面向 SWE-Bench 的 Agent 系统设计
随着大语言模型 LLM 在代码生成领域的快速发展,评估其解决实际软件工程问题的能力成为关键挑战。SWE-bench1 作为首个针对真实 GitHub 问题的基准测试框架,旨在衡量 LLM 在复杂代码环境中理解、推理和生成有效补丁的能力。
SWE-Bench 是什么?
SWE-bench 由普林斯顿大学在 2023 年开发2 SWE-bench: Can Language Models Resolve Real-World GitHub Issues? 1,收录了 12 个流行 Python 仓库的 2294 个 GitHub issue-PR 对。每个任务包含代码库、问题描述和对应的单元测试,要求模型生成补丁以修复问题并通过测试。问题类型涵盖 bug 修复、功能增强等,常需跨文件、跨函数的协调修改,远超传统代码生成任务的复杂度。
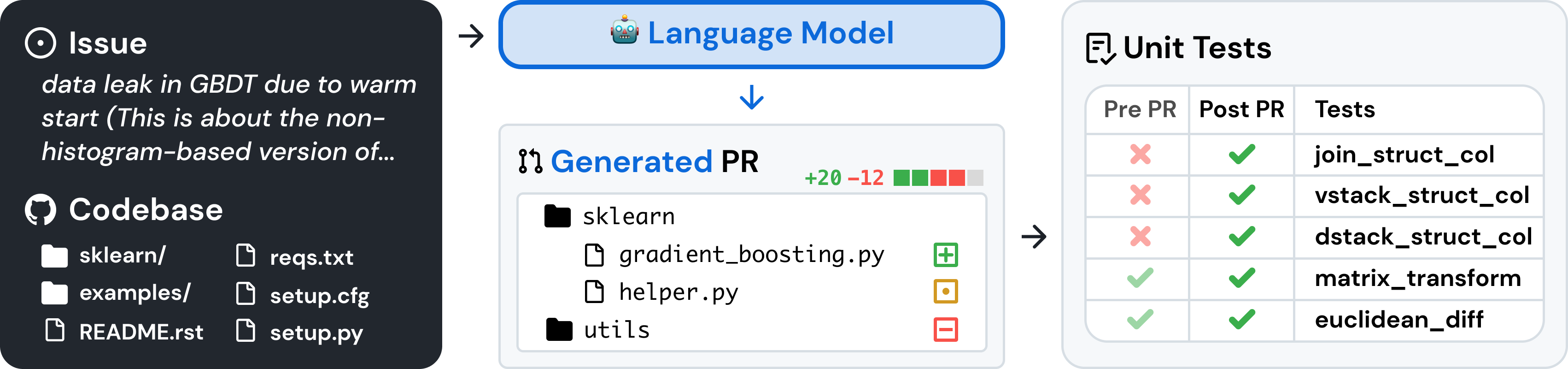
SWE-bench 的输入包括 (code repo,issue description, task instruction) ,期望模型或者对应的系统能够生成对应的 patch,应用 patch 到代码库之后,期望能够通过单元测试的验证:
- FAIL_TO_PASS 测试:补丁前失败,补丁后通过,验证问题是否解决;
- PASS_TO_PASS 测试:补丁前后均通过,确保未破坏现有功能。
因为大型代码工程里面开发的时候一般 PR 通过的时候都会要求通过 CI 的测试,因此一般新的问题出现的时候,其实对应版本的代码都已经通过了所有的单测。
因此,对于 bug fix 或者 feature request 更多对应着原有代码仓库的单元测试遗漏了一些测试情况,此时的任务是要求加入新的单元测试和对应的代码修改。要保证原来的代码不能通过这个新的单元测试,新的代码通过新的单元测试,也就是 FAIL_TO_PASS。而对于其他的单元测试,都要保证 PASS_TO_PASS。这个过程也就是软件开发中常见的增量式开发。

插入一个论文的图
如果把全部 codebase 直接给到模型,对于当前大模型的上下文长度难度有点大(可能多交互几轮上下文长度就超出了,如果以后模型上下文长度近似无限这个约束是否还存在?),因此 SWE-bench 论文中的做法是去做了检索:
- Sparse Retrieval: 基于 BM25 在整个 repo 上搜索和 issue 相关的 files,然后尽可能多的塞给 model
- Oracle Retrieval: 直接在原本 PR 里面修改过的那些 file 做 retrieve
还有一个特点是,因为不同代码库的依赖往往都不太一样,为了保证每一个 task 能够正确执行 Unit Test 验证,SWE-bench 也将执行环境从最初的 conda 环境转换成了 docker 环境,保证每次评估的环境稳定和可靠3。
随着大模型的编程能力的发展,SWE-bench 这一基准测试受到越来越多的关注,以 Devin4, Genie5 等为代表的 AI 编程工具纷纷以 SWE-bench 作为展示其能力的基准测试。


这个换个图
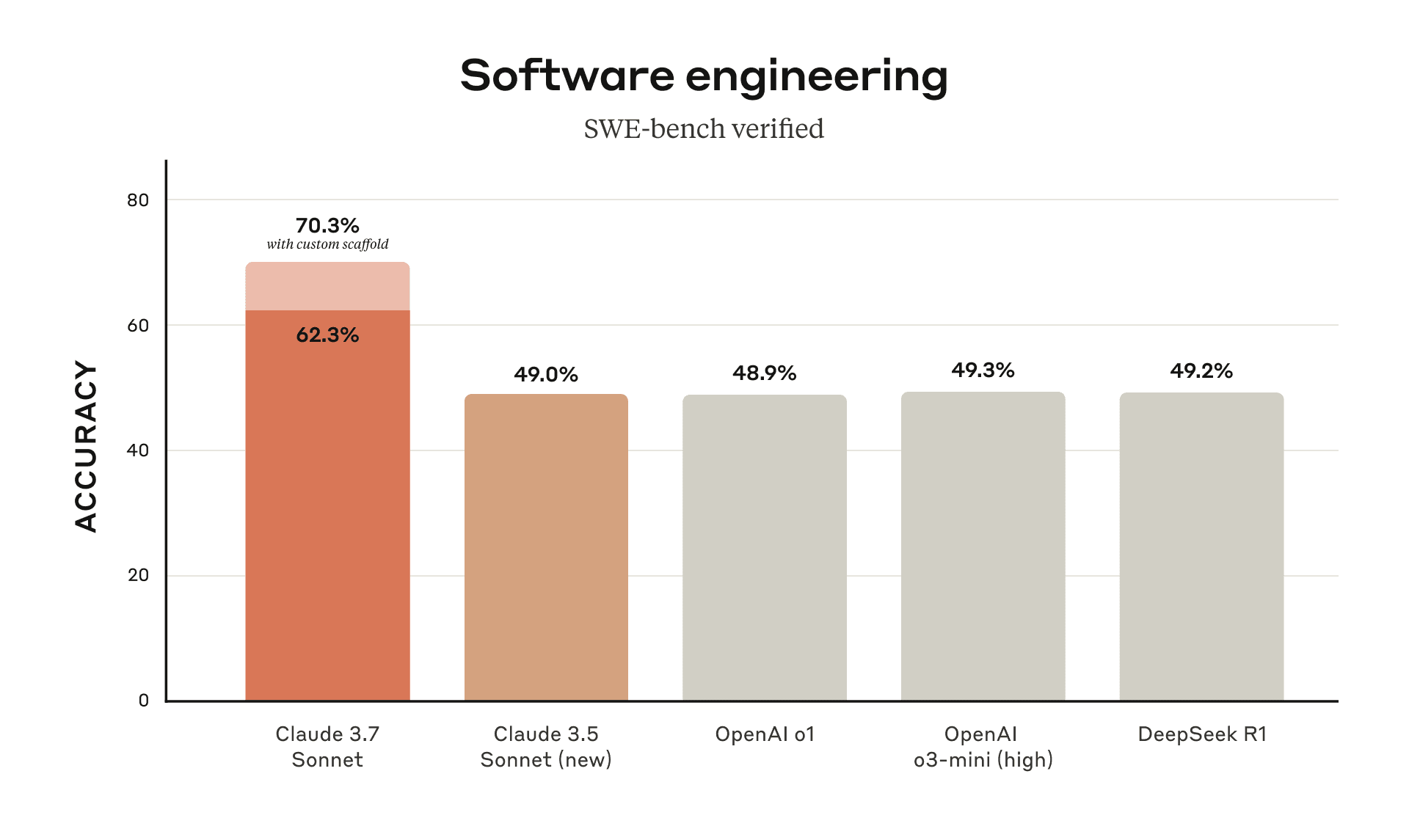
OpenAI 发现原始的 SWE-bench 存在一些问题,可能导致模型的自主软件工程能力被低估,进一步推出了 SWE-bench verified6。在改进过程中,他们与 SWE-Bench 原作者合作,进行了人工筛选和改进,确保单元测试的范围适当且问题描述明确,将问题从原来的 2294 个降为 500 个。在 SWE-bench Verified 上进行的新测试中,很多 AI 编程智能体的得分都比原来要高,当前的评测标准基本上会采用 SWE-bench verified。
Agents on SWE-bench
在 2023 年 SWE-bench 评测基准提出的时候,当时的 SOTA 模型 Claude 2 等模型只能解决 2% 左右的问题,并很快受到了社区的重视。一个直接的努力自然是卷模型能力,倾向于尽可能提高基础模型的代码能力。考虑到 SWE-bench 问题的复杂性,另一个方向则是聚焦于 Agent,通过设计高效的问题解决流程、构建交互工具链,在不修改模型底层架构的前提下,实现了软件工程任务处理能力的突破。下面介绍几个面向 SWE-bench 经典的 Agent 系统。
SWE-Agent
SWE-Agent 是一个利用大语言模型(如 GPT-4、Claude 等)来自动化软件工程任务的 Agent 系统。它的目标是让 AI 模型能够像人类软件工程师一样,通过在命令行环境中导航文件系统、编辑文件、运行测试等方式来解决编程问题。
SWE-Agent 基于 ReAct 框架,提出了 ACI(Agent-Compute Interface)的概念,并证明 ACI 能够显著降低 LLM 与计算机环境交互的门槛。


- File Viewer:限制单次显示 100 行代码,避免模型因信息过载而误判,可以打开或者关闭文件
- Linter: 在编辑命令执行前自动校验代码格式,防止无效修改
- Filer Editer:拥有 ScrollUp 和 ScrollDown 等能力,并且可以在文件中搜索
- Code Search:支持全局字符串匹配,并简洁列出匹配文件,减少模型处理复杂度
- Code Sandbox:通过 Docker 沙箱运行代码,确保修改不会影响宿主系统
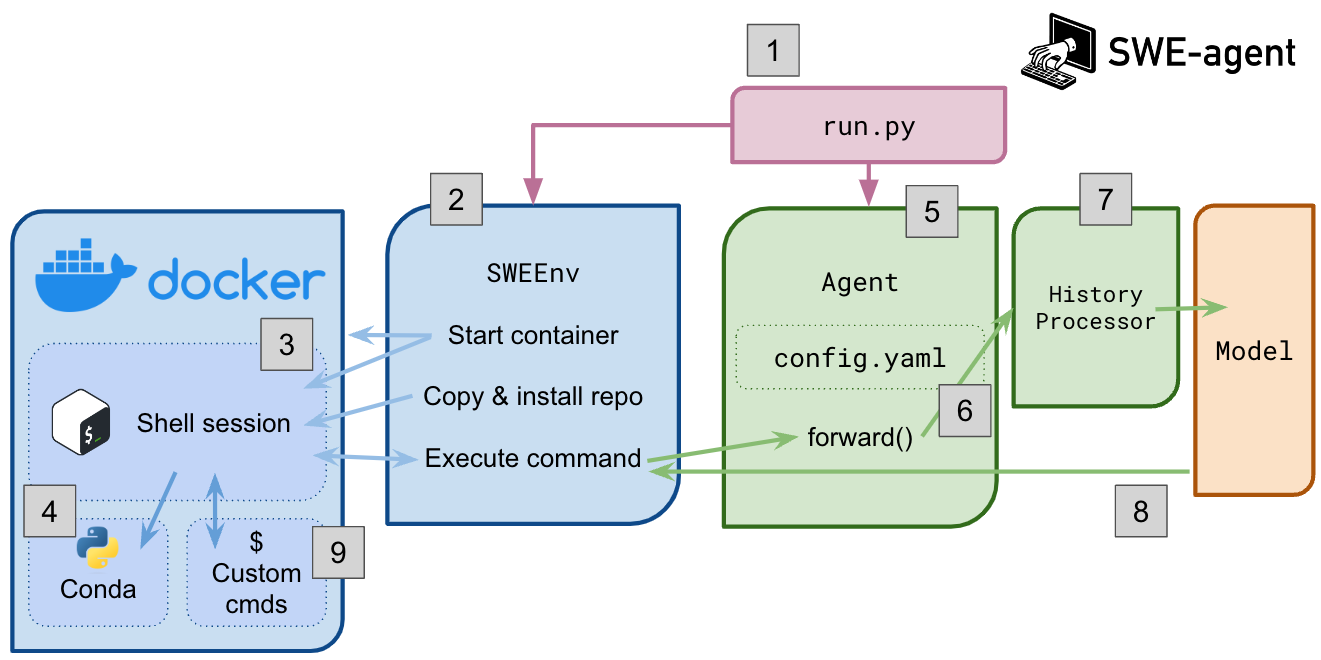
下图是 SWE-Agent 的系统架构图,其中的 2 即是 SWE-Agent 的 Environment,具体对应着实际的 Sandbox 沙箱环境,它可以是运行在本地的 Docker 容器,也可以运行在 AWS 上。在容器中,会启动一个 Shell Session 图中的 5,它可以运行上面提到的 ACI 工具,或者是其他的 Tools,包括可以 pip install 软件包等。
图中的 6 作为实例化的 Agent,通过 forward 和 LLM 模型交互,其中 history processor 图中的 7 维护了和 LLM 的 Context Window。接收到 LLM 的 output 之后,Agent 将其解析为对应的 Action,并且在 SWEEnv 中也就是到 Docker 沙箱中具体执行,并得到对应的反馈结果,从而进行下一轮交互。
下面是 SWE-Agent 的一个简单 demo。
SWE-Agent 的这种操作范式属于典型的仿人类思维直觉的逐步操作:
让 Agent 观察当前 issue ,然后给定项目的目录,让其模拟人类决策当前应该做什么操作,人类可选的操作一般是:打开文件夹,打开文件,鼠上滚动,定位到某行,定位到某个类等。Agent 每进行一步操作,系统将会把操作的结果返回的 LLM ,让其再次决策接下来的行动,这和人类程序员利用编辑器看代码是一样的。因为通用模型拥有大量人类真实世界项目的知识,可以根据这些信息去决定接下来做什么。为什么这里称
仿人类思维直觉,因为这类操作和人类相似,没有用视觉以外的外挂7
AutoCodeRover
AutoCodeRover89 则是类似预先设置好标准的 SOP 流程:
- 首先进行 context retrieval,找到 bug 代码的位置
- 然后 generate patch 生成对应的修改

AutoCodeRover 相对于 SWE-Agent 的一个区别在于,它直接将项目的本地代码库解析为抽象语法树(AST)并在其上进行搜索来进行本地处理,局部执行这些 API 的结果返回给代理,形成代码上下文。AutoCodeRover 算是基于视觉以外的能力来显著提高定位代码的效率。
插入一个 AST 的图。
以下是基于 AutoCodeRover 来解决 Django 代码中 bug 的流程示例:

Agentless
在前面提到的 Agent Framework 中,LLM 被一系列工具包装成可以自主执行 Action 的 Agent:比如在 SWE-bench 这个场景,Agent 可以通过上下文在增删改查中灵活的选择不同的 Action。
While there is not a fixed definition for agent-based approaches, they generally equip LLMs with a set of tools and allow agents to iteratively and autonomously perform actions, observe feedback, and plan future steps.
Example tools can include the ability to open/write/create files, search for code lines, run tests, and execute shell commands. In each attempt to solve a problem, agent-based approaches will have multiple turns, where each turn consists of performing an action. Subsequent turns depend on previous actions and the feedback information the agent receives from the environment.
乍一看,Agent-based 的方法似乎是处理软件开发任务的一种自然而直接的方法,整个流程和人类开发的流程非常相似。然而 Agentless10 论文提到,由于当前模型的在进行反思、规划方面存在困难,这种直接模仿人类的流程存在的诸多局限:
- Complex tool usage/design:为了利用工具,当前基于代理的方法在 Agent 和 Env 之间应用了一个抽象层。例如,将实际 Action 映射到 API 调用,以便 Agent 可以通过输出 API 调用指令来使用工具。然而,这样的抽象和 API 调用规范需要仔细设计输入/输出格式,并且很容易导致不正确或不精确的工具设计/使用,尤其是对于更复杂的动作空间。鉴于基于代理的方法的迭代性质,其中当前 Action/Plan 取决于以前的轮次,错误或不精确地定义/使用工具既会降低性能,又会在浪费 LLM 查询时产生额外的成本。
- Lack of control in decision planning:除了使用工具之外,当前基于 Agent 的方法还将决策过程委托给 Agent,允许他们决定何时执行以及执行什么 Action。 Agent 根据之前采取的 Action 和 Env 提供的反馈来决定当前要采取的 Action,通常只需进行最少的检查,以确保所采取的 Action有意义。由于可能的动作空间和反馈响应很大,自主代理很容易感到困惑并执行次优探索。此外,为了解决问题,代理可能需要 30 或 40 个回合以上,这使得既要理解代理做出的决策,又要调试做出错误决定的确切回合变得极其困难。
- Limited ability to self-reflect:现有的代理倾向于接受所有信息/反馈,而不知道如何过滤或纠正不相关、不正确或误导性的信息。有限的自我反省能力意味着不正确的步骤很容易被放大,并对 Agent 未来做出的所有决定产生负面影响。
于是 Agentless 则反其道而行之,不再通过复杂的工具调用,通过简单的 localization、repair 和 repair 的三阶段流程实现了 SWE-bench 上的效果显著提升。
Agentless employs a simplistic three-phase process of localization, repair, and patch validation, without letting the LLM decide future actions or operate with complex tools.11
由于 Agentless 结构固定、使用简便、结果稳定,基本已成为各个主流模型测试 swe-bench 的常规 agent 框架。
在 Localization 的过程中,Agentless 采用分层流程,首先将故障定位到特定文件,然后定位到相关的类或函数,最后定位到细粒度的编辑位置。从文件到 Class/Function,再到编辑的 location,每个步骤都可能会多次调用 LLM(步骤 2/4/5),如下图所示,其中步骤 3 定位无关文件还用到了 embedding 模型。
在 Repair 的过程(步骤 6)中,Agentless 对于每个编辑位置,生成多个 patch。假设有 m 个编辑位置,每个编辑位置生成 m 个 patch,那么这里 LLM 的调用为 m*n 次。
在 Patch 的过程中:
- 首先要求 LLM 生成 k 个 reproduction test 从而能够复现原来 issue 的问题 (步骤 7),这里 LLM 的调用为 k 次。然后基于 SWE-bench 测试来验证在原来的代码库中是否会重现这里的 test(注意这个时候会去起容器实际跑 SWE-bench)
- 然后根据跑出来的结果选择最优的 test 作为这个 issue 的 test(步骤 8),然后 apply 步骤 6 生成的 patch 后运行 SWE-bench 来验证 patch 是否有效,这里的 SWE-bench 的调用次数为
n*m,并对不同的 patch 做 ranking 和 selection,并且同时验证已有的回归测试得以通过(步骤 9) - 最终排序后选择排序最高的 patch 作为整个流程的返回结果,也就是可以生成对应的 PR

虽然 Agentless 利用 LLM 来执行每项详细任务,但与以前基于代理的复杂工具不同,Agentless 不允许 LLM 自主 决定未来的作或使用任何复杂的工具进行作。Agentless 刻意选择避免使用代理,不仅让 Agentless 拥有简单明了、易于理解的设计,也有助于避免 LLM 代理在软件开发中的上述局限性。
O1 在模型发布的时候,其对于 SWE-bench verified 这一基准测试所采用的方法正是 Agentless:
o1 does not support code execution or file editing tools. To compensate, we use the best-performing open-source scaffold at the time of our initial implementation, Agentless.7
Claude 3.712 在发布的时候也仔细介绍了其 SWE-bench Verified 榜单的评分来源,相比于 OpenAI O1 和 DeepSeek R1 直接使用 Agentless 方法,其采用了一个更加简单的框架,只依赖于一个 bash tool, 一个 file editing tool 和 planning tool 来实现评测:
总结回顾
本文简单介绍了 SWE-bench 和这一基准测试对于模型代码能力的参考价值。随着 Cursor 等 AI 辅助编码工具以及 vibe coding 的流行,基础模型的代码能力和基于大模型的 SWE-Agent 和 Agentless 等框架也都在迅速发展,在目前公开发布的模型中 Claude 3.7 已经在 SWE-bench verified 评测到达了 70 分的成绩,OpenAI 的 O3 模型也宣称达到了 71 分的成绩。可以预见,在不久的将来,LLM 的代码能力将会进一步提升,有可能打穿这一基准测试,并向着更进一步的智能迈进。
-
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? https://arxiv.org/abs/2310.06770 ↩︎ ↩︎
-
https://github.com/SWE-bench/SWE-bench/tree/main/docs/20240627_docker ↩︎
-
Introducing SWE-bench Verified, OpenAI, https://openai.com/index/introducing-swe-bench-verified/ ↩︎
-
AutoCodeRover: Autonomous Program Improvement, https://arxiv.org/abs/2404.05427 ↩︎
-
Agentless: Demystifying LLM-based Software Engineering Agents, https://arxiv.org/abs/2407.01489 ↩︎
-
No backlinks found.