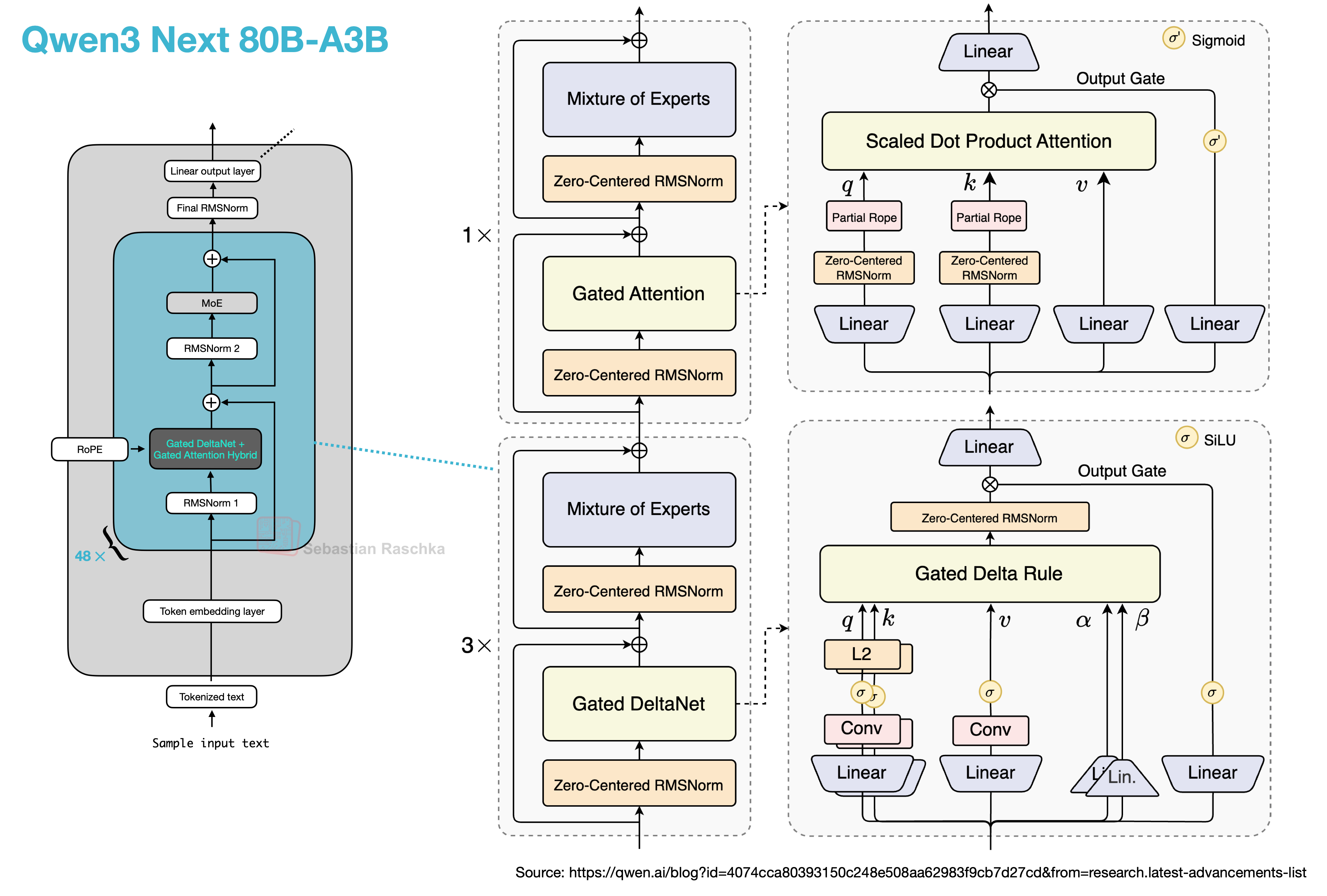
Gated Attention
当前的 Transformer 架构中,Attention 层的输出通常直接线性投影。作者提出在 Scaled Dot-Product Attention (SDPA) 的输出之后,直接加入一个 Sigmoid 门控机制。
核心收益:
- 性能提升:在 15B MoE 和 1.7B Dense 模型(训练数据达 3.5T token)上,PPL 和下游任务(MMLU, GSM8k 等)均有显著提升。
- 训练极其稳定:该机制几乎消除了训练过程中的 Loss Spikes,使得模型可以使用更大的学习率进行训练,这对于大规模模型训练至关重要。
- 消除 Attention Sink:这是个意外之喜。该机制引入了
Input-dependent sparsity,使得模型不再需要将注意力强行分配给首个 Token,从而天然地消除了 Attention Sink 现象。 - 长窗口外推能力增强:在进行长 Context 扩展(如使用 YaRN)时,Gated Attention 的表现显著优于 Baseline。
|
|
Gated Attention Layer
标准 Attention 回顾
标准的 Multi-Head Attention 计算流程通常如下:
$$Q, K, V = XW_Q, XW_K, XW_V$$
$$SDPA(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
$$Output = \text{Concat}(\text{head}_1, … , \text{head}_h)W_O$$
加入门控机制
作者尝试了在 Attention 的不同位置(Query, Key, Value, SDPA Output, Final Output)加入门控。最终发现在 SDPA 输出之后($G_1$)加入门控效果最好。
公式如下: $$Y’ = Y \odot \sigma(XW_\theta)$$ 其中:
- $Y$ 是 SDPA 的输出。
- $X$ 是当前的输入(通常是 Pre-norm 后的 hidden states)。
- $\sigma$ 是 Sigmoid 激活函数。
- $W_\theta$ 是可学习的门控参数。
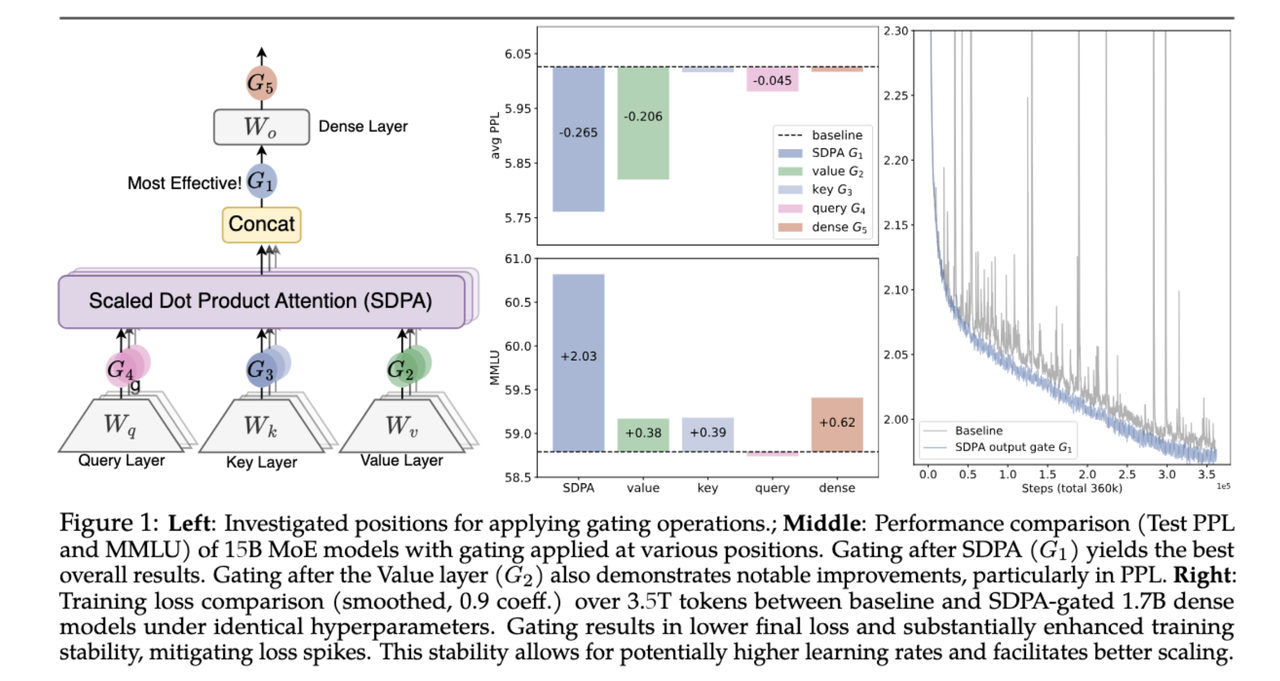
- 位置:在 SDPA 输出之后。
- 粒度:Element-wise或 Head-wise。Element-wise 效果略好,且增加参数极少。
- 激活函数:Sigmoid 优于 SiLU,因为 Sigmoid 输出在
[0, 1]之间,具有更强的“过滤”物理含义。 - Head-Specific:不同 Head 应该有独立的门控参数,而不是共享。
深度分析:为什么简单的 Gating 如此有效?
论文并没有止步于刷榜,而是花了大量篇幅分析“为什么”。这是本文最精彩的部分,Gating 如此有效主要归因于两点:非线性和稀疏性。
增加低秩映射的非线性
在标准 Attention 中,Value 投影($W_V$)和输出投影($W_O$)是两个连续的线性层。对于第 $k$ 个 Head,输出可以写成: $$o^k_t = \sum_j S^k_{tj} \cdot X_j (W_V^k W_O^k)$$ 由于 $d_k < d_{model}$,这里的 $W_V^k W_O^k$ 本质上是一个低秩的线性映射,限制了模型的表达能力。引入门控后,相当于在两个线性变换之间插入了一个非线性操作: $$o^k_t = \text{Non-Linearity-Map}\left(\sum_j S^k_{tj} \cdot X_j W_V^k\right)W_O^k$$ 这显著增加了 Attention 模块的表达能力。这也解释了为什么在 $W_O$ 之后加门控($G_5$)无效,因为它没有打破中间的线性瓶颈。
引入 Input-Dependent Sparsity
这是 Gating 区别于简单 LayerNorm 或激活函数的关键。
- Query-Dependent:门控的分数 $\sigma(XW_\theta)$ 是由当前 Token 的输入 $X$ 决定的(即 Query 端的信息)。
- 过滤机制:实验发现,训练好的门控分数大部分集中在 0 附近,具有很高的稀疏性。这意味着门控机制充当了一个“动态过滤器”,根据当前的 Query,选择性地让某些 Attention 结果通过,或者直接抑制(置零)。
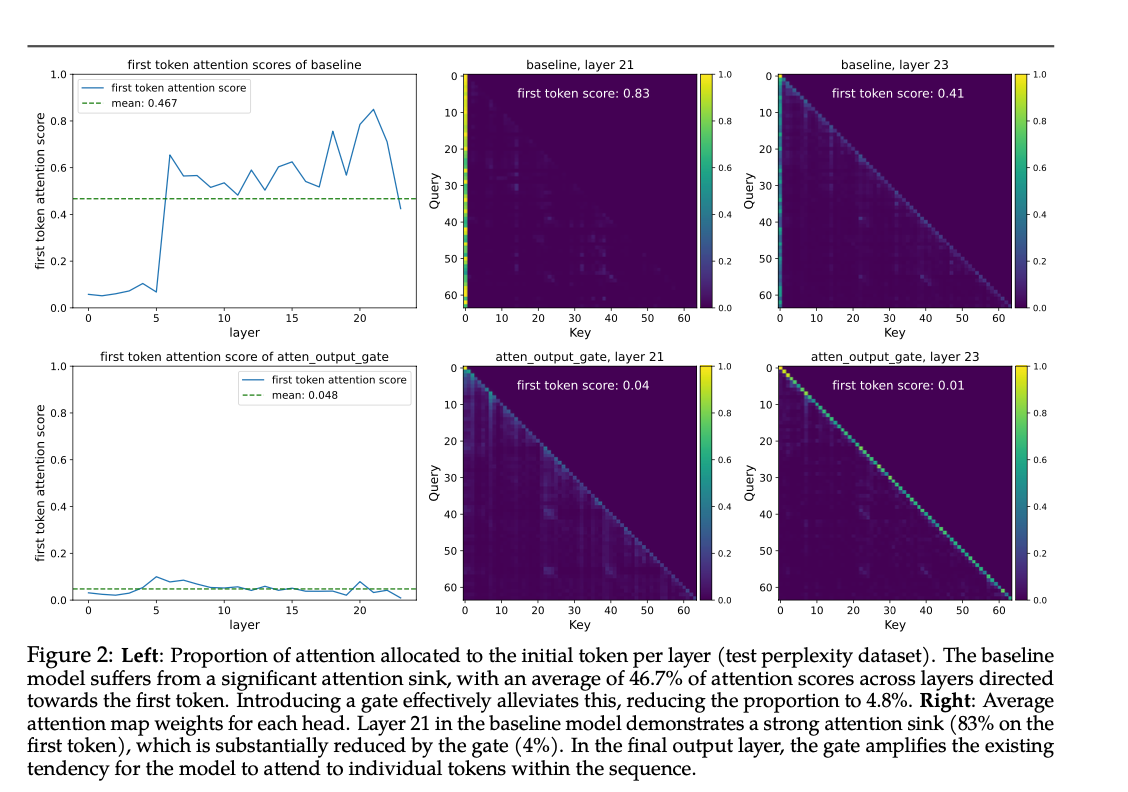
意外之喜:彻底消除 Attention Sink
什么是 Attention Sink?
由于标准 Softmax 中所有值加起来必须为1,导致在当前 Query 无法在上下文中找到相关信息(即缺乏匹配的 Key)时,模型倾向于将大量注意力分数分配给第一个 Token(作为“垃圾桶”来存放多余的注意力权重),导致第一个 Token 拥有极高的 Attention Score,这就是 Attention Sink。这不仅破坏了语义分布,也严重影响了长文本外推能力。
Gating 如何解决?
论文发现,使用了 Post-SDPA Gating 的模型,Attention Sink 现象完全消失了。
- 原因推测:因为有了 Sigmoid 门控,模型有了“拒绝”的能力。当上下文无关时,模型不需要通过 Softmax 强行找一个 Sink,而是可以通过门控将输出 乘以一个接近 0 的系数,直接阻断信息流。
- 验证:实验显示,Gated 模型的第一 Token 注意力占比从 Baseline 的 46.7% 降到了 4.8%。
消除 Massive Activations
与此同时,Gating 还显著减少了模型内部的异常大的激活值。之前的研究认为 Massive Activations 是导致 BF16 训练不稳定的元凶之一。Gating 通过稀疏化输出,天然抑制了这些异常值,解释了为什么训练稳定性得到了巨大提升。
总结
这篇论文给了我们几个非常实用的工程建议:
- 架构改进性价比极高:在 SDPA 后加一个
x * sigmoid(Linear(x))几乎不增加计算量(Latency < 2%),也不怎么增加显存,但能换来更好的 PPL 和更稳的训练。这应该成为未来 LLM 的标准组件。 - 训练稳定性的新解法:如果你在训练大模型时遇到 Loss Spike 或梯度爆炸,除了查数据和 LayerNorm,可以试试加 Gating。它从原理上减少了激活值的漂移。
- 对 Attention 机制的再思考:Softmax 的强制归一化(Sum=1)可能是一个过于强的归纳偏置。Gating 实际上赋予了 Attention 机制 “Unnormalized” 的能力(即输出的总能量可以根据 Query 的需求动态调整),这比单纯的 Softmax 更加合理。
参考资料
-
No backlinks found.