In The Loop 科技周刊#1:纽约时报 vs OpenAI,新时代的版权之争
In The Loop 科技周刊记录每周值得分享的科技内容,周日发布。本周刊开源1,欢迎投稿2。
Politics
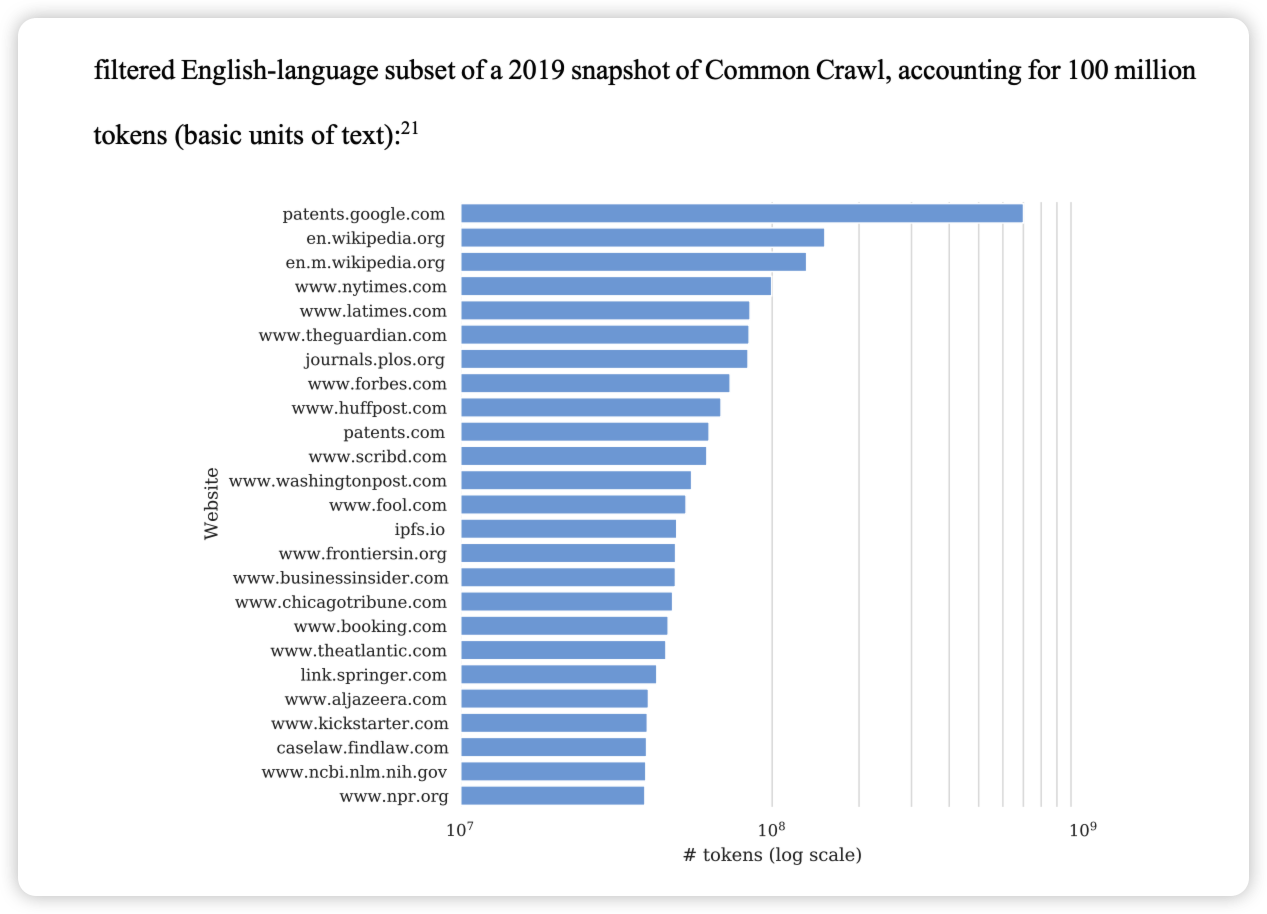
经过多个月的商业谈判,纽约时报最终没能够与 OpenAI 在版权问题上达成协议。在 2023 年底,纽约时报对 OpenAI 和微软发起诉讼3,指控其人工智能模型侵权,并要求其赔偿数十亿美元的潜在经济损失。这不是 Gen AI 与媒体和内容公司的第一起诉讼,这也不是 OpenAI 的第一起版权纠纷。

2022 年 10 月,OpenAI 与美国多媒体库提供商 Shutterstock 达成协议4,允许 OpenAI 访问其图像、视频和音乐库等数据进行训练。作为交换,Shutterstock 也获得了 OpenAI 最新技术的使用权,并继续将 DALL-E 的 text-to-image 的功能直接应用于 Shutterstock 平台。
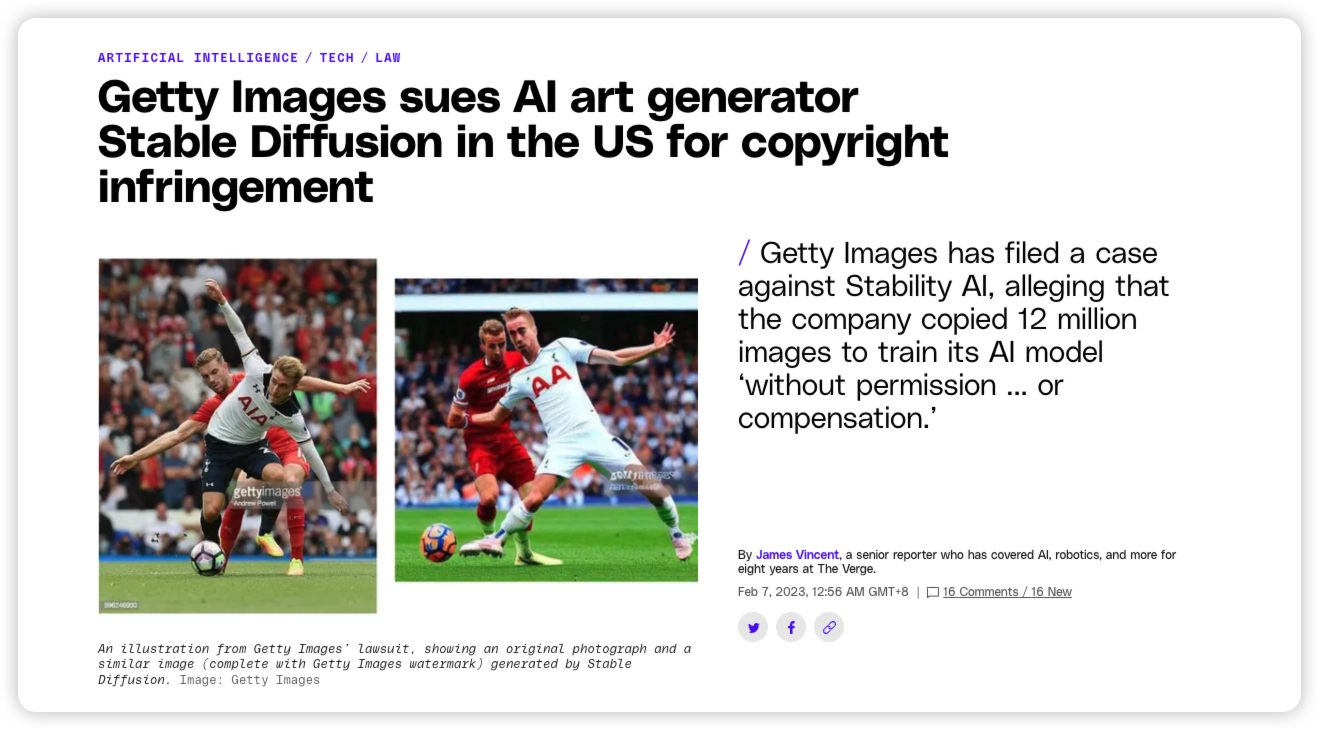
与之相反,Shutterstock 的竞争对手 Getty Images 则对 Gen AI 持强烈反对,在 2023 年 2 月对 Stability AI 发起诉讼56。
2023 年 7 月,OpenAI 和美联社(AP)签订了一项许可协议78,部分获取美联社自 1985 年以来的新闻报道。与此同时,美联社将获得 OpenAI 的技术和产品专业知识,以探索生成应用。
这一次有什么不同? 纽约时报作为具有超过 170 年历史的媒体,距今已经获得 130 项普利策奖,在美国国内和国际上都具有巨大影响力。其诉讼开篇明义,骄傲地回顾了他们在新闻媒体行业 170 多年以来的持续贡献。
Independent journalism is vital to our democracy. It is also increasingly rare and valuable. For more than 170 years, The Times has given the world deeply reported, expert, independent journalism. Times journalists go where the story is, often at great risk and cost, to inform the public about important and pressing issues. They bear witness to conflict and disasters, provide accountability for the use of power, and illuminate truths that would otherwise go unseen… This work has always been important. But within a damaged information ecosystem that is awash in unreliable content…
OpenAI 使用了来自纽约时报的语料进行训练是确定事实,纽约时报的讼状已经明确展示了这一点。


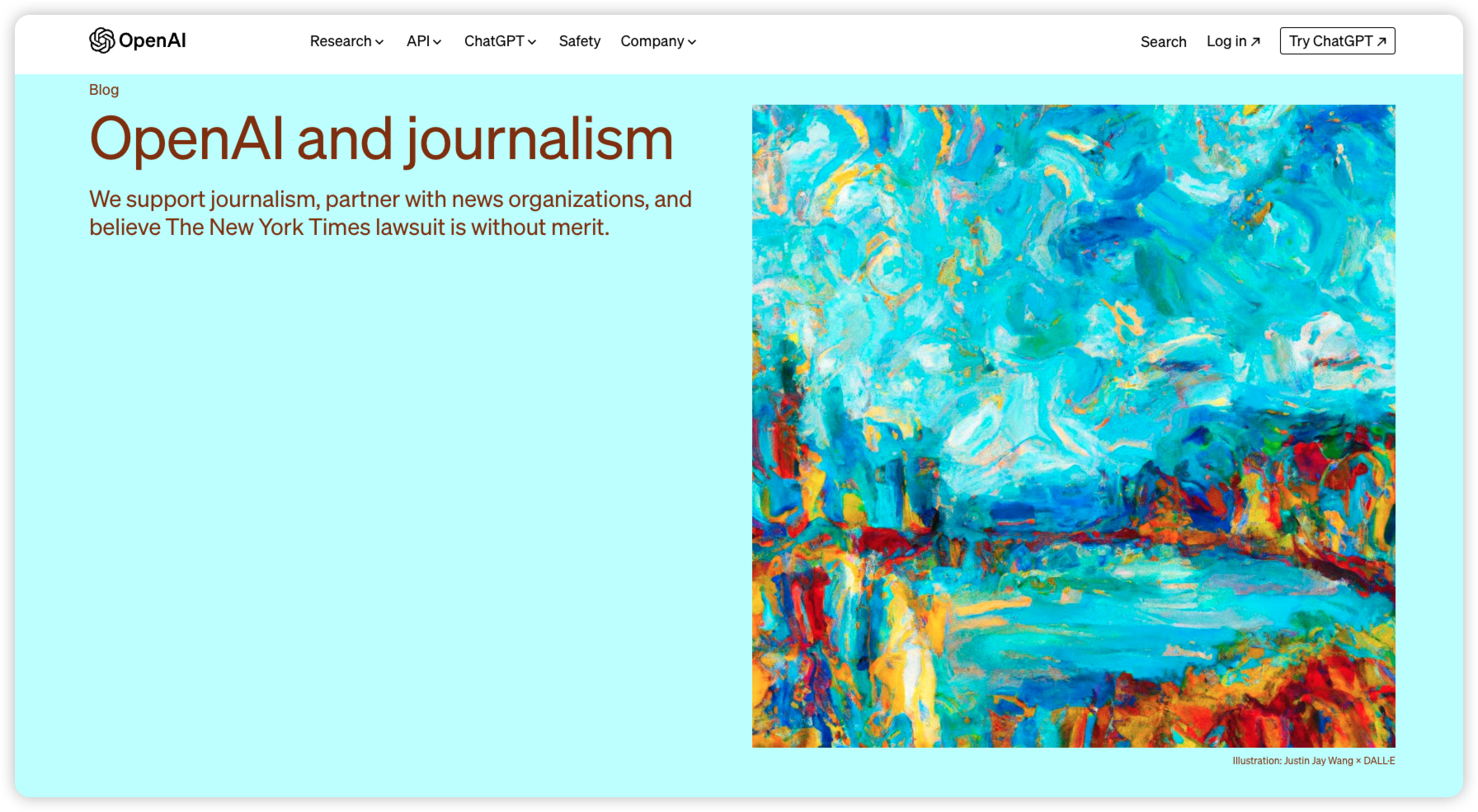
OpenAI 反驳的点在于他们的训练是为了 fair use ,并且声称 Regurgitation 反刍现在是个 bug,并且将会避免让这种问题再发生。另外,面对纽约时报占据的 Independent journalism is vital to our democracy 的道德高地,OpenAI 扛起了技术这另一个大旗,声称他们正在并且将会继续和媒体合作,而且还会通过新一代的 AI 创造新的机会9。
While we disagree with the claims in The New York Times lawsuit, we view it as an opportunity to clarify our business, our intent, and how we build our technology. Our position can be summed up in these four points, which we flesh out below:
- We collaborate with news organizations and are creating new opportunities
- Training is fair use, but we provide an opt-out because it’s the right thing to do
- “Regurgitation” is a rare bug that we are working to drive to zero
- The New York Times is not telling the full story
每当与内容相关的技术发生变革时,关于版权的争议都会产生。比如 Napster 法案之于 P2P 技术10,比如今日头条之于推荐技术,再比如目前的 OpenAI 之于 Gen AI 技术。在目前,版权是否限制训练模型还是一个悬而未决的问题,大多数国家的法律并没有解决这个问题,日本是最近的一个典型例外11。
为了减少用户对 Gen AI 相关产品使用的版权担忧,微软、Adobe、Shutterstack 等都在用户协议里面向用户保证,对使用 Gen AI 相关产品的任何版权索赔案件中,公司都将承担任何法律风险。与之类似,OpenAI 在最近的 DevDay 发布 Copyright Shield,向用户保证其免受版权问题困扰12。
OpenAI is committed to protecting our customers with built-in copyright safeguards in our systems. Today, we’re going one step further and introducing Copyright Shield—we will now step in and defend our customers, and pay the costs incurred, if you face legal claims around copyright infringement. This applies to generally available features of ChatGPT Enterprise and our developer platform.
这场诉讼仍在继续,OpenAI 也在积极与各个媒体巨头继续协商13,不知道这场诉讼是否能够给 Gen AI 的版权问题提供一种新的解决方案。
Research
Google 推出 VideoPoet,A large language model for zero-shot video generation1415
VideoPoet 的输入可以是 text,image,video 以及 audio,输出则可以是 video 和 audio,也就是说它使用多个 tokenizer(用于视频的 MAGVIT-v2 和用于音频的 SoundStream),VideoPoet 将图像、视频和音频等多种模式转换为统一的,从而可以实现各种不同的功能:
- 文本生成视频 text to video
- 图片生成视频 image to video
- 视频风格化 video stylization
- 生成音频 audio generating
- 长视频 long video
- 扩展视频
- 交互式视频编辑
- 视频修复

相对于目前在图片和视频生成领域中主流的 diffusion+u-net 架构,VideoPoet 继续基于 transformer 架构进行开发,展示了 transformer 架构在视频生成上可能具有的极大潜力。关于更多内容,也推荐阅读海外独角兽对 VideoPoet 作者蒋路老师的采访16。
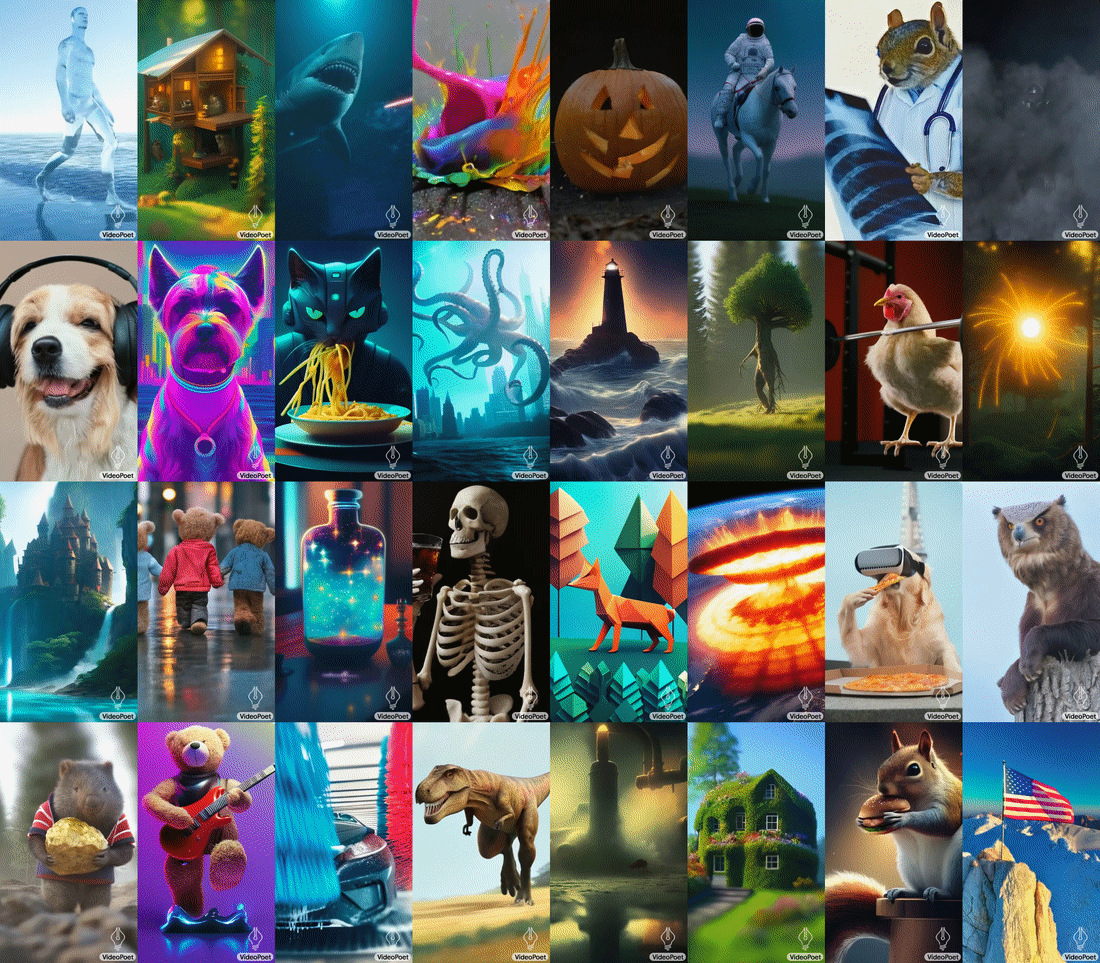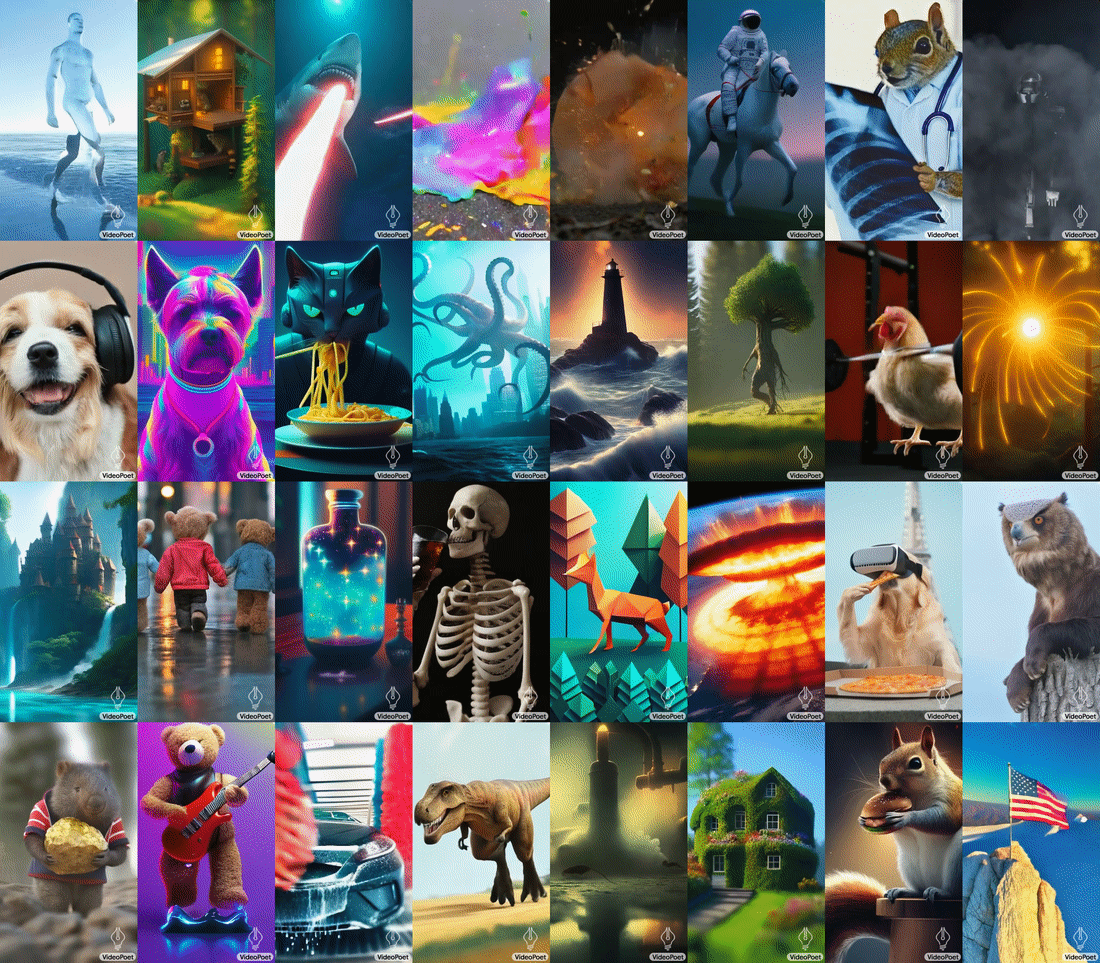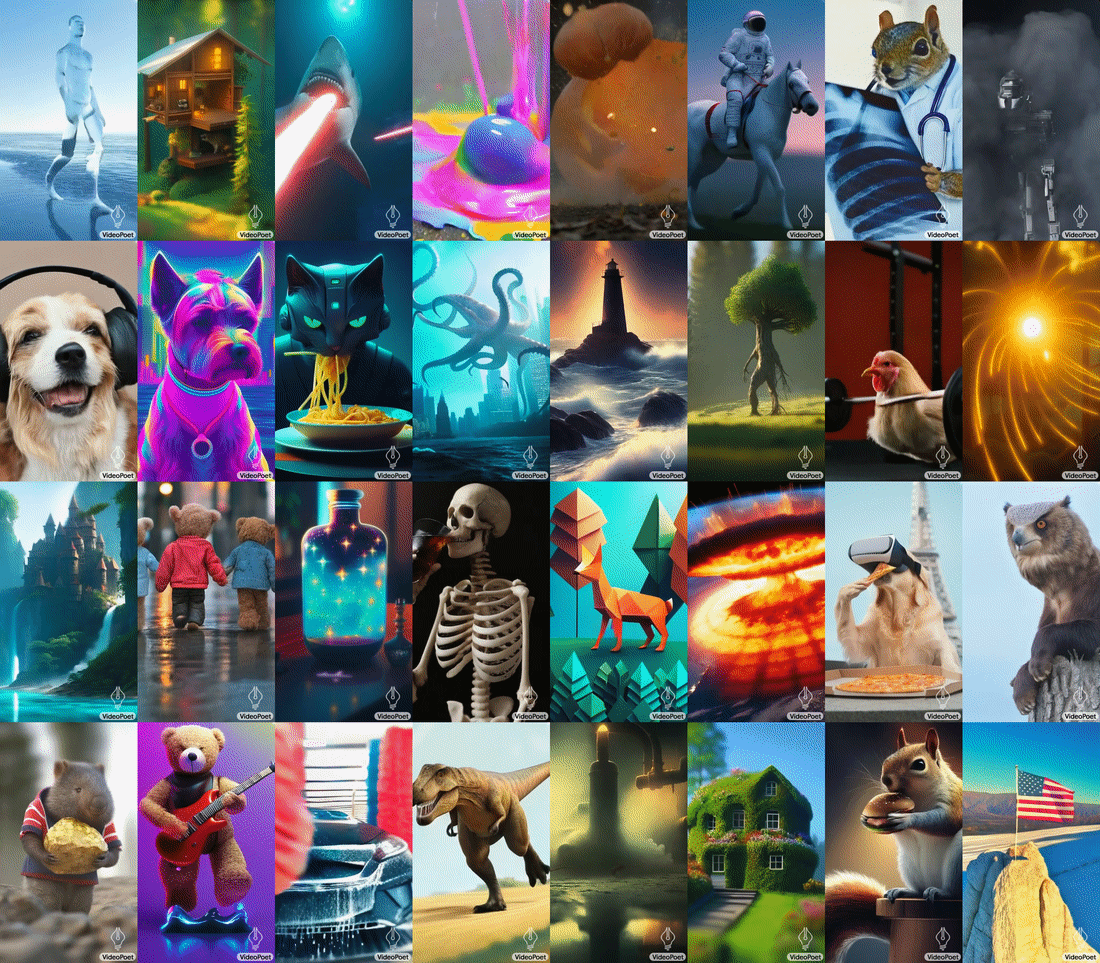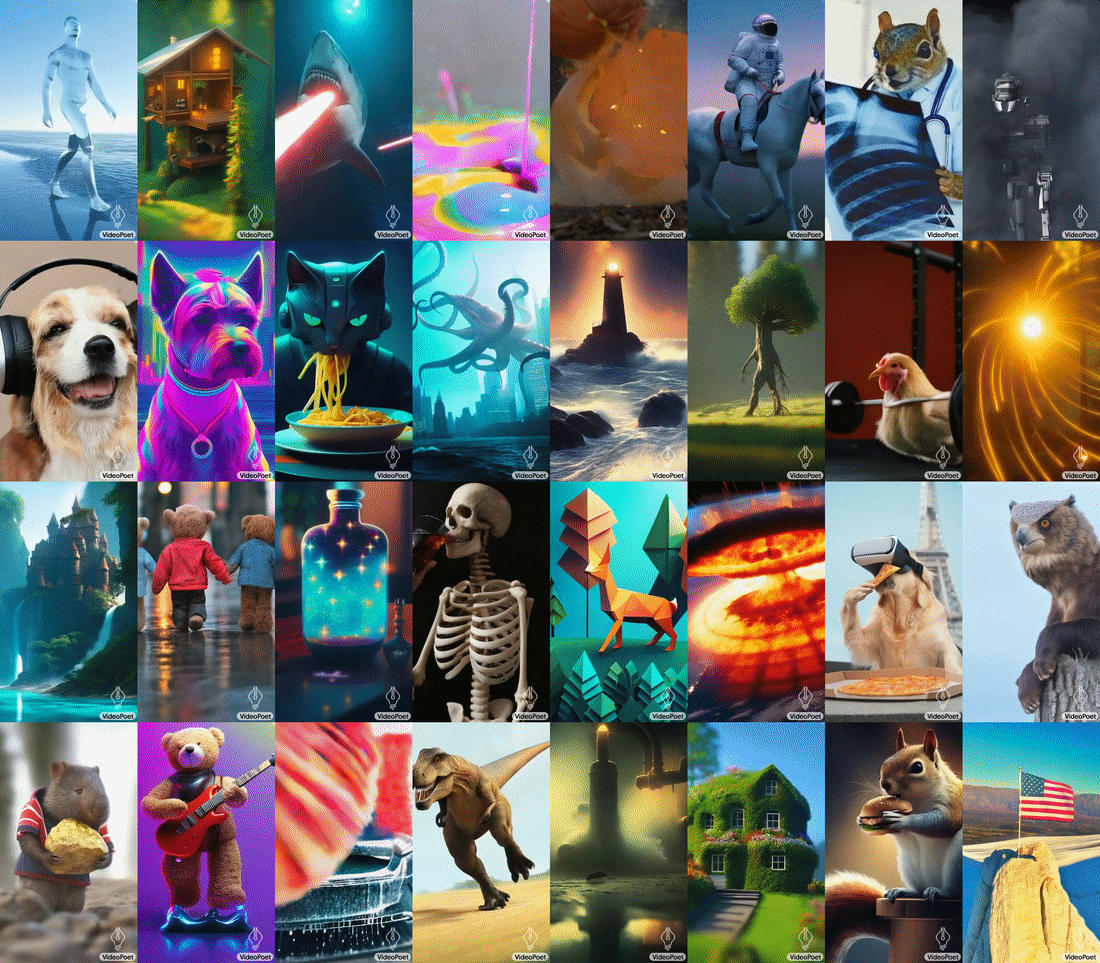
本周分享到此结束,Enjoy
-
New York Times 控告 OpenAI 原始文件, https://nytco-assets.nytimes.com/2023/12/NYT_Complaint_Dec2023.pdf ↩︎
-
https://www.theverge.com/2023/2/6/23587393/ai-art-copyright-lawsuit-getty-images-stable-diffusion ↩︎
-
https://fingfx.thomsonreuters.com/gfx/legaldocs/byvrlkmwnve/GETTY%20IMAGES%20AI%20LAWSUIT%20complaint.pdf ↩︎
-
ChatGPT-maker OpenAI signs deal with AP to license news stories, https://apnews.com/article/openai-chatgpt-associated-press-ap-f86f84c5bcc2f3b98074b38521f5f75a ↩︎
-
AP, Open AI agree to share select news content and technology in new collaboration, https://www.ap.org/press-releases/2023/ap-open-ai-agree-to-share-select-news-content-and-technology-in-new-collaboration ↩︎
-
https://www.biia.com/japan-goes-all-in-copyright-doesnt-apply-to-ai-training/ ↩︎
-
https://openai.com/blog/new-models-and-developer-products-announced-at-devday ↩︎
-
https://www.nytimes.com/2023/12/29/business/media/media-openai-chatgpt.html ↩︎
-
https://blog.research.google/2023/12/videopoet-large-language-model-for-zero.html ↩︎
-
专访 VideoPoet 作者:LLM 能带来真正的视觉智能, https://mp.weixin.qq.com/s/Hamz5XMT1tSZHKdPaCBTKg ↩︎
-
No backlinks found.