Comet
混合专家模型(MoE)通过稀疏激活机制突破了传统稠密模型(Dense Model)的计算瓶颈,然而,MoE 的分布式训练仍面临一项严峻挑战:跨设备通信开销巨大。例如,Mixtral-8x7B 模型在 Megatron-LM 框架中的通信时间占比可高达 40%,严重制约了训练效率和成本。
核心问题在于,MoE 的专家网络分布在多个 GPU 上,每次计算需频繁执行 Token Dispatch 与结果 Combine,导致 GPU 计算资源大量闲置。因此,如何将通信隐藏到计算的过程中,提升模型训练效率、节省计算资源,成为了 MoE 系统优化的关键。

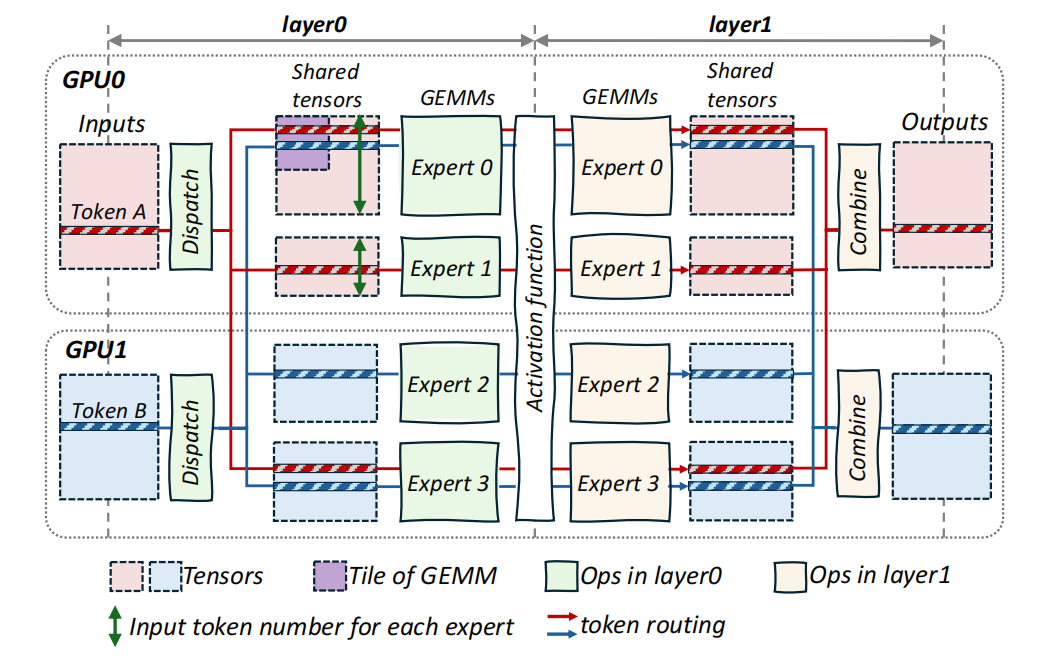
Figure 1: Analysis of the execution of MoE. (a) Time breakdown of MoE models executed on 8 H800 GPUs using Megatron-LM. (b) An illustration of communication-computation overlap by partitioning an expert computation kernel into two.
Comet 的主要工作是对通信和计算之间的共享 Buffer(即文章中的 Shared Tensor)进行分析, 并按照特定的维度分解来消除通信和计算之间粒度不匹配的问题, 并重新组织数据进行调度, 实现了细粒度的 Overlap, 最终单个 MoE 层执行速度性能提升了1.96倍. E2E 提升了1.71倍.
难点 :「复杂的数据依赖」与「流水线气泡」
为了掩盖巨大的通信开销,现有方案主要集中在如何对「计算-通信」进行高效重叠。
一种方案是将流水线调度与通信算子结合起来,即通过定制训练中流水线并行的调度方式,将不同 microbatch 的计算和通信进行重叠,如 DeepSeek 的 DualPipe。但是,这一方式会导致较大的显存开销,并需要对现有训练框架进行复杂的侵入性改动。
其它 MoE 系统方案则是在 microbatch 内部采用了粗粒度的计算-通信流水线,将输入数据分割成「数据块」进行通信与计算的重叠。然而,这种粗粒度的重叠方式难以高效利用计算资源,且无法实现无缝的通信延迟隐藏,尤其在动态路由、异构硬件环境下,性能损失显著。
因此,团队认为现有的系统级 MoE 解决方案仍面临两大困境:
1. 难以解决复杂的数据依赖
MoE 架构的稀疏特性导致计算和通信间的依赖动态且复杂。MoE 会动态地将 Token 分配给不同专家,而传统的粗粒度矩阵分块方式,会导致 GPU 频繁等待远程数据,从而造成计算资源闲置。
如图 1 所示,当专家 0 需要在紫色「数据块」中进行 Tile-level 的计算时,必须先通过 Token-level 的通信接收远程数据(Token B),这种由于复杂数据依赖导致的计算-通信粒度上的错配,使得效率严重下滑。
2. 难以消除计算-通信流水线气泡
另一个问题是,现有方法无法精确控制计算任务和通信任务对硬件资源的使用,因而,也无法根据不同的模型结构和动态输入,来自适应地调整资源分配。这导致计算和通信无法实现无缝重叠,进而产生大量流水线气泡,增加了系统的延迟。
因此,团队认为:解决 MoE 模型中计算与通信的粒度不匹配问题是实现两者高效重叠的关键,同时,还需要根据负载情况自适应调整通信和计算的资源分配,以进一步实现无缝重叠。
COMET 核心方案
COMET 是一个针对 MoE 模型的通信优化系统,通过细粒度计算-通信重叠技术,助力大模型训练优化。
团队分析发现,MoE 架构包含两条不同的生产-消费流水线:
- 「计算-通信流水线」
- 「通信-计算流水线」。
如图 2 所示,数据在流水线中流动时,各流水线内的操作会通过一个共享缓冲区链接,该缓冲区被称作「共享张量」。
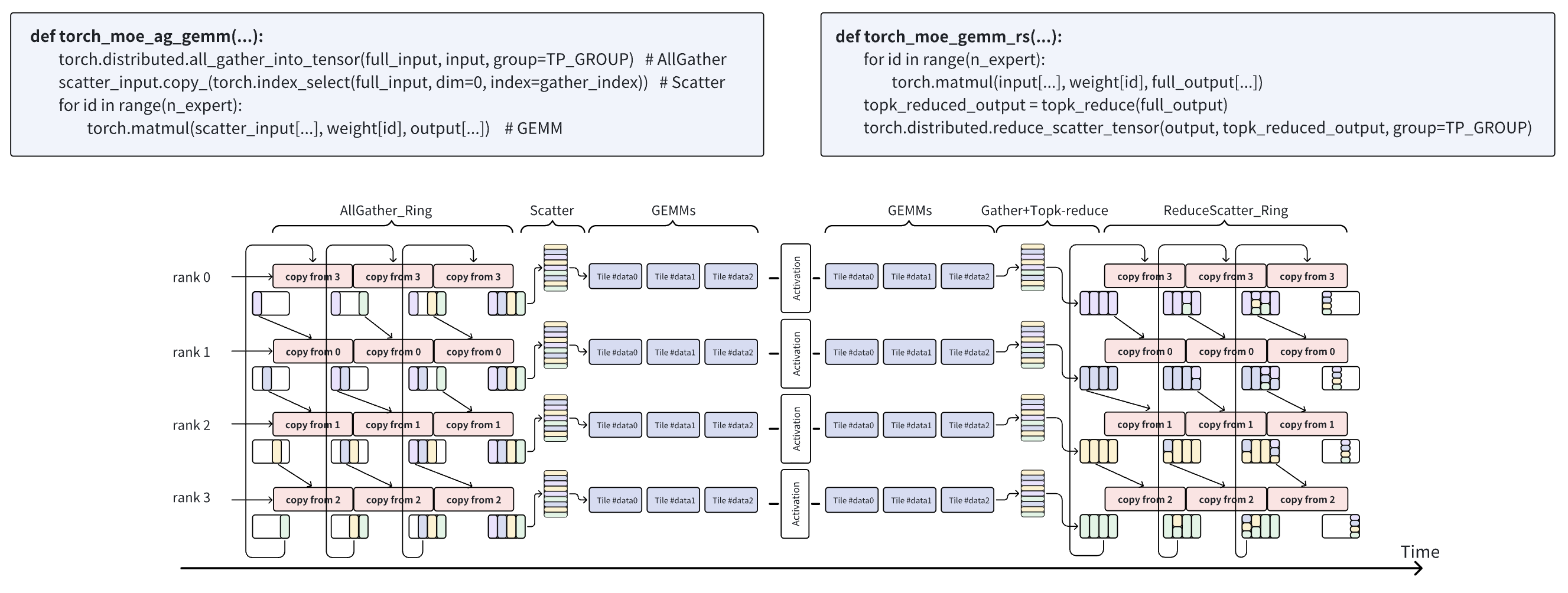
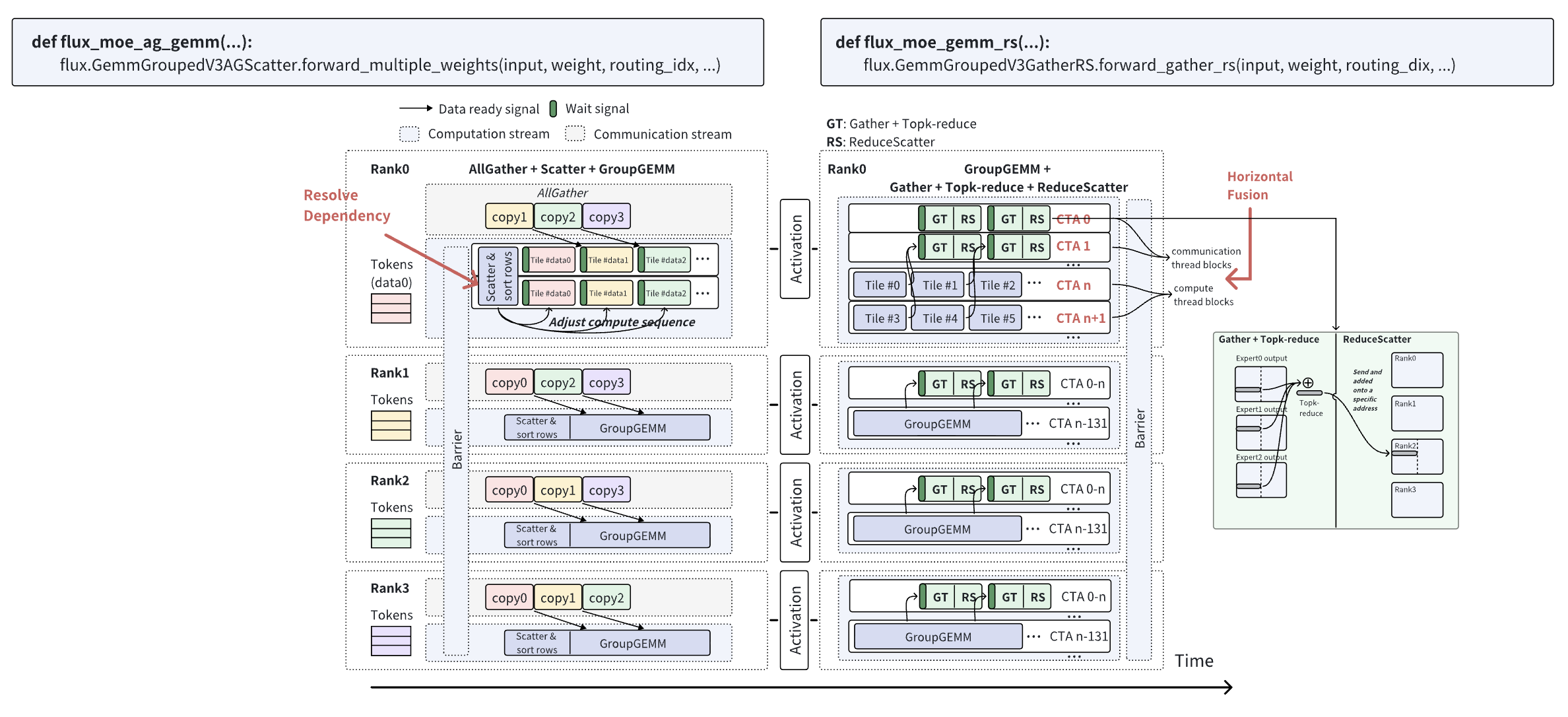
参考
-
No backlinks found.