线性注意力:Delta-Net
vanilla softmax attention
如下所示 $$ \begin{aligned} \mathrm{Parallel\ training:} &&& \mathbf{O} = \mathrm{softmax}(\mathbf{Q}\mathbf{K}^\top \odot \mathbf{M})\mathbf{V} &&\in \mathbb{R}^{L\times d} \ \mathrm{Iterative\ inference:} &&&\mathbf{o_t} = \sum_{j=1}^t \frac{\exp(\mathbf{q}_t^\top \mathbf{k}j)}{\sum{l=1}^t\exp(\mathbf{q}^\top_t \mathbf{k}_l)}\mathbf{v}_j &&\in \mathbb{R}^d \end{aligned} $$ 其中
- $L$ represents sequence length
- $d$ represents head dimension
- $\mathbf{Q}, \mathbf{K}, \mathbf{V}, \mathbf{O} \in \mathbb{R}^{L \times d}$ represent the query, key, value, and output matrices respectively.
- $\mathbf{M} \in \mathbb{R}^{L \times L}$ is the causal mask for autoregressive modeling by ensuring each position can only attend to previous positions.
问题:随着 sequence length 增长计算呈现平方复杂度
Linear Attention
$$\begin{aligned} \mathrm{Parallel\ training:} &&&\mathbf{O}= (\mathbf{Q}\mathbf{K}^\top \odot \mathbf{M})\mathbf{V} &&\in \mathbb{R}^{L\times d} \ \mathrm{Iterative\ inference:}&&&\mathbf{o_t} = \sum_{j=1}^t (\mathbf{q}_t^\top \mathbf{k}_j) \mathbf{v}_j &&\in \mathbb{R}^d \end{aligned}$$
Gated Linear Attention
DeltaNet 引入 Delta Rule
虽然基础线性注意力解决了速度问题,但它的记忆方式太简单了。它只是简单地对 $K^TV$ 进行累加,这会导致模型难以“忘记”旧信息或“更新”错误的记忆。
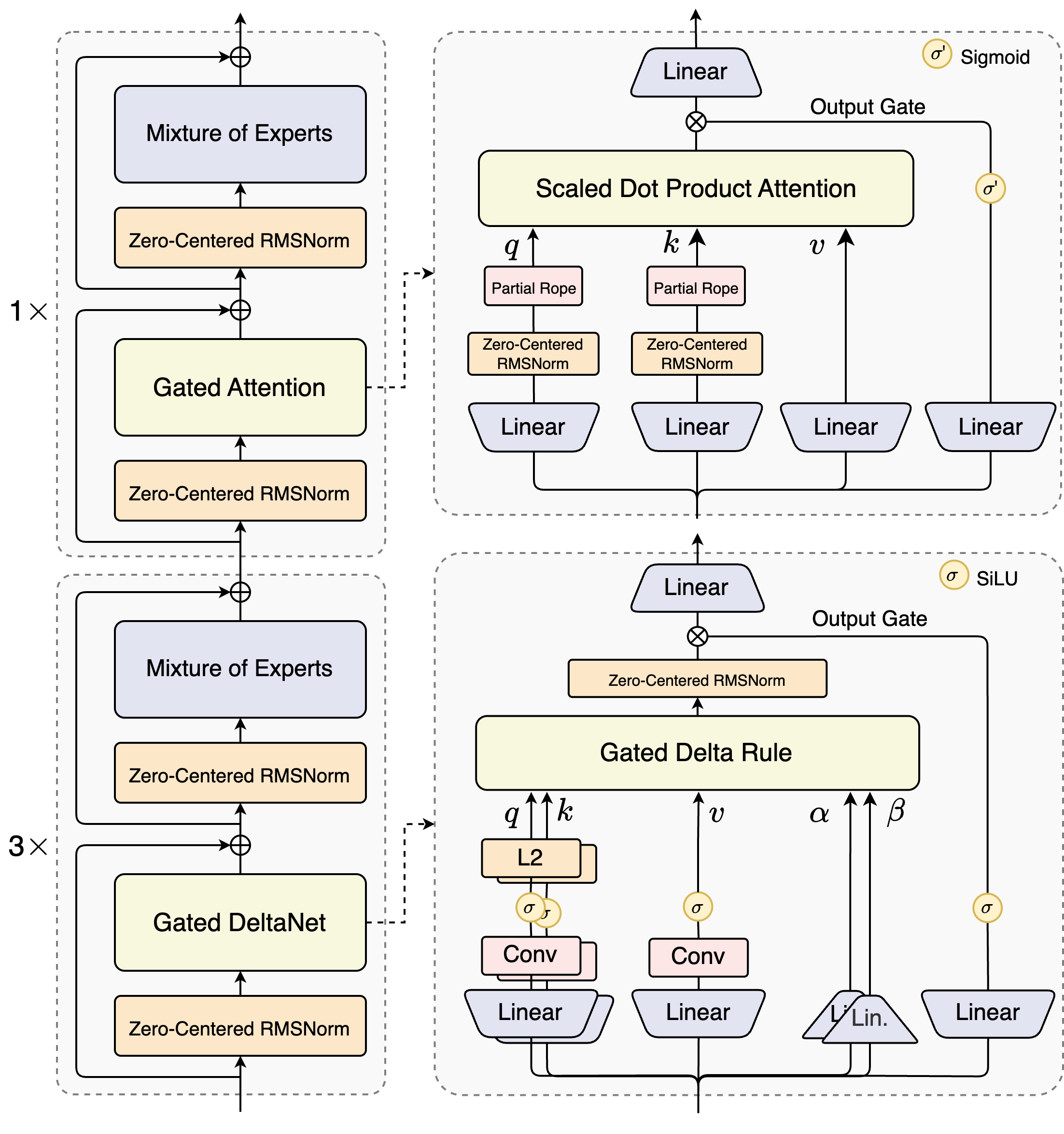
DeltaNet 的关键是把线性注意力里的”只加不减“的记忆变成了可擦写的记忆。
它首先用当前 key 从旧状态中取出旧的 value,然后用一个门控系数 β 来决定本步应该保留多少旧信息、写入多少新信息。接着在状态矩阵里先删除旧的kv外积 ,再写入融合后的新外积。引入了beta,是一个0,1之间的值,可以控制写入的强度。
$$ \begin{aligned}
\color{purple} \mathbf{q}_t &= \color{purple} W_Q \mathbf{x}_t & &\quad \text{\color{purple}{Query}}\text{ vector is computed} \
\color{teal} \mathbf{k}_t &= \color{teal} W_K \mathbf{x}_t & &\quad \text{\color{teal}{Key}}\text{ vector is computed} \
\color{green} \mathbf{v}_t &= \color{green} W_V \mathbf{x}_t & &\quad \text{\color{green}{Value}}\text{ vector is computed} \
% Beta标量
\color{violet} \beta_t &= \color{violet} sigmoid(W_\beta \mathbf{x}_t) & &\quad \text{\color{violet}{Beta}}\text{ scalar value is computed} \
% Old Value
\color{orange} \mathbf{v}t^{\text{old}} &= \color{orange} S{t-1} \mathbf{k}_t & &\quad \text{\color{orange}{Old value}}\text{ is retrieved using current key} \ \color{blue} \mathbf{v}_t^{\text{new}} &= \color{blue} \beta_t \mathbf{v}_t + (1-\beta_t) \mathbf{v}_t^{\text{old}} & &\quad \text{\color{blue}{New value}}\text{ combines current and old values} \
% State矩阵更新
S_t &= S_{t-1} - \underbrace{\color{orange} \mathbf{v}_t^{\text{old}} \mathbf{k}t^\top }{\text{\color{orange}remove old}} + \underbrace{\color{blue} \mathbf{v}_t^{\text{new}} \mathbf{k}t^\top }{\text{\color{blue}write new}} & &\quad \text{State matrix}\text{ is updated} \
\color{brown} \mathbf{o}_t &= \color{brown} S_t \mathbf{q}_t & &\quad \text{\color{brown}{Output}}\text{ is retrieved from memory using query}
\end{aligned} $$
DeltaRule,Delta Rule 是神经网络中一项基本的误差校正学习原则。它的核心思想非常简洁:根据期望值(目标值)与实际结果(预测值)之间的差异(delta)来调整模型的参数。
DeltaNet 就是将这种纠错机制应用于线性 attention。它不再简单地累积键值外积,而是基于预测误差来更新自身状态: $$ \begin{align*} \mathbf{S}{t} &= \mathbf{S}{t-1} - \beta_t(\mathbf{S}_{t-1} \mathbf{k}_t - \mathbf{v}t)\mathbf{k}t^\top \ &= \mathbf{S}{t-1} - \beta_t \mathbf{S}{t-1} \mathbf{k}_t \mathbf{k}_t^\top + \beta_t \mathbf{v}_t \mathbf{k}_t^\top \end{align*} $$ 其中:
- $\beta_t \in \mathbb{R}$ 可以视作 state 更新的 learning rate
- $\mathbf{k}_t \in \mathbb{R}^d$ 是 input data
- $\mathbf{v}_t \in \mathbb{R}^d$ 是 target
- $\mathbf{S}_{t-1} \mathbf{k}_t \in \mathbb{R}^d$ 是当前我们的 prediction
我们可以把可以 $\mathbf{S}_{t-1} \mathbf{k}_t$ 视作是从 memory 中取出与 $\mathbf{k}_t$ 相关的 old value,记作 $\mathbf{v}t^{old}=\mathbf{S}{t-1} \mathbf{k}_t$ ,然后我们根据 token 获得了当前 token 的 $\mathbf{v}_t$,因此我们用一下公式来更新 vaule:
$$
\begin{align*} \mathbf{v}_t^{\text{new}} &= (1-\beta_t) \mathbf{v}_t^{\text{old}} + \beta_t \mathbf{v}_t, \ \mathbf{S}t &= \mathbf{S}{t-1} - \underbrace{\mathbf{v}_t^{\text{old}} \mathbf{k}t^\top}{\text{erase}} + \underbrace{\mathbf{v}_t^{\text{new}} \mathbf{k}t^\top}{\text{write}} \end{align*}
$$
这里的 $\mathbf{v}_t^{\text{new}}$ 是 learned combination of the old and current values,被 $\beta_t$ 控制:
- 当 $\beta_t = 0$ 时,memory 保持不变
- 当 $\beta_t = 1$ 时,我们擦除 old value,用当前 value 代替
整理上面的过程,把 DeltaNet 的更新写成更紧凑的形式:
$$ \begin{align*}
\boldsymbol{S}t &= \mathbf{S}{t-1} - \underbrace{\mathbf{v}_t^{\text{old}} \mathbf{k}t^\top}{\text{erase}} + \underbrace{\mathbf{v}t^{\text{new}} \mathbf{k}t^\top}{\text{write}} \ &= \mathbf{S}{t-1} -\mathbf{v}_t^{\text{old}}\mathbf{k}_t^\top + (1-\beta_t) \mathbf{v}_t^{\text{old}}\mathbf{k}_t^\top + \beta_t \mathbf{v}_t\mathbf{k}t^\top \ &= \mathbf{S}{t-1} - \beta_t \left( \mathbf{v}_t^{\text{old}} - \mathbf{v}_t \right) \mathbf{k}_t^\top \
&= \mathbf{S}{t-1} - \beta_t \left( \mathbf{S}{t-1}\mathbf{k}_t - \mathbf{v}_t \right) \mathbf{k}_t^\top \
&= \mathbf{S}_{t-1} \left( \mathbf{I} - \beta_t \mathbf{k}_t \mathbf{k}_t^\top \right) + \beta_t \mathbf{v}_t \mathbf{k}_t^\top
\end{align*} $$
下图可以更直观的理解信息流
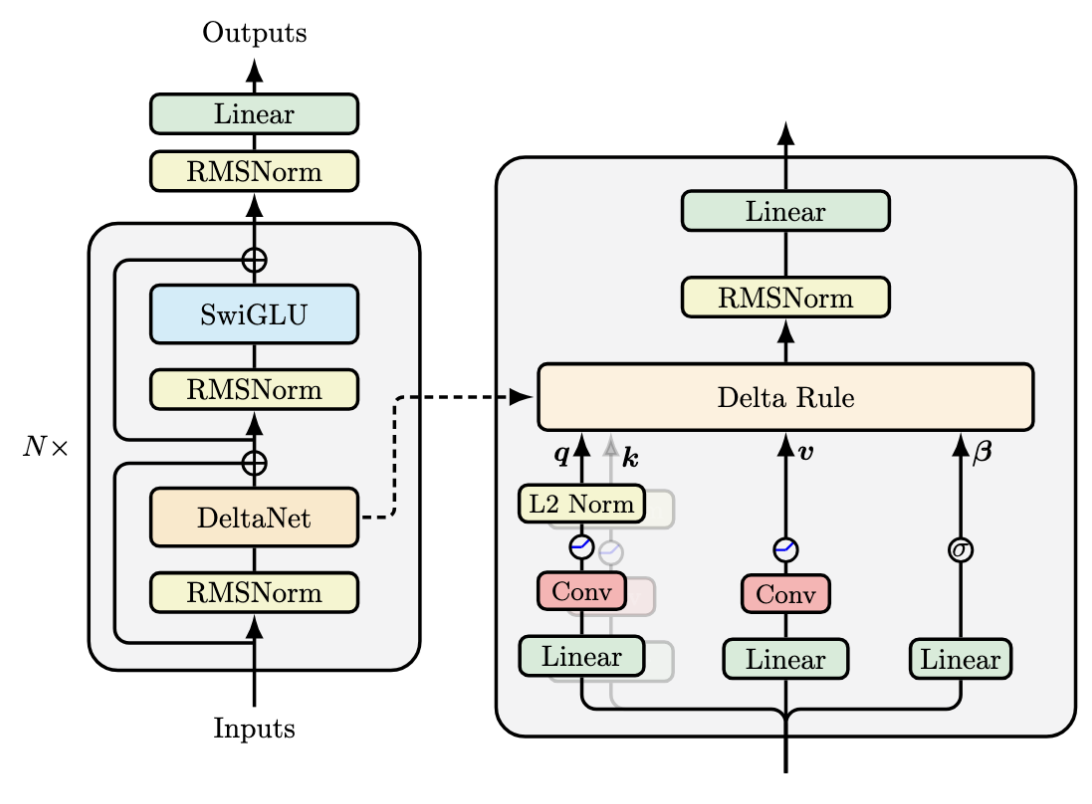
Gated DeltaNet
在 DeltaNet 控制写入的强度后,Gated DeltaNet 则引入了遗忘门 Forget Gate。
把 Mamba2 的全局遗忘门和 DeltaNet 的按 key 擦写机制结合起来:先用 $\alpha$ 对当前状态做一次整体衰减,再用 $\beta$ 在当前 key 方向上进行定点清除和写入。
所以 Gated DeltaNet 既能快速全局忘记,又能精确局部更新,比两者单独使用都更稳定。
Gated DeltaNet 使用了 Mamba2 风格的 $\textcolor{red}{scalar-valued}$ forget gate: $$ \begin{aligned} &\mathbf{S}t = \textcolor{red}{\alpha_t}\mathbf{S}{t-1} + \mathbf{v}_t\mathbf{k}_t^\top \quad &&\text{Mamba2} \
&\mathbf{S}t = \textcolor{red}{\alpha_t}\mathbf{S}{t-1}\left(\mathbf{I} - \textcolor{blue}{\beta_t}\mathbf{k}_t\mathbf{k}_t^\top\right) + \textcolor{blue}{\beta_t}\mathbf{v}_t\mathbf{k}_t^\top \quad &&\text{Gated DeltaNet} \end{aligned} $$

这里面:
α(decay gate) controls how fast the memory decays or resets over time,β(update gate) controls how strongly new inputs modify the state.
对应于模型结构,给出关键权重:
$$ \begin{aligned} \boldsymbol{q}_t &= \boldsymbol{W}_Q \boldsymbol{x}_t, \ \boldsymbol{W}_Q \in \mathbb{R}^{d_k \times d}, \ \boldsymbol{q}_t \in \mathbb{R}^{d_k} \ \boldsymbol{k}_t &= \boldsymbol{W}_K \boldsymbol{x}_t, \boldsymbol{W}_K \in \mathbb{R}^{d_k \times d}, \ \boldsymbol{k}_t \in \mathbb{R}^{d_k}\ \boldsymbol{v}_t &= \boldsymbol{W}_V \boldsymbol{x}_t, \boldsymbol{W}V \in \mathbb{R}^{d_v \times d}, \ \boldsymbol{v}t \in \mathbb{R}^{d_v} \ \beta_t &= \sigma(\boldsymbol{W}\beta \boldsymbol{x}t) \in (0,1), \ \boldsymbol{W}\beta \in \mathbb{R}^{d_k \times d} \ \alpha_t &= \sigma(\boldsymbol{W}\alpha \boldsymbol{x}t) \in (0,1), \ \boldsymbol{W}\alpha \in \mathbb{R}^{d \times d} \ \end{aligned} $$
代码实现
|
|
总结
$$ \begin{array}{c|c} \hline & \text{公式} \[4pt] \hline \text{Softmax Attention} & (\exp(\boldsymbol{Q}\boldsymbol{K}^{\top})\odot \boldsymbol{M})\boldsymbol{V} \[4pt] \text{最早的线性Attention} & (\boldsymbol{Q}\boldsymbol{K}^{\top}\odot \boldsymbol{M})\boldsymbol{V} \[4pt] \text{加入遗忘门后} & (\boldsymbol{Q}\boldsymbol{K}^{\top}\odot \boldsymbol{\Gamma})\boldsymbol{V} \[4pt] \text{DeltaNet} & (\boldsymbol{Q}\boldsymbol{K}^{\top}\odot \boldsymbol{M})(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot \boldsymbol{M}^-)^{-1}\boldsymbol{V} \[4pt] \text{Gated DeltaNet} & \begin{gathered}((\boldsymbol{Q}\boldsymbol{K}^{\top}\odot \boldsymbol{M})(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot \boldsymbol{M}^-)^{-1}\odot\boldsymbol{\Gamma})\boldsymbol{V} \ =(\boldsymbol{Q}\boldsymbol{K}^{\top}\odot \boldsymbol{\Gamma})(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot \boldsymbol{\Gamma}^-)^{-1}\boldsymbol{V}\end{gathered} \[4pt]
\hline
\end{array} $$
参考资料
- DeltaNet Explained, https://sustcsonglin.github.io/blog/2024/deltanet-1/
-
No backlinks found.