Kubelet PLEG
PLEG 全称叫 Pod Lifecycle Event Generator,即 Pod 生命周期事件生成器。实际上它只是 Kubelet 中的一个模块,主要职责就是通过每个匹配的 Pod 级别事件来调整容器运行时的状态,并将调整的结果写入缓存,使 Pod 的缓存保持最新状态。
Background
在 Kubernetes 中,每个节点上都运行着一个守护进程 Kubelet 来管理节点上的容器,调整容器的实际状态以匹配 spec 中定义的状态。具体来说,Kubelet 需要对两个地方的更改做出及时的回应:
- Pod spec 中定义的状态:对于 Pod,Kubelet 会从多个数据来源
watchPod spec 中的变化 - 容器运行时的状态:对于容器,Kubelet 会定期(例如10s)轮询容器运行时,以获取所有容器的最新状态。
随着 Pod 和容器数量的增加,轮询会产生不可忽略的开销,并且会由于 Kubelet 的并行操作而加剧这种开销123(为每个 Pod 分配一个 goruntine,用来获取容器的状态)。轮询带来的周期性大量并发请求会导致较高的 CPU 使用率峰值(即使 Pod 的定义和容器的状态没有发生改变),降低性能。最后容器运行时可能不堪重负,从而降低系统的可靠性,限制 Kubelet 的可扩展性。
为了降低 Pod 的管理开销,提升 Kubelet 的性能和可扩展性,引入了 PLEG4,改进了之前的工作方式:
- 减少空闲期间的不必要工作(例如 Pod 的定义和容器的状态没有发生更改)。
- 减少获取容器状态的并发请求数量。
Overview
整体的工作流程如下图所示,虚线部分是 PLEG 的工作内容。

|
|
Pod Lifecycle Event
Pod Lifecycle Event 是 Pod 级别抽象出来的用来解释底层容器状态变化,从而在 Kubernetes 看是对于容器运行时是无感知的。当前定义的 Event Type 如下所示:
|
|
PLEG 的具体实现逻辑主要是以下三个函数:
|
|
Relist
前面提到,Kubelet 通过 PLEG 定期产生 Pod Lifecycle Event,通过 channel 将事件传递给 syncLoop 来处理 Pod 的创建和删除等事件。以 Docker 为例,在 Pod 中启动一个容器就会在 Kubelet 中注册一个 ContainerStarted Pod 生命周期事件。
那么 PLEG 是如何知道新启动了一个 infra 容器呢?它会定期重新列出节点上的所有容器(例如 docker ps),并与上一次的容器列表进行对比,以此来判断容器状态的变化。其实这就是 relist() 函数干的事情,尽管这种方法和以前的 Kubelet 轮询类似,但现在只有一个线程,就是 PLEG。现在不需要所有的线程并发获取容器的状态,只有相关的线程会被唤醒用来同步容器状态。而且 relist 与容器运行时无关,也不需要外部依赖。
当前 Kubelet 设置 relist 的调用周期为 1s。尽管每秒钟调用一次 relist,但它的完成时间仍然有可能超过 1s。因为下一次调用 relist 必须得等上一次 relist 执行结束,设想一下,如果容器运行时响应缓慢,或者一个周期内有大量的容器状态发生改变,那么 relist 的完成时间将不可忽略,假设是 5s,那么下一次调用 relist 将要等到 6s 之后。
|
|

前面提到,我们在 NewMainKubelet 中创建了 GenericPLEG 对象,当 Kubelet.Run() 时,我们会开启 Start() 开启一个 goroutine 以 1s 为周期定期去 relist。相关的源代码如下:
|
|
Healthy Check
为了检查每次 relist 是否正常,Kubelet 设置了 relist 的完成时间为 3min。Kubelet 在 syncLoop 中会定期检查 relist 进程(PLEG 的关键任务)是否在 3 分钟内完成。如果 relist 进程的完成时间超过了 3 分钟,就会报告 PLEG is not healthy 。
下面是调用 Healthy() 函数的相关代码:
|
|
那么 Healthy 是如何被调用的呢 ?Healthy() 函数会以 PLEG 的形式添加到 runtimeState 中,Kubelet 在一个同步循环(SyncLoop() 函数)中会定期(默认是 10s)调用 Healthy() 函数。

|
|
深入解读 relist 函数
下面我们来看一下 relist() 函数的内部实现。完整的流程如下图所示:
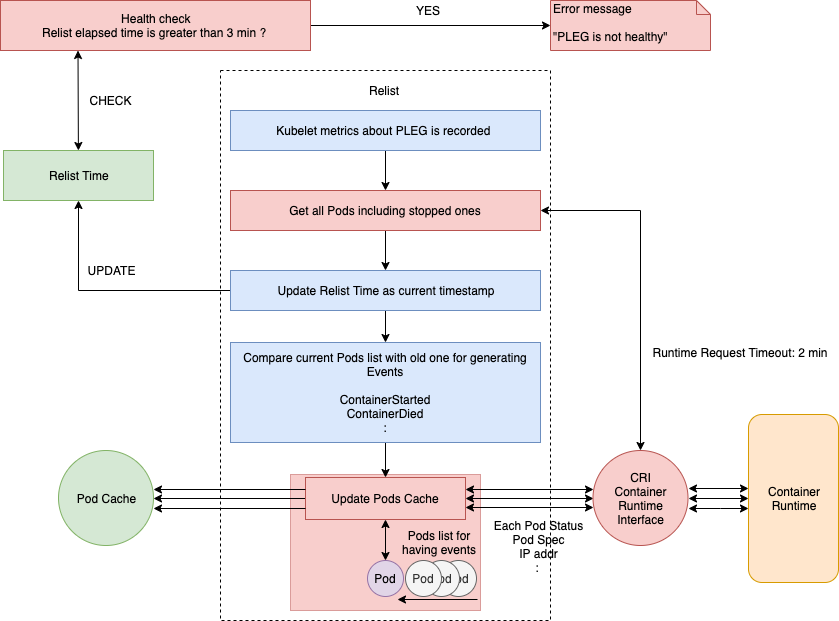
如上所示,relist 函数第一步就是记录 Kubelet 的相关指标(例如 kubelet_pleg_relist_latency_microseconds),然后通过 CRI 从容器运行时获取当前的 Pod 列表(包括停止的 Pod)。该 Pod 列表会和之前的 Pod 列表进行比较,检查哪些状态发生了变化,然后同时生成相关的 Pod 生命周期事件和 更改后的状态 。
|
|
GetPods
其中 GetPods() 函数的调用堆栈如下图所示:

相关的源代码如下:
|
|
获取所有的 Pod 列表后,relist 的完成时间就会更新成当前的时间戳。也就是说,Healthy() 函数可以根据这个时间戳来评估 relist 是否超过了 3 分钟。
|
|
computeEvents
将当前的 Pod 列表和上一次 relist 的 Pod 列表进行对比之后,就会针对每一个变化生成相应的 Pod 级别的事件。相关的源代码如下:
|
|
其中 generateEvents() 函数(computeEvents() 函数会调用它)用来生成相应的 Pod 级别的事件(例如 ContainerStarted、ContainerDied 等等),然后通过 updateEvents() 函数来更新事件。
computeEvents() 函数的内容如下:
|
|
updateCache
relist 的最后一个任务是检查是否有与 Pod 关联的事件,更新事件到 plegCh,并按照下面的流程更新 podCache。
|
|
updateCache() 将会检查每个 Pod,并在单个循环中依次对其进行更新。因此,如果在同一个 relist 中更改了大量的 Pod,那么 updateCache 过程将会成为瓶颈。最后,更新后的 Pod 生命周期事件将会被发送到 eventChannel。
某些远程客户端还会调用每一个 Pod 来获取 Pod 的 spec 定义信息,这样一来,Pod 数量越多,延时就可能越高,因为 Pod 越多就会生成越多的事件。
updateCache() 的详细调用堆栈如下图所示,其中 GetPodStatus() 用来获取 Pod 的 spec 定义信息:

完整的代码如下:
|
|
上面就是 relist() 函数的完整调用堆栈,我在讲解的过程中结合了相关的源代码,希望能为你提供有关 PLEG 的更多细节。为了实时了解 PLEG 的健康状况,最好的办法就是监控 relist。
监控 relist
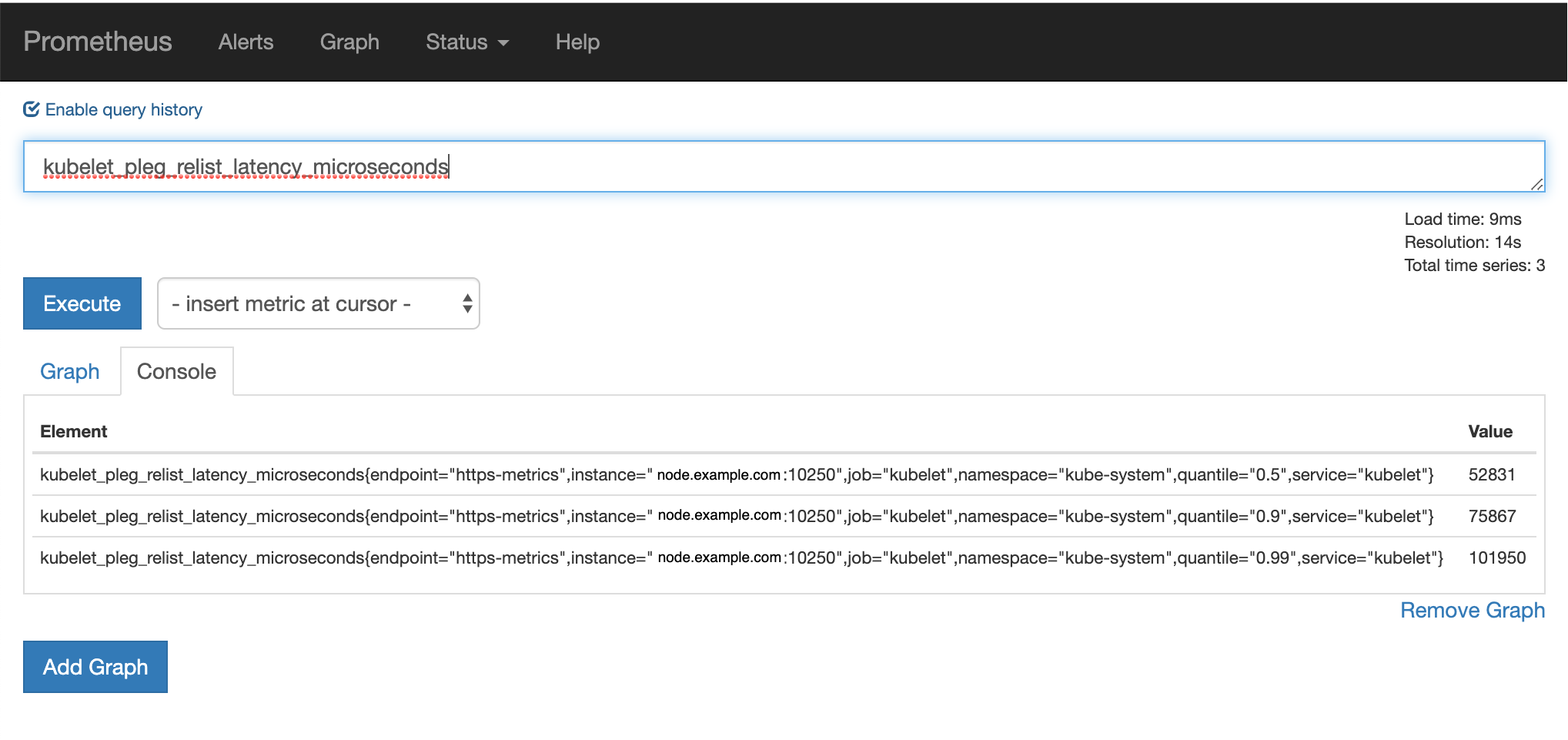
我们可以通过监控 Kubelet 的指标来了解 relist 的延时。relist 的调用周期是 1s,那么 relist 的完成时间 + 1s 就等于 kubelet_pleg_relist_interval_microseconds 指标的值。你也可以监控容器运行时每个操作的延时,这些指标在排查故障时都能提供线索。

你可以在每个节点上通过访问 URL http://127.0.0.1:10255/metrics 来获取 Kubelet 的指标。
|
|
可以通过 Prometheus 对其进行监控:
PLEG is not healthy
造成 PLEG is not healthy 的因素有很多,下面是几种可能的原因:
Container Runtime
RPC 调用过程中 容器运行时5 响应超时(有可能是性能下降,死锁或者出现了 bug)。这种情况下可以通过以下命令检查执行 list container 时间
|
|
一种 workaround 的方法6是:
We created a bash script that checks if docker ps is executed properly in less than 60 seconds. If this check fails 3 times, the Docker service is restarted. It happens from time to time, but the script solves the issue.
Overload
节点上的 Pod 数量太多,导致 relist 无法在 3 分钟内完成。事件数量和延时与 Pod 数量成正比,与节点资源无关。
System Bug
Reference
-
No backlinks found.