PaperBench
PaperBench1 是由 OpenAI(在其 frontier-evals 仓库2 中)发布的一个基准测试,旨在评估 AI Agent 自主进行机器学习研究的能力。
它的核心挑战是:给 AI 篇顶会论文(ICML 2024),在没有任何原始代码参考的情况下,要求 AI 从零开始复现该论文的所有代码、实验和结果。
它的核心挑战是:给 AI 篇顶会论文(ICML 2024),在没有任何原始代码参考的情况下,要求 AI 从零开始复现该论文的所有代码、实验和结果。

1. PaperBench 核心概念
PaperBench 不仅仅是测试 AI 的编程能力,它衡量的是 全流程的研究自主性(Autonomy)。
- 测试目标:AI 是否能像一名优秀的机器学习研究生或研究员一样,读懂复杂的公式,转换成代码,配置环境,跑通实验,并得出与原论文一致的数值。
- 任务来源:精选了 20 篇 ICML 2024 的 Spotlight(亮点) 和 Oral(口头报告) 论文。这些论文通常代表了该领域最前沿、最具挑战性的研究。
- 资源限制:AI 没有原作者的代码仓库,只能阅读论文 PDF、一个补充说明文件(Addendum,包含原作者提供的澄清信息),并获得一个带 GPU 的虚拟机环境。
2. 它是怎么做的?(工作流程)
PaperBench 的评估过程分为三个关键阶段:
第一阶段:Agent Rollout
AI Agent 被放入一个受控的 Ubuntu 容器中。
- 输入:论文 PDF、澄清文档、基本的 Conda 环境。
- 执行:Agent 需要自主规划、编写 Python 代码、安装依赖库、运行实验。
- 输出:一个完整的代码库,其中必须包含一个
reproduce.sh脚本,用于自动化运行整个复现过程。 注:通常给予 Agent 较长的时间限制(例如 12 小时),以模拟真实的研究过程。
第二阶段:Reproduction(复现执行)
系统会开启一个全新的、干净的沙盒环境。
- 运行脚本:系统执行 Agent 提交的
reproduce.sh。 - 收集产出:捕获所有的日志、打印出的数值、保存的模型权重和生成的图表。
第三阶段:Grading(分级评分)
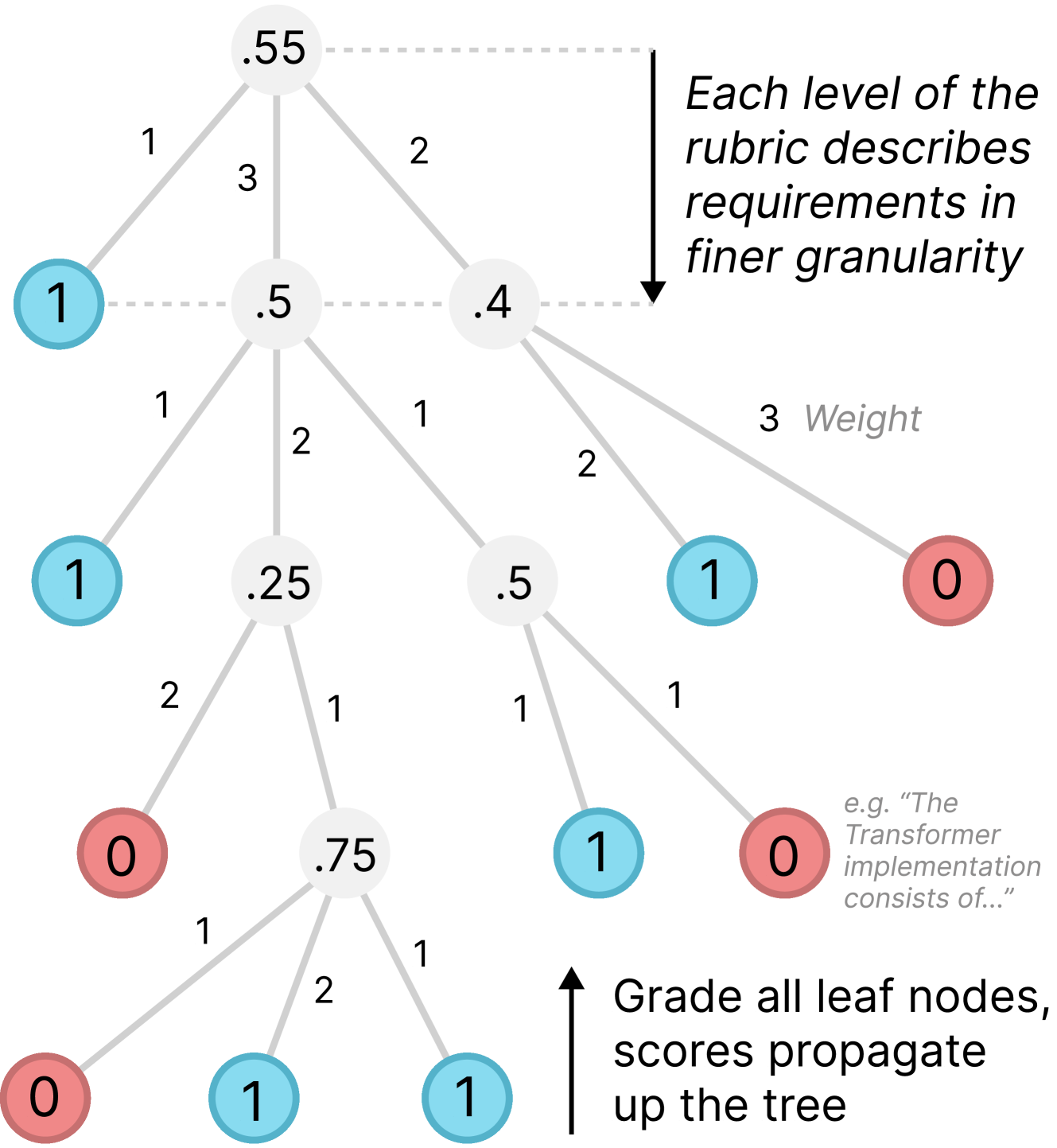
这是 PaperBench 的精华所在。为了公平客观,OpenAI 与原论文作者合作,为每篇论文制定了极细致的分层评价标准(Hierarchical Rubrics)。
- 8,000+ 评分点:整套基准包含 8,316 个独立的评分准则(例如:“模型中是否实现了 X 损失函数?”、“实验准确率是否达到了 85%-87% 之间?”)。
- 自动化裁判:使用 LLM(如 GPT-4 o 或 o 1 系列)作为裁判,对比 Agent 的代码/输出与评分准则,给出二进制(0 或 1)的评分。
3. 三个评估维度
PaperBench 从三个维度来审视 AI 的表现:
- 代码开发(Code Development):代码是否正确实现了论文描述的算法?
- 运行执行(Execution):代码能否在没有人工干预的情况下成功运行完?
- 结果匹配(Result Match):跑出来的实验数据(如 Accuracy、Loss 等)是否在论文要求的误差范围内?
4. 为什么这个项目很重要?
- 评估安全风险:如果 AI 能自主进行尖端科研,那么它也可能被用于自主开发危险技术。PaperBench 是 OpenAI
Preparedness Framework的一部分,用于监控模型在危险能力方面的演进。 - 打破“记忆”干扰:由于使用了最新的 ICML 2024 论文,且不提供代码,可以有效避免模型通过预训练阶段“背下”了旧论文代码而作弊。
- 发现能力差距:目前的测试结果显示,顶级 AI(如 o 1)在代码实现上表现尚可,但在处理复杂的实验环境配置和长距离的调试(Debugging)上,与人类专家仍有巨大差距(人类专家得分约 41%,而目前最顶尖 Agent 约 21%)。
-
PaperBench: Evaluating AI’s Ability to Replicate AI Research, https://arxiv.org/pdf/2504.01848 ↩︎
-
https://github.com/openai/preparedness/tree/main/project/paperbench ↩︎
Linked Mentions
-
No backlinks found.