NaViT
NaViT(Native Resolution Vision Transformer)是 Google DeepMind 于 2023 年在论文 Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution 中提出的创新架构,彻底解决了传统 ViT 依赖固定分辨率 / 方形比例的痛点,实现了 “任意分辨率、任意宽高比” 的高效训练与推理。
固定分辨率输入图像在 CV 领域一直是一个问题。ViT 的出现,将图片进行图块化,得到 1D token 序列进行统一处理的这种形式,使得我们有望克服这一问题。我们可以参考 NLP 在 Transformer 的序列建模方面的一些经验,应用到 ViT 上,实现任意分辨率、任意长宽比的高效训练上。
首先,在模型结构上,原始 ViT 无法支持任意分辨率输入图像的根本原因是在于其位置编码是可学习的 1D 位置嵌入,只能处理固定分辨率、固定长宽比的输入。作者首先对 ViT 的位编码进行了修改。但是今天来看更好地的 ViT 位置编码方式或许是 2D RoPE
其次,在支持任意分辨率输入后,不同图片在同一个 batch 内,为了进行并行计算需要 padding 以保持序列长度相同,如果 batch 内图片分辨率差异过大,会造成大量的计算资源浪费。NaViT 借鉴自然语言处理中的处理方式,提出训练时将多张图片打包到同一个序列中,从而避免浪费,提高可变长序列的训练效率。同时为了避免同 sequence 内的不同图片相互干扰,NaViT 还在 self attention 和最终的输出 pooling 上为每张独立图片添加了对应的 mask。
由来与演进背景
1. 传统 ViT 的核心局限
ViT(Dosovitskiy et al., 2021)将图像切分为固定大小的 patch(如 16x16),并输入 Transformer 编码器。但为了适配硬件矩阵运算,必须将所有图像缩放到固定分辨率(如 224x224),导致两个关键问题:
- 缩放破坏细节:强制拉伸 / 压缩会扭曲图像结构(如宽屏风景图变方形);
- 填充效率低下:若用 padding 保留宽高比,大量无效区域会浪费计算资源。
对 ImageNet 等数据集的分析显示,超 70% 的图像非方形,固定分辨率训练与真实数据分布存在天然矛盾。
2. 前期探索:FlexiViT 与 Pix2Struct
在 NaViT 之前,已有工作尝试突破固定分辨率限制:
- FlexiViT(Beyer et al., 2023):支持多种 patch 尺寸(如 12x12、16x16),通过随机采样 patch 大小动态调整序列长度,但仍需固定图像宽高比;
- Pix2Struct(Lee et al., 2022):保留图像原始宽高比,通过 “分块填充” 适配文档 / 图表理解任务,但未解决训练效率问题。
NaViT 在这两个方向的基础上,进一步提出 Patch n’ Pack 机制,同时实现了 原生分辨率训练 和 硬件高效利用。
位置编码
首先,在模型结构上,ViT 需要支持变长的输入 token 序列。原始的 ViT 显然是无法做到这一点的,它只能处理方形、固定分辨率 $(R, R)$ 的输入图片,因为其位置编码采用的是可学习 1D 位置嵌入,这样在训练完成之后,原始 ViT 只能处理特定分辨率的输入图像,如果想要拓展到其他分辨率,需要对学习到的位置嵌入进行插值。
Pix2Struct 在训练时学习尺寸为 [maxLen, maxLen] 的 2D 位置嵌入,对每个图块位置通过 (x, y) 进行二维索引,这样就能在推理时处理分辨率最大为 (P * maxLen, P * maxLen) 的输入图片。然而这需要在训练时见到过所有 (x,y) 组合,也比较麻烦。
NaViT 考虑了拆分的位置编码(factorized positional embedding),即将图片的长、宽两个位置维度分开来进行编码,使用两个分离的嵌入 $\phi_x, \phi_y$ 来表示位置 (x,y) 处的位置编码,然后将它们加和起来。
作者考虑了
- 绝对索引嵌入 $\phi(p): [0, \text{maxLen}] \to \mathbb{R}^D, \quad p \in [0, \text{maxLen}]$
- 相对位置嵌入 $\phi(r): [0, 1] \to \mathbb{R}^D, \quad r = \frac{p}{\text{sideLen}} \in [0, 1]$ 后者可以给出与图片绝对尺寸无关的位置编码,但是会对原始长宽比造成一定程度的混淆。对于位置编码的具体形式,作者也考虑了可学习、正弦和傅里叶三种形式。
核心技术 Patch n’ Pack
借鉴 NLP 中的 example packing(将多个短文本打包成一个长序列训练)
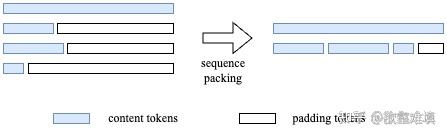
NaViT 将不同分辨率 / 宽高比的图像 patch 打包到单个 Transformer 序列中,如下图所示:
在模型结构支持了任意分辨率输入图像后,我们在训练时需要对不同序列长度的输入图片进行 padding,以保证 batch 内序列长度相等。这会造成很多的计算资源浪费。作者借鉴 NLP 中的做法,将多张图片打包到同一个系列中,以尽量减少 padding。
但是我们将多个样本的 token 打包进了同一个序列中,需要保证不同样本彼此之间没有影响。在 ViT 中,会导致 token 之间彼此影响的地方就是自注意力层,因此我们在 ViT 的自注意力计算时,根据 token 所来自的不同样本设置掩码,避免来自不同样本的 token 互相 attend 到。
此外,ViT 会采取对各 token 进行 pooling 的方式来得到最终的单个输出 embedding,在这里我们也需要进行 pooling,对来自同一个样本的输出 token 进行 pooling,每个样本最终得到单个 embedding。
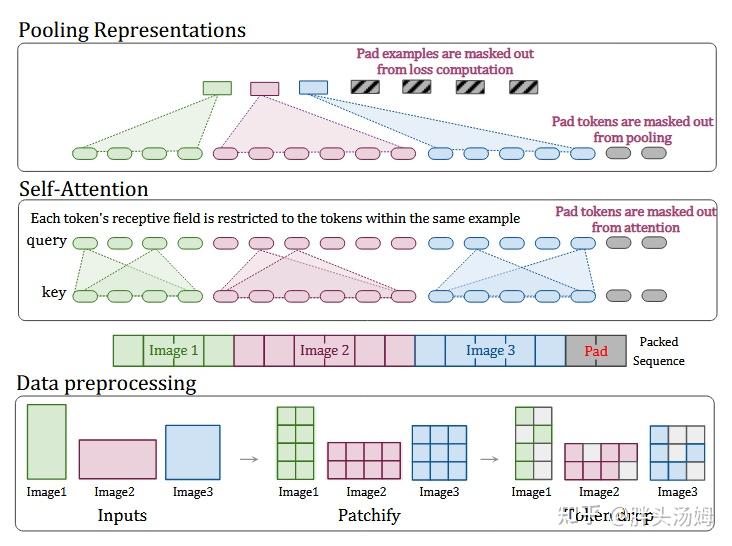
工作流程:
- 原生分块:对每张图像保持原始分辨率,按固定 patch 大小(如 16x16)切分,得到数量不等的 patch 序列(如宽屏图可能有 32x12 个 patch,竖屏图有 12x32 个 patch);
- 序列打包:将多张图像的 patch 序列拼接成一个长序列(用特殊标记分隔不同图像);
- 批量训练:将多个 “打包后的长序列” 作为 batch 输入,充分利用硬件并行计算。
优势:
- 无需缩放 / 填充,保留图像原生结构;
- 硬件利用率从传统的~50% 提升至~90%+(避免 padding 浪费)。
|
|
训练策略
在模型架构适配后,利用支持可变分辨率的特性,NaViT 又提出了两个训练策略,进一步提高模型的训练效率和在可变分辨率上的最终性能。
1 continuous token dropping
token dropping,即训练时随机丢弃一些输入图块,可以用来加速训练。但之前的方法都需要对所有样本丢弃相同的比例,NaViT 采用 sequence packing 之后我们可以进行 continuous token dropping,对不同的样本的丢弃比例可以不同。这样就可以在使用 token dropping 来提高训练效率的同时,让一些样本保持是完整的图片,从而减小训练-推理时的差异。
2 分辨率采样
在传统的ViT中,我们需要在训练/推理效率和模型性能之间进行权衡,要么采用高分辨率图像,最终性能更强但是训练和推理开销更大,要么采用低分辨率图像,开销降低但是性能稍差。一般我们会分阶段训练,先在较小的分辨率下预训练,然后在更高的分辨率下微调。
NaViT 更加灵活,我们可以随时通过从图像大小分布中采样来进行混合分辨率训练,同时保留每张图像的原始长宽比。这使得 NaViT 整体吞吐更高,且也能见到高分辨率图像,整体在训练推理耗时和模型性能上相比原始 ViT 有较大的提高。并且模型可以适应大范围内的可变分辨率图像。
效率分析
self attention 开销
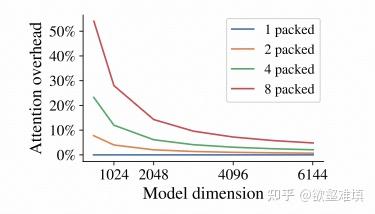
我们将多张图片 packing 到一个序列中,会导致序列长度大幅增加。这样一个最直接的担心就是 self attention 中的复杂度。但是作者指出,随着隐层维度的增加,NaViT packing 带来的额外开销是不断减小的。下图展示了这种趋势。除了速度外,长序列另一个需要担心的是空间复杂度,作者说有 Flash Attention 这也不成问题。
Packing, and sequence-level padding
我们需要保证 packing 了多张图片的最终序列在 batch 内的长度是相同的,作者采用了一种贪心的策略来进行 packing,不过一般没办法完美地 packing 到固定的序列长度,因此或多或少还是得 padding 一点 token。如果想进一步做得更细致一点,可以设计方案动态地选择分辨率和 token dropping 的个数,来实现完美 sequence packing,不过作者说目前的实现 padding token 只占 2%,已经是一个简单且不错的方案了。
Padding examples and the contrastive loss.
做了 sequence packing 之后,计算 token-level 的损失是很直接的,但是计算 example-level 的损失比较麻烦,而很多视觉任务都是基于 example-level 的损失。首先,我们要进行上面提到的 masked pooling,来对可变长度的 token 序列进行 pooling。每个 sequence 中的 example 个数不同,如果我们要固定 batch size,需要设置一个 $E_{max}$ ,每个序列中的样本超过该值则丢弃,少于该值则用 padding token 的表征。
这类似对比损失中的一个问题,对比损失计算在时间和内存上的规模约为 $O (n^2)$ 。为了避免这种情况,可以使用 chunked constrastive loss(这里引的 paper 没搜到,我估计就是局部 softmax + block online softmax 全局合并?),各个设备先在本地计算,然后累积全局 softmax 归一化所需的统计数据,这就避免了全局 softmax 需要收集所有数据。这使得我们可以设置很高的 $E_{max}$ (从而有效使用模型编码器),而损失计算不会成为瓶颈。
参考
-
No backlinks found.