KL 散度估计
信息论基础
分类模型的损失函数常用交叉熵 CrossEntropyLoss,而 KL 散度又称为相对熵,它们之间的关系是怎样的呢?下面从香农的信息论出发进行理解:
信息量:一个事件发生时携带信息的多少或消除不确定性的程度
-
直观理解:越不可能发生的事件,发生时携带的信息量越大。例如,“太阳从东方升起” 是必然事件,信息量为 0;“彩票中头奖” 是小概率事件,信息量极大。
-
核心逻辑:事件发生的概率越大,确定性越高,带来的新信息越少,信息量越小;反之,概率越小,信息量越大。
-
数学定义(自信息):对于概率为 $P(x)$ 的事件 $x$,其自信息定义为:$$I(x) = -\log P(x)$$
-
公式说明:
- 当 $P(x)$ 越小时,$I(x) = -\log P(x)$ 越大(小概率事件信息量高);
- 当 $P(x) = 1$(必然事件),$I(x) = -\log 1 = 0$(无信息量);
- 当 $P(x) \to 0$(几乎不可能事件),$I(x) \to +\infty$(信息量极大)。
-
log 底数说明:
- 底数为 2 时,单位为 比特(bit)
- 底数为 e 时,单位为 奈特(nat)
- 底数为 10 时,单位为 哈特(hart)
-
log 选择原因:
- 保证信息量为正数,且是概率的单调递减函数;
- 概率为 0 时信息量无穷大,概率为 1 时信息量为 0;
- 多个独立事件联合发生的信息量 = 各单独事件信息量之和。
信息熵:香农熵 Entropy
香农熵是整个概率分布的平均自信息,衡量了分布的 “不确定性” 或 “平均信息量”。
- 离散分布:对于离散分布 P,香农熵定义为:
$$ H(P) = \mathbb{E}_P[I(x)] = \sum_x P(x) \cdot I(x) = -\sum_x P(x) \log P(x) $$
- 连续分布:对于连续分布 $P(x)$(概率密度函数),香农熵为: $$ H(P) = -\int P(x) \log P(x) dx $$
- 编码角度解释:香农熵是
描述一个分布所需的最小平均编码长度。例如,熵为 3 比特意味着理论上可用平均 3 比特的编码表示该分布的所有事件(最优编码,无冗余)。
交叉熵 CrossEntropy
假设随机变量 $x$ 的真实分布为 $P$,用近似分布 $Q$ 编码 $P$ 的事件时,所需的平均编码长度即为交叉熵。
一般来说,在机器学习中,$P$ 代表训练数据的真实分布,我们用神经网络模型预测的 $Q$ 分布来模拟 $P$ 分布。
数学表达为:真实分布 P 的情况下,用预测分布 Q 编码数据时,所需的平均信息量
- 数学定义: $$ H(P, Q) = \mathbb{E}P[-\log Q(x)] = \sum{x} P(x) \cdot (-\log Q(x)) = -\sum_{x} P(x) \log Q(x) $$
- 连续分布:求和改为积分,形式类似。
- 核心性质:
- 与香农熵的关系:$H(P, Q) \geq H(P)$,当且仅当 $Q = P$ 时等号成立;
- 编码效率损失:Q 与 P 差异越大,$H(P, Q)$ 越大(编码越冗余);Q 与 P 越接近,$H(P, Q)$ 越接近 $H(P)$(冗余越小)。
在机器学习中
KL 散度:相对熵 RelativeEntropy
KL 散度本质是 “用 Q 近似 P 时多付出的冗余信息量”,即交叉熵与香农熵的差值。
-
数学定义: $$ D_{\text{KL}}(P \parallel Q) = \mathbb{E}P \left[ \log \frac{P(x)}{Q(x)} \right] = \sum{x} P(x) \log \frac{P(x)}{Q(x)} $$
-
连续分布: $$ D_{\text{KL}}(P \parallel Q) = \int P(x) \log \frac{P(x)}{Q(x)} dx $$
-
与交叉熵、香农熵的关系: $$ \begin{split} D_{\text{KL}}(P \parallel Q) &= \sum_{x} P(x) \log P(x) - \sum_{x} P(x) \log Q(x) \ &= \left( -\sum_{x} P(x) \log Q(x) \right) - \left( -\sum_{x} P(x) \log P(x) \right) \ &= H(P, Q) - H(P) \end{split} $$
-
核心逻辑:$$\text{KL 散度} = \text{交叉熵(用 Q 编码 P 的代价)} - \text{香农熵(用 P 编码 P 的最优代价)}$$
KL 散度的性质
非负性
$D_{\text{KL}}(P \parallel Q) \geq 0$,当且仅当 $P = Q$(几乎处处)时等号成立;
Jenson 不等式证明
凸函数是一个定义在某个向量空间的凸子集 $C$(区间)上的实值函数 $f$ ,如果在其定义域 ( C ) 上的任意两点 $x_1, x_2$,$0 \leq t \leq 1$,有 $$ tf(x_1) + (1 - t)f(x_2) \geq f(tx_1 + (1 - t)x_2)$$也就是说凸函数任意两点的割线位于函数图形上方,这也是 Jensen 不等式的两点形式。
Jensen 不等式:若对于任意点集 ${x_i}$,若 $\lambda_i \geq 0$ 且 $\sum_i \lambda_i = 1$,使用数学归纳法,可以证明凸函数 $f(x)$ 满足: $$ f\left(\sum_{i=1}^M \lambda_i x_i\right) \leq \sum_{i=1}^M \lambda_i f(x_i)$$ Jensen 不等式,它是两点式的泛化形式。

选择严格凸函数 $f(t) = -\log t, (t > 0)$,证明其凸性:二阶导数 $f’’(t) = \frac{1}{t^2} > 0$,满足严格凸函数定义)。
令随机变量 $X = \frac{Q(x)}{P(x)}$(以 $P(x)$ 为权重),则随机变量 X 的期望为:
$$
\mathbb{E}P[X] = \sum{x} P(x) \cdot \frac{Q(x)}{P(x)} = \sum_{x} Q(x) = 1
$$
对 $f(X) = -\log X$ 应用 Jensen 不等式:
$$
\mathbb{E}_P\left[ -\log \frac{Q(x)}{P(x)} \right] \geq -\log \left( \mathbb{E}_P\left[ \frac{Q(x)}{P(x)} \right] \right)
$$
代入化简得非负性,将 $\mathbb{E}_P\left[ \frac{Q(x)}{P(x)} \right] = 1$ 代入右侧: $$ -\log \left( \mathbb{E}_P\left[ \frac{Q(x)}{P(x)} \right] \right) = -\log 1 = 0 $$
因此: $$ \mathbb{E}_P\left[ -\log \frac{Q(x)}{P(x)} \right] \geq 0 $$
结合 KL 散度的变形定义: $$ D_{\text{KL}}(P \parallel Q) = \mathbb{E}_P\left[ -\log \frac{Q(x)}{P(x)} \right] \geq 0 $$
等号成立条件:因 $f(t) = -\log t$ 是严格凸函数,Jensen 不等式等号成立当且仅当 $X = \mathbb{E}[X]$(几乎处处),即: $$ \frac{Q(x)}{P(x)} = 1 \implies Q(x) = P(x) \quad (\forall x) $$ 综上,KL 散度非负,且仅当两分布完全相同时取值为 0。
信息论角度证明
由于 “实际编码长度不可能小于最优编码长度”(编码的基本原理),即 $H(P, Q) \geq H(P)$,因此 $D_{\text{KL}}(P \parallel Q) \geq 0$,进一步验证了非负性。
非对称性
$D_{\text{KL}}(P \parallel Q) \neq D_{\text{KL}}(Q \parallel P)$
(衡量 “Q 近似 P” 与 “P 近似 Q” 是完全不同的)。
Forward KL
$$ D_{\text{KL}}(P \parallel Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)} $$
如果要最小化 forward kl 差距,则 $$ \begin{aligned} &\arg \min {\theta} D{K L}\left(P | Q_{\theta}\right) \ &=\arg \min {\theta} \mathbb{E}{x \sim P}\left[\log \frac{P}{Q_{\theta}}\right] \ &=\arg \min {\theta} \mathbb{E}{x \sim P}\left[-\log Q_{\theta}\right]-H(P) \ &=\arg \min {\theta} \mathbb{E}{x \sim P}\left[-\log Q_{\theta}\right] \ &=\arg \max {\theta} \mathbb{E}{x \sim P}\left[\log Q_{\theta}\right] \end{aligned} $$ 可见在此情况下和交叉熵优化是等价的,即通过进行 $Q_{\theta}$ 最大似然估计。也就是说,数据 $x$ 由 $P$ 产生,基于这些数据,选取让平均在上的似然函数最大。直观的理解则是:
$P (X)$ **平均概率高的地方,$Q (X)$ 概率也要高。但是不会惩罚 $Q (X)$ 概率大而 $P (X)$ 概率小的,因此有可能无法保证生成的样本的质量。
如果 Q 满足高斯分布,则最终 FKL 得到的是如下图所示的 mean-seeking 的结果,也称作 mode-covering
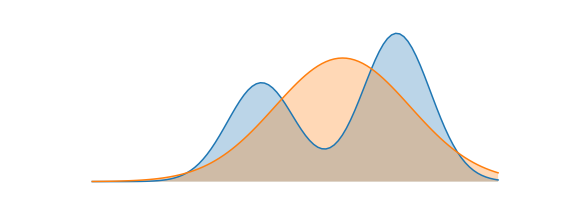
Forward KL 与 SFT
FKL 相当于 Supervised Learning
FKL 的优化过程关注于样本整体的均值,这一过程类似于监督学习的优化过程,即固定分布 $P(x)$ 中采样 sample,通过 cross-entropy loss 来拟合分布
$$ \arg \min_{\theta} \mathbb{E}{(x,y) \sim \mathcal{D}} \left[ L\left( f{\theta}(x), y \right) \right] $$
包括分类模型采用的交叉熵损失,以及回归模型的均方误差,本质都是最小化模型经验风险。
Reverse KL
$$ D_{\text{KL}}(Q \parallel P) = \sum_{x} Q(x) \log \frac{Q(x)}{P(x)} $$ 如果要最小化 reverse kl 差距,则 $$ \begin{aligned} &\arg \min {\theta} D{K L}\left(Q_{\theta} | P\right) \ &=\arg \min {\theta} \mathbb{E}{x \sim Q_{\theta}}\left[\log \frac{Q_{\theta}}{P}\right] \ &=\arg \min {\theta} \mathbb{E}{x \sim Q_{\theta}}[-\log P]-H\left[Q_{\theta}\right] \ &=\arg \max {\theta} \mathbb{E}{x \sim Q_{\theta}}[\log P]+H\left[Q_{\theta}\right] \end{aligned} $$
此时, 需要选取参数 $\theta$,让平均在 $Q_{\theta}(X)$ 上的 $logP(X)$ 似然函数最大; 同时, 让 Shannon 熵 $H\left[Q_{\theta}\right]$ 也比较大, 即约束不要过于集中, 可以理解为 $Q_{\theta}(X)$ 起到了一个正则化 (regularization) 的效果。总的来看,即:
$Q_{\theta}(X)$ 平均概率高的地方,$P(X)$ 概率也要高。倾向于去覆盖 $P(x)$ 最高的峰,同时加上熵约束,防止出现坍缩。
如果 $Q$ 满足高斯分布, 则最终 RKL 得到的是如下图所示的 mode-seeking 的结果
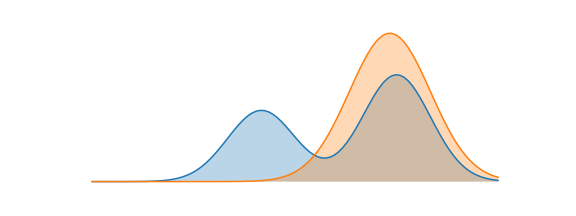
Reverse KL 与 RL
RKL相当于Maximum Entropy Reinforcement Learning
RKL 的优化过程即关注于均值,又关注于方差,这一过程类似于强化学习中对于累计回报的优化过程,即
$$ \begin{aligned} &\arg \max_{\pi} \mathbb{E}{\tau \sim Q{\pi}} \left[ \log P(\tau) \right] + \mathcal{H}\left( Q_{\pi}(\tau) \right) \ &= \arg \max_{\pi} \mathbb{E}{\tau \sim Q{\pi}} \left[ \sum_{t=1}^{T} r\left( s_t, a_t \right) \right] + \mathbb{E}{\tau \sim Q{\pi}} \left[ \sum_{t=1}^{T} -\log \pi\left( a_t \mid s_t \right) \right] \ &= \arg \max_{\pi} \mathbb{E}{\tau \sim Q{\pi}} \left[ \sum_{t=1}^{T} \left( r\left( s_t, a_t \right) - \log \pi\left( a_t \mid s_t \right) \right) \right] \end{aligned} $$
其中
Now, we can’t sample directly from the distribution of optimal trajectories $P_{opt}(\tau)$, but we know that the probability of a trajectory under optimality is exponential in the sum of rewards received on the trajectory. $$ \log P(\tau) = \sum_{t=1}^T r(s_t,a_t) $$
这也是 RL 算法(如 TRPO, PPO)中非常关注于减小方差的原因。
KL 散度近似计算
在实际场景中,精确计算 KL 散度成本极高:
- 离散分布:需对所有可能结果求和(如大模型的 256K token 词汇表);
- 连续分布:需求积分,仅简单分布(如高斯分布)有封闭解。
- Computing it exactly requires too much computation or memory.
- There’s no closed form expression.
- We can simplify code by just storing the log-prob, not the whole distribution. This is a reasonable choice if KL is just being used as a diagnostic, as is often the case in reinforcement learning.
因此我们需要一个近似方法来计算 KL1。
KL 近似估计的必要性
需遍历完整样本空间,计算成本爆炸
样本空间 $\mathcal{X}$ 的规模直接决定计算复杂度:
- 对于小维度任务(如 MNIST 分类,样本空间为 10 个类别),直接求和是可行的;
- 对于大模型 RLHF 场景(如词汇表大小为 100K 的 token 序列),样本空间是指数级规模(长度为 s 的序列空间大小为 $100K^s$),遍历所有 $x$ 是物理上不可能完成的任务。
需获取精确的概率分布 $P(x)$ 和 $Q(x)$ 与 显存爆炸
kl_div 类方法的核心假设是已知两个分布的完整概率质量 / 密度函数,但在机器学习中:
- P 和 Q 通常是由神经网络参数化的黑箱分布(如策略网络 $\pi_\theta(a|s)$、语言模型 $p_\theta(token|context)$),无法显式写出 $P(x)$ 的表达式;
- 只能通过模型采样或输出对数概率的方式获取单个样本的概率值,无法直接得到整个分布的概率函数。
以大模型为例,大模型 Autoregressive 生成或训练过程中,模型的运作方式是高度优化的:
- 计算 Logits:模型进行前向传播,得到 50,000 维的 logits 向量。
- 采样(Sampling):从这个 logits 向量(经过 Softmax 转换成概率)中采样一个词元。例如,通过贪心策略(Greedy Search)选择概率最高的那个词,或者通过 Top-p/Top-k 采样在概率较高的一个小子集中进行随机选择。假设最终采样的词元是 “公园”。
- 计算损失/记录信息:在训练中,我们通常只需要计算 **被采样或目标词元(”公园”)**的概率公园,用来计算损失函数(比如强化学习中的策略梯度)。
- 释放内存:为了节省宝贵的 GPU 显存,计算框架(如 PyTorch, TensorFlow)在完成上述步骤后,会立即丢弃那个庞大的、包含 50,000 个概率值的完整向量。它只会保留与 “公园” 这个词元相关的梯度信息用于反向传播。
困境就在这里:当我们想回头计算 KL 散度时,我们发现我们手上只有 公园 和 公园 这两个值。而计算完整的 KL 散度需要词汇表中所有 50,000 个词元的概率,但这些信息(比如 散步, 吃饭 等)为了节省显存,已经被丢弃了!
强行保留这两个 50,000 维的完整概率向量会极大地增加显存占用,可能导致显存溢出(Out of Memory),使得训练无法进行,或者只能使用非常小的批量大小(batch size),严重影响训练效率。
如前所述,在强化学习中,Reverse KL 更加常见,因为我们希望 actor 不要偏离 reference policy 太远,而非要求完全覆盖所有模式。因此,下面关于 KL 散度近似估计的讨论中,都以计算 Reverse KL $D_{\text{KL}}(Q \parallel P)$ 为目标进行讨论。
其中:
- $P$ 为数据的真实分布,在 RL 场景对应着 old policy 或者 ref policy 的分布
- $Q$ 为模型分布或者预测分布,在 RL 场景中对应着正在被优化的目标策略的分布
K1 估计:无偏、高方差、可能为负
- 核心思路:将 KL 散度表示为对数比率的期望,用蒙特卡洛估计逼近:
$$ D_{\text{KL}}(Q \parallel P) = \mathbb{E}_{x \sim Q(x)} \left[ \log \frac{Q(x)}{P(x)} \right] $$
- 蒙特卡洛近似公式:从 $Q$ 中采样 $x_1, x_2, \ldots, x_N$,估计为: $$ \hat{D}{\text{KL}}(Q \parallel P) = \frac{1}{N} \sum{k=1}^{N} \log \frac{Q(x_k)}{P(x_k)} $$
- 令 $r(x) = \frac{P(x)}{Q(x)}$,则 K1 估计公式为 $$ \hat{D}{\text{KL}}(Q \parallel P) = \frac{1}{N} \sum{k=1}^{N} -\log r(x_k) $$
- 性质:
- 无偏性:当 $N \to \infty$ 时,估计值收敛到真实 KL 值:$$ \frac{1}{N} \sum_{k=1}^{N} \log \frac{Q(x_k)}{P(x_k)} \xrightarrow{N \to \infty} D_{\text{KL}}(Q \parallel P) $$
- 高方差:不同实验结果波动大;
- 可能为负:与 KL 散度非负的理论性质冲突。
K2 估计:有偏、低方差、非负
- 核心思路:对对数比率项平方,确保估计值非负,降低方差: $$ \hat{D}{\text{KL}}(Q \parallel P) = \frac{1}{N} \sum{k=1}^{N} \frac{1}{2} \left( \log \frac{Q(x_k)}{P(x_k)} \right)^2 $$
- 令 $r(x) = \frac{P(x)}{Q(x)}$,则 K2 估计公式为 $$ \hat{D}{\text{KL}}(Q \parallel P) = \frac{1}{N} \sum{k=1}^{N} \frac{1}{2} (\log r(x_k))^2 $$
- 性质:
- 低方差:平方操作抑制极端值波动;
- 非负性:避免负值与理论冲突;
- 有偏性:P 与 Q 差异较大时,估计值与真实值偏差明显。
设计动机:$k_1$ 的问题在于可正可负,而 $k_2$ 通过取平方保证每个样本都是正的,直观上每个样本都在告诉你 $P$ 和 $Q$ 相差多远。
为什么偏差很小? $k_2$ 本质上是一个 f-散度(f-divergence),其中 $f(x) = \frac{1}{2}(\log x)^2$。f-散度有一个优美的性质:所有可微的 f-散度在 $q \approx p$ 时,二阶展开都形如 $$D_f(p, q_\theta) = \frac{f^{\prime\prime}(1)}{2} \theta^T F \theta + O(\theta^3)$$ 其中是 Fisher 信息矩阵。KL 散度对应 $f(x) = -\log x$,有 $f^{\prime\prime}(1) = 1$;而 $k_2$ 对应的 $f(x) = \frac{1}{2}(\log x)^2$,同样有 $f^{\prime\prime}(1) = 1$。这意味着当策略接近时,$k_2$ 与真实 KL 的行为几乎一致,偏差仅体现在高阶项。
K3 估计:无偏、低方差、非负
- 核心思路:引入期望值为 0 的修正项(控制变量),平衡偏差与方差。
- 定义修正项:令 $r(x) = \frac{P(x)}{Q(x)}$,则 K3 估计的计算方法为: $$ \begin{align} \hat{D}{\text{KL}}(Q \parallel P) &= \frac{1}{N} \sum{k=1}^{N} \left[ r(x_k) - 1 - \log r(x_k) \right] \ &= \frac{1}{N} \sum_{k=1}^{N} \left[ \frac{P(x)}{Q(x)} - 1 - \log \frac{P(x)}{Q(x)} \right] \end{align} $$
- 性质:
- 无偏性:修正项期望为 0,不影响估计的无偏性;
- 低方差:非负项抑制波动;
- 非负性:由函数 $f(x) = x - 1 - \log x \geq 0$ $(x > 0)$ 保证。
证明 K3 估计的无偏性:
首先计算 $r(x)$ 的期望: $$ \mathbb{E}{x \sim Q}[r (x)] = \mathbb{E}{x \sim Q}\left[ \frac{P (x)}{Q (x)} \right] = \int Q (x) \cdot \frac{P (x)}{Q (x)} dx = \int P (x) dx = 1 $$
因此 $\mathbb{E}_{x \sim Q}[r(x) - 1] = 0$。
再将 $k3(x)$ 拆分: $$ k_3 (x) = \left ( \frac{P (x)}{Q (x)} - 1 \right) - \log \frac{P (x)}{Q(x)} $$ 其期望为: $$ \mathbb{E}[k 3 (x)] = \mathbb{E}\left[ \frac{P (x)}{Q (x)} - 1 \right] - \mathbb{E}\left[ \log \frac{P (x)}{Q (x)} \right] = 0 + \mathbb{E}\left[ \log \frac{Q (x)}{P (x)} \right] = D_{\text{KL}}(Q \parallel P) $$
即 K3 是无偏估计器。
总结不同估计计算方法
这篇文章2 总结了 3 种估计的联系,可以参考。
$$ \begin{align} r &= \frac{P(x)}{Q(x)} \ k_1 &= -log \ r \ k_2 &= \frac{1}{2} (log \ r)^2 \ k_3 &= r - 1 -log\ r \end{align} $$
总结成表格:
| 估计器 | 定义 | 设计原理 | 对数值的偏差 | 方差特性 |
|---|---|---|---|---|
| $k_1$ | $-log \ r$ | 最朴素定义 | 无偏 | 高(可正可负) |
| $k_2$ | $\frac{1}{2} (log \ r)^2$ | f-散度,二阶行为与 KL 一致 | 有偏(但极小) | 低(恒正) |
| $k_3$ | $r - 1 -log\ r$ | 控制变量 + Bregman 散度 | 无偏 | 低(恒正) |
从数值估计的角度看,是「无偏 + 低方差」的最优选择;但正如后文将分析的,梯度层面的故事完全不同——不同估计器的梯度可能对应不同的优化目标。此外,KL 是加入 reward 做 shaping,还是作为 loss 直接回传梯度,也会根本性地影响训练行为。
KL 梯度求解
记 score function $s_\theta(x) = \nabla_\theta \log q_\theta(x)$ 它有一个重要性质:$\mathbb{E}{q\theta}[s_\theta] = 0$ 因为 $\int \nabla_\theta q_\theta dx = \nabla_\theta \int q_\theta dx = \nabla_\theta 1 = 0$
Forward KL 梯度求解
$$D_{\mathrm{KL}}(p | q_\theta) = \int p(x) \log \frac{p(x)}{q_\theta(x)} dx$$ 由于 $p (x)$ 不依赖于 $\theta$ : $$\nabla_\theta D_{\mathrm{KL}}(p | q_\theta) = \int p(x) \cdot \nabla_\theta \left(-\log q_\theta(x)\right) dx = -\mathbb{E}p[s\theta]$$ 为了用 $q$ 的样本估计这个量,进行重要性采样 $$ -\mathbb{E}p[s\theta] = -\mathbb{E}q\left[\frac{p}{q\theta} \cdot s_\theta\right] = -\mathbb{E}q[r \cdot s\theta] $$ 利用 $\mathbb{E}q[s\theta] = 0$,可改写为: $$ \boxed{\nabla_\theta D_{\mathrm{KL}}(p | q_\theta) = \mathbb{E}q[(1-r) \cdot s\theta]} $$
Reverse KL 梯度求解
$$ D_{\mathrm{KL}}(q_\theta | p) = \int q_\theta(x) \log \frac{q_\theta(x)}{p(x)} dx $$ 对 $\theta$ 求梯度(使用乘积法则):
$$\nabla_\theta D_{\mathrm{KL}}(q_\theta | p) = \int \nabla_\theta q_\theta \cdot \log \frac{q_\theta}{p} dx + \int q_\theta \cdot \nabla_\theta \log \frac{q_\theta}{p} dx$$ 利用 $\nabla_\theta q_\theta = q_\theta \cdot s_\theta$ 以及 $\nabla_\theta \log q_\theta = s_\theta$ 和 $\nabla_\theta \log p = 0$: $$ = \mathbb{E}q\left[s\theta \cdot \log \frac{q_\theta}{p}\right] + \mathbb{E}q[s\theta] = \mathbb{E}q\left[s\theta \cdot \log \frac{q_\theta}{p}\right] $$ 即 $$ \boxed{\nabla_\theta D_{\mathrm{KL}}(q_\theta | p) = \mathbb{E}q\left[s\theta \cdot \log \frac{q_\theta}{p}\right] = -\mathbb{E}q[s\theta \cdot \log r]} $$
两种求导顺序
在代码实现中,存在两条路径:
- 先梯度、后期望:对每个样本的 求梯度,再对梯度求期望(Monte Carlo 估计)
- 先期望、后梯度:把 当作损失函数,对解析表达式求梯度
在典型的深度学习代码中,我们实际执行的是「先梯度、后期望」——自动微分对每个样本计算梯度,然后在 batch 上取平均。
三种估计器的梯度推导:先梯度后期望
现在我们计算三种估计器的梯度,看它们的期望分别对应哪个 KL 的真梯度。
推导 $\nabla_\theta k_1$ : $$ k_1 = -\log r = -\log \frac{p(x)}{q_\theta(x)} = \log q_\theta(x) - \log p(x) $$ $$ \nabla_\theta k_1 = \nabla_\theta \log q_\theta(x) - \nabla_\theta \log p(x) = s_\theta - 0 = s_\theta $$ 推导 $\nabla_\theta k_2$:
$$ k_2 = \frac{1}{2}(\log r)^2 $$ 由链式法则: $$ \begin{aligned} \nabla_\theta k_2 &= (\log r) \cdot \nabla_\theta(\log r) \ &= (\log r) \cdot \nabla_\theta(\log p(x) - \log q_\theta(x)) \ &= (\log r)(-s_\theta) \ &= - (\log r) s_\theta. \end{aligned} $$
推导 : $$k_3 = r - 1 - \log r$$ 首先计算 $\nabla_\theta r$。由于 :$r = p(x) \cdot q_\theta(x)^{-1}$ $$ \nabla_\theta r = p(x) \cdot (-1) \cdot q_\theta(x)^{-2} \cdot \nabla_\theta q_\theta(x) = -\frac{p(x)}{q_\theta(x)} \cdot \frac{\nabla_\theta q_\theta(x)}{q_\theta(x)} = -r \cdot s_\theta $$ 再计算 $\nabla_\theta \log r$ : $$ \nabla_\theta \log r = \frac{1}{r} \nabla_\theta r = \frac{1}{r} \cdot (-r \cdot s_\theta) = -s_\theta $$ 因此: $$ \nabla_\theta k_3 = \nabla_\theta r - 0 - \nabla_\theta \log r = -r \cdot s_\theta - (-s_\theta) = (1 - r) \cdot s_\theta $$ 对它们在 $q_\theta$ 下取期望:
| Estimator | $\mathbb{E}{q}[\nabla\theta k_i]$ | Equals |
|---|---|---|
| $k_1$ | $\mathbb{E}{q}[s\theta] = 0$ | Zero (useless as loss) |
| $k_2$ | $-\mathbb{E}{q}[(\log r) \cdot s\theta] = \nabla_\theta D_{\mathrm{KL}}(q | p)$ | Gradient of reverse KL |
| $k_3$ | $\mathbb{E}{q}[(1-r) \cdot s\theta] = \nabla_\theta D_{\mathrm{KL}}(p | q)$ | Gradient of forward KL |
关键洞察:
- $k_2$ 的梯度等价于反向 KL 的真梯度——这是优化「约束策略不偏离 ref」的正确选择
- $k_3$ 的梯度等价于正向 KL 的真梯度——这对应「mode-covering」目标
- $k_1$ 的梯度期望恒为零——作为 loss 反传毫无意义!
这也解释了为什么 DeepSeek-R1 的 Nature 论文中强调要 周期性重置 reference model —— 如果长时间不重置 $\pi$ $\pi_{ref}$ 的差距会不断扩大,K3 估计将极易失稳。
「先期望后梯度」vs「先梯度后期望」
如果从解析角度把 $\mathbb{E}{q}[\nabla\theta k_i]$ 当作一个关于 $\theta$ 的函数再求梯度(即「先期望后梯度」),那么: $$ \nabla_\theta \mathbb{E}q[k_1] = \nabla\theta D_{\mathrm{KL}}(q | p) $$ $$ \nabla_\theta \mathbb{E}q[k_3] = \nabla\theta D_{\mathrm{KL}}(q | p) $$ 两者都给出反向 KL 的梯度。但在代码中直接对 $k_3$ 的样本均值调用反传时,自动微分执行的是「先梯度后期望」,得到的是 $\mathbb{E}q[\nabla\theta k_3]$,即正向 KL 的梯度。
这个区分非常重要:同一个估计器,两种求导顺序可能给出完全不同的结果。
扩展:从行为策略 $\mu$ 采样时的 KL 梯度估计
前面的分析都默认样本来自当前策略 $q_\theta$。然而在实际 RL 训练中,我们常常遇到这样的 off-policy 场景:
- 用旧策略或混合策略生成数据,再更新当前 actor $q_\theta$
- 离线 RL / 经验回放中,样本分布固定为 $\mu$,而不是当前的 $q_\theta$
这时,如果我们仍然希望优化反向 KL $D_{\text{KL}}(q_\theta | \mu)$,就必须引入重要性权重。
设置与记号
仍然沿用前文的记号,现在加入采样分布 $\mu(x)$,并定义重要性权重 $$
w(x) = \frac{q_\theta(x)}{\mu(x)}
$$
当从 $x \sim \mu$ 采样时,用 $w(x)k_i(x)$ 的 batch 均值作为 loss,然后调用自动微分。那么三种估计器分别给出什么梯度?
一个关键差异是:
以前的期望是 $\mathbb{E}{q\theta}[\cdot]$,分布本身依赖 $\theta$;现在的期望是 $\mathbb{E}_\mu[\cdot]$,而 $\mu$ 与 $\theta$ 无关。
这会让「先期望后梯度」与「先梯度后期望」的关系发生根本变化。
关键观察:两种求导顺序的等价性
因为 $\mu$ 与 $\theta$ 无关,对任何关于 $\theta$ 可微的函数 $f_\theta(x)$,有 $$
\nabla_\theta \mathbb{E}\mu \left[ f\theta(x) \right] = \mathbb{E}\mu \left[ \nabla\theta f_\theta(x) \right]
$$
换句话说,代码中对样本均值反传(先梯度后期望)就等价于对解析形式求梯度(先期望后梯度),不会再像 on-policy 时那样分裂成两个不同的结果。
所以在 off-policy + 重要性加权的情形下,对反向 KL 数值无偏的估计器 $k_1$ 和 $k_3$,它们的梯度期望都将对应于反向 KL 的真梯度。
这是与 on-policy 情形的根本区别。
数值层面:无偏性仍然保持
由标准的重要性采样关系 $\mathbb{E}\mu\left[ w \cdot f \right] = \mathbb{E}{q_\theta}\left[ f \right]$,有
$$
\mathbb{E}\mu\left[ w k_1 \right] = D{\text{KL}}(q_\theta | p),\quad \mathbb{E}\mu\left[ w k_3 \right] = D{\text{KL}}(q_\theta | p) \quad (\text{无偏})
$$
$$
\mathbb{E}\mu\left[ w k_2 \right] = \mathbb{E}{q_\theta}\left[ k_2 \right] \neq D_{\text{KL}}(q_\theta | p) \quad (\text{有偏})
$$
这与 on-policy 情形完全一致。
梯度推导
首先计算重要性权重的梯度。由 $w = q_\theta / \mu$ 且 $\mu$ 不依赖 $\theta$: 因为 $s_\theta(x) = \nabla_\theta \log q_\theta(x)$ ,因此 $\nabla_\theta q_\theta = q_\theta \cdot \nabla_\theta \log q_\theta = q_\theta \cdot s_\theta$ $$ \begin{align} \nabla_\theta w(x) &= \nabla_\theta \frac{q_{\theta}}{\mu} \ &= \frac{1}{\mu} \cdot \nabla_\theta q_{\theta} \ &= \frac{1}{\mu} \cdot (q_{\theta} \cdot s_{\theta}) \ &= \frac{q_{\theta}}{\mu} \cdot s_{\theta} \ &= w(x) s_\theta(x) \end{align} $$
结合前文已推导的 $\nabla_\theta k_i$,用乘积法则:
$\boxed{\nabla_\theta (w k_1)}$: $$
\nabla_\theta (w k_1) = (\nabla_\theta w) k_1 + w (\nabla_\theta k_1) = w s_\theta k_1 + w s_\theta = w s_\theta (k_1 + 1)
$$
$\boxed{\nabla_\theta (w k_2)}$:
$$
\nabla_\theta (w k_2) = w s_\theta k_2 + w (-\log r) s_\theta = w s_\theta (k_2 - \log r)
$$
$\boxed{\nabla_\theta (w k_3)}$:
$$
\nabla_\theta (w k_3) = w s_\theta k_3 + w (1 - r) s_\theta = w s_\theta (k_3 + 1 - r)
$$
代入 $k_3 = r - 1 - \log r$:
$$
k_3 + 1 - r = (r - 1 - \log r) + 1 - r = -\log r = k_1
$$
因此有一个漂亮的简化: $$
\boxed{\nabla_\theta (w k_3) = w s_\theta k_1 = -w s_\theta \log r}
$$
哪些给出无偏的反向 KL 梯度?
利用 $\mathbb{E}\mu[w \cdot f] = \mathbb{E}{q_\theta}[f]$ 和 $\mathbb{E}{q\theta}[s_\theta] = 0$:
$\boxed{\mathbb{E}\mu\left[ \nabla\theta (w k_1) \right]}$:
$$
\mathbb{E}\mu\left[ w s\theta (k_1 + 1) \right] = \mathbb{E}q\left[ s\theta k_1 \right] + \underbrace{\mathbb{E}q\left[ s\theta \right]}{=0} = \nabla\theta D_{\text{KL}}(q_\theta | p) \quad \checkmark
$$
$\boxed{\mathbb{E}\mu\left[ \nabla\theta (w k_2) \right]}$:
$$
\mathbb{E}\mu\left[ w s\theta (k_2 - \log r) \right] = \mathbb{E}q\left[ s\theta (k_2 - \log r) \right] = \nabla_\theta \mathbb{E}_q\left[ k_2 \right]
$$
其中 $\mathbb{E}q\left[ k_2 \right] = \frac{1}{2}\mathbb{E}{q}[(\log r)^2]$ 和 $\mathbb{E}q\left[ s\theta (k_2 - \log r) \right]=\mathbb{E}q\left[s\theta (\frac{1}{2} (log \ r)^2- logr) \right]$
这是 $\mathbb{E}_q\left[ k_2 \right]$ 这个 f-散度的真梯度,不是反向 KL 的梯度。
$\boxed{\mathbb{E}\mu\left[ \nabla\theta (\bar{w} k_2) \right]}$($\boxed{\bar{w} = \text{sg}(w)}$ 表示 detach):
如果把重要性权重视为常数(在代码中 detach 掉),则: $$ \nabla_\theta (\bar{w} k_2) = \bar{w} \cdot \nabla_\theta k_2 = \bar{w} \cdot (-\log r) s_\theta $$
取期望: $$
\mathbb{E}\mu\left[ \bar{w} \cdot (-\log r) s\theta \right] = \mathbb{E}q\left[ (-\log r) s\theta \right] = \nabla_\theta D_{\text{KL}}(q_\theta | p) \quad \checkmark
$$
这正是反向 KL 的真梯度!
$\boxed{\mathbb{E}\mu\left[ \nabla\theta (w k_3) \right]}$:
$$
\mathbb{E}\mu\left[ w s\theta k_1 \right] = \mathbb{E}q\left[ s\theta k_1 \right] = \nabla_\theta D_{\text{KL}}(q_\theta | p) \quad \checkmark
$$
总结表格:
| 加权估计器 | 期望对应的目标 | 梯度期望对应的真梯度 |
|---|---|---|
| $\frac{q_\theta}{\mu} k_1$ | $D_{\text{KL}}(q_\theta | p)$ | $\nabla_\theta D_{\text{KL}}(q_\theta | p)$(反向 KL) $\checkmark$ |
| $\frac{q_\theta}{\mu} k_2$ | $\mathbb{E}_q [k_2]$(f-散度) | $\nabla_\theta \mathbb{E}_q [k_2]$,不是反向 KL $\boldsymbol{\times}$ |
| $\text{sg}\left( \frac{q_\theta}{\mu} \right) k_2$ | $\mathbb{E}_q [k_2]$(f-散度) | $\nabla_\theta D_{\text{KL}}(q_\theta | p)$(反向 KL) $\checkmark$ |
| $\frac{q_\theta}{\mu} k_3$ | $D_{\text{KL}}(q_\theta | p)$ | $\nabla_\theta D_{\text{KL}}(q_\theta | p)$(反向 KL) $\checkmark$ |
与 on-policy 情形的对比——一个有趣的反转:
- On-policy 时,用 $k_2$ 做 loss 的梯度是反向 KL,而 $k_1$ 的梯度期望恒为零
- Off-policy + 重要性加权时,$\frac{q_\theta}{\mu} k_1$ 和 $\frac{q_\theta}{\mu} k_3$ 给出反向 KL 的真梯度,而 $\frac{q_\theta}{\mu} k_2$(权重参与梯度计算)不再适用
- 但如果把重要性权重 detach 掉,$\text{sg}\left( \frac{q_\theta}{\mu} \right) k_2$ 的梯度也是反向 KL 的真梯度
三个无偏梯度估计器的方差对比
前一小节我们看到,在 off-policy + 重要性采样的设置下,下面三个 loss 都给出反向 KL 的无偏梯度估计: $$ L_1(x) = w(x)k_1(x),\quad L_2(x) = \bar{w}(x)k_2(x),\quad L_3(x) = w(x)k_3(x), $$ 其中 $w = \frac{q_\theta}{\mu}$,$\bar{w} = \text{sg}(w)$ 表示对权重做 stop-gradient。它们对应的梯度随机变量为: $$ g_1(x) := \nabla_\theta L_1(x),\quad g_2(x) := \nabla_\theta L_2(x),\quad g_3(x) := \nabla_\theta L_3(x). $$ 利用前文已推导的结果:
- $\nabla_\theta w = w s_\theta$
- $\nabla_\theta k_1 = s_\theta$
- $\nabla_\theta k_2 = -(\log r) s_\theta = k_1 s_\theta$
- $\nabla_\theta k_3 = (1 - r) s_\theta$ 有: $$ \begin{align*} g_1(x) &= \nabla_\theta (w k_1) = w s_\theta k_1 + w s_\theta = w(x) s_\theta(x) \left( k_1(x) + 1 \right), \ g_2(x) &= \nabla_\theta (\bar{w} k_2) = \bar{w} \nabla_\theta k_2 = w k_1 s_\theta = w(x) s_\theta(x) k_1(x), \ g_3(x) &= \nabla_\theta (w k_3) = w s_\theta k_3 + w(1 - r) s_\theta = w s_\theta (k_3 + 1 - r) = w(x) s_\theta(x) k_1(x). \end{align*} $$ 最后一步用到了 $k_3 + 1 - r = (r - 1 - \log r) + 1 - r = -\log r = k_1$。于是出现了一个非常关键的事实:
在 off-policy + detach 权重的情况下,$\bar{w}k_2$ 与 $w k_3$ 的梯度完全一样:$g_2(x) \equiv g_3(x)$。换言之,三个 loss 实际上只对应两种不同的梯度随机变量:$g_1$ 与 $g_\star := g_2 = g_3$。
下面比较这两种随机变量的方差。为简化记号,令 $$ A(x) := w(x) s_\theta(x),\quad B(x) := k_1(x), $$ 则 $$ g_1 = A(B + 1),\quad g_\star = AB. $$ 两者的期望都等于 $\nabla_\theta D_{\text{KL}}(q_\theta | p)$,因此有相同的均值项。展开方差定义并相减得到: $$ \boxed{\text{Var}\mu(g_1) - \text{Var}\mu(g_\star) = \mathbb{E}\mu\left[ A^2\left((B + 1)^2 - B^2\right) \right] = \mathbb{E}\mu\left[ A^2(2B + 1) \right]} $$ 也就是 $$ \text{Var}\mu(g_1) - \text{Var}\mu(g_\star) = \mathbb{E}\mu\left[ w(x)^2 s\theta(x)^2 \left( 2k_1(x) + 1 \right) \right]. $$ 在常见的 KL 惩罚 regime 下,$q_\theta \approx p \approx \mu$,取 $r(x) = 1 + \varepsilon(x),\ |\varepsilon| \ll 1$。此时 $k_1 = -\log r \approx -\varepsilon$,因此 $2k_1 + 1 \approx 1 - 2\varepsilon$,主导项为正的 $O(1)$ 常数。这意味着上式右侧近似为 $\mathbb{E}\mu\left[ w^2 s\theta^2 \right] > 0$,从而 $\text{Var}\mu(g_1) > \text{Var}\mu(g_\star)$。更具体地,一阶近似 $$ k_1 \approx -\varepsilon,\quad k_1 + 1 \approx 1 - \varepsilon. $$ 于是 $$ g_1(x) \approx w(x) s_\theta(x) (1 - \varepsilon(x)),\quad g_\star(x) \approx w(x) s_\theta(x) (-\varepsilon(x)). $$ 核心直觉:
- $g_1$ 包含一个量级为 $O(1)$ 的零均值噪声项 $w s_\theta$,导致单样本方差较大;
- $g_\star$ 已把该常数噪声项消去,剩下与 $\varepsilon$ 成正比的一阶小量,方差为 $O(\varepsilon^2)$,显著更小。
小结表格:
| 估计器 | 梯度随机变量 | 系数量级 ($r \approx 1$) | 方差 |
|---|---|---|---|
| $w k_1$ | $w s_\theta (k_1 + 1)$ | $O(1)$ | 高 |
| $\text{sg}(w) k_2$ | $w s_\theta k_1$ | $O(\varepsilon)$ | 低 |
| $w k_3$ | $w s_\theta k_1$ | $O(\varepsilon)$ | 低 |
结论:在 off-policy + 重要性采样的设置下,给出反向 KL 真梯度的无偏估计器有三个:$w k_1$,$\bar{w} k_2$,$w k_3$。其中 $\bar{w} k_2$ 与 $w k_3$ 在梯度层面完全等价——同均值、同方差、同高阶矩;相比之下,$w k_1$ 的梯度多了一个零均值的常数噪声项 $w s_\theta$,在典型的 KL 惩罚 regime 下其方差大约高一个量级。
实践建议:
若在 off-policy 场景下优化反向 KL,首选 $w k_3$ 或 $\text{sg}(w) k_2$(两者梯度等价且方差低);$w k_1$ 虽无偏但方差高,可作为备选并需配合 clipping/正则化。
极度 off-policy 时的警示:
当 $\mu$ 与 $q_\theta$ 差异很大——比如 $\mu$ 在 $q_\theta$ 的高密度区域几乎没有采样,或 $w = \frac{q_\theta}{\mu}$ 在尾部爆炸——任何基于 $\frac{q_\theta}{\mu}$ 的方法都会遭遇严重的方差问题。此时 $\frac{q_\theta}{\mu} k_3$(或 $\text{sg}\left( \frac{q_\theta}{\mu} \right) k_2$)相对 $\frac{q_\theta}{\mu} k_1$ 的优势不再有理论保证,需要结合 clipping、正则化等策略综合处理。
不过,在 RL 实践中我们通常会控制 KL 约束、限制 off-policy 程度(比如使用近邻策略 $\mu = q_{\theta_{\text{old}}}$),在这个常见的 regime 里,可以相当有信心地说:
如果已经决定用 off-policy + 重要性采样来优化反向 KL,推荐使用 $\boxed{\frac{q_\theta}{\mu} k_3}$ 或 $\boxed{\text{sg}\left( \frac{q_\theta}{\mu} \right) k_2}$(两者梯度等价且方差低);相较之下,$\boxed{\frac{q_\theta}{\mu} k_1}$ 方差更高。
这就是为什么 DeepSeek v3.2 技术报告中使用的是 $\frac{q_\theta}{\mu} k_3$ 作为 off-policy KL 惩罚的估计器。
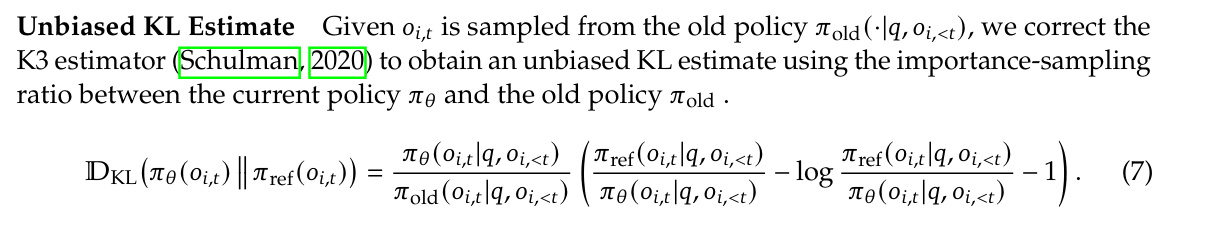
KL 梯度总结
- 从行为策略 $\mu$ 采样时,自然的 off-policy KL 估计为 $\frac{q_\theta}{\mu} k_i$。
- 数值上,$\frac{q_\theta}{\mu} k_1$ 与 $\frac{q_\theta}{\mu} k_3$ 仍然是反向 KL 的无偏估计。
- 梯度上,因为 $\mu$ 与 $\theta$ 无关,「先期望后梯度」与「先梯度后期望」等价:
- $\mathbb{E}\mu\left[ \nabla\theta \left( \frac{q_\theta}{\mu} k_1 \right) \right] = \nabla_\theta D_{\text{KL}}(q_\theta | p)$
- $\mathbb{E}\mu\left[ \nabla\theta \left( \frac{q_\theta}{\mu} k_3 \right) \right] = \nabla_\theta D_{\text{KL}}(q_\theta | p)$
- $\mathbb{E}\mu\left[ \nabla\theta \left( \frac{q_\theta}{\mu} k_2 \right) \right] \neq \nabla_\theta D_{\text{KL}}(q_\theta | p)$
- 方差上,$\frac{q_\theta}{\mu} k_3$ 与 $\text{sg}\left( \frac{q_\theta}{\mu} \right) k_2$ 的梯度完全相同(两者都是 $w s_\theta k_1$),在统计性质上等价。相比之下,$\frac{q_\theta}{\mu} k_1$ 的梯度多了一个零均值噪声项 $w s_\theta$,在 $q_\theta \approx p \approx \mu$ 的典型场景下方差显著更高。
梯度估计总览
下表汇总了 on-policy 与 off-policy 两种场景下,各估计器的梯度期望及其对应的优化目标:
| 采样来源 | Loss | $\boxed{\nabla_\theta \text{Loss}}$ 的期望 | 对应的优化目标 | 能否用于优化反向 KL? |
|---|---|---|---|---|
| $q$ (on) | $k_1$ | $\mathbb{E}q[s\theta] = 0$ | 无(梯度恒为零) | × |
| $q$ (on) | $k_2$ | $\nabla_\theta D_{\text{KL}}(q | p)$ | 反向 KL | ✓ |
| $q$ (on) | $k_3$ | $\nabla_\theta D_{\text{KL}}(p | q)$ | 正向 KL | × |
| $\mu$ (off) | $\frac{q}{\mu} k_1$ | $\nabla_\theta D_{\text{KL}}(q | p)$ | 反向 KL | ✓(但方差较高) |
| $\mu$ (off) | $\frac{q}{\mu} k_2$ | $\nabla_\theta \mathbb{E}_q[k_2]$ | f-散度(非 KL) | × |
| $\mu$ (off) | $\text{sg}\left( \frac{q}{\mu} \right) k_2$ | $\nabla_\theta D_{\text{KL}}(q | p)$ | 反向 KL | ✓ |
| $\mu$ (off) | $\frac{q}{\mu} k_3$ | $\nabla_\theta D_{\text{KL}}(q | p)$ | 反向 KL | ✓(推荐,低方差) |
关键结论:
- On-policy 优化反向 KL:唯一正确选择是 $\boxed{k_2}$
- Off-policy 优化反向 KL:有三个正确选项:
- $\boxed{\frac{q}{\mu} k_1}$:无偏但方差较高
- $\boxed{\text{sg}\left( \frac{q}{\mu} \right) k_2}$:无偏,与 $\frac{q}{\mu} k_3$ 梯度完全等价
- $\boxed{\frac{q}{\mu} k_3}$:无偏且方差更低(与上一项等价,均为推荐选择)
- $\boxed{\frac{q}{\mu} k_2}$(权重参与梯度)在 off-policy 下失效:这是一个容易被忽视的陷阱
然而,在选定估计器之前,还有一个更基础的问题需要回答:KL 应该加进 reward 里,还是作为 loss 的一部分? 这一选择会从根本上影响优化行为和 credit assignment。
KL 在不同场景的应用
在强化学习中,对应到上面的 notation
- $Q_\theta$ 为当前 actor 的 policy
- $P$ 为 ref 模型的 policy
则
- Reverse KL 计算为 $D_{K L}\left(Q_{\theta} | P\right) = \mathbb{E}{x \sim Q{\theta}(x)} \left[\log \frac{Q(x)}{P(x)} \right]$
- Forward KL 计算为 $D_{\text{KL}}(P \parallel Q_{\theta}) = \mathbb{E}{x \sim P(x)} \left[ \log \frac{P(x)}{Q{\theta}(x)} \right]$
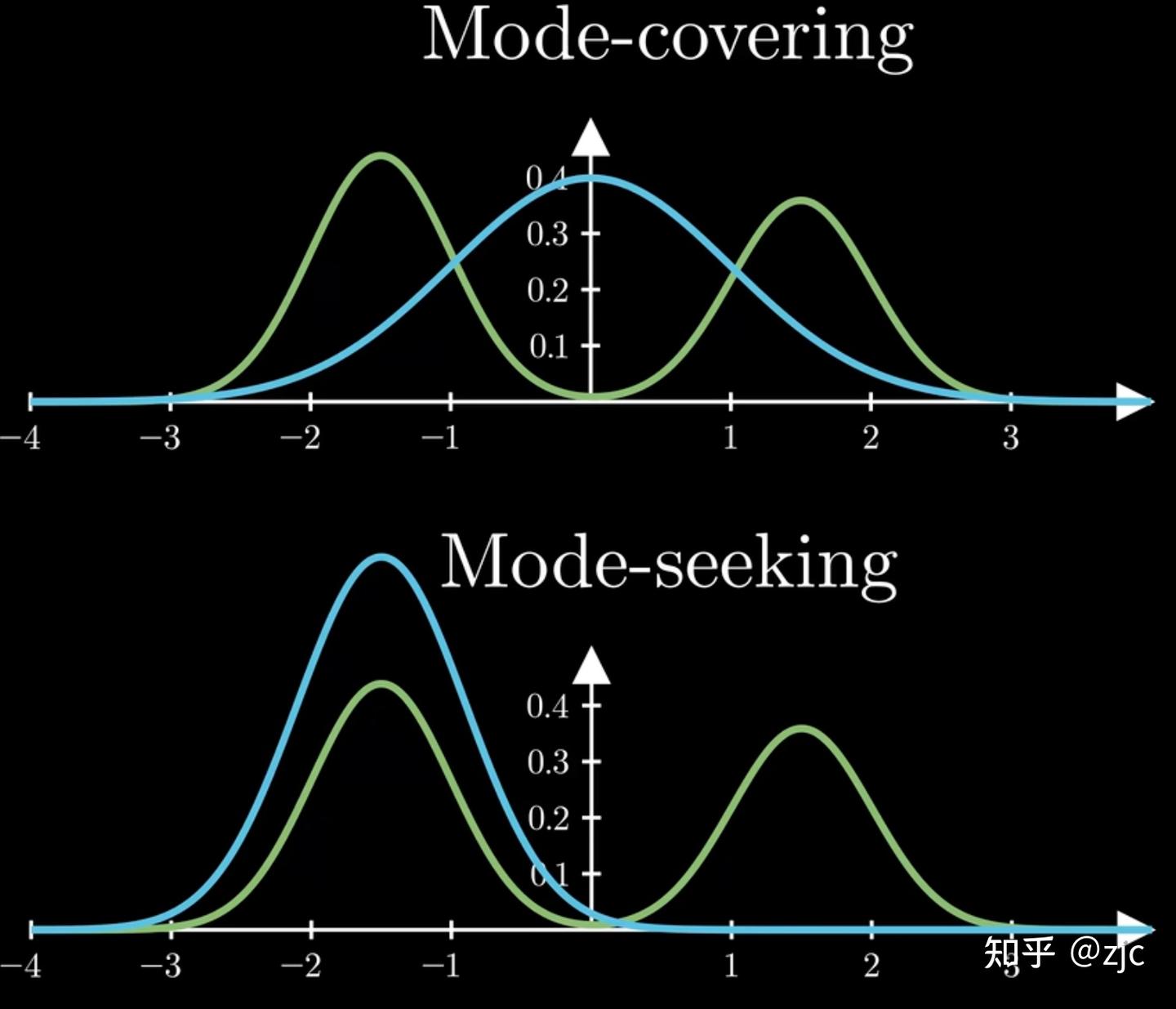
- Reverse KL 倾向于 mode-seeking ——策略会集中在参考分布的高概率区域,可能牺牲多样性
- Forward KL 倾向于 mode-covering ——策略会尽量覆盖参考分布的支撑集
在 RLHF 的主流实现中,Reverse KL 更为常见,因为我们希望 actor 不要偏离 reference policy 太远,而非要求完全覆盖所有模式。
RLHF 中 reward 增加 KL 惩罚 (不需要梯度)
当 KL 仅作为标量惩罚加入 reward shaping 时,我们只需要准确的数值估计,不需要反传梯度。此时应参考前文「估计 KL 数值时的偏差与方差」中的分析。
推荐:
- 使用 $k_1$ 或 $k_3$(两者对反向 KL 数值均无偏)
- 当策略已接近参考策略时,$k_3$ 往往更低方差
- 覆盖不足或尾部错配明显时,$k_1$ 更稳健
- Off-policy 时加重要性权重 $\frac{q_\theta}{\mu}$ 即可
注:若想施加正向 KL 惩罚(偏向覆盖行为分布),数值上可用 $\mathbb{E}_q[r \log r]$ 或 $\mathbb{E}_p[\log r]$(若可从 $p$ 采样)。
RL 中 KL Loss (需要梯度回传)
当 KL 作为 loss 的一部分参与反传时,必须考虑梯度的正确性。
On-policy:优化反向 KL(最常见场景)
目标:控制 actor 不偏离 reference policy。
正确做法:使用 $k_2$ 作为 loss。
$$\mathcal{L}_{k_2} = \frac{1}{2} (\log r)^2$$
其梯度期望 $\mathbb{E}q[\nabla k_2] = \nabla\theta D_{\text{KL}}(q|p)$ 正是反向 KL 的真梯度。
On-policy:优化正向 KL(mode-covering 场景)
目标:让策略覆盖参考分布的支撑集(如离线 RL、模仿学习等)。
正确做法:使用 $k_3$ 作为 loss。
$$\mathbb{E}q[\nabla k_3] = \mathbb{E}q[(1 - r) \cdot s\theta] = \nabla\theta D_{\text{KL}}(p|q)$$
直接对 $k_3$ 的样本均值调用反传,自动微分计算的就是 $\mathbb{E}q[\nabla\theta k_3]$,即正向 KL 的梯度,无需额外处理。
Off-policy:优化反向 KL
目标:数据来自行为策略 $\mu$,仍希望优化反向 KL。
推荐做法:使用 $\frac{q_\theta}{\mu} k_3$ 或 $\text{sg}\left( \frac{q_\theta}{\mu} \right) k_2$ 作为 loss(两者梯度完全等价)。
$$\mathcal{L} = \frac{q_\theta(x)}{\mu(x)} \cdot \left( \frac{p(x)}{q_\theta(x)} - 1 - \log \frac{p(x)}{q_\theta(x)} \right)$$
或
$$\mathcal{L} = \text{sg}\left( \frac{q_\theta(x)}{\mu(x)} \right) \cdot \frac{1}{2} \left( \log \frac{p(x)}{q_\theta(x)} \right)^2$$
- 梯度无偏
- 在 $q_\theta \approx p$ 时方差都显著更低
备选方案:使用 $\frac{q_\theta}{\mu} k_1$(梯度同样无偏,但方差更高)
一份拿来就能用的对照表
下表按「目标 KL 方向」×「采样来源」×「使用方式」三个维度给出推荐的估计器选择。其中「用于数值」对应 KL 作为 reward 惩罚(不需要梯度),「用于梯度」对应 KL 作为 loss(需要反传梯度)。
下表按「目标 KL 方向」×「采样来源」×「使用方式」三个维度给出推荐的估计器选择。其中「用于数值」对应 KL 作为 reward 惩罚(不需要梯度),「用于梯度」对应 KL 作为 loss(需要反传梯度)。
| 目标 | 采样来源 | 用于数值(KL 作为 Reward) | 用于梯度(KL 作为 Loss) |
|---|---|---|---|
| 反向 $\text{KL } D_{\text{KL}}(q|p)$ | $q$(on-policy) | $k_1$ 或 $k_3$(无偏) | $k_2$ |
| 反向 $\text{KL } D_{\text{KL}}(q|p)$ | $\mu$(off-policy) | $\frac{q}{\mu}k_1$ 或 $\frac{q}{\mu}k_3$(无偏) | $\frac{q}{\mu}k_3$(推荐)或 $\text{sg}\left( \frac{q}{\mu} \right)k_2$ |
| 正向 $\text{KL } D_{\text{KL}}(p|q)$ | $q$ | $\mathbb{E}_q\left[ r \log r \right]$ | $k_3$ |
对应到 veRL 的实现
在 veRL 中3,也指明了对于 KL 在不同场景的计算方法:
- KL penalty in the reward 的时候,支持 $k_1$ $k_2$ $k_3$ 等方法,也就是下面代码中的 forward_score,推荐用 $k_3$
- KL loss for KL divergence control 的时候,因为 $k_1$ 和 $k_3$ 估计的期望梯度不等于 reverse KL 的期望梯度,只有 $k_2$ 估计的期望梯度是正确的
|
|
On Policy Distill 计算 KD Loss
传统蒸馏使用 Forward KL
$$D_{KL}(\pi_T || \pi_S) = D_{KL}(P || Q) = \sum_x P(x) \cdot \log(\frac{P(x)}{Q(x)})$$
- 使用教师的概率 P (x) 来加权计算 loss
- 学生 Q 被迫覆盖教师 P 认为所有可能的“好答案”
- 如果教师 $P$ 认为“你好”和“Hi”都是 50% 可能的好答案,学生 $Q$ 必须同时学会“你好”和“Hi”。
- 对于能力有限的学生(小模型),试图覆盖所有模式会导致一种“平庸的平均”。它可能会学到一个“你好”和“Hi”的“中间态”,比如输出一个模糊的、低质量的 “Hillo”,而不是一个清晰的高质量答案。
On Policy Distill 使用 Reverse KL
$$D_{KL}(\pi_S || \pi_T) = D_{KL}(Q || P) = \sum_x Q(x) \cdot \log(\frac{Q(x)}{P(x)}) $$
- 使用学生的概率 Q (x) 来加权计算 loss
- 学生 Q 被迫只在他有把握的答案上(Q (x) 高)下注,并且这些答案必须是教师 P 也认可的(P (x) 也高)。
- 如果教师 $P$ 认为“你好”和“Hi”都是 50% 可能的好答案,学生 $Q$ 只需要学会其中一个(比如 100% 输出“你好”)就能拿到高分。
- 这允许学生模型 Q 集中其有限的能力(capacity)来完美地学习教师 P 的至少一个模式(mode)。这会产生更清晰、更高质量的输出。
参考资料
-
Approximating KL Divergence, http://joschu.net/blog/kl-approx.html ↩︎
-
PPO 与 GRPO 中的 KL 散度近似计算, https://zhuanlan.zhihu.com/p/25208314999 ↩︎
-
https://verl.readthedocs.io/en/latest/algo/ppo.html#kl-divergence-control ↩︎
-
No backlinks found.