Kube-Router
Kube-router 是一个挺有想法的项目,兼备了 calico 和 kube-proxy 的功能,是基于 Kubernetes 网络设计的一个集负载均衡器、防火墙和容器网络的综合方案。
体系架构
Kube-router 是围绕 观察者 和 控制器 的概念而建立的。
观察者 使用 Kubernetes watch API 来获取与创建,更新和删除 Kubernetes 对象有关的事件的通知。 每个观察者获取与特定 API 对象相关的通知。 在从 API 服务器接收事件时,观察者广播事件。
控制器 注册以获取观察者的事件更新,并处理事件。
Kube-router 由3个核心控制器和多个观察者组成,如下图所示。
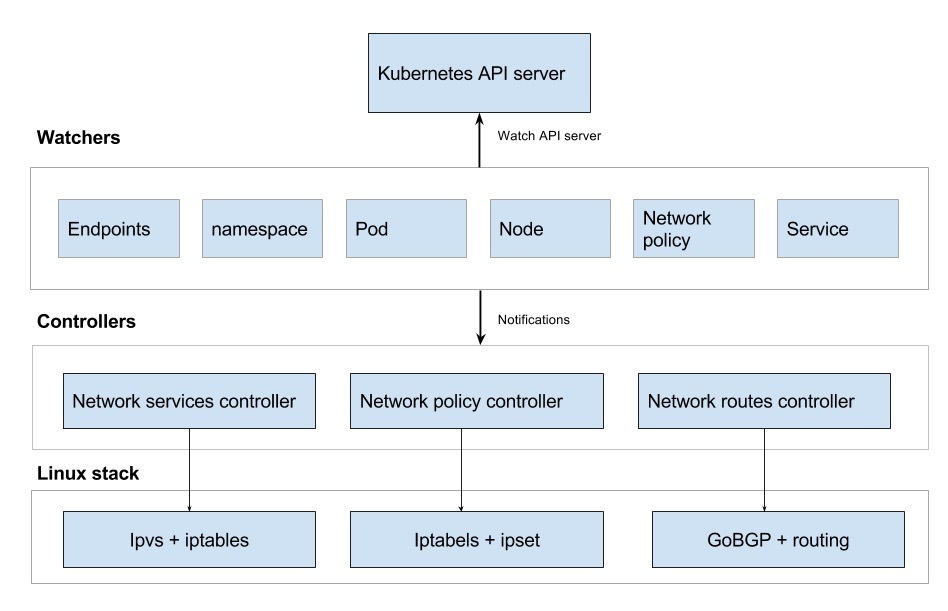
流程分析
Kube-router 启动之后,首先创建 wathcer:
|
|
在 startApiWatchers 中,会启动 endpoint、namespace、pod、node、networkpolicy、service 这六个 watcher。
这六个 wathcer 将监听的变化发送到 Broadcaster。
|
|
之后创建三个 controller:NetworkPolicyController、NetworkRoutingController、NetworkServicesControllers。 每个 controller 会监听所关心的资源的变化。
|
|
每个 controller 遵循以下结构。
|
|
主要功能
基于 IPVS/LVS 的负载均衡器 | --run-service-proxy
Kube-router 采用 Linux 内核的 IPVS 模块为 K8s 提供 Service 的代理。Kube-router 的负载均衡器功能,会在物理机上创建一个虚拟的 kube-dummy-if 网卡,然后利用 k8s 的 watch APi 实时更新 svc 和 ep 的信息。svc 的 cluster_ip 会绑定在 kube-dummy-if 网卡上,作为 lvs 的 virtual server 的地址。realserver 的 ip 则通过 ep 获取到容器的IP地址。
基于 Kubernetes 网络服务代理的 Kube-router IPVS 演示

特征:
- 轮询负载均衡
- 基于客户端IP的会话保持
- 如果服务控制器与网络路由控制器(带有
–-run-router标志的 kube-router)一起使用,源IP将被保留 - 用
–-masquerade-all参数明确标记伪装(SNAT)
更多详情可以参考:
- Kubernetes network services prox with IPVS/LVS
- Kernel Load-Balancing for Docker Containers Using IPVS
- LVS负载均衡之持久性连接介绍
容器网络 | --run-router
Kube-router 利用 BGP 协议和 Go 的 GoBGP 库和为容器网络提供直连的方案。因为用了原生的 Kubernetes API 去构建容器网络,意味着在使用 kube-router 时,不需要在你的集群里面引入其他依赖。
同样的,kube-router 在引入容器 CNI 时也没有其它的依赖,官方的 bridge 插件就能满足 kube-rouetr 的需求。
更多关于 BGP 协议在 Kubernetes 中的使用可以参考:
网络策略管理 | --run-firewall
网络策略控制器负责从 Kubernetes API 服务器读取命名空间、网络策略和 pod 信息,并相应地使用 ipset 配置 iptables 以向 pod 提供入口过滤,保证防火墙的规则对系统性能有较低的影响。
Kube-router 支持 networking.k8s.io/NetworkPolicy 接口或网络策略 V1/GA semantics 以及网络策略的 beta 语义。
更多关于 kube-router 防火墙的功能可以参考:
使用 kube-router 替代 kube-proxy
下面进入实战阶段,本方案只使用 kube-router 的 service-proxy 功能,网络插件仍然使用 calico(估计只有我能想到这么奇葩的组合了 ✌️)
前提
- 已有一个 k8s 集群
- kube-router 能够连接
apiserver - 如果您选择以
daemonset运行 kube-router,那么 kube-apiserver 和 kubelet 必须以–allow-privileged=true选项运行
集群环境
| 角色 | IP 地址 | 主机名 |
|---|---|---|
| k8s master | 192.168.123.250 | node1 |
| k8s node | 192.168.123.248 | node2 |
| k8s node | 192.168.123.249 | node3 |
安装步骤
如果你正在使用 kube-proxy,需要先停止 kube-proxy 服务,并且删除相关 iptables 规则。
|
|
接下来以 daemonset 运行 kube-router,这里我们使用 DR 模式。
|
|
在每台机器上查看 lvs 条目
|
|
可以看出,kube-router 使用的是 lvs 的 nat 模式。
创建一个应用测试 kube-router
|
|
查看创建好的服务
|
|
查看 lvs 规则条目
|
|
可以发现本机的 Cluster IP 代理后端真实 Pod IP,使用 rr 算法。
通过 ip a 可以看到,每添加一个服务,node 节点上面的 kube-dummy-if 网卡就会增加一个虚IP。
session affinity
Service 默认的策略是,通过 round-robin 算法来选择 backend Pod。 要实现基于客户端 IP 的会话亲和性,可以通过设置 service.spec.sessionAffinity 的值为 ClientIP (默认值为 “None”)。
|
|
可以看到 lvs 的规则条目里多了个 persistent,即 lvs 的持久连接,关于 lvs 持久连接的具体内容可以参考我的另一篇博文 LVS负载均衡之持久性连接介绍。
可以通过设置 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 的值来修改 lvs 的 persistence_timeout 超时时间。
|
|
NodePort
|
|
可以看到不仅有虚拟IP条目,还多了对应主机的 lvs 条目。
更改算法
- 最少连接数
|
|
- 轮询
|
|
- 源地址哈希
|
|
- 目的地址哈希
|
|
问题解决
接下来需要面对一些非常棘手的问题,我尽可能将问题描述清楚。
**问题1:**在集群内某个节点主机上通过 SVC IP+Port 访问某个应用时,如果 lvs 转到后端的 pod 在本主机上,那么可以访问,如果该 pod 不在本主机上,那么无法访问。
可以通过抓包来看一下,现在 service whats-my-ip 后端有三个 pod,分别运行在 node1、node2 和 node3 上。
|
|
在 node3 上访问 whats-my-ip 服务:
|
|
同时在 node1 上抓包:
|
|
可以看到 node1 将数据包丢弃了,因为源IP是 10.254.175.147,系统认为这是 node1 自己本身。
根本原因可以查看 node3 的路由表:
|
|
src 的值用来告诉该 host 使用 10.254.175.147 作为 source address,可以通过修改路由表来解决这个问题:
|
|
再次在 node1 上抓包可以发现源IP已经变成了 192.168.123.249。
|
|
**问题2:**在集群内某个节点主机上通过 SVC IP+Port 访问 service kubernetes 时,如果该节点是 master 节点(即 kube-apiserver 运行在该节点上),那么可以访问,如果该节点不是 master 节点,那么无法访问。
原因和问题1类似,可以通过修改路由表解决:
|
|
**问题3:**在某个 pod 内访问该 pod 本身的 ClusterIP:Port,如果 lvs 转到后端的 IP 是该 pod 的 IP,那么无法访问,如果不是则可以访问。
kube-proxy 的 iptables 模式也有同样的问题,这个问题可以忽略。
总结
问题1和问题2修改路由表可以通过批量 shell 脚本来解决:
|
|
如果想要在创建 service 时自动修改路由表,最好还是将该 fix 整合进 kube-router 的源码中。
5. 参考
-
No backlinks found.