Routing Replay
Rollout Routing Replay 主要解决在专家混合(MoE)大模型中,因其路由机制在训练和推理阶段的行为不一致,导致训练和推理的 logprob 产生比较大的差异进而引起强化学习(RL)训练不稳定甚至崩溃的问题。
Rollout Routing Replay 会在模型进行推理时(Rollout 阶段),记录下每个 token 的 router 分布,然后在后续的训练过程中使用这些 router 分布进行计算。通过这种方式,强制训练过程模仿并对齐推理时的 router 行为,从而弥合两者之间的差异。
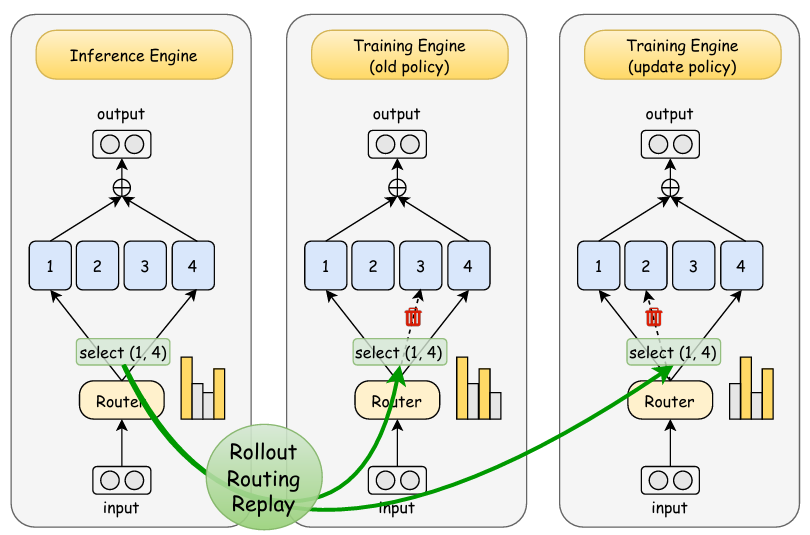
需要注意的是, GSPO 论文中提到的 Routing Replay, 是训练侧 old 和 target 策略之间,如果进行 token-level 的重要性采样,可能导致专家激活模式在新旧策略之间有差异,这种路由波动可能破坏训练稳定性,GSPO 因为引入了 seq-level 的重要性采样,对单个 token 的专家波动不敏感,可以不需要 routing replay(而 GRPO 不引入 routing replay 容易训崩)。而上面讨论的 routing replay,主要还是解决训推不一致导致的路由波动带来的问题。
Ref
- https://zhuanlan.zhihu.com/p/1937513263362471465
- https://zhuanlan.zhihu.com/p/81645193936
- https://zhuanlan.zhihu.com/p/1932872549869528407
- https://zhuanlan.zhihu.com/p/1936899646334140977
- https://www.zhihu.com/question/1933114350496875895/answer/1938328361345737229
- https://www.zhihu.com/question/1961967212060442711
- https://zhuanlan.zhihu.com/p/1959976628290590602
- https://arxiv.org/pdf/2510.19338
- https://code.byted.org/seed/alpha-seed/merge_requests/1214
- https://github.com/THUDM/slime/pulls?q=routing+replay
- https://code.byted.org/seed/alpha-seed/merge_requests/1549
- https://github.com/volcengine/verl/issues/3762
- https://arxiv.org/pdf/2507.18071
- https://arxiv.org/pdf/2510.11370
Linked Mentions
-
No backlinks found.