MoE
Gating – Routing tokens to experts
MoE 中比较重要的是将 tokens 路由到不同的 expert。考虑一个 token,是一个 d 维的 vector,通过
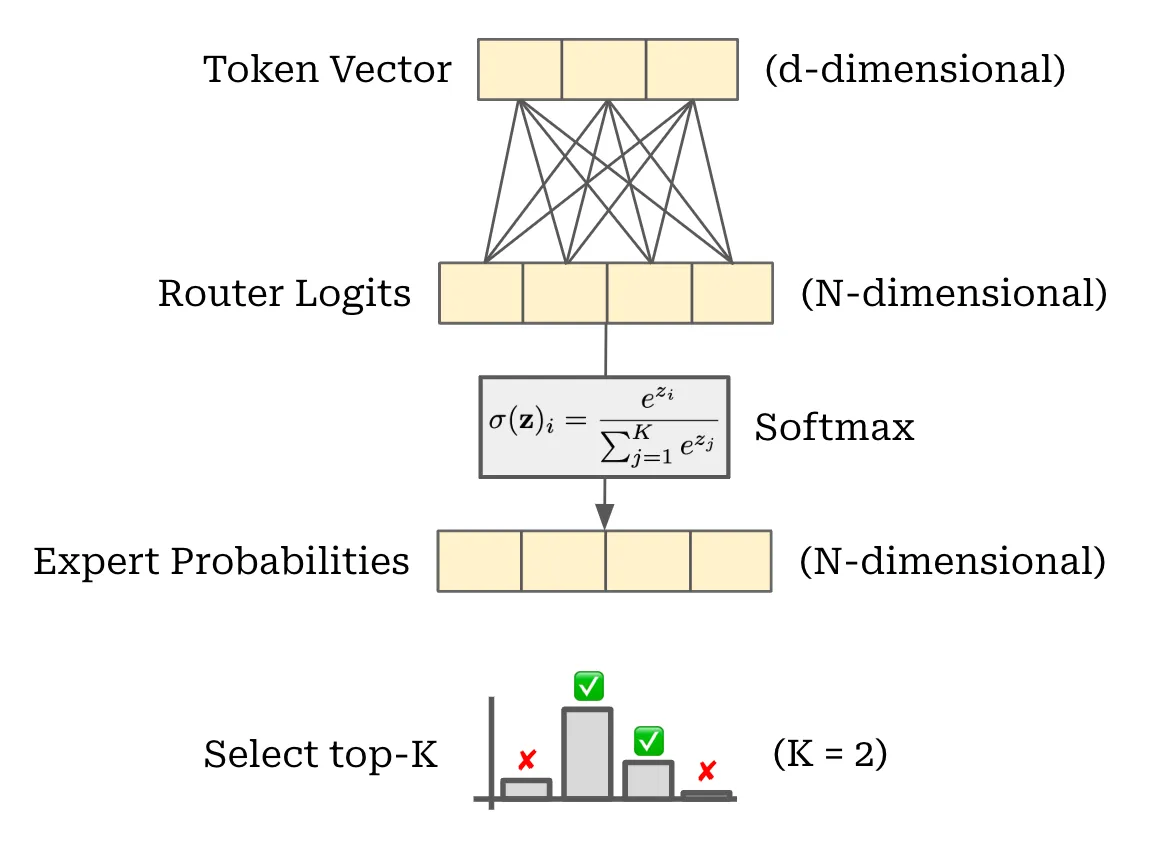
代码实现如下,经过 Attention 当前的 tensor shape 为 (B, C, d),其中 router 为 linear 层 (d, n_exp) ,输出为 (B, C, n_exp),表示对于每个 token,路由到不同 expert 的权重,也就是上图的 Router Logits。
接下来经过 Softmax,
|
|
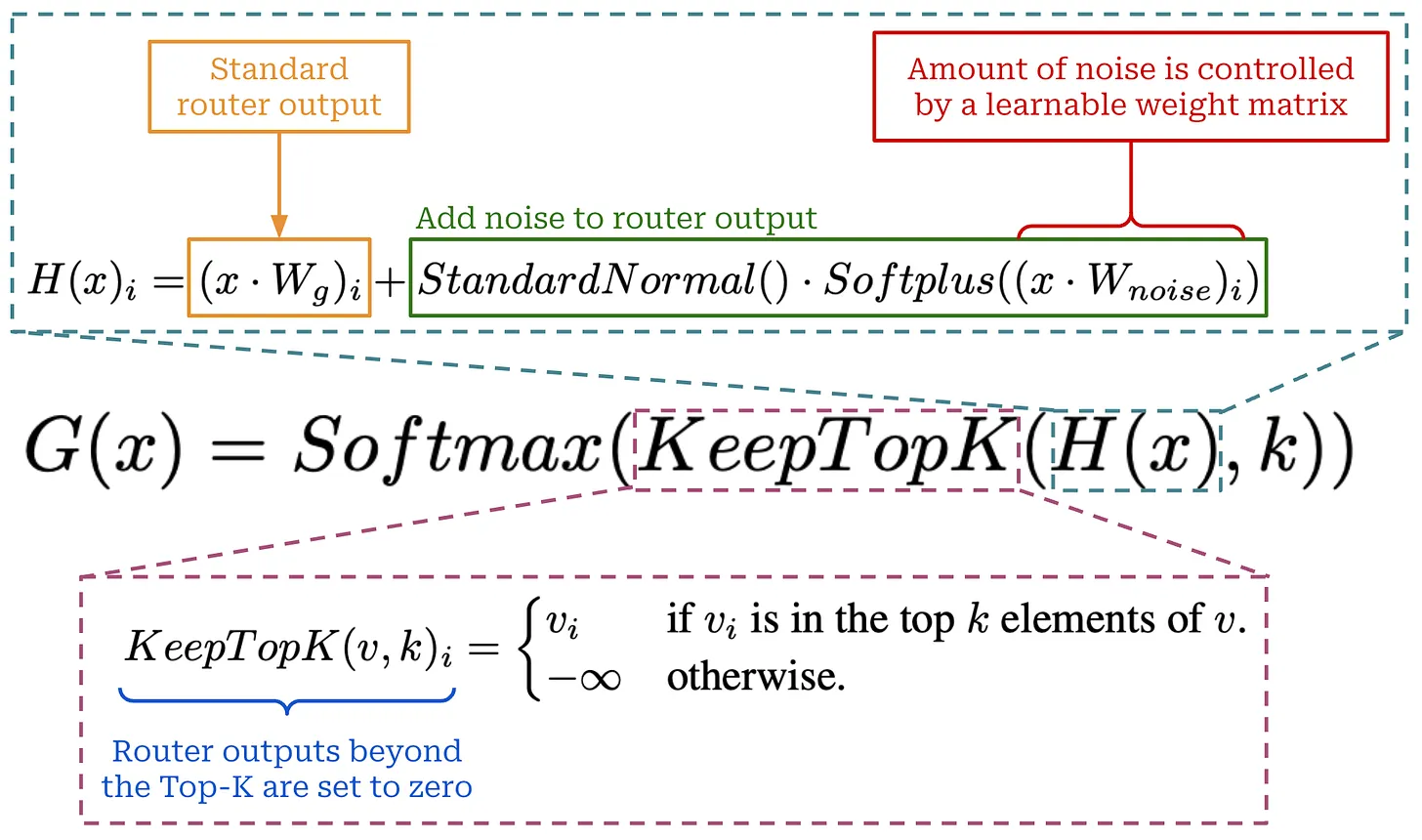
Megatron-LM
|
|
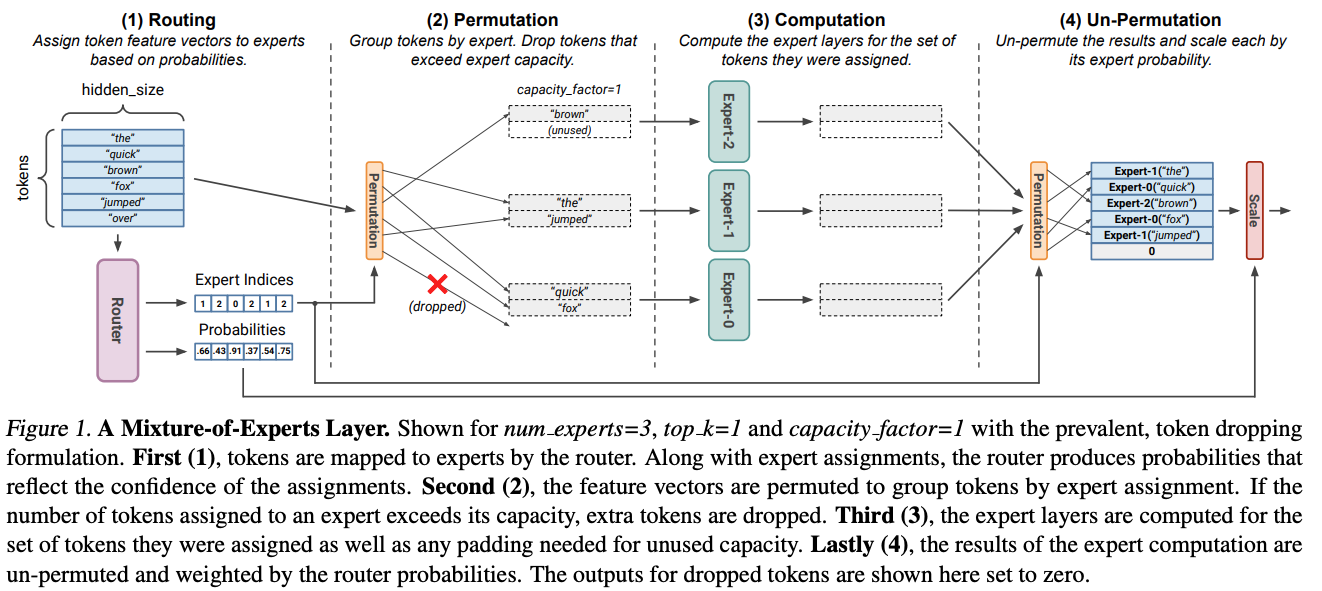
Routing
|
|
Dispatch
|
|
Expert Compute
|
|
Combine
|
|
Expert Parallelism
- Gating function: decide target experts for each token
- Dispatch Phase
- Layout transformation: tokens to the same target experts are grouped in a continuous memory buffer
- Alltoall: dispatch tokens to their corresponding experts
- Expert Compute: each expert process its tokens
- Combine Phase
- Combine processed tokens batch to their GPUs
- Layout transform: restore tokens to their original positions
|
|

-
Deepspeed MoE
Transformers 代码阅读
参考资料
Linked Mentions
-
No backlinks found.