Blockwise Parallel Decoding
3.1 动机
BPD 旨在解决 Transfomer-based Decoder 串行贪心解码的低计算效率问题:在序列生成时是串行的一个一个 Token 的生成,计算量和生成结果所需的时间与生成的 Token 数目成正比。
我们接下来看看 BPD 的出发点和思路。
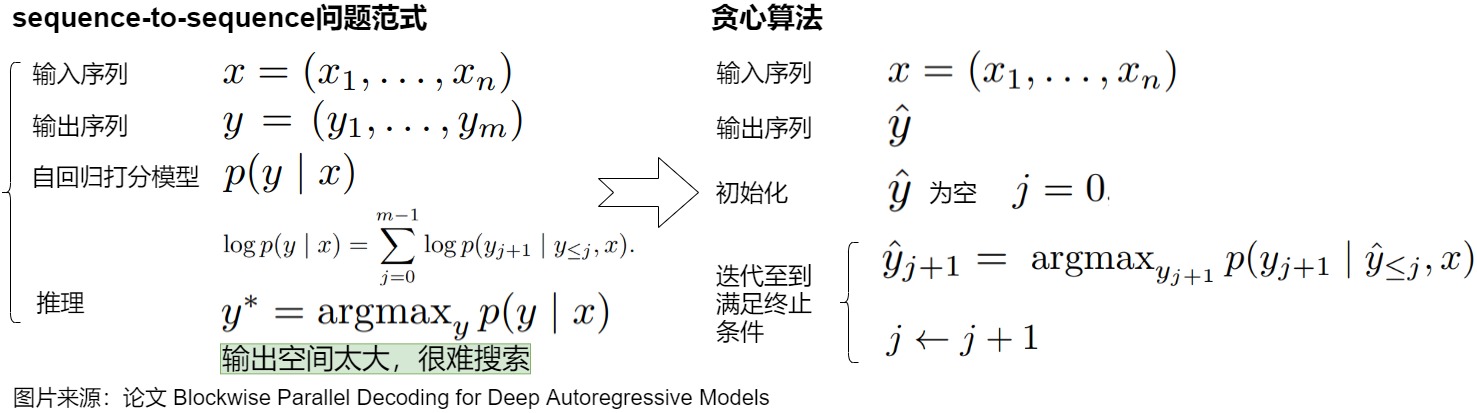
上图是贪心解码的展示。贪心解码效率很高,但可能无法找到全局最优,而且存在很多问题,具体如下。
- 假设输出序列的长度为 m,那么 Autoregressive Decoding 要执行 m 步才能获得最终结果,随着模型的增大,每一步的时延也会增大,整体时延也会放大至少 m 倍。
- 因为每次进行一个 token 生成的计算,需要搬运全部的模型参数和激活张量,这使解码过程严重受限于内存带宽。
为了克服上述限制,BPD 的改进动机如下。
- 作者期望通过 n 步就可完成整个预测,其中 n 远小于 m。
- 但是如何打破串行解码魔咒,并行产生后 k 个 token?因为语言模型都是预测下一个 token,如果我们有 k-1 个辅助模型,每个模型可以根据输入序列跳跃地预测后 2 到 k 个位置的 token。那么,辅助模型和原始模型就有可能独立运行,从而并行生成后 k 个 token。
3.2 思路
论文提出了针对深度自回归模型的并行解码技术——分块并行解码(Blockwise Parallel Decoding)方案。该方案通过训练辅助模型(通过在原始模型的 Decoder 后面增添少量参数),使得模型能够预测未来位置的输出(并行地预测并验证后 k 个 token),然后利用这些预测结果来跳过部分贪心解码步骤,从而加速解码过程。具体而言,BPD 提出了使用特殊 drafting heads 的 draft-then-verify 范式,其三个阶段分别是 Predict、Verify 和 Accept 阶段。
- Predict 阶段使用“原模型+k-1 个辅助模型”进行 k 个位置 token 的预测。论文将模型原来的单 head(最后用于预测 Token 分布的 MLP)转换为多个 head,第一个 head 为保留原始模型的 head,用于预测下一个 Token,后面新增的 head 分别预测下下一个 Token,下下下一个 Token,相当于一次预测多个 Token。
- Verify(验证)阶段使用原模型并行地验证这 k 个位置上候选词所形成的几种可能。因为已经生成了多个 token,因此在下一次推理的时候,即可使用原模型并行地验证这些 Token 序列(由于模型计算本身是 IO bound,并行验证增加的计算几乎不会增加推理的时延)。Verify 过程会将这些 token 组成 batch,实现合适的 attention mask,一次性获得这个 k 个位置的词表概率。因为第一个 head 就是原始模型的 head,所以结果肯定是对的,这样就可以保证每个 decoding step 实际生成的 Token 数是 >= 1 的,以此达到降低解码次数的目的。另外,在验证同时也可顺带生成新的需要预测的 Token。
- Accept 阶段会接受验证过的最长前缀,附加到原始序列上。此阶段会贪心地选择概率最大的 token,如果验证结果的 token 和 Predict 阶段预测的 token 相同则保留。如果不同,则后面的 token 预测都错误。
需要说明的是,这篇论文的工作只支持贪婪解码(Greedy Decoding),不适合其他的解码算法(而 Speculative Sampling 可以适配 Beam Search),在不牺牲效果的情况下,有效 Token 数可能并不多。而且模型还需要使用训练数据进行微调。因此,Blockwise Parallel Decoding=multi-draft model +top-1 sampling+ parallel verification。受此启发,后续提出的 Speculative Sampling 方法也使用小模型并行预测,大模型验证的方式解决相同的问题。
3.3 架构
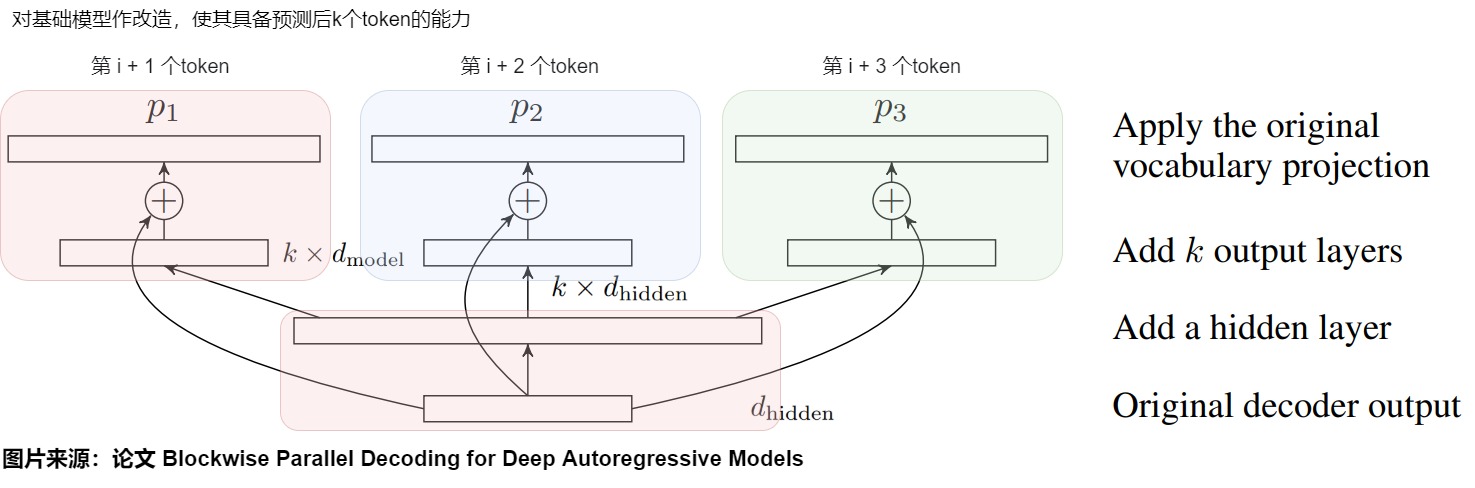
BPD 提出了多头并行解码机制。除了原始模型 p 外,在 Predict 阶段还有几个辅助模型 p 2,…,pk 。用这些模型来辅助预测。但是我们会面临一个问题:如果这些辅助模型采用和原始模型 p 同样的结构并单独训练,那么在 Predict 阶段的计算量就是生成一个 Token 的 K 倍。即使忽略 Verify 阶段,理想情况下整个训练任务的计算量也没有降低。而且这 K 个模型对于内存的占用将是非常惊人的。因此,论文并没有真的构造出 k-1 个辅助模型,即 p 2,…,pk 并非是独立的原始模型的副本。论文是对原始模型略作改造,让这些辅助模型与原始模型 p 1 共享 backbone,然后增加一个隐藏层,针对每个模型 p 1,…,pk 都有独立的输出层。这样就就可以让新模型具备预测后 k 个 token 的能力,能保证 Predict 段实际的计算量与之前单个 Token 预测的计算量基本相当。
具体模型架构如下图所示,在原始模型之上一共增加了三层(从下至上):
- 在原始模型的最后一个 Transformer Decoder 层之后先加上一个隐层,它的输入是 (batch_size, sequence_length, d_model),输出是 (batch_size, sequence_length, k* d_model)。
- 在隐层之后会额外加上几个 head,分别为 p 2,…,pk。Transformer Decoder 层输出的 logit 会先传给隐层进行投影,投影后的输出会分别传给这几个头。这些头的计算结果会分别再与原始模型的 logit 做残差连接。每个头负责预估一个 token,这 k 个头的输出就是 k 个不同位置 token 的 logits。头 1 负责预估 next token,头 2 负责预估 next next token,以此类推。
- 最后再将结果送入到词表投影层(包括一个线性变换和一个 Softmax),预估每个词的概率分布,最终通过某种采样方法生成 token。这个词表投影层是在多 Head 之间共享的。
主干网络 + 头 1(下图红色)是原模型或者说基础模型,也就是预训练的模型。其他 Head 是论文说的辅助网络(auxiliary model)(蓝色和绿色分别是两个辅助网络)。既然可以根据输入序列预测下一个 Token,那么也就可以根据同样的序列预测下下一个,下下下一个 Token,只是准确率可能会低一些而已,这样就可以在 Decoding step 的同时额外生成一个候选序列,让基础模型在下次 Decoding step 来验证即可。
3.4 训练
改造后的模型还需要使用训练数据进行训练。由于训练时的内存限制,论文无法使用对应于 k 个 project layer 输出的 k 个交叉熵损失的平均值作为 loss。而是为每个 minibatch 随机均匀选择其中的一个 layer 输出作为 loss。
训练 FFN 的参数可以使用如下几种方式:
- Frozen Parameters:将原始模型参数冻结,只更新那些新加入的 FFN 层参数。这样预测下一个 token 肯定是准确的,但可能影响辅助模型预测的准确性。
- Finetuning:以原始参数为初始化值对全部参数进行微调,这可能会提高模型的内部一致性,但在最终性能上可能会有所损失。
- Distillation:蒸馏很适合并行解码,因为 teacher 和 student 都有相同的结构。蒸馏数据是原始模型用相同的超参数但不同的随机种子进行 beam search 产生的。
3.5 步骤
下图展示了 blockwise decoding 的三个阶段,分别是 Predict、Verify 和 Accept 阶段。
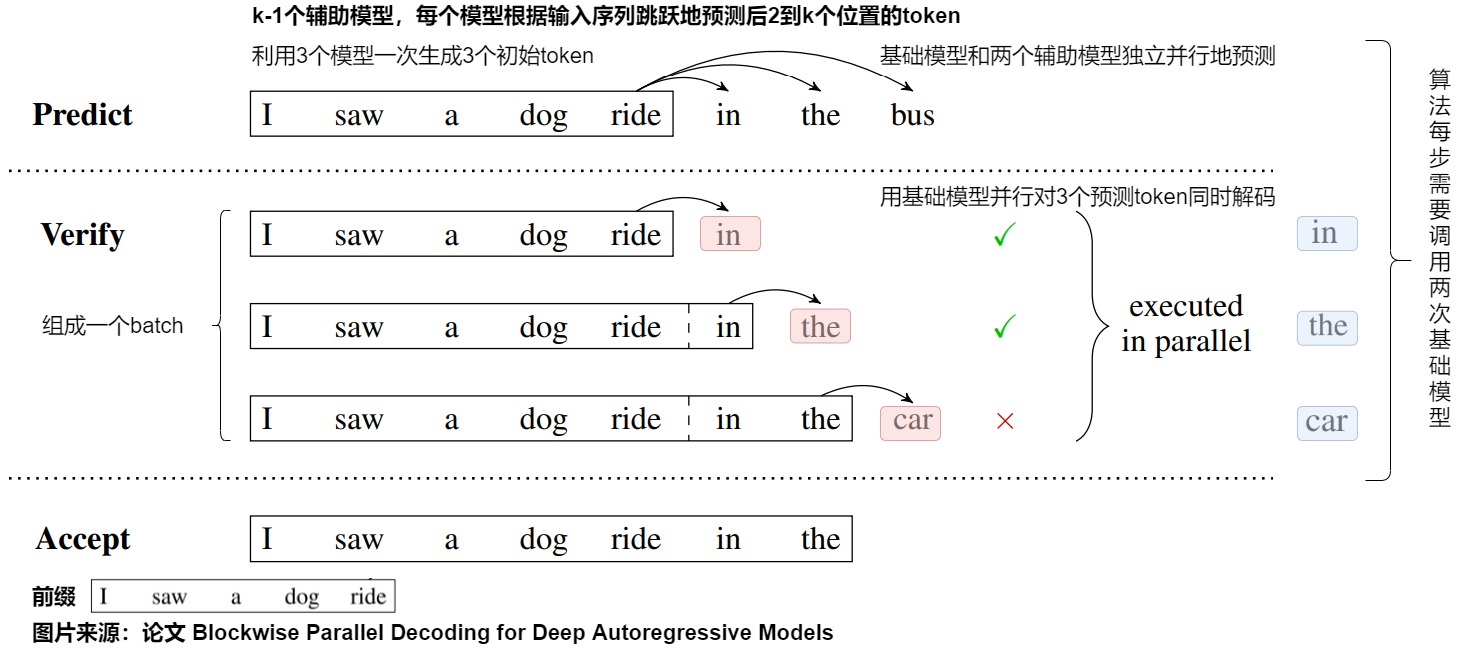
我们基于上图进行详细解读,假设要生成的序列长度为𝑚 ,并行 Head 数为 k。
在 Predict 阶段中。
- 预测即使用原模型+k-1 个辅助模型进行 k 个位置 token 的预测。原模型 p 1 和辅助模型 p 2,…,pk 都是相互独立的,可以并行的执行,因此生成这个 k 个单词的时间和生成一个单词时间基本一致,所以可降低整体生成的步数,也就帮助降低整体时延。
- 针对上图,则是原模型和两个辅助模型独立并行地预测出后三个 token,即“in”、“the”和“bus”。
Verify 阶段中,我们需要在上一步中生成的 K 个单词里选择符合要求的最长前缀。
- 将原始的序列和生成的 𝑘 个 token 拼接成
𝑃𝑎𝑖𝑟<𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒_𝑖𝑛𝑝𝑢𝑡,𝑙𝑎𝑏𝑒𝑙>,这 𝑘 个𝑃𝑎𝑖𝑟<𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒_𝑖𝑛𝑝𝑢𝑡,𝑙𝑎𝑏𝑒𝑙>将组成一个 Batch(也会加上对应的掩码),一次性发给头 1 并行地验证这 k 个位置(看看头 1 生成的 token 是否跟 𝑙𝑎𝑏𝑒𝑙 一致)。 - 针对上图,则是对上一步生成的三个 token 进行打分。具体而言,我们把生成的’in the bus’和前缀拼接后送入原始模型进行一次前向推理运算,上图 Verify 阶段中的黑框里是 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒_𝑖𝑛𝑝𝑢𝑡 ,蓝色的是要验证的 𝑙𝑎𝑏𝑒𝑙 ,箭头指向的红色是预测结果。这样只进行一次前向推理运算,就可以获得后三个输出位置词表的概率分布。
- Batch 的第一个输入是“I saw a dong ride",输出是”in“。
- Batch 的第二个输入是“I saw a dong ride in",输出是”the“。
- Batch 的第三个输入是“I saw a dong ride in the",输出是”car“。
在 Accept 阶段中会选择 𝐻𝑒𝑎𝑑1 预估结果与 𝑙𝑎𝑏𝑒𝑙 一致的最长的 𝑘 个 token,作为可接受的结果。
- 我们可以贪心地选择概率最大的 token 作为验证结果。从左到右看,如果验证结果的 token 和 Predict 阶段预测的 token 相同,则保留这个 token。如果不同,则该 token 和其之后的 token 预测都错误。
- 因为只接受第一个不一致的单词之前的单词,并且验证时候使用的就是原始模型 p 1 ,这也就保证了最终结果是与原始序列预测的结果是完全一致的。
- 针对上图,因为“car“和”bus“不一致,所以只保留”in“和”the“。
假设要生成的序列长度为𝑚 ,并行 Head 数为 𝑘。自回归生成方法中,总共需要 m 步执行。BDP 中,对每 𝑘 个 token 执行一次上述三阶段过程,predict 阶段执行 1 步产出多个 Head 的输出, verify 阶段并行执行 1 步,accept 阶段不耗时。因此在理想情况下(每次生成的 K 个 Token 都能接受),总的解码次数从 m 降低到 2 m/K。这其中由于 Predict 阶段 p 1 和 Verify 阶段都使用的原始模型,所以只使用两次原模型。
3.6 优化
由于存在 Predict 和 Verify 两个阶段,因此即使理想情况下整体的解码次数也是 2 m/K,而不是最理想的 m/K。事实上,由于 Predict 阶段的模型有共同的 backbone,并且 Verify 阶段使用的模型也是原始模型 p 1,因此就可以利用第 n 步的 Verify 结果来直接生成第 n+1 步的 Predict 结果。于是作者们进一步优化这个算法,在原始模型验证时同时预测后 k 个 token。这样 Predict 和 Verify 阶段可以合并,验证同时也获得了后 k 个 token 的候选。
优化之后,模型第一次推理只执行 predict 阶段( 1 步),调用一次原始模型。然后进入 verify 和 predict 重叠的阶段,每次处理序列往前走 𝑘 长度,直到生成终止 token(共 m/k 步,调用 m/k 次原始模型)。即,除了第一次迭代,每次迭代只需调用一次模型 forward,而不是两次,从而将解码所需的模型调用次数减半。进一步将模型调用次数从 2 m/k 减少到 m/k + 1。
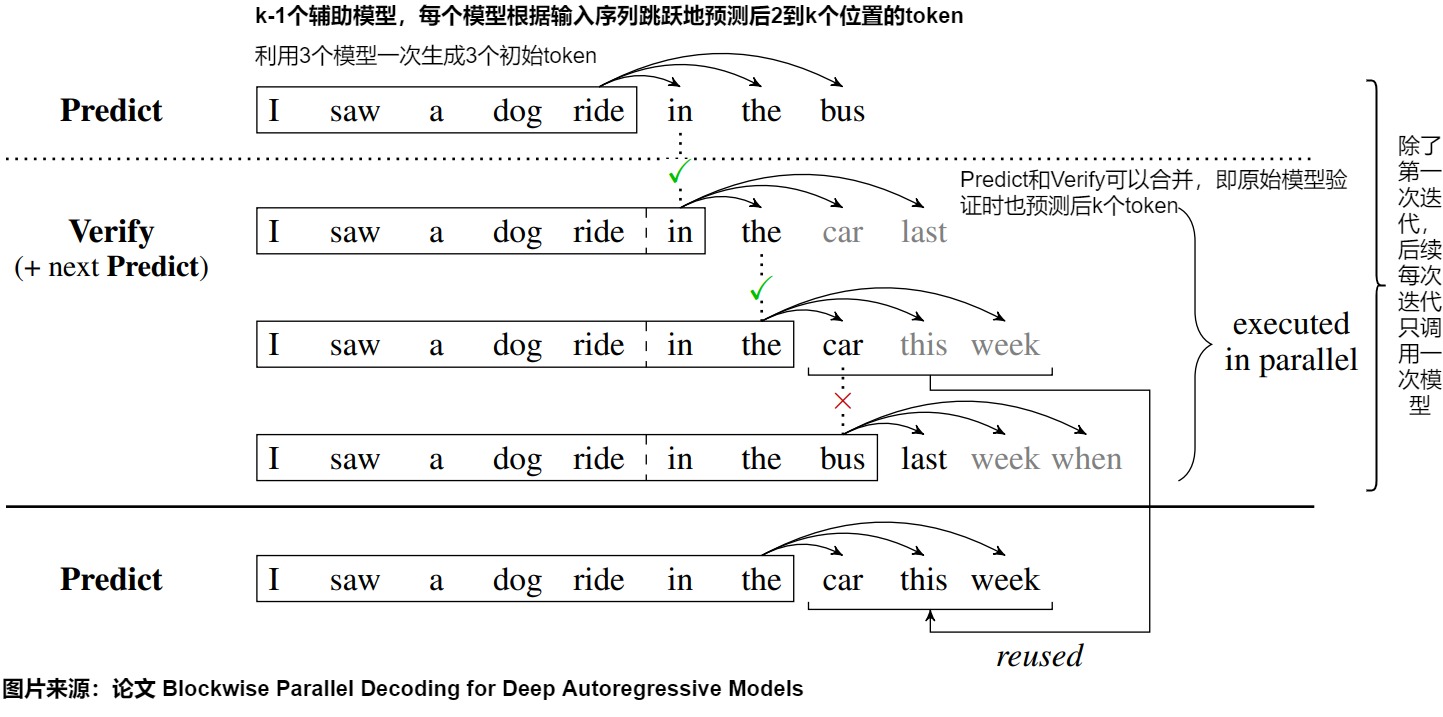
如上图所示,还是以之前的例子为例:
-
Predict 阶段,输入单词 I saw a dog ride in the,进行一次原模型推理,生成了新单词 in,the,bus。
-
Verify 阶段:
- 第一组:输入 I saw a dog ride,待验证单词为 in,实际预测得到 in,the,car,last,第一个单词的 Top 1 为 in,结果相同,接受 in 这个单词
- 第二组:输入 I saw a dog ride in,待验证单词为 the,实际预测得到 the,car,this,week,第一个单词的 Top 1 为 the,结果相同,接受 the 这个单词
- 第三组:输入 I saw a dog ride in the,待验证单词为 car,实际预测得到 bus,last,week,when,第一个单词的 Top 1 为 bus,结果不相同,不接受 car 这个单词。
-
Accept 阶段。因为第三组的 bus 和 car 不相同,所以不接受第三组的结果,接受第二组的结果。因此可以把 car,this,week 作为新的 Predict 结果,继续进行 Verify。
3.7 收益
我们接下来看看收益。
这种方案之所以可以加速解码,在于 Verify 阶段可以用基础模型 p 1 并行对 k 个预测 token 进行同时解码。因为每个迭代 Predict 阶段产生 k 个 token 可以看成一个 block,故这种方法被称为 blockwise parallel decoding。这种方法推理时得到的结果和自回归方式解码的结果一样,因此没有任何生成效果的精度损失。
Blockwise Decoding 的速度取决于执行模型 forward 的次数。在访存受限的情况下,对”I saw a dog ride”进行 forward 运算的时间和对“I saw a dog ride in the car”进行 forward 运算的时间近似相同,因为它们都需要访问模型参数和 KV Cache,多出几个 tokens 带来的激活访存开销显得微不足道。
参考资料
- Blockwise Parallel Decoding for Deep Autoregressive Models
-
No backlinks found.