Sliding Window Attention
静态稀疏化可以通过注意力机制来实现,即稀疏注意力机制或者线性注意力。稀疏注意力机制的核心思想就是在推理中选择合适的 Token 来进行相应的计算,这种方案在序列比较长时尤其有帮助,可以大幅降低 Attention 部分的 KV Cache 大小和计算量。线性注意力机制(如 Linear Transformer、RWKV 和 Mamba 等)通过将标准注意力机制替换为与序列长度线性相关的机制来减少内存需求。然而,这种方法可能会降低模型的表达能力,导致在需要复杂、长距离词元依赖关系的任务中性能下降。
比如,Mistral-7B使用被称为滑动窗口注意力(SWA)或局部注意力的注意力机制变体。局部注意力保证我们不需要关注整个序列,只通过关注最后(4096个)相邻的词元来构建词元表示,这样在KV缓存中永远不会存储超过窗口大小(例如4096)的张量对。再比如,
论文"Efficient Streaming Language Models with Attention Sinks"中分析了四种 Attention 实现,具体如下图所示。其中T 为待预测的第 T 个 Token,L 表示 pretrain 时的最大序列长度(一般为 2k、4k 等),由于主要针对的是长序列场景,因此 T 远大于 L。

第一种是原始注意力实现,后三种是稀疏化实现,这些稀疏化方法都是静态的,即 Token 之间的相关性是一种固定的范式,每个 Token 的相关的 Token 都是固定距离的。
- Dense Attention是vanilla Attention 实现。每个 Token 都能看到该 Token 及之前的 Token,其计算复杂度为 O(T2),KVCache 存储复杂度为O(T)。由于复杂度比较高,T 在预训练的时候会比较小。在推理的时候,当文本长度超过了预训练时的长度,模型效果就会大幅降级,所以表现出来的 PPL 值也比较大。
- 窗口注意力(Window Attention)缓存最近的 n 个tokens的KV。这种方法相当于只在最近的tokens的KV状态上维护一个固定大小的滑动窗口。其中灰色的虚线框表示超过窗口长度后从 cache 中淘汰的 Token。计算复杂度为 O(T*L),计算复杂度低,cache 比较小,在推理中效率高。但是模型效果很差(PPL 很大),因为虽然但一旦开始tokens的键和值被删除,性能就会急剧下降。
- 带重计算的滑动窗口(Sliding Window with Re-computation)。 这种 Attention 与 Window Attention 类似,区别是 Sliding Window 不缓存窗口的 Tokens,而是为每个新token重建来自 L个最近tokens的KV状态。这种方案的模型效果对比Window Attention 高,PPL 值远低于 Window Attention。主要原因是重计算把窗口中的 Tokens 作为初始 Tokens,这样既保留初始 Tokens 又保证计算只在一个窗口内,大大降低了KVCache 存储复杂度。由于重计算的存在,其精度可以保证,但是性能损失比较大。虽然它在长文本上表现良好,但由于在上下文重计算中的二次注意力,其的O(TL2) 复杂度使其相当缓慢,使得这种方法不适用于实际的流式应用。
- StreamingLLM 保留了用于稳定注意力计算的attention sink(几个初始tokens),并结合了最近的tokens。它高效并且在扩展文本上提供稳定的性能。黄色的框表示初始的几个 Token,也就是 Attention Sink,其计算复杂度为 O(T*L),模型精度很不错,和带重计算的滑动窗口 Attention 相当。
我们接下来分析窗口注意力和StreamingLLM。
1.2.1 Window Attention
Window Attention采用滑动窗口机制来解决长文本推理挑战,其中落在窗口外的token被永久驱逐并变得无法访问。
在原始注意力中,每一个token,都要和它之前所有的token做Attention。而通过我们平时语言习惯中可以知道,一段话中每个字之间的相关性差别很大。对于当前token,一般来说越相近的字相关性越强,距离越远的token,能提供的信息量往往越低,因此似乎没有必要浪费资源和这些远距离的token做Attention。因此,滑动窗口(Sliding Window Attention)机制就是:每一个token只和包含其本身在内的前 L(L 表示窗口长度)个token做Attention,即只和当前token距离相近的token做注意力计算。这样就可以把cache的容控制在 L 内。因为每个 Token 只和邻近的 Token 做 Attention 计算,所以计算复杂度为 O(TL) ,KVCache 存储复杂度为O(L)。这种方法极大的降低了 KVCache 的存储开销,从线性复杂度降低到常数复杂度。
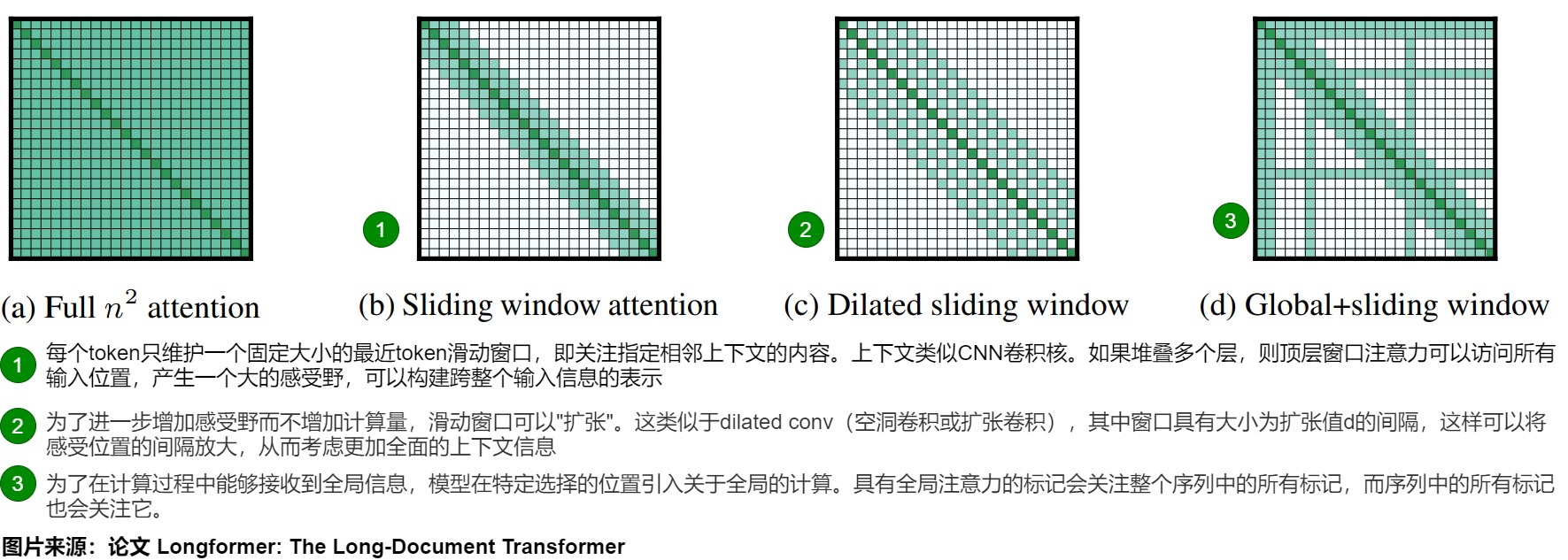
典型代表即 Longformer,具体如下图所示。
-
(a)展示了传统的“全注意力”机制,其中每个新生成的token都会关注序列中所有先前的token。
-
(b)描述了“滑动窗口注意力”。该方法维护一个固定大小的最近token滑动窗口,给定固定的窗口大小w,每个token都会关注其两侧$ \frac{1}{2}w 个token。滑动窗口允许我们拥有一个固定大小的缓存。一旦序列增长超出滑动窗口token数,我们可以在缓存中循环并开始覆盖。由于w可以设置的比较小,所以可以和输入序列长度n呈线性关系,其计算复杂性为O(n×w)$,更加适合浅层捕获局部信息。而且,因为缓存中的位置无关紧要,所有与位置相关的信息都通过位置嵌入编码,所以很容易实现并且效果很好。然而,这种方法限制了模型从过去捕获全面语义信息的能力,导致文本生成质量较低且准确性下降。
人们可能会疑惑,虽然距离越远的token涵盖的信息量可能越少,但不意味着它们对当前token一点用处都没有,在滑动窗口中直接杜绝了它们的参与,这真的合理吗?其实,Silding Window Attention并非完全不利用窗口外的token信息,而是随着模型层数的增加,间接性地利用起窗口外的tokens。这里可以类比为CNN技术中的感受野。如果堆叠多个层,从layer0开始,每往上走一层,对应token的感受野就往前拓宽W,虽然在每一层它“最远”只能看到前置序列中部分token,但是只要模型够深,它一定能够在某一层看到所有的前置tokens。该层窗口注意力可以访问所有输入位置,产生一个大的感受野,可以构建跨整个输入信息的表示。在具有l层的Transformer中,顶层的感受野大小为l×w(假设对于所有层w是固定的)。根据应用程序的不同,可能为每个层使用不同的w 值更好,以在效率和模型表示能力之间取得平衡。具体如下图所示。

-
(c)展示了一种称为“膨胀窗口注意力”的变体,其准确性与窗口注意力类似,也存在类似的限制。其特点如下。
- 为了进一步增加感受野而不增加计算量,滑动窗口可以"扩张"。这类似于dilated conv(空洞卷积或扩张卷积),其中窗口具有大小为扩张值d的间隔,这样可以将感受位置的间隔放大,让token在当前位置适当捕捉到得更远处的信息,关注更大的视野,考虑了更加全面的上下文信息。由于考虑了更加全面的上下文信息,空洞滑窗机制比普通的滑窗机制表现更佳。
- 每个位置的Q关注的K还是W个,但是W个不是连续的而是跳跃的。定义跳跃的间隔是d, 那么Q关注的K的范围就是w * d。计算方面依然保持滑动窗口在计算性能方面的优点。
- 假设对于所有层都是固定的d和w,那么感受野大小为l×d×w,即使对于较小的d值,也可以触及成千上万个token。在多头注意力中,每个注意力头计算不同的注意力分数。每个头部具有不同的扩张配置的设置可以通过允许一些没有扩张的头部关注局部上下文,而其他具有扩张的头部专注于更长的上下文,从而提高性能。
-
(d)是Global+sliding window(融合全局信息的滑窗机制),滑动窗口和扩张注意力不足以学习特定任务的表示,需要从其它方面借鉴。因此引入了全局注意力对这两者进行补充。其特点如下:
- 全局注意力就和普通的transformer是一样的,都是关注全部的K。依据具体任务的不同,在特定选择的位置引入关于全局的计算,使得模型在计算过程中能够接收到全局的信息。
- 具有全局注意力的token会关注整个序列中的所有token,而序列中的所有token也会关注它。由于这些token的数量相对较小且独立于n,因此结合局部和全局注意力的复杂度仍然为O(n)。虽然指定全局注意力是与任务相关的,但这是一种向模型的注意力添加归纳偏差的简单方式,比起使用复杂架构将信息跨越较小的输入块组合的现有任务特定方法要简单得多。
1.2.2 StreamingLLM
StreamingLLM 利用“注意力沉积”效应,用早期Token 的KV结合近期上下文来优化长序列处理,实现了对无限长度输入的支持,同时生成无限长度的输出。
StreamingLLM 来自论文《Efficient Streaming Language Models with Attention Sinks》,其目标是让模型能够处理无限长度的输入(这里的“无限长度输入”与“无限长度上下文”有所不同——前者无需记住所有输入内容)。
Window Attention方案虽然压缩了KVCache的长度被压缩,但是模型效果却不好,主要原因是最初始的 Token 被丢弃了。这种 Token 的重要性其实非常高,丢弃会严重影响模型效果,精度下降比较大。而StreamingLLM恰恰弥补了这个缺憾。StreamingLLM发现注意力中的一个关键现象,即初始序列token中保留的键值对保持了关键的模型性能。这种注意力下沉效应通过早期位置的不对称注意力权重积累来体现,而与语义意义无关。该方法利用了这一特性,将注意力汇位置与最近的上下文相结合,以实现高效处理。
StreamingLLM策略在 Window Attention 的基础上,通过仅保留最初的位置词元(sink tokens)和最后相邻的词元(局部注意力)来构建了一个滑动窗口缓存。因此,StreamingLLM KV Cache 的长度是固定的,既有固定部分(通常1到4个 token ),也有滑动部分。这样既保留 Window Attention的特性,使得 KVCache 存储复杂度为O(L),计算复杂度为 O(TL) ,同时又保证了模型效果不因丢失初始 Tokens 而大幅下降,PPL 和 Sliding Window Attention with recomputation 相似。
Attention sink
StreamingLLM 作者发现,window attention 只要加上开头的几个 token 比如就4个,再操作一下位置编码,模型输出的 PPL 就不会变好,输出到20k 长度都很平稳。论文将这种现象叫做 Attention Sink。就好像文本的注意力被“沉溺”到了开头的位置。即初始词元聚集了大量注意力。而且 intial tokens 与生成 token 的绝对距离距离和语义信息都不重要,重要的是 intial tokens 是第一个或者前面几个 token,就是这些 token 作为锚点,所以其权重特别大。
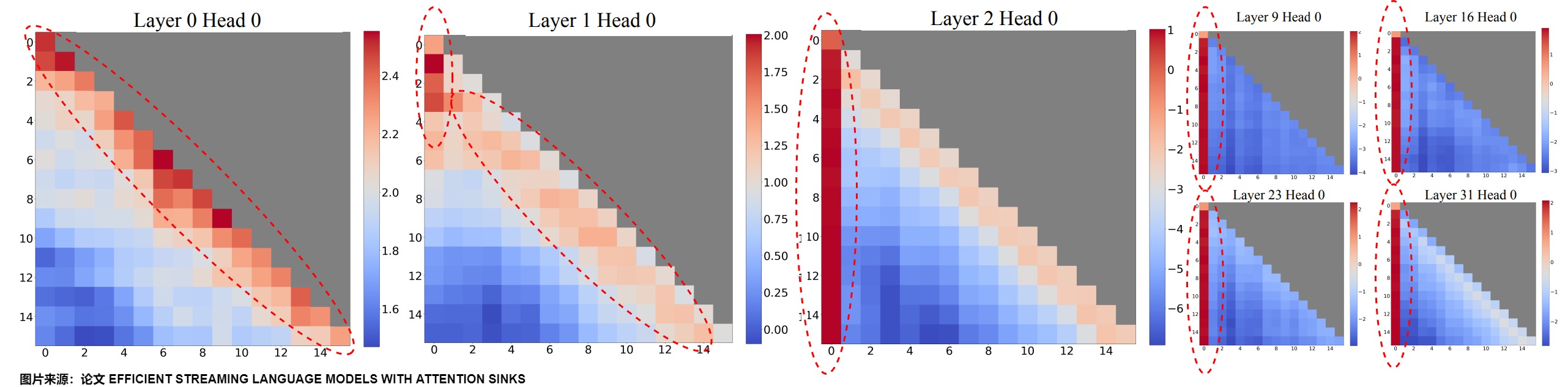
上图给出了lama-2-7B中256个句子的平均注意力逻辑的可视化,每个句子的长度为16。观察结果包括:
- 前两层(第0层和第1层)的注意力图呈现出“局部”模式,最近的token受到了更多的关注。
- 除了前两层之外,之后的注意力主要集中在first token。
如果删除这些初始token的KV,将导致注意力计算中SoftMax函数的相当一部分分母也被删除。这种变化导致注意力得分的分布发生了显著变化,偏离了正常推理环境中的预期。
为何会出现这种现象?Evan Miller 在“Attention Is Off By One” 做了精彩的解读。
The problem with using softmax is that it forces each attention head to make an annotation, even if it has no information to add to the output vector. Using softmax to choose among discrete alternatives is great; using it for optional annotation (i.e. as input into addition) is, like, not cool, man. The problem here is exacerbated with multi-head attention, as a specialized head is more likely to want to “pass” than a general-purpose one. These attention heads are needlessly noisy, a deafening democracy where abstention is disallowed.
在Attention机制中,Softmax的输出代表了key/query的匹配程度的概率,如果softmax在某个位置的值非常大,那么在反向传播时,这个位置的权重就会被大幅度地更新。然而,有时候attention机制并不能确定哪个位置更值得关注,但是Softmax又需要所有位置的值的总和为1,因此模型必须“表态”给某些位置较大的权重,因此,模型倾向于将不必要的注意力值转嫁给特定的token,这些token就是initial tokens。
因此,Evan Miller改进了一下Softmax,提出了“SoftMax-off-by-One”:把softmax的分母加了个1,这样所有位置值可以加和不为1,Attention就有了可以不对任何位置“表态”的权利。
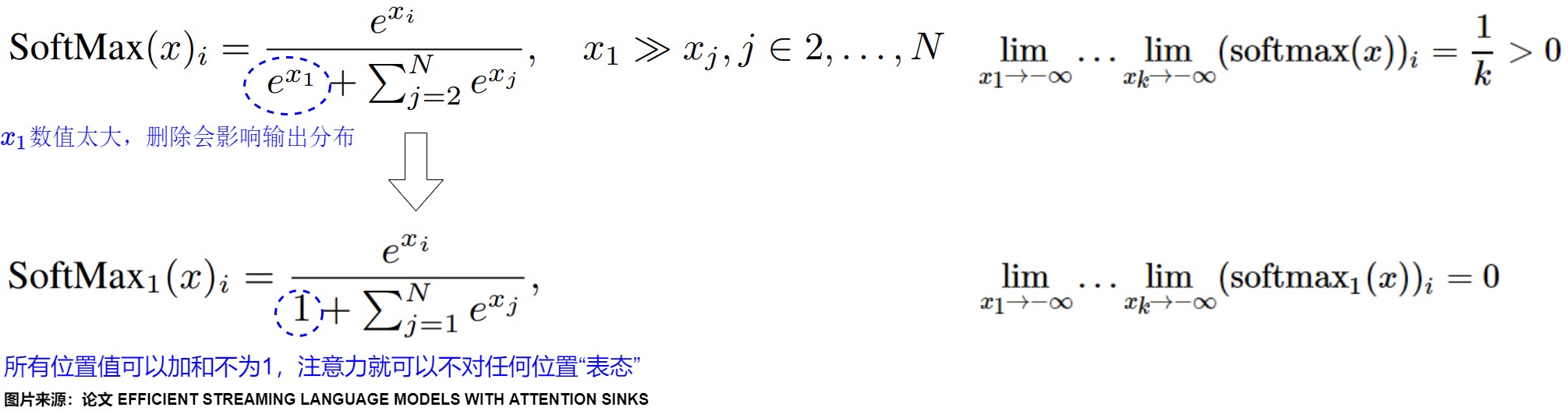
思路
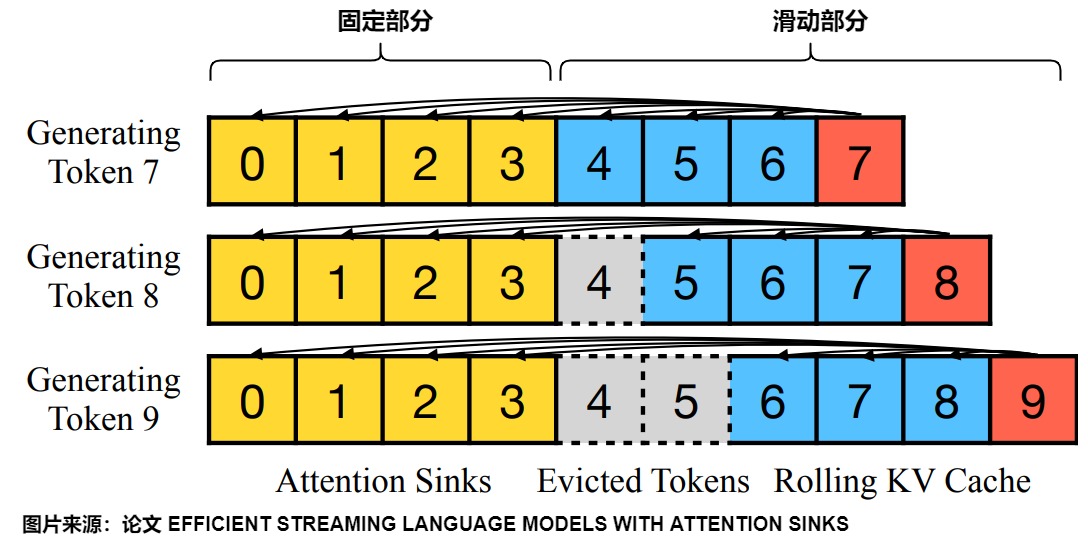
根据 attention sinks 特性,论文作者参考之前多轮对话场景的解决方法,给出 StreamingLLM 的解决方案,即在 window attention 基础上,新引入了 initial tokens 的 KV。
- 锚点加窗口。StreamingLLM中的KV cache可以分为两部分,既有一个固定部分(通常为1到4个词元),又有一个滑动部分。
- 固定部分。保留整个序列的初始 Tokens(attention sink部分),图中画的是4个initial tokens;其作用是识别并保存模型固有的attention sink,锚定其推理的初始token来进行注意力计算并稳定模型性能。
- 滑动部分。滑动窗口的KV(Rolling KV部分)cache,保留了最近的3个tokens,窗口值固定为3。其目的是:想让大模型无限输出,达到“Streaming”效果:不用KV cache会计算太慢,但是用了KV cache,显存占用随长度增长太多。因此需要丢弃一些KV cache。
- 计算。每个 token 只和窗口内的 Tokens 以及序列的初始 Tokens 进行 Attention 计算。而且训练期间,用“SoftMax-off-by-One”替代常规softmax,解决attention sink问题。
在实现中,会用“Rolling Buffer Cache"技术来丢弃KV cache中的某些行,同时也会控制位置编码。下图给出了Rolling Buffer Cache的运作流程,当我们使用滑动窗口后,KV Cache就不需要保存所有tokens的KV信息了,你可以将其视为一个固定容量(W)的cache,随着token index增加,我们来“滚动更新” KV Cache。

问题
StreamingLLM 虽然记住了 Attention sink 以及最近的窗口里面的 token 对应的 KV cache,然而仅仅在注意力机制中依赖这 k 个 token 并不能提供必要的准确性。因为目前是按照位置把中间的 token 都丢掉了,万一中间的 token 就是重要的怎么办。这就是静态 Token 稀疏化的问题:Token 候选集过于固定。这种 Token 候选集的设计源于作者通过观察某些数据集中 Token 之间的相关性发现的规律。这种规律不能保证具备普适性,会导致关键 token 注意力中近期上下文的丢失和窗口注意力中关键上下文的缺失,会损害模型在长序列任务上 的性能。
Sliding Window Attention
核心思想:**通过堆叠 Transformer 层,逐层扩展注意力范围。每层的隐藏状态仅关注前一层窗口内的位置,但多层堆叠后,最终层的注意力跨度可覆盖更广的上下文(理论跨度 = 窗口大小 W x 层数 K)。
关键机制:**逐层递归扩展
-
逐层递归扩展:第 k 层的每个位置可间接访问输入层中距离不超过W x k 的token。
-
计算优化:结合稀疏注意力(窗口大小 W)和层堆叠,复杂度从 $O(N*N)$ 降至 $O(N×W)$。
-
实际效果:
-
当 W=4096,K=32时,最后一层理论注意力跨度达 131K token。
-
对FlashAttention和xFormers优化后,在16K序列长度下,速度提升2倍。
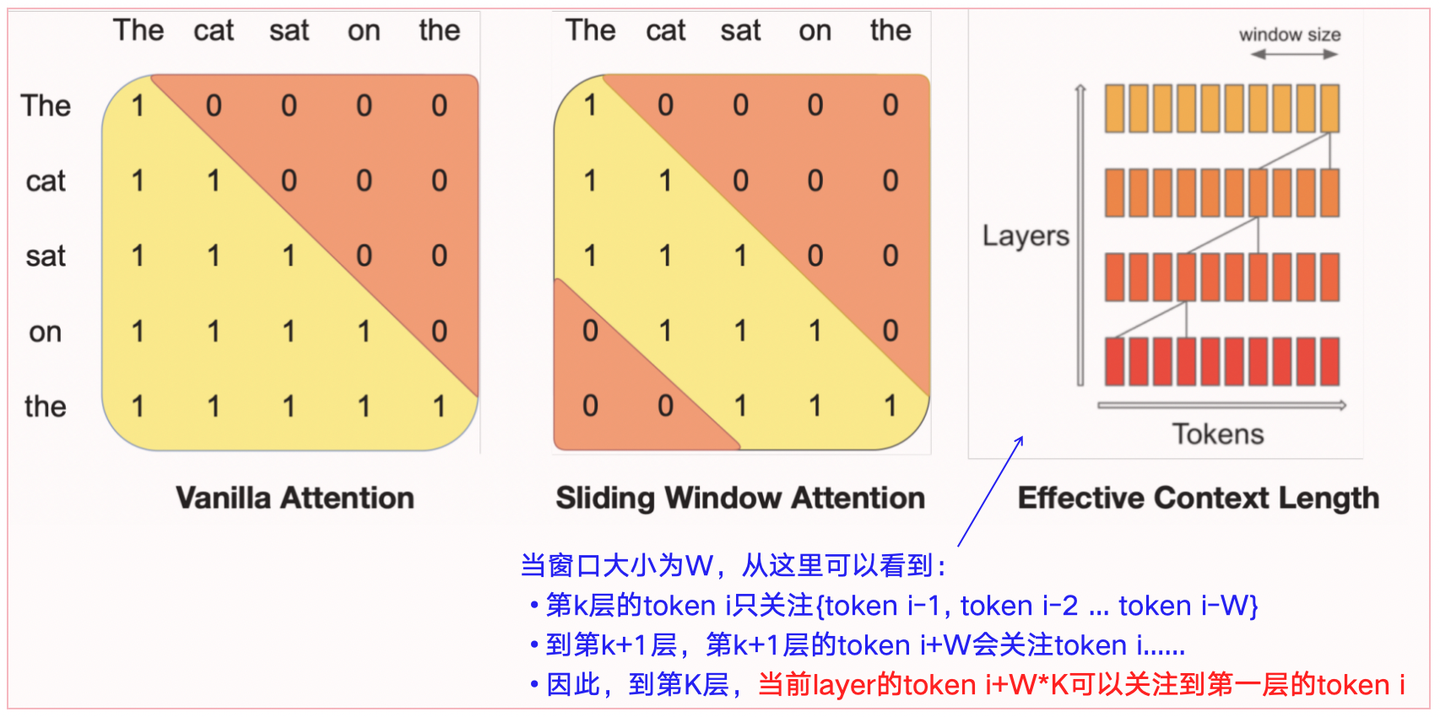
图1-1:滑动窗口注意力的图解
1.2 Rolling Buffer Cache(滚动缓冲缓存,RBC)**
1)核心思想:固定缓存大小(W),通过滚动覆盖机制存储键值对(KV Cache),避免缓存随序列长度线性增长
**2)关键机制:**缓存覆盖规则
- 缓存覆盖规则:位置 i 的 key value 存储在缓存位置 i mod W。
- 内存优化:缓存大小始终为 W,即使序列长度超过 W,旧值会被新值覆盖。
- 实际效果:
- 在32K token 的序列下,缓存内存占用减少8倍(例如,原需缓存32K,现仅需4K)。
- 不影响模型质量,仅依赖局部上下文的任务(如语言建模)表现稳定。
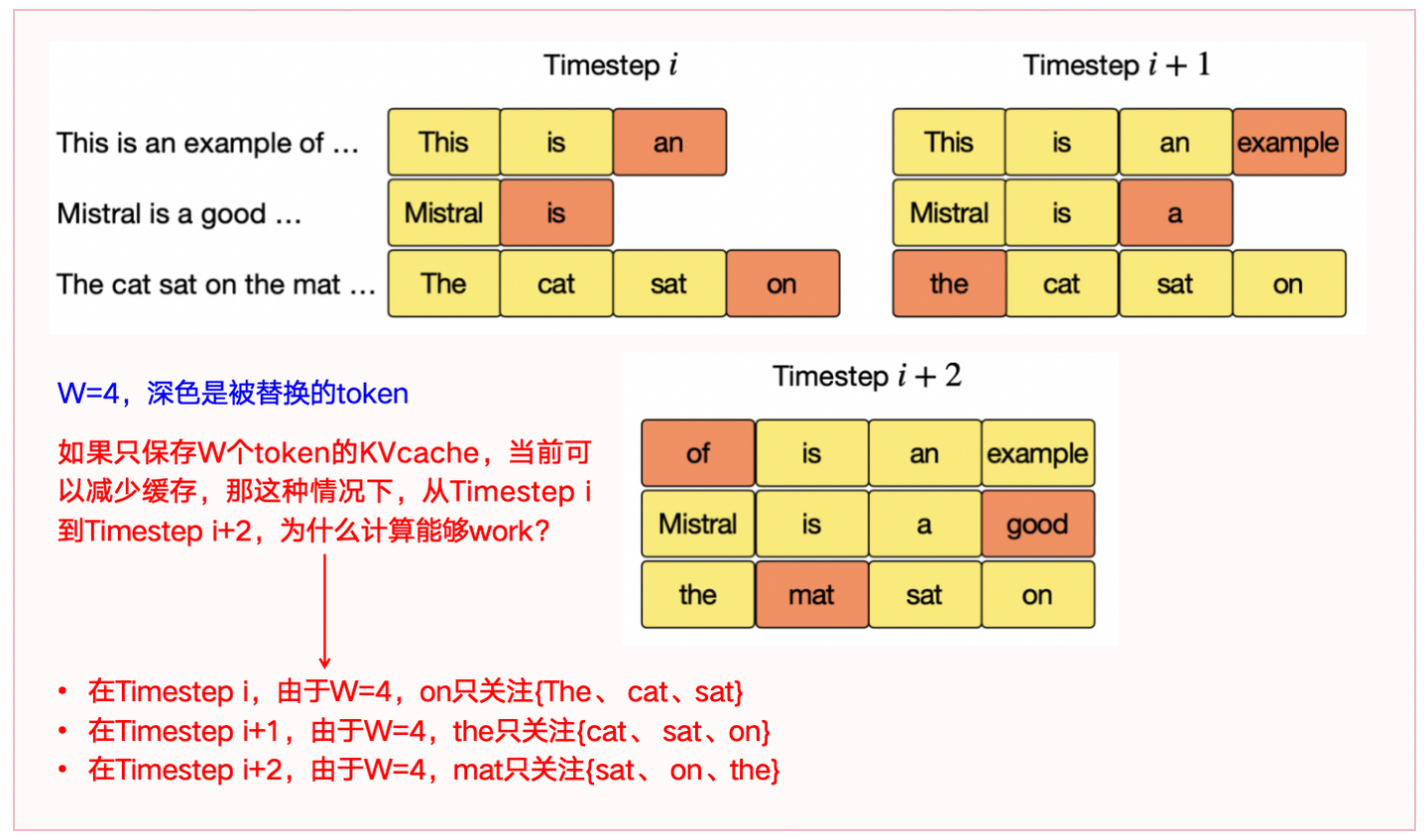
图1-2:滚动缓冲缓存的图解
参考资料
-
No backlinks found.