BF16/FP16 混合精度训练
为什么要 混合精度训练?
-
传统深度学习一般默认使用单精度 (FP32)训练,但模型规模一大,FP32 的内存和计算成本大
-
只使用 FP16 会有精度损失的问题,所以需要 混合精度训练:本文主要介绍半精度(FP16)和单精度(FP32)混合的情况
-
混合精度训练的三大技术
- 维护 FP32 主副本的权重:前向、反向传播时,使用 FP16,而只在更新权重 的时候,累加到 FP32 的权重副本
- 损失缩放:如果梯度太小,FP16 可能下溢,简单的应对方法是让梯度先放大一个倍数,保证计算过程中不溢出,更新权重时再缩放回来
- 算术精度累积:在进行向量点积、求和等操作时,部分计算结果需要在更高的精度下累积,以避免 FP 16 的精度限制导致数值误差。
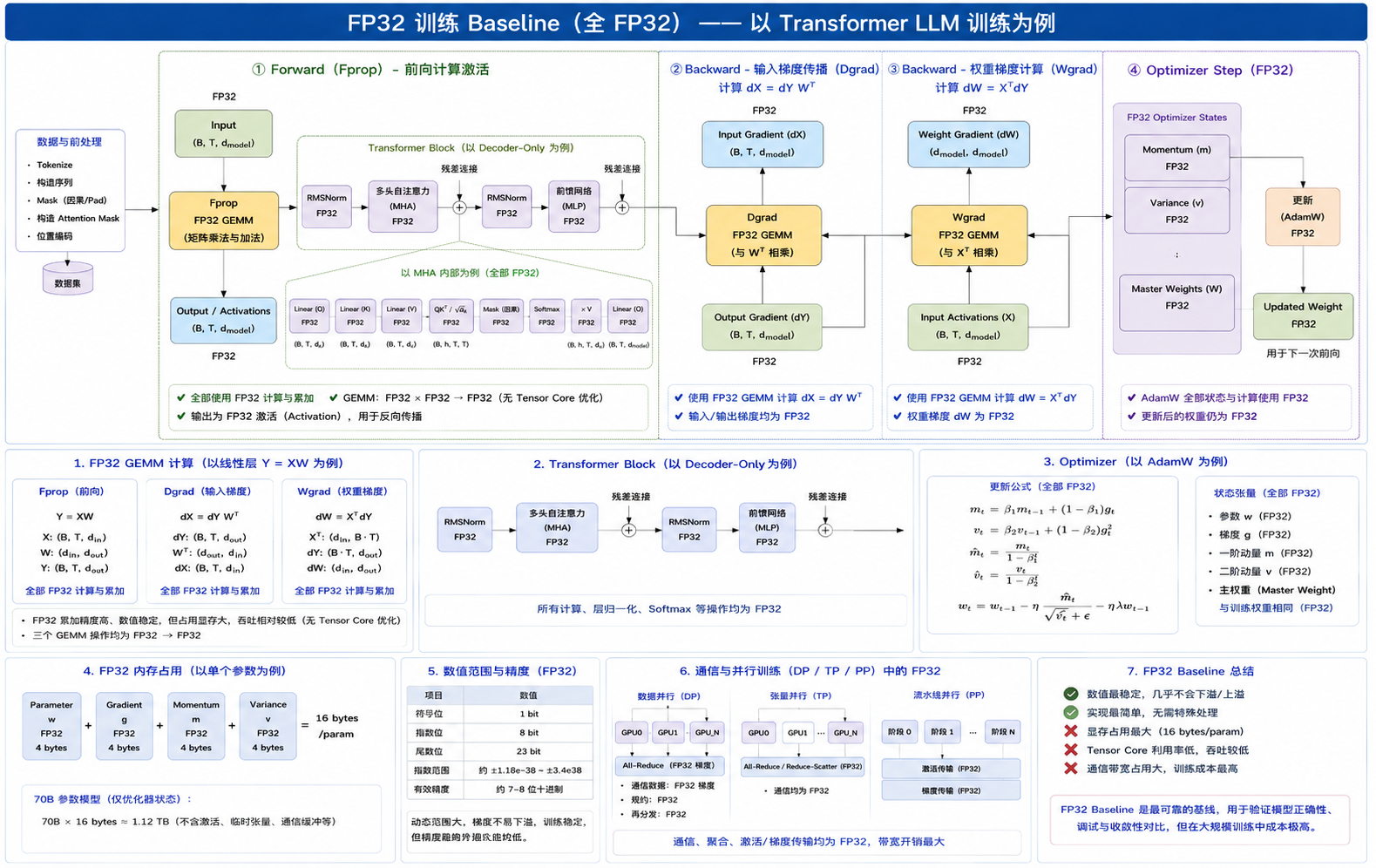
纯 FP32 训练 baseline
在 LLM 训练里,如果完全不用混合精度,最直接的 baseline 就是:
- 参数是 FP32
- 激活值是 FP32
- 反向传播中的梯度是 FP32
- 优化器状态也是 FP32
如果把一个线性层写成矩阵乘 $Y = XW$ ,那么一个训练 step 里最核心的计算通常可以拆成 3 部分:
1. Fprop(Forward Propagation)
也就是前向传播。给定输入激活 X 和权重 W,计算输出激活 Y:
|
|
在 Transformer / LLM 里,下面这些大头计算本质上都属于 Fprop:
Q = X @ WqK = X @ WkV = X @ WvAttnOut = P @ VMLP_up = X @ W1MLP_down = H @ W2
这一阶段会产生大量中间激活,供后续反向传播使用。
2. Dgrad(Data Gradient)
反向传播时,先从上一层传回来输出梯度 dY。要继续往前一层传,就要计算输入梯度 dX:
|
|
这部分叫 Dgrad,可以理解成“对输入激活的梯度”。它的作用是把误差信号继续往网络前面传。
3. Wgrad(Weight Gradient)
同样拿到 dY 之后,还要计算当前层权重的梯度 dW:
|
|
这部分叫 Wgrad,也就是“对权重的梯度”。优化器后面更新参数,依赖的就是它。
所以,从算子视角看,一个 LLM layer 的训练主干其实就是:
Fprop:Y = X @ WDgrad:dX = dY @ W.TWgrad:dW = X.T @ dYOptimizer step: 用dW去更新参数和优化器状态
如果写成更贴近训练过程的伪代码,大概是这样:
|
|
这个 baseline 的优点是数值稳定、行为简单、最容易对齐理论公式。在模型刚开始验证正确性时,很多团队还是会先跑纯 FP32,确认:
- loss 曲线正常
- 梯度没有异常
- Fprop / Dgrad / Wgrad 的实现都正确
但它也有一个非常现实的问题:太贵。当模型从几亿参数走向几十亿甚至上百亿参数时,FP32 的训练成本会迅速变得不可接受。
为什么 FP32 太慢/太贵
FP32 的“贵”,在 LLM 训练里最好不要只理解成“显存更大一点”,而要理解成:
- Fprop 贵
- Dgrad 贵
- Wgrad 贵
- 保存它们需要的激活、梯度、优化器状态也贵
也就是说,一个 step 里最贵的几段矩阵乘,全都在用 32 bit 做。
1. 显存占用高
FP32 每个数占 4 Byte。对 LLM 来说,显存消耗不只是“参数本身”,还包括:
- 参数(weights)
- Fprop 需要保留的激活(activations)
- Dgrad / Wgrad 产生的梯度(gradients)
- 优化器状态(例如 Adam 的
m和v)
其中最容易被忽略的一点是:Wgrad 依赖前向时保存下来的输入激活 X。这意味着:
- Fprop 不能只是“算完就丢”
- 为了反向做 Dgrad/Wgrad,很多中间结果必须缓存
- sequence length、micro-batch、hidden size 一大,激活显存就会非常夸张
再加上 AdamW 这类优化器,单个参数往往至少对应:
- 1 份参数
- 1 份梯度
- 2 份优化器状态
也就是说,仅参数相关状态就可能接近 4 份 FP32 张量,还没算激活、临时 buffer、通信 buffer。模型一大,显存马上爆掉。
2. Tensor Core 利用率低
NVIDIA Tensor Core:
- FP16/BF16/FP8 吞吐极高
- FP32 throughput 很低
例如 Hopper H 100:
| 精度 | Tensor Core TFLOPS |
|---|---|
| FP32 | ~60 |
| BF16 | ~1000 |
| FP8 | ~2000 |
差距巨大。
3. Memory Bandwidth 成瓶颈
FP32:每个元素 4 bytes。
大模型训练:
真正瓶颈往往不是 FLOPS,
而是:
- HBM 带宽
- NVLink 带宽
- All-reduce 带宽
降低精度可以直接减轻 IO
一张图总结
FP16/BF16 混合精度训练
FP 16 混合精度训练是最早成熟的混合精度方案,其核心思想是:
能用 FP 16 的地方尽量用 FP 16 提速和省显存;真正对数值稳定性敏感的地方保留 FP 32。
1. 朴素 FP 16 训练的问题
如果简单地将所有计算都转换为 FP16,会遇到两个致命问题:
- 梯度下溢:大部分梯度值会小于 FP16 的最小正数值,变为 0,导致模型无法收敛
- 权重更新失效:权重更新量(学习率 × 梯度)通常很小,在 FP16 下无法精确表示
2. 完整 FP16 混合精度训练流程 (经典 AMP)
NVIDIA 在 2017 年提出的混合精度训练方案1 通过三个核心技术解决了上述问题:
- 模型前向多数算子用 FP 16
- 线性层、卷积、attention 中的大矩阵乘,优先走 FP 16 Tensor Core
- 激活值通常也以 FP 16 保存,减少显存
- 反向传播多数梯度计算仍在 FP 16 路径上进行
- 梯度张量本身很多时候是半精度
- 维护 FP 32 master weight
- 训练时真正用于更新的“主参数”保留一份 FP 32
- 每次更新先在 FP 32 上做,再 cast 回 FP 16 供下一轮 forward 使用
- 部分算子强制保留 FP 32
- 例如 softmax、layer norm、某些 reduction、loss 计算等
- 因为这些地方更容易出现舍入误差、上溢或下溢
- 损失缩放
Loss Scaling防止梯度下溢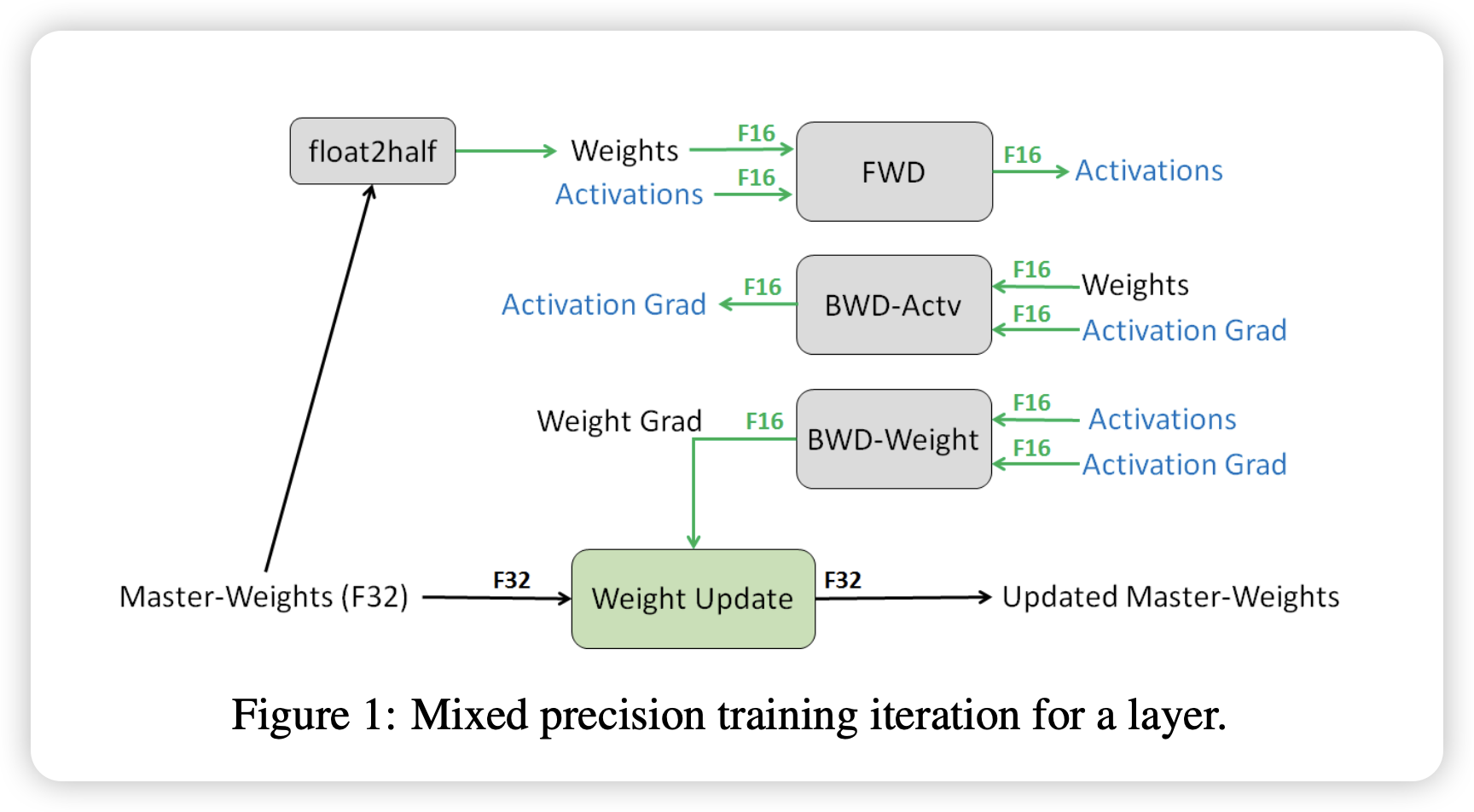
FP16 完整流程如下2:
- Maintain a primary copy of weights in FP32.
- Initialize S to a large value.
- For each iteration:
- Make an FP16 copy of the weights.
- Forward propagation (FP16 weights and activations).
- Multiply the resulting FP32 loss with the scaling factor S.
- Backward propagation (FP16 weights, activations, and their gradients).
- If there is an Inf or NaN in weight gradients: 6. Reduce S. 7. Skip the weight update and move to the next iteration.
- Multiply the weight gradient FP16 ->FP32 with 1/S.
- Complete the weight update FP32 (including gradient clipping, etc.).
- If there hasn’t been an Inf or NaN in the last N iterations, increase *S
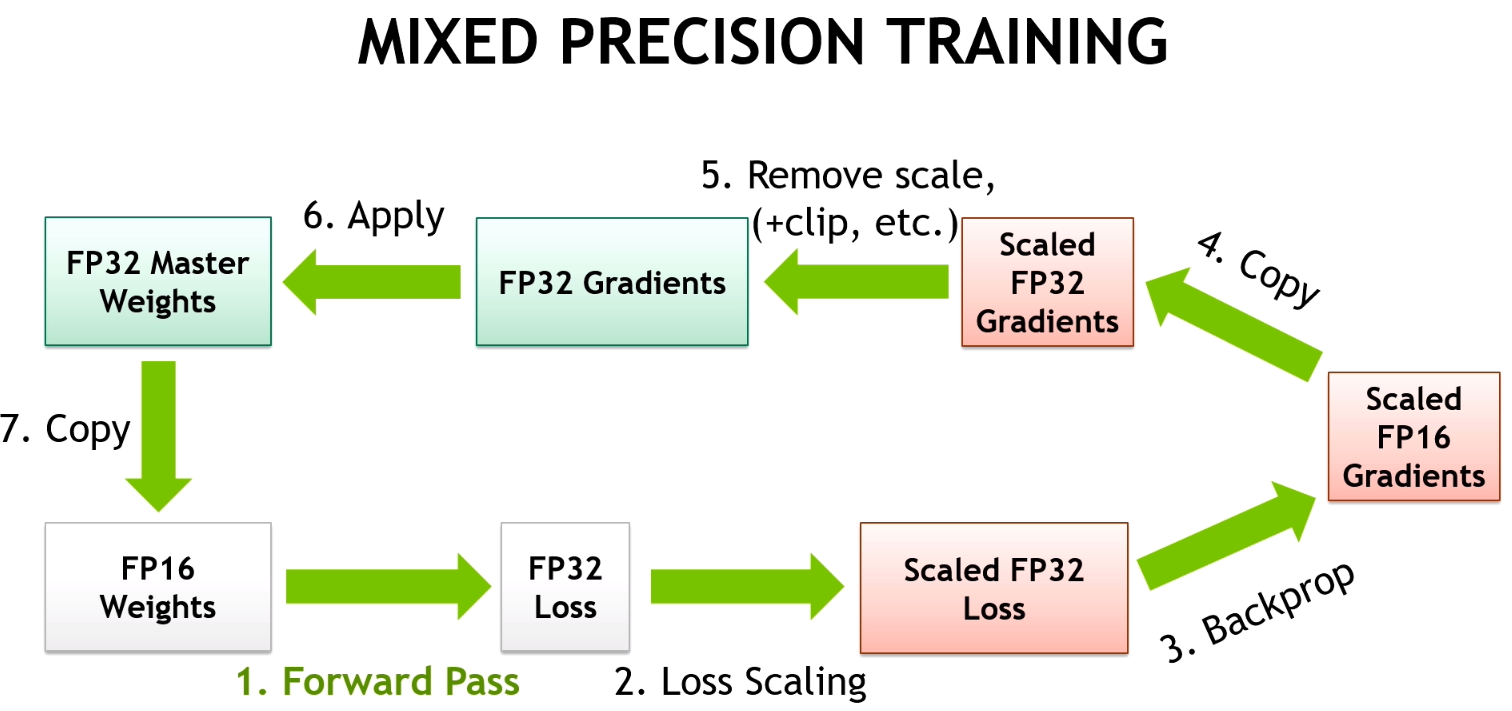
经典 AMP(Automatic Mixed Precision)的收益非常直接:
- 大量 GEMM/Conv 使用 Tensor Core,吞吐显著提升
- 参数和激活改成半精度后,显存占用下降
- 保留 FP32 的关键路径后,训练仍能收敛
但 FP16 并不是“免费午餐”。它虽然省显存、算得快,却有很明显的数值缺陷,最典型的就是动态范围太小,这会直接引出下面的 loss scaling。
3. FP16 下的 Dynamic Loss Scaling
FP16 的最大问题不是只有“小数不够精确”,而是很小的梯度可能直接下溢为 0。
深度网络反向传播时,很多梯度本来就很小。如果它们在 FP16 中落到可表示范围之外,就会变成 0,结果是:
- 一部分参数得不到更新
- 梯度统计失真
- 训练可能不稳定,甚至完全不收敛
loss scaling 的思路非常简单:既然梯度太小,那就先把它们整体放大。
基本过程
- forward 之后得到原始
loss - 将
loss乘上一个缩放因子scale - 对放大后的 loss 做 backward
- 得到的梯度会同步被放大
- 在 optimizer step 前,再把梯度除以同样的
scale
伪代码如下:
|
|
为什么需要“动态” loss scaling
如果 scale 设得太小,还是会下溢;但如果设得太大,又可能上溢成 inf 或 nan。因此经典 AMP 通常不是用固定值,而是使用 dynamic loss scaling:
- 一段时间没有溢出,就把
scale提高 - 一旦发现梯度出现
inf/nan,就跳过这次更新并降低scale
|
|
这套机制让 FP16 训练在工程上变得可用,但也带来了额外复杂度:
- 需要做 overflow 检测
- 需要跳过异常 step
- 训练流程更复杂,调试也更麻烦 而 BF16 的崛起,恰恰就是因为它在很大程度上绕开了这个问题。
|
|
autocast 做的事情不是“全都转成半精度”,而是3:
- 给适合低精度的算子分配 BF16/FP16
- 给敏感算子保留 FP32
- 自动处理算子输入输出的 dtype 协调
4. 当前主流:BF16 + FP32 Master Weight + FP32 Optimizer State
BF16(bfloat16)也是 16 bit,但它和 FP16 的位分配不一样:
- FP16:指数位少、尾数位相对多
- BF16:指数位和 FP32 一样多,尾数位更少
这意味着 BF16 的关键优势是:
- 动态范围接近 FP32
- 对非常大或非常小的数更不容易溢出/下溢
- 在深度学习训练里,通常比 FP16 更稳定
可以把两者简单理解为:
- FP16:精度稍细,但“量程短”
- BF16:精度粗一点,但“量程长”
训练里更怕什么?通常更怕梯度、激活、logits 在中间过程直接炸掉或归零,所以 BF16 往往比 FP16 更实用。
于是工业界逐渐形成了非常一致的结论:
- 如果硬件支持 BF16,优先用 BF16,而不是 FP16
- BF16 训练通常不需要 loss scaling
- 对大模型、长序列、复杂 attention 结构,BF16 往往更稳
当然,BF16 也不是完美的。它的尾数位比 FP32 少很多,所以:
- 仍然不适合把所有状态都一股脑降到 BF16
- 某些需要高精度累积和更新的地方,还是应该保留 FP32
这就形成了现代混合精度训练的主流范式:BF16 负责大部分算子计算,FP32 负责关键累积与更新。
|
|
如果用的是 BF16,一般可以不启用 GradScaler;如果是 FP16,则常配合 GradScaler 处理 loss scaling。
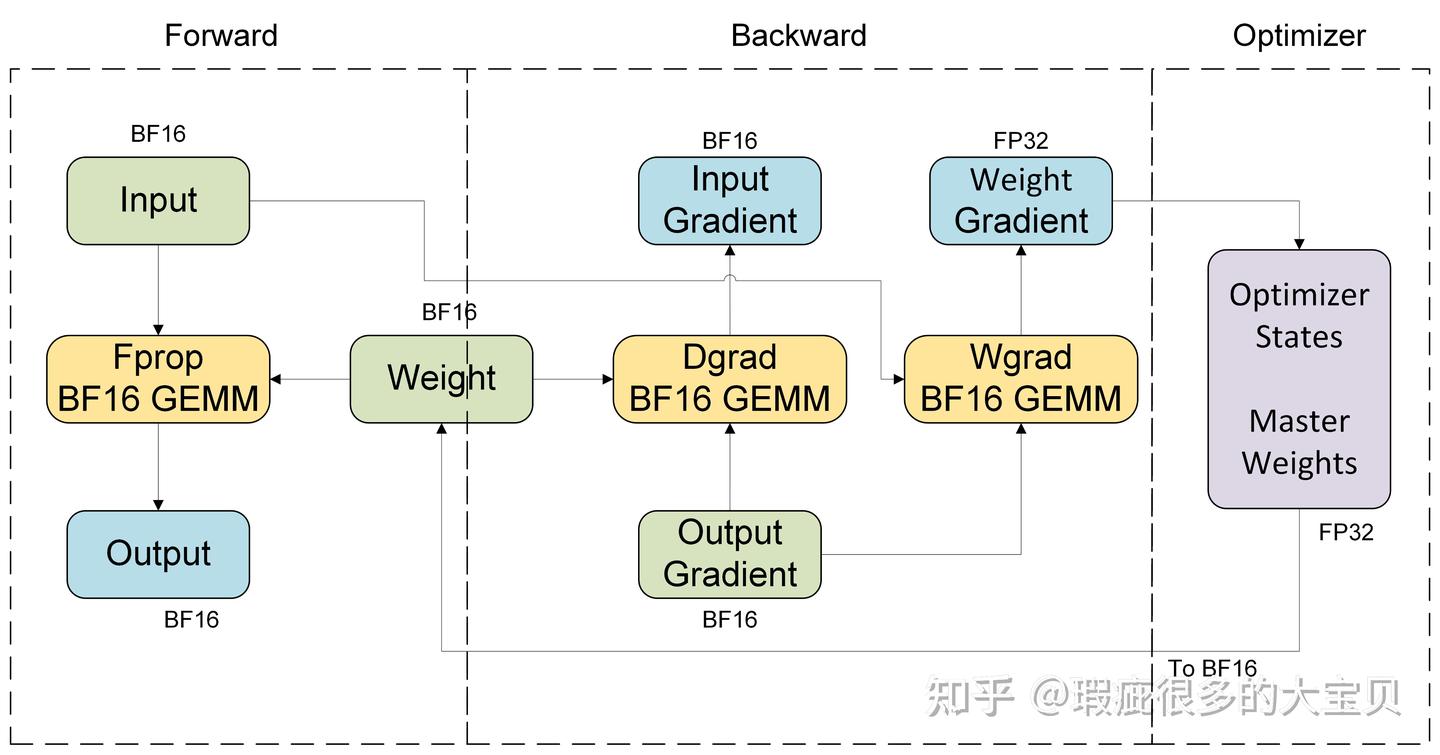
把前面的内容合起来,当前业界最常见、也最稳妥的范式可以概括为:
计算侧
- Forward 使用 BF16
- Backward 的大部分张量计算也使用 BF16
- GEMM/Attention 等核心算子在 Tensor Core 上完成
- 关键 reduction 和 accumulate 使用 FP32
状态侧
- 参数存在 BF16 计算副本
- 更新时使用 FP32 master weight,或者等价的 FP32 update buffer
- Adam/AdamW 的
m、v等优化器状态维持 FP32 - 某些框架还会保留 FP32 gradient accumulation buffer
一个典型 step 会发生什么
- 读取 BF16 权重做 forward
- 生成 BF16 激活并完成 backward
- 对梯度做必要的 all-reduce / reduce-scatter
- 在 FP32 语义下执行优化器更新
- 将更新后的结果转换回 BF16,作为下一轮 forward 的参数
这个设计之所以成为主流,是因为它在三件事之间取得了平衡:
- 性能:主算子走低精度 Tensor Core
- 显存:大部分激活和计算副本是 16 bit
- 稳定性:参数更新和优化器状态保留 FP32
需要补充的是,不同框架对 “FP 32 master weight” 的实现方式并不完全一样:
- 有的显式维护一份独立 FP 32 参数副本
- 有的在优化器内部保存 FP32 更新视图
- 在 ZeRO/FSDP 中,这份 FP32 状态还可能是分片存储的
但无论实现细节如何,背后的原则基本一致:更新时不要只依赖低精度状态。
5. 一张图总结


现代框架(PyTorch / Megatron / DeepSpeed)的典型实现
FSDP:BF16 混合精度是怎么落地的
结合 PyTorch 新版 FSDP(torch.distributed.fsdp._fully_shard,也常被叫作 FSDP2)代码来看,FSDP 的 mixed precision 不是像 autocast 那样按 op 粒度决定 dtype,而是按 module 边界管理参数的 all-gather、forward/backward 计算、梯度 reduce-scatter。
入口配置就是 MixedPrecisionPolicy:
|
|
如果我们想做典型的 BF16 训练,常见模型就是:
|
|
param_dtype=torch.bfloat16:unshard 后给 forward/backward 用的参数是 BF16reduce_dtype=None:梯度规约默认跟计算梯度 dtype 走,也就是通常还是 BF16reduce_dtype=torch.float32:如果更在意数值稳定,也可以强制梯度规约走 FP32output_dtype:需要和别的 mixed precision policy 串接时,再把 forward 输出转成指定 dtype
FSDP 的一个关键点是:它并不会把底层 sharded parameter 永久改成 BF16。 FSDPParam.init_dtype_attrs() 里会把:
orig_dtype = self.sharded_param.dtypeparam_dtype = mp_policy.param_dtypereduce_dtype = mp_policy.reduce_dtype
分开保存。也就是说,假设模型初始化时参数本来是 FP32,那么:
- 常驻内存里的 sharded parameter 仍然是 FP32
- 只有在 forward/backward 前 all-gather 成 unsharded parameter 时,才按
param_dtype变成 BF16 供计算使用
这就是 _fsdp_api.py 注释里那句 “optimizer step uses the sharded parameter in the original dtype” 的真实含义:FSDP 不需要再额外维护一整份完整的 FP32 master weight,因为它本来就保留着分片后的原始精度参数。
把一个训练 step 展开,代码路径大致是这样的:
-
forward 前把输入转成 BF16
FSDPState._pre_forward()会在cast_forward_inputs=True且param_dtype非空时,把 floating-point inputs cast 到param_dtype
-
all-gather 时按
param_dtype准备参数FSDPParam.all_gather_inputs会把本 rank 的 sharded parameter 转成self.param_dtypeforeach_all_gather()再把这些 BF16 shard all-gather 成完整参数FSDPParam.init_unsharded_param()用 all-gather 结果恢复出 unsharded parameter,dtype 是self.param_dtype or self.orig_dtype
-
forward/backward 主计算使用 BF16 参数
- 因为 module 上注册的参数已经被切换成 unsharded BF16 parameter,所以线性层、attention、MLP 这些主干算子会自然跑在 BF16 路径上
- 这就是
_fsdp_api.py文档里说的 “module-level mixed precision”:cast 主要发生在 module 边界,而不是每个算子内部反复 cast
-
backward 结束后,梯度按
reduce_dtype做 reduce-scatterFSDPParamGroup.post_backward()会收集 unsharded gradforeach_reduce()里reduce_dtype = reduce_dtype or grad_dtype- 如果
reduce_dtype is None,那就直接用当前梯度 dtype 规约;在 BF16 compute 场景下,通常就是 BF16 reduce-scatter - 如果显式设成
torch.float32,就会先把梯度 buffer 建成 FP32,再走 FP32 规约
-
规约后再转回原始参数 dtype,供 optimizer step 使用
foreach_reduce()在规约结束后会执行reduce_output = _to_dtype_if_needed(reduce_output, orig_dtype)- 随后把结果写回
fsdp_param.sharded_param.grad - 这意味着如果原始分片参数是 FP32,那么优化器看到的 sharded grad 也是 FP32,参数更新就在 FP32 语义下完成
所以,FSDP 中 BF16 mixed precision 的本质可以总结成一句话:
常驻的分片参数保留原始精度(通常 FP32),临时 all-gather 出来的计算参数用 BF16,梯度通信可以用 BF16 或 FP32,最后再把梯度恢复到原始参数精度去做 optimizer step。
这和经典 AMP + full master weight 很像,但又不完全一样:
- 经典 AMP:常见做法是保留一份完整 FP32 master weight,再派生出 FP16/BF16 计算副本
- FSDP:保留的是分片后的原始精度参数,计算时临时 all-gather/cast,所以不用多存一份完整 FP32 副本
从这个实现也能看出,FSDP 在回答的其实是三个更具体的问题:
- 计算参数用什么 dtype? 由
param_dtype控制,典型是 BF16 - 通信时梯度用什么 dtype? 由
reduce_dtype控制,默认跟 compute dtype,也可单独升到 FP32 - 优化器更新用什么 dtype? 用
orig_dtype,通常仍是 FP32
Tensor Core 上的真实计算路径
从硬件角度看,现代 GPU 上的混合精度训练并不是“整个训练都在 BF16”或“整个训练都在 FP16”,而是一个输入精度、乘法精度、累加精度、输出精度分层处理的过程。
最常见的路径是:
- 输入张量是 BF16/FP16
- Tensor Core 执行低精度矩阵乘
- 累加(accumulate)在更高精度里完成,通常是 FP32
- 输出再根据算子策略写回 BF16 或 FP32
现在我们把 Tensor Core 和你之前学的混合精度训练结合起来,看一个完整的线性层前向传播过程:
|
|
|
|
对矩阵乘来说,这一点尤其关键。因为训练里真正占大头的是:
LinearAttention QK^TAttention Prob @ VMLP中的大 GEMM
这些操作通常都在 Tensor Core 上跑,而 Tensor Core 的高吞吐正是混合精度训练性能提升的来源。
到了 Hopper 一代,这种趋势更明显:
- 对 BF16/FP16 的硬件支持更强
- 对 FP8 也开始提供专门路径
- fused attention、fused MLP、Transformer Engine 等会更积极地管理 dtype
因此,“混合精度训练”在真实 GPU 上的含义,并不是简单地把模型 .half(),而是:
把大吞吐矩阵乘放到低精度 Tensor Core,把数值敏感的累加和更新保留在更高精度。
更进一步:FP8 / MXFP8 的方向
当 BF16 已经成为主流后,行业还在继续往更低精度推进,代表方向就是 FP8。
推动 FP8 的核心动力还是老问题:
- 进一步提升 Tensor Core 吞吐
- 进一步降低显存与带宽压力
- 让更大的模型、batch、sequence 能塞进同样的硬件
不过 FP8 比 BF16/FP16 更激进,因此它通常不会像 BF16 那样“直接默认开启”。常见做法是:
- 只让一部分张量使用 FP8
- 给不同张量维护独立的 scaling factor
- 依赖专门的 runtime 或 Transformer Engine 管理量化/反量化
- 继续保留更高精度的累积、权重更新和优化器状态
所以 FP8 更像是在 BF16 混合精度之上的下一层精细化工程:
- BF16 解决的是“主流训练低精度化”
- FP8 解决的是“进一步逼近硬件吞吐上限”
对大多数团队来说,今天最值得掌握的仍然是这条主线:
- 先理解纯 FP32 baseline
- 再理解经典 FP16 AMP 与 loss scaling
- 最后掌握 BF16 compute + FP32 accumulate/update 这一现代主流范式
掌握这条主线之后,再去看 FP8、MXFP8、Transformer Engine、块级 scaling 等新技术,就会顺畅很多。
-
MIXED PRECISION TRAINING, https://arxiv.org/pdf/1710.03740 ↩︎
-
Train with mixed precision, NVIDIA, https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html ↩︎
-
https://docs.pytorch.org/tutorials/recipes/recipes/amp_recipe.html ↩︎
-
No backlinks found.