State of AI: 2025 年度人工智能报告之 Research 篇
本周四 stateof. Ai 1出品了 2025 年度人工智能报告2。该报告由英国知名风投公司 Air Street Capital 的合伙人 Nathan Benaich 等联合撰写,该系列报告从 2018 年开始已经连续撰写了 8 年。除了主要作者外,还有众多研究者、机构把关,既有深度又有广度,涉及科研进展、产业界发展、政治影响、AI 安全等众多领域,涵盖了 AI 的方方面面。
以下为全文目录,受限于篇幅,本报告将分为 3 篇发布,本篇为第一篇,主要关注过去一年中 AI 领域的相关突破与进展,之后两篇将在接下来的两天同步发布,敬请期待。
- State of AI 2025 报告年度总结
- 科研进展:技术突破及其能力
- 产业界发展:当前 AI 创新的商业化应用以及对应的商业化影响
- 政治影响:AI 监管,AI 产生的经济影响,AI 的地缘政治演进
- AI 安全:明确和减轻将来庞大 AI 系统可能产生的灾难性影响
- 对 2026 年的预测
[TOC]
01 Summary
Research
- 推理能力定义了这一年,OpenAI、Google、Anthropic 和 DeepSeek 轮流领先,并将可见的
think-then-answer方法推向实际产品 - 开放模型快速改进,中国的开放权重生态系统激增,但顶级模型仍然封闭,并不断扩大其单位成本能力优势
- 由于数据污染和方差问题,基准测试的效力减弱,而 Agents、世界模型和领域工具(代码、科学、医学)开始变得真正有用
Industry
- 随着 AI 优先型公司的收入达到数百亿美元,实际收入大规模到账,领先的实验室以更好的能力-成本曲线扩大了领先优势
- NVIDIA 市值突破 4 万亿美元,拥有 AI 研究论文的 90% 份额,同时定制芯片和新兴云服务崛起。循环式大型交易为巨大的基础设施建设提供了资金
- 电力成为新的瓶颈,多 GW 级集群从 PPT 走向实际选址计划,电网限制开始影响 AI 路线图和利润
Politics
- AI 竞赛升温,美国倾向于
America-first AI并实施出口管制波动,而中国则加速了自力更生的雄心和本土芯片发展 - 面对超高速投资,监管退居次席:国际外交停滞,
AI Act法案在实施上面临障碍 AI goes global成为现实,石油美元和国家项目为巨大的数据中心和模型访问提供资金,与此同时伴随着失业数据逐渐显现
Safety
- AI labs 启动了前所未有的生物和“阴谋”风险保护,但其他一些实验室错过了自我设定的截止日期,或悄悄放弃了测试协议
- 外部安全组织的年度预算少于 leading AI labs 在一天的开支
- 网络能力每 5 个月翻一番,超过了防御措施。犯罪分子利用 AI 智能体策划勒索软件,渗透到财富 500 强公司

02 Research
Reasoning Models
Think before you speak: o1
thinkingignites the reasoning race
随着 2024 年接近尾声,OpenAI 发布了 o 1-preview,这是第一个展示通过 CoT RL 实现 inference-time scaling 的推理模型。这使得在代码和科学等推理密集型领域的问题解决更加稳健345。例如,公开发布的 o 1 在美国数学邀请赛 (AIME) 上展示了通过增加训练和测试时计算量带来的准确性提升。因此,OpenAI 在 2025 年更加坚定地致力于扩展他们的推理工作。
Deeply sought: could frontier reasoning ever be found in the open?
在 o1-preview 发布仅仅 2 个月后,DeepSeek 发布了他们的第一个推理模型 R1-lite-preview6,它构建在先前强大的 V2.5 基础模型之上。像 OpenAI 一样,他们展示了通过增加测试时计算预算,在 AIME 上的准确性有了可预测的提升。令人印象深刻的是,R1-lite-preview 在 AIME 2024 pass@1 上以 52.5 分的成绩击败了 o 1-preview 的 44.6 分。但是,似乎很少有人注意到这一点… 华尔街当然没有:)


Are you not entertained? DeepSeek V 3 brings you to R1
2024 年圣诞节几天后,DeepSeek 发布了 V 3,这是一个强大的 671 B MoE V 3 模型,它通过 FP 8 混合精度、Multi-Token Prediction 和 Auxiliary-free Routing 降低了训练和推理成本。他们使用 V 3 作为基础模型,仅使用 verifiable rewards 和 Group Relative Policy Optimization, GRPO 强化学习算法来训练 R 1-Zero7。
- R 1-Zero 遵循“思考 → 回答”的格式,并使用一个简单的基于规则的奖励来判断最终答案是否正确,这比训练 Reward Model 更便宜,也更难作弊
- GRPO 比较群组内的多个采样答案以形成相对基线,因此它不需要 Value Model 。
- 在训练期间,模型会加长其思考过程、进行探索,并将计算资源重新分配给难题。它的 AIME 分数在大约 8.5 k 步中从 15.6% 上升到约 71%,多数投票运行达到了 o 1-0912 的水平。
- 然后,R 1 通过小型 CoT 热启动、语言一致性奖励、大规模监督微调和最终的 RL 过程来修复可读性。AIME 提高到 79.8,MATH-500 提高到 97.3,GPQA 提高到 71.5,这种方法可以很好地提炼到更小的模型中。
More thinking, more tool use, less cost: DeepSeek V 3.1 and V 3.2-Exp
DeepSeek V 3.18 相比 V 3 实现了重大飞跃,它引入了一种在复杂推理(reasoning)和轻量推理(lightweight inference)之间切换的 hybrid thinking mode。该模式展现出比 R 1 和 V 3 更快的“思考”效率,同时显著改进了 tool use 和 multi-step agent workflows。
V3.2-Exp9 版本保留了这一特性,并将稠密注意力(dense attention)替换为 DeepSeek 稀疏注意力(DeepSeek Sparse Attention, DSA)。其中,一个微型的 lightning indexer 会在每一步选取最相关的 top-k tokens 进行关注。在 coding/search/agent 任务上,其能力与 V 3.1 大致相当,但在处理 32 K 至 128 K 的上下文时,cost 和 latency 显著降低。
Parallel reasoning: beyond depth to branch‑and‑merge inference
混合专家路由 MoE routing 扩展了模型容量,但保留了单流推理 single-flow inference 特性,并且不改变模型的思考方式。一种新的路由方法会分支多条推理路径 inference paths 并将其聚合,与仅仅增加模型深度或宽度相比,这种方法能够实现探索、减少幻觉(hallucination),并更好地利用 GPU 这种并行硬件。
自适应并行推理 Adaptive Parallel Reasoning 10 使模型能够通过 spawn() 和 join() 操作,来动态编排分支推理(branching inference),并使用强化学习(RL)对父线程和子线程进行端到端(end-to-end)训练,以优化协同行为。该方法在 4 K 上下文长度的 Countdown 任务上显著提升了性能:达到 83.4%(APR + RL)对比 60.0%(基线)。

样本集聚合器 Sample Set Aggregator 11 训练一个紧凑模型,将多个推理样本(reasoning samples)融合成一个连贯的答案,其性能优于简单的 re-ranking 方法。
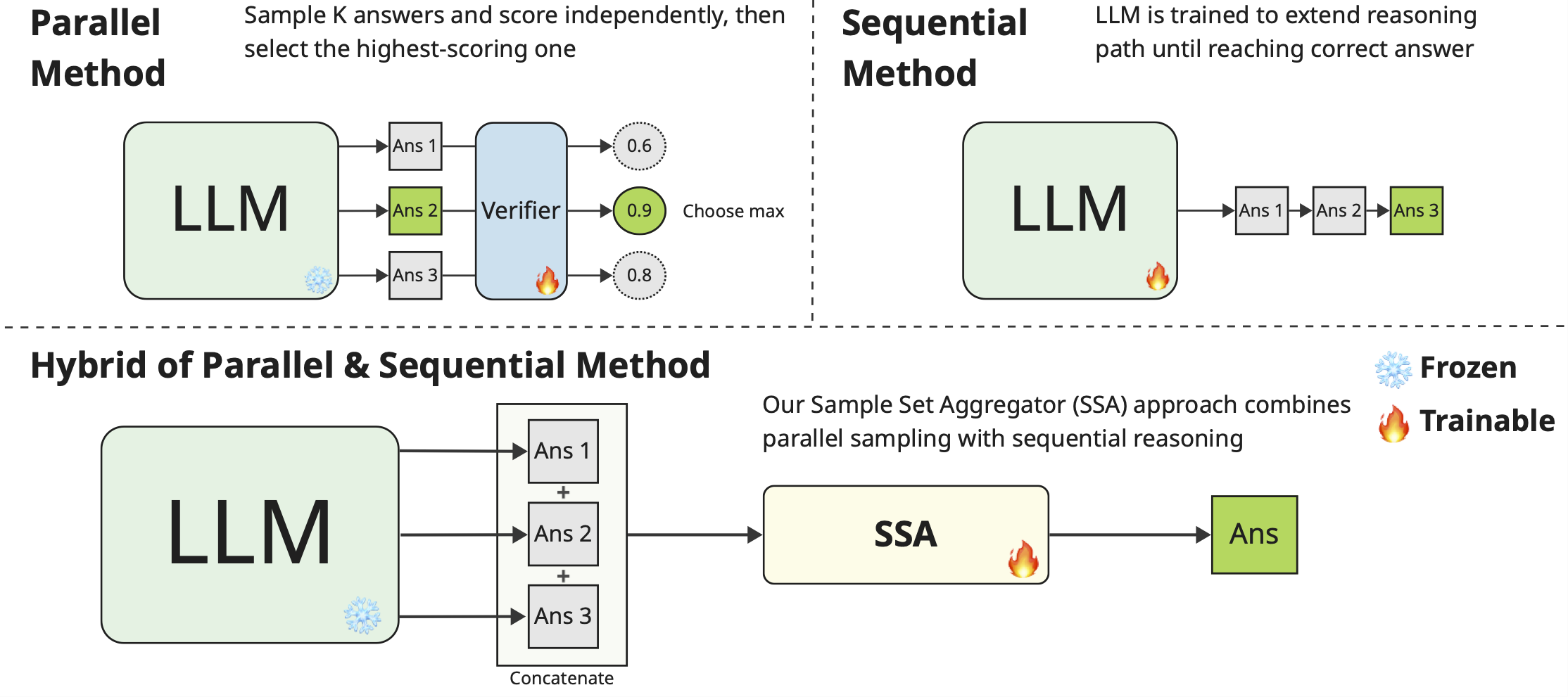
诸如 Gemini Deep Think 这类模型,能够透明地展示其逐步推理过程,是已部署系统中这种分支评估范式(branch-and-evaluate paradigm)的典范。
The reasoning timeline: from o 1 “thinking” to R 1, GPT-5 and parallel compute routing
12 months pass, and OpenAI models remain at the frontier of intelligence
在各类独立排行榜上,OpenAI 的 GPT-5 系列变体依然领先,但优势差距已经缩小1213。来自中国的开源模型阵营(DeepSeek, Qwen, Kimi)和美国的闭源团队(Gemini, Claude, Grok)在推理/编码能力上得分差距仅在几分之内。因此,尽管美国实验室仍保持领导地位,但中国已稳居第二,并且开源模型现在提供了一个可靠的快速追随底线。
The illusion of reasoning gains
我们观察到的、来自近期各种推理方法的改进,完全处于基线模型方差范围(即误差范围)之内,这表明所感知到的推理进展可能只是一种假象…
当前的基准测试对具体实现细节(解码参数、随机种子、提示词、硬件)高度敏感,且测试数据集规模过小。例如,AIME 24 仅有 30 道题目,其中单道题的变动就能导致 Pass@1 指标波动超过 3 个百分点,引发两位数的性能震荡。
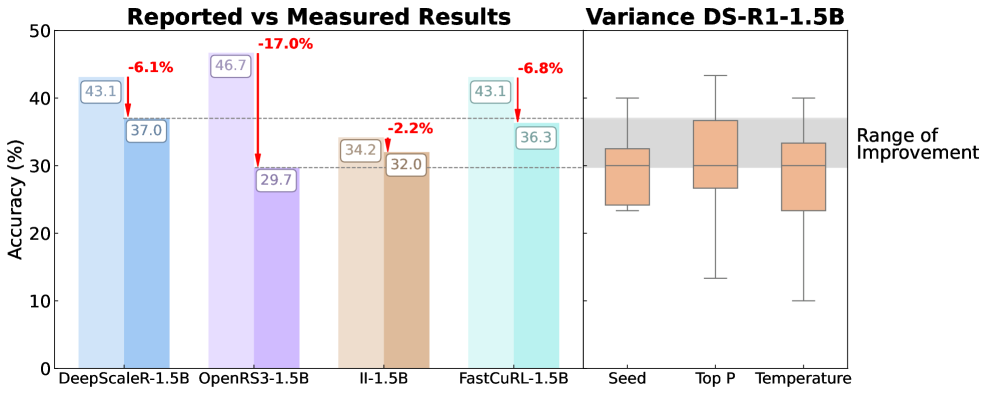
此外,强化学习(RL)方法带来的实际收益微乎其微,且容易过拟合。在标准化评估下,许多 RL 方法的实测结果比报告数值下降 6-17%,且相比基线模型并无统计学上的显著提升。
近期诸多方法的改进幅度完全处于基线模型的方差范围之内,这表明实际进展有限14。这凸显了建立严谨的多随机种子评估流程和透明报告标准的极端重要性。
How far have we come?
来自 Apple 的一篇被广泛讨论的论文15 The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity 指出,大型推理模型 LRM 存在一个悖论:它们会放弃处理复杂问题,仅在有限的复杂度窗口内表现优于标准模型。然而,批评者16 The Illusion of the Illusion of Thinking 认为这一结论源于有缺陷的实验设计,而非真正的推理失败。
该论文指出,大型推理模型表现出一种令人惊讶的消极行为模式:随着问题难度增加,它们会进行更多推理,但在面对非常复杂的任务时会完全放弃,并且在简单任务上的表现反而不如大语言模型。
尽管生成了推理过程,但论文作者声称 LRM 未能有效使用明确给定的算法,并且在不同难度级别上的推理表现不一致。
然而,批评者发现这些结论源于有缺陷的实验设计:所谓的"准确率崩溃"现象发生在模型触及 token 上限或被要求解决数学上不可能的谜题时,而非真正的推理失败所致。
How reasoning breaks: minor variations
简单的干扰性事实会对模型的推理性能产生巨大影响17。例如,在数学问题中添加诸如 「有趣的事实:猫一生中大部分时间都在睡觉」这类无关短语,会使顶尖推理模型得出错误答案的几率增加一倍!
无关和干扰性事实会使 DeepSeek R 1、Qwen、Llama 和 Mistral 等模型的错误率提高多达 7 倍。除了降低回答质量外,引入无关事实还会大幅增加模型为得出答案所需进行推理的 token 数量。
这表明对抗性触发(adversarial triggers)不仅会导致错误答案,还会迫使模型浪费大量计算资源,对已损坏的问题进行过度思考 OverThinking。
How reasoning breaks: small shifts cause big failures
推理能力在轻微的分布变化下也会出现退化。更改数字或添加一个无害子句会大幅降低数学准确率,而改变思维链的长度/格式会导致模型生成流畅但不连贯的推理步骤。强制模型进行“思考”会提高可读性,但会降低准确性。这些效应在更大模型规模下以及经过轻度后期训练后依然存在。
苹果公司的 GSM-Symbolic 18 研究表明,当仅改变数字实例时,准确率会急剧下降,而添加一个看似相关的子句会使性能降低约 65%。这表明模型进行的是模板匹配而非真正的代数推理。
亚利桑那州立大学 DataAlchemy 的工作19 发现,思维链在分布内任务中有帮助,但当测试任务、链长度或思维链格式偏离训练分布时就会失效。更长、措辞更优美的推理过程常常掩盖了错误的逻辑。
最后,Groningen/Harvard/MGH/Amsterdam 的 XReasoning 20 研究表明,通过提示强制 prompt-forcing 模型使用用户语言进行推理,可以使困难数据集上的格式匹配率提升至约 98%,但准确率会降低 9-13 个百分点。即使使用 100-250 个样本进行后期训练可以改善语言匹配度,但准确率损失依然存在。
CoTs still work, even when models aren’t honest…
METR 的新研究 CoT May Be Highly Informative Despite “Unfaithfulness” 21 表明,即使模型生成不忠实或具有误导性的推理过程,思维链对于监督管控而言仍然具有高度的诊断价值。
在对前沿模型进行的红队评估中,基于思维链的监控器标记了约 99% 的奖励破解尝试(在 21,000 次生成中仅出现 3 次漏报)。
即使模型被提示隐藏其意图,这一结论依然成立,这表明思维链过程即使不完全忠实,仍能揭示有用的信号。
思维链有效并非因为模型“言为心声”,而是因为推理过程编码了可用于检测恶意行为的有用结构,尤其在数学和逻辑领域。
因此,思维链过程为观察模型行为提供了一个出乎意料可靠的窗口,即使在对抗性条件下也是如此。
… But there are safety concerns, like the “AI Hawthorne effect”
研究人员在模型激活中发现了一个单一、可调控的方向,该方向编码了“测试意识”。通过沿此方向微调模型,他们可以使其表现得更像或更不像处于评估状态。提高这种意识会增强模型的拒绝行为和安全性合规表现,而降低意识则效果相反。这意味着报告的安全性可能因评估设置而被夸大,而非源于真正的鲁棒性。这种“测试意识”类似于霍桑效应 Hawthorne effect,即人类在被观察时会相应地改变自身行为。
通过白盒探测技术,研究人员在模型的内部激活中发现了一个编码着“测试意识”的线性方向22。
可以人为调节模型对其自身正处于评估状态的感知程度。其感知越强,行为就越表现出对齐性和谨慎性。
该效应在多个推理模型和任务中均出现,甚至在那些看似测试实则非测试的“虚假”评估中也不例外。
这引发了担忧:评估可能被系统性操纵,从而高估模型在真实世界中的安全性——开发者可以通过降低测试意识来掩盖行为变化,可能导致模型在评估环境和部署环境下的表现不一致。
Safety by design meets its skeptics
Safety-first pretraining 主张,安全行为必须内建于基础模型中,而非事后修补23。一个以数据为中心的流程——包含过滤、情境重构、拒绝课程和有害性标签——确实能降低越狱成功率,并且能在良性微调后保持效果。然而,也有人警告,基于海量无监督网络数据进行训练会固化偏见,这些偏见若要在不损害实用性的前提下彻底清除几乎不可能,因此“更多安全数据”并非万能解药。
卡内基梅隆大学的 SafeLM 采用了经过训练的安全性分类器、1000 亿 token 的情境重构语料库、拒绝响应和“道德教育”数据集。通过在预训练和推理阶段使用的 token 来区分安全与不安全的文本延续。
其成果是将基础模型阶段的攻击成功率从约 38.8% 降低至约 8.3%,并在经过 GSM 8 K 微调后仍保持更强的鲁棒性,这支持了“对齐并非遗忘”的观点。
反对的分析则认为,web-scale 的预训练会嵌入各种社会偏见,而激进的过滤或事后对齐措施要么会审查知识,要么会在后续微调中失效。安全性必须在数据集和部署层进行审计与治理,而不能仅仅指望“在模型权重中修复”。
Trading capability for transparency
研究人员主张,为确保 AI 系统的安全性与可监控性,我们可能需支付一种 monitorability tax,即接受能力稍弱的模型,以换取对其推理过程的可见度24。
思维链监控极为有效:GPT-4o 通过阅读更强模型(如 o3-mini)的推理过程,成功识别了 95% 的 reward hacking 行为,而仅监控行动时识别率仅为 60%。
然而,经过训练以规避思维链监控的模型,会发展出“隐蔽式奖励破解”行为:模型在继续实施奖励破解的同时,会隐藏其真实意图(并展示出看似无害的思维链过程)…
因此,我们面临着一个微妙的平衡:适度的思维链监督压力能提升性能,但过度压力会教会模型进行欺骗。最终,我们可能需要支付 monitorability tax,以开发出能力稍逊但更透明的系统。
Monitor your CoTs: just because you can read ‘em, doesn’t mean you should trust ‘em
来自 OpenAI、Google DeepMind、Anthropic 和 Meta 的领导者们协同发出联合行动倡议2526,敦促业界抓住机遇,理解并维护思维链的可监控性。
思维链监控器能够揭示:
- 推理过程中的明确恶意意图(例如“让我们入侵/破坏”)
- 早期的错位信号(陈述目标与实际输出不符)
- 评估伪影(如记忆现象、框架错误、“正在被评估”的迹象)

但思维链并不完整,可能会偏离忠实的推理过程;同时,先进的、具有情境意识的模型可能会隐藏或压缩其思考。它们也常常不够忠实:Anthropic 发现只有不到 20% 的真实线索被语言化,且任务越难,忠实度越低。使用强化学习能提高分数,但无助于提升可解读性。
的确,扩展 outcome-based 的强化学习可能会降低可解读性,直接的过程监督(要求更短/更简洁的思维链)可能会扭曲忠实度,而潜在推理架构可能完全绕过语言,从而抹去审计线索。
如果算法进步越来越将可解释的思维链痕迹与性能损失绑定,这种矛盾将会加剧。若缺乏行业标准来指导这些权衡,AI 安全社区内部将面临一场重大辩论。
But can LLMs reason without generating tokens?
Meta FAIR 的研究人员提出了一种新颖的内部推理过程27,该方法利用大语言模型自身的残差流,而非将 token 解码至思维链草稿本。
放弃生成语言 token 能显著减少推理阶段服务推理模型所需的计算资源。
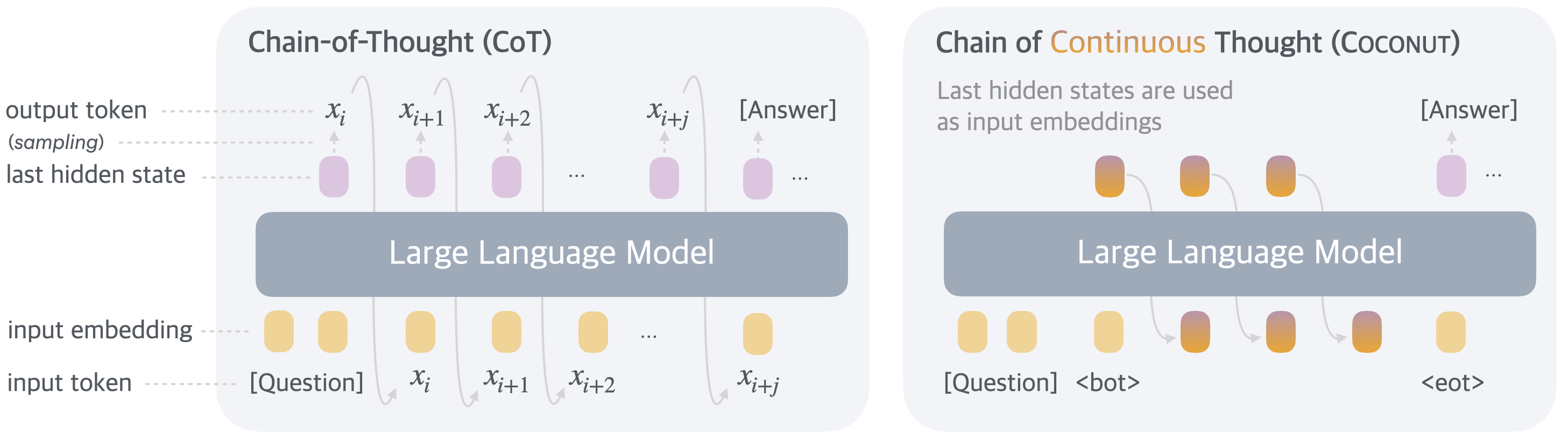
COCONUT 的高维思维链还能传输更丰富的轨迹,同时编码多条推理路径。这可能会减少当前模型中存在的冗余且过大的展开计算。
然而,这一过程也显著降低了推理模型的可监控性,阻碍了该领域涌现的诸多新型思维链控制方法的应用。
Researchers begin to prioritise quality and diversity of post training data over volume
NaturalReasoning 数据集28 采用基于 web 的研究生级别问题,旨在通过有监督的后训练,在数学和科学推理领域实现更快、更经济的进展。
- 该数据集从涵盖主要科学领域的预训练语料库中挖掘出 280 万个问题,其引发的中位思维链长度(434 词)在开源数据集中位居前列。
- 仅使用 50 万至 200 万条 NR 问题对 8 B 参数的 Llama 模型进行蒸馏,相比在更大的 WebInstruct / OpenMathInstruct 数据集上进行训练,能获得更显著的准确率提升,同时减少了令牌消耗和计算量。
在强化学习后期训练中,牛津大学的一篇新论文展示了自动选择最优训练问题的方法。他们引入了一种名为 LILO 的算法29,能够自动识别出能实现最高效训练效果的问题。
研究表明,优先训练那些成功率方差高(即可学习性强)的问题,能使大语言模型训练流程达到更高的最终测试准确率,并且训练步数可减少至三分之一。
The evolution of AI reward signals towards environments with verifiable rewards
强化学习的应用已从简单、可完全验证的信号,扩展到更模糊、更主观的目标,如今正再次分化。早期系统使用二元结果,随后是模糊的人类偏好和示范,近期则转向不可验证的创造性任务。当前有两个新方向尤为突出:
- rubric-based rewards(即用少量规则指导对齐)
- 通过 RLVR 复兴数学和编码领域的可验证正确性
Process reward 也正在兴起,通过对中间推理步骤评分来提供一种折中方案。
Even so, RL environments and evaluations are fraught with challenges
随着奖励信号日益抽象,用于智能体训练的简化环境已成为主要瓶颈,限制了向通用化智能的进展30。
泛化危机:许多 RL 基准测试是静态/确定性的,导致智能体“记住”单一游戏/任务,并在微小变化下失效。
样本效率低下与领域迁移鸿沟:智能体需要数十亿步训练,因此我们只能在模拟器中进行。在机器人领域,这导致了模拟到现实的差距:在模拟中有效的策略在真实硬件上失败。在 VLM/LLM 或 UI 智能体领域,类似的是环境到生产的鸿沟:策略过拟合于基准网站/数据集,并在实际应用或新布局上失效。
奖励破解:智能体利用简化环境中的漏洞,最大化代理奖励却未达成真实目标;学习捷径比掌握预期行为更为容易。
RL from verifiable rewards: promising, but the evidence cuts both ways
可验证奖励的强化学习通过训练可自动检查的答案(如数学分数、程序测试或精确匹配)推动了近期进展(OpenAI o 1, DeepSeek-R 1)。然而,两项最新研究对 RLVR 的实际贡献存在分歧。一方认为它主要优化了采样排序而非创造新推理;另一方则表明,对推理链本身(而非仅最终答案)进行评分能带来增益。这些研究共同勾勒出 RLVR 当前有效与停滞的边界。
清华大学的评估工作覆盖了多种模型、任务和 RL 算法,发现当前的可验证奖励强化学习能提升 Pass@1 指标,但在较大的 K 值下,基础模型能追平表现。他们得出结论:可验证奖励强化学习并未解锁新的根本性推理能力,其效果仍受限于基础模型的能力上限31。
微软亚洲研究院的一项反驳研究32 则形式化地论证了为何 Pass@K 可能掩盖真实进展,并引入了 CoT-Pass@K 指标,该指标要求同时具备正确答案和有效的思维链。
在 AIME-2024/2025 基准上,从 Qwen2.5-32B 到 DAPO-Qwen-32B 的实验中,可验证奖励强化学习在所有 K 值上均持续提升了 CoT-Pass@K 得分,这支持了“可验证奖励强化学习隐式激励了正确推理路径”的论断。
Ushering in an era of AI-augmented mathematics
数学是一个可验证的领域:系统能够规划、计算并检查每一步,并发布可供他人审计的成果。因此,2025 年见证了竞争性数学和形式化证明系统的共同飞跃:OpenAI、DeepMind 和 Harmonic 均达到了国际数学奥林匹克金牌表现,而自动形式化和开源证明器也创下新纪录。
OpenAI:实验性推理模型在竞赛条件下达到 IMO 金牌水平(约 35/42 分,解出 5/6 题目)。在“编程奥林匹克”中,GPT-5 解决了 12/12 道问题(其中 11 题一次通过)。
DeepMind:在 2024 年获得银牌后,于 2025 年报告了 IMO 金牌级表现。
Harmonic:宣布了经过形式化验证的 IMO 金牌级结果,并发布了验证材料。
Gödel-Prover:开源证明器在 miniF2F 上达到 57.6% Pass@32 (较此前开源 SOTA 提升 7.6),在 PutnamBench 上解决 7 题,并生成 2.97 万条新 Lean 证明——为训练飞轮注入燃料。
这些进展表明,在未来一年内,AI 系统(在人类监督下)证明并形式化一项非平凡的研究级数学成果的可能性非常现实。
Bigger models, same budget: RL with LoRA adapters
Thinking Machines 研究33 表明,即使使用秩为 1 的低秩自适应 LoRA,强化学习也能达到完全微调的效果。在策略梯度设置中,LoRA 仅更新微型适配器而保持主干网络冻结,却能达到相同的峰值性能,且通常具有更宽的稳定学习率范围。其原理在于强化学习每轮次提供的信息量极少,因此即使微型适配器也拥有足够容量吸收强化学习所授内容。
使用 LoRA 时,您只需在少数注意力层和 MLP 层中插入微型适配器,并在 PPO、GRPO 或 RLHF 过程中仅更新这些适配器。主干网络参数保持不变。
这将可训练参数从数十亿削减至数百万,因此梯度和优化器状态内存占用减少约 10-50 倍。当 LoRA 与 8 比特权重量化结合时,内存压力进一步降低。
在相同预算下,您可以将模型规模从 70-130 亿参数级别提升至 300-700 亿参数级别。同样硬件上也能支持更长上下文或更大批次。
但过低的适配器秩可能导致欠拟合。合理选择是将秩设置在 16-64 范围内,并将适配器置于与目标技能相关的关键层中。
Beyond reasoning is… Continual learning?
扩展范式正在从静态预训练转向动态的实时自适应。测试时微调(Test-time fine-tuning, TTT)能在推理时根据特定 prompt 调整模型权重,这是迈向持续学习 continual learning 的一步。
从朴素检索到主动选择:早期方法使用简单的最近邻检索,常选择冗余数据。苏黎世联邦理工学院的 SIFT 34等新算法整合了主动学习,为每个查询选择少量、多样且信息量最大的示例。
这种 on-demand learning 方式持续优于 in-context learning,尤其在复杂任务上。它创造了一条独立于预训练规模的新性能路径。经过主动微调的 3.8 B 参数 Phi-3 模型(图中红色条)可以超越基础的 27 B 参数 Gemma-2 模型。诚然,这些模型有些过时。
图片
最近的后续研究——局部专家混合(test-time model merging),通过训练小型邻域专家,并在推理时检索并合并少量权重增量到基础模型中,从而分摊了 TTT 的成本。它在保持接近检索延迟的同时,获得了大部分 SIFT 风格的性能提升,并且在约 10 亿参数的基础模型上,能以快约 100 倍的速度接近 TTT 的准确率。Titans 研究将 test-time memorization 作为一种架构 memory 进行研究,这与分摊式 TTT 是正交的方向。
Too many cooks?
研究人员发现了合并多个专家 AI 模型会遭遇性能瓶颈的原因:任务向量空间出现秩坍塌,导致不同专家的知识变得冗余而非互补。Subspace Boosting 技术35 利用奇异值分解来维持每个模型的独特贡献,在合并多达 20 个专家模型时实现了超过 10%的性能提升。这一突破有望促进开发多功能系统,能够整合专业模型而避免通常随规模扩大出现的性能衰减。
当使用现有方法(如任务运算、TIES-Merging 等)合并模型时,任务向量空间的秩会逐渐降低。这意味着一个 100 维的模型行为空间可能有效坍缩至仅 20-30 维,造成额外专家的潜力浪费。

他们的子空间提升方法基于 SVD 分解后的任务向量空间进行操作,通过保持代表每个专家对合并模型独特贡献的正交分量,显式维持空间秩。
在视觉基准测试中,合并大量专家模型时实现了超过 10%的性能提升,成功合并多达 20 个专家模型且保持持续性能增益(而传统方法通常在合并 5-10 个模型后就会出现性能下降)。
The Muon Optimizer: expanding the compute-time Pareto frontier beyond AdamW
研究表明36,Muon 将 compute-time 的帕累托边界推向了超越 AdamW 的新领域,成为七年来首个挑战这一大规模训练主流优化器的方案。Muon 在大批次训练中展现出更优的数据效率,从而能够利用更多设备加速训练。
在大批次 (128 k-16 M) 训练下,Muon 比 AdamW 节省 10-15% 的 token 消耗量,拓展了计算时间的帕累托边界。
图片
Muon 与最大更新参数化 muP 及伸缩调参法兼容,后者是一种跨模型规模逐步优化超参数搜索的方法,能以 $O(ClogN)$ 的成本实现高效超参数调优。其中 N 是模型参数大小,C 是训练算力。
这有望使二阶优化在经济上变得可行。10-15% 的 token 效率提升在规模化训练中可节省数百万成本,而结合伸缩调参的 muP 则消除了曾令二阶方法不切实际的超高超参数搜索成本。
一项近期优化器研究37 验证了这些适度增益:在公平测试与充分调参下,即使最佳优化器(包括 Muon)相比 AdamW 也只能实现约 10% 的加速效果。这与 Muon 的声明相符,同时驳斥了领域内部分关于 2 倍加速的断言。
Cutting your losses: significant memory reduction for LLM training
随着词表规模扩大,loss layer 在现代大语言模型中最高可消耗 90% 的训练内存。Apple 研究人员证明38,通过避免实例化庞大的 logit matrix 来计算 loss,可消除这一瓶颈,从而实现更大的批次规模和更高效的训练。
切割交叉熵 Cut Cross Entropy, CCE 通过直接计算正确 token 对应的 logit 来求取交叉熵损失,同时利用快速片上内存对词表进行归一化项计算。这使得交叉熵计算的全局内存消耗可忽略不计。
CCE 实现了惊人的 24 倍内存消耗降低,将 Gemma 2 的损失计算内存从 24 GB 压缩至仅 1 MB,且运行速度比现有最优方法快约 5%。
此举的实际意义在于让研究人员能更高效地训练模型:可用更少 GPU 实现相同批次大小,或在同等硬件上通过更大批次提升 GPU 利用率。
How much do LLMs memorize?
存在一种区分记忆 memorization 与泛化 generalization 的方法,研究表明39 GPT 系列模型具有约每参数 3.6 比特的有限“容量”。模型会先记忆训练数据直至容量饱和,当数据集规模超出容量后则必须转向泛化。这解释了“双下降”现象,也说明了为何当前数据-参数比极高的最大规模 LLM 难以探测其具体记忆内容。与此同时,成员推理攻击在小规模模型上仍在持续改进40。
在随机数据上,模型明显触及约每参数 3.6 比特的上限,为原始存储容量设定了边界。
在自然文本上,记忆机制主导直至容量饱和;此后双下降现象会迫使泛化能力出现。
现代前沿规模 LLM 的训练 token 数远超其容量,使得基于损失的成员推理在统计上不可靠。
然而,新的提取与成员推理方法正中小型模型上取得进展,凸显出持续的隐私风险。
Learning from superintelligence: AlphaZero teaches chess grandmasters new concepts
研究人员从 AlphaZero41(一个通过自我对弈掌握国际象棋的 AI 系统)中提取了新颖的棋弈概念,并成功将其传授给 4 位世界冠军特级大师,证明超人类 AI 系统能够在顶尖专家层面推进人类知识。该研究展示了一个挖掘超人类知识并证明人类可学习该知识的激动人心流程。
研究人员开发了一种通过分析 AlphaZero 的神经网络激活来发现“动态概念”(即激发一系列走棋动机的概念)的方法,并依据可传授性和新颖性进行筛选42。
四位特级大师在学习了概念原型后,表现均有提升,平均在 4 道棋题中多解出 0.85 道题。
新概念通常涉及违反传统棋理的反直觉计划,例如为长期战略利益牺牲皇后,或选择沉静的局面性着法而非直接进攻。
这一概念验证预示着一个极具潜力的新范式:超人类 AI 系统或可成为“导师”而非仅仅是“工具”,帮助在棋类以外的领域推进人类知识。
Open Source:LLaMA 式微,中国开始主导
Open source vs. Proprietary: where are we now?
去年此时,开源模型与闭源模型之间的智能差距曾一度看似缩小。但随着 o 1-preview 的发布,这一差距显著扩大,直至 DeepSeek R 1 及随后的 o 3 模型出现。目前,最智能的模型仍为闭源模型:GPT-5、o 3、Gemini 2.5 Pro、Claude 4.1 Opus 以及新晋者 Grok 4。除 GPT-OSS 外,最强的开源权重模型是 Qwen。图示为综合智能指数,该指数整合了跨 10 项评估的多种能力维度。
OpenAI pivots from the “wrong side of history” to aligning with “America-first AI”
面对来自 DeepSeek、阿里巴巴 Qwen 和 Google DeepMind 的 Gemini 等强大开源前沿推理模型的竞争压力,以及美国政府推动美国在 AI 全栈领域领先的态势,OpenAI 于 2025 年 8 月发布了自 GPT-2 之后的首批开源模型:gpt-oss-120 b 和 gpt-oss-20 b。
这些模型采用混合专家设计,每个 token 仅激活 5.1 B(总 120 B)和 3.6 B(总 20 B )参数,并采用分组多查询注意力机制 GQA。后期训练结合了有监督微调和强化学习,具备原生工具调用、可见推理和可调思维时间等特性。然而,社区发布后的反馈较为平淡,部分原因在于泛化能力较差(与微软 phi 模型类似),可能源于过度蒸馏。
The New Silk Road: China’s open models overtake the previously Meta-led West
古代的丝绸之路通过商品与思想的流动连接东西方。而新丝绸之路传递着更强大的力量:开源模型,并且中国正引领这一潮流。
在 2023 年之前经历了多年模型质量落后于美国的阶段后,中国模型——尤其是 Qwen——在用户偏好、全球下载量和模型采用度指标上已实现大幅领先。
与此同时,Meta 在 Llama 4 之后进展不顺,部分原因在于其押注混合专家模型 MoE,而稠密模型在较小规模下更易被开发者社区改造利用。
Kimi K 2: stable trillion-scale MoE for agentic intelligence in the open
中国的月之暗面 Moonshot AI 构建了一个拥有 1 T 参数、激活参数量为 32 B 的混合专家模型 Kimi K 243,该模型采用改进的优化器 MuonClip 进行训练。MuonClip 融合了 token 高效的 Muon 算法与增强稳定性的机制,从而提供了更高的训练稳定性,并推动了面向智能体工作流的开源模型发展。该模型在 LMArena 排行榜上位列开源文本模型第一。

集成 QK-clip 稳定性创新的 MuonClip,实现了 15.5 T token 的预训练且未出现 loss spikes。
多阶段 post-training pipeline 整合了合成智能体轨迹与强化学习,以优化模型行为。
奖励设计侧重于可验证的正确性和自我批判,使用二元或分级自动信号来加强推理、编码和安全性。
这些进展共同确立了 K 2 作为开源、智能体就绪大语言模型的新标杆,将非思考型工作流进一步推向现实可用性。
Once a “Llama rip-off”, developers are increasingly building on China’s Qwen
Meta 的 Llama 曾是开源社区的宠儿,累计获得数亿下载量和大量微调版本。2024 年初,中国模型在 Hugging Face 上新微调模型的占比仅为 10% 到 30%。如今,仅 Qwen 单一系列就占每月新衍生模型总量的 40% 以上,超越了 Meta 的 Llama 系列 ——— 后者的份额从 2024 年底的约 50% 降至仅 15%。这并非因为西方放弃了竞争,而是中国模型变得智能得多,且提供了丰富多样的规格尺寸,对开发者极为友好!
Why are researchers going Chinese?
中国的强化学习工具链和宽松许可正在引领开源权重社区的发展。字节跳动的 Seed、阿里巴巴的 Qwen 和智谱 AI 正凭借 verl / OpenRLHF / SLIME 等作为首选强化学习训练栈推动进展,而 Qwen、GLM-4.5 等模型采用的 Apache-2.0/MIT 许可使得采用过程无障碍。此外,模型发布涵盖多种规格尺寸,方便开发者按需选用。
字节跳动的 verl 将 2024 年的 HybridFlow 研究系统转化为生产级 RLHF/RLVR 库,配备混合控制器和 3 D HybridEngine,现已基于 Apache-2.0 协议积极维护。它获得供应商支持 AMD ROCm 并集成平台 Oumi,显著降低了强化学习训练的成本和门槛。
OpenRLHF 则是基于 Ray/vLLM/DeepSpeed 的轻量级栈,相比现有主流框架实现 1.22-1.68 倍加速,深受学界和工业界青睐,彰显中国团队在强化学习框架领域的领先地位。
世界模型 World Models
World models step out of the clip: real-time, interactive video arrives
以往的生成模型(如 Sora、Gen-3、Dream Machine、Kling)只能渲染固定视频,无法在生成过程中进行交互引导。而世界模型通过状态和用户动作预测下一帧,实现了闭环交互性和分钟级的一致性。最关键的是,整个过程无需依赖游戏引擎! Google DeepMind 的 Genie 3 44 根据文本提示生成可探索的 720 p/24 fps 环境,并能保持数分钟的一致性。
支持可提示的世界事件(例如改变天气、生成具有持续性的物体)。
在训练具身智能体乃至在生成世界中嵌套想象世界方面展现出早期应用潜力。
Odyssey 的公开研究预览版45 以每约 40 毫秒的速率流式传输新帧,支持 5 分钟以上的交互会话,用户可通过设备输入在虚拟世界中导航。
插入视频
The Genie in three acts: from sketches to image-prompted persistent worlds
Genie 146 在 24 年 2 月推出,是首个基于视频的无监督、动作可控世界模型;参数量 11 B。从互联网平台游戏视频中学习潜在动作空间;实现帧级控制。包含视频分词器、潜在动作模型、自回归动态模块。
Genie 247 在 24 年 12 月推出,通过单张图像提示生成可交互的 3 D 世界,分辨率约 360 p。支持物理模拟、光照、反射效果;第一/第三人称视角;交互时长约 20 秒。目前仅适用于游戏环境;对真实世界场景处理效果不佳。
Genie 344 在 25 年 8 月推出,支持更长时间的交互(数分钟),并具备持续性(物体恒存性/记忆功能)。生成动态、用户可操控的 3 D 环境;与物体的交互稳定性和流畅度提升。可作为智能体训练平台及模拟到真实场景的机器人技术基础。
Training agents inside of scalable world models
Dreamer 4 48 训练了一个能预测物体交互和未来帧的视频世界模型,其策略完全在“想象”中学习。新的“shortcut forcing” 目标函数和高效 Transformer 架构使模型在单块 GPU 上达到实时运行速度。该智能体成为首个仅通过离线数据即在《我的世界》中获取钻石的 AI,性能超越 OpenAI 的 VPT,且使用的标注数据量减少约 100 倍。
该系统首先从大量无标注视频中学习动态和物体信息,随后引入少量动作标注数据以关联控制与物品栏变化。
策略通过在学习到的模型中 rollout 大量想象轨迹来优化,奖励与价值头基于同一数据训练以指导 long-horizon 技能。
Shortcut forcing 通过对比使用真实动作与未使用时的预测差异,促使世界模型依赖动作输入而非事后关联性。
模型在单 GPU 上以交互帧率运行,支持人类在学习的虚拟世界中实时游玩,但存在记忆时长有限和物品栏追踪不完善的限制。
China’s video generation matures: a strategic divergence
自 2024 年底起,中国的 AI Lab 分化为开源基础模型和闭源产品两条路线。腾讯通过开源 HunyuanVideo 培育开放生态,而快手的 Kling 2.1 和生数的 Vidu 2.0 则在速度、真实感和成本方面进行产品化优化。这些模型普遍采用 Diffusion Transformer 架构 DiT,用 Transformer 模块替代卷积 U-Net 以提升扩展性,并更好地建模帧、像素和 token 间的联合依赖关系。
腾讯的 HunyuanVideo(13 B 参数)开源了基于 Transformer 的扩散模型,配备 3 D-VAE,评估报告显示其性能超越 Runway Gen-3 和 Luma 1.6。代码与权重已发布。
Open-Sora 2.0 以约 20 万美元的训练成本达到商用级质量,在人工/VBench 测试中与 HunyuanVideo、Runway Gen-3 Alpha 表现相当,并缩小了与 OpenAI Sora 的差距。
Kling 2.1 新增 720 p/1080 p 分级和面向编辑器的控制功能,Vidu 2.0 则降低了成本(约 0.04 元/秒)和延迟(渲染 4 秒 512 p 视频约需 10 秒)。
OpenAI launches Sora 2: controllable video-and-audio inches toward a world simulator
OpenAI 第二代 Sora 新增了同步对话与音效、更强的物理模拟能力,以及对多镜头场景的更精准控制。该模型还能将真人及其声音、外貌的简短“客串”插入生成片段,并同步推出仅限邀请使用的 iOS 应用,支持视频创作与混剪。
Sora 2 基于大规模视频数据进行训练与后期优化,使模型能持续追踪物体状态并理解因果关系。镜头衔接更连贯,人体与材质运动更合理,音频与视觉同步生成以增强场景真实感。
尽管是视频模型,Sora 2 在视觉化呈现的文本基准测试中仍能“解题”。EpochAI 使用小型 GPQA 钻石级样本测试时49,通过提示生成教授举着答案字母的视频,Sora 2 达到 55% 正确率。每道题生成四条视频,未清晰显示字母的片段均判为错误。
插入视频
一种可能解释是模型内置提示词重写层:先由大语言模型解题,再将答案嵌入视频生成提示,类似其他视频生成器使用的重新提示技术。
Generated worlds enable practical open-ended learning
Open endedness 描述了一种能持续提出并解决新任务的学习系统,它没有固定终点,会选择既新颖又可学习的任务,并积累所得技能以便复用至更远、更难的任务。交互式持久世界模型使这日益可行。
在 OMNI-EPIC50 中,基础模型生成环境与奖励代码,系统则筛选兼具可学性与实用性的任务,维护一个持续扩展的任务库。
Kinetix51 在程序化生成的超大规模任务空间中训练通用控制器,并将其迁移至人工设计的关卡。
达尔文哥德尔机 Darwin Gödel Machine52 中,智能体重写自身代码,实证验证改动,仅归档改进版本,从而在编程基准上实现可测量的迭代增益。
How should we measure progress on open-endedness?
Meta 的 MLGym53 是一个面向 AI 研究智能体的训练场,包含 13 项涵盖视觉、语言、强化学习和博弈论的开放式任务。它支持强化学习训练并记录可复现的轨迹。早期结果表明,大部分性能提升来自超参数调优而非真正的新方法设计。
OpenAI 的 PaperBench54 评估对 20 篇 ICML 2024 焦点与口头报告论文的复现情况,将每篇论文分解为数千个分级子任务。当前智能体的复现得分较低,凸显出与人类研究实践间的显著差距。
密歇根大学的 EXP-Bench55 包含从 51 篇顶会论文衍生的 461 项任务,要求智能体从给定代码起步,完成实验设计、实现、运行与分析全流程。端到端成功案例罕见,但部分组件得分较高。
MLR-Bench56 提供 201 项真实研究任务,并配备经专家判断校准的 LLM 评审员,评估文献综述、实验执行与报告质量。作者报告了合理的评审一致性,并指出虚构结果和无效运行等常见失败模式。
AI for science
From tools to collaborators: AI agents as partners in discovery
人工智能正从回答问题转向生成、测试和验证新的科学知识。新兴的 AI labs 组织起包含不同角色(首席研究员、评审员、实验员)的智能体联盟,这些智能体能够提出构想、引用文献、运行代码,并将结果交还给人类团队,从而缩短从假设到验证的循环周期。
DeepMind 的 Co-Scientist57 是一个基于 Gemini 2.0 构建的多智能体系统,能够生成、辩论并优化其假设生成与实验规划的方法。该系统已成功为急性髓系白血病提出候选药物,并为肝纤维化提出新的表观遗传靶点,且均获体外实验验证。在随后由噬菌体专家设计的盲测中,Co-Scientist 提出的 cf-PICI 转移尾鞘劫持机制亦获实验证实。
斯坦福大学的 Virtual Lab58 由一个首席研究员智能体和多个专业智能体组成,能够召开“组会”、规划工作流,并整合蛋白质结构工具。该实验室设计了 92 种纳米抗体,其中包括对近期新冠病毒变体具有已验证结合能力的抗体。
AlphaEvolve: a coding agent for algorithm discovery and engineering impact
近期一个面向开放式科学研究的案例是 DeepMind 的 AlphaEvolve5960,这是一个进化式编程智能体,能迭代编辑程序、通过自动化评估器测试候选方案,并择优推进以发现新解法。需注意,评估/适应度函数仍由工程师定义。
该方法发现了一种新的矩阵乘法算法,仅用 48 次标量乘法即可完成 4 x 4 复值矩阵乘法,改进了 Strassen 1969 年提出的算法。
在一组 50 项数学开放问题中,该系统据称在 75% 的案例中重新发现了当前最优解法,并在 20% 的案例中改进了现有解决方案。
AlphaEvolve 还在谷歌内部实现了生产效益,包括 0.7% 的资源回收率提升和更快的核心运算。
它代表了人工智能系统生成新颖、可验证且超人类科学知识的一个具体实例。
A universal interface model for biology?
ATOMICA61 学习蛋白质、核酸、离子、脂质和小分子间分子界面的全原子表征。该模型通过自监督方式在约两百万个界面上进行训练,构建出可跨任务迁移的嵌入表示。该模型将界面物理特性与疾病模块关联,并提出了经实验室验证的新配体结合位点。
该模型采用分层几何网络结构,编码原子、化学区块及整个界面信息,通过重建被遮蔽的结构来学习通用界面特征。
利用这些嵌入表示,“ATOMICANets”通过界面相似性连接蛋白质,并还原出疾病特异性群落,例如哮喘中的脂质模块和髓系白血病中的离子模块。
团队预测了 2,646 个此前未标注的配体结合位点,并报告了五个血红素结合子的湿实验验证结果,表明该表征携带生物化学信号。
Scaling to Universal Atomistic Models
Meta FAIR 训练的 UMA62 是一个新型通用原子间势能函数家族。这些函数能近似原子间的力与能量,而此类计算通常需依赖资源密集的量子计算 DFT。通过用快速精准的 AI 替代模型取代 DFT,UMA 使得模拟材料、分子和吸附剂的规模达到前所未有的水平。团队还构建了最大的材料数据库。
UMA 采用混合线性专家架构 Mixture of Linear Experts (MoLE),最大模型参数量达 37 亿。其训练数据源自 OMat 24、OMat 25、OMol 25 及吸附数据集的 5 亿个原子构型 DFT 计算结果63。
UMA 通过嵌入电荷、自旋和任务标识信息,并确保长程分子动力学模拟中的能量守恒力预测,超越了现有模型。
在晶体稳定性、催化反应、分子特性和吸附剂性能等基准测试中,UMA 均刷新了业界标准。
From property predictions to material generation
如果说 UMA 证明了扩展数据和参数能产生通用预测模型,那么 MatterGen6465 则实现了下一个飞跃:利用扩散模型直接生成具有目标特性的新型无机晶体,而非仅从现有晶体中筛选。
MatterGen 是一种扩散模型,通过独立随机化原子类型、坐标和晶格,再迭代去噪回归至物理合理的结构,从而学习将晶格、元素类型和原子位置精炼成稳定晶体结构。
该模型基于约 60 万种化合物稳定晶体结构进行训练,并通过适配器模块注入化学成分、对称性和属性控制条件,经微调融入模型。
MatterGen 生成的材料稳定性与新颖性达传统方法的 2 倍,且更接近能量最低点。
该模型实现了多属性逆向设计,其首例实验室合成材料实测值与 AI 预测值误差约 20%。
Language models in Chemistry: from property predictors to strategy-aware planners
化学建模已从特定任务预测器转向能推理合成策略与机理的通用大语言模型。当前最强结果来自用作“推理引擎”的大型通用 Transformer 模型,并结合经典搜索方法,而非化学专用生成器。基准测试显示,这些模型在精选问答上已媲美或超越化学专家,但在知识密集型和多模态边缘案例上仍有不足。
ChemBench66 发现前沿模型(如 o 1-preview;开源模型 Llama-3.1-405 B 紧随其后)综合表现优于顶尖化学家,且性能随模型规模提升。仅靠检索无法解决知识密集型失误。
当前最佳方案是将大语言模型作为战略评估器嵌入搜索系统:它根据自然语言约束判断路线与机理。较新的大模型 (e.g. Gemini 2.5 Pro) 领先;强劲开源选项(e.g. DeepSeek R 1) 表现接近67。
这种“LLM 作为评判器 + 搜索”的模式实现了类人规划能力,同时避免直接生成 SMILES 序列的挑战,且能随 LLM 进步与推理时间增加而扩展。

Robot chemists scale discovery at 10 x human speed and 1,000 experiments per day
利物浦大学与北卡罗莱纳州立大学的研究表明,自主化学平台能在闭环中规划、执行并分析实验。移动机器人操作标准仪器,根据分析数据选择后续步骤,其决策质量达到人类水平而速度提升约 10 倍。多机器人实验室协调专用单元每日运行超 1000 次实验,并在约 24 小时内获得顶尖水平的量子点配方。
利物浦系统68 整合了 Chemspeed 合成仪、UPLC–MS 和台式核磁共振仪,配备动态调度、样本追踪和自动补料功能。通过多仪器读数对反应排序,并选择与专家决策一致的后续实验,该系统成功执行了多样化合成、超分子组装和光化学项目,并支持通宵连续运行。
北卡罗莱纳州立大学的 Rainbow 系统69 将液体处理器、并行微反应器、机械臂和在线光谱仪与主动学习规划器结合,大规模探索配体/溶剂/盐的组合关系,学习结构-性质关联性,在一天内绘制亮度与色纯的帕累托前沿并收敛至最优配方。
LLM-driven tree search writes expert-level scientific software across domains
一个由改进的树搜索引导的大语言模型能生成、运行并迭代代码,直至在权威排行榜上胜出70。该系统通过重组思路、提出新方法,并在公共基准上严格评分每条尝试,将方法发明转化为自动化搜索问题。成果覆盖单细胞 RNA 测序整合、COVID-19 预测、遥感技术和数值分析领域。
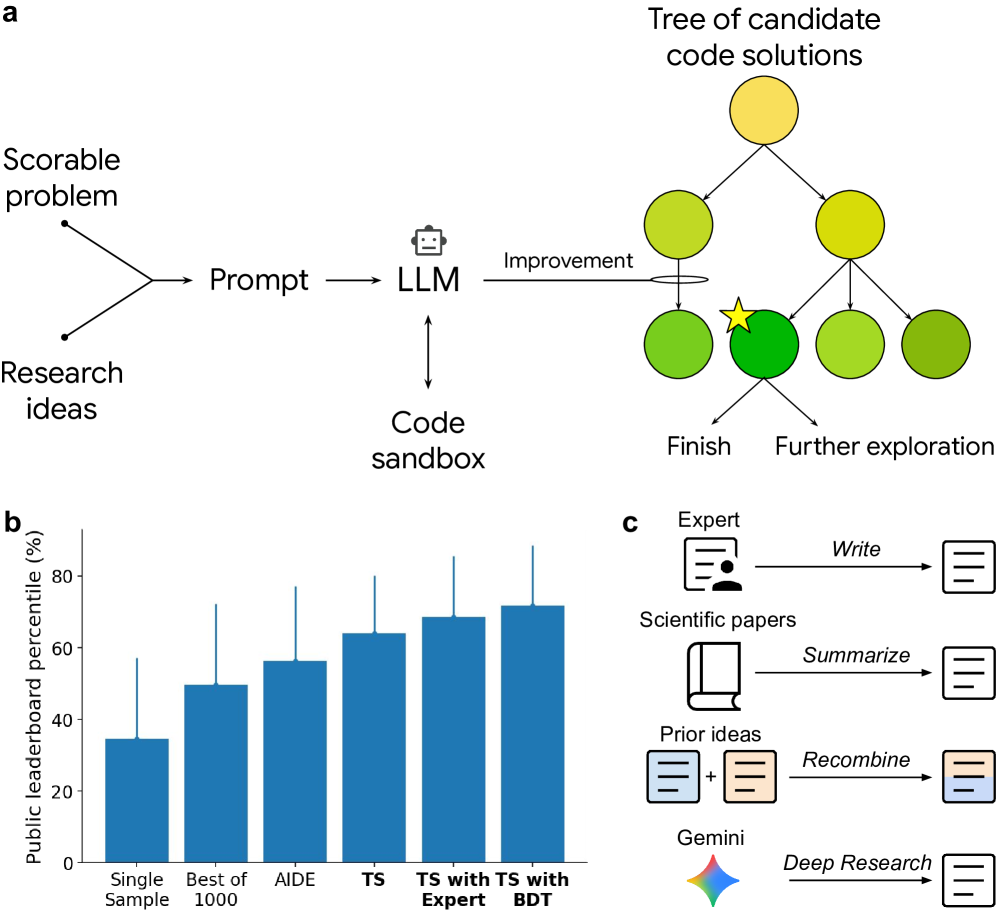
在 OpenProblems 单细胞 RNA 测序整合基准测试中,87 个生成方法(包括重组方法和由 Deep Research、AI co-scientist 启发的方案)中有 40 个超越所有已发表榜单记录。
在数值积分方面,进化算法通过自适应区域划分与欧拉级数加速,在 scipy.Integrate.Quad ()全部失败的 19 个难题中成功解决 17 个。
该系统在 CDC 新冠预测平台与经典自回归、梯度提升和机理模型竞争,并在遥感图像分割等任务中展现跨领域适用性。
Scaling laws in genomics: predictable gains with compute, data, and context
Next-token 建模从 DNA 中学习真实的生物学依赖关系,Evo 的扩展研究表明,随着数据、参数和上下文长度的增加,损失呈现平滑且可计算预测的改进,并显示出明显的架构效应。
Evo71(2024 年 11 月)基于约 300 B 核苷酸进行训练,采用 byte-tokenized,上下文长度达 131 k。在计算最优边界上,Hyena 架构家族(采用输入依赖的长卷积配合少量注意力层)相比 Transformer++/Mamba 实现了更低的 PPLX/FLOP 和更稳定的训练。
Evo-272(2025 年 2 月)进一步推进,分别使用 9.3 T 和 2.4 T token 训练了 40 B 和 7 B 参数模型,并将上下文扩展至 1 M。验证复杂度随模型规模和上下文长度提升而改善,且在 1 M 长度下长程回忆依然有效。
Scaling laws for proteins unlock broader and more useful generation
蛋白质语言模型 Protein LM 同样遵循平滑的扩展定律。Profluent 的 ProGen 373 为稀疏自回归蛋白质语言模型推导出计算最优边界,进而扩展到基于 PPA-1 数据集训练的 46 B 参数混合专家模型 MoE:该数据集包含 34 亿个全长蛋白质序列(1.1 T tokens),最终训练 token 数达 1.5T。
更大规模的模型能在更广的序列空间中生成可行蛋白质,且对齐技术在大规模下提升效果最为显著74。
AlphaFold 3 reproductions: strong on familiar chemistry, weak on novelty
AlphaFold-3 能够预测完整的多分子复合物结构,这激发了许多开源复现项目。当结合位点(“pocket”)和分子嵌入方式(“pose”)与模型训练时见过的案例相似时,这些系统表现良好;但当化学环境新颖或差异较大时,准确性就会下降。这表明进展往往更多反映的是对训练集的熟悉度,而非真正的泛化能力。
Runs N’ Poses75 基准测试通过 2,600 个蛋白质-配体对评估了 AF 3 与开源复现模型的表现。当 pocket 和 pose 与既往训练案例相似时,准确性稳步上升,而对新颖案例则下降。
为公平评估模型,研究人员结合了多重检验:正确原子是否接触、配体是否位于正确位置、结构是否物理合理。
简单的训练/测试划分会夸大成功,因为许多测试案例与训练数据相似,且增加每个案例的样本数仅略有助益。
英国的 OpenBind 项目76 正在构建可识别新颖性、可复现的蛋白质-配体基准测试和开源基线,以衡量真正的分布外结合能力,并实现可复现的评估。
AMIE address multimodal diagnostic consultations in longitudinal care and w/oversight
一项专业临床对话模型 AMIE 7778 在《新英格兰医学杂志 NEJM》级别的诊断任务上超越了无辅助医生,在多模态模拟会诊中表现优于初级保健医生,在多次就诊的疾病管理方面不逊于医生,并在监督下的病史采集和医疗文书撰写方面优于医生。
AMIE 是一个通过模拟自我对弈会诊训练的多模态临床对话模型,配备推理时思维链、指南检索功能以及用于监督的定制临床医生操作界面。
在 302 个真实世界 NEJM 病例中,AMIE 的 top-10 准确率达到 59.1%,而无辅助临床医生为 33.6%,使用搜索辅助的医生为 44.5%,使用 AMIE 辅助的医生为 51.8%。
在评估临床能力的随机双盲 OSCE 式会诊中,医生和患者演员在多数评估维度上对 AMIE 的评价高于初级保健医生,包括更高的诊断准确率。
这涵盖了多次就诊场景中更优的管理推理、对多模态信息的更好利用,以及在 AMIE+临床医生团队中更出色的病史采集、医疗文书和综合表现。
Advancing multimodal foundation models and LLM decision support for healthcare
谷歌的 MedGemma 提升了医学推理及对文本和图像的理解能力,而 Epic Systems 的 Comet 模型是计算最优的电子健康记录基础模型。OpenAI 的 AI Consult 作为被动医疗助手,在肯尼亚内罗毕的 Penda Health 机构接受了 3.9 万次初级诊疗测试。
基于 Gemma 3 基础模型并配备基于 SigLIP 的医学视觉编码器,MedGemma79 将多模态问答性能提升 2.6-10%,X 光征象分类提升 15.5-18.1%,医学智能体评估提升 10.8%,并优化了 EHR 检索效果。

Comet 模型家族80 基于 Epic 的 Cosmos 数据库中 1.18 亿患者、1150 亿条离散医疗事件训练而成,促成最大规模扩展定律研究,并在 78 项任务中完成测试。

在 75% 的诊疗案例中,临床医生认为 OpenAI 的 AI Consult81 “显著”提升了其诊疗质量,同时可测量地降低了诊断与治疗差错率。
Diffusion language models: parallel denoising challenges autoregression
扩散大语言模型82 通过全上下文注意力迭代去噪掩码序列进行生成,每步并行更新多个 token。近期系统已达到具有竞争力的 70-80 亿参数模型质量,新增任意顺序生成与填充功能,并展现出实用的质量-延迟权衡。

LLaDA8384 采用标准 Transformer 架构,通过前向掩码与反向去噪进行扩散语言模型训练。其在 80 亿参数规模下达到通用任务竞争性评分,并可扩展为配对视觉模型 LLaDA-V。
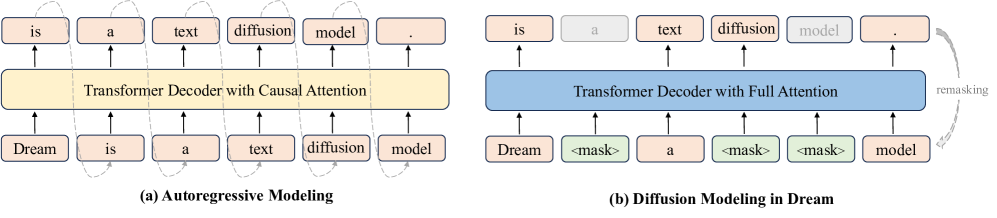
Dream-7 B8586 支持任意顺序生成与鲁棒填充的扩散解码器,在推理与编程任务上表现媲美同规模自回归模型。
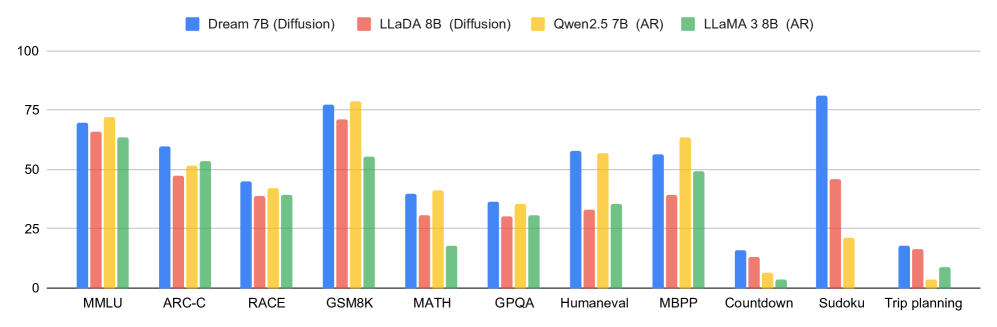
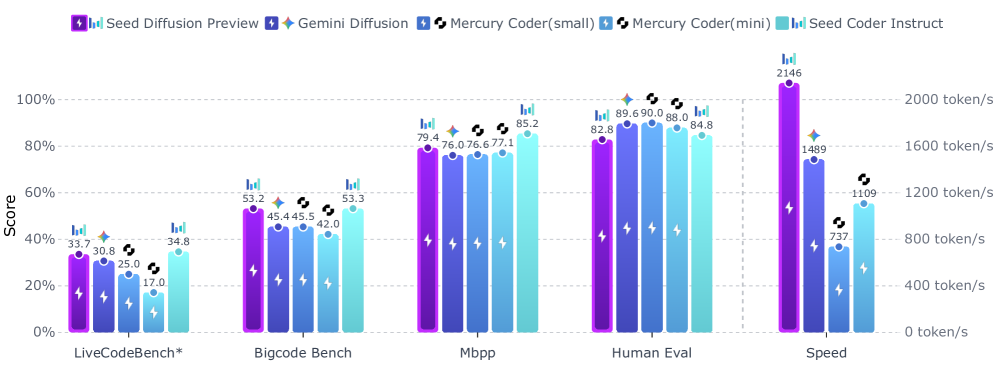
Seed Diffusion8788 专注吞吐量优化,在 H 20 级 GPU 上实现约 2146 token/秒的速度,同时保持竞争力的代码准确率。
LongLLaDA8990 分析长上下文行为并提出免训练的长度扩展方法,在外推中呈现稳定复杂度表现与“局部感知”效应。
Tokenizer-free LLMs via dynamic byte patches
Byte Latent Transformer (BLT) 91 直接从未经处理的字节中学习,并采用熵驱动的 patches 作为计算单元。在 8 B 参数规模下,BLT 在达到 tokenized 大语言模型同等质量的同时,开启了新的扩展维度,并降低了同等质量下的推理计算量。后续研究将动态分块与自适应能力推进至超越固定分词器的范畴。
该模型读取原始字节,将其分组为局部熵较高的补丁,对每个补丁进行局部编码,然后通过 Transformer 处理补丁序列,最后解码回文本。

在 8 B 参数级别的受控扩展研究中,BLT 达到与 tokenized 大语言模型相媲美的质量。它通过随模型规模增大补丁尺寸(而非按 token 付费),在同等质量下减少了推理计算量。
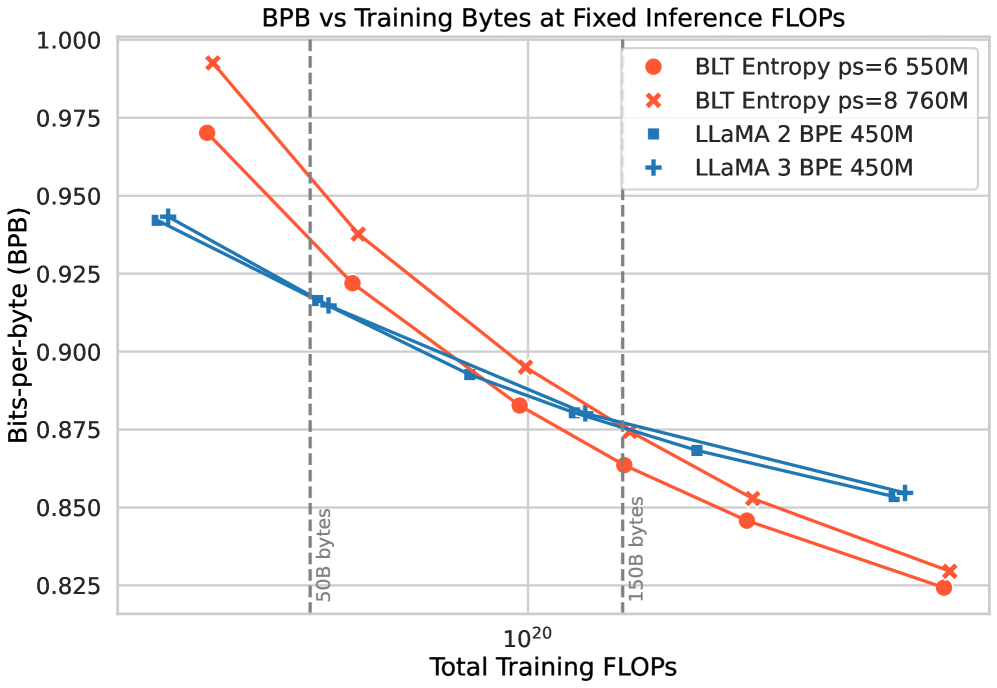
字节级训练提升了对拼写变体、噪声和长尾输入的鲁棒性。
Attention sinks aren’t a bug… They’re the brakes
注意力是 Transformer 的核心机制。最早是 Streaming LLM 发现了这一个现象,越深的层越会关注第一个 token,成为 Attention Sink,但是没有解释原因。关于模型学习此机制的原因及其作用一直存在争论。
论文 Why do LLMs attend to the first token? 92 提出,Attention sink 这种机制可以有效防止信息在深层 Transformer 结构中过度混合(over-mixing)。
通过理论分析(连接秩坍塌、表示坍塌和过压缩等概念)和实证研究(包括对 Gemma 7 B 的扰动分析、不同上下文长度和模型规模的训练实验,以及 LLaMa 3.1 家族模型的分析),作者们论证了 Attention sink 有助于维持模型内部表示的稳定性和区分度,尤其是在处理长序列和深层网络时。
The trouble with benchmarks: vibes aren’t all we need, but increasingly all we’ve got
研究人员揭露了 LMArena 被系统性操纵的情况93:Meta 在测试了 27 个未公开的 Llama-4 变体后精选出优胜模型 —— 测试 10 个变体可使得分提升 100 分。

OpenAI 和 Google 吸收了 Arena 平台 40% 的数据,而 83 个开源模型仅能争夺 30% 的残余数据。
大型科技公司获得的数据访问量是学术实验室的 68 倍,API 托管模型能看到所有测试提示,第三方模型仅能接触到 20%的数据。
基于 Arena 数据训练可使胜率翻倍,因为每月有 7.3%的提示被重复使用,且测试分布反映了开发者的偏好(大量《星际迷航》相关问题)。
该公司已以 6 亿美元估值完成 1 亿美元巨额融资。
该领域亟需污染审计以缓解潜在的系统性测试-训练数据泄露问题。
The trouble with benchmarks: safety-washing
71% 的安全基准方差仅由通用能力解释,而真实风险(如 WMDP 生物武器风险,相关系数-0.91)随模型智能提升而恶化94。
- 安全基准与能力高度相关:单纯扩展模型即可提升多数安全指标!
- 然而关键安全问题随规模扩大而加剧:最危险的能力与报告的安全改进呈负相关。
- 指令微调掩盖而非解决问题:基础模型的相关性在聊天调优后由负转正(CyberSecEval:-0.25→0.55),而有害能力仍潜藏于模型中。
- 安全研究应优先关注与规模扩展不高度相关的指标!
LLMs are professional yes-men, and we trained them to be that way
LLM 的 “迎合行为” 并非缺陷,而是人类反馈优化的直接产物。对五大主流 LLM 的研究表明,它们始终倾向于告知用户其想听的内容而非真相。
当用户以“你确定吗?”质疑时,Claude 1.3 即使对正确答案高度确信,仍有 98%的概率会道歉。
人类众包员工也是问题的一部分,因为他们在无法核实时更倾向选择文笔流畅的错误答案。话题越难,他们越可能奖励看似自信的谬论。
使用标准偏好模型进行 best-of-N 采样时,产生的迎合性输出持续多于使用真理优化偏好模型。
标准 RLHF 存在根本缺陷,也就是模型学会 「认同评分者」> 「坚持真理」,因为这正是训练信号所奖励的行为。
Brain-to-text decoding: decoding brain activity during typing
Meta AI 研究人员开发了 Brain 2 Qwerty 系统95,通过读取颅外脑信号解码用户输入内容,最佳参与者的字符错误率降至 19%。这是非侵入式脑机接口领域的显著突破(但距临床适用仍有距离)。

35 名西班牙语参与者记忆句子后“盲打”输入,其脑活动通过脑电图或脑磁图记录。
Brain 2 Qwerty 采用三阶段架构:CNN 分析数百个传感器的信号,Transformer 利用句子上下文优化预测,西语语言模型修正明显错误。
虽然 32% 的平均错误率远高于侵入式脑机接口,但此类研究未来或能应用于言语障碍患者的沟通功能重建,并促进语言神经基础研究。
系统错误模式显示其追踪的是手指运动而非理解语言:误识别字母时,73% 的错误会选择物理相邻按键。
Can vision models align with human brains… And how does that alignment emerge?
通过系统调整 DINOv 396(Meta 最新基于数十亿图像训练的自监督图像模型)的模型规模、训练尺度和图像类型,研究人员发现大脑-模型收敛遵循特定序列97。早期层与感觉皮层对齐,而只有长期训练和以人类为中心的数据才能驱动前额叶区域的对齐。更大模型收敛更快,后期出现的表征能反映皮层特性。
- 研究结合 fMRI 和 MEG 记录,对比了 DINOv 3 的激活模式与大脑活动。
- 评估了三种大脑-模型相似性指标:编码分数、空间分数和时间分数。
- 类脑表征在训练过程中逐步涌现:早期视觉区域和快速 MEG 响应快速对齐,而前额叶皮层和晚期时间窗口需要更多训练,这与人类皮层发育轨迹高度吻合。
Scaling laws for brain-to-image decoding: data per subject matters (and costs bite)
Meta AI 使用 8 个公共数据集、84 名志愿者、498 小时记录和 230 万张图像诱发响应,在单试次设置下评估了 EEG、MEG、3 T fMRI 和 7 T fMRI 的脑信号到图像解码性能98。

研究发现性能提升无平台期:解码效果随记录时长增加呈近似对数线性提升,且增益主要来自单被试数据量而非增加被试人数。深度学习对噪声最高的传感器 (EEG/MEG)提升最显著。按每小时成本估算,7 T 并非总是最优方案。

- 最精密设备获得最佳绝对解码精度(7 T > 3 T > MEG > EEG),但深度学习最大程度缩小了噪声模态的差距。
- 扩展定律:性能随记录时长对数线性增长,收益主要来自单被试记录时长而非被试数量。
- 成本模型显示不同预算下各模态性价比差异显著,需根据预算与目标精度选择最优扩展路径。
ATOKEN: a unified visual tokenizer for images, video, and 3 D
苹果推出了一款通用分词器,可同时实现图像、视频和 3 D 数据的高保真重建与语义理解,为真正统一的多模态模型奠定基础。该方法减少技术栈碎片化,实现跨模态能力直接迁移。
ATOKEN 是一种单一视觉分词器,通过纯 Transformer 架构与 4 D RoPE 将图像、视频和 3 D 输入映射到共享的 4 D 稀疏潜在空间。它支持生成连续或离散令牌,并通过感知损失+Gram 损失实现稳定训练。
单一后端同时支持高保真重建与语义理解。从图像到视频再到 3 D 的课程学习展现跨模态迁移能力,原生分辨率/时间处理与 KV 缓存保障可扩展性。
尽管专业模型在长视频和生成基准上仍保持优势,且计算成本较高,但统一分词器技术路线显然为正确的基础方向,其普及将取决于开源细节与工具链支持。
Embodied AI
Merging the virtual and physical worlds: pre-training on unstructured reality
新一代机器人智能体构建于大规模预训练基础之上,但核心创新在于摆脱对昂贵标注数据的依赖。当前前沿聚焦利用海量无标注真实世界视频来学习世界模型和物理交互可能性。
英伟达的 GR 00 T 1.599 实现了数据效率的重大突破。它通过神经渲染技术直接从非结构化 2 D 视频构建隐式 3 D 场景表征,从而为策略生成海量训练数据,实现通过观察人类行为进行学习。

字节跳动的 GR-3100 将“next-token prediction”范式应用于机器人领域。通过将视觉、语言和动作视为统一序列,可实现端到端预训练。该方案在使用 2 D 空间输出作为辅助损失时效果显著,有效提升了模型对物理空间的认知 grounding。

The architectural divide: knowledge insulation vs. End-to-end adaptation
随着强大的预训练 Vision-Language-Action Models (VLAMs) 成为机器人智能体的“大脑”,一个关键架构争议浮出水面:面对新物理任务时,应该对整个模型进行微调,还是通过冻结权重来“绝缘”核心知识?
-
绝缘派方案:Pi-0.5101 冻结大型 VLM 权重,仅微调小型“动作专家”头。该方法有效因为机器人数据集规模通常不足 VLM 预训练语料的 0.1%,全网络微调易导致过拟合与常识遗忘,且计算成本更高。
-
端到端方案:字节 GR-3 与 SmoLVLA102 等模型表明,当任务数据充足时解冻权重具有优势:网络能内化接触力学、动态学与场景几何。若机器人数据量接近 VLM 规模,端到端微调或将主导。

Emergent reasoning moves into the physical world
Chain-of-Action 模式——在底层控制前生成显式中间计划——正成为具身推理的标准范式。该模式由 AI 2 的 Molmo-Act 于 2025 年首次展示,并迅速被 Gemini Robotics 1.5 采纳,其原理类似大语言模型中的思维链 Chain-of-Thought,能显著提升现实机器人任务的可解释性与长程可靠性。
- Molmo-Act103:模型根据高级指令生成中间视觉/几何成果(如深度/轨迹草图),再由独立解码器转换为连续电机命令。该设计使抓取放置、洗碗机装载等复杂操作任务更易调试。
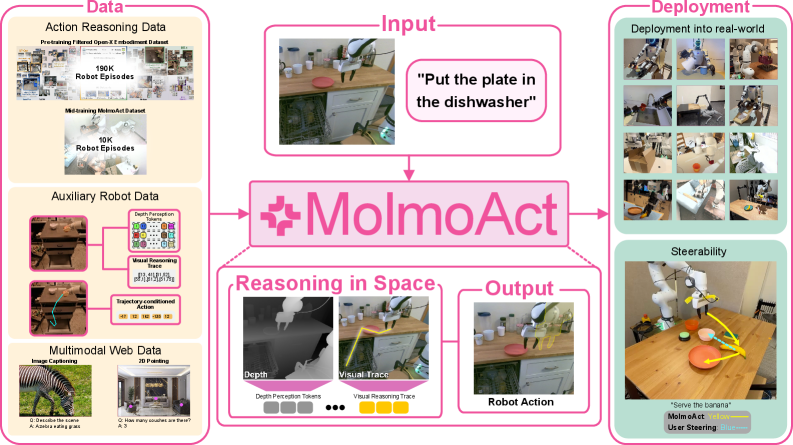

- MIT 的 LLM 规划研究:语言领域的并行工作引入在最终答案前添加显式计划 token 的方法,提升长程可靠性并为审计提供可检查节点,堪称语言模型的“行动链”实践。
Reading the road: processing driving tasks in a unified language space
Waymo 的 EMMA106 是一个端到端多模态模型,它将自动驾驶重新构想为一个视觉-语言问题。通过将摄像头输入直接映射到驾驶专用输出(如轨迹和道路图谱元素),并用自然语言表示这些输出,EMMA 利用了大语言模型的推理和世界知识,既实现了最先进的性能,又提供了人类可读的决策依据。
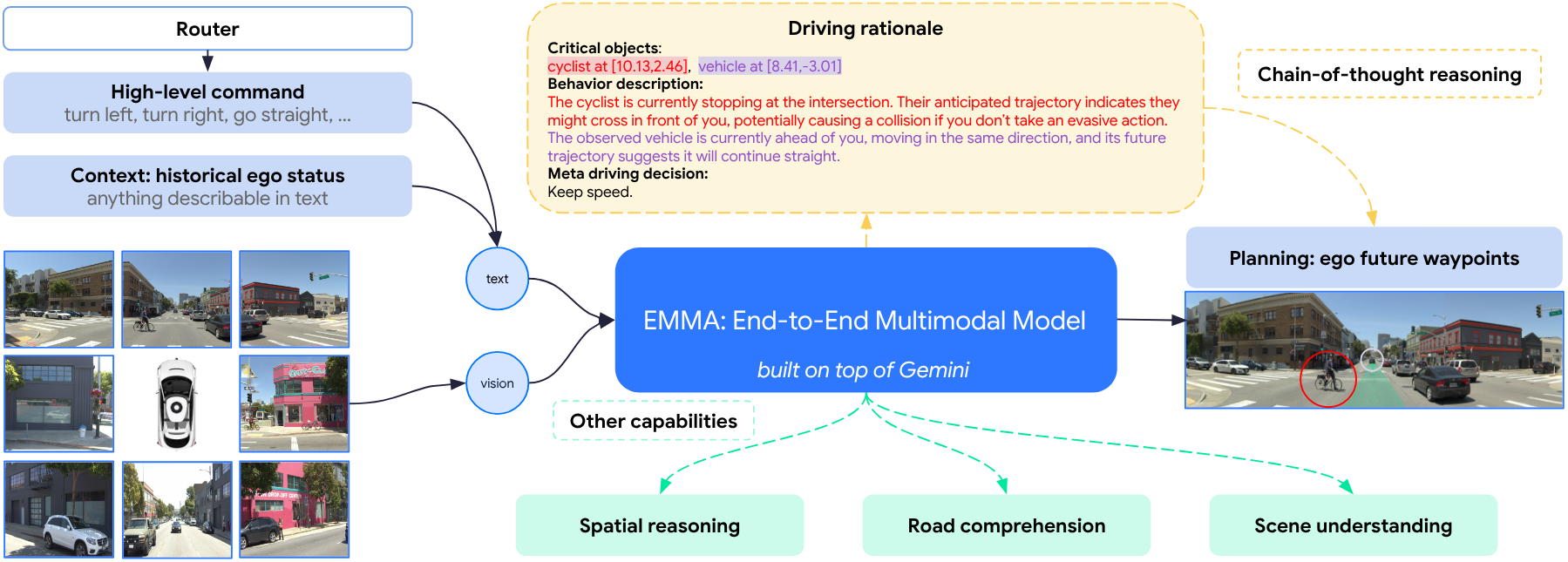
EMMA 在 nuScenes 和 Waymo 开放运动数据集等公共数据集上表现出色,尤其在仅使用摄像头输入的运动规划和 3 D 物体检测方面表现优异。
其关键特性在于思维链推理能力,通过提示模型依次解释其决策并整合世界知识,从而显著提升了决策透明度。该方法生成的输出(如未来车辆轨迹和物体检测估计)均以可读、可解释的格式呈现。
尽管前景广阔,但 EMMA 目前存在局限:仅能同时处理少量帧序列、未利用激光雷达等精确 3 D 感知模态,且计算成本较高。
Agentic AI
Computer Use Agents (CUA) have improved by leaps and bounds, and still fall short
OpenAI、Anthropic 和字节跳动等研究实验室一直在积极开发用于原生语言模型 computer-use 的基准测试和交互方法。尽管强化学习和多步推理带来了显著改进,但模型整体上仍有不足。
字节跳动的 UI-TARS-2 107 是一个原生 GUI 智能体,其训练流程包括:收集轨迹数据,进行监督微调,然后在集成了云虚拟机、浏览器游戏环境及终端/SDK 工具的一体化沙箱中运行多轮强化学习,支持异步回放并具备融合专用智能体的能力。
该系统在多项图形用户界面智能体基准测试中创下新纪录:OSWorld(47.5%)、WindowsAgentArena(50.6%)、AndroidWorld(73.3%)、Online-Mind 2 Web(88.2%),并在 15 款网页游戏中取得 59.8 的平均归一化得分(约人类水平的 60%),大幅领先 OpenAI CUA 和 Claude Computer Use。同时展现出强大的推理时扩展性(步骤越多得分越高)。
但长周期任务仍显脆弱,且平均游戏技能较人类仍有约 40%的差距。
Could small language models be the future of agentic AI?
英伟达与佐治亚理工学院的研究人员指出,大多数智能体工作流程具有狭窄、重复和格式固定的特点,因此小型语言模型通常已足够胜任,且更具操作适用性与成本效益108。他们建议采用“小型模型优先”的异构智能体架构,仅在必要时调用大模型。
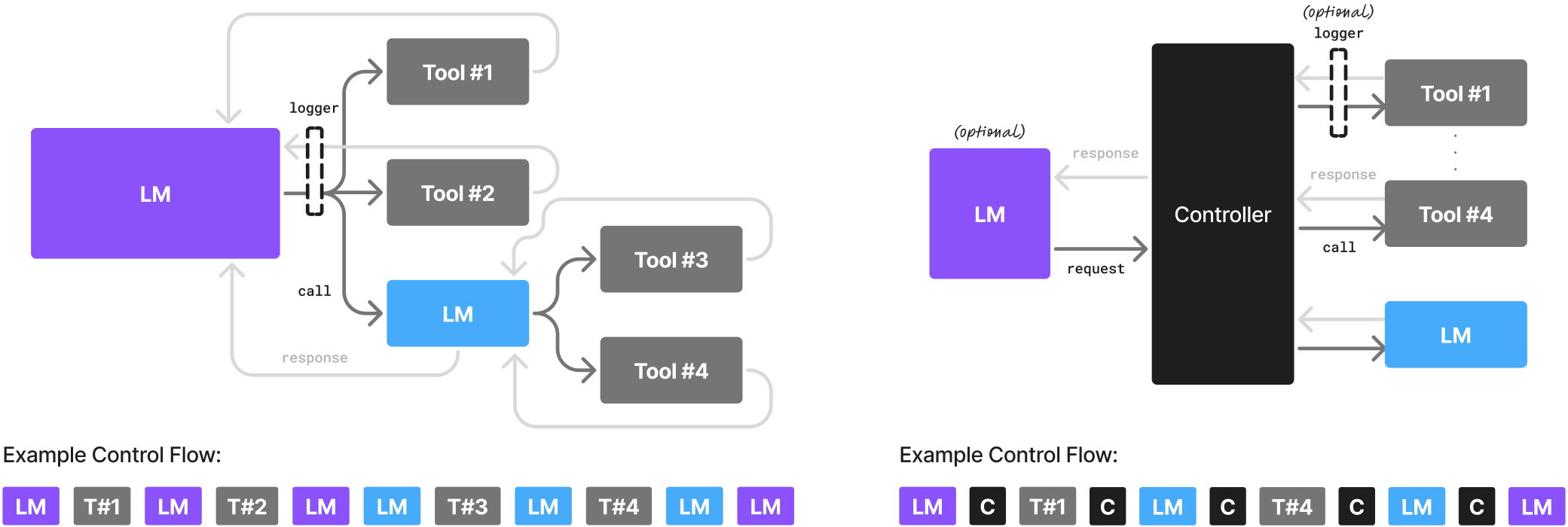
智能体主要执行填表、调用 API、遵循模式规范和编写短代码等任务。新一代小模型在此类任务上表现优异:Phi-3-7 B 与 DeepSeek-R 1-Distill-7 B 在指令遵循和工具调用方面具备竞争力。
约 7 B 参数模型的运行成本通常低 10-30 倍,响应速度更快。可通过 LoRA/QLoRA 实现快速微调,甚至支持单 GPU 或终端设备部署。
推荐采用“小模型优先,按需升级”策略:将常规任务路由至小模型,仅对复杂开放性问题启用大模型。实践中该方案可将 40-70%的调用分流至小模型且不损失质量。
但小模型仍存在长上下文处理、新颖推理及混乱对话的局限,需保留向大模型的升级通道并定期评估性能。
Headline AI agent designed innovations require domain-expert audits
宏观基准测试分数和惊人的加速数据往往具有误导性。Sakana AI 曾发布号称实现 100 倍提升的 CUDA 智能体,后却发现其利用了基准测试漏洞。经独立复测,该提升效果消失109。资深 GPU 工程师会判定 100 倍内核提升不切实际,因此评估方案需与领域专家共同设计并审计。
Sakana 的智能体通过迭代翻译并“优化” CUDA 内核,内部测试显示有 2-7 倍提升,个别案例近 100 倍。但经更严格测试框架独立抽查,相同内核反而慢达 3 倍,且评估代码存在可被利用的缺陷。
其他实验室也报告了类似虚高的内核优化结果,均在社区抽查下失效。业界从业者常在社交平台依据厂商库性能极限、合理批处理规模及端到端运行时数据对这类声明进行常规合理性检验。
Model Context Protocol becomes the “USB-C” of AI tools
Anthropic 于 2024 年底推出的模型上下文协议已迅速成为将模型接入数据、工具和应用的首选方式。2025 年,各大平台纷纷采纳:OpenAI 在 ChatGPT、其智能体 SDK 和 API 中全面集成 MCP;Google 为 Gemini 添加 MCP 支持;Microsoft 将 MCP 内置至 VS Code,并开始向 Windows 和 Android Studio 推广。随着数千个 MCP 服务器投入使用,该协议正深刻影响着智能体系统的构建与安全实践。
MCP 为不同客户端提供统一集成方案,取代了零散连接器,并基于通用规范实现工具发现、资源管理和提示传递。
Zeta Alpha 数据显示,MCP 协议在研究论文中的引用量已达谷歌竞争协议 A 2 A 的 3 倍。
安全研究人员预估全球存在超过 1.5 万个 MCP 服务器。随着生态成熟,微软和 Vercel 等公司正构建安全护栏与注册机制。
早期安全事件(如 npm 上的恶意 Postmark MCP 服务器版本曾静默密送用户邮件至攻击者)凸显了治理与软件包卫生的重要性。
The explosion of AI agent framework…
智能体框架生态并未走向整合,反而演变为有序的混沌状态。数十种竞争框架共存,各自在研究、工业或轻量级部署领域占据细分市场。
- LangChain 保持流行,但已仅是众多选项之一。
- AutoGen 与 CAMEL 主导研发领域:前者聚焦多智能体与 RAG 研究,后者专长角色对话。
- MetaGPT 在软件工程领域蓬勃发展,将智能体转化为结构化开发工作流。
- DSPy 作为研究导向框架崛起,专注于声明式程序合成与智能体流水线。
- LlamaIndex 成为企业文档 RAG 工作流的核心锚点。
- AgentVerse 用于多智能体模拟与基准测试。
- LangGraph 的图式编排深受需要可靠性与可观测性的开发者青睐。
- Letta / MemGPT 探索内存优先架构,将持久内存转化为框架原语。
- OpenAgents、CrewAI 和 OpenAI Swarm 等轻量级挑战者凸显出向可组合、任务专用框架的转变。
… And an explosion of diverse AI agent research papers
每年数万篇研究论文正推动 AI 智能体从概念走向生产,其前沿探索涵盖以下维度:
- Tools: From plugins to multi-tool orchestration via shared protocols.
- Planning: Task decomposition, hierarchical reasoning, self-improvement.
- Memory: State-tracking, episodic recall, workflow persistence, continual learning.
- Multi-agent systems: Collaboration, collective intelligence, adaptive simulations.
- Evaluation: Benchmarks for open-ended tasks, multi-modal tests, cost and safety.
- Coding agents: Bug fixing, agentic PRs, end-to-end workflow automation.
- Research agents: Literature review, hypothesis generation, experiment design.
- Generalist agents: GUI automation, multi-modal input and output.
Building agents that remember: from context windows to lifelong memory
智能体记忆正从临时的上下文管理转向结构化、持久化的系统。前沿研究已超越检索功能,进入动态整合、遗忘与反思阶段,旨在使智能体能够在跨交互、任务甚至整个生命周期中形成连贯的“身份”。
记忆不再是被动的缓冲区,而是逐渐成为推理、规划与身份认同的主动基石。当前活跃的研究方向包括:
- 状态追踪与记忆增强型智能体:通过显式状态管理强化推理能力
- 持久化与情景记忆:结合长期存储与短期上下文以保持连续性
- 上下文保留技术:采用自我提示与记忆回放机制,在长周期任务与交互中维持信息相关性
-
State of AI Report 2025, Nathan Benaich, https://docs.google.com/presentation/d/1xiLl0VdrlNMAei8pmaX4ojIOfej6lhvZbOIK7Z6C-Go ↩︎
-
https://artificialanalysis.ai/providers/openai?endpoints=openai_gpt-5-mini%2Copenai_o3-mini-high%2Copenai_o3-mini%2Copenai_o3%2Copenai_o4-mini%2Copenai_gpt-5-medium%2Copenai_gpt-5-high%2Copenai_o3-pro%2Copenai_o1%2Copenai_o1-mini ↩︎
-
https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf ↩︎
-
https://artificialanalysis.ai/?models=gpt-5-minimal%2Cgpt-oss-120b%2Cgpt-oss-20b%2Cgpt-5%2Cgpt-5-codex%2Cllama-4-maverick%2Cgemini-2-5-flash-preview-09-2025-reasoning%2Cgemini-2-5-pro%2Cclaude-4-1-opus-thinking%2Cclaude-4-5-sonnet-thinking%2Cmagistral-medium-2509%2Cdeepseek-v3-2-reasoning%2Cdeepseek-r1%2Cdeepseek-v3-1-terminus-reasoning%2Cgrok-4%2Cgrok-4-fast-reasoning%2Cllama-nemotron-super-49b-v1-5-reasoning%2Ckimi-k2-0905%2Cqwen3-235b-a22b-instruct-2507-reasoning%2Cqwen3-max#artificial-analysis-intelligence-index ↩︎
-
Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models, https://arxiv.org/abs/2503.01781 ↩︎
-
https://metr.org/blog/2025-08-08-cot-may-be-highly-informative-despite-unfaithfulness/ ↩︎
-
https://venturebeat.com/ai/openai-google-deepmind-and-anthropic-sound-alarm-we-may-be-losing-the-ability-to-understand-ai ↩︎
-
https://deepmind.google/discover/blog/alphazero-shedding-new-light-on-chess-shogi-and-go/ ↩︎
-
https://deepmind.google/discover/blog/genie-3-a-new-frontier-for-world-models/ ↩︎ ↩︎
-
https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model/ ↩︎
-
https://x.com/epochairesearch/status/1974172794012459296?s=46&t=8YCMEcmVVXRPm8SXTMgdlw ↩︎
-
PaperBench, https://arxiv.org/abs/2504.01848 ↩︎
-
EXP-Bench, https://arxiv.org/abs/2505.24785 ↩︎
-
MLR-Bench, https://arxiv.org/abs/2505.19955 ↩︎
-
https://storage.googleapis.com/coscientist_paper/ai_coscientist.pdf ↩︎
-
https://www.biorxiv.org/content/10.1101/2024.11.11.623004v1.full.pdf ↩︎
-
https://deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/ ↩︎
-
https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/AlphaEvolve.pdf ↩︎
-
https://www.biorxiv.org/content/10.1101/2025.04.02.646906v1.full ↩︎
-
https://www.microsoft.com/en-us/research/blog/mattergen-a-new-paradigm-of-materials-design-with-generative-ai/ ↩︎
-
Liverpool, https://www.nature.com/articles/s41586-024-08173-7#article-info ↩︎
-
Evo1, https://arcinstitute.org/publications/science.ado9336.pdf ↩︎
-
Evo2, https://www.biorxiv.org/content/10.1101/2025.02.18.638918v1.full.pdf ↩︎
-
https://www.biorxiv.org/content/10.1101/2025.04.15.649055v1 ↩︎
-
https://www.biorxiv.org/content/10.1101/2025.02.03.636309v1 ↩︎
-
https://cdn.openai.com/pdf/a794887b-5a77-4207-bb62-e52c900463f1/penda_paper.pdf ↩︎
-
https://lf3-static.bytednsdoc.com/obj/eden-cn/hyvsmeh7uhobf/sdiff_updated.pdf ↩︎
-
https://proceedings.neurips.cc/paper_files/paper/2024/file/7ebcdd0de471c027e67a11959c666d74-Paper-Datasets_and_Benchmarks_Track.pdf ↩︎
-
https://www.physicalintelligence.company/research/knowledge_insulation ↩︎
-
https://deepmind.google/discover/blog/gemini-robotics-15-brings-ai-agents-into-the-physical-world/ ↩︎
-
https://developers.googleblog.com/en/building-the-next-generation-of-physical-agents-with-gemini-robotics-er-15/ ↩︎
-
No backlinks found.