Context Condense
1. Long-Horizon Agent 的兴起
随着 LLM 推理能力的成熟,agent 任务的复杂度正在从"一问一答"急剧扩展到 long-horizon(长程) 形态:
- Deep Research:给定一个开放性问题(如"分析 2024 年美国大选选情"),agent 需要调用 Search、TextBrowser、Code Interpreter 等工具,反复"搜索 → 阅读 → 反思 → 再搜索",往往需要 30-100+ 轮工具调用才能产出可靠答案。
- SWE Agent:在真实代码库中完成 issue 修复,需要 cd / ls / grep / read / edit / run-test 等数十轮 shell 操作。
- GUI Agent:在浏览器或桌面环境完成多步操作(订机票、报销、数据采集),单任务轨迹长度普遍在 50 轮以上。
- Multi-turn Math/CI:复杂数学题需要写代码验证、debug、再尝试,常见 10-30 轮迭代。
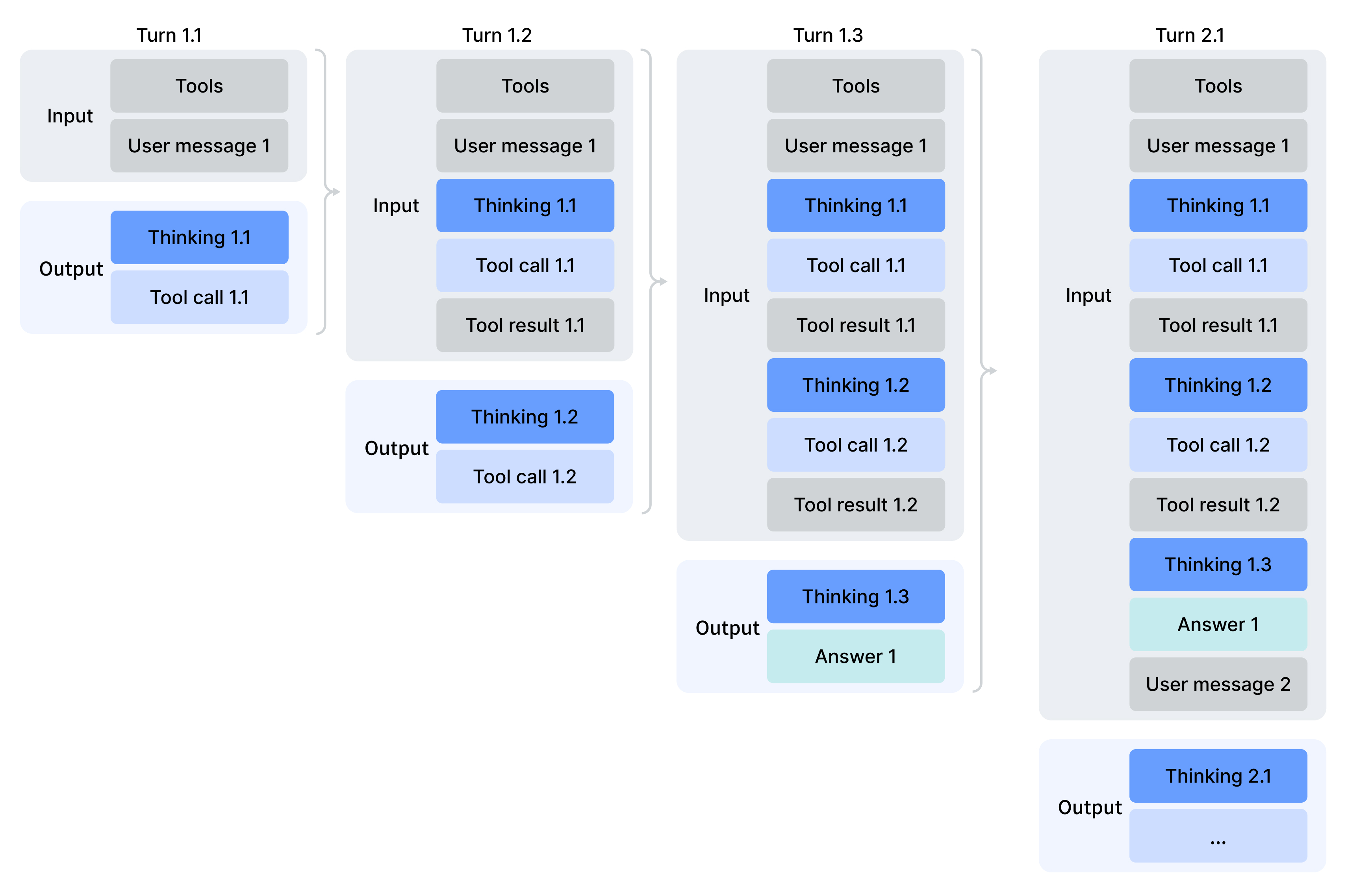
这些任务的共同特征:单条轨迹由数十轮 (LLM 输出 → 工具调用 → 观察结果) 循环组成,每一轮的观察 observation 可能是数百到数千 token 的网页 / 代码 / 终端输出。
2. 上下文窗口 = 长程能力的硬性瓶颈
LLM 的 prompt 窗口物理上是有限的,常见配置为 128 K / 256 K token 乃至 1M context length。在 long-horizon agent 场景下,prompt 会以线性甚至超线性速度增长: $$Prompt_t=system+task+ \sum_{i=1}^{t−1} (assistant_i+tool_call_i+observation_i)$$
其中 $observation_i$ 是最不可控的来源 —— 一次 TextBrowser.fetch 可能返回 8K token 的网页正文,一次 JupyterCI.run 可能返回 4 K token 的 stack trace。实测一个深搜任务跑到第 10-15 轮就会逼近 32 K 上限;第 25 轮基本必定爆窗口。
对于这种 long-running 的 agent 任务,长上下文带来的问题1,即 Context Rot:
- Response Speed: Larger contexts take longer to process
- Operating Costs: More tokens means higher API costs
- Effectiveness: LLMs are less effective with lots of irrelevant info in the context
一旦 prompt 溢出,常见的几种粗暴处理都不理想:
| 方案 | 问题 |
|---|---|
| 硬截断(truncate from head) | 丢掉 task description,模型彻底跑偏 |
| 硬截断(truncate from tail) | 丢掉最近的工具结果,丢失最相关信息 |
| 直接终止 rollout | 长任务永远走不完,reward 永远拿不到,训练信号极度稀疏 |
| 一味扩 context window | 显存 / KV cache 二次方增长,rollout 吞吐崩盘;且模型超长 attention 退化严重 |
3. Condense(上下文压缩)成为必选项
工业界普遍的解法是 condense:当 prompt 即将超限时,按某种策略压缩历史,腾出空间让 agent 继续往下走。常见策略包括:
- FIFO / 滑动窗口:丢掉最早的若干轮 tool observation(保留 assistant thought)。最简单也最常用。
- Summarization:让另一个 LLM 把旧历史压成 summary 注入。开销大,且 summary 质量影响下游推理。
- Tool-call result selective drop:只丢观察结果,保留 tool call 本身(保留"agent 试过什么"的记忆)。
- External memory / Retrieval:把历史存到向量库,按需检索回来。
无论用哪种策略,condense 都是 long-horizon agent 跑通的前提:没有 condense,rollout 根本无法到达"最终答案"那一步。
社区里 上下文压缩 有多个习惯叫法,指代基本是同一件事:
| 称呼 | 来源 / 出处 | 强调的点 |
|---|---|---|
| Context Condensation / Condenser | OpenHands (前 OpenDevin) 设计文档;alpha-seed / swalm-agent 内场 | “压缩对话事件” |
| Context Compaction | OpenAI, Anthropic23(Claude Code 的 /compact 命令);Cursor、Aider 等编辑器助手;学界 long-context 论文 |
“把上下文折叠成更小” |
| Memory Management / Recursive Summarization | MemGPT、LangChain Memory;Sumers et al. Cognitive Architectures for LLMs | 强调"做成长期记忆" |
| Context Pruning / Eviction | KV-cache 角度(H 2 O, StreamingLLM, SnapKV) | 物理层面的"剪枝/驱逐" |
| Conversation Summarization | ChatGPT、Bing Chat 早期方案 | 强调"对话级摘要" |
本质问题都是同一个:当 agent 的对话历史超出 LLM 的有效上下文窗口时,必须以某种策略压缩 / 丢弃 / 改写历史,让 agent 还能继续往下推进。
OpenHands LLM Summary Condenser
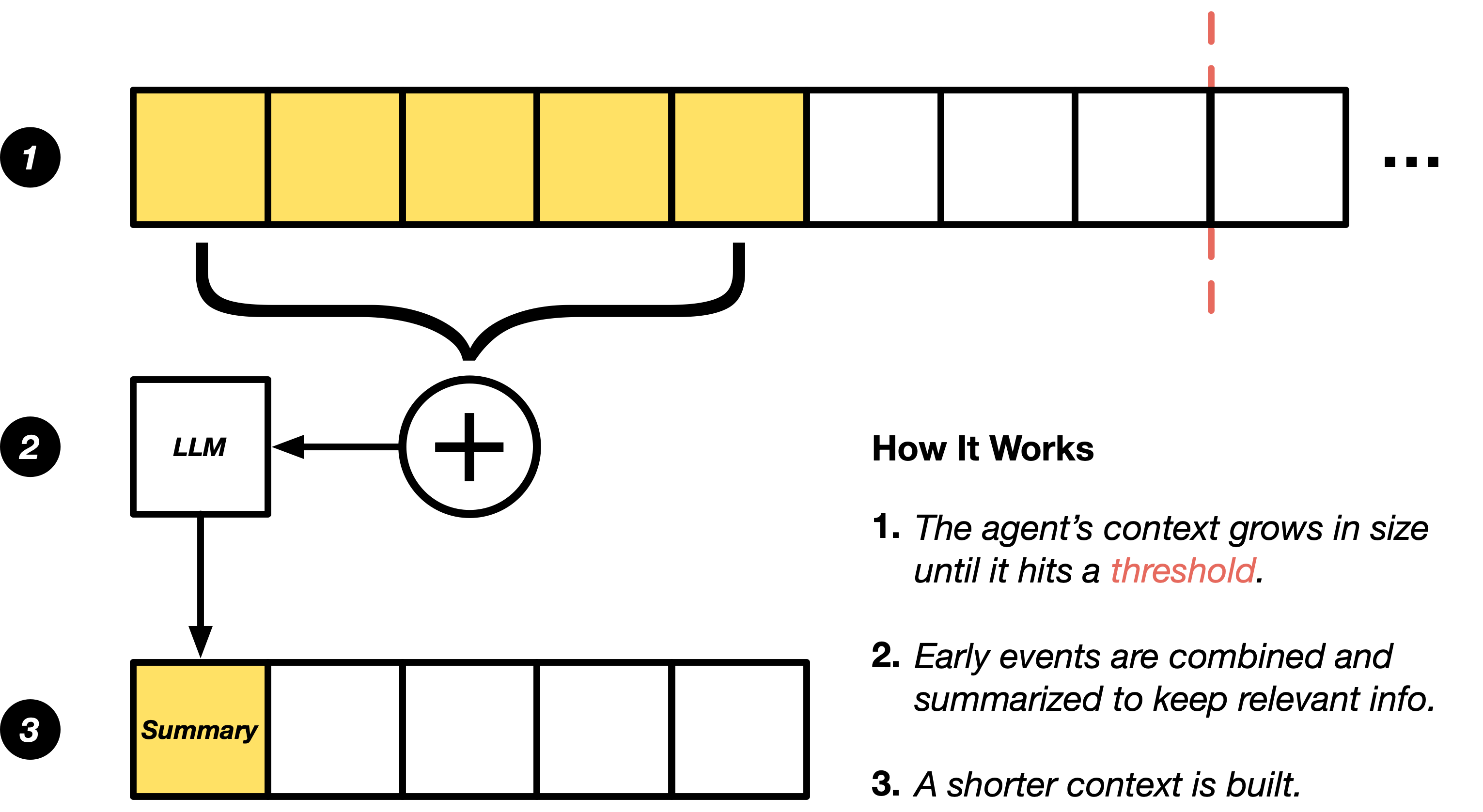
OpenHands 等 Agent 框架最早提出 LLM Summary1 来实现上下文 condense 核心思路:context 接近上限时(默认在 75-95% 阈值),自动调用底层 LLM 用一段固定 system prompt 把当前对话总结成简短记忆,保留几条最近消息 + summary 拼成新对话继续。
- 触发:基于 token 占用比例
- 操作:summarize
- 选择:保留 first message + 最近 K 轮 + summary 中间历史
- 特点:用户也可以手动
/compact,并能注入自定义重点关注什么的指令
适用场景:编辑代码任务,需要保持 用户最初要求和 最近几步状态。
- 对 RL 训练不友好:summarization 不可求梯度,且 summary 文本本身可能让模型分布漂移。
|
|
Observation Mask Condenser
Observation Mask Condense4 的核心思想是:在 long-horizon agent 中,真正导致 context 爆炸的往往不是 reasoning,而是大量 tool observation(如日志、search 结果,grep 输出、DOM、pytest logs 等)
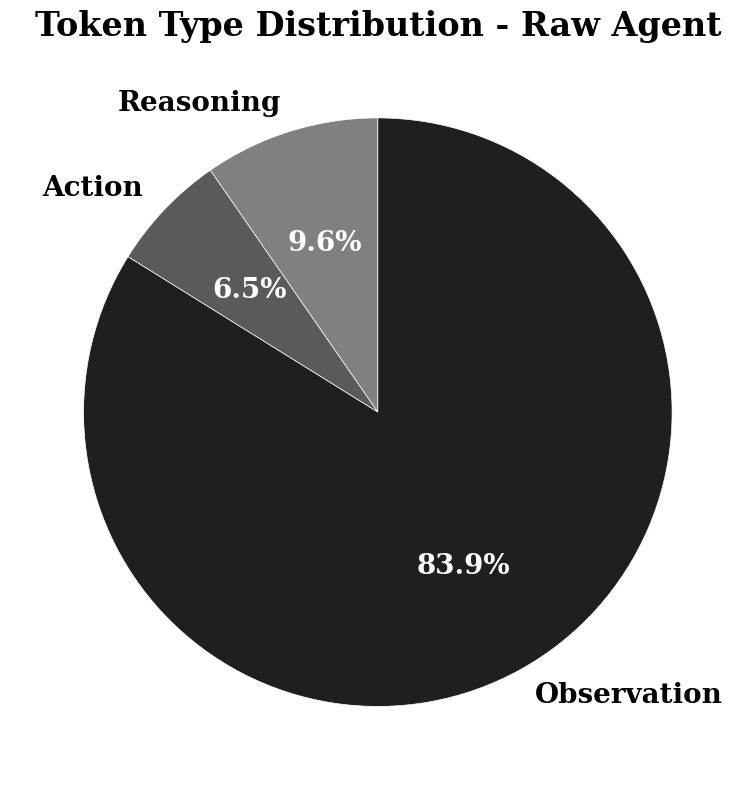
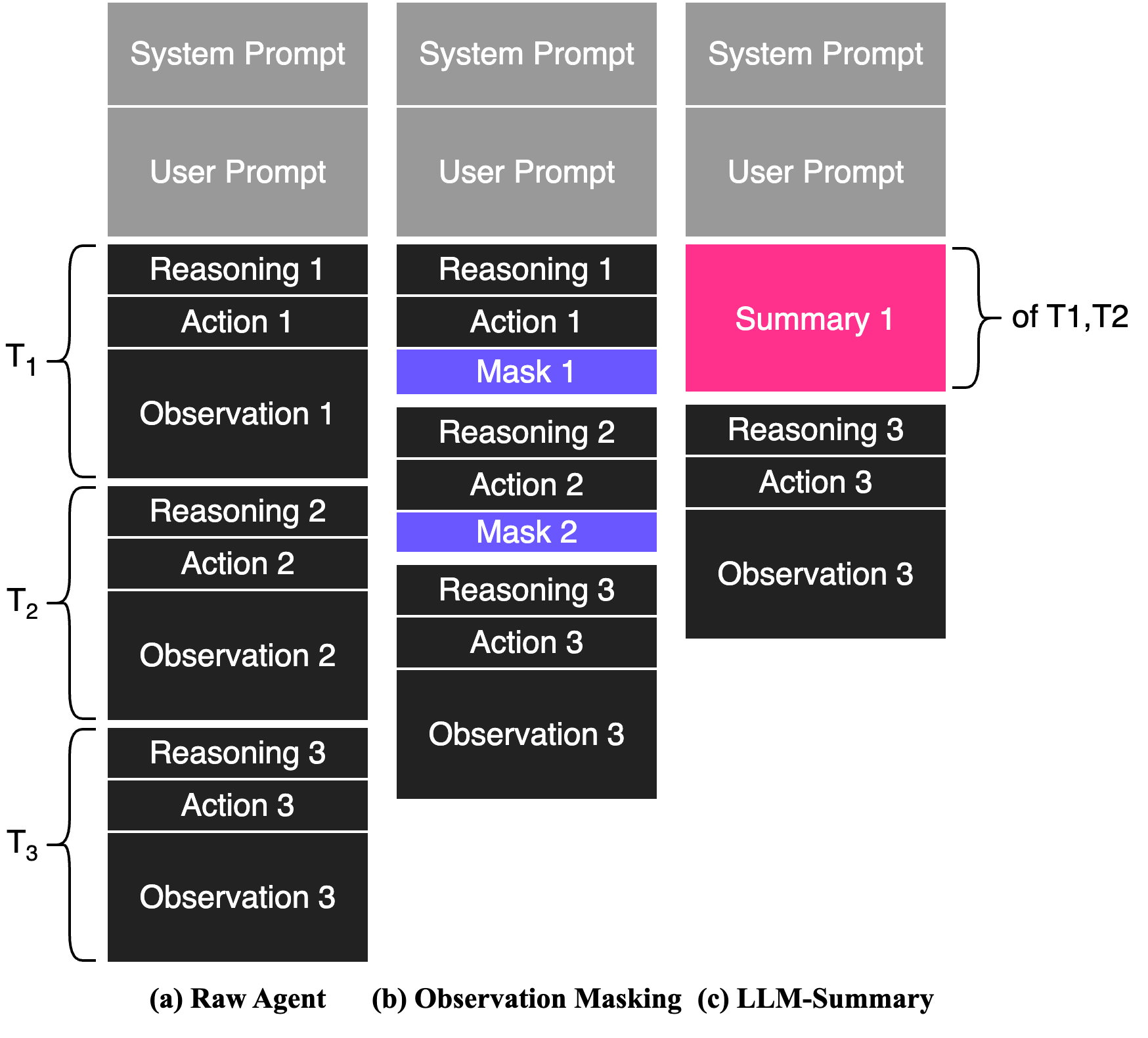
因此相比用 LLM 对历史进行复杂 summarization,更简单有效的方法是直接 mask / 删除旧 observation,仅保留 user goal、reasoning trace、action trajectory 和最近的 working context。
The Complexity Trap4 证明,这种 结构化删除 在 SWE-agent 等任务上能够显著降低 token 成本,同时几乎不降低 solve rate,甚至有时优于 summary-based compaction,因为过多历史 observation 本身会造成 attention dilution、context rot 和 reasoning pollution。其本质上是在把 agent memory 从 保存完整 trajectory转向 仅维护未来决策所需的 executable state。
伪代码实现:
|
|
ToolFIFOCondenser
|
|
Structured Note-taking
- Agent 主动写出外部笔记/scratchpad
- 让重要信息离开上下文窗口,但需要时可以读回
- 类比人类用文件系统/书签,不靠记忆
Multi-agent Architectures
- 不同 sub-agent 各自维护小而聚焦的上下文
- 主 agent 只看到子 agent 的最终结论
- 天然限制每个上下文的体量
-
https://www.openhands.dev/blog/openhands-context-condensensation-for-more-efficient-ai-agents ↩︎ ↩︎
-
https://platform.claude.com/cookbook/tool-use-automatic-context-compaction ↩︎
-
The Complexity Trap: Simple Observation Masking Is as Efficient as LLM Summarization for Agent Context Management, https://arxiv.org/html/2508.21433v3 ↩︎ ↩︎
-
No backlinks found.