Rubric 评分细则的奖励机制
在现实世界的许多任务中,“验证答案是否正确”远比“真正回答正确”更容易。所以我们可以在这些场景下很好的通过强化学习提高模型的效果。1

数学推导、代码执行这些任务天然可验证——写个程序跑一遍就能判断对错。但开放式对话、创意写作、长文推理、医学咨询等,却没有单一的标准答案。
Rubrics as Rewards 提供了一个思路:把人类评分量表(rubric)直接当作奖励函数,让强化学习能在缺乏“标准答案”的环境中依然获得稳定的训练信号。
什么是 Rubric?
Wikipedia2 中的定义是“一套用于评价学生主观题作答质量的评分标准”
In the realm of US education, a rubric is a “scoring guide used to evaluate the quality of students’ constructed responses” according to James Popham. In simpler terms, it serves as a set of criteria for grading assignments. Typically presented in table format, rubrics contain evaluative criteria, quality definitions for various levels of achievement, and a scoring strategy. They play a dual role for teachers in marking assignments and for students in planning their work.
一个评分准则(scoring rubric)通常包含以下要素:
- 用于评判表现的维度或“标准”;
- 用以阐明所衡量属性的定义和示例;
- 以及针对每个维度的评分等级。
具体实操层面往往有四个角度:
- 评判依据(特质或维度):明确根据什么来评价学生的回答。
- 清晰的阐释:为每个评判维度提供明确的定义和具象化的示例。
- 评分量表:为每个维度设定一套评分的等级或分值。
- 优秀范例:为不同的表现层级(例如“优秀”、“良好”)设立标杆,并提供相应的范文或榜样。
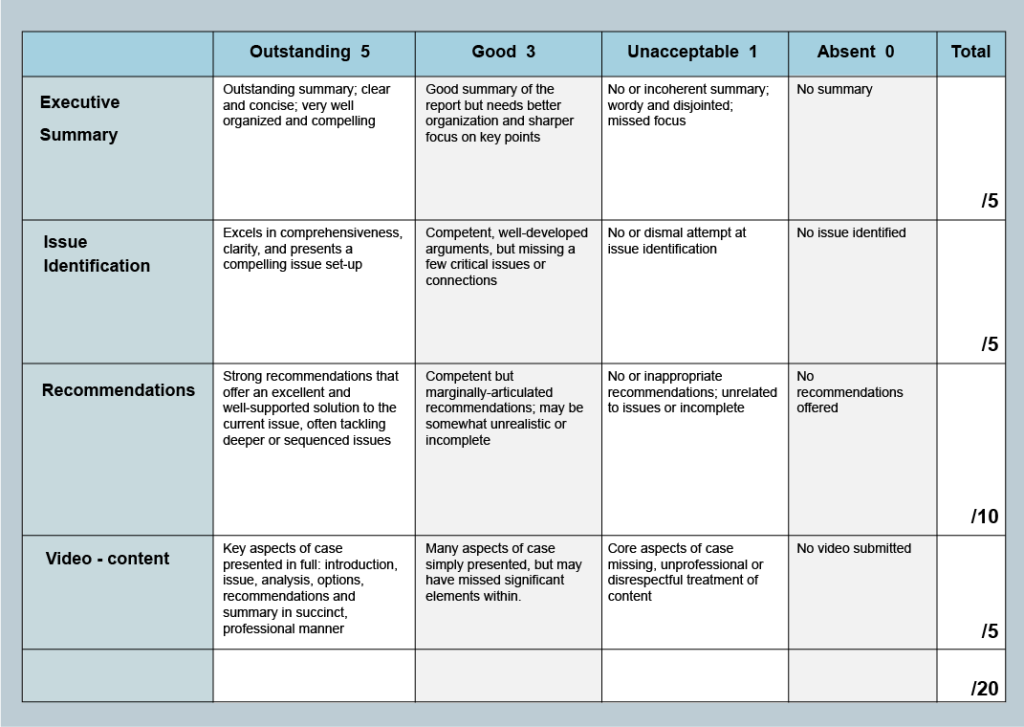
Rubric 如何参与强化学习
核心思想可以概括为一句话:Rubric as a Reward。
- 设计 Rubric:定义维度、分档、权重、示例。
- 大模型打分:使用强大的 LLM 作为“评分官”,按 Rubric 给出奖励分。
- 强化学习:将打分结果无缝嵌入 GRPO、DAPO 等 RL 算法,更新策略。
与传统 reward model 需要大规模人工标注不同,rubric 允许我们用已预训练的大模型来自动打分,大幅降低人工成本,并提供更细粒度的奖励信号。
这里没那么准确,其实 Reward Model 的标注往往也需要一份非常完备的 Rubric 作为操作手册,以保证标注数据的一致性和质量。所以我认为当前的 Rubric as a Reward 更像是用 LLM 替代外包标注人员,迭代重点变为如何找到更适合 LLM 理解的 Rubric Prompt。
设计高质量 Rubric 的五步法
高质量 Rubric 决定了奖励信号的有效性。一个实用的方法包括[3]:
- 确定维度
- 明确目标任务需要的品质,例如“事实正确”“逻辑连贯”“情感细腻”“安全合规”。
- 关键维度可设置 一票否决(veto),如安全、真实性。 2. 定义评分档
- 0–5 或 Pass/Fail,每档都需客观且可验证的描述。
- 避免模糊用语,用“是否包含具体事实错误”替代“是否感觉合理”
3. 示例与边界
- 为每档提供正反例,列出易引发歧义的案例及处理原则,降低评分噪声。 4. 聚合与权重
- 关键维度可 hard veto;其余维度用加权平均或非线性函数,体现“负面信号更有力”的不对称性。 5. 防范 Reward Hacking
- 专门设立“防御 Rubric”,覆盖常见作弊手法,如过度自夸、关键词堆砌、讨好用户。
- 一旦触发,直接降为 0 分。
和写 prompt 差不多。。。挺吃业务理解,以及对产品理想态的清晰思考和定义,还需要迭代式地覆盖更多类型的可能输入
在 LLM 训练中的应用
Rubric 得到的Score除了作为RL Reward,也可以用于其他地方
- Rubric-First Workflow
先写 Rubric,再产出数据与训练计划,确保目标一致。 - SFT 数据筛选
- 仅保留 Rubric 高分样本,保证微调数据质量。
- RL Reward
- 训练时直接使用 Rubric 打分结果,避免人工二次标注。
- SFT数据合成
- 在prompt中加入Rubric引导teacher model生成质量更高的轨迹数据 / 利用rubric对不合理的地方进行reflection & edit
用复杂 prompt 合成探索数据(加上Rubric),再用简单 prompt 做 SFT / RL。
参考
-
Jason Wei’s Blog: Asymmetry of verification and verifier’s rule, https://www.jasonwei.net/blog/asymmetry-of-verification-and-verifiers-law ↩︎
-
Rubric Wikipedia , https://en.wikipedia.org/wiki/Rubric_(academic) ↩︎
-
No backlinks found.