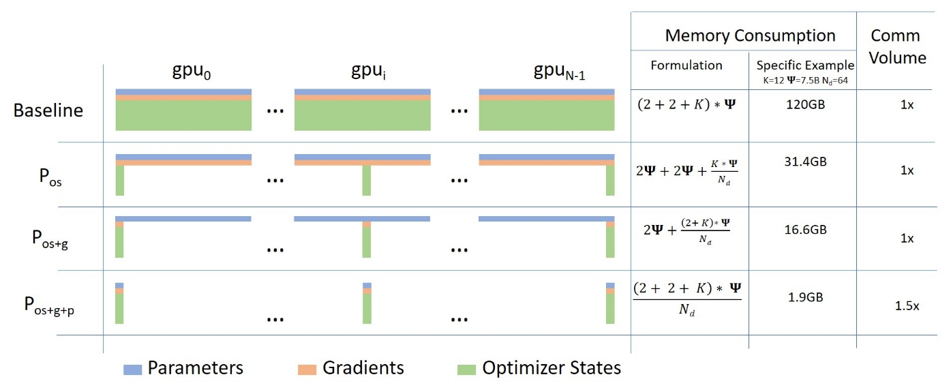
The original Fully Sharded Data Parallel (FSDP)7 is an effective implementation of ZeRO8 that offers large model training capability in PyTorch. However, the original implementation (FSDP1) in PyTorch suffers from various limitations due to its FlatParameter implementation.
Given these limitations, TorchTitan integrates a new version of Fully Sharded Data Parallel (FSDP2), which uses the per-parameter Distributed Tensor sharding representation and thus provides better composability with model parallelism techniques and other features that require the manipulation of individual parameters…
Optimizer step 中,每个 rank 根据自己的 weights 和 grad 更新本地权重
1
2
3
4
5
6
7
8
9
10
11
12
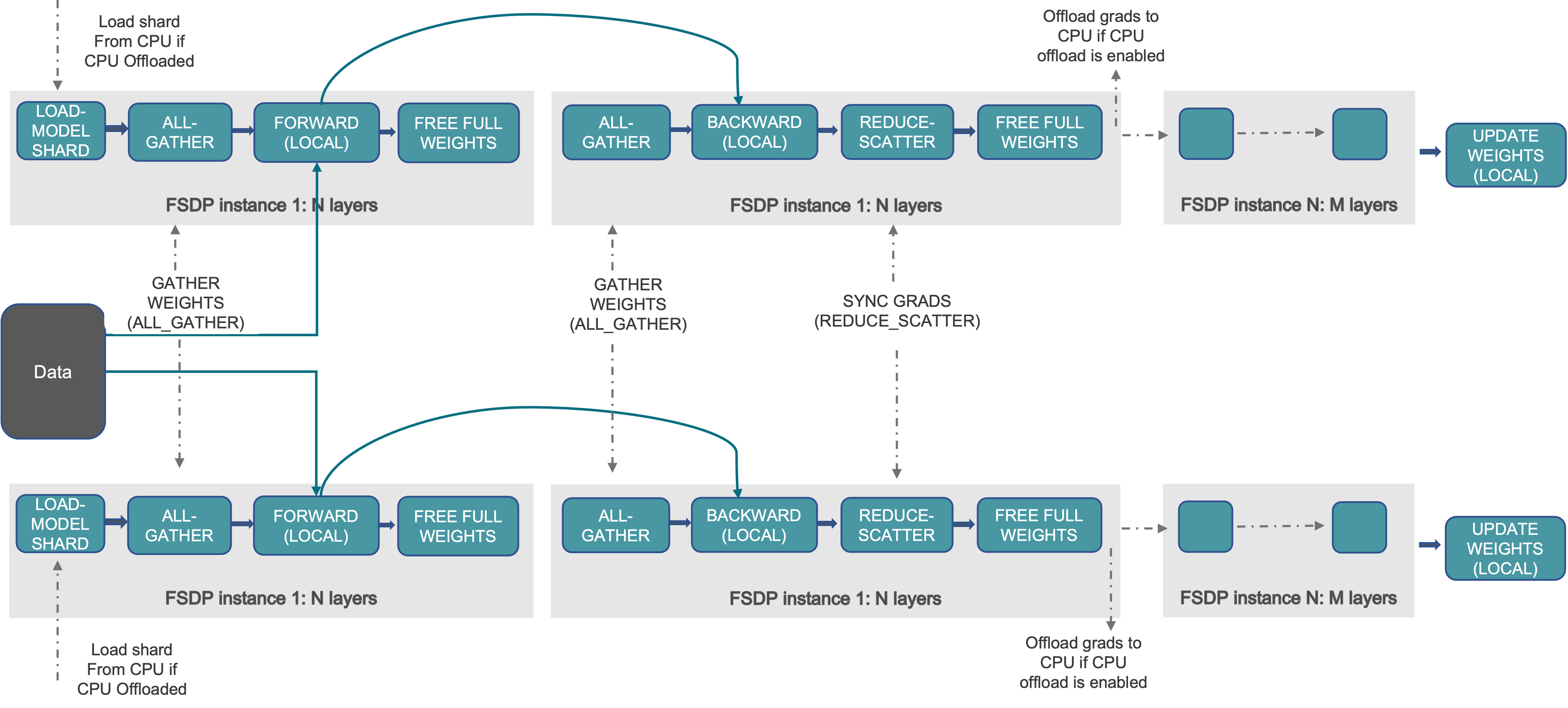
FSDP forward pass:
for fsdp_instance_i in fsdp_instances:
all-gather full weights for fsdp_instance_i
forward passfor fsdp_instance_i
discard full weights for fsdp_instance_i
FSDP backward pass:
for fsdp_instance_i in fsdp_instances:
all-gather full weights for fsdp_instance_i
backward passfor fsdp_instance_i
discard full weights for fsdp_instance_i
reduce-scatter gradients for fsdp_instance_i
Rule 1: If the user wraps fsdp_module = FullyShardedDataParallel(module) *, then every parameter inmodulenot already flattened is flattened into asinglenewFlatParameterand assigned tofsdp_module.
def_recursive_wrap(
module: nn.Module, # Module to recursively wrap. auto_wrap_policy: Callable,
wrapper_cls: Callable,
ignored_modules: Set[nn.Module],
ignored_params: Set[nn.Parameter],
only_wrap_children: bool =False,
**kwargs: Any,
) -> Tuple[nn.Module, int]:
# ...# We count all params, assuming none of them are already wrapped. nonwrapped_numel = sum(
p.numel() for p in module.parameters() if p notin ignored_params
)
if auto_wrap_policy(module=module, recurse=True, nonwrapped_numel=nonwrapped_numel):
total_wrapped_numel =0# Iterate through the children, recursively wrap if necessaryfor name, child in module.named_children():
if child in ignored_modules:
continue wrapped_child, num_wrapped_params = _recursive_wrap(
module=child,
auto_wrap_policy=auto_wrap_policy,
wrapper_cls=wrapper_cls,
ignored_modules=ignored_modules,
ignored_params=ignored_params,
**kwargs,
)
# 这里返回的是已经被 wrapped 的 module# 经过 setattr 后 child_module 已经变成 FSDP Module setattr(module, name, wrapped_child)
# Keep track of how many parameters have been wrapped total_wrapped_numel += num_wrapped_params
# decide if we need to wrap the current module,# since the left over parameters exceed the number of params to wrap remainder = nonwrapped_numel - total_wrapped_numel
ifnot only_wrap_children and auto_wrap_policy(
module=module, recurse=False, nonwrapped_numel=remainder
):
# Leaf node or final wrapping of the remainder both happen here.# 这里的 wrapper_cls 就是 FSDP class# _wrap 函数返回的就是 wrapper_cls(module, **kwargs)return _wrap(module, wrapper_cls, **kwargs), nonwrapped_numel
else:
return module, total_wrapped_numel
return module, 0
_default_stream # Default stream for computation_unshard_stream # Stream for unshard logic, including allocating the all-gather destination tensors and the all-gathers themselves_post_backward_stream # Stream for overlapping gradient reduction with the backward pass gradient computation(i.e. reduce-scatter)_pre_unshard_stream # Stream for pre-unshard logic, namely allocations and writes for CPU offloading (H2D copy) and mixed precision (low precision cast)_all_reduce_stream # Stream to run HSDP's all-reduce as async (if using HSDP)
注意,这里除了 _default_stream 之外的几个 stream 并不是 communication stream,为什么要创建这几个 stream 后面会进一步讨论。真正的 communication stream 是用的 process group 自带的 stream:
classFlatParamShardMetadata(NamedTuple):
"""
This holds metadata specific to this rank's shard of the flat parameter.
Attributes:
param_names (Tuple[str, ...]): Prefixed parameter names of this rank's
shard of the parameters; see :class:`FlatParameter`.
param_shapes (Tuple[torch.Size, ...]): Parameter shapes of this rank's
shard of the parameters; see :class:`FlatParameter`.
param_strides (Tuple[torch.Size, ...]): Parameter strides of this rank's
shard of the parameters; see :class:`FlatParameter`.
param_contiguities (Tuple[bool, ...]): Parameter `.contiguous` call results
of this rank's shard of the parameters; see :class:`FlatParameter`.
param_numels (Tuple[int, ...]): Parameter numels of this rank's shard
of the parameters; see :class:`FlatParameter`.
param_offsets (Tuple[Tuple[int, int], ...]): [start, end] offsets (in
units of numels) giving this rank's part of each flattened
original parameter.
"""
@torch.enable_grad()
def_use_unsharded_views(self, as_params: bool) ->None:
"""
Unflatten the unsharded flat parameter by setting the original parameter variables to be views into it.
""" flat_param = self.flat_param
views = self._get_unflat_views()
for i, (view, (param_name, module, _)) in enumerate(
zip(views, flat_param._param_infos)
):
# ... param_var: Tensor = view
self._setattr_tensor(module, param_name, param_var)
# ...
defupdate_process_group(self):
# create fsdp shard group and replicate group,# if world size = 8, rank_id = [0,1,2,3,4,5,6,7],# for hybrid_shard_group_size=4,# the shard group would be[[0,1,2,3],[4,5,6,7]]# and the replicate group would be [[0,4],[1,5],[2,6],[3,7]] shard_group =None replicate_group =None# create shard_group hybrid_shard_group_size = self._world_size // self._num_shard_group
for i in range(self._num_shard_group):
rank_ids = [
i * hybrid_shard_group_size + j
for j in range(hybrid_shard_group_size)
]
tmp_group = dist.new_group(
rank_ids,
backend="nccl",
)
if self._rank in rank_ids:
shard_group = tmp_group
# create replicate groupfor i in range(hybrid_shard_group_size):
rank_ids = [
i + j * hybrid_shard_group_size
for j in range(self._num_shard_group)
]
tmp_group = dist.new_group(
rank_ids,
backend="nccl",
)
if self._rank in rank_ids:
replicate_group = tmp_group
self._process_group = tuple([shard_group, replicate_group])
# 第一个维度是 replica group 的 size,第二个 group 是 sharding group 的 size# 即对应着上图的拆分方法device_mesh = init_device_mesh("cuda", (2, 8), mesh_dim_names=("replicate", "shard"))
model = FSDP(model,
#... device_mesh=device_mesh,
)
另外需要注意的是,虽然这里命名 process group 的时候按照 intra node 还是 inter node,实际上不仅仅限于 sharding group 必须在一个节点内,可以根据需要来设置,比如 1024 卡训练的时候,可以设置 device mesh 为 (8, 128),也就是在 128 卡内做 shard,然后对应的每 8 个 rank 做 replicate。这样可以在规模较大的时候比较好的降低通信的瓶颈。
FSDP1 计算与通信优化
前面我们详细介绍了 FSDP 的计算与通信流程,接下来介绍 FSDP 中的计算与通信优化。
Overlapping Communication and Computation
计算与通信 overlap 的一个简单想法就是,在当前 FSDP Unit 在做 FWD 计算的时候,提前发起下一个 FSDP Unit 的 AllGather。这样当上一个 FSDP Unit 完成 FWD 计算的时候,下一个 FSDP Unit 的参数已经准备好,可以直接开始下一个 FSDP Unit 的 FWD 计算,而不再需要等待通信的完成,保证 GPU 能一直占满。
FSDP Overlap Communication and Computation
_default_stream # Default stream for computation_unshard_stream # Stream for unshard logic, including allocating the all-gather destination tensors and the all-gathers themselves_post_backward_stream # Stream for overlapping gradient reduction with the backward pass gradient computation(i.e. reduce-scatter)_pre_unshard_stream # Stream for pre-unshard logic, namely allocations and writes for CPU offloading (H2D copy) and mixed precision (low precision cast)_all_reduce_stream # Stream to run HSDP's all-reduce as async (if using HSDP)
如 PyTorch FSDP 论文所说:
For general correctness, ProcessGroupNCCL synchronizes the internal stream with the current stream before running the collective.
// [Sync Streams] Helper that lets the input ncclStreams to wait for the current
// stream. NCCL communications run on ncclStreams, but input tensors are
// allocated on different streams (i.e., current streams). Communications on
// ncclStreams cannot start before pending input tensor ops on current streams
// finish. Otherwise, ops on two streams might read/write same tensors
// concurrently.
//
// The synchronization above alone is not enough. We also need to make sure
// input tensors are not freed before their usages on ncclStreams finish. This
// can be achieved by calling c10::cuda::CUDACachingAllocator::recordStream,
// which remembers the usage stream (ncclStream), creates an event on the usage
// stream when GC attempts to free the input tensor, and delays GC until that
// event is done.
voidsyncStream(
at::Device& device,
at::cuda::CUDAEvent& ncclEvent,
at::cuda::CUDAStream& ncclStream) {
ncclEvent.record(at::cuda::getCurrentCUDAStream(device.index()));
ncclEvent.block(ncclStream);
}
但是实际上这里下一个 FSDP Unit 的 all_gather 和当前 FSDP Unit 并没有依赖关系,只是因为目前 ProcessGroupNCCL 的实现让其必须先等当前 stream 计算完成,也就是论文里面说的 false dependency。
if forward_prefetch=True, then FSDP explicitly prefetches the next forward-pass all-gather before the current forward computation. This is only useful for CPU-bound workloads, in which case issuing the next all-gather earlier may improve overlap. This should only be used for static-graph models since the prefetching follows the first iteration’s execution order
具体的 prefetch 方式就是在当前 FSDP Unit all-gather 之后,在当前 FSDP Unit forward 之前,如下所示:
这个优化只适用于 slow cpu 的场景,并且 prefetch 也会带来更多的 GPU 显存开销,对于 LLM 场景下,大多数不需要打开这个参数。
Backward Prefetching
对于 backward,继续看下面这张图。因为 FSDP 对 all-gather 和 reduce-scatter 只用了一个 NCCL process group,这意味着 all-gather 和 reduce-scatter 只能串行执行。因此,当 current FSDP Unit 反向执行完成,需要通过 reduce-scatter 来同步梯度,然后 all-gather 来重建下一个 FSDP Unit 的参数,从而继续下一个 FSDP Unit 的反向计算。
因此,尽管计算和通信能够 overlap,但是因为反向中当前 FSDP Unit 的 reduce-scatter 和下一个 FSDP Unit 的 all-gather 只能串行,会导致下一个 FSDP Unit 必须等待,从而产生 bubble,如下图的 BWD1 执行所示。
FSDP Overlap Communication and Computation
BACKWARD_PRE:在 pre_backward_hook 执行,也就是在当前 FSDP Unit 的 backward unshard 之后,在实际计算 backward 之前执行。也就是 overlap next all-gather 和 current grad 计算,这种为 FSDP 默认值。
BACKWARD_POST:在 post_backward_hook 执行,也就是在当前 FSDP Unit backward 之后,在梯度 reduce-scatter 之前执行。这里的 all-gather 和 reduce-scatter 仍然是串行的,但是提前发起 unshard 可以让下一个 FSDP unit 提前开始计算,从而与当前 reduce-scatter overlap。
def_pre_backward_hook(
state: _FSDPState,
module: nn.Module,
handle: FlatParamHandle,
grad,
*unused: Any,
) -> Any:
# ...with torch.profiler.record_function("FullyShardedDataParallel._pre_backward_hook"):
# ... handle._training_state = HandleTrainingState.BACKWARD_PRE
if handle._needs_pre_backward_unshard:
# If the handles have been prefetched, then there is no need to# call `_unshard()` againifnot handle._prefetched:
_unshard(
state,
handle,
state._unshard_stream,
state._pre_unshard_stream,
)
# Don't wait during traceifnot torch.distributed._functional_collectives.is_torchdynamo_compiling():
state._device_handle.current_stream().wait_stream(state._unshard_stream)
# Set this to `False` to ensure that a mistargeted prefetch does not# actually unshard these handles handle._needs_pre_backward_unshard =Falsewith torch.profiler.record_function(
"FullyShardedDataParallel._pre_backward_prefetch" ):
_prefetch_handle(state, handle, _PrefetchMode.BACKWARD)
handle.prepare_gradient_for_backward()
handle._ran_pre_backward_hook =Truereturn grad
def_unshard(state: _FSDPState, handle: FlatParamHandle, unshard_stream: torch.Stream, pre_unshard_stream: torch.Stream) ->None:
# ...with state._device_handle.stream(pre_unshard_stream):
ran_pre_unshard = handle.pre_unshard()
if ran_pre_unshard:
unshard_stream.wait_stream(pre_unshard_stream)
if state.limit_all_gathers:
event = state._free_event_queue.dequeue_if_needed()
if event:
with torch.profiler.record_function(
"FullyShardedDataParallel.rate_limiter" ):
event.synchronize()
with state._device_handle.stream(unshard_stream):
handle.unshard()
handle.post_unshard()
最开始 event queue 队列为空,所以 CPU 可以直接发起前两个 all_gather 不需要等待。然后执行 CPU 执行到 reshard 的时候,记录对应的 event,等 FWD 计算中对对应 parameter 计算结束之后,对应的 event 也就结束了。因此当 CPU 执行到第三个 FSDP Unit 来的时候,因为 GPU 还没执行完,这个时候 event queue 里面有 event,CPU 必须执行 event.synchronize() 来做 CPU 阻塞。等对应的 GPU kernel 执行完毕,synchronize 结束,CPU 可以继续下发对应的 all_gather
1
2
3
4
5
6
7
8
9
10
11
12
13
def_reshard(state: _FSDPState, handle: FlatParamHandle, free_unsharded_flat_param: bool):
handle.reshard(free_unsharded_flat_param)
if state.limit_all_gathers and free_unsharded_flat_param:
ifnot torch.distributed._functional_collectives.is_torchdynamo_compiling():
# We don't run a even queue for freeing under torch compile atm# But maybe we need to? TODO(voz): Look into this free_event = state._device_handle.Event()
free_event.record()
state._free_event_queue.enqueue(free_event)
handle.post_reshard()
# Flat parameter freed or not, we always have to "unshard" the parameter# upon next access to get its shape correct. handle._prefetched =False
def_free_unsharded_flat_param(self):
self._check_sharded_strategy()
unsharded_flat_param = self._get_padded_unsharded_flat_param()
self._check_on_compute_device(unsharded_flat_param)
# Do not free the memory until all ops in the current stream finish _no_dispatch_record_stream(
unsharded_flat_param, self._device_handle.current_stream()
)
_free_storage(unsharded_flat_param)