投机解码 Eagle
通过上文关于 Speculative Decoding 和 Medusa 的介绍,EAGLE 的作者观察到两个现象:
- Token-Level 自回归解码方式的不足:在自回归生成中,使用 Token 的隐藏层特征(Feature Level)比直接使用 Token Embedding 预测 Next Token 效果更好。这是因为 Token Embedding只是文本的一个简单转化,没有经过深层网络抽取特征,表达能力不足,在使用轻量 Draft 模型时预测效果会有折损;而 Token 的隐藏层特征指最后一层 TransformerLayer 的输出,LM Head 的输入。隐藏层特征经过深层网络的计算,其表达能力要强于 Token Embedding,也更适用于采样。常规的投机推理就是 Token Level 自回归解码方式,接收率受限;
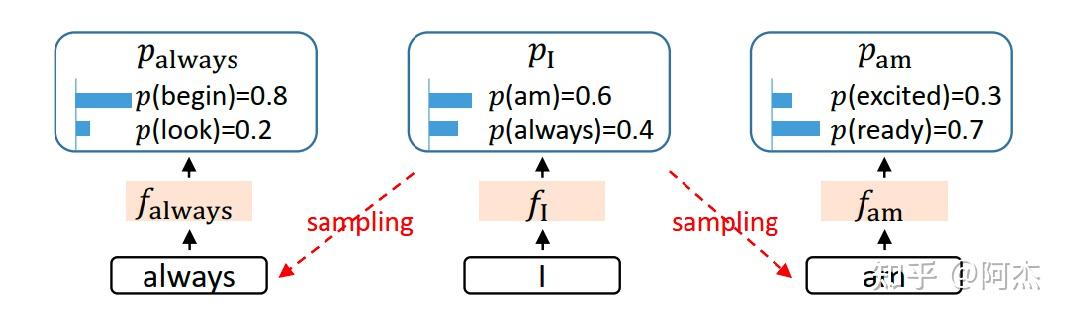
- 采样算法的不确定性会限制生成 Next Token 的隐藏层特征的效果:当前 Token 的隐藏层特征经过 LM Head 后使用采样算法随机生成 Next Token。而在 Next Token 生成 Next Next Token 过程中,需要生成 Next Token 的隐藏层特征,该特征完全由 Next Token 决定,间接由采样算法决定。采样算法具有随机性,有一定概率选择不同的 Next Token,这样使得 Next Token 的隐藏层特征也具有随机性,会影响 Next Next Token 的生成效果。如下图所示。当前 Token 为 “I”,对应的隐藏层特征为 $f_I$ ,可能会采样 “am” 和 “always”。这两个 Token 会通过模型计算得到隐藏层特征 $f_{am}$ 和 $f_{always}$。这两个隐藏层特征仅仅依赖 “am” 和 “always” 两个 Token 的 Embedding 特征,与 $f_I$ 无关,所以隐藏层特征的生成非常依赖采样算法的结果,生成效果的稳定性不足,影响接收率。Medusa 也有类似的随机问题。虽然 Medusa 采样时使用隐藏层特征,但是在生成每一个 Draft Token 时,都缺乏上一个 Token 的信息,导致生成效果也不稳定。**所以为了提高 Token 生成的稳定性,在生成当前 Token 的隐藏层特征时,可以融合当前 Token 的 Embedding 以及上一个 Token 的隐藏层特征,保证 Draft Token 生成时具备足够的信息,增强 Token 生成效果。
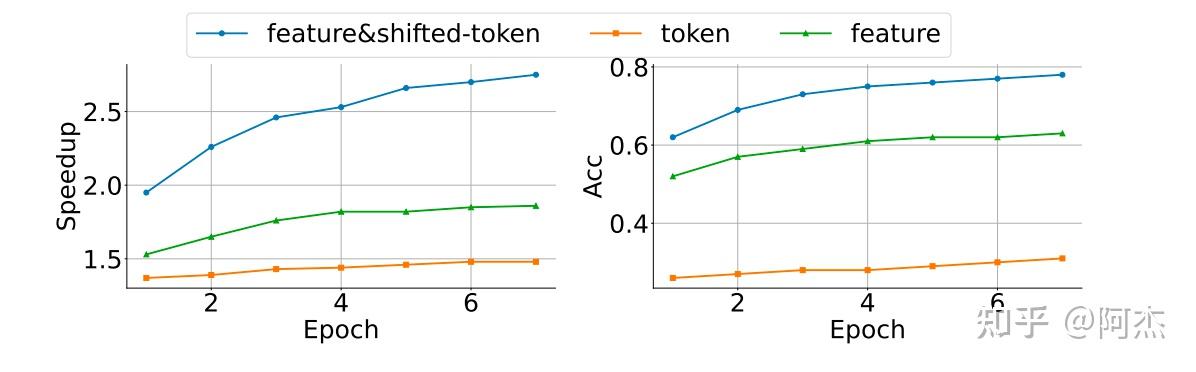
作者做了一个实验,比较了 Token-Level 以及 Feature-Level 采样算法的接收率与加速比。如下图所示。橙色曲线表示 Token-Level 采样算法,其接收率和加速比均是最低;绿色曲线表示 Feature-Level 采样算法,其接收率和加速比均比 Token-Level 采样算法要高;蓝色线表示 Feature-Level 和 Token-Level 的融合采样算法,模型的输入由当前 Token 的 Embedding 以及上一个 Token 的隐状态组成,该算法接收率和加速比均是最高,也是 EAGLE 将使用的加速算法。
方法
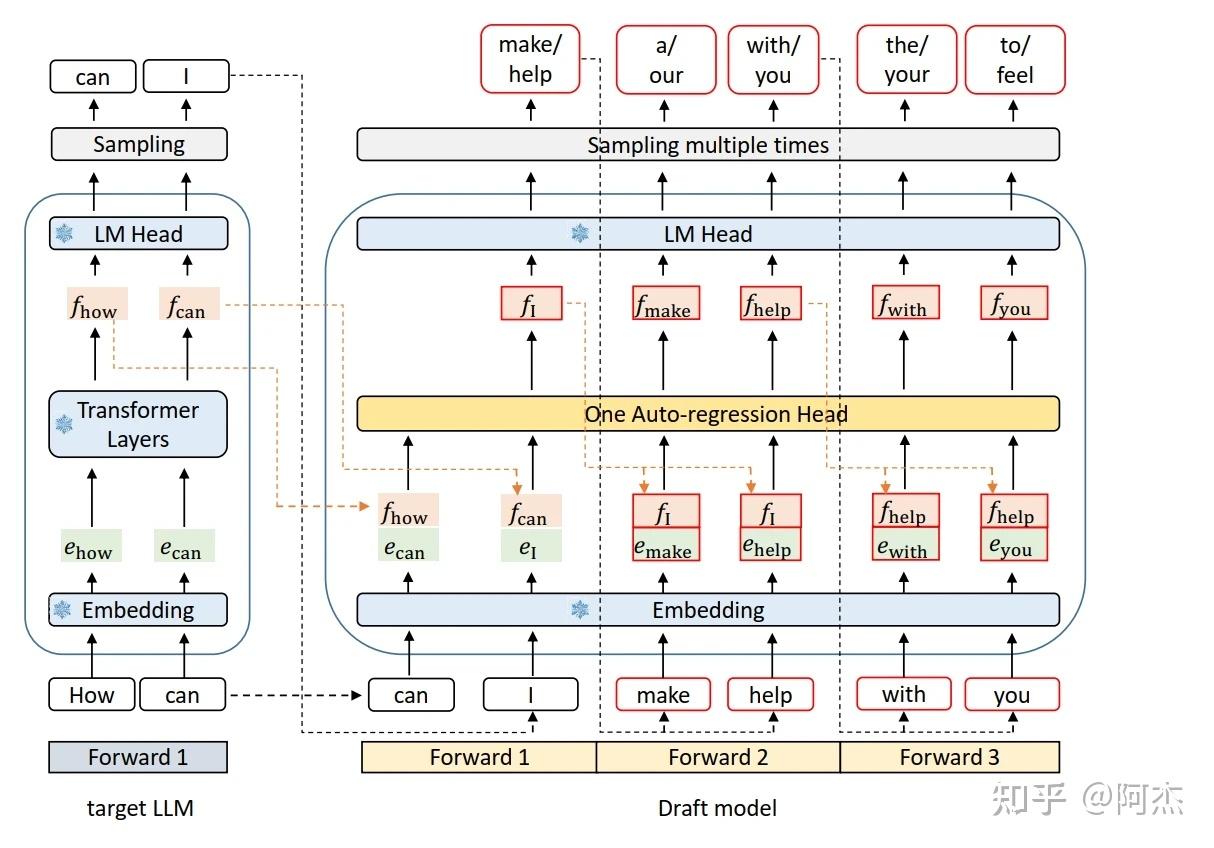
EAGLE 是一种投机采样方法,整体模型架构如下。左边是原始 LLM 模型,右边是 Draft 模型及其生成 Draft Token 的流程。Draft 模型是一个同构的轻量 LLM,其中 Embedding 层和 LM Head 层均复用原始 LLM 模型,中间的 One Auto-regression Head(简称 AR Head) 为由一层 FC 层以及一层 Transformer Layer 组成。AR Head 是唯一需要微调的网络层,训练成本也是极低。
EAGLE 使用 Draft 模型通过自回归采样方式生成 Draft Tokens,并且为了提升接收率,在运行 AR Head 前会融合上一个 Token 的隐状态与当前 Token 的 Embedding 层,并通过 AR Head 的 FC 层融合(形状从 [seqlen, hidden_size*2] 变为 [seqlen, hidden_size] )。在 Draft 阶段,自回归采样的第一轮输入是原始 LLM 模型生成的 Token,通过 TopK 采样生成第一轮的 Top K1 个 Draft Token。该 K1 个 Draft Token 作为第二轮输入,对应生成 K1 组 Draft Tokens,每组通过采样生成 K1 个 Draft Token。下一轮会从当前轮中选择若干个 Draft Token 的输出作为输入,继续自回归采样,直至到达预设的运行轮次。
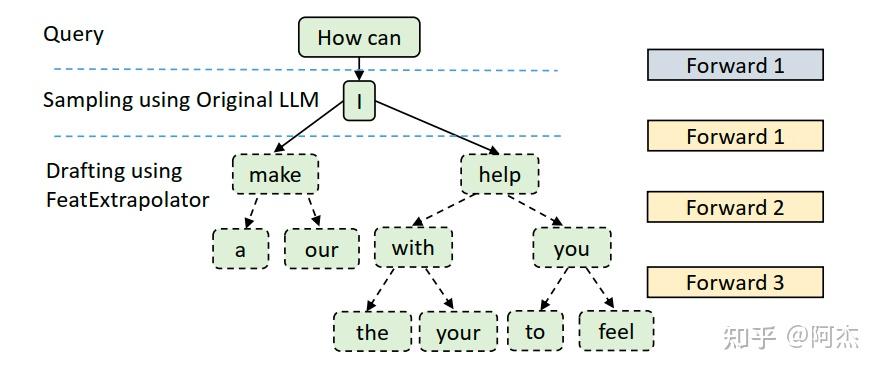
通过上述方式的 Draft 采样过程,就得到一颗 Draft 树, 如下图所示。 与 Medusa 不同的是,Draft 树并不是不同轮次的 Draft Tokens 通过笛卡尔积方式生成的,而是根据不同的 Draft Token,生成不同的Draft Token 子节点。这样的好处是:天然地去掉 Draft 树中无用的分支,使 Verify 阶段的验证序列长度大大缩小;使路径中每个节点之间的相关性更高,进一步提高接收率。
在生成 Draft 树后,Verify 阶段使用 Medusa 的 Tree Attention 进行验证,批量验证所有 Draft 路径。与 Medusa 类似,EAGLE 也使用先验的方式,提供一个静态的 Draft 树,如下图所示。对于任意输入,Draft 阶段都将按照图中所示的 Draft 树生成 Draft Tokens。
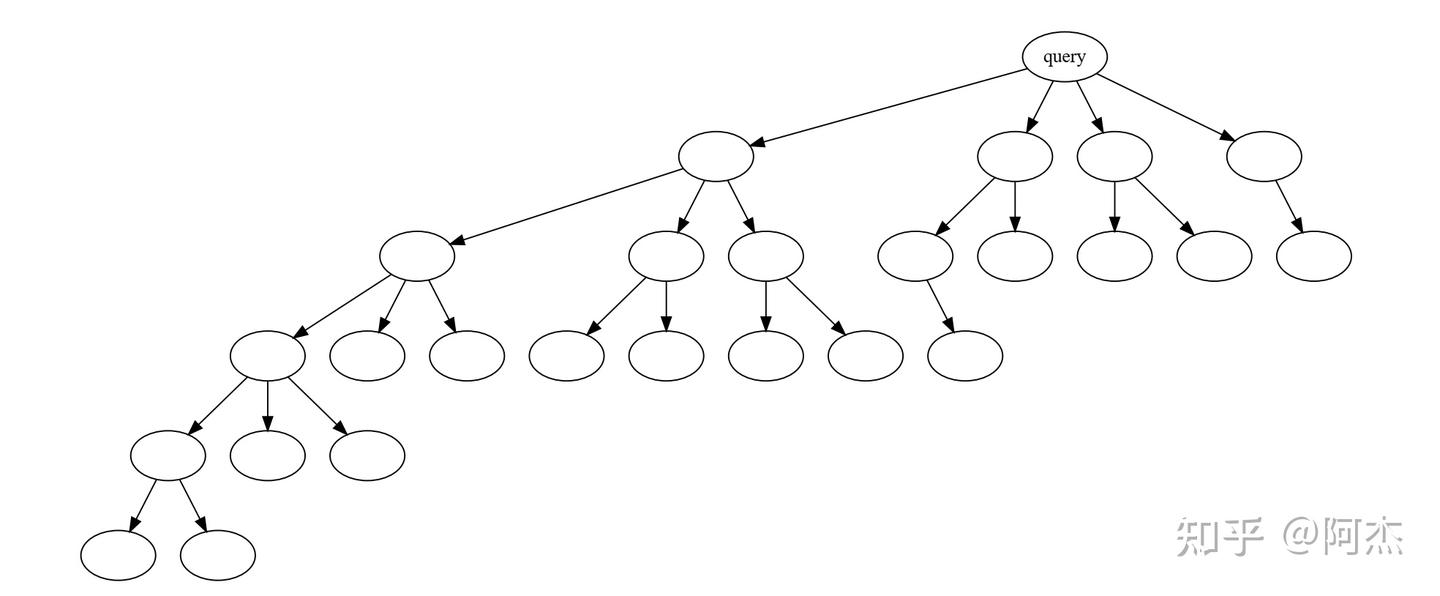
实验现象
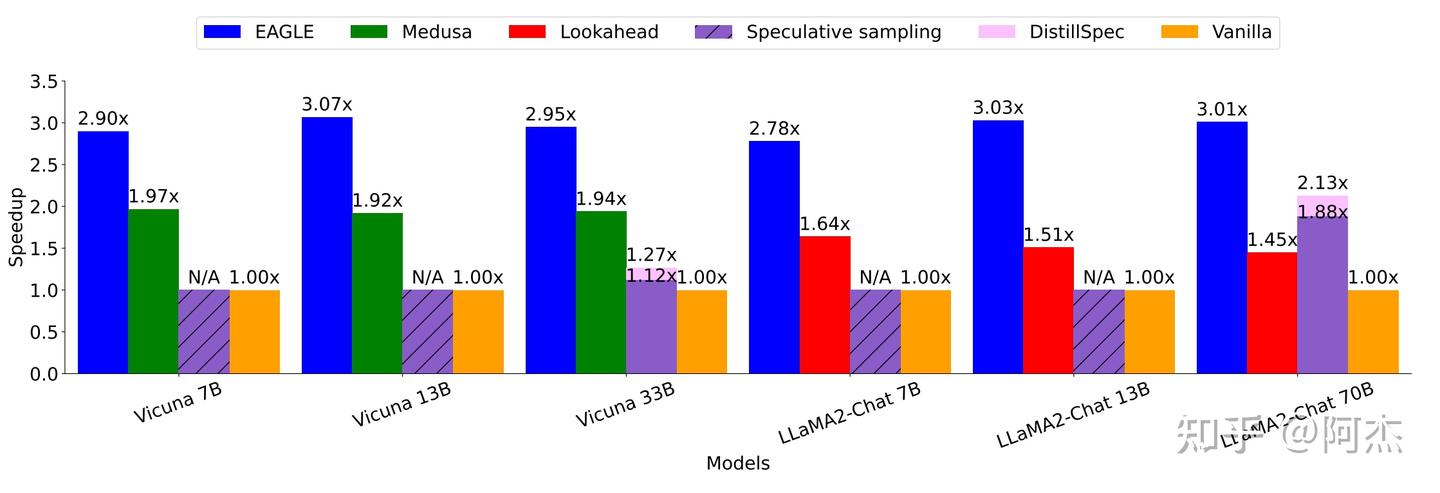
作者在 MT Bench 数据集中完成了性能测试。结果表明,EAGLE 算法在所有模型中均比现有的投机采样的加速方案更快。
结论
EAGLE 方法融合 Speculative Decoding 和 Medusa 的优点,使用 Token-Level & Feature-Level 方式进行 Draft Token 的采样,不仅提高了每个 Draft Token 的准确率(与Speculative Decoding 对比),还提高了每个节点之间的相关性(与 Medusa 对比),使接收率大大提高;并且自回归的采样方式也避免了通过笛卡尔积方式生成 Draft 树,使得验证序列的长度大大缩小,也减少了 Verify 阶段的 overhead,与 Medusa 相比提高了 Compute-Bound 的 batch size 临界点,可以在更大的流量下提升推理速度。
EAGLE 2
2个观察
EAGLE 2 在 EAGLE 1 的基础上,观察到两个现象:
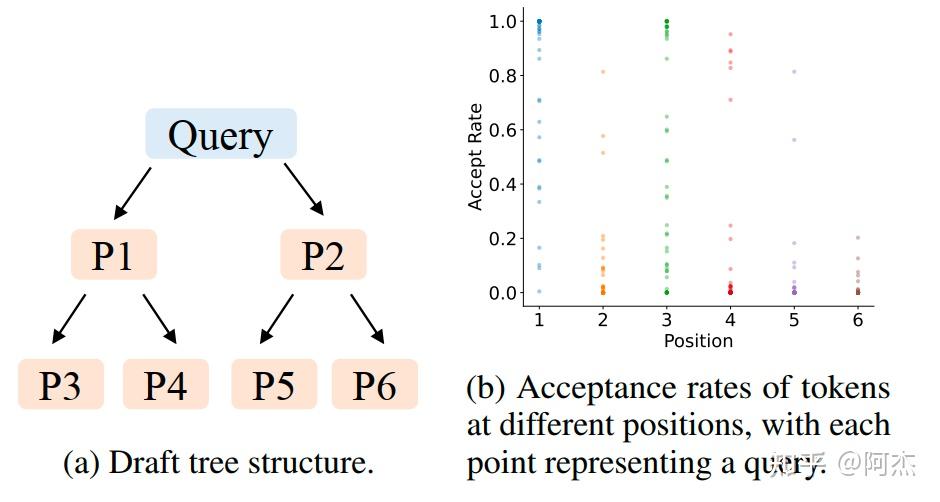
- 接受率除了与 Token 所在位置相关以外(在树中所处的位置),还和上文相关(树中的祖宗节点)。作者在 Alpaca 数据集上测试了 Vicuna 7B,记录了不同的 Draft Token 的接收概率,如下图所示。下图左侧表示 Draft 树的结构,一共有 6 个节点,分别是 P1 至 P6 节点。右侧表示不同位置的接收率。通过接收率可以观察到,树中的左上角部份接收率更高,右下角的接收率更低。P3、P4 和 P5、P6 虽然都是同一层的节点(即同一个 Step 的 Draft Tokens),但接收率上 P3、P4 普遍高于P5、P6 节点,一个重要的原因是 P3、P4 的父节点为 P1,其概率高于 P5、P6 节点的父节点 P2。P3、P4的概率甚至普遍高于 P2,这更加说明在生成 Draft 树的时候,采用静态 Draft 树并不是一个最优选择,更应该选择动态 Draft 树,选择接收率高的节点继续发展子节点。
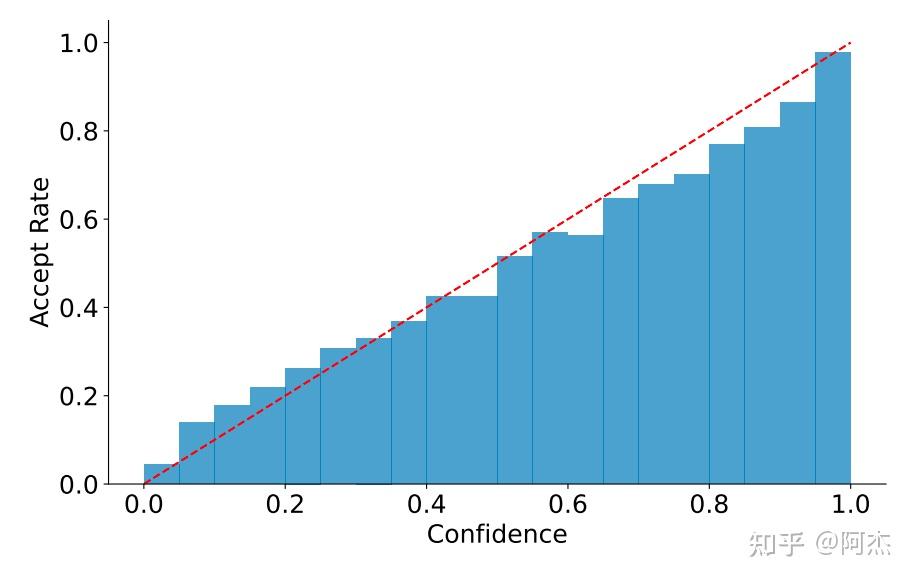
- 原始 LLM 自回归生成的 Token 概率分布表示 Token 接收概率。Eagle 的 Draft 模型生成的 Draft Tokens 概率分布与 Token 接收率分布接近。下图展示了 Draft Tokens 生成概率和 Token 接收率的分布图,可以看出分布很接近,可以通过 Draft Tokens 生成概率预估 Token 的接收率。
方法
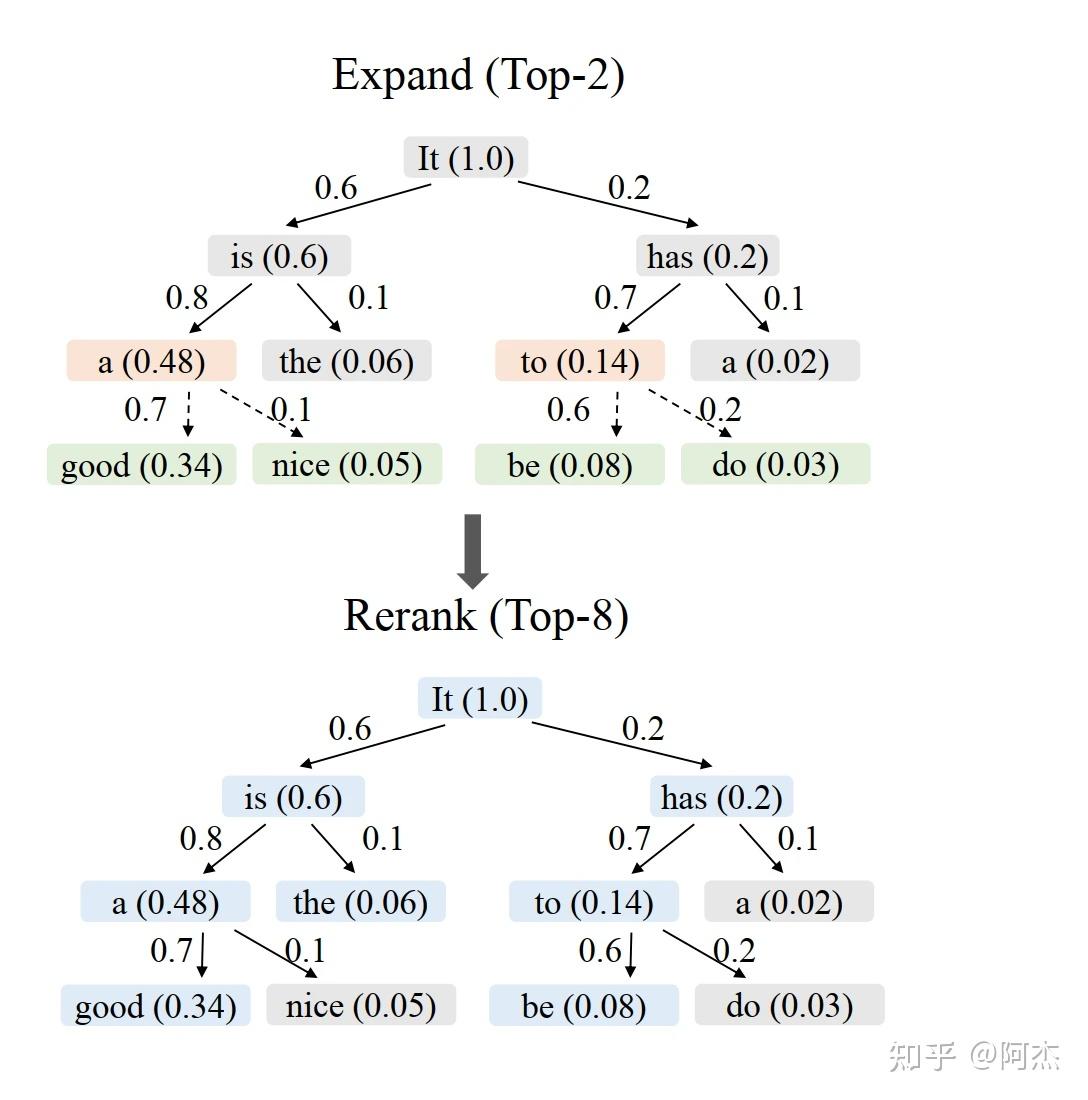
EAGLE 2 提出上文感知的动态 Draft Tokens 树结构,通过 Token 的联合概率预估接收率,利用接收率动态展开 Draft 树,在保证树节点个树基本不变的前提下(即verify开销基本不变),提高 Draft Tokens 的接受长度。这是一种二阶段方法,包括 Expand 阶段和 Rerank 阶段。
- Expand 阶段:生成 Draft 树。每个节点包含路径的概率信息,通过将路径上边的权重相乘得到。Expand 过程中,当展开的节点的概率值小于阈值时,则停止该节点继续展开,否则继续展开。如下图 Expand 阶段所示,阈值为 0.1, 为 2,每个节点取前 2 个子节点进行 Expand。当节点概率小于 0.1 时,不再对该 Token 采样下一个 Token。
- ReRank 阶段:保留概率最高的 个节点,其余节点删除。当不同的节点概率相等时,保留浅层节点,目的是保证树的结构。如下图所示, 为 8,取树中概率最高的前 8 个 Token 组成新的 Draft 树。
实验现象
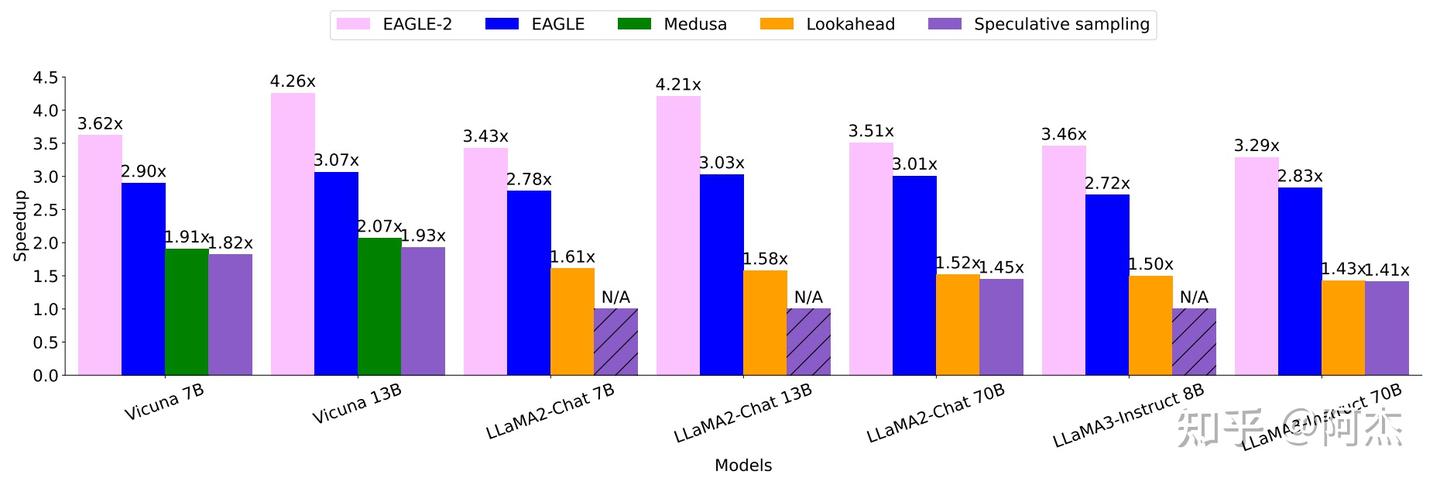
作者在 MT Bench 数据集中完成了性能测试。结果表明,EAGLE 2 进一步突破性能天花板,在所有模型下性能均优于 EAGLE。
结论
EAGLE 2 在 EAGLE 1 的基础上,加入了动态Draft 树生成,在保证 Draft 树节点个数基本不变的前提下(即 Verify 阶段的 overhead 基本不变),提高 Draft Tokens 的接受长度。
结论
投机采样的核心优化方向是 Draft Token 的接收率及投机采样的 overhead。接收率上的优化主要依赖模型架构的魔改,overhead 的优化主要依赖压缩 Draft 树规模。EAGLE 提出了 Token-Level & Feature-Level 融合采样算法和动态 Draft 树生成算法,提升 Draft Token 的接收率,并且通过剔除大量无用的 Draft 树分支,提升了验证效率。
参考资料
-
No backlinks found.