Quant
我们在前面介绍了校准。实际上,在实践中将浮点模型转为量化模型的方法有以下三种方法:
data free:不使用校准集,传统的方法直接将浮点参数转化成量化数,使用上非常简单,但是一般会带来很大的精度损失,但是高通最新的论文DFQ不使用校准集也得到了很高的精度。calibration:基于校准集方案,通过输入少量真实数据进行统计分析。finetune:基于训练finetune的方案,将量化误差在训练时仿真建模,调整权重使其更适合量化。好处是能带来更大的精度提升,缺点是要修改模型训练代码,开发周期较长。
按量化工作阶段的不同(压缩模型的阶段或者说量化应用的时间)来分类,校准可以分为如下三种:
- 训练中量化(QAT, Quantization-Aware-Training)。QAT 在模型训练过程中加入伪量化算子 Fake Quant,让量化目标无缝地集成到模型的训练过程中,然后使用训练数据进行微调,让模型在量化值的约束下进行调整和学习,通过训练时统计输入输出的数据范围来提升量化后模型的精度,适用于对模型精度要求较高的场景。
- 训练后量化(PTQ, Post-Training-Quantization)。PTQ 在模型训练完成后对其参数进行量化,只需要少量校准数据进行校准,以计算裁剪范围和缩放因子。PTQ 的主要优势在于其简单性和高效性,无需对 LLM 架构进行修改或进行重新训练。适用于追求高易用性和缺乏训练资源的场景。但 PTQ 可能会在量化过程中引入一定程度的精度损失。
- 量化感知微调(Quantization-Aware Fine-tuning,QAF)。QAF 在预训练模型的微调期间应用量化。主要目标是确保经过微调的 LLM 在量化为较低位宽后仍保持性能。通过将量化感知整合到微调中,以在模型压缩和保持性能之间取得平衡。
因为 QAF 比较小众,所以我们重点介绍 QAT 和 PTQ。
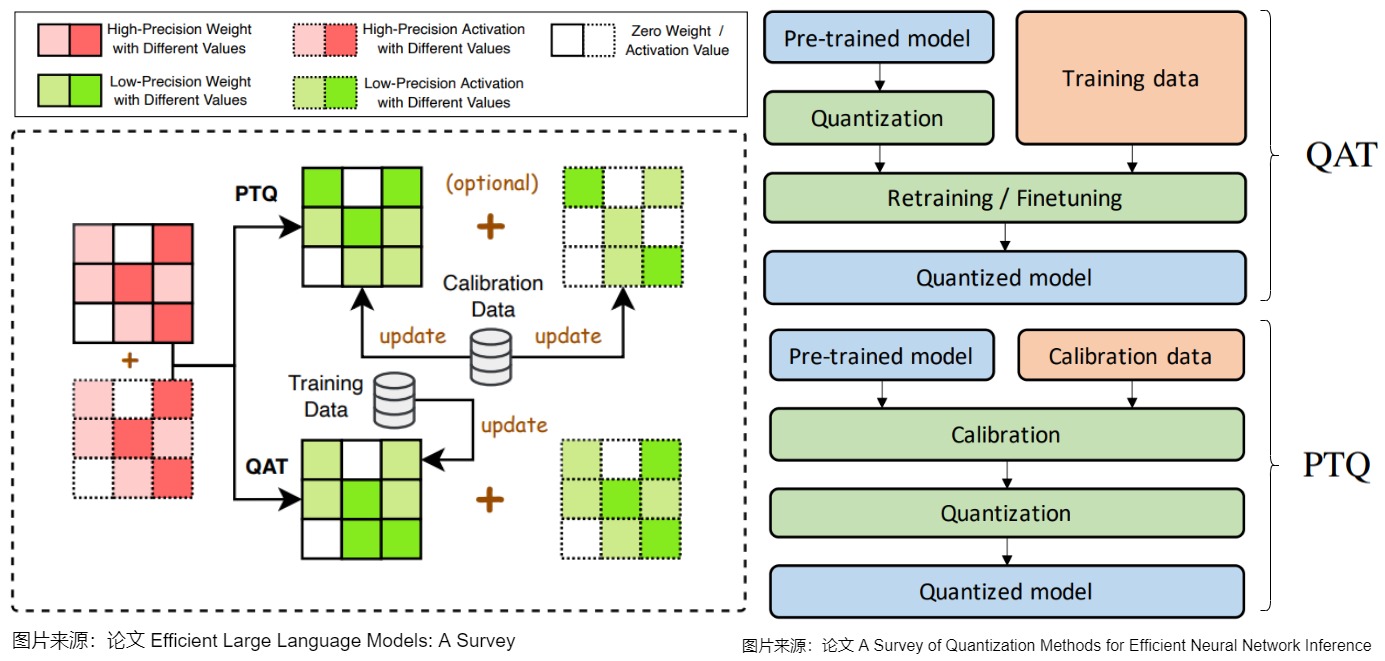
下图是 QAT 和 PTQ 之间的比较。
- 在 QAT 中,对预训练模型进行量化,然后使用训练数据进行微调,以调整参数并恢复准确性下降。
- 在 PTQ 中,使用校准数据(例如,训练数据的一个小子集)来校准预训练模型,以计算裁剪范围和缩放因子。然后,根据校准结果对模型进行量化。本质上 PTQ 就是在校准过程中,研究不同的 metric 来更好地选择截断上下界。
在实际应用中,更为常用的是 PTQ 的方法,大部分芯片厂商自己的编译器,已经集成了基础的 PTQ 方法,并与算子融合图优化等组合使用,对绝大部分模型能获得精度与速度都令人满意的结果。PTQ 还有一个额外的优点,那就是它可以应用于数据有限或未标记的情况。然而,与 QAT 相比,这通常会以较低的精度为代价,特别是对于低精度量化。另外,PTQ 还有一个缺点是,量化并不考虑实际的训练过程。
PTQ
PTQ 涉及在训练模型之后对模型的参数(包括权重和激活)进行量化。
权重的量化可以在推理之前使用对称量化或非对称量化来执行,因为在大多数情况下,在推理期间参数是固定的,裁剪范围可以事先静态确认。但是,激活 的量化需要推断模型以获取它们的潜在分布,因为每个输入样本的激活映射是不同的,我们事先不知道它们的范围。
所以这里又引出了激活量化的两种形式,即按照是否推理时使用可以分为静态/动态量化。静态量化是在推理前预先计算量化参数,通过校准样本输入离线找到典型的激活统计信息。动态量化是在运行时使用统计信息来动态计算量化参数,通常更准确但需要较高的开销来计算所需的统计信息。
从架构设计的角度来看,静态量化通过预计算的方式实现了最优的推理性能,这种方案在延迟稳定性和资源效率方面表现出色,特别适合边缘计算和大规模服务器部署场景。而动态量化则通过运行时自适应机制提供了更大的灵活性,能够更好地处理数据分布变化剧烈的场景,这在自然语言处理等领域具有独特优势。
动态量化
动态量化是一种在模型运行时进行量化的技术。它只对权重进行预先量化,对于激活值,则是在运行时动态计算量化参数,即在运行的时候动态计算每个激活的范围。具体流程是:
-
数据通过隐藏层后,其激活值被收集。
-
然后使用这些激活值的分布来计算量化输出所需的零点(z)和比例因子(s)值。
-
每次数据通过新层时都会重复此过程。每一层都有其自己的z 和 s 值,因此具有不同的量化方案。
动态量化每次计算范围开销很大,不如静态量化快,而且在某些硬件上也没法使用。但是这种方式简单灵活且效果也很好(精度更高),特别适用于那些输入数据分布变化较大的场景。
静态量化
静态量化是在模型推理之前完成的,因此称为"静态"量化。这种方法就是在量化前预先计算激活的范围值(z 和 s),为了找到这些值,需要使用一个代表性数据(校准数据集),将其提供给模型以收集激活值的分布情况。实际操作步骤如下:
- 模型训练完成后,在激活函数上放置观察器来记录激活值。
- 使用校准数据集进行若干次前向传播(大约使用几百个样本就足够了),执行推理流程后统计每层激活值的数据分布并且得到相应的量化参数。
- 在收集了这些值之后,就可以计算推理过程中执行量化所需的s 和 z 值,然后作为参数的一部分存储下来。
- 在进行实际推理时,s 和 z 值不会重新计算,而是全局使用,量化所有激活。因为它在校准过程中只用了一组和值。如果在实际推理时激活值的分布变化很大,就可能导致更高的量化误差。
小结
通常,动态量化由于仅尝试计算每个隐藏层的s 和 z 值,因此可能更准确。但是这会大大增加计算时间,因为需要计算这些值。静态量化的精度虽然较低,但由于已经知道用于量化的s 和 z 值,因此速度更快,所以一般都会使用静态量化。
QAT
有时候,一个训练好的模型数值分布较差,各种 PTQ 策略都不能获得很好的效果的时候,就需要采用 QAT 的方法,在训练或微调中引入量化误差,约束数值分布从而获得较好的量化结果。或者在少部分特殊的模型结构场景,更低 bit 量化的量化需求情况下,就得求助于 QAT 方法。
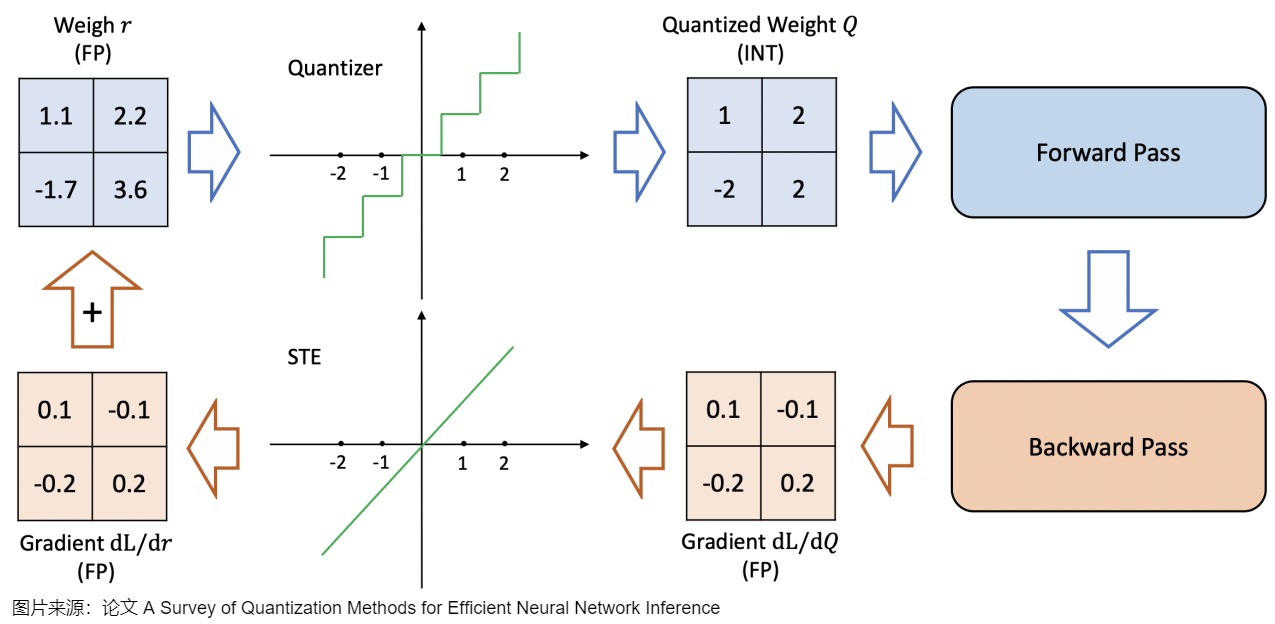
与训练后量化(PTQ)在模型训练完成 之后 进行量化不同,QAT 是在训练过程中学习量化过程(模拟量化),其利用伪量化算子将量化带来的精度损失计入训练误差,使得优化器能在训练过程中尽量减少量化误差,得到更高的模型精度。
QAT 通常比 PTQ 更精确,因为量化过程已在训练中被考虑。其工作原理如下:
- 初始化:设置权重和激活值的范围 qmin 和 qmax 的初始值;
- 构建模拟量化网络:在需要量化的权重和激活值后插入伪量化算子;这是一个首先将权重量化为例如 INT 4,然后再反量化回 FP 32 的过程。这个过程允许模型在训练、损失计算和权重更新过程中考虑量化过程。QAT 试图探索损失中的“宽”极小值以最小化量化误差,因为“窄”极小值往往会导致较大的量化误差。在一个“宽”极小值中选择一个不同的更新权重,其量化误差将大大降低。
- 量化训练:重复执行以下步骤直到网络收敛,计算量化网络层的权重和激活值的范围 qmin 和 qmax,并根据该范围将量化损失带入到前向推理和后向参数更新的过程中;
- 导出量化网络:获取 qmin 和 qmax,并计算量化参数 s 和 z;将量化参数代入量化公式中,转换网络中的权重为量化整数值;删除伪量化算子,在量化网络层前后分别插入量化和反量化算子。
所以尽管 PTQ 在高精度(例如 FP 32)中有更低的损失,但 QAT 在低精度(例如 INT 4)中会获得更低的损失。
参考资料
-
No backlinks found.