In The Loop 科技周刊#3:从真实世界中获取数据,从数据中获取智慧
In The Loop 科技周刊记录每周值得分享的科技内容,周日发布。本周刊开源1,欢迎投稿2。
近日,Lecun 的一条推文3 引起广泛关注,他指出,「在 4 年内,一个孩子看到的数据比最大的 LLM 多 50 倍… 文本的带宽太低,无法了解世界如何运作,相对来说,视觉数据则丰富的多,4 岁儿童看到的所有视觉数据仅相当于 Youtube 半个小时内的视频上传量。」
I’ve made that point before:
LLM: 1E13 tokens x 0.75 word/token x 2 bytes/token = 1E13 bytes.
4 year old child: 16k wake hours x 3600 s/hour x 1E6 optical nerve fibers x 2 eyes x 10 bytes/s = 1E15 bytes.
In 4 years, a child has seen 50 times more data than the biggest LLMs.3
是的,研究机构 Epoch 在 2022 年即提出,可用于训练的高质量文本可能会在2026年耗尽4。
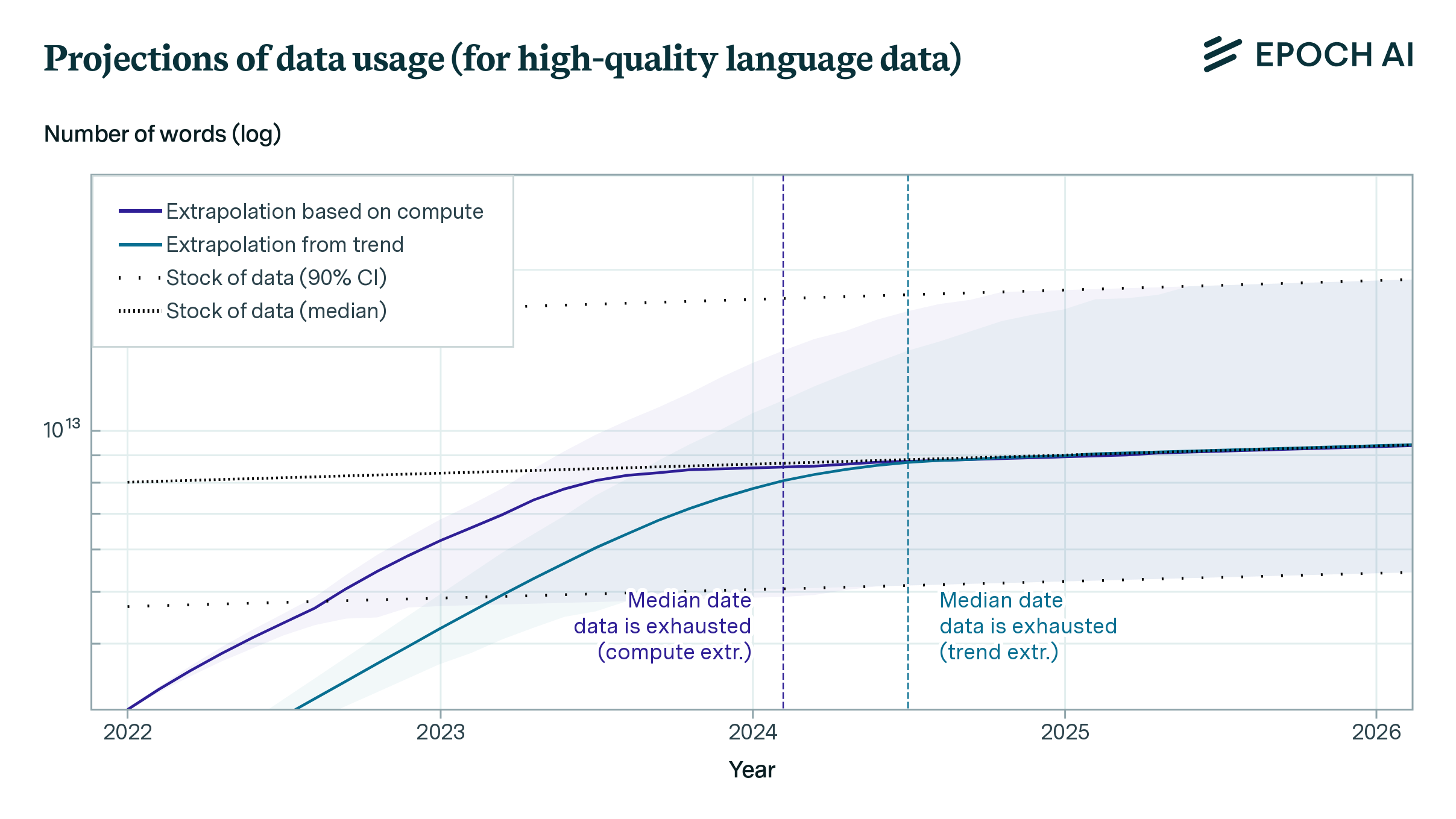
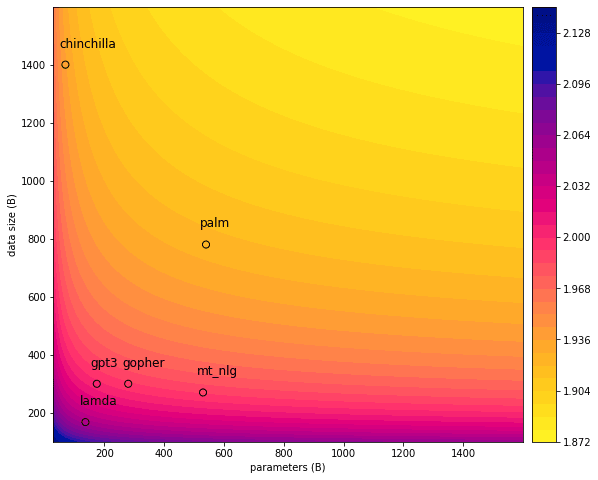
以 Chinchilla 70B 模型5为例,其在 1.4T 个 Token 上训练,消耗训练文本数据量已经达到 E12 的量级。LessWrong 的这篇文章 「chinchilla’s wild implications」6 粗略分析了目前可以收集到的高质量文本数据大概在 E13 这个量级,指出了目前训练数据将会成为 LLM 进一步 Scaling 的关键瓶颈。
高质量文本的训练数据即将耗尽,下一步将怎么办?对于这个问题有很多探索的方向,其中「多模态」和「数据合成」是目前的两个主流路径。在进一步讨论之前,我们可以先退一步,回顾一下数据到底是什么?
数据是真实世界的若干个切面
数据到底是什么?对计算机而言,它只是一连串的零一序列,而对应到真实世界,数据代表着各种信息实体的最终总结。它可能是你昨天阅读的 Chinchilla 论文「Text」,也可能是你今天在电影院看的热辣滚烫的电影 「Video」,它可能是你与父母畅快淋漓的谈话 「Audio」,也可能是你与朋友的一个温暖的拥抱「Touch」,它可能是你在年夜饭闻到的香味「Smell」,也可能是你在南方感受到天气的潮湿,etc.
在知识管理中,有一个经典的 DIKM 理论7,首先需要从真实世界中收集到各个切面的数据 Data,然后经过处理,将其转换为有用的信息 Information,接下来从信息中正确认知才可以提取出知识 Knowledge,最后经过正确判断才可以获得真正的智慧 Wisdom。

对应到当前的机器学习模型,如果要获取真正的 AGI,当前仅依靠 Language Model 可能并不足够。当前语言模型所依赖的训练数据来自人类智慧高度压缩的文本,人类真实的物理三维世界有着更为丰富的信息,如果能够将通用的数据表示(比如现在的零一序列),给到更加统一的模型统一训练,将来的模型可能会产生更加完备的智能。
「登月」有几个不同的生产要素,算力肯定是一个核心… 今天能看到最好的模型是 E25 到 E26 FLOPs 这种规模…这个数量级接下来肯定还会持续增长… 数据也是一个生产要素,包括真个实际的数字化,和来自用户的数据… 如果视频和多模态的卡点解决不了,那文本的数据瓶颈就会成为关键… 最后可能是多模态解决数据问题,合成数据解决能源问题…8
如月之暗面杨植麟所说,我们需要一个更加能够 Scale Up 的架构,进而基于这个架构给模型不停加入各种新的数据类型,从而更好地模拟整个物理世界,进而获取真正的智能。

-
https://epochai.org/blog/will-we-run-out-of-ml-data-evidence-from-projecting-dataset ↩︎
-
https://www.deepmind.com/publications/an-empirical-analysis-of-compute-optimal-large-language-model-training ↩︎
-
chinchilla’s wild implications, https://www.lesswrong.com/posts/6Fpvch8RR29qLEWNH/chinchilla-s-wild-implications ↩︎
-
专访月之暗面杨植麟:lossless long context is everything, https://mp.weixin.qq.com/s/UMY0qZsCGh87KnW4wjfvoA ↩︎
-
No backlinks found.