Flux: Fast Software-based Communication Overlap on GPUs through Kernel Fusion
Background
TP 通信占比高
如下图所示,作者统计了不同训练任务、推理任务在不同 GPU 上的 TP 通信时延,可以看出,在 PCIe 设备中通信占比很高;而 H800 NVL 相比 A100 NVL 的算力提升更多,通信带宽提升较少,也就导致通信占比更高。在 PCIe 设备中 TP 通信占比甚至达到 40%-60%。

Non-overlapped communication portion within tensor parallelism in common LLM workloads for training with 2-way data, 8-way pipeline, 8-way tensor parallelism on various 128-GPU clusters, and inference with 8-way tensor parallelism on various 8-GPU clusters.
MLP 通信范式
下图展示了 MLP 示例在前向传播中的常见通信分区模式 (Megatron 风格的 TP+SP)
- TP size: N
- input: shape
[BxL/N, E] - W1: 按列切
[E, F/N] - W2: 按行切
[F/N, E]

Ring AllReduce = ReudceScatter + AllGather
对于常见的基于 Ring 的 AllReduce 实现中,通常可以把 AllReduce 操作看成为一个 ReduceScatter 和一个 AllGather 操作,如下图所示:
具体的 ReduceScatter 操作如下,每个设备(GPU)发送一部分数据给下一个设备,同时接收上一个设备的数据并累加。这个过程进行 K-1 步(假设有 K 个设备),ReduceScatter 后每个设备都包含一部分数据的 Sum:
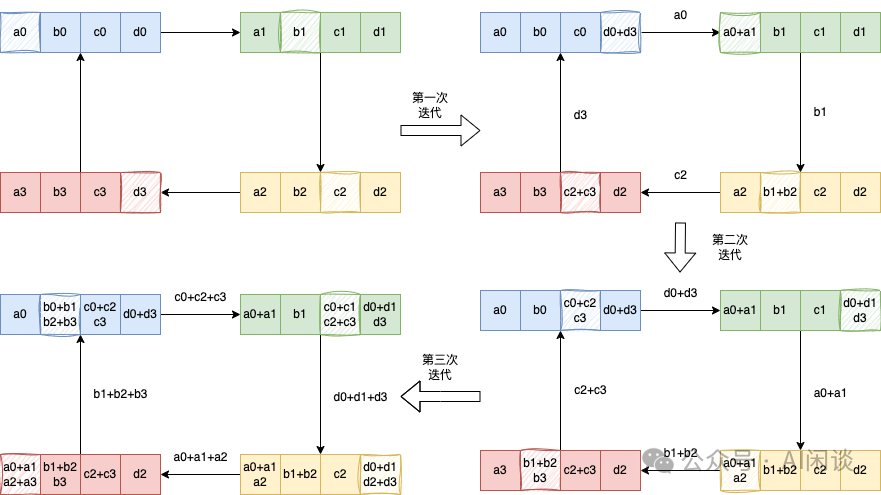
具体的 AllGather 操作如下,每个设备将其持有的部分结果发送给下一个设备,同时接收上一个设备的部分结果,逐步汇集完整的结果,同样需要 K-1 步。AllGather 后,每个设备都包含全量的数据:
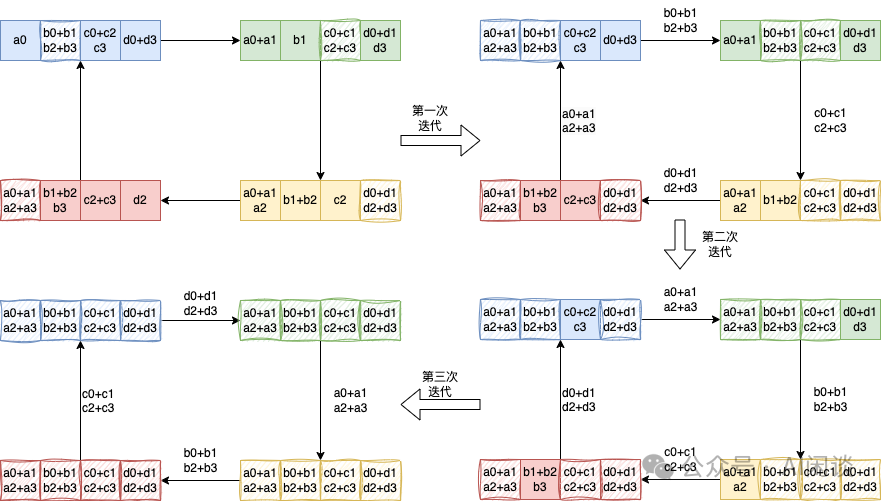
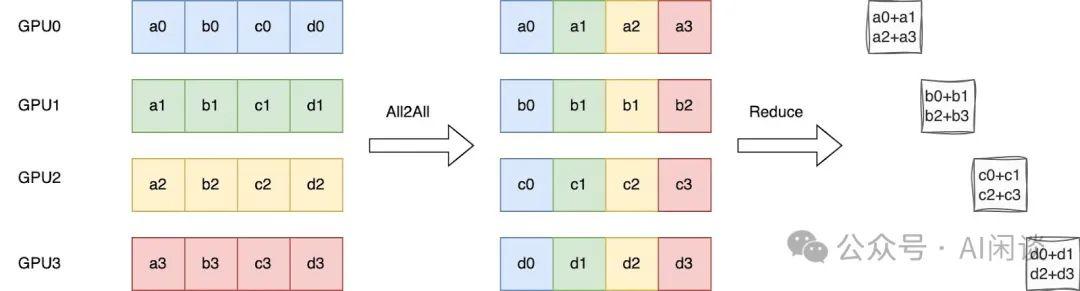
ReduceScatter = All2All + Local Reduce
如下图所示为 Ring ReduceScatter 的优化,可以等效为一个 All2All 操作实现数据的重排,然后在 Local 进行 Reduce 操作。此过程只有一个 All2All 的整体通信操作,虽然实际上与 Ring 实现的方式的通信量和计算量没有变化,但可以避免 K-1 个 Ring Step 的同步,进而可以有效降低时延。
Microsoft - CoCoNet
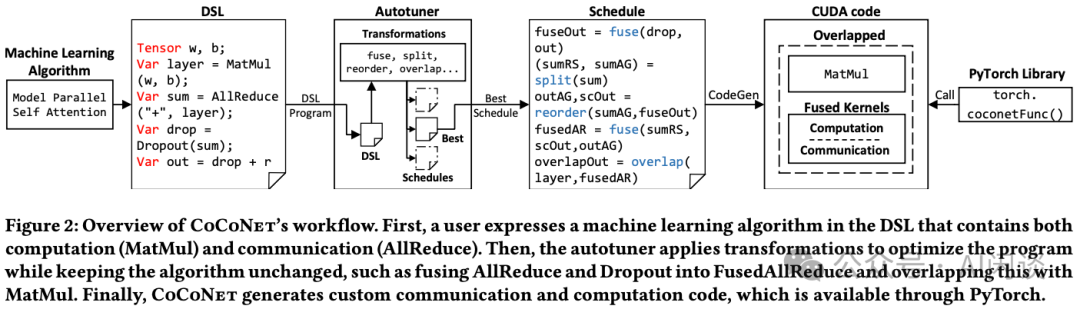
CoCoNet1 可能是最早提出异步张量并行(Async Tensor Parallelism)的工作,作者提供了一种通用 Kernel 融合的范式,能够自动生成集合通信与常见计算操作(如 GEMM 和卷积)之间的融合 Kernel。具体来说,CoCoNet 包含:
- 一种领域特定语言(DSL),用于以计算和通信操作的形式表示分布式机器学习程序。
- 一组保持语义的转换规则,以优化程序。
- 一个编译器,可以生成联合优化通信和计算的 GPU Kernel。
PS:然而,生成的代码执行效率不及直接采用 cuBlas、cutlass 或 cuDNN 中的高度优化 Kernel,主要原因在于为实现这种细粒度计算-通信 Overlap 需要在 Kernel 内引入额外同步操作。
方法
如下图 Figure 2 所示为 CoCoNet 的工作流:
- 首先,使用 DSL 表示用户的机器学习算法,该语言同时包含计算(如矩阵乘和卷积)与通信操作(如 AllReduce)。
- 然后,Autotuner 应用一系列变换以优化程序,同时确保算法逻辑保持不变。例如,将 AllReduce 与 Dropout 融合为 FusedAllReduce,并使其与矩阵乘法 Overlap。
- 最后,生成对应的通信与计算代码,并且可以通过 PyTorch 执行。
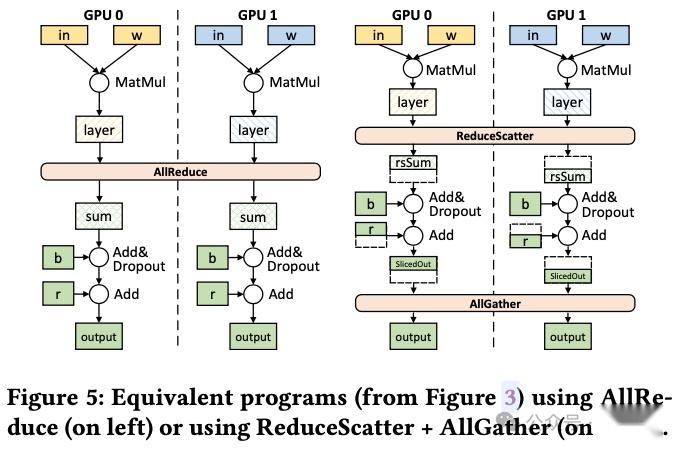
CoCoNet 提供了 4 种能够保持语义的转换方案,用于优化以 DSL 表示的程序。以下图 Figure 3 的代码为例,其主要是实现了 :矩阵乘法 + AllReduce + Dropout + Add。

具体的几个转换过程如下:
- AllReduce 拆分为 ReduceScatter(RS)和 AllGather(AG)
- 操作重排并拆分为等价算子(如下图 Figure 5):
-
scD 和 scOut 均为 Slice 切片操作。
-
agOut 用于收集计算的最终结果。
-
算子融合:
-
FushedAllReduce(FusedAR):融合了 ReduceScatter(rsSum)、计算操作(scD 和 ScOut),以及 AllGather(agOut)。
-
fusedAR.comp%28scOut%29 则指定了需要与 FusedAllReduce 融合的计算,返回的 out 则是输出结果。
-
Overlap:对一系列生产者-消费者操作,可以执行 Overlap 变换。比如有多个数据要执行上述操作(不同样本,数据的不同 Chunk),则可以实现通信与计算的 Overlap。

CoCoNet 提供了 AutoTunner,能够自动探索程序的所有调度方案的空间,并针对特定底层框架和输入规模,返回性能最佳的调度方案。
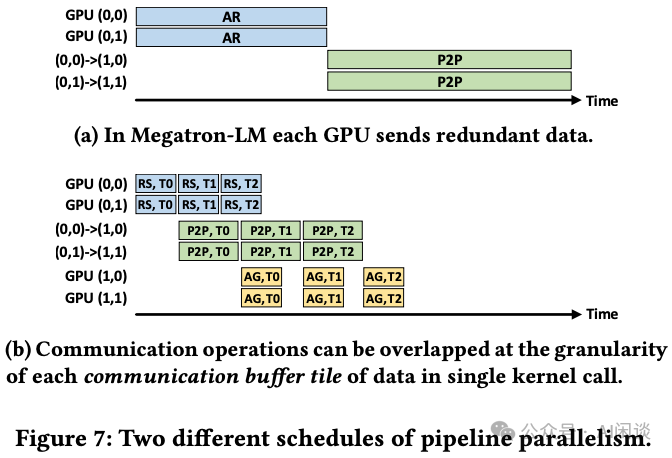
以下图 Figure 7 所示为将其应用到 Megatron-LM 中的 TP+PP 的优化案例,具体来说,总共 4 个 GPU,分成两个 PP Stage,每个 Stage 有 2 个 GPU,使用 TP 切分。比如下图 GPU%280, 1%29 表示 PP Stage 0 的 1 号 GPU。
- %28a%29:两个 PP Stage 之间会有一个 PP Stage 0 内部的 AllReduce 操作,以及一个 PP Stage 0 与 Stage 1 之间的 P2P 操作。
- %28b%29:将数据拆分为多个 Chunk,并使用 ReduceScatter + AllGather 代替 AllReduce,即可实现一定的 Overlap,并减少冗余数据传输。
结果
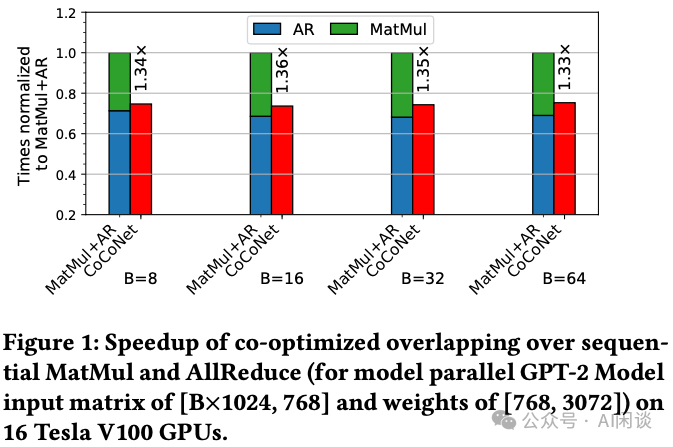
如下图 Figure 1 所示,MatMul 与 AllReduce 的细粒度 Overlap 执行可掩盖 80% 的 MatMul 执行时间,并带来 1.36x 的加速效果。
Google - Intra-layer Overlapping via Kernel Fusion
在大规模深度学习模型训练中,层内模型并行化 Intra-Layer Parallel,也就是 TP,产生的通信开销可能占据整体训练时间的显著部分,而层内模型并行化又对支持大型深度学习模型至关重要。
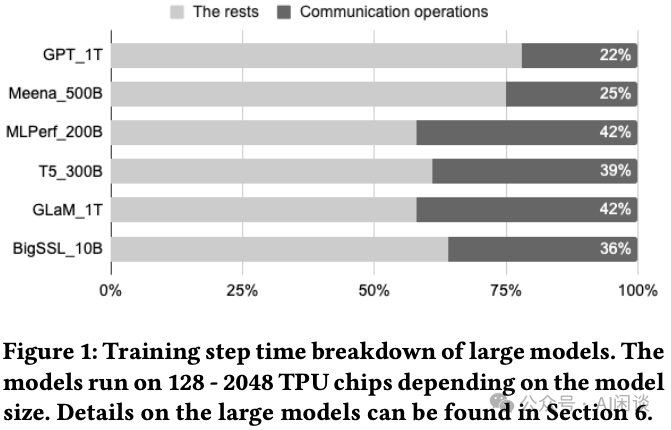
如下图 Figure 1 所示,不同规模模型在 128-2048 TPU 上训练,通信开销可达 22%-42%:
因此作者提出了一种新颖计算,通过计算与通信的 Overlap 来有效降低通信开销。
该技术将识别出的原始集合通信与依赖的计算操作分解为一系列更细粒度的操作,通过创造更多 Overlap 机会并并行执行新生成的细粒度通信与计算操作,可以有效隐藏数据传输时延,实现更优的系统利用率。
在 TPU v4 Pod 上评估不同规模的大模型(10B - 1T 参数量),所提方案可以实现 1.14x 到 1.38x 的吞吐提升。在 1024 TPU 集群中,500B 参数量语言模型训练可以实现 72% 的峰值 FLOPs 利用率。
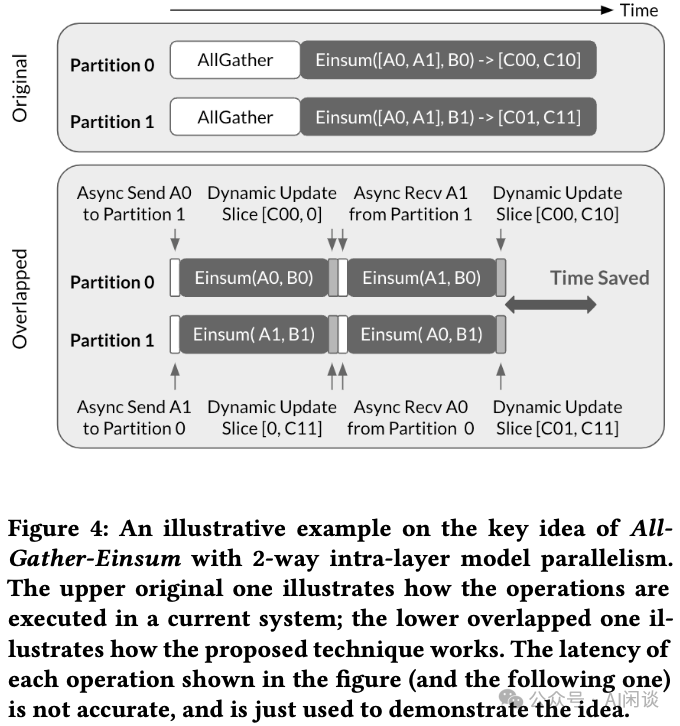
如下图 Figure 4 展示了 AllGather 场景中的执行流程。假设数据 A 在初始阶段已被切分,每个设备各持有 A 的一个分片,A0 位于设备 0,A1 位于设备 1。
- 现有系统中:两个设备均需要通过 AllGather 操作得到完整的数据 A,即
[A0, A1],然后开始相应的计算。 - 所提系统中:并不用等待全部数据准备就绪再启动计算。
- 每个设备异步发送存储在当前设备的数据到其他设备(比如设备 1 异步发送 A1 到设备 0),同时利用已有数据开始启动计算,这样设备即在计算,也在通信。
- 当之前结果计算完成,并且从其他设备接收完成(比如设备 1 的
[A1, B1]已经计算完,并且已经接收完 A0),开始启动新数据的计算(比如设备 1 上的[A0, B1])。 - 为了得到最终结果,每个部分结果需要额外执行一次 Dynamic Updata Slice 操作
- 通过执行多次上述操作可以获得最终结果,确切的步骤次数取决于 A 的切片数。
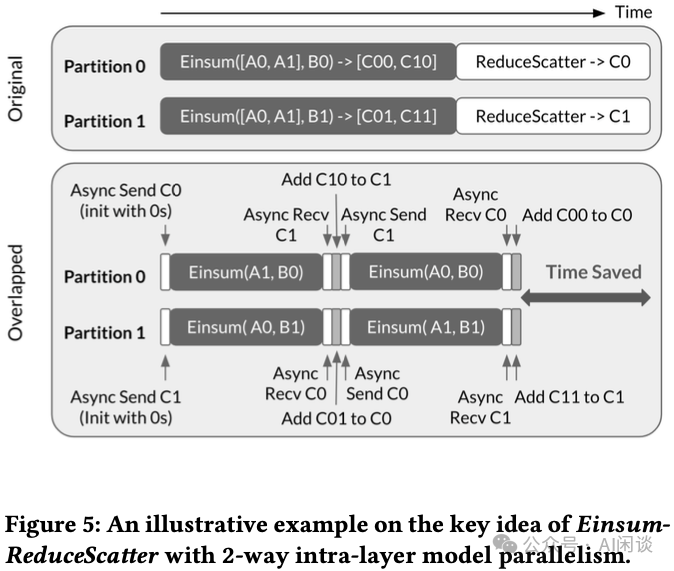
同样地,ReduceScatter 操作可与相应的计算过程 Overlap 执行,如下图 Figure 5 所示。在此例中,C0(C00 与 C01 之和)及 C1(C10 与 C11 之和)分别为 C 在设备 0 和 设备 1 上进行 ReduceScatter 后的操作分片。由于基于计算结果进行通信传输,在此情形下,各设备需要异步传输累加结果分片而非操作数,累加结果分片在各设备上初始化为 0:
- 每轮迭代开始时,各设备异步发送累加结果分片到另一个设备(例如,首轮迭代中设备 0 发送切片 C0 到设备 C1),并与此同时启动部分 Einsum 计算。
- 计算完成后,部分结果在迭代末尾被加到接收的累加结果分片,比如首轮迭代的结果 C10 与从设备 1 接收的结果分片 C1。
Kernel Fusion 是一种有效减少慢速主内存访问和 Kernel 启动开销的方案,作为最重要的优化手段之一,Kernel Fusion 在 XLA 中通过启发式方法自动执行。因此,针对本文的方案作者也会进一步应用 Kernel Fusion。
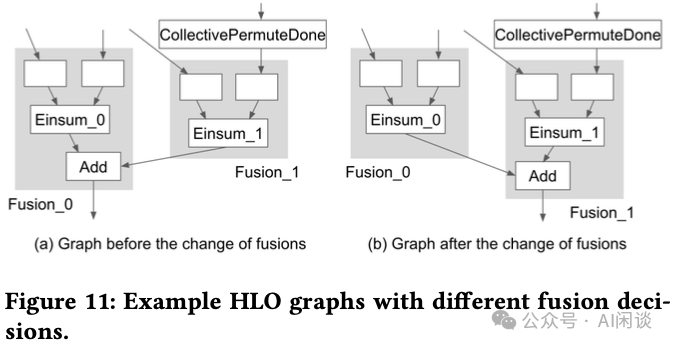
然而,基于默认启发式构建的某些融合操作可能损害 Overlap 性能。如下图 Figure 11 所示,11a 展示了一个简化的图结构,为默认的融合策略,其中的灰色方框为融合节点,白色方框表示一个或多个融合的高阶算子指令。其中两个 Einsum,Einsum_1 有一个异步的 CollectivePermuteDone 输入,由于 Einsum_0 与 CollectivePermuteDone 相互独立,预期其能与异步数据通信并行执行,以实现 Overlap。然而,与 Einsum_0 融合的加法操作在 Fusion_0 与 CollectivePermuteDone 之间引入了数据依赖,导致第三个节点顺序执行。为了避免这种不良融合,启发式策略调整为先将 Add 操作与具有异步 CollectivePermuteDone 操作的 Einsum 进行融合,新生成的图结构如图 11b 所示,数据通信得以成功与 Fusion_0 Overlap。
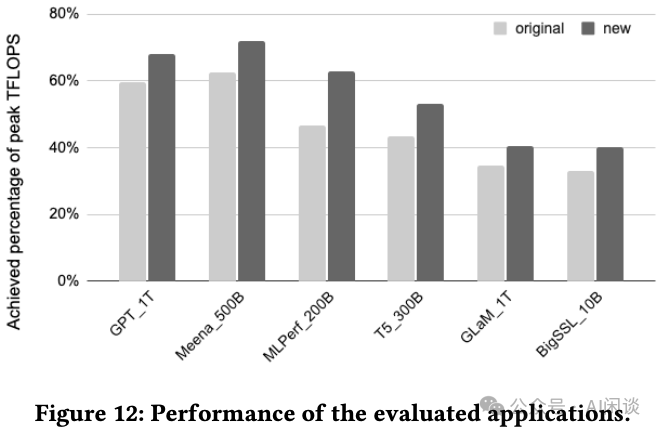
如下图 Figure 12 所示为不同模型优化前后可以达到的峰值 TFLOPS,可以看出,优化后有比较明显的提升:
北大 Centauri
高效训练 LLMs 要求采用混合并行方法,这其中克服通信瓶颈至关重要,通常通过通信与计算的 Overlap 来实现。然而,现有 Overlap 方法多侧重于细粒度 Kernel 融合或有限的算子(OP)调度,限制了异构训练环境下的性能。
本文作者提出 Centauri 框架,其构建了一个由三个固有抽象维度组成的切分空间:原语替换、拓扑感知组切分及工作负载切分。这些维度共同构成了一个全面的优化空间,用于高效 Overlap。
为确定通信与计算的高效 Overlap,作者将混合并行训练中的调度任务分解为 OP、Layer 和模型三个层次。通过这些技术,Centauri 有效 Overlap 了通信时延,提升了硬件利用率。评估结果表明,在各种并行训练配置下,Centauri 相较于主流方法可实现高达 1.49x 的加速。
方案对比
以前的工作在 Overlap 通信和计算时存在一些不足,有些框架专注于优化单一并行策略的调度,未能有效应对混合并行方法中的复杂 Overlap 挑战。值得注意的是,即便在 Forward 和 Backward 过程中,最优的 Overlap 模式也可能存在差异。
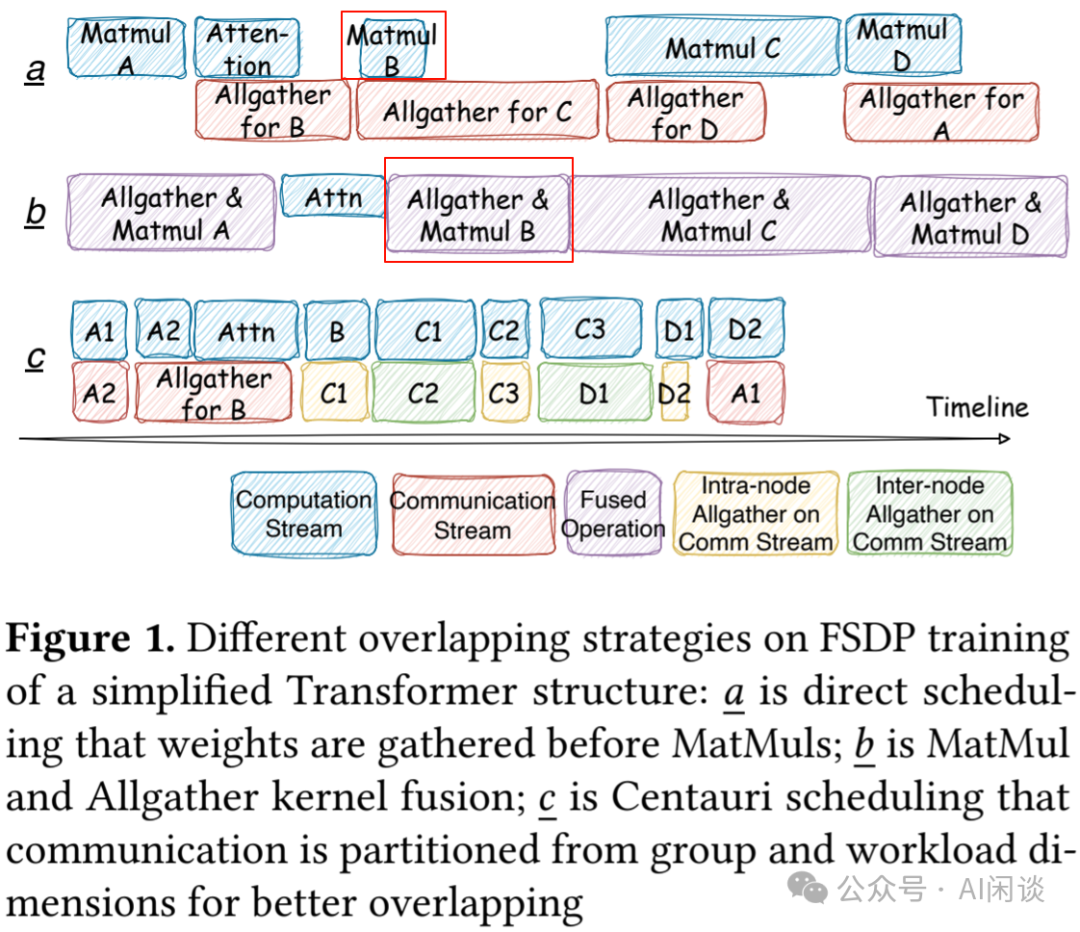
- 如下图 Figure 1a 所示,其依赖粗粒度方式进行 Graph 级别的 Overlap,可能未能充分利用 GPU 硬件资源。
- 如下图 Figure 1b 所示,有些工作依赖复杂的编译器相关工作来对集合通信及邻近计算进行切分,并在算子层面生成融合 Kernel(比如上述的 Microsoft CoCoNet)。然而,细粒度的 Kernel 融合可能忽视了更广泛的 Graph 级别的调度计算(上述 Microsoft - CoCoNet 和 Google Intra-layer Overlapping via Kernel)。比如,1b 中的 Matmul B 反而比 1a 中的 Matmul B 慢。
- 如下图 Figure 1c 所示,本文方案可以系统且全面地发掘 Overlap 空间的全部潜力,通过合理切分通信操作,能够充分扩展通信 Overlap 的优化空间。
方案概览
如下图 Figure 3 所示,Centauri 的工作流程包含两个核心环节:通信切分与层次调度。以 DP 与 FSDP 混合并行训练为例:
- 通信切分:通过考量三个基本维度,生成潜在切分空间,并为每种集合通信选择高效策略。
- 层次调度:在上述全面但较大的切分空间下,优化整图的 Overlap 调度成为一项复杂的任务,为了简化复杂的调度任务,作者将复杂的混合并行集合通信分解为三个层次,每个集合通信被分配至特定调度层级。各层级选取开销较低的切分与调度方案,旨在实现整体优化 Overlap 方案。
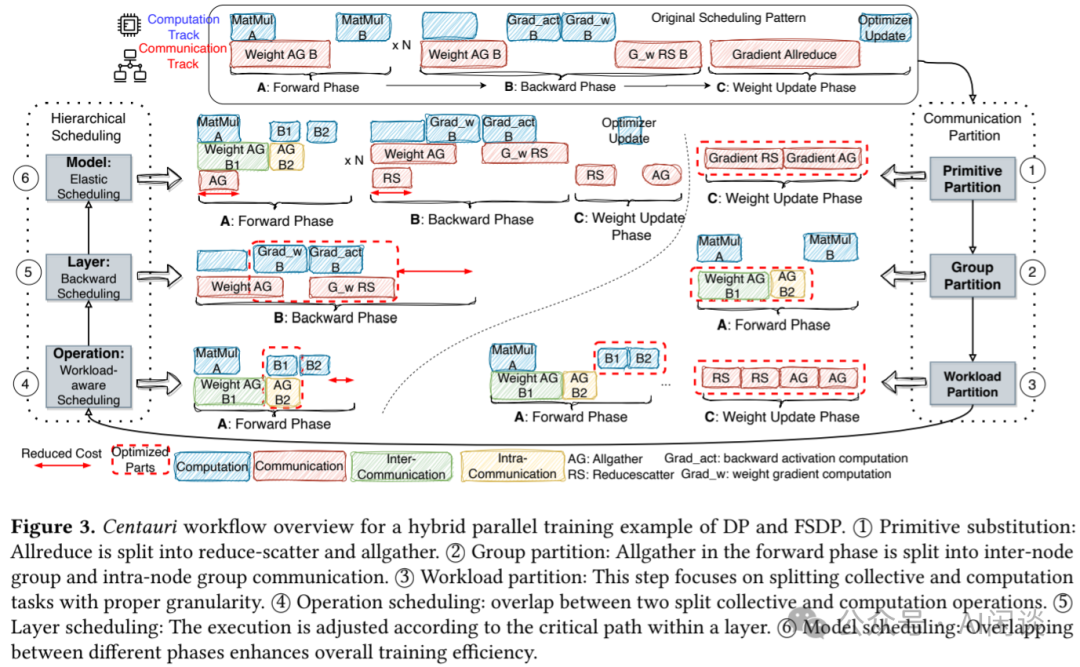
- 原语替换:将 AllReduce 拆分为 Reduce-Scatter 和 AllGather。
- 组切分:Forward 阶段中的 AllGather 被切分为节点间组和节点内组通信。具体来说,集合通信在 Rank Group G 内进行,该 Group G 可以进一步细分为若干 Sub Group { ₁, ₂, ₃, …},以实现更细粒度的通信。在组切分时,应充分考虑网络拓扑结构,比如 FSDP 或 DP 等并行方法通常涉及跨节点的集合通信,导致设备连接的异质性。在带宽不均衡的子组中,低带宽链路上的瓶颈可能抵消高带宽链路的性能优势,此外,组切分应充分利用本地连接的高带宽(比如 NVLink+NVSwitch),并尽量限制跨节点通信量。
- 任务切分:以适当粒度切分集合通信与计算任务。在给定的原始通信与组切分方案下,若通信触发的工作负载切分与其依赖的计算链之间的 Overlap 不足,则需要进一步切分计算链路。比如,FSDP 训练中,AllGather 可与随后的 MatMul 及 GeLU 和 Dropout Overlap 执行。整个计算链路的工作负载切分是各 OP 切分方案的综合结果。依赖计算链中各 OP 的切分策略会产生多种切分维度的组合,选择兼容的可行切分组合至关重要。例如,沿 Batch 维度切分的 MatMul 输出与随后沿隐藏层维度切分的逐元素加法 OP 不兼容。
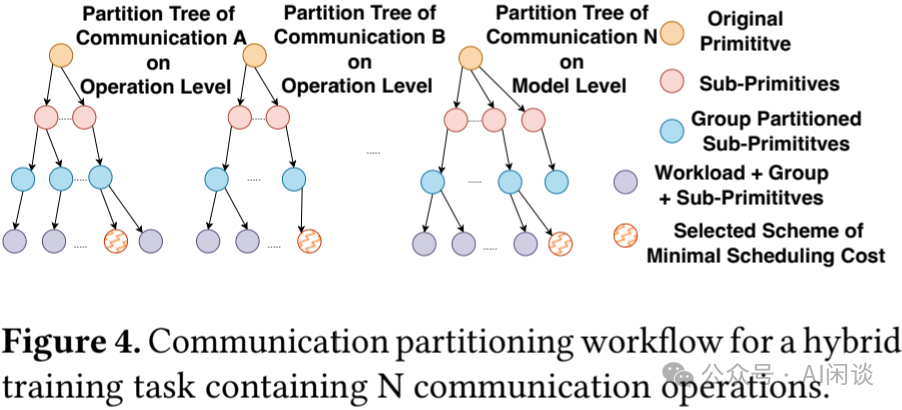
如下图 Figure 4 展示了通信切分的流程抽象,在混合训练中的每一个通信都会生成一个树形结构的切分空间,树中的每个叶节点都代表一种可行的切分方案。所选的方案旨在实现最小的调度成本,所有节点上的分区策略构成了一个庞大的切分方案森林,适用于混合训练任务。
- OP 级调度:OP 级别的细粒度调度旨在有效地 Overlap 每个 Forward Transformer Layer 内的通信和计算操作,实现两个拆分后的集合通信和计算 OP 之间的 Overlap。这个优化保证了每个 通信的 Overlap 策略是按顺序决定的,从而以贪婪的方式提高整个 Layer 的效率。
对于每个集合通信,基于各种切分模式的不同调度方案会导致不同的整体性能。
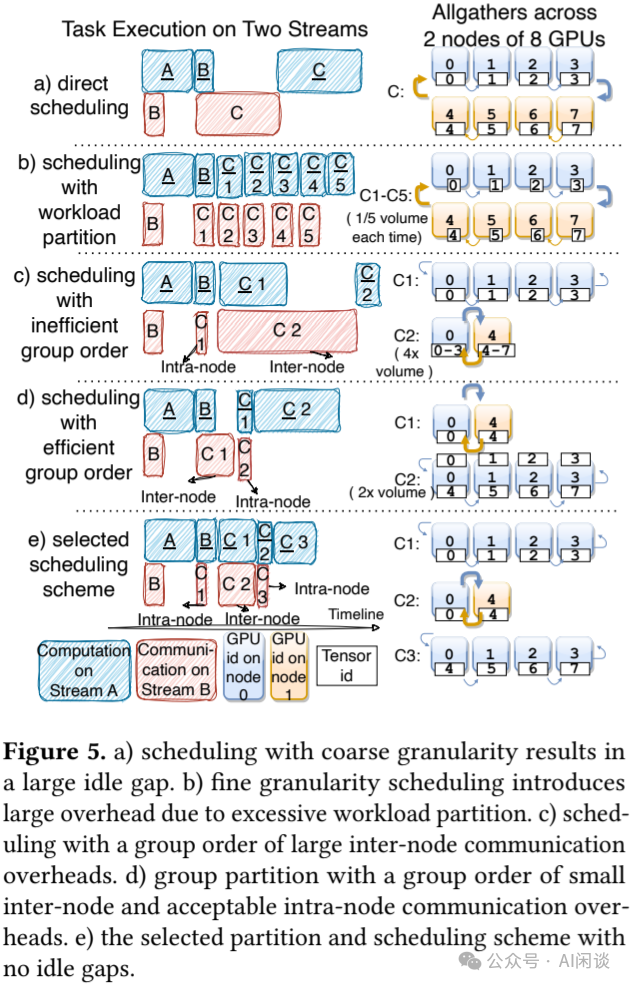
- 过于精细的工作负载切分可能会导致通信和计算几乎完全 Overlap,但由于多个小型 GPU Kernel 启动和数据移动开销,它可能会对整体性能产生负面影响,如下图 Figure 5b 所示。因此,粒度较大的策略更可取。
- 对于组切分,带宽感知调度以及节点间和节点内通信的恰当顺序至关重要,如下图 Figure 5c 和 5d 的比较所示,适当交错节点内和节点间调度方案,在下图 Figure 5e 中取得了最大的性能改进。因此,以适当的切分粒度正确交错执行节点内和节点间通信至关重要。
- Layer 级调度:根据 Layer 内关键路径调整执行顺序。
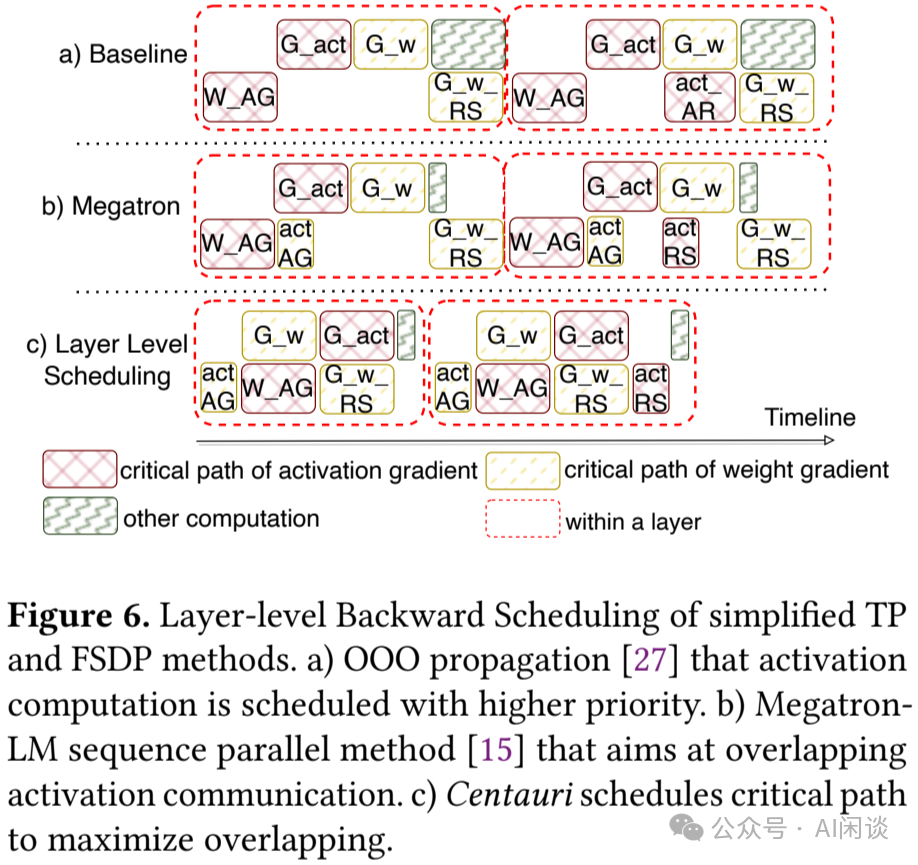
与 Forward 阶段不同,Forward 阶段的高效 Overlap 依赖于切分策略,而 Backward 则具备天然的调度空间。Backward 包含两个独立部分:激活梯度计算与权重梯度计算。
-
如下图 Figure 6a 和 6b,传统方法中,激活计算的输出作为前一 OP Backward 的输入,激活计算往往会赋予更高的调度优先级。然而,在混合并行配置中,这两部分的不同执行优先级会导致不同的时延。
-
如下图 Figure 6c,作者区分了激活梯度计算与权重梯度计算的两条关键路径,在同一个 Layer 内,通过不同调度优先级带来的成本来选择相应的最优策略。(这一部分也可以参考之前我们介绍过的 Zero Bubble)
- 模型级调度:模型级别的 Overlap 旨在隐藏梯度和权重在 Forward 和 Backward 阶段中的通信过程,提升整体训练效率。
- 在单一数据并行(DP)场景中,所有 AllGather 操作与 Forward 阶段 Overlap 进行,按块粒度方式的 ReduceScatter 操作则与 Backward 阶段 Overlap。
- 在 DP + PP 中,细粒度的流水线调度策略旨在减少流水线 Bubble,这些 Bubble 影响计算与通信的 Overlap 效果。
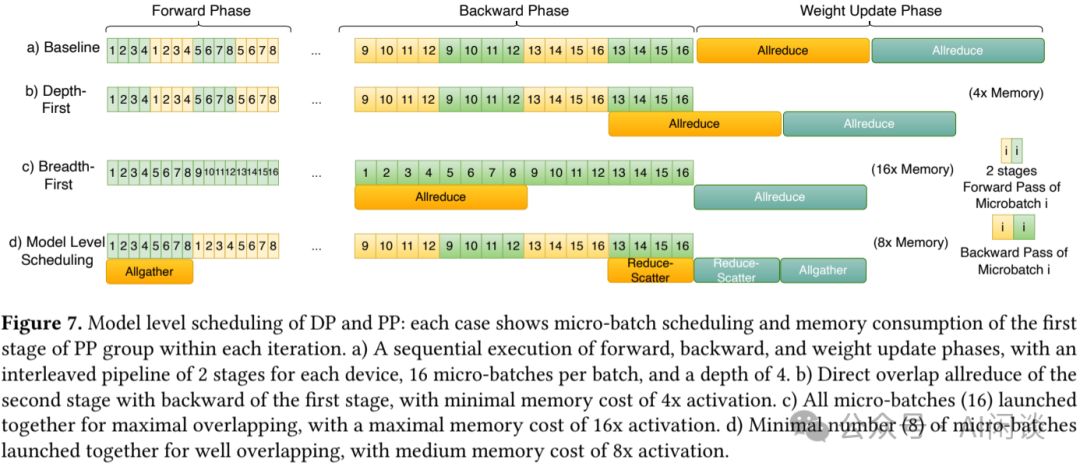
通常,Micro-Batch 的模型 Chunk 的计算开销小于相关的梯度或权重通信开销。启动多个相同模型 Chunk 的 Micro-Batch 能够释放 Overlap 的潜力,但激活内存消耗也会随着同时启动的 Micro-Batch 数量增加而增长。内存与时间成本是影响 PP 调度方案设计的两大因素。
- 如下图 Figure 7a 所示,Forward、Backward 和 Weight Update 各阶段依次执行,每个设备包含 2 个 PP Stage,每个 Batch 16 个 Micro-Batch,PP 深度为 4。
- 如下图 Figure 7b 所示,为节省内存消耗,深度优先调度选择最小数量的 Micro Batch 同时启动,数量等于流水线阶段深度,它忽略了为提升 End2End 性能而进行的 Overlap 潜力。
- 如下图 Figure 7c 所示,广度优先调度则走向另一个极端,即启动每个 Batch 中所有大小为 的 Micro-Batch 以实现 Overlap(16 个 Micro-Batch 同时启动),但伴随而来的是峰值内存消耗的显著增加。这种权衡体现在内存最小化调度与 Overlap 最大化调度之间。
- 如下图 Figure 7d 所示,AllReduce 拆分为 ReduceScatter 和 AllGather,通过优化选择最优策略,同时启动 8 个 Micro-Batch,内存消耗适中,8 倍激活量。
结果
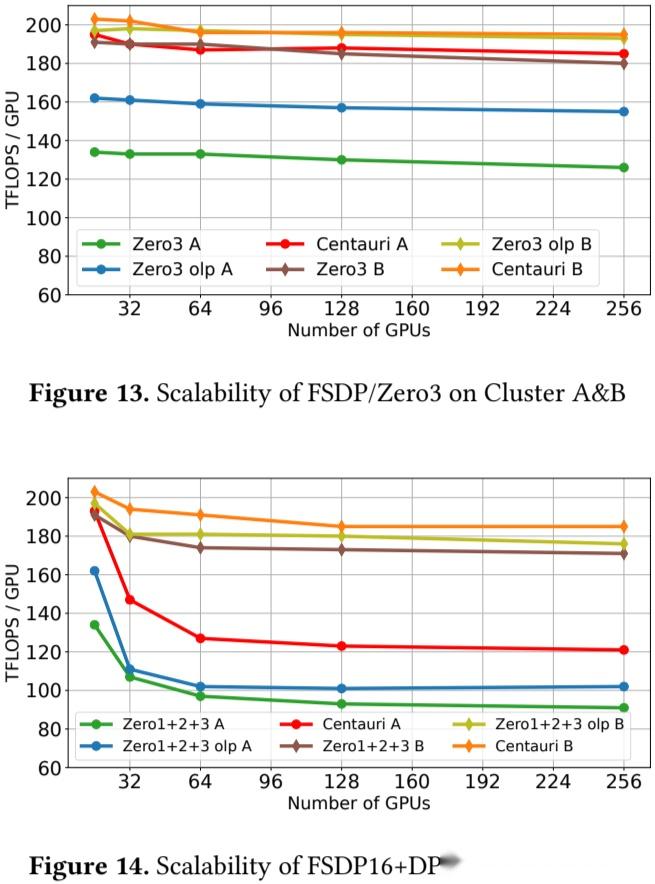
如下图 Figure 13 和 Figure 14 所示,作者在两种不同的网络环境中验证了 Centauri 的可扩展性。
- 集群 A 代表带宽受限环境,Centauri 显著提升了 FSDP/Zero3 配置对应的吞吐量。并且所达到的吞吐量水平与高性能环境(集群 B)的表现相当,突出了 Centauri 对带宽变化的不敏感性。
- 尽管在集群 B 中性能提升的潜力有限,但仍能在 256 个 GPU 上将吞吐量提高 5%。
- 在 FSDP + DP 配置中,初始阶段,由于 DP 通信开销的增加,所有 6 种配置的吞吐量均有所下降,然而,Centauri 始终能保持更高的加速比。
Flux
之前 GEMM-ReduceScatter overlapping with 2-way tensor parallelism,也就是上面讨论的 Google 方案。这种将原始计算和通信操作分解为多个块,然后通过精心调度操作来潜在地重叠通信与计算。分解中的分区数量与张量并行中的设备数量一致(或是其两倍,以更好地利用双向数据传输)。限制分区数量可以避免复杂的调度并减少可能的调度开销。图3展示了一个 ReduceScatter 重叠的场景。理想情况下,通信可以完全被 GEMM 计算隐藏。

这些方法在 TPU 上可能效果很好,但在 GPU 上效果不佳,原因在于不同的编程模型。
- 这些方法的性能严重依赖于独立分区的执行顺序、并发执行和执行时机。虽然可以通过流和事件实现 GPU 内核之间的执行顺序和并发执行,但大多数 GPU 编程模型无法轻松控制执行时机。单个操作的时间变化可能稳定可控,但在涉及 multi-stream 和事件的实际生产环境中通常变得不可预测。
- ReduceScatter Overlap 通常需要在 GEMM 操作之间执行额外的计算操作(如上图中的加法操作),这会产生数据依赖,阻止通过 GPU 多路复用并发执行多个 GEMM 内核。虽然可以进一步将加法操作与通信融合,但仍阻止多个 GEMM 内核的并发执行。
- 将一个大型 GEMM 内核拆分为多个小型 GEMM 内核,很可能导致 GPU 流处理器(SMs)未被充分利用,效率低下,无法很好的打满 GPU,特别是在张量并行扩展时。
ReduceScatter Overlapping

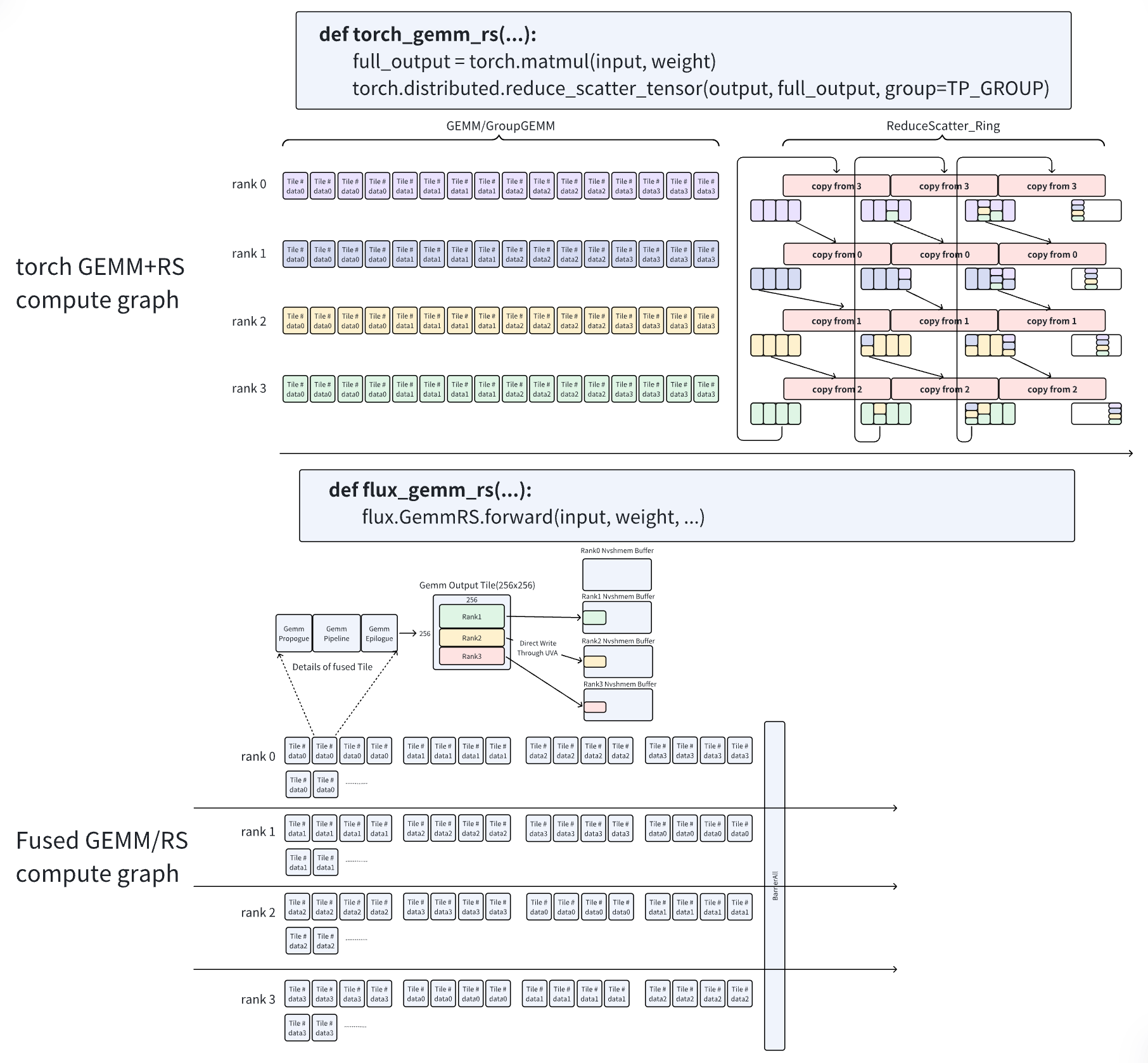
如下图展示了 ReduceScatter 中 Overlap 之间的主要差异。
现有 Overlap 方案 Tm 理论上可能比原始方法 Tc 执行得更快,但通常情况下,Tm 仍慢于原始 GEMM 操作时间 Tg。主要原因在于,将一个 GEMM Kernel 拆分为一系列较小的 GEMM Kernel 会降低 GPU GEMM 的执行效率。GEMM 通常需要合理大小的矩阵才能充分利用 GPU 的计算能力。这些具有数据依赖性的小型 GEMM 操作序列进一步阻碍了 GEMM Kernel 通过 GPU 多路复用技术并行运行,因此,Tensor 并行度越高,GPU 上的 GEMM 效率越低。

相比之下,作者提出的技术不存在上述限制。作者的 Overlap 方案 Tf 能够在极小开销下实现与原始 GEMM 操作 Tg 相当的性能。其细粒度分解策略完美契合现代 GPU 设计特性,即通过上下文切换的 Warp 和数百个在 SM 间并发活跃的 Warp 来隐藏延迟,如图中底部所示。最终,作者的方法在不影响 GEMM 计算效率的前提下,仅在执行末尾引入少量通信开销。
All-Gather Overlapping
与 ReduceScatter 不同,AllGather 的实现采用首部融合方式,直接嵌入 GEMM Kernel 中。具体而言,AllGather 的信号检查功能被融合至 GEMM 内核的前序阶段。如下图 Algorithm 2 展示了融合 AllGather 后的 GEMM 伪代码,用于计算 C = Aagg × B,其中 Aagg 是通过 AllGather 聚合的输入矩阵 A 的缓冲区,B 为另一输入矩阵,C 为输出矩阵。
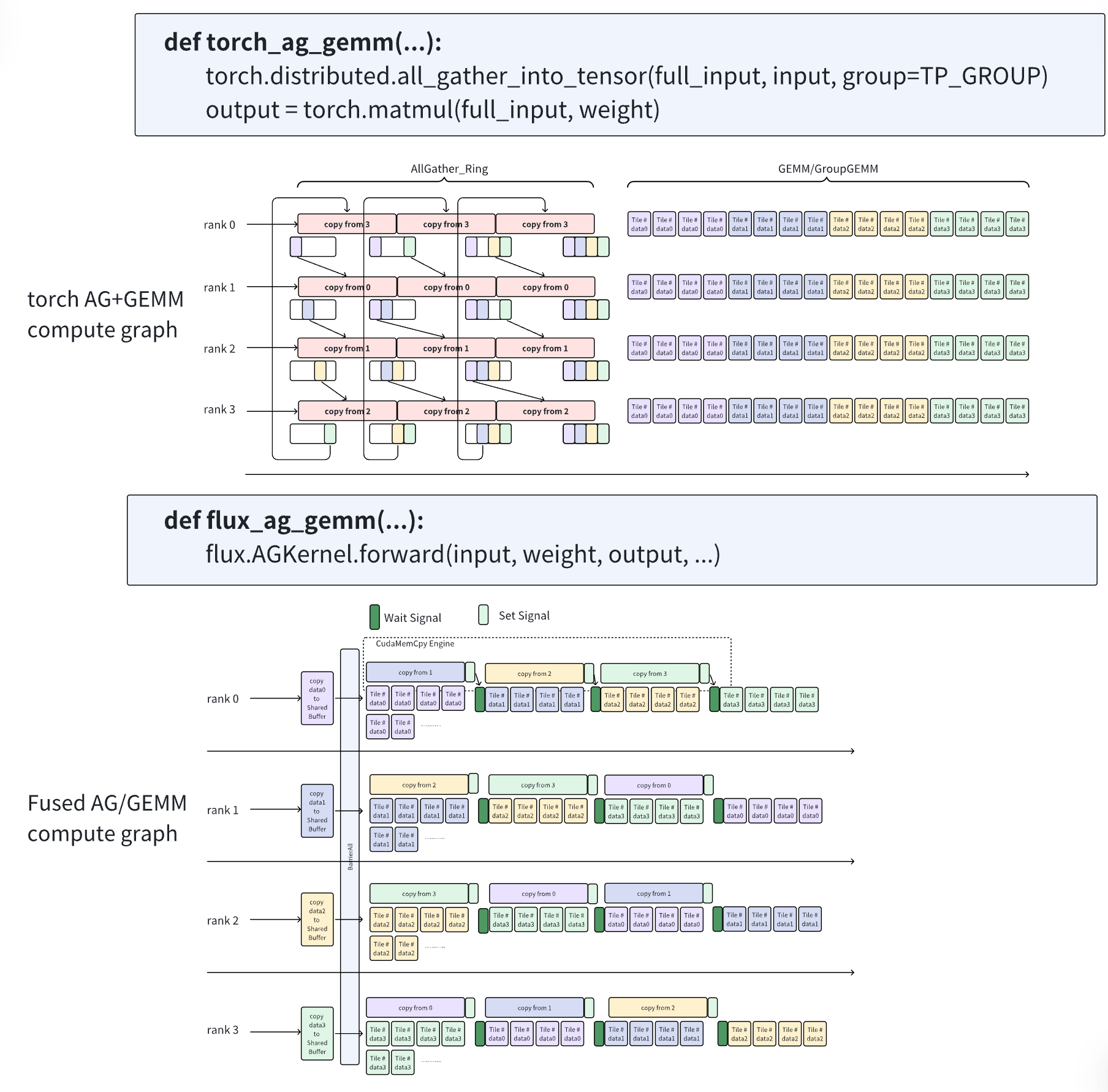
在 Kernel 端,GEMM 分块计算被函数 WaitSignal 阻塞,直至信号值被设置为真。此处,信号由 GetSignal 依据输出坐标(m 和 n)以及 TP 中的设备数量 $N_{TP}$ 从信号集合(signal_list)中选取。每个通信信号仅在主机端当对应输入 Tensor 的部分(通信分块)准备就绪时才被设置为真,即该部分已在运行融合 Kernel 的设备上接收完毕后。

如图 Algorithm 3 展示了主机端相应的通信过程:主机端(无论是基于 pull 还是 push)执行分块通信操作(DataTransfer),并异步地将相应信号(SetSignal)设置为真。
- 基于 pull 的方法通过 GetRemotePtr 函数和 GetLocalPtr 函数从远程设备 pulling 分块,从分块 A 矩阵列表(A_list)和聚合矩阵缓冲区列表(Aagg_list)中选择正确的指针,然后设置本地信号。信号由 GetSignalHost 依据通信分块索引从信号集合(signal_list)中选取。
- 基于 push 的方法则将分块推送至远程设备,随后设置远程信号。
- 需注意的是,在 pull 模式下,signal_list 仅包含本地信号,而在 push 模式下,signal_list 包含远程设备的信号。这两种变体的选择被视为一个调优参数。
值得一提的是,在 AllGather 方法中,作者将通信的等待逻辑融合到 GEMM Kernel 中,而非整个通信操作。因此,AllGather 并不必然依赖 P2P 通信。同时,在 AllGather 中,通信的分块策略(tilescomm)与 GEMM 计算的分块策略相互解耦。这一设计提供了一种灵活的权衡方式,能够在不损害 GEMM 效率的前提下,选择 Overlap 机会与通信效率之间的最佳平衡。
如下图展示了 AllGather 中的各种 Overlap 技术间的关键差异。现有 Overlap 技术 Tm 虽较原始粗粒度方法 Tc 有所提速,但因 GPU GEMM 效率降低,仍逊于原始 GEMM 操作时间 Tg。而作者的 Overlap 技术 Tf 则能实现与原始 GEMM 操作 Tg 相媲美的性能。

AllGather 中长时延指令源于等待信号,此现象始于每个 Warp 的开端,因 WaitSignal 在起始阶段已融合,其时延取决于相应数据传输的到达时间。对于数据已抵达的 Tile,时延近乎为 0;而对于数据尚未就绪的 Tile,Warp 间的上下文切换可掩盖其等待时延。值得一提的是,本地 Tile 的信号始终预设为真,因此总有部分 Warp 无需等待信号。最终,作者的方法仅在执行初期引入少量通信,且未损害 GEMM 计算效率。
Torch Async TP 实现
参考 2
-
Breaking the Computation and Communication Abstraction Barrier in Distributed Machine Learning Workloads ↩︎
-
https://discuss.pytorch.org/t/distributed-w-torchtitan-introducing-async-tensor-parallelism-in-pytorch/209487 ↩︎
-
No backlinks found.