Paged Attention
现有的 LLM 服务系统在管理 KV 缓存内存方面效率不高。这主要是因为它们把 KV 缓存存储在连续的内存空间中(大多数深度学习框架要求张量必须存储在连续的内存中)。然而,与传统深度学习工作负载中的张量不同,KV 缓存有其独特的特点(每个请求都需要大量的内存,且这些内存的需求是动态变化的):
- 它随着模型生成新词而动态增长和收缩。而且,每个请求的 KV 缓存增长缓慢,即每次迭代增加一个 token。
- 它的生命周期和长度是未知的。无法预先预判 KV 缓存的总大小。
问题
这些特点使得现有系统的管理方式显得非常低效。在现有系统的块预分配方案中,具体存在以下几种主要的内存浪费来源:为潜在最大序列长度过度分配导致的内部碎片化,为未来 token 保留的插槽、以及来自内存分配器(如伙伴分配器)的外部碎片化。
-
现有的大语言模型(LLM)服务系统在管理 KV 缓存内存方面效率不高。这主要是因为它们把 KV 缓存存储在连续的内存空间中(大多数深度学习框架要求张量必须存储在连续的内存中)。然而,与传统深度学习工作负载中的张量不同,KV 缓存有其独特的特点(每个请求都需要大量的内存,且这些内存的需求是动态变化的):
-
它随着模型生成新词而动态增长和收缩。而且,每个请求的 KV 缓存增长缓慢,即每次迭代增加一个 token。
-
它的生命周期和长度是未知的。无法预先预判 KV 缓存的总大小。
这些特点使得现有系统的管理方式显得非常低效。在现有系统的块预分配方案中,具体存在以下几种主要的内存浪费来源:为潜在最大序列长度过度分配导致的内部碎片化,为未来 token 保留的插槽、以及来自内存分配器(如伙伴分配器)的外部碎片化。
为潜在最大序列长度过度分配导致的内部碎片化
对应下图上的圆形标号 1。
- 由于请求的总序列长度事先不确定,为了在连续空间中存储请求的 KV 缓存,这些系统通常会预测请求的最大可能序列长度,从而提前为一个请求静态分配一块连续的存储空间,以容纳最大的序列长度。而不管实际的输入或最终的输出长度。因为请求的实际长度往往比最大长度短很多,这种分配中的一部分几乎肯定永远不会被使用,并且也无法被其他请求利用,最终被浪费(即内部内存碎片化)。由于内部碎片而浪费了大量的 GPU 内存。因此,这些系统的吞吐量较差,无法支持大批量大小。
- KV 缓存是矩形的:你分配一个大的矩形内存,其中一个维度是批量大小(模型一次可以处理的最大序列数),另一个维度是允许用户使用的最大序列长度。当一个新序列进入时,你会为这个用户分配整行内存,假设预测每个用户最大上下文长度是 2048,则需要为每个用户预先分配一个可支持 2048 个 tokens 缓存的显存空间。如果用户实际使用的上下文长度低于 2048,这种方法显然会造成存储资源的大量浪费。
提前为未来 token 保留的插槽
对应下图上的圆形标号 2。即使实际序列长度事先已知,预分配的方式仍然低效。因为每个请求的 KV-cache 每次增加一个标记,而在请求的生命周期内,整个内存块都会被保留,由于内存逐渐被消耗,但内存块被保留到请求的整个生命周期,较短的请求仍然无法使用尚未使用的内存块。
External Fragmentation
来自内存分配器 (如伙伴分配器)的外部碎片化和其它损耗。对应下图上的圆形标号 3。
- 由于 KV Cache 是一个巨大的矩阵,且必须占用连续内存,操作系统只分配大的连续内存,如果不同请求的预分配大小不同,势必有很多小的内存空间被浪费掉,导致外部内存碎片化。
- 在 Paged Attention 之前,业界主流 LLM 推理框架在 KV Cache 管理方面均存在一定的低效。HuggingFace Transformers 库中,KV Cache 是随着执行动态申请显存空间,由于 GPU 显存分配耗时一般都高于 CUDA kernel 执行耗时,因此动态申请显存空间会造成极大的时延开销,且会引入显存碎片化。
- 现有系统无法利用内存共享的机会。LLM 服务常常使用高级解码算法,比如并行采样和束搜索,这些算法会为每个请求生成多个输出。在这些场景中,请求包含的多个序列可以部分共享其 KV 缓存。然而,现有系统中,序列的 KV 缓存存储在不同的连续空间中,无法实现内存共享。
另外,尽管已经提出了压缩作为解决碎片化的潜在方案,但在一个对性能敏感的LLM服务系统中执行压缩是不现实的,因为KV缓存非常庞大。即使有压缩,每个请求的预分配块空间也阻碍了现有内存管理系统中特定解码算法的内存共享。

PagedAttention (vLLM) 借鉴了操作系统中的分页(Page)方式进行存储,将 KV Cache 分为固定大小块,存储在非连续的物理内存中,这样可以为 vLLM 提供更灵活的分页内存管理。通过使用相对较小的小块并按需分配,PagedAttention 缓解了内部内存碎片化问题。此外,由于所有小块大小相同,它还消除了外部内存碎片化问题。PagedAttention 也可以使同一请求的不同序列甚至不同请求之间可以在小块级别共享内存,实现了内存共享。
下图给出了因为内部碎片造成的内存浪费,阴影框表示 KV token 占用的内存,而白色框表示已分配但未使用的内存。
- Orca(顶部)提前为 KV 缓存保留一块连续的虚拟内存。分配的大小对应于模型支持的最大序列长度,例如 32 K。由于模型生成的 token 通常远少于最大限制,因此由于内部碎片而浪费了大量 GPU 内存。
- vLLM(底部)通过动态内存分配减轻碎片化。

实现
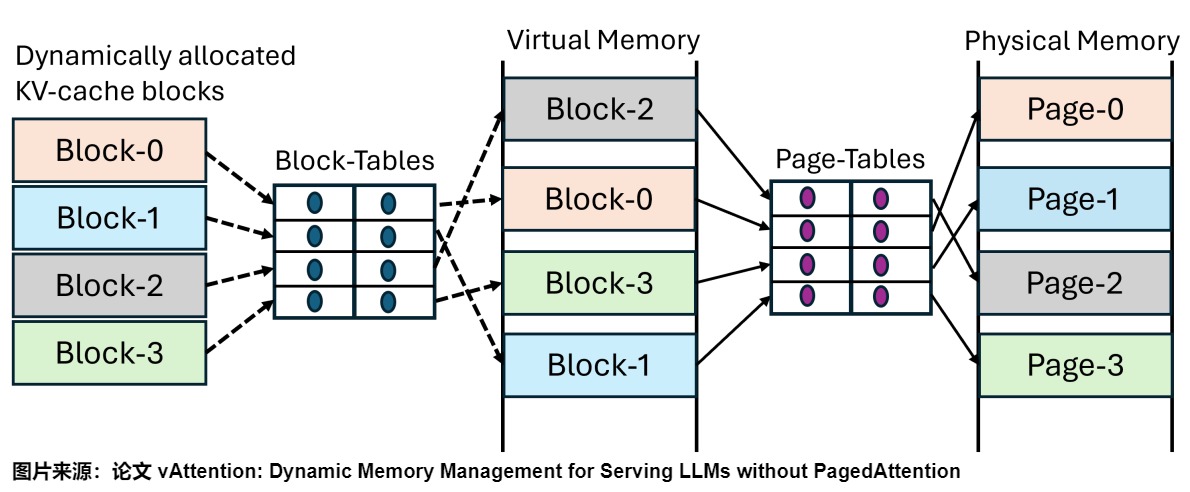
PagedAttention 的灵感来源于操作系统中的虚拟内存和分页技术。操作系统将内存划分为固定大小的页面,并将用户程序的逻辑页面映射到物理页面。连续的逻辑页面可以对应非连续的物理内存页面,使得用户程序可以像访问连续内存一样访问内存。PagedAttention 将 KV 缓存组织成固定大小的 KV 块,类似于虚拟内存中的页面。而 vLLM 实现了一个类似虚拟内存的系统,通过复杂的映射机制管理这些块。这种架构将逻辑和物理 KV 块分开,通过跟踪映射关系和填充状态的块表实现动态内存分配和灵活的块管理。具体特点如下。
- 为了能够动态分配物理内存,PagedAttention 将 KV Cache 的布局从连续的虚拟内存更改为非连续的虚拟内存。
- PagedAttention 将 KV 缓存分割为固定大小且相对较小的内存块,称为块,每个块可以包含固定数量的词元的键和值。这些块类似于进程虚拟内存中的页面,因此我们可以像操作系统管理虚拟内存那样灵活地管理 KV 缓存。PagedAttention 每次为一个块分配内存。这些小块不需要存储在连续的空间中,可以在 GPU 和 CPU 内存之间进行交换,并且必要时可以在不同的请求之间共享。
- VLLM 不是预先保留 KV 缓存内存的最大序列长度,而是只在需要时分配请求所需的内存,即允许生成过程中不断为用户追加显存,而不是提前分配。通过 token 块粒度的显存管理,系统可以精确计算出剩余显存可容纳的 token 块的个数,配合 Dynamic Batching 技术,即可避免系统发生显存溢出的问题。
- PagedAttention 实现一个块表来将这些非连续的分配拼接在一起。也实现了一个高效的显存管理器,通过精细化管理显存,实现了在物理非连续的显存空间中以极低的成本存储、读取、新增和删除 KV向量。
PagedAttention 涉及两层地址转换。首先,该框架通过 Block Table 跟踪 KV Cache 块的虚拟内存地址。其次,GPU 通过操作系统管理的页表执行虚拟到物理地址的转换。具体如下图所示。
架构
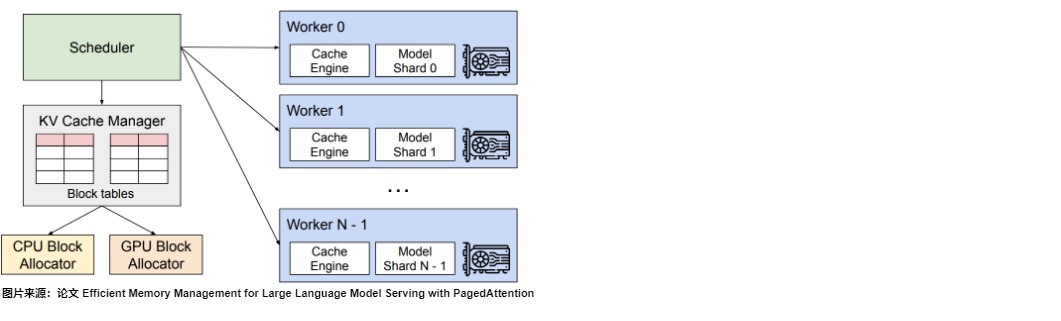
VLLM 的架构如下图所示,具体分为 2 部分:
- Scheduler。VLLM 采用集中式调度器来协调分布式 GPU worker 的执行和对应的物理 KV 缓存内存。
- KV Cache Manager。KV 缓存管理器通过 PagedAttention 以分页方式有效地管理 KV 缓存。
KV Cache 管理器
PagedAttention 首先加载模型,这样就知道剩余多少空间给 KV Cache,后续会用内存块填充这些空间。这些块可以包含最多 16 或 32 个 token。
系统会动态维护一个显存块的链表——每个请求的逻辑和物理 KV 块之间的映射关系。每个块表条目记录了逻辑块的相应物理块及其填充位置的数量,通过该方式即可实现将地址不连续的物理块串联在一起统一管理。当一个请求来到之后,系统会为这个请求分配一小块显存,这一小块显存通常只够容纳 8 个字符,当请求生成了 8 个字符之后,系统会追加一块显存,请求可以把结果再写到这块显存里面。当生成的长度不断变长时,系统会不断地给用户追加显存块的分配,并动态更新显存块列表。将逻辑和物理 KV 块分开使得 vLLM 可以动态增长 KV 缓存内存,而无需提前为所有位置预留空间,这消除了现有系统中大部分的内存浪费。
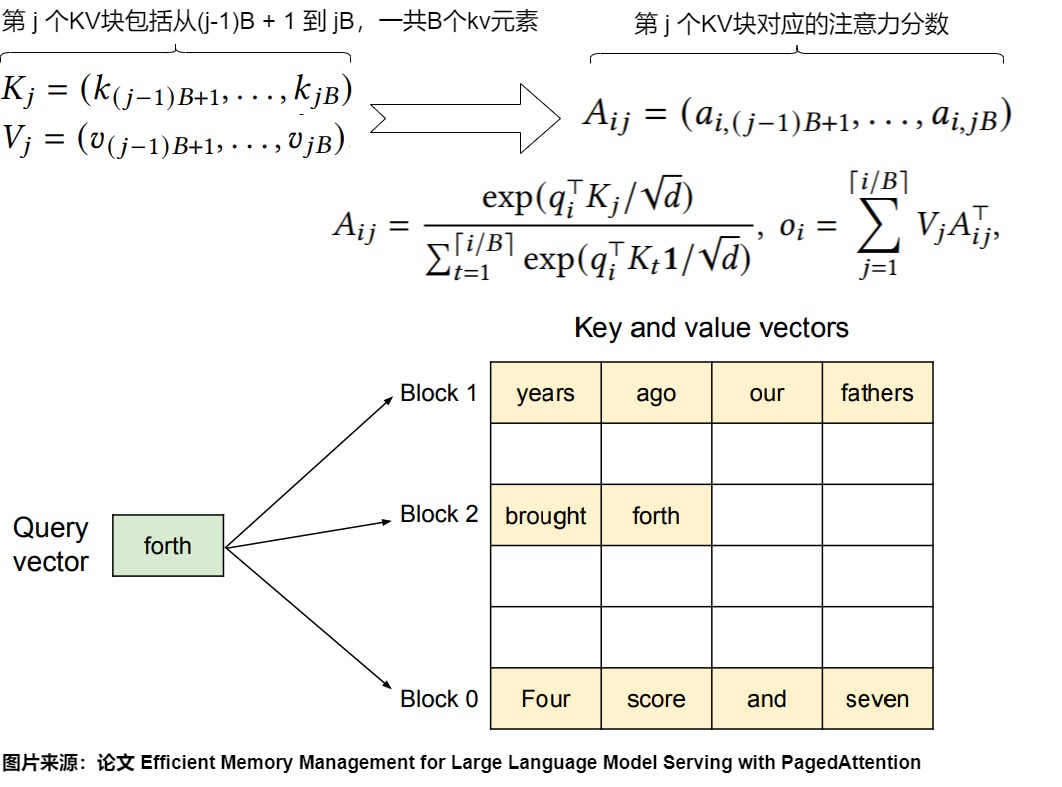
下图是算法。PagedAttention 将每个序列的键值(KV)缓存划分为 KV 块。每个块包含一定数量的 token 的键和值向量。例如,键块 Kj 包含的是第 j 个块中的键向量,而值块 Vj 包含的是第 j 个块中的值向量。在注意力计算过程中,PagedAttention 内核分别识别和获取不同的 KV 块。例如,当处理 query token为“forth”时,内核将查询向量 qi 与每个块中的键向量 Kj 相乘,以计算注意力得分 Aij。然后,它将这些得分与每个块中的值向量 Vj 相乘,得出最终的注意力输出。
基本场景的解码算力
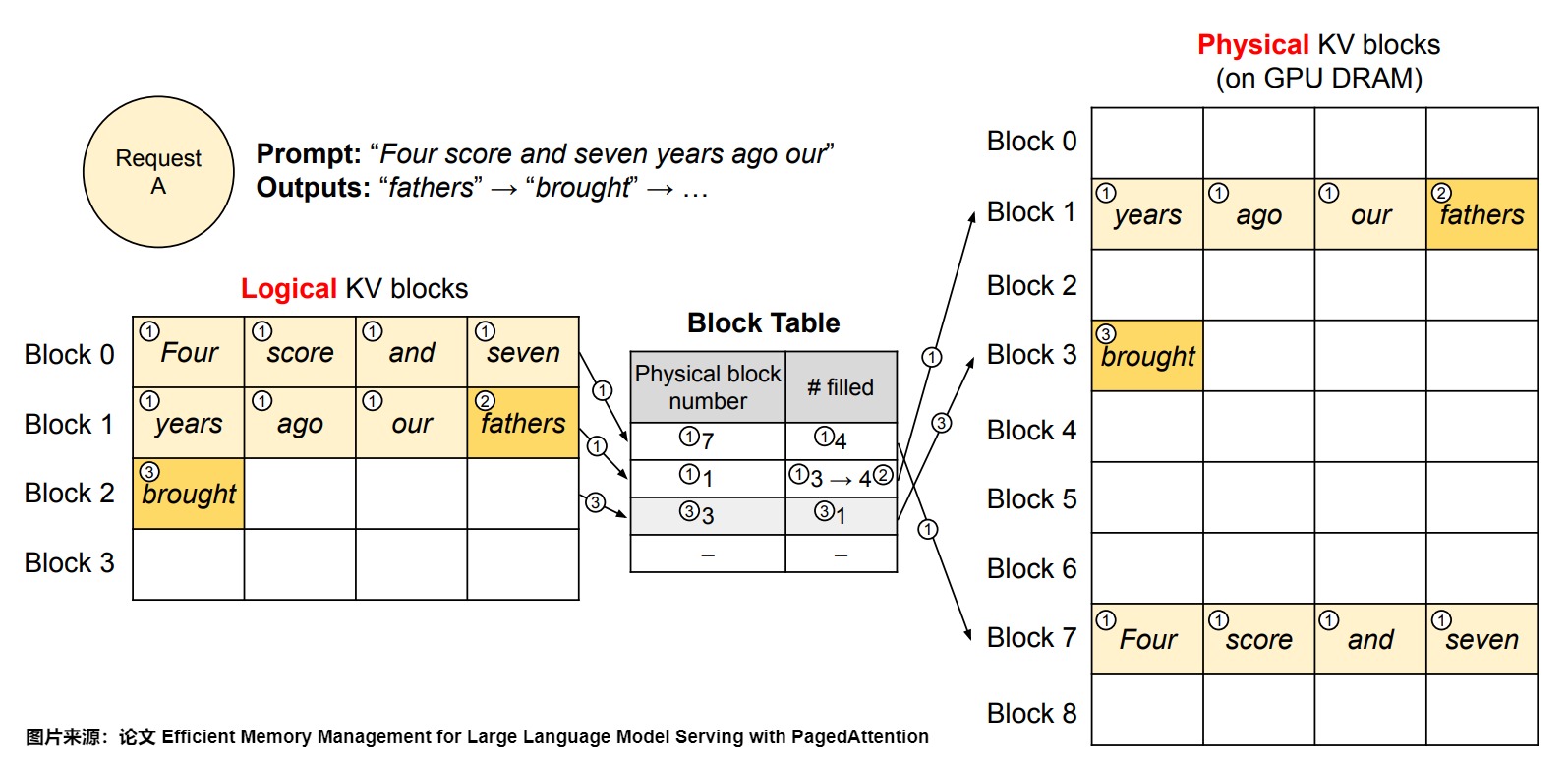
下图是 vLLM 是如何执行 PagedAttention,并在单个输入序列的解码过程中管理内存的示例。总的来说,对于每个解码迭代,vLLM 首先选择一组候选序列进行批处理,并为新需求的逻辑块分配物理块。然后,vLLM 将当前迭代的所有输入标记(即提示阶段请求的所有标记和生成阶段请求的最新标记)串联为一个序列,并将其输入到 LLM 中。
- VLLM 在初始阶段不需要为最大可能生成的序列长度预留内存。相反,它只保留了足够容纳 prompt 计算期间生成的 KV 缓存所需的 KV 块。在本例中,提示有 7 个标记,因此 vLLM 将前两个逻辑 KV 块(0 和 1)映射到两个物理 KV 块(7 和 1)。在 prefill步骤中,vLLM 使用传统的自注意力算法生成提示和第一个输出标记的 KV 缓存。然后,vLLM 将前 4 个标记的 KV 缓存存储在逻辑块 0 中,后续 3 个标记存储在逻辑块 1 中。剩余的位置留待后续自回归生成阶段使用。此处对应下图上标号1。
- 在第一个自回归解码步骤中,vLLM 使用 PagedAttention 算法在物理块 7 和 1 上生成新的标记。由于最后一个逻辑块中还有一个空位,新生成的 KV 缓存被存储在那里,并且更新了块表中的已填充记录。
- 在第二个自回归解码步骤中,由于最后一个逻辑块已满,vLLM 将新生成的 KV 缓存存储在一个新的逻辑块中;vLLM 为其分配一个新的物理块(物理块 3)并将此映射存储在块表中。
劣势
然而,为了能够动态分配物理内存,PagedAttention 也增加了软件复杂性、导致可移植性问题、冗余和低效。
- 需要重新编写注意力核心(GPU 代码),以便注意力核心通过索引查找到 KV 缓存(虚拟连续对象)的所有元素。
- 增加了软件复杂性和冗余(CPU 代码)。PagedAttention 还迫使开发人员在服务框架中实现内存管理器,使其负责(解)分配 KV 缓存并跟踪动态分配的 KV 缓存块的位置。这种方法实质上是在用户代码中重新实现了按需分页-这是一个操作系统功能。
- 引入了性能开销。PagedAttention 在关键路径上增加了运行时开销。首先,它需要 GPU 核心执行与从非连续内存块获取 KV 缓存相关的额外代码。我们展示了这在许多情况下可能会使注意力计算速度减慢超过 10%。其次,用户空间内存管理器可能会增加 CPU 开销,导致额外的10%成本。
vAttention
VAttention 作者认为保留 KV Cache 的虚拟内存连续性对于减少 LLM 部署中的软件复杂性和冗余至关重要,并主张利用操作系统中现有的虚拟内存抽象来管理动态 KV Cache 内存,从而实现简化部署和更高性能。基于这些思考,vAttention 作者提出了 vAttention,其特点如下。
- 将 KV Cache 存储在连续的虚拟内存中,而不是事先分配物理内存。作为对比,PagedAttention 在虚拟地址上是不连续的。
- 为 KV Cache 保留连续的虚拟空间,并按需分配物理内存。
- 在不需要在服务系统中实现内存管理器的情况下,实现了更高的可移植性,同时可以无缝重用现有的 GPU 核心。使注意力核心开发人员不必显式支持分页,并避免在服务框架中重新实现内存管理,实现了对各种注意力核的无缝动态内存管理。
洞察
VAttention 对 LLM 服务系统有一些洞察。
- 观察 1:在每次迭代中,KV Cache 的内存需求是可以预先知道的。这是由于自回归解码每次只生成一个标记。因此,随着每次迭代,请求的 KV Cache 内存占用量会均匀地增加一个标记,直到请求完成。
- 观察 2:KV Cache 不需要高内存分配带宽。在所有层中,单个标记的内存占用通常为几十到几百 KB。此外,每次迭代持续 10 到 100 毫秒,这意味着每秒最多需要几兆字节的内存。虽然批处理可以提高系统的吞吐量,但每秒生成的标记数量在达到一定批大小后就会趋于平稳。这意味着内存分配带宽需求在大批大小下也会饱和。
设计概述
VAttention 目标是通过为现有的 kernel 添加动态内存分配支持来提高效率和可移植性。为了实现这一目标,vAttention 利用系统支持的动态内存分配,而不是在用户空间中实现分页。
VAttention 基于将虚拟内存和物理内存分别分配的能力进行构建。具体来说,vAttention 预先在虚拟内存中为 KV-cache 分配一个大的连续缓冲区(类似于基于保留的分配器),而将物理内存的分配推迟到运行时,即只在需要时分配物理内存(类似于 PagedAttention)。这样,vAttention 在不浪费物理内存的情况下保留了 KV Cache 的虚拟连续性。这种方法之所以可行,是因为内存容量和碎片化仅对物理内存构成限制,而虚拟内存是充裕的,例如,现代 64 位系统为每个进程提供 128 TB 的用户管理虚拟地址空间。
- 预留虚拟内存。由于虚拟内存是丰富的,我们预先分配足够大的虚拟内存空间,以容纳所需支持的最大批次大小的 KV-cache(可配置)。虚拟内存缓冲区的数量:每个 LLM 中的每个层都维护自己的 K 和 V 张量:我们将它们分别称为 K-cache 和 V-cache。我们为 K-cache 和 V-cache 分别分配单独的虚拟内存缓冲区。
- 按需分配物理内存。VAttention 优先按页一次性分配物理内存,仅当一个请求使用完其先前分配的所有物理内存页时才分配。
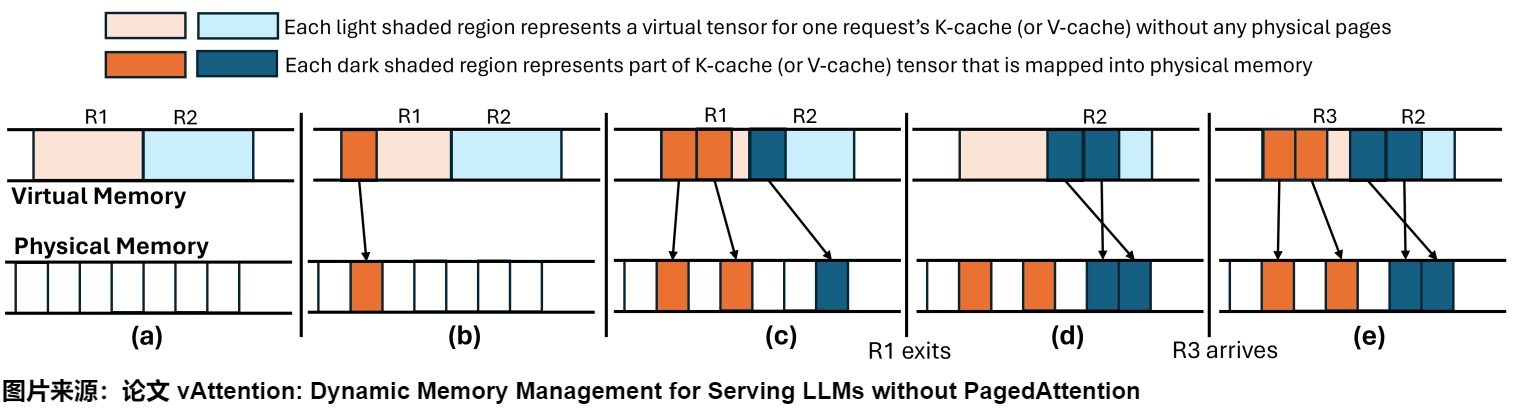
下图展示了 vAttention 如何通过按需分配物理内存来动态管理 KV Cache 的内存,同时通过延迟回收策略优化内存使用,以便在新的请求到达时可以高效地重新利用已经分配的物理内存。此处是处理模型的一层中的 K-cache(或 V-cache),假设最大批次大小为两个。其余的 K-cache 和 V-cache 缓冲区在所有层中以相似的方式进行管理。具体分为五个步骤:
- (a):虚拟内存中包含了两个请求(R1 和 R2)的虚拟张量,但还没有进行任何物理内存分配。浅色阴影区域代表了没有任何物理页支持的虚拟张量部分。
- (b):R1 被分配了一页物理内存。这个分配使得虚拟张量的一部分(浅色阴影区域)映射到了实际的物理内存上(深色阴影区域)。
- (c):R1 被分配了两页物理内存,而 R2 被分配了一页物理内存。此时,R1 的虚拟张量有两部分映射到了物理内存上,而 R 2 的虚拟张量有一部分映射到了物理内存上。
- (d):R 1 已经完成了它的任务,但 vAttention 没有立即回收其内存(延迟回收)。因此,R 1 的虚拟张量依旧占据物理内存。
- (e):当新的请求 R3 到达时,vAttention 将 R 1 的张量分配给 R 3,因为这些张量已经有物理内存支持。
-
No backlinks found.