Ulysses Sequence Parallel
Ulysses Sequence Parallel (USP) 是由 DeepSpeed 团队提出的一种高效的序列并行方案。它主要为了解决在大模型训练中,由于序列长度(Sequence Length)过长导致单张显卡显存溢出(OOM)的问题。
与传统的 Megatron-LM 序列并行不同,Ulysses 的核心思想是:在 Attention 计算前,通过 All-to-All 通信将序列维度的分布式转变为注意力头(Attention Heads)维度的分布式。
| 符号表示 | 数学含义 |
|---|---|
| $N$ | sequence length |
| $hc$ | head number |
| $l$ | transformer layer number |
| $b$ | batch size |
| $V$ | vocabulary size |
| $d$ | hidden layer size |
| $h_s$ | per head hidden size, $h_s = d // hc$ |
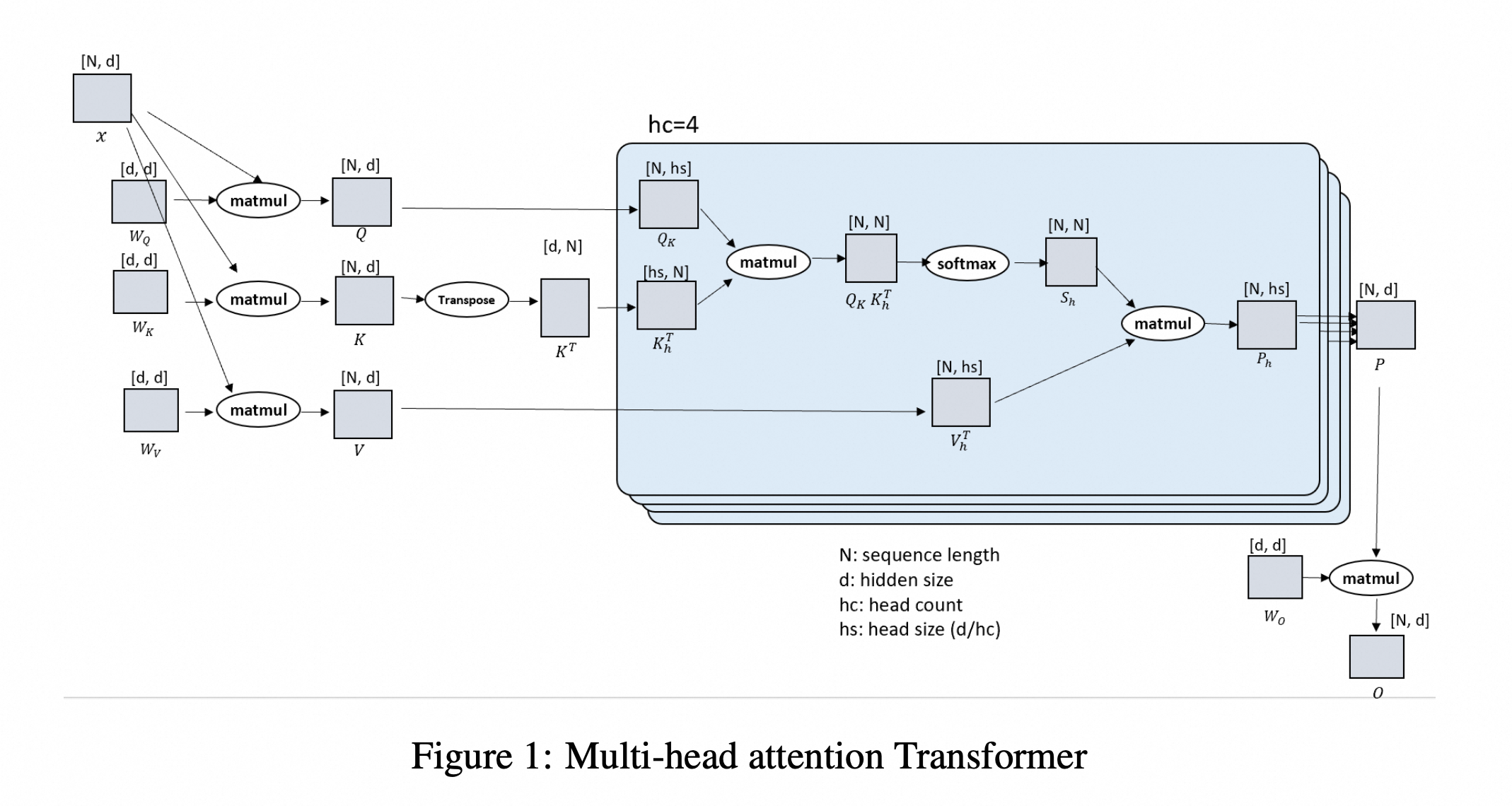
核心原理:维度转换
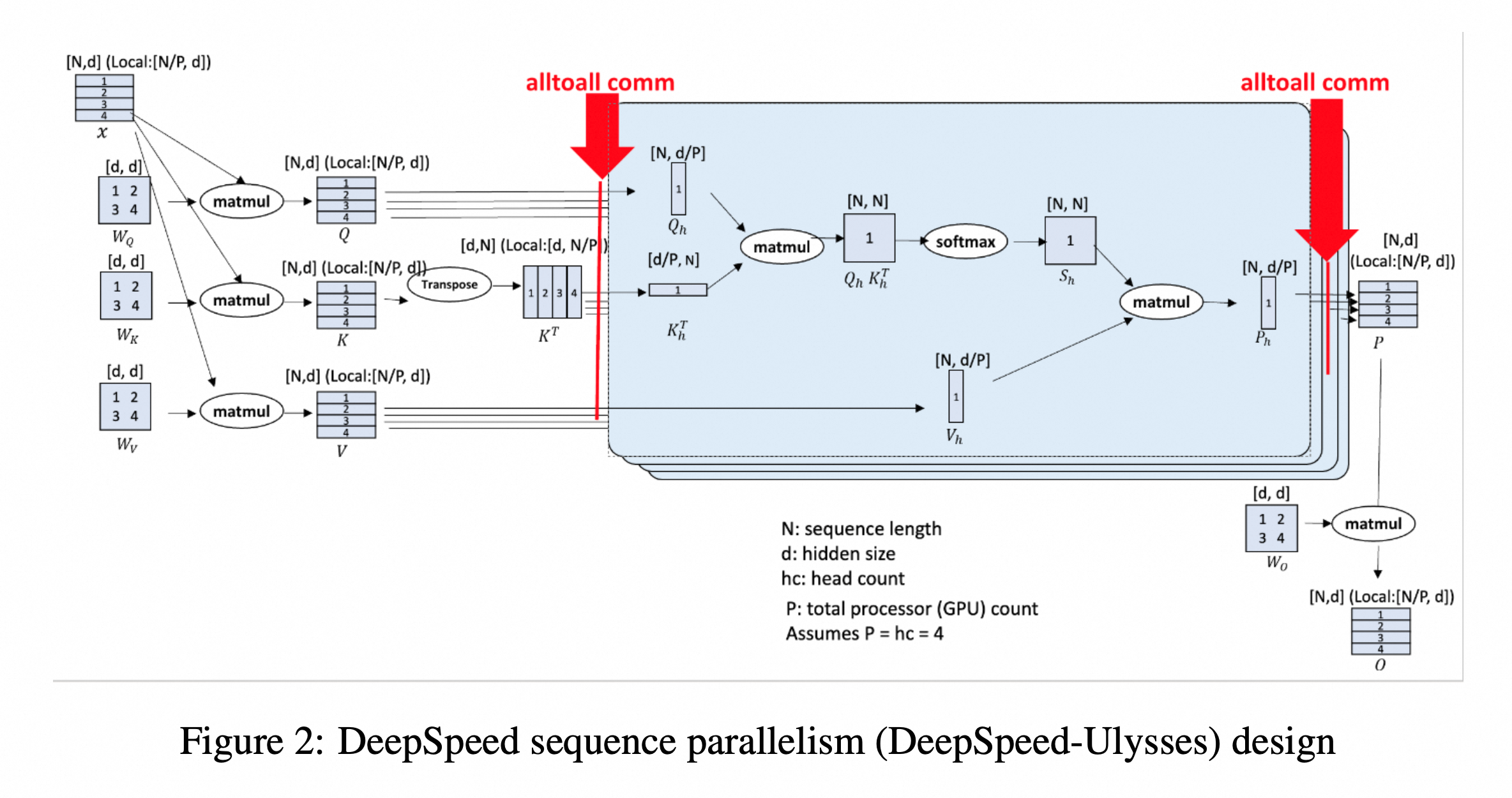
在 Ulysses 方案中,模型在计算 Self-Attention 之前和之后各进行一次 All-to-All 通信。
核心步骤
- 输入状态:按 seq 维度切分输入数据,每个 rank 输入 sequence 形状为
[N/P, d] - 对应计算 $Q, K, V$ 张量的形状为
[N/P, d],对应于[N/P, hc, hs]。这里 $P$ 是并行度(Degree of Parallelism),序列被切分到了不同的 GPU 上。- 注意,这里说明 ulysses 不切分模型,只切分数据的 sequence 维度
- 第一次 All-to-All:将数据从 序列维度 (Sequence) 重新排列到 头维度 (Head)。变换后,每张显卡拥有完整的序列长度,但只拥有部分注意力头,形状变为
[N, hc/P, hs],也就是[N, d/P]。- 这里要求 hc 可以整除 P,也就是每个 rank 分到
hc/P的 head - 这里的 all-to-all 可以理解成一种 permutation 转置式通信
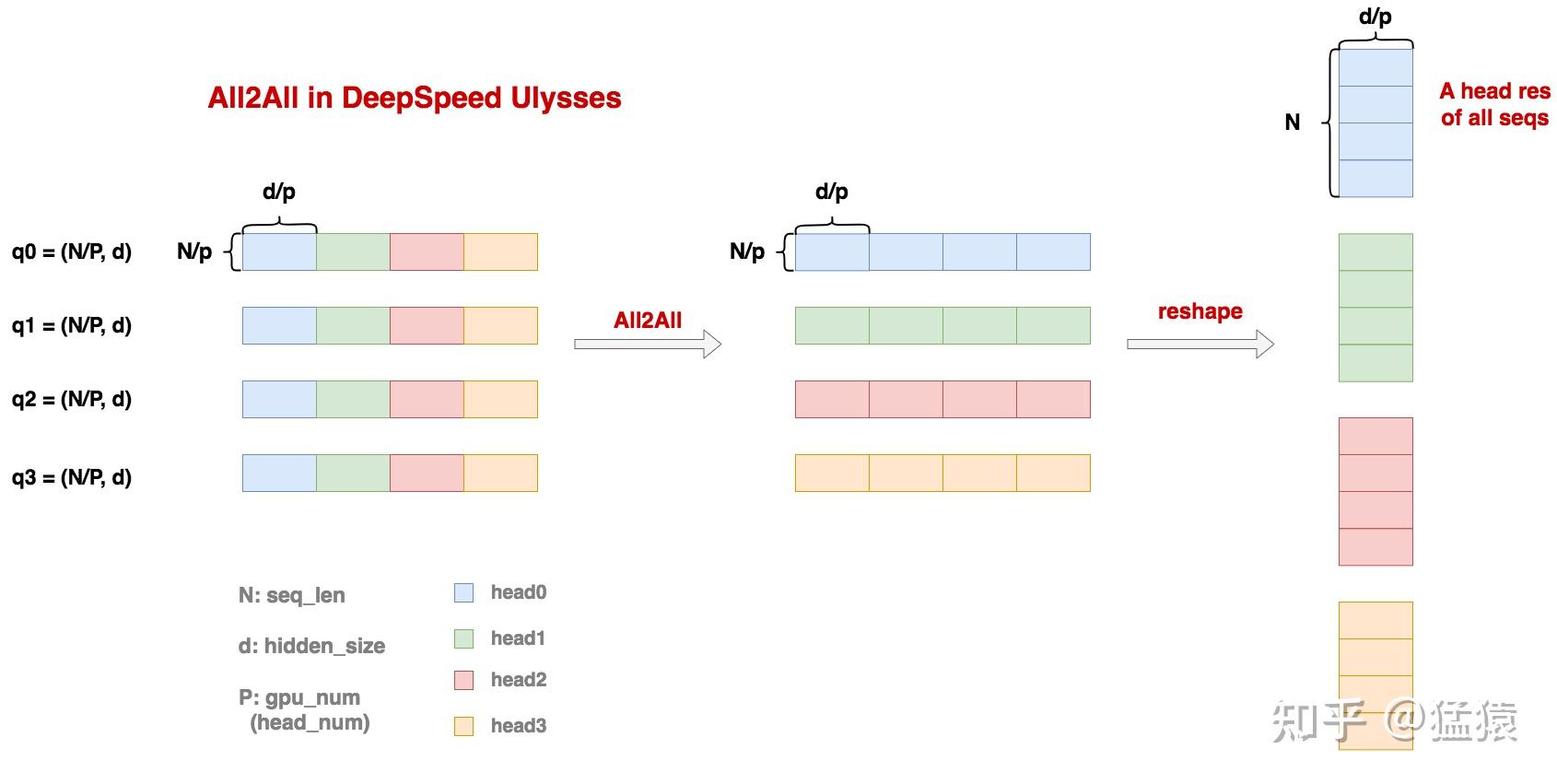
- 这里要求 hc 可以整除 P,也就是每个 rank 分到
- 计算 Attention:每张显卡独立计算它所拥有的那部分 Heads 的 Attention,最终每张卡上产出结果 $P_h$ chunk,尺寸为
(N, d/P) - 第二次 All-to-All:计算完成后,再通过 All-to-All 把数据从 头维度 还原回 序列维度,每张卡上维护的 P Chunk 形状回到
[N/P, d]。 - 单张卡上拥有完整的 $W_O$ 矩阵,我们将 P chunk 和它相乘,得到最后的输出 O chunk,尺寸为
(N/P, d) - 进入 MLP 层,由于在 MLP 层中,不涉及 token 和 token 之间的相关性计算,所以各 seq_chunk 块可以独自计算。
- 重复上述过程,直到算到Loss 为止。
代码实现
这里主要列出
|
|
FSDP 与 Ulysses 配合使用
下面的代码以 veRL 中代码为例,参考1:
切分 sequence
在 veRL 的 prepare_model_inputs 中,会先调用 ulysses_pad_and_slice_inputs 去 sequence 维度切分
|
|
对应的实现
|
|
Attention 计算流程
- 先计算 q, k, v,对应的 shape 为
(bsz, seq_len/n, n_head, head_dim),其中 Q 和 V 的 head 数可能不一致。转置之后,shape 为(bsz, n_head, seq_len/n, head_dim)- 注意,代码里的 q_len 是已经经过切分了的
seq_len/n
- 注意,代码里的 q_len 是已经经过切分了的
- 第一次 all_to_all,调用 gather_seq_scatter_heads,得到 query_states 为
(bsz, n_head/n, seq_len, head_dim)- 因此这里获取了 full_q_len
- Apply RoPE
- Repeat_KV,针对于 GQA/MQA 场景
- 每个 rank 计算 local attention
- 第二次 all_to_all,调用 gather_heads_scatter_seq,得到 attn_output 为
(bsz, seq_len/n, n_head, head_dim) - 经过 o_proj,attn_output 为
(bsz, seq_len/n, n_head, head_dim)
|
|
第一次 all-to-all
在 ulysses 的第一次 all-to-all,从 [N/P, d] 形状转换成 [N, d/P],也就是 gather sequence,scatter heads。
|
|
这里用到了 SeqAllToAll 这个算子,具体的对应于在 head_dim 维度 scatter,在 seq_dim 维度 gather。
|
|
对应的 all_to_all_tensor 的实现
|
|
注意,对于 SeqAllToAll 这个算子,其 backward 对应也是一个 all_to_all,只是 gather_dim 和 scatter_dim 正好反了过来。
- Forward:
all_to_all_tensor(input, scatter_dim, gather_dim, ...) - Backward:
all_to_all_tensor(grad, gather_dim, scatter_dim, ...)
第二次 all-to-all
|
|
gather 恢复 sequence
在 veRL 的 prepare_model_outputs 中,将计算的结果在 sequence dim 维度 gather 起来,这样每个 rank 都有完整的计算结果,就像最开始完整的输入一样。
|
|
gather_outputs_and_unpad 的实现实际上是调用了 Gather 算子,并且去除掉 pad
|
|
对应的算子实现为
- forward 就是将各个 rank 被切分的 logprob 按照 sequence 维度 gather 在一起
- backward 就是将算出来的 grad 切片,分到每个 rank
- 注意这里 backward 需要执行 grad_scale
|
|
Ulysses Sharding Manager
在 veRL 最开始的 ulysses 实现中1,引入了 FSDPUlyssesShardingManager,
|
|
这里是因为将 update_actor 通过 DP_COMPUTE_PROTO 下发给不同 worker 的时候会沿着 FSDP 维度 worker_group.world_size 对数据平均切分,但是在 Ulysses 中,我们需要保证同一个 sp group 中的数据是相同的。
|
|
比如说,假设原来 bsz=1024, world_size=64, sp_size=4,那么实际的 dp_size=16,每个 DP group 切分到的数据 bsz 应该为 1024/16=64,但是这里是直接切 64 份,每个 worker 上的 bsz=16。因此要通过 preprocess_data 将其 all_gather 起来。
|
|
对应的,计算结束之后,通过 postprocess_data 再将数据平均切分下去。
|
|
这个看起来有点麻烦,因为我们已经有 device_mesh 的信息了,可以不需要这么处理,因此在这个 PR2 移除了 preprocess_data 和 postprocess_data 这部分逻辑。主要是通过 make_nd_compute_dataproto_dispatch_fn 来实现的。
|
|
注册信息如下
|
|
然后在 make_nd_compute_dataproto_dispatch_fn 会通过注册的信息。计算出正确的 dp_size 去做分发 dispatch。
|
|
对于 collect 是类似的,只是只会在 dp_group 的 sp rank 0 上执行 collect,因为同一个 dp group 其他的 sp rank 数据都是相同的。
-
No backlinks found.