ip 地址保存到全局 bootstrapNetIfAddrs,默认除了 docker 和 lo 其他的网卡都可以使用,例如在测试机器上有三张网卡,分别是 xgbe 0,xgbe 1,xgbe 2,那么就会把这三个 ifaname 和对应的 ip 地址保存下来,另外 nccl 提供了环境变量 NCCL_SOCKET_IFNAME 可以用来指定想用的网卡名,例如通过 export NCCL_SOCKET_IFNAME=xgbe 0 来指定使用 xgbe 0,其实就是通过 prefixList 来匹配做到的
|
|
initNetPlugin
首先执行 initNetPlugin,查看是否有 libnccl-net. So,测试环境没有这个 so,所以直接返回。
|
|
initNet
然后通过 initNet 分别尝试使用 IB 网络和 Socket 网络,这里实际执行的是每个 ncclNet_t 结构的 init 函数,对于 IB 网络就是 ncclIbInit
|
|
ncclIbInit
首先执行 ncclNetIb 的 init 函数,就是 ncclIbInit
|
|
首先第三行通过 wrap_ibv_symbols 加载动态库 libibverbs.so,然后获取动态库的各个函数
然后通过 wrap_ibv_fork_init 避免 fork 引起 rdma 网卡读写出错
后面会讲到 ib 网络也会用到 socket 进行带外网络的传输,所以这里也通过 findInterfaces 获取一个可用的网卡保存到 ncclIbIfAddr
然后通过 ibv_get_device_list 获取所有 rdma 设备到 devices 中,遍历 devices 的每个 device,因为每个 HCA 可能有多个物理 port,所以对每个 device 遍历每一个物理 port,获取每个 port 的信息,然后将相关信息保存到全局的 ncclIbDevs 中,比如是哪个 device 的哪个 port,使用的是 IB 还是 ROCE,device 的 pci 路径,maxqp,device 的 name 等,注意这里也有类似 bootstrap 网络 NCCL_SOCKET_IFNAME 的环境变量,叫 NCCL_IB_HCA,可以指定使用哪个 IB HCA
到这里整个初始化的过程就完成了,一句话总结就是获取了当前机器上所有可用的 IB 网卡和普通以太网卡然后保存下来
bootstrapGetUniqueId
然后开始生成 UniqueId,如果不是环境变量设置,实际调用 bootstrapCreateRoot
|
|
bootstrapCreateRoot
|
|
ncclNetHandle_t 也是一个字符数组,然后执行 bootstrapNetListen
bootstrapNetListen
|
|
bootstrapNetGetSocketAddr
首先是通过 bootstrapNetGetSocketAddr 获取一个可用的 ip 地址
|
|
此时 dev 是 0, bootstrapNetIfs 是初始化 bootstrap 网络的时候一共找到了几个可用的网卡,这里就是获取了第 0 个可用的 ip 地址
bootstrapNetNewComm
然后是通过 bootstrapNetNewComm 创建 bootstrapNetComm,bootstrapNetComm 其实就是 fd,bootstrapNetNewComm 其实就是 new 了一个 bootstrapNetComm
|
|
createListenSocket
然后通过 createListenSocket 启动 socker server
|
|
创建监听 fd,ip 由 localaddr 指定,初始端口为 0,bind 时随机找一个可用端口,并通过 getsockname (sockfd, &localAddr->sa, &size)将 ip 端口写回到 localaddr,这里 localaddr 就是 UniqueId。
到这里 UniqueId 也就产生了,其实就是当前机器的 ip 和 port
ncclCommInitRank
rank 0 的机器生成了 ncclUniqueId,并完成了机器的 bootstrap 网络和通信网络的初始化,这节接着看下所有节点间 bootstrap 的连接是如何建立的。
|
|
ncclCommInitRankDev
Rank 0 节点执行 ncclGetUniqueId 生成 ncclUniqueId,通过 mpi 将 Id 广播到所有节点,然后所有节点都会执行 ncclCommInitRank,这里其他节点也会进行初始化 bootstrap 网络和通信网络的操作,然后会执行到 ncclCommInitRankSync
|
|
ncclCommInitRankSync
NcclComm_t 是指向 ncclComm 的指针,ncclComm 是一个大杂烩,包含了通信用到的所有上下文信息,里面的字段等用到的时候再介绍,然后通过 commAlloc 分配 newcom,并且完成初始化,比如当前是哪个卡,对应的 pcie busid 是什么,然后执行 initTransportsRank
|
|
initTransportsRank bootstrap 网络连接建立
|
|
bootstrapInit -> send info to root
|
|
首先看下 commState,即 ncclComm 的 bootstrap,类型为 extState
|
|
其中 extBstrapRingSendComm 是当前节点连接 next 的 socket 连接,extBstrapRingRecvComm 是当前节点和 prev 节点的 socket 连接,extBstrapListenComm 是当前节点的监听 socket,peerBstrapHandles 是所有 rank 的 ip port(对应 extBstrapListenComm),dev 默认为 0,表示用第几个 ip 地址。
然后通过 bootstrapNetListen 创建 extHandleListen 和 extHandleListenRoot 两个 bootstrap comm,如前文所述,bootstrap comm 其实就是保存了 fd,这里创建两个 comm 的原因是 extHandleListen 是 rank 之间实际使用的 bootstrap 连接,extHandleListenRoot 是 rank 0 节点和其他所有 rank 进行通信使用的连接
|
|
BootstrapNetListen 函数上节有介绍过,会获取到第 dev 个当前机器的 ip,然后 listen 获取监听 fd,将 ip port 写到 nethandle,获取到的 bootstrap comm 写到 listencomm
然后将 rank,nrank,extHandleListen 和 extHandleListenRoot 写到 extInfo 里
|
|
NetHandle 为 ncclUniqueId,即 rank 0 的 ip port,然后通过 bootstrapNetConnect 创建 bootstrap send comm,类比 bootstrapNetListen,bootstrapNetConnect 就是建立到 netHandle 的 socket 连接,将 socket 写到 sendComm 里,这里 dev 并没有用到
|
|
然后通过 bootstrapNetSend 将 extInfo 发送出去,即发给 rank0
|
|
其中 socketSend 就是执行 send 接口发送数据
然后通过 bootstrapNetCloseSend 关闭 fd。
Rank 0 收到数据后会做什么工作呢,回顾一下,rank 0 的节执行 ncclGetUniqueId 生成 ncclUniqueId,其中在执行 bootstrapCreateRoot 的最后会启动一个线程执行 bootstrapRoot
bootstrapRoot
|
|
ListenComm 是之前 rank 0 创建的监听 fd,bootstrapNetAccept 是从 listenComm 中获取一个新连接,使用新连接的 fd 创建 recvcomm。
|
|
然后通过 bootstrapNetRecv 读取 tmpComm 的数据,即其他 rank 发送来的 extInfo,然后保存其他 rank 的 extHandleListen 和 extHandleListenRoot,这个时候 rank 0 就获取到其他所有 rank 的 ip 和 port 了。
获取完所有 rank 的 info 之后开始建环,将节点 (r+1) % nranks 的 extHandleListen 发送给节点 r,就是说将节点 r 的 next 节点的 nethandle 发送给节点 r。这里可以看出,每个节点创建了两个 listen comm,其中 rank 0 使用 extHandleListenRoot 进行通信,其他节点之间通过 extHandleListen 进行通信
bootstrapInit -> get next rank info from root
|
|
接着所有 rank 都会在 extHandleListenRoot 上接收新连接创建 tmpRecvComm,然后接收到当前 rank 的 next 的 ip,port;然后连接 next 创建 bscomm 到 state->extBstrapRingSendComm,接收 prev 的连接创建 bscomm 到 state->extBstrapRingRecvComm,到现在 bootstrap 网络连接就完全建立起来了,如下图
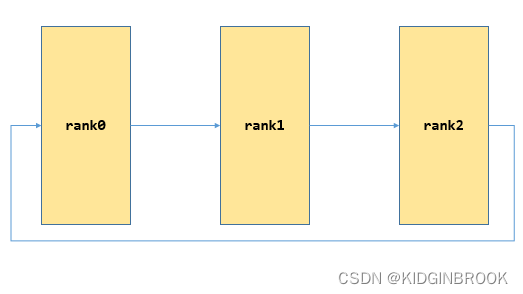
最后 gather 所有 rank 的 ip port,首先将自己的 nethandle 放到 peerBstrapHandles 的对应位置,如下所示
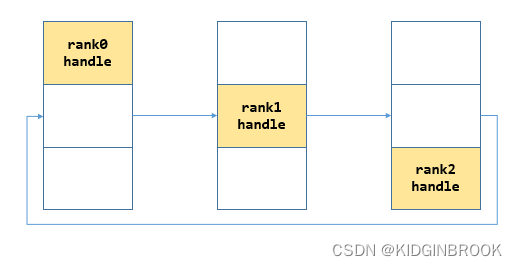
bootstrapAllGather
然后执行 bootstrapAllGather
|
|
第一步:

第二步:

到这里每个 rank 就都有了全局所有 rank 的 ip port。
最后总结一下,本节主要创建了 bootstrap 环形网络连接,并保存到 ncclComm 里。
initTransportsRank bootstrap 机器内拓扑分析
|
|
创建 nrank 个 allGather1Data,然后通过 fillInfo 填充当前 rank 的 peerInfo,ncclPeerInfo 是 rank 的一些基本信息,比如 rank 号,在哪个机器的哪个进程等。
|
|
initTransportsRank 建图过程
暂时省略
initTransportsRank 路径计算
暂时省略
|
|
InitTransportsRank channel 搜索
nccl 中 channel 的概念表示一个通信路径,为了更好的利用带宽和网卡,以及同一块数据可以通过多个 channel 并发通信,另外后续可以看到一个 channel 对应了一个 GPU SM,所以基于这些原因,nccl 会使用多 channel,搜索的过程就是搜索出来一组 channel。
|
|
ncclTopoSearchInit
ncclTopoSearchInit 就是初始化 system->maxWidth,如果是单机单卡的情况,那么 maxWidth 设置为 LOC_WIDTH,否则就遍历每个 GPU 节点,查看到其他所有 GPU 节点或者网卡最大带宽。
|
|
Nccl 执行集合通信时支持 ring,tree 和 collnet 三种算法,这里我们以 ring 来举例,后续专门介绍 ring 和 tree
|
|
NcclTopoGraph 记录了搜索到的结果,具体含义见注释。
ncclTopoCompute
然后看下 ncclTopoCompute,这里就是实际搜索 channel 的过程,目标是搜索出来尽可能多,带宽尽可能大的一系列 channel,本质就是暴力搜索,先设置一系列的条件搜答案,如果搜不出来则降低条件继续搜。
由于此时没有 NET 节点,所以 crossNic 为 0,然后初始化 graph,首先设置最高的条件,限制节点内部只能使用不超过 PATH_NVL 路径,节点间只能使用不超过 PATH_PIX 的路径,然后通过 system-maxWidth 设置 speedIntra 和 speedInter,接着执行 ncclTopoSearchRec 搜索出一个答案存储到 tmpGraph 中。
暂时省略。
initTransportsRank 机器间 channels 连接
上节中完成了单机内部的 channel 搜索,仍然以 ringGraph 为例的话,相当于在单台机器内部搜索出来了一系列的环,接下来需要将机器之间的环连接起来。
为了方便理解假设两机十六卡的情况下第一台机器的一个 ring 为:
|
|
第二个机器对应的 ring 为:
|
|
AllGather3 Data 用于 rank 间聚合 channel 的信息,ncclGraphInfo 记录了环的信息,比如 speed 和 type
|
|
ncclTopoPreset
然后开始设置 ncclTopoRanks,获取当前 rank 在 ring 中的 prev 和 next,其中第一个 rank 的 prev 和最后一个 rank 的 next 为-1,如 rank 6 的 prev 为 7,next 为 3;获取当前 ring 的 ringRecv 和 ringSend,即 ring 的第一个节点和最后一个节点,最后将搜索到的环复制了一遍,这里在官方 issue 中看到相关解释是为了进一步的并行以充分利用带宽。
|
|
然后通过 bootstrapAllGather 获取全局的 allGather 3 Data 信息,计算出当前 rank 所在的 node 保存在 comm->node,以及每个 node 的第一个 rank 保存在 nodesFirstRank,因此例子中:
|
|
ncclTopoPostset
然后开始将每个机器的环首尾相连组成大环。
|
|
connectRings
这里将所有 channel 的 prev,next,send,recv 信息打平到数组中,例如 recv[0]表示第一个 ring 中 rank0的 recv 是哪个 rank,然后开始计算当前机器第一个 rank 的 prev 和最后一个 rank 的 next。
|
|
如上所示,当前机器 recv rank 的 prev 就是前一个机器的 send rank,当前机器 send rank 的 next 就是下一个机器的 recv rank
ncclBuildRings
然后执行 ncclBuildRings 按照大环的顺序依次记录 rank 到 rings。
|
|
还是以上述为例,其中 rank 6 记录的 rings 的第一个大环为:
|
|
到这里就完成了机器之间大环建立,每个 rank 都知道自己的上一个和下一个 rank 是谁,那么就可以建立实际的通信链路了。
打印日志信息如下:
|
|
initTransportsRank 设置亲和性和日志
Log format:
|
|
比如下面的日志可以解读为
|
|
tensorflow-mnist-worker-0 中上的设备 3,其 rank 为 3,有两颗树,分别为 channel 0 和 channel 1:
- Channel 0 上的子节点只有 1,父节点为 4
- Channel 1 上的子节点只有 1,父节点为 4
|
|
接下来每个 rank 都要为通信分配一些内存,为了提高性能,这里会在分配 buffer 之前设置 cpu 亲和性,使得分配的内存尽量是当前 numa 本地的。
对应代码
|
|
完整的一个两机器十六卡的 channel 信息如下
|
|
ncclTransportP2pSetup 数据通信链路 transport 的建立
|
|
- 接收端执行 recv setup,创建 buffer 等,将相关信息记录到 connectIndo,启动一个监听 socket,ip port 同样记录到 connectInfo,通过 bootstrap 发送 connectInfo 到发送端。
- 发送端执行 send setup,创建 buffer 等,将相关信息记录到 connectInfo,然后发送给接收端。这一步 rdma 场景没有用到 connectInfo。
- 发送端接受到步骤 1 中接收端的信息,然后建立发送端到接收端的链接,p 2 p 场景的话只是简单记录对端 buffer,rdma 场景的话需要初始化 qp 到 INIT 状态。
- 接收端接受到步骤 2 中 send 发送的信息,然后建立接收端到发送端的链接,p 2 p 场景还是记录对端 buffer,rdma 场景需要初始化 qp 到 RTS 状态,将本端的 qp 信息发送回对端。
- 如果 rdma 场景的话,发送端还需接收对端的 qp 状态初始化本端的 qp 到 RTS 状态。
Channel log 格式
|
|
比如下面的日志表示 tensorflow-mnist-worker-0 上的设备 6 (rank 为 15,busID 为 b2000 其 channel 0 连接到 rank 6,传输方式为 NET/IB/0/GDRDMA
|
|
ncclTransport
ncclConnector 的 ncclTransportComm 定义了一系列的通信相关的函数指针,用户可以自己实现这些接口,ncclTransport 定义了 send 和 recv 两个 ncclTransportComm,本节会介绍下 P2P 和 NET 两个 ncclTransport。
|
|
Nccl 现共有三个 transport:
P2P通过卡间 P2P 通信- SHM 通过机器内共享的 host 内存通信
- NET 通过网络通信
selectTransport
Nccl 会依次通过这三个 transport 的 canConnect 判断是否可用,然后选择第一个可用的,由于 rank 1 不在当前机器,因此只有 NET 的 recv 可用,设置 connector 的 transportComm 为 netTransport 的 recv。
|
|
接收端 setup
|
|
根据 selectTransport 可以看到,这里 type = 0,表示是接收端,执行 netRecvSetup
netRecvSetup
|
|
首先分配 netRecvResources 赋给 ncclConnector,主要字段含义见注释,其中 LOC_CONUT 为 2,表示有两个 buffer,如果支持 gdr,那么会使用第 LOC_DEVMEM(1)个 buffer,即显存,如果不支持 gdr,那么会使用第 LOC_HOSTMEM(0)个 buffer,即锁页内存;sendMem,recvMem 记录了 fifo 的 head 和 tail,用来协调生产者消费者,这个下节具体介绍,本节可忽略;用户执行的通信操作比如 ncclSend 一块数据,nccl 会将这块数据分成多个小块流水线发送,step 表示第几个小块,这个也在下节具体介绍。
|
|
ncclTopoGetNetDev
ncclTopoGetNetDev为当前rank的gpu选择网卡,我们在搜索channel的时候将环对应的网卡记录在了graph->inter里,所以这里通过inter就可以找到对应网卡 。
|
|
ncclTopoCheckGdr
ncclTopoCheckGdr检查选择的网卡和当前rank的gpu是否支持gdr,具体逻辑在第五节中介绍过,这里不再赘述。然后为sendMem和recvMem分配锁页内存,设置head和tail;测试机器支持gdr,所以protoLoc均为LOC_DEVMEM,即显存,然后分配三个协议所需的buffer,三个协议的buffer连续存储,通过offset记录各自的起始地址,offset保存到conn。mhandles即rdma用的mr,mhandlesProtoc指向mhandles。
ncclIbListen
由于基于socket的建链方式需要通过socket交换发送端和接收端的信息,比如qp number,port,mtu,gid或者lid等,所以这里通过ncclIbListen创建了监听socket,过程类似bootstrap,fd写到listenComm,ip port写到handle,即connectInfo。
|
|
到这里就 recv 就初始化完成了。
bootstrapSend
然后回到 ncclTransportP2pSetup,通过 bootstrapSend 将 connectInfo 发送到了 peer,即 rank 1,connectInfo 就是上述的 ip port。
|
|
发送端 setup
当 rank 1执行这个函数的时候,会遍历 nsend,此时 rank 1的 peer 就是 rank 10,然后执行 selectTransport,就会执行 netTransport 的 send 的 setup,即 netSendSetup,这个逻辑和 netRecvSetup 基本一致,主要还是分配各种 buffer,不再赘述。接着看下边逻辑。
|
|
netSendSetup
|
|
bootstrapRecv
然后 rank 1通过 bootstrapRecv 收到了 rank 10发送来的 ip 和 port
netSendConnect
|
|
然后执行 connect,即 netSendConnect
|
|
这里的 info 就是 rank 10的 ip,port,然后执行 ncclNetConnect,即 ncclIbConnect,这里主要就是创建 qp 并将相关信息通过 socket 发送到接收端。
ncclNetConnect
这里调用了 ncclNetConnect,实际上对于 IB 就是 ncclIbConnect
|
|
看下ncclIbConnect创建qp的过程,先看下下边两个会用到的api
|
|
ncclIbInitVerbs 创建 pd 和 cq,ncclIbVerbs 保存了 pd 和 cq
|
|
NcclIbCreateQp 用于创建和初始化 qp,设置 send 和 recv 使用的完成队列,设置 qp_type 为 rc,设置 send 和 recv 的最大 wr 个数,以及每个 wr 里最多有多少个 sge,然后创建 qp,此时这个 qp 处于 RST 状态,还无法做任何事情;然后设置 qp_state 为 init,然后设置 port 和 access_flag 为 IBV_ACCESS_REMOTE_WRITE,表示 qp 可以接受远端的写,然后修改 qp 状态,此时 qp 就处于 INIT 状态了,此时 qp 可以下发 recv wr,但是接收到的消息不会被处理。
然后再来看 ncclIbConnect,ncclIbMalloc 分配的是页对齐的内存,包括后边可以看到 nccl 在注册内存的时候都进行了页对齐,但 ibv_reg_mr 并不要求内存为页对齐的。
QP 初始化好之后就准备通过 socket 交换发送端和接收端的信息,获取 port 相关信息,将 port,mtu,qpn 赋值给 qpInfo,然后判断使用的是 ib 还是 roce,roce 里 lid 为 0,只能用 gid 进行通信,而 ib 可以使用 lid 进行通信,最后通过 socket 将 qpInfo 发送到接收端,即 rank 10。
ncclNetRegMr
再回到 netSendConnect,需要将 setup 过程中分配的数据 buffer 进行注册,即 ncclIbRegMr,这里进行了页对齐,mr 写到了 resource 的 mhandle 里。
|
|
netRecvConnect
然后再回到 ncclTransportP2pSetup,rank 1 执行了 connect,将 qp 相关信息通过 socket 发送给了 rank 10,这时候 rank 10 接着执行下边的 connect,即 netRecvConnect。另外在 rdma 场景下这里通过 bootstrap 收到的 ncclConnect 没有用到。
|
|
进入到 netRecvConnect
|
|
ncclNetAccept
Rank 10 会执行 ncclIbAccept,通过 socket 收到了 rank 1 的 qp 信息,然后通过 net dev 获取对应网卡的 context 和 port,和上述过程一样通过 ncclIbInitVerbs 创建 pd 和 cq,通过 ncclIbCreateQp 创建 qp,然后根据 rank 1调整 mtu
|
|
ncclIbRtrQp
然后执行 ncclIbRtrQp,将 qp 从 INIT 状态转到 RTR 状态,设置 mtu,对端的 qpn,gid 和 port 等信息,这个时候 qp 可以下发 recv 消息并正常 接收了
|
|
ncclIbRtsQp
然后执行,此时 qp 从状态 RTR 转为状态 RTS,此时 qp 可以下发 send 消息正常发送了。
|
|
Transfer fifo info
然后继续看 ncclIbAccept,这里 fifo 也是用来控制发送过程的,后边介绍数据通信再写。
|
|
GpuFlush 也对应一个 qp,不过这个 qp 是 local 的,即他的对端 qp 就是自己,当开启 gdr 之后,每次接收数据后都需要执行一下 flush,其实是一个 rdma read 操作,使用网卡读一下接收到的数据的第一个 int 到 hostMem。官方 issue 里解释说当通过 gdr 接收数据完成,产生 wc 到 cpu 的时候,接收的数据并不一定在 gpu 端可以读到,这个时候需要在 cpu 端执行以下读取。
|
|
最后将 rank 10 的 port,qpn,gid 等通过 socket 发送回 rank 1,到这里 ncclTransportP 2 pSetup 就执行完成了,但是此时 rdma 还没有完成建立连接,因为 rank 1 还没有拿到 rank 10 的信息,qp 还处于 INIT 状态。Rank 1 直到开始发送数据的时候才会去检查是否完成最后一步建链,如果还没有建链那么执行 ncclSendCheck,过程和上述一致,不再赘述。
|
|
到这里 rank 1 和 rank 10 的 rdma 链接就建立完成了,然后我们再看下 rank 10 和 rank 9的 p2p 链接。
ncclNetRegMr
跟上面一样
节点内 P2P 建连
上面主要讲了跨界点通过 IB 实现建连,这部分主要讲解本节点内建立连接,原理基本一致,只是从 IB 换成了 P2P。我们以 rank 10和 rank 9的 p2p 连接为例。
p2p 场景 rank 之间交换的 connectInfo 如下所示
|
|
仍然按照刚刚的顺序,rank 9先执行 recv 的 setup,首先分配 resource,数据通信 buffer 会保存在 ncclRecvMem 的 buff 字段。
|
|
然后判断 useRead,如果两个 rank 之间的路径类型小于 p2pLevel(默认是 PATH_SYS),那么 useP2P 为 1,如果路径类型为 PATH_NVL 并且为安培架构,那么 useRead 为 1,ncclRecvMem 使用柔性数组存储 buffer,还是只关注 NCCL_PROTO_SIMPLE,如果 read 为 1 那么不需要分配 buffer,由于当前场景为单进程,所以记录 direct 为 1,devMem 记录到 direcPtr,然后通过 cudaDeviceEnablePeerAccess 开启卡间 p2p 访问。
p2pRecvSetup
|
|
p2pSendSetup
接下来 rank 10会执行 send 的 setup,大体逻辑一致,从这里我们可以看出 useRead 的作用,如果 useRead 为1,那么 buffer 放在 send rank,如果为0,则放在 recv rank。
|
|
p2pSendConnect
然后 rank 10 执行 send connect 过程,Info 为 rank 9 的信息,remDevMem 就是刚刚 rank 9 分配的显存,如果 read 为 0,则需要设置 conn 的 direct,接下来设置 conn 的 buff,如果 read 为 1,buff 为当前卡,否则设置为 rank 9 的显存,接下来设置的 head,tail 用来协调发送端和接收端,下节详细介绍。
|
|
p2pRecvConnect
对于 recv connect 逻辑基本一致
|
|
建连日志
|
|
ncclAllReduce
在完成设备的 Communicator 初始化后,就可以调用集合通信的相关原语。在这里我们以 Allreduce 为例,分析集合通信原语的实现逻辑。
|
|
可以看到,调用 ncclAllReduce 时,所有的变量被存到一个 ncclInfo 结构体中,然后通过 ncclEnqueueCheck 将这个结构体插入到队列中。
ncclEnqueueCheck
|
|
ncclPrimitives
ncclPrimitives 这个类实现了各类通信原语。
|
|
GenericOp
比较巧妙的设计是,通过设计一个 GenericOp,改变其 6 个 input 的值就能使用相同的代码实现多种不同的功能。
|
|
在 GenericOp 中,调用 send 和 recv 之类的操作时,会修改ncclConnInfo 这个结构体中的void* *ptrsFifo; 以及int *sizesFifo; 这两个数据结构,这两个结构中存储着要传输的数据地址以及对应的数据大小。在 netTransport 的 proxy 相关的函数中,会检查这个队列,进行传输。
比如在 ncclPrimitives 中有如下方法,send 的模板参数为
- DIRECTRECV 为 0
- DIRECTSEND 为 0
- RECV 为 0
- SEND 为 1
- SRC 为 1
- DST 为 0
|
|
proxy 线程
数据传输过程其实是 GPU 上的 NCCL kernel 跟 CPU 上的 Proxy 线程协同完成的。
Proxy 线程中与数据传输有关的三个函数是
-
ncclNetIrecv:Proxy 从网络收到数据 -
ncclNetIsend:Proxy 发送数据到网络 -
ncclNetIflush: Proxy 将数据从 CPU 传到 GPU -
数据怎样从一个 GPU 传输到同一个节点的另一个 GPU?
- Peer-to-peer, PCI+host memory
-
数据怎样从一个 GPU 传输到另一个节点的 GPU?
- Socket, InfiniBand
netSendProxy
|
|
netRecvProxy
|
|
persistentThread
可以看到 proxy 执行逻辑 persistentThread 是一个 while 循环,会循环检查队列中有无 op。op->progress 则是每个 op 对应的 proxy 操作。
|
|
SaveProxy
那么这些 op 是怎么入队的呢,具体的就是在 SaveProxy 中处理的。而 SaveProxy 则是通过的调用路径
|
|
可以看到这里的 op->progress 就具体的和 connector->transportComm->proxy 关联上了。如果 transport 为 netTransport,则 proxy 则是对应的 netSendProxy 和 netRecvProxy。
|
|
当 netTransport 使用 IB 作为 backend 时,则会调用到通过下面三个函数真正调用到 RDMA IB 接口。
ncclNetIrecv:Proxy 从网络收到数据ncclNetIsend:Proxy 发送数据到网络ncclNetIflush: Proxy 将数据从 CPU 传到 GPU
ncclIbIsend
实际是通过 RC 连接中 RDMA_REMOTE_WRITE 的单边操作来实现的。
|
|
参考资料
-
No backlinks found.