Chunked Prefill
挑战
ORCA 虽然很优秀,但是依然存在两个问题:GPU 利用率不高,流水线依然可能导致气泡问题。
GPU 利用率
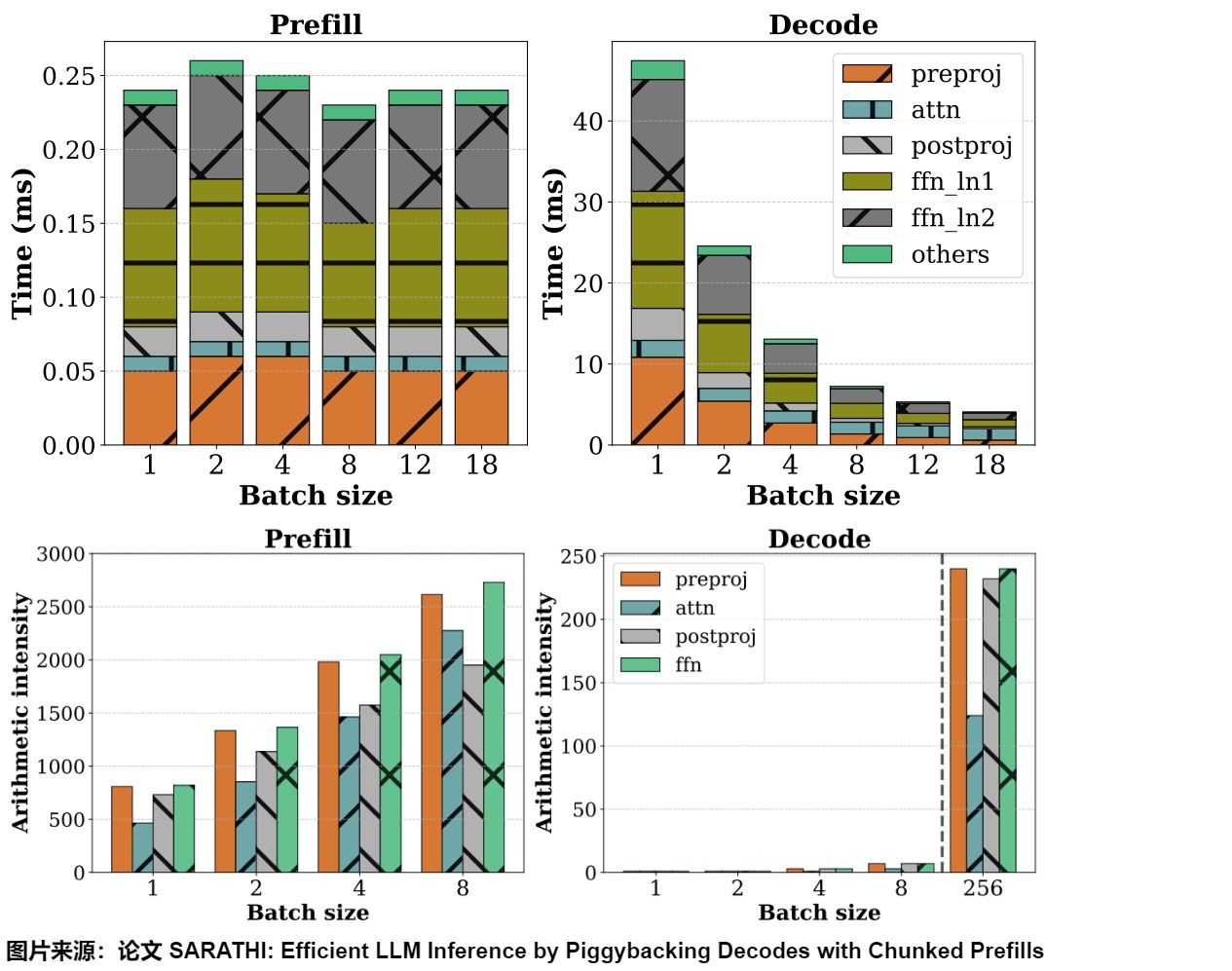
我们来看 sarathi-serve 做的一个实验。左右两图分别刻画了在不同的 batch size 下,prefill 和 decode 阶段的处理时间和计算强度。可以观察到如下:
- Prefill:提升 batch size 时,速度的变化不明显。即使在批处理大小为 1 的情况下也会使 GPU 计算饱和,并导致跨批处理大小的每个 token 时间几乎恒定。
- Decode:提升 batch size 时,处理速度降低的线性趋势非常明显。这是因为 decode 是 memory-bound 的,decode 阶段的算力严重打不满,所以当增大 batch size 时,不仅能多利用算力,也能把多次读取合并成一次读取,降低处理速度。当 batch size 达到一定阈值时,速度的降低幅度也达到瓶颈。随着批大小的增加,用于解码的线性算子的增量成本几乎为零。注意力成本不会从批处理大小中受益,因为它是内存受限的。
流水线
虽然 Orca 已经能在一定程度上改善 pp 气泡问题了,但是它仍然可能导致气泡问题,我们以下图为例:
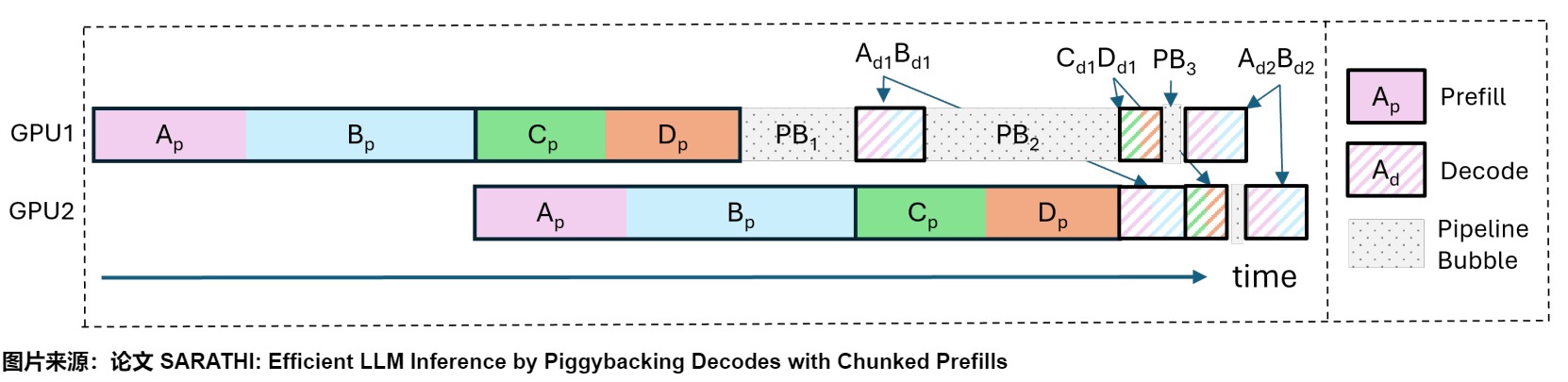
观察到图中一共有 3 种类型的 bubble:
PB1: 因为两个连续的微批中,prefill 序列长度不一致而产生的 bubble。PB2: 因为 prefill 和 decode 阶段计算时间的差异而产生的 bubble。PB3: 不同微批的 decode 计算时间差异而产生的 bubble,这是因为不同 micro-batch 在做 decode 时,要读取的 KV cache 的长度不一致,这也导致了在读取数据上所花费的时间不一致。
原因分析
产生以上问题的原因在于:ORCA 组装 batching 的过程比较随机,一个 batch 中做 prefill 和做 decode 的请求有多少条是不确定的,只是大体按照先来后到的原则做动态组装。这就造成了一些问题。
- 如果一个 batch 中 prefill 的请求非常多,或者遇到非常长的 system prompts,那么 prefill tokens 会占据大量计算资源,使得整个 batch 变成 compute-bound。
- 如果一个 batch 中做 decode 的请求非常多(比如当所有的请求都没做完推理时,或者请求队列中没有新序列可以调度时),这个 batch 就可能变成 memory-bound 的。
因此,我们需要一个机制来保证每个 batch 中 prefill 和 decode 请求的均衡程度。或者说,假设一个 batch 中能够容纳的 token(即达到 GPU 计算能力的上限)是确定的,我们要找到一个方案来按照一定比例去分配做 prefill 的 tokens 和做 decode 的 tokens,通过重叠这两种请求来让这个 batch 做到性能最大化,解决吞吐量和延迟之间的权衡。在这种思路下,prefill 的序列是必定要拆开的,这就是 Sarathi 提出来的 Chunked-prefills(分块预填充)。
Chunked-prefills
Chunked-prefills 方案的核心思想是:将长序列的预填充请求拆分为几乎相等大小的小块,然后构建了由 prefill 小块和 decode 组成的混合 batch。或者说,Chunked Prefill 策略通过将不同长度的 prompts 拆分成长度一致的 chunks 来进行 prefill,以避免长 prompt 阻塞其他请求,同时利用这些 chunks 的间隙进行 decode 的插入/捎带(piggyback)操作,从而减少延迟并提高整体的吞吐。
Decode 阶段的开销不仅来自从 GPU 内存中获取 KV Cache,还包括提取模型参数。而通过这种 piggyback 方法,decode 阶段能够重用 prefill 时已提取的模型参数,几乎将 decode 阶段从一个以内存为主的操作转变为一个计算为主的操作。因此,这样构建的混合批次具有近乎均匀的计算需求(而且增加了计算密集性),使我们能够创建平衡的微批处理调度,缓解了迭代之间的不平衡,导致 GPU 的管道气泡最小化,提高了 GPU 的利用率。也最小化了计算新预填充对正在进行的解码的 TBT(Time-Between-Tokens)的影响,从而实现了高吞吐量和低 TBT 延迟。
对比
下图给出了传统方案,ORCA 方案和 Sarathi 方案的时间线。
- 默认机制(下图 (a))仅在请求级别进行批处理。在这种情况下,就绪请求被分批处理,但是只有当正在处理的批次的所有请求都完成之前,调度器才会接收新的批次。由于请求可能具有较长的 token 生成阶段,这可能会导致请求在其间到达的等待时间较长,从而导致高 TTFT 和高 E2E 延迟。
- 连续批处理(下图 (b))是在默认机制上的优化。在这种情况下,调度决策是在模型的每次前向传递之前做出的。然而,任何给定的批处理要么只包含处于 prompt(提示)阶段的请求,要么只包含 decode 阶段的请求。Prompt 阶段被认为更重要,因为它会影响 TTFT。因此,等待的 prompt 请求可以抢占 decode 阶段。虽然这会导致 TTFT 缩短,但它会大大增加 TBT,从而增加 E2E 延迟。
- 混合批处理(下图 (c))就是 Sarathi 方案。通过这种批处理,在每次前向传播时都会做出调度决策,prefill 和 decode 阶段可以一起运行。这减少了对 TBT 的影响,但并没有完全消除这种影响,因为与 prompt 阶段一起调度的 decode 阶段将经历更长的运行时间。
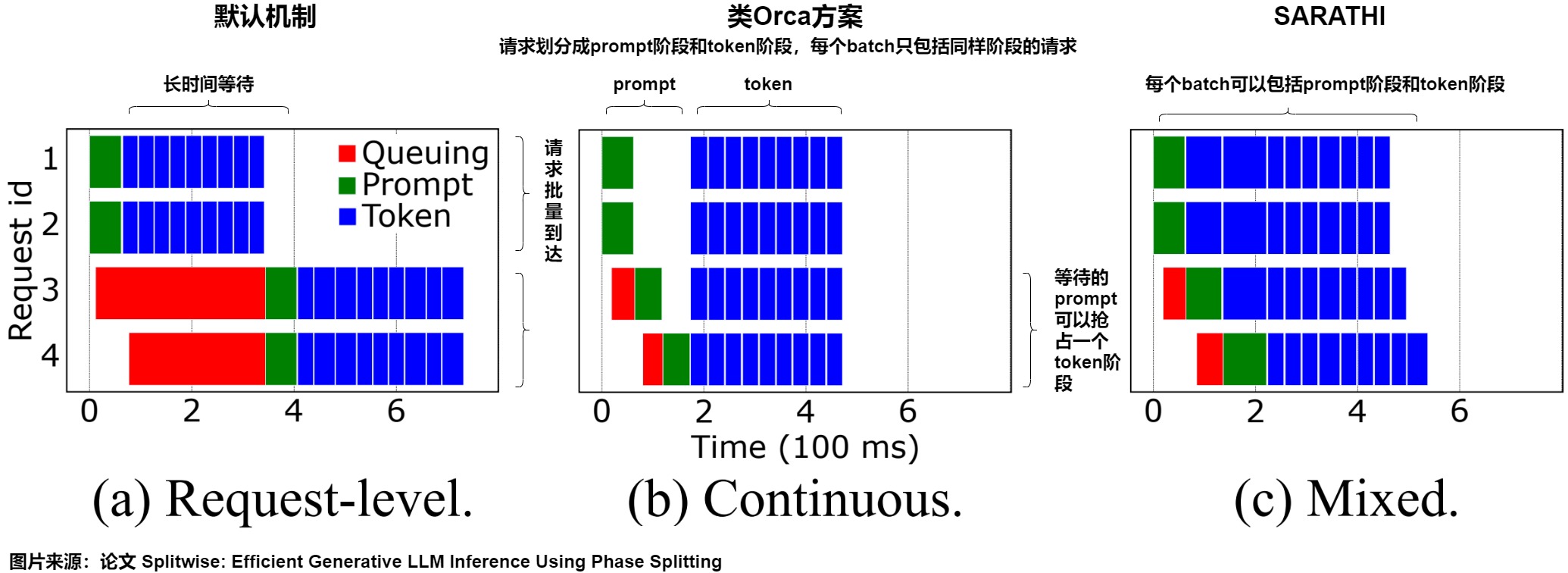
注意:这里的 ORCA 指的是后续的类 ORCA 优化方案。
实现
要使用预填充来附带解码,我们需要注意两件事。
- 首先,我们需要确定可以携带的解码的最大可能批量大小,并确定构成预填充块的预填充 token 的数量。
- 其次,为了真正利用混合批的 GPU 饱和预填充计算来提高解码效率,我们需要将预填充块和批解码的线性运算计算融合到一个操作中。
另外,动态分割的关键是将较长的预填充分成更小的块(chunk),从而通过将预填充块与多个解码任务组合形成批处理,并充分调动 GPU,这个过程称为捎带确认(piggybacking)。
要使用预填充来附带解码,我们需要注意两件事。首先,我们需要确定可以携带的解码的最大可能批量大小,并确定构成预填充块的预填充 token 的数量。其次,为了真正利用混合批的 GPU 饱和预填充计算来提高解码效率,我们需要将预填充块和批解码的线性运算计算融合到一个操作中。
该实现中很重要的一点就是如何确定 chunk 的大小,Sarathi 提供了“固定”和“动态”两种 chunk size 策略。
- 固定策略:该策略会依据硬件和 profilling 实验计算出来一个可以最大限度把 GPU 利用起来的单 batch 中的 tokens 数量。这个是 batch 的 token 总配额,其在运行过程中会尽量保持不变,而 prefill tokens 数量会随着 decode tokens 的增减而变化,但是因为 decode tokens 数量一般也不多,所以 prefill tokens 数量和整体 batch tokens 配额也不会相差很多。
- 动态策略:该策略希望对于一个请求,其 prefill tokens 的数量能随着迭代次数的增加而减少。这是因为如果一个 prompt 特别长,它在每次迭代中都会占据很多计算资源,从而历史累积的 decode 序列和新来的请求受到影响。因此对于这种新进入 batch 的长序列请求,Sarathi 会在开始多配置一些 prefill tokens 额度,后续随着迭代次数的增加,递减这个配额,降低它对其它迭代的影响。
两阶段流水线的 chunked-prefills 运作流程如下:
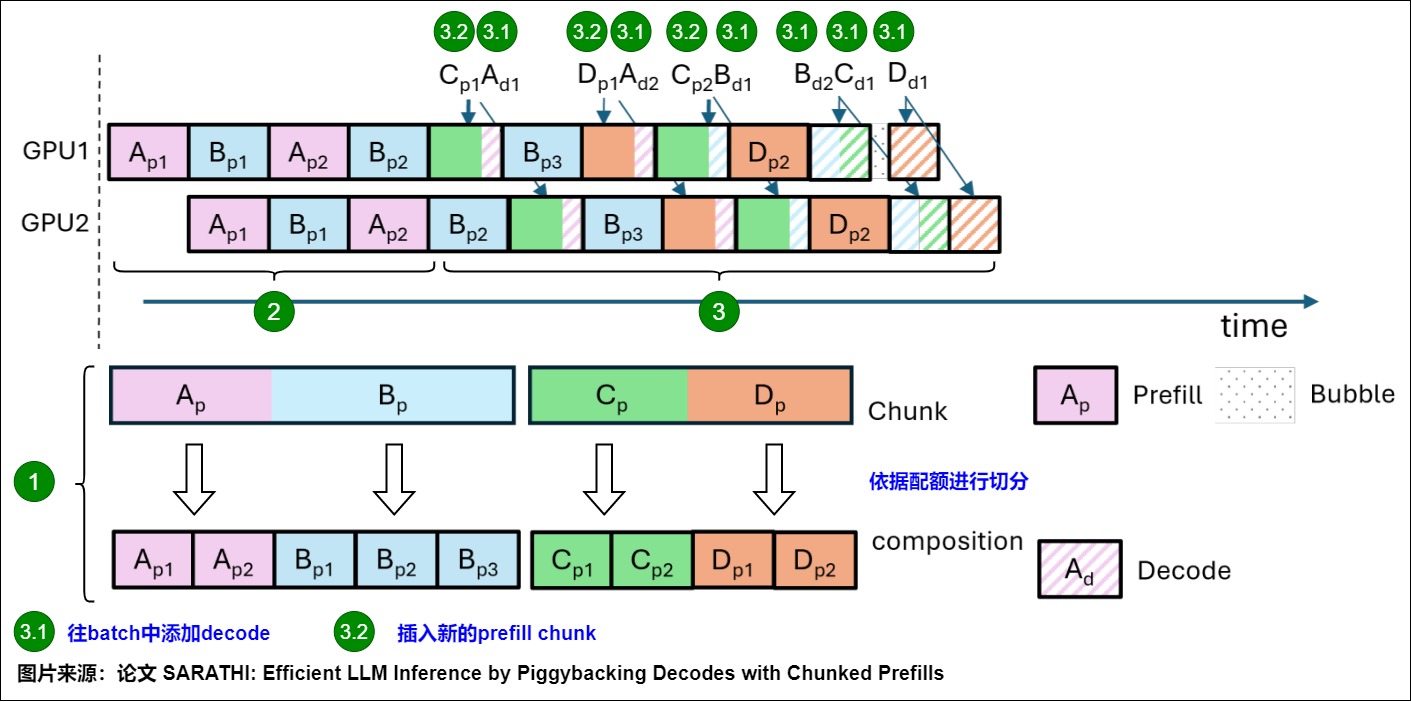
具体步骤是:
-
依据 GPU 的性能来确定每个 batch 中最多能处理的 tokens 数量。对应上图标号 1。图上有 4 个请求(A,B,C,D),被分别拆分成小块(chunk)。
-
当整个系统刚启动时,batch 中只有做 prefill 的序列。系统会依据整个 prefill 的长度预先分配好 KV cache 空间,这确保在这条 prefill 的后续迭代中,一定有充足的 KV Cache 空间。对应上图标号2。
-
往 batch 中添加需要做 decode 的序列,直到 KV Cache 空间不足(因为 decode 操作需要有对应的 KV Cache)。对应上图标号 3.1。同时也要根据这个 batch 中剩余的 tokens 预算,对需要做 prefill 的序列做 chunk 切割,把对应的 prefill tokens 添加进 batch 中。对应上图标号3.2。
比如上图中产生了 Ad 1 这个需要做 decode 的迭代。为了进一步处理 Ad 1,此时需要在 A 所在 batch 中分配 1 token 的配额给 Ad 1。同时也要去等待队列中按 FCFS(先到先服务)的原则找出请求 C,依据配额比例把 C 切分成 Cp 1 和 Cp2,然后把 Cp1放到 batch 中。
-
推理的每一步后,scheduler 都会重新组建 batch。因为 Sarathi-Serve 依然采用的是 iteration-level schedules。
我们针对上图,再次看看当 A 做完 prefill 之后,Orca 和 Sarathi 的区别。
- Orca 在硬件资源允许的情况下,会让 CD 做 prefill,AB 继续做 decode。但由于 decode 和 prefill 的完整序列绑定,也使得整个 decode 的计算时间变长了。所以这其实也算是一种 decode 暂停。
- Sarathi-serve 也允许 decode 和 prefill 一起做,但是它通过合理控制每个 batch 中 prefill tokens 的数量,使得 decode 阶段几乎没有延迟。这样即保了延迟,又保了吞吐。
分析
在 Linear 层,Decode 和 Prefil 可以一起执行,在 Attention 阶段分开执行,不过在很多场景下,Attention 时间占比比较小。这样就可以将 Decode 和 Prefill 一起变成计算密集型任务。此时 Decode 应该是凑批越大越好。但是同时带来的问题就是,Decode 的时延会比较高。所以需要在吞吐和时延之间有个平衡。在 Prefill 上,达到 GPU 计算瓶颈之后,更长的序列会使得 Prefill 时延陡增,所以在遇到这个拐点之后,Perfill 吞吐不再增加。这个值就是我们需要找到的 Chunk Size 值,Decode + Prefill 的总 Token Size 应该小于等于这个 Chunk Size,但是这个 Chunk Size 不一定很好寻找。而且 Decode 和 Prefill 的请求密度,不一定能达到最完美的比例。最完美的比例就是:在 Prefill 的每一轮执行中,Decode 都能凑批执行。如果 Decode 的密度高,那么可能 Decode 会单独运行。如果 Prefill 密度高,那么 Prefill 会单独运行。
另外,做了 chunked prefill 后,prefill 的开销会略微增大。因为在计算后续 chunk 时,需要把这些 chunk’ 对应的 KV 不断从 GPU memory 中读到 kernel 中。不做 chunked prefill 时,这些 KV 始终在 kernel 中。做 chunked prefill 的好处是,采用 piggyback 的方式捎带 decode 到 chunk 的 bubble 后,可以直接复用 prefill 阶段加载的模型参数。这几乎可以让 decode 从一个 memory bound 操作转换为一个 compute bound 操作。
chunked-prefills VS 分离式推理架构
我们可以看到,在使用 chunked-prefills 的策略下,通过合理划分 prefill tokens 和 decode tokens 比例,似乎也能同时保全 TTFT 和 TPOT/TBT,利用好 GPU。那么在这样的前提下,分离式推理架构还有什么优势呢?
其实,由于 Chunked Prefill 的提出,Prefill 和 Decode 节点的边界已经模糊了起来。Mooncake 论文就指出,设计一个单独的弹性预填充池的必要性和最佳实践仍然存在争议。随着分块预填充的引入,这种分离是否仍然必要?因为 Chunked Prefill 有两个明显的好处:1)没有分离,所有节点都被平等对待,使调度更容易;2) 在解码批中嵌入分块预填充可以提高解码批的计算强度,从而获得更好的 MFU。
Mooncake 继续保留了分离架构(使用独立的 Prefill 节点)。只有当请求可以在不分块(比如特别短的 prompt,可以直接一次性加入到 decode 的 continues batch 里提升 MFU)、且不影响 TBT SLO 的情况下转发时,请求的预填充才会内联到解码批中。这一决定有两个主要原因:1)预填充节点需要不同的跨节点并行设置来处理长上下文。2)它提供了一个保存 VRAM 的独特机会。

另外也许还有如下几点原因:
- 分块预填充会导致预填充的计算开销,因此选择明显低于 GPU 饱和点的块大小会延长预填充任务的执行时间。
- 仍然存在 prefill 阶段无法最大化 MFU 的可能。因为在 chunk-prefill 中,我们只是用 profiling 估算出在特定设备上一个 batch 的最大 tokens 配额,这些 tokens 包括 prefill 和 decode。这个 size 是对整体的,而不是单独对 prefill 或 decode 的。而且如果序列长度除不尽 tiles 尺寸,则又会产生额外的计算开销。
- 即使块大小被优化到几乎最大化 GPU 使用率,分块预填充也会显著增加预填充任务的内存访问量,因为需要将 KV Cache 从 GPU 的 HBM 加载到 SRAM 以用于每个后续块。而且长序列可能会持久地占据着 KV cache 的存储空间以及 gpu 的计算资源。
至于 TPOT,将预填充和解码在批次中合并实际上会降低所有这些解码任务的速度。
总之,分块预填充可能有助于最大化整体吞吐量,但由于动态分割无法完全解耦预填充和解码操作,会导致资源争用以及 TTFT 与 TPOT 之间的妥协。当应用程序无法在 TTFT 和 TPOT 之间进行权衡,而是要同时遵守这两者时,解耦就成为更好的选择。
所以,基于以上这些对 chunked-prefills 策略缺陷的猜想,或许使用分离式架构,对 prefill 阶段独立开发一套策略,可能可以更加针对性地解决以上问题。当然,这也取决于各策略的具体实现、业务场景和真实的实验效果。
我们接下来就看看分离式推理架构。
注:笔者并非说明分离式推理架构就一定比融合式更好,而是各有优劣。比如,论文“Injecting Adrenaline into LLM Serving: Boosting Resource Utilization and Throughput via Attention Disaggregation”就指出了 LLM 服务系统中的 PD 分离导致了严重的 GPU 资源浪费的问题。具体来说,运行计算密集型 Prefill 阶段的 GPU 的 HBM 容量和带宽的利用率较低。内存密集型的 Decode 阶段则面临算力资源利用率低的问题。该论文也给出了改进方案 Adrenaline。
-
No backlinks found.