Kubelet
Kubelet 作为 k8s 集群中 Node 上的关键组件,在每个 Node 上以 Agent 进程的形式运行,负责管理 Pod 和其中容器的生命周期。Kubelet 主要功能是定时从某个地方获取节点上 Pod/container 的期望状态,并调用容器平台接口达到这个状态。本文将作为 Kubelet 分析的开篇,介绍 Kubelet 的主要功能和实现原理。
Overview
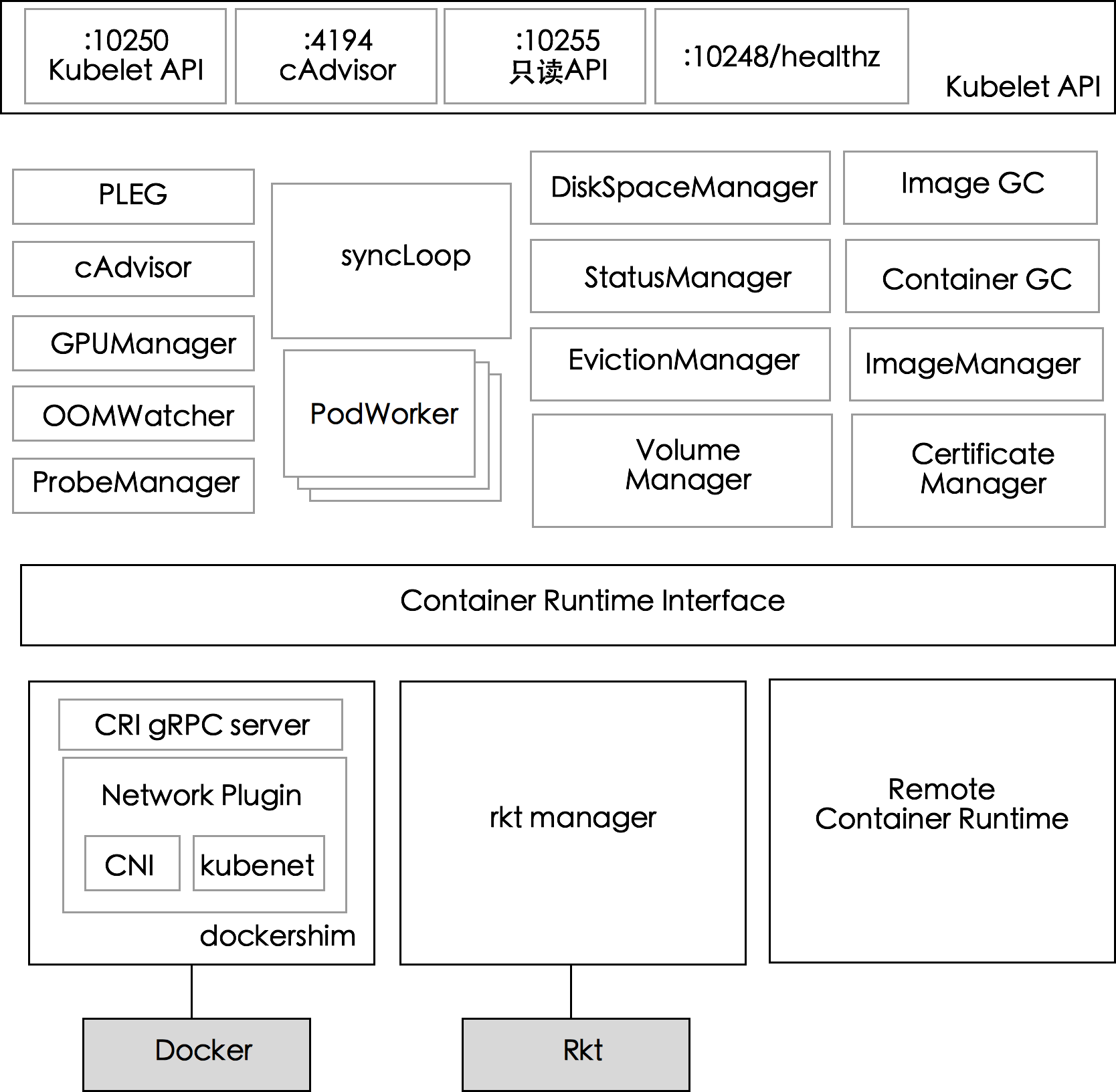
下图展示了 kubelet 内部组件结构,Kubelet 由许多内部组件构成
- Kubelet API,包括 10250 端口的认证 API、4194 端口的 cAdvisor API、10255 端口的只读 API 以及 10248 端口的健康检查 API
- syncLoop:从 API 或者 manifest 目录接收 Pod 更新,发送到 PodWorkers 处理,大量使用 channel 处理来处理异步请求
- 辅助的 manager,如 cAdvisor、kubelet-pleg、Volume Manager 等,处理 syncLoop 以外的其他工作
- CRI:容器执行引擎接口,负责与 container runtime shim 通信,关于 CRI 的更多内容可以参考 CRI
- 容器执行引擎,如 dockershim、rkt 等
- 网络插件,目前支持 CNI 和 kubenet
Source
Kubelet 基于 PodSpec 来工作,它需要确保这些 PodSpec 中描述的容器处于运行状态且运行状况良好,因此 Kubelet 不管理那些不是由 k8s 创建的容器。PodSpec 的来源有以下四种:
API Server:通过 API Server 监听 etcd 目录获取数据,这也是最主要的来源File:利用命令行参数传递路径,kubelet 周期性地监视此路径下的文件是否有更新,监视周期默认为 20sHTTP Endpoint:利用命令行参数指定 HTTP 端点。 此端点的监视周期默认为 20 秒HTTP Server:kubelet 还可以侦听 HTTP 并响应简单的 API (目前没有完整规范)来提交新的清单
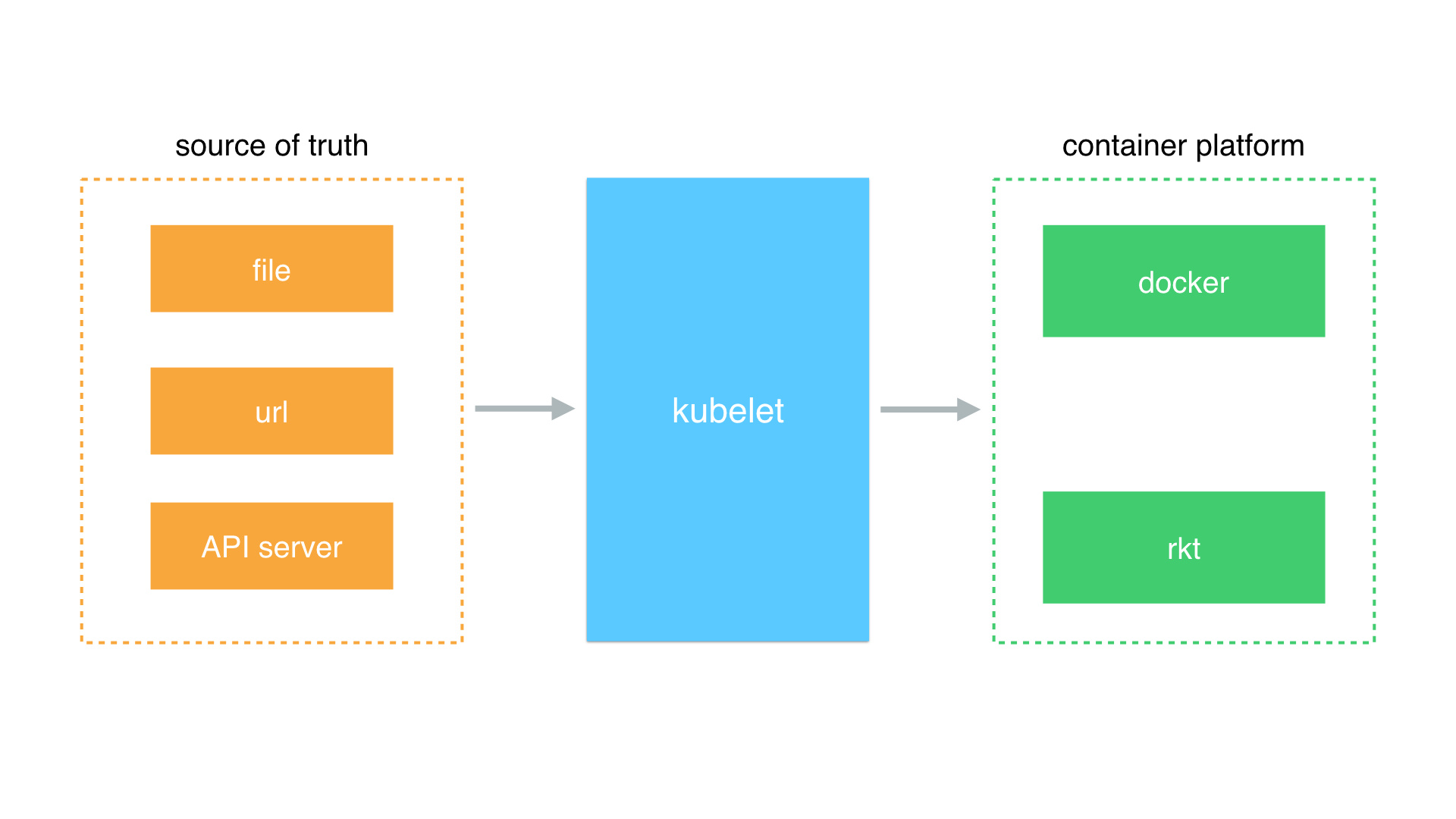
所有以非 API Server 方式创建的 Pod 都叫 Static Pod。Kubelet 将 Static Pod 的状态汇报给 API Server,API Server 为该 Static Pod 创建一个 Mirror Pod 和其相匹配。Mirror Pod 的状态将真实反映 Static Pod 的状态。当 Static Pod 被删除时,与之相对应的 Mirror Pod 也会被删除。
监听 API Server
Kubelet 通过 API Server Client 使用 List/Watch 的方式监听 /registry/Nodes/<NodeName> 和 /registry/Pods 路径,将获取的信息同步到本地缓存中。Kubelet 监听 etcd,所有针对 Pod 的操作都将会被 Kubelet 监听到:
- 如果发现有新的绑定到本节点的 Pod,则按照 PodSpec 的要求创建该 Pod。
- 如果发现本地的 Pod 被修改,则 Kubelet 会做出相应的修改,比如删除 Pod 中某个容器时,则通过 ContainerRuntime Client 删除该容器。
- 如果发现删除本节点的 Pod,则删除相应的 Pod,并通过 ContainerRuntime Client 删除 Pod 中的容器。
Kubelet 读取监听到的信息,如果是创建和修改 Pod 任务,则执行如下处理:
- 为该 Pod 创建一个数据目录
- 从 API Server 读取该 PodSpec
- 为该 Pod 挂载外部卷
- 下载 Pod 用到的 Secret
- 检查已经在节点上运行的 Pod,如果该 Pod 没有容器或 Pause 容器没有启动,则先停止 Pod 里所有容器的进程。如果在 Pod 中有需要删除的容器,则删除这些容器
- 用
kubernetes/pause镜像为每个 Pod 创建一个容器。Pause 容器用于接管 Pod 中所有其他容器的网络。每创建一个新的 Pod,Kubelet 都会先创建一个 Pause 容器,然后创建其他容器。 - 为 Pod 中的每个容器做如下处理:
- 为容器计算一个 hash 值,然后用容器的名字去 ContainerRuntime 查询对应容器的 hash 值。若查找到容器,且两者 hash 值不同,则停止 Docker 中容器的进程,并停止与之关联的 Pause 容器的进程;若两者相同,则不做任何处理;
- 如果容器被终止了,且容器没有指定的 restartPolicy,则不做任何处理;
- 调用 ContainerRuntime Client 下载容器镜像,调用 ContainerRuntime Client 运行容器。
SyncLoop 工作原理
Kubelet 的工作核心是 SyncLoop 这个控制循环,驱动整个控制循环的事件包括:
kubetypes.PodUpdate:Pod更新事件pleg.PodLifeEvent:Pod生命周期变化periodic sync events:kubelet本身设置的执行周期housekeeping events:定时清理事件
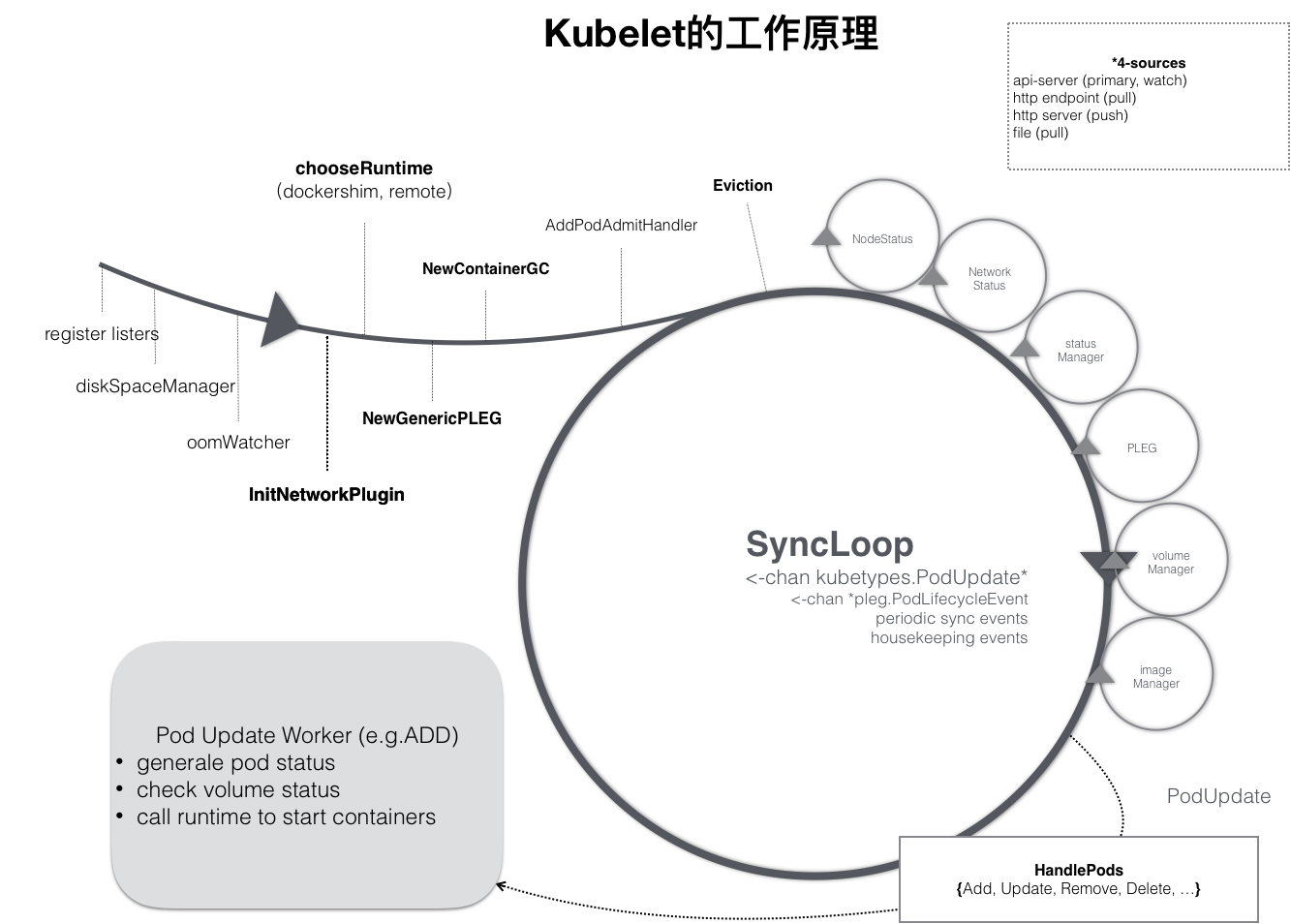
在 SyncLoop 循环上有很多 Manager:
kubelet-pleg
即 Pod Lifecycle Event Generator ,字面意思 Pod 生命周期事件生成器,是 kubelet 的核心模块。PLEG 会一直调用 ContainerRuntime 获取本节点 containers/sandboxes 的信息,并与自身维护的 Pods cache 信息进行对比,生成对应的 PodLifecycleEvent,然后输出到 eventChannel 中,通过 eventChannel 发送到 kubelet syncLoop 进行消费,然后由 kubelet syncPod 来触发 Pod 同步处理过程,最终达到用户的期望状态。
Pod Lifecycle Event:
ContainerStartedContainerDiedContainerRemovedContainerChanged
PodWorkers
处理事件中 Pod 的同步。核心方法 managePodLoop() 间接调用 kubelet.syncPod() 完成 Pod 的同步:
- 如果 Pod 正在被创建,记录其延迟
- 生成 Pod 的 API Status,即
v1.PodStatus:从运行时的 status 转换成 api status - 记录 Pod 从
pending到running的耗时 - 在
StatusManager中更新 Pod 的状态 - 杀掉不应该运行的 Pod
- 如果网络插件未就绪,只启动使用了主机网络(host network)的 Pod
- 如果 static Pod 不存在,为其创建镜像(Mirror)Pod
- 为 Pod 创建文件系统目录:Pod 目录、卷目录、插件目录
- 使用
VolumeManager为 Pod 挂载卷 - 获取 image pull secrets
- 调用容器运行时(container runtime)的
#SyncPod()方法
PodManager
提供了接口来存储和访问 Pod 的信息,维持 static Pod 和 mirror Pods 的关系,PodManager 会被 statusManager/volumeManager/runtimeManager 所调用,PodManager 的接口处理流程里面会调用 secretManager 以及 configMapManager
ContainerManager
负责 Node 节点上运行的容器的 cgroup 配置信息,kubelet 启动参数如果指定 --cgroups-per-qos 的时候,kubelet 会启动 goroutine 来周期性的更新 Pod 的 cgroup 信息,维护其正确性,该参数默认为 true,实现了 Pod 的Guaranteed/BestEffort/Burstable 三种级别的 Qos。
StatusManager
负责维护状态信息,并把 Pod 状态更新到 apiserver,但是它并不负责监控 Pod 状态的变化,而是提供对应的接口供其他组件调用,比如 probeManager
StatsProvider
提供节点和容器的统计信息,有 cAdvisor 和 CRI 两种实现。
ContainerRuntime
ContainerRuntime 负责 kubelet 与遵循 CRI 规范的不同 runtime 实现进行对接,实现对于底层 container 的操作,初始化之后得到的 runtime 实例将会被之前描述的组件所使用。
containerGC:负责清理 Node 节点上已消亡的 Container,具体的 GC 操作由 runtime 来实现
Deps.PodConfig
PodConfig 是一个配置多路复用器,它将许多 Pod 配置源合并成一个单一的一致结构,然后按顺序向监听器传递增量变更通知。
配置源有:文件、apiserver、HTTP
PodAdmitHandlers
Pod admission 过程中调用的一系列处理器,比如 eviction handler(节点内存有压力时,不会驱逐 QoS 设置为 BestEffort 的 Pod)、shutdown admit handler(当节点关闭时,不处理 Pod 的同步操作)等。
OOMWatcher
系统 OOM 的监听器,会与 cadvisor 模块之间建立 SystemOOM,通过 Watch 方式从 cadvisor 那里收到的 OOM 信号,并产生相关事件。
CertificateManager
处理证书轮换。
ProbeManager
依赖于 statusManager,livenessManager,containerRefManager,会定时去监控 Pod 中容器的健康状况。
容器健康检查通过 LivenessProbe 与 ReadinessProbe 两类探针来判断容器是否健康。
- LivenessProbe :用于判断容器是否健康,告诉 Kubelet 一个容器什么时候处于不健康的状态。如果 LivenessProbe 探针探测到容器不健康,则 Kubelet 将删除该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含 LivenessProbe 探针,那么 Kubelet 认为该容器的 LivenessProbe 探针返回的值永远是 Success;
- ReadinessProbe:用于判断容器是否启动完成且准备接收请求。如果 ReadinessProbe 探针探测到失败,则 Pod 的状态将被修改。Endpoint Controller 将从 Service 的 Endpoint 中删除包含该容器所在 Pod 的 IP 地址的 Endpoint 条目。
Kubelet 定期调用容器中的 LivenessProbe 探针来诊断容器的健康状况。LivenessProbe 包含如下三种实现方式:
- ExecAction:在容器内部执行一个命令,如果该命令的退出状态码为 0,则表明容器健康;
- TCPSocketAction:通过容器的 IP 地址和端口号执行 TCP 检查,如果端口能被访问,则表明容器健康;
- HTTPGetAction:通过容器的 IP 地址和端口号及路径调用 HTTP GET 方法,如果响应的状态码大于等于 200 且小于 400,则认为容器状态健康。
EvictionManager
Kubelet 会监控资源的使用情况,并使用驱逐机制防止计算和存储资源耗尽。当节点的内存、磁盘或 iNode 等资源不足时,达到了配置的 evict 策略, Node 会变为 pressure 状态,此时 kubelet 会按照 qosClass 顺序来驱赶 Pod,以此来保证节点的稳定性。
在驱逐时,Kubelet 将 Pod 的所有容器停止,并将 PodPhase 设置为 Failed。Kubelet 定期(housekeeping-interval)检查系统的资源是否达到了预先配置的驱逐阈值,包括
| Eviction Signal | Condition | Description |
|---|---|---|
memory.available |
MemoryPressue | memory.available := Node.status.capacity[memory] - Node.stats.memory.workingSet (计算方法参考这里) |
Nodefs.available |
DiskPressure | Nodefs.available := Node.stats.fs.available(Kubelet Volume以及日志等) |
Nodefs.iNodesFree |
DiskPressure | Nodefs.iNodesFree := Node.stats.fs.iNodesFree |
imagefs.available |
DiskPressure | imagefs.available := Node.stats.runtime.imagefs.available(镜像以及容器可写层等) |
imagefs.iNodesFree |
DiskPressure | imagefs.iNodesFree := Node.stats.runtime.imagefs.iNodesFree |
这些驱逐阈值可以使用百分比,也可以使用绝对值,如
|
|
ImageManager
调用 kubecontainer 提供的 PullImage/GetImageRef/ListImages/RemoveImage/ImageStates 方法来保证Pod 运行所需要的镜像。
imageGC: 负责 Node 节点的镜像回收,当本地的存放镜像的本地磁盘空间达到某阈值的时候,会触发镜像的回收,删除掉不被 Pod 所使用的镜像
VolumeManager
负责 Node 节点上 Pod 所使用 Volume 的管理,Volume 与 Pod 的生命周期关联,负责 Pod 创建删除过程中 volume 的 mount/umount/attach/detach 流程,kubernetes 采用 Volume Plugins 的方式,实现存储卷的挂载等操作,内置几十种存储插件。
cAdvisor
Kubernetes 集群中,应用程序的执行情况可以在不同的级别上监测到,这些级别包括:容器、Pod、Service 和整个集群。Kubelet 通过 cAdvisor 获取其所在节点及容器的数据。
cAdvisor 是一个开源的分析容器资源使用率和性能特性的代理工具,集成到 Kubelet中,当Kubelet启动时会同时启动cAdvisor,且一个cAdvisor只监控一个Node节点的信息。cAdvisor 自动查找所有在其所在节点上的容器,自动采集 CPU、内存、文件系统和网络使用的统计信息。cAdvisor 通过它所在节点机的 Root 容器,采集并分析该节点机的全面使用情况。
关于 cAdvisor 更多的内容,可以参考 cAdvisor 。
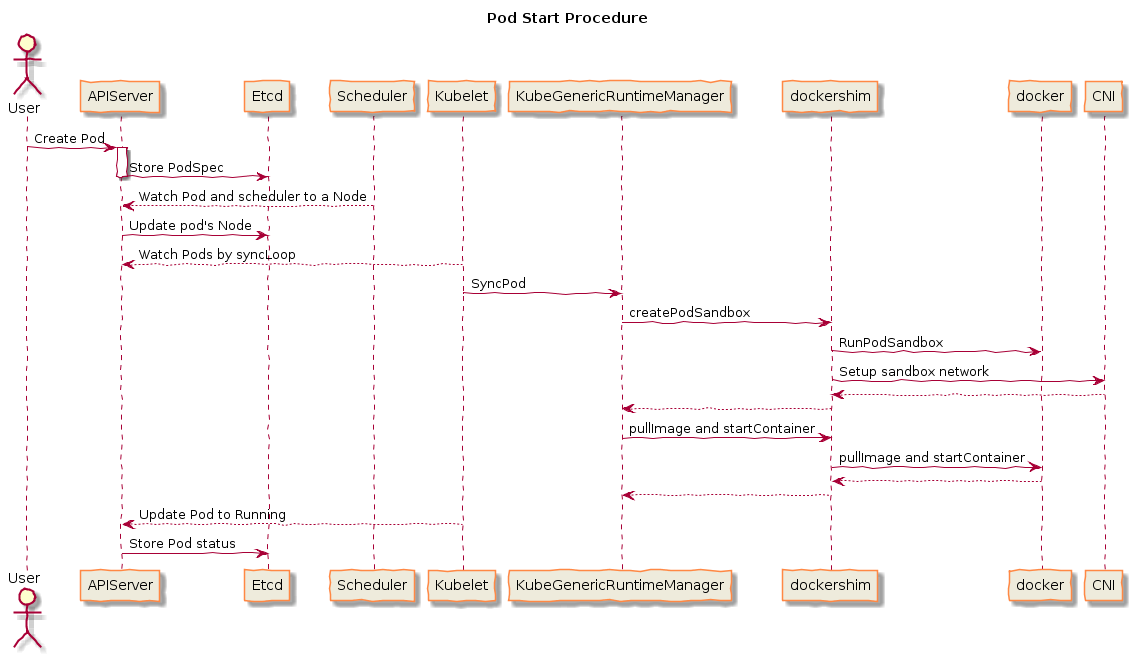
源码分析
bootstrap
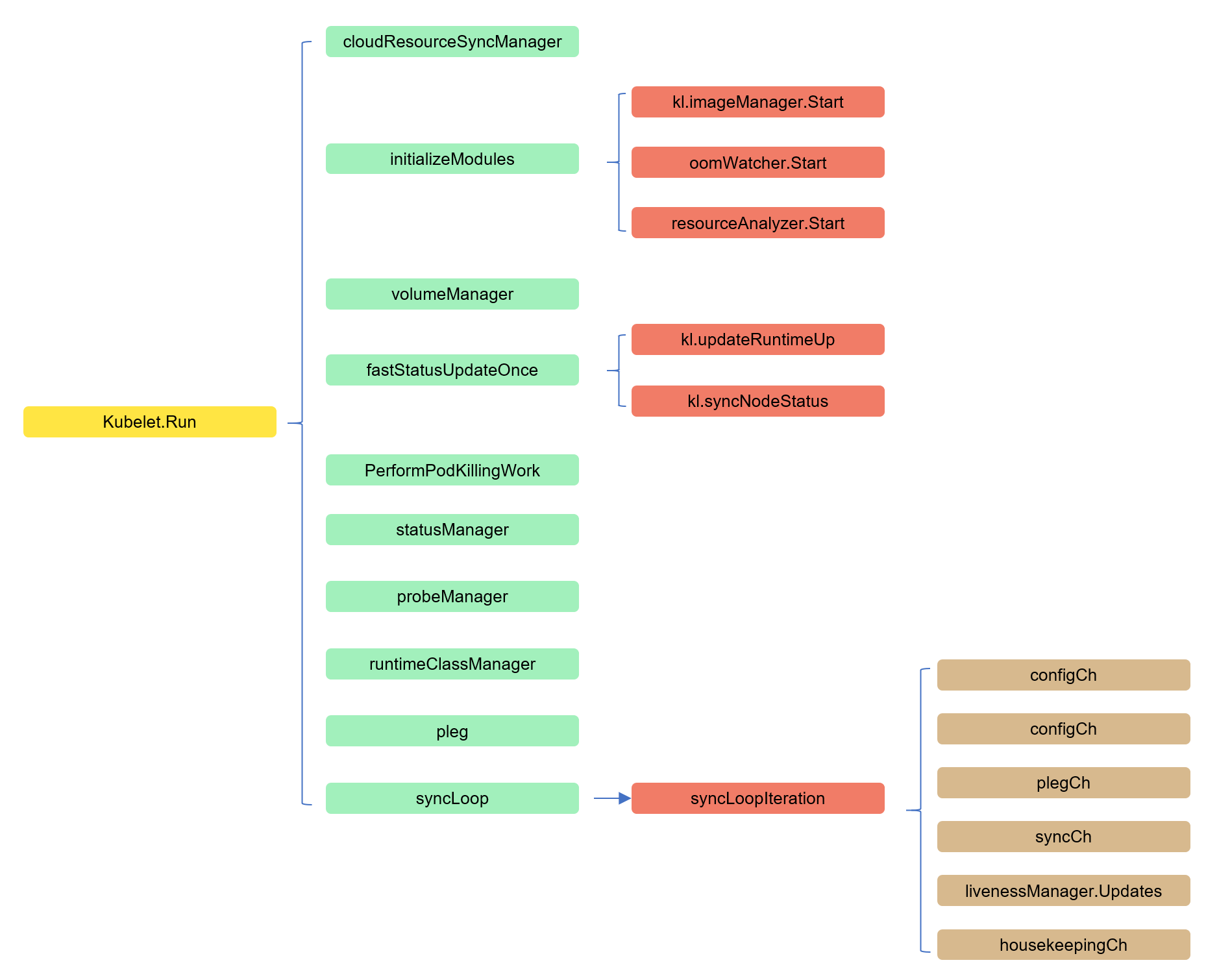
cmd/kubelet/app/server.go 的 Run 方法为程序实际入口:
- 调用
RunKubelet方法。 - 调用
createAndInitKubelet方法,创建并初始化 kubeletpkg/kubelet/kubelet.go的NewMainKubelet方法,创建 kubelet的 各种组件。- 调用
BirthCry方法:放出Starting事件 - 调用
StartGarbageCollection方法,开启ContainerGC和ImageGC
- 调用
startKubelet方法(大量使用 goroutine 和通道)- goroutine:
kubelet.Run() - 初始化模块
- metrics 相关
- 创建文件系统目录目录
- 创建容器日志目录
- 启动
ImageGCManager - 启动
ServerCertificateManager - 启动
OOMWatcher - 启动
ResourceAnalyzer
- goroutine:
volumeManager.Run()开始处理 Pod Volume 的卸载和挂载,保障存储与容器状态一致 - goroutine:
syncNodeStatus()将节点注册到k8s集群,并收集节点信息定期上报到api-server - goroutine:状态更新
fastStatusUpdateOnce()(更新 Pod CIDR -> 更新ContainerRuntime状态 -> 更新 Node 节点状态) - goroutine:
NodeLeaseController.Run()更新节点租约 - goroutine:
PodKiller.PerformPodKillingWork杀掉未被正确处理的 Pod initNetworkUtil()同步 iptables 相关规则StatusManager.Start()开始向 apiserver 更新 Pod 状态RuntimeClassManager.Start()k.pleg.Start():持续从ContainerRuntime获取 Pod/容器的状态,并与 kubelet 本地 cache 中的比较,生成对应的EventsyncLoop()重点, 持续监控并处理来自文件、apiserver、http 的变更 。包括 Pod 的增加、更新、优雅删除、非优雅删除、调和。
- goroutine:
- 启动 server,暴露
/healthz端点 - 通知
systemdkuberlet服务已经启动
syncLoop
syncLoop 是 Kubelet 的核心同步逻辑。该模块将同时 watch 3 个不同来源的 Pod 信息的变化(file,http,apiserver),一旦某个来源的 Pod 信息发生了更新(创建/更新/删除),PodUpdate channel 中就会出现被更新的 Pod 信息和更新的具体操作。
syncLoop 中首先定义了一个 syncTicker 和 housekeepingTicker,即使没有需要更新的 pod 配置,kubelet 也会定时去做同步和清理 pod 的工作。然后在 for 循环中一直调用 syncLoopIteration,如果在每次循环过程中出现比较严重的错误,kubelet 会记录到 runtimeState 中,遇到错误就等待 5 秒中继续循环。
|
|
syncLoop方法在一个循环中不断的调用 syncLoopIteration 方法执行主要逻辑。
syncLoopIteration
syncLoopIteration 这个方法就会对多个管道进行遍历,发现任何一个管道有消息就交给 handler 去处理。它会从以下管道中获取消息:
- configCh:该信息源由 kubeDeps 对象中的 PodConfig 子模块提供,该模块将同时 watch 3 个不同来源的 pod 信息的变化(file,http,apiserver),一旦某个来源的 pod 信息发生了更新(创建/更新/删除),这个 channel 中就会出现被更新的 pod 信息和更新的具体操作。
- syncCh:定时器管道,每隔一秒去同步最新保存的 pod 状态
- houseKeepingCh:housekeeping 事件的管道,做 pod 清理工作
- plegCh:该信息源由 kubelet 对象中的 pleg 子模块提供,该模块主要用于周期性地向 container runtime 查询当前所有容器的状态,如果状态发生变化,则这个 channel 产生事件。
- livenessManager.Updates():健康检查发现某个 pod 不可用,kubelet 将根据 Pod 的 restartPolicy 自动执行正确的操作
- …
|
|
configCh
|
|
configCh 读取配置事件的管道,该模块将同时 watch 3 个不同来源的 Pod 信息的变化(file,http,apiserver),一旦某个来源的 Pod 信息发生了更新(创建/更新/删除),这个 channel 中就会出现被更新的 Pod 信息和更新的具体操作。这里对于Pod的操作我们下一篇再讲。
plegCh
PLEG.Start 的时候会每秒钟启动调用一次relist,根据最新的 PodStatus 生成PodLiftCycleEvent,然后存入到 PLEG Channel 中。
syncLoop 会调用 pleg.Watch 方法获取 PLEG Channel 管道,然后传给 syncLoopIteration 方法,在syncLoopIteration方法中也就是 plegCh 这个管道,syncLoopIteration 会消费 plegCh 中的数据,在 handler 中通过调用 dispatchWork 分发任务。
|
|
syncCh
syncCh 是由 syncLoop 方法里面创建的一个定时任务,每秒钟会向syncCh添加一个数据,然后就会执行到这里。这个方法会同步所有等待同步的Pod。
|
|
对失败的Pod或者liveness检查失败的Pod进行sync操作。
housekeepingCh
housekeepingCh 这个管道也是由 syncLoop 创建,每两秒钟会触发清理。
|
|
livenessManager.Updates
|
|
readinessManager.Updates
|
|
syncHandler
kl.syncLoop 接受两个参数,第一个是 <-chan kubetypes.PodUpdate,第二个是 SyncHandler,SyncHandler 定义如下:
|
|
在 kl.syncLoop 中调用了 kl.syncLoopIteration,接收了以下几种 chan:
|
|
dispatchWork
dispatchWorker 的主要作用是把某个对 Pod 的操作(创建/更新/删除)下发给 podWorkers。
|
|
HandlePodAddtions
对于事件中的每个 pod,执行以下操作:
- 把所有的 Pod 按照创建日期进行排序,保证最先创建的 Pod 会最先被处理
- 把它加入到 podManager 中,podManager 子模块负责管理这台机器上的 Pod 的信息,pod 和 mirrorPod 之间的对应关系等等。所有被管理的 pod 都要出现在里面,如果 podManager 中找不到某个 Pod,就认为这个 Pod 被删除了
- 如果是 mirror Pod 调用其单独的方法
- 验证 Pod 是否能在该节点运行,如果不可以直接拒绝
- 通过 dispatchWork 把创建 Pod 的工作下发给 podWorkers 子模块做异步处理
- 在 probeManager 中添加 Pod,如果 Pod 中定义了 readiness 和 liveness 健康检查,启动 goroutine 定期进行检测
|
|
HandlePodUpdates
|
|
HandlePodRemoves
|
|
HandlePodReconcile
|
|
HandlePodSyncs
|
|
PodWorkers
podWorkers 子模块主要的作用就是处理针对每一个的 Pod 的更新事件,比如 Pod 的创建,删除,更新。而 podWorkers 采取的基本思路是:为每一个 Pod 都单独创建一个 goroutine 和更新事件的 channel,goroutine 会阻塞式的等待 channel 中的事件,并且对获取的事件进行处理。而 podWorkers 对象自身则主要负责对更新事件进行下发。
managePodLoop
managePodLoop 调用 syncPodFn 方法去同步 pod,syncPodFn 实际上就是 kubelet.syncPod。
|
|
将这个 pod 信息插入 kubelet 的 workQueue 队列中,等待下一次周期性的对这个 pod 的状态进行 sync 将在这次 sync 期间堆积的没有能够来得及处理的最近一次 update 操作加入 goroutine 的事件 channel 中,立即处理。
syncPod
syncPod 用来完成创建容器前的准备工作,在这个方法中,主要完成以下几件事情:
- 如果是删除 pod,立即执行并返回
- 同步 podStatus 到 kubelet.statusManager
- 检查 pod 是否能运行在本节点,主要是权限检查(是否能使用主机网络模式,是否可以以 privileged 权限运行等)。如果没有权限,就删除本地旧的 pod 并返回错误信息
- 创建 containerManagar 对象,并且创建 pod level cgroup,更新 Qos level cgroup
- 如果是 static Pod,就创建或者更新对应的 mirrorPod
- 创建 pod 的数据目录,存放 volume 和 plugin 信息,如果定义了 pv,等待所有的 volume mount 完成(volumeManager 会在后台做这些事情),如果有 image secrets,去 apiserver 获取对应的 secrets 数据
- 然后调用 kubelet.volumeManager 组件,等待它将 pod 所需要的所有外挂的 volume 都准备好。
- 调用 container runtime 的 SyncPod 方法,去实现真正的容器创建逻辑
这里所有的事情都和具体的容器没有关系,可以看到该方法是创建 pod 实体(即容器)之前需要完成的准备工作。
|
|
syncTerminatingPod
|
|
syncTerminatedPod
|
|
ContainerRuntime
SyncPod
ContainerRuntime(pkg/kubelet/kuberuntime)子模块的 SyncPod 函数才是真正完成 Pod 内容器实体的创建。 syncPod 主要执行以下几个操作:
- Compute sandbox and container changes.
- Kill pod sandbox if necessary.
- Kill any containers that should not be running.
- Create sandbox if necessary.
- Create ephemeral containers.
- Create init containers.
- Create normal containers.
initContainers 可以有多个,多个 container 严格按照顺序启动,只有当前一个 container 退出了以后,才开始启动下一个 container。
|
|
startContainer
It starts the container through the following steps:
- pull the image
- create the container
- start the container
- run the post start lifecycle hooks (if applicable)
|
|