Traffic Control
流量控制(Traffic Control, tc)是 Linux内核提供的流量限速、整形和策略控制机制。
它以 qdisc-class-filter的树形结构来实现对流量的分层控制 :
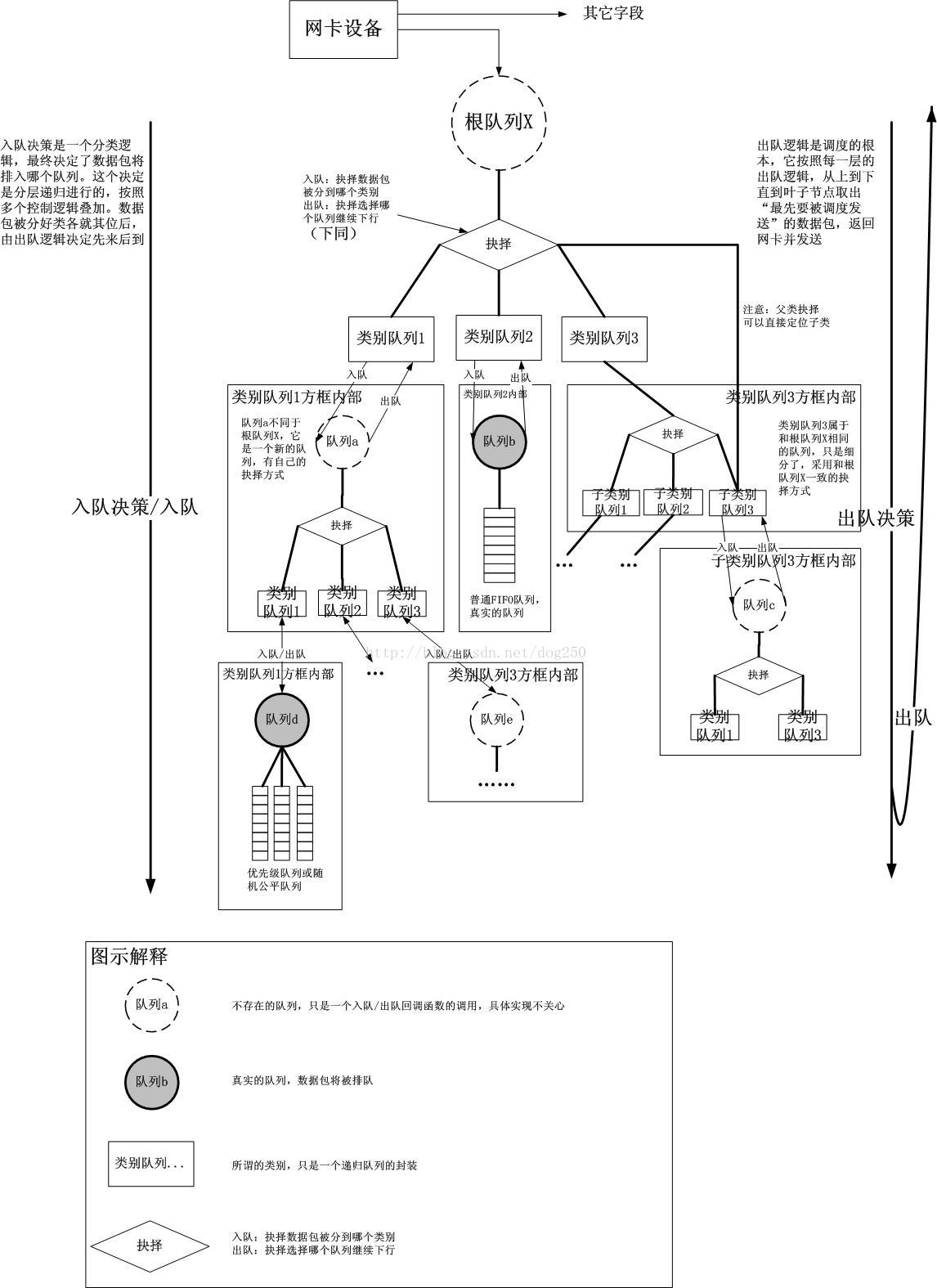
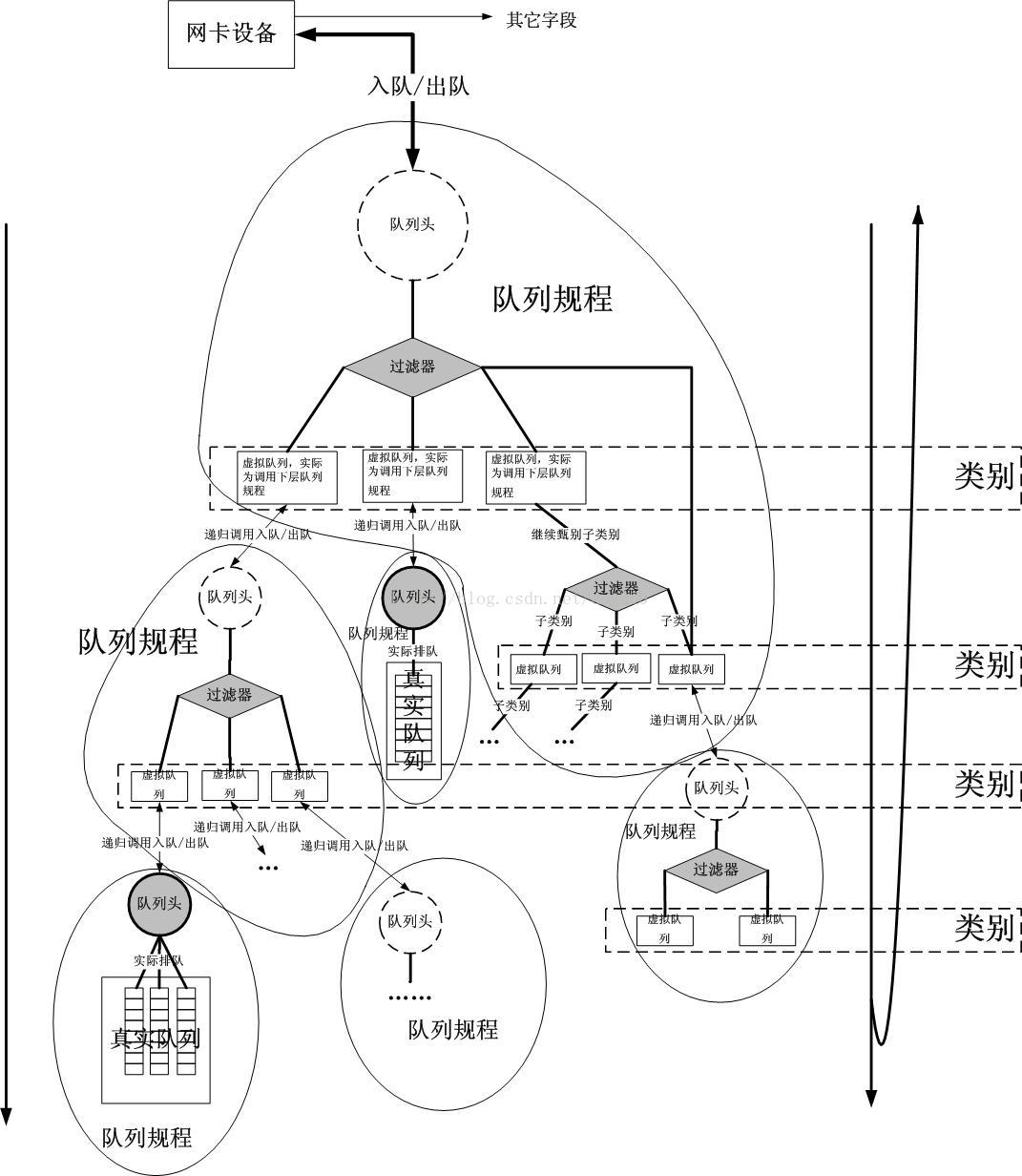
tc最佳的参考就是Linux Traffic Control HOWTO,详细介绍了 tc 的原理和使用方法。
基本组成
从上图中可以看到,tc 由 qdisc、fitler和 class三部分组成:
qdisc通过队列将数据包缓存起来,用来控制网络收发的速度class用来表示控制策略filter用来将数据包划分到具体的控制策略中
qdisc
qdisc,全称是 queueing discipline,通过队列将数据包缓存起来,用来控制网络收发的速度。实际上,每个网卡都有一个关联的 qdisc。每当内核需要将报文分组从网卡发送出去,都会首先将该报文分组添加到该网卡所配置的队列中,由该队列决定报文分组的发送顺序。因此可以说,所有的流量控制都发生在队列中。它包括以下几种:
- 无分类 qdisc(只能应用于 root 队列)
[p|b]fifo:简单先进先出pfifo_fast:根据数据包的tos将队列划分到 3 个band,每个band内部先进先出red:Random Early Detection,带带宽接近限制时随机丢包,适合高带宽应用sfq:Stochastic Fairness Queueing,按照会话对流量排序并循环发送每个会话的数据包tbf:Token Bucket Filter,只允许以不超过事先设定的速率到来的数据包通过 , 但可能允许短暂突发流量朝过设定值
- 有分类 qdisc(可以包括多个队列)
cbq:Class Based Queueing,借助EWMA(exponential weighted moving average, 指数加权移动均值 ) 算法确认链路的闲置时间足够长 , 以达到降低链路实际带宽的目的。如果发生越限 ,CBQ就会禁止发包一段时间。htb:Hierarchy Token Bucket,在tbf的基础上增加了分层prio:分类优先算法并不进行整形 , 它仅仅根据你配置的过滤器把流量进一步细分。缺省会自动创建三个FIFO类。
注意,一般说到 qdisc 都是指 egress qdisc。每块网卡实际上还可以添加一个 ingress qdisc,不过它有诸多的限制
ingress qdisc不能包含子类,而只能作过滤ingress qdisc只能用于简单的整形
如果相对 ingress方向作流量控制的话,可以借助 ifb( Intermediate Functional Block) 内核模块。因为流入网络接口的流量是无法直接控制的,那么就需要把流入的包导入(通过 tc action)到一个中间的队列,该队列在 ifb 设备上,然后让这些包重走 tc 层,最后流入的包再重新入栈,流出的包重新出栈。
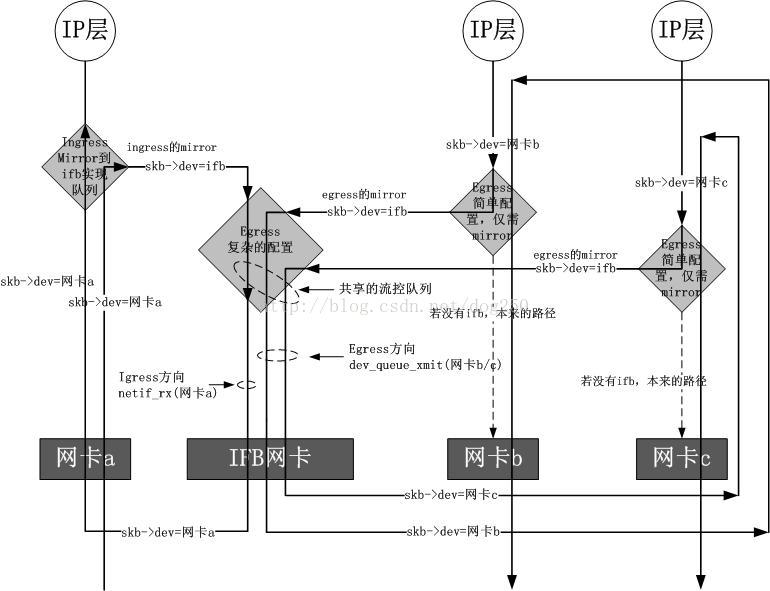
filter
filter用来将数据包划分到具体的控制策略中,包括以下几种:
u32:根据协议、IP、端口等过滤数据包fwmark:根据iptables MARK来过滤数据包tos:根据tos字段过滤数据包
class
class用来表示控制策略,只用于有分类的 qdisc上。每个 class要么包含多个子类,要么只包含一个子 qdisc。当然,每个 class还包括一些列的 filter,控制数据包流向不同的子类,或者是直接丢掉。
使用 TC
在 Linux 中,流量控制都是通过 TC 这个工具来完成的。通常,要对网卡进行流量控制的配置,需要进行如下的步骤:
- 为网卡配置一个队列; - 在该队列上建立分类 - 根据需要建立子队列和子分类 - 为每个分类建立过滤器
在 Linux 中,可以配置很多类型的队列,比如 CBQ、HTB 等,其中 CBQ 比较复杂,不容易理解。HTB( Hierarchical Token Bucket )是一个可分类的队列, 与其他复杂的队列类型相比,HTB 具有功能强大、配置简单及容易上手等优点。在 TC 中,使用"major:minor"这样的句柄来标识队列和类别,其中 major 和 minor 都是数字。
对于队列来说,minor 总是为 0,即"major:0"这样的形式,也可以简写为"major: “比如,队列 1:0 可以简写为 1:。需要注意的是,major 在一个网卡的所有队列中必须是惟一的。对于类别来说,其 major 必须和它的父类别或父队列的 major 相同,而 minor 在一个队列内部则必须是惟一的(因为类别肯定是包含在某个队列中的)。举个例子,如果队列 2:包含两个类别,则这两个类别的句柄必须是 2:x 这样的形式,并且它们的 x 不能相同,比如 2:1 和 2:2。
下面,将以 HTB 队列为主,结合需求来讲述 TC 的使用。假设 eth0 出口有 100mbit/s 的带宽,分配给 WWW、E-mail 和 Telnet 三种数据流量,其中分配给 WWW 的带宽为 40Mbit/s,分配给 Email 的带宽为 40Mbit/s,分配给 Telnet 的带宽为 20Mbit/S。
创建 HTB 队列
有关队列的 TC 命令的一般形式为:
|
|
首先,需要为网卡 eth0 配置一个 HTB 队列,使用下列命令:
|
|
- 命令中的
add表示要添加, dev eth0表示要操作的网卡为 eth0。root表示为网卡 eth0 添加的是一个根队列。handle 1:表示队列的句柄为 1: 。htb表示要添加的队列为 HTB 队列。- 命令最后的
default 11是 htb 特有的队列参数,意思是所有未分类的流量都将分配给类别 1:11。
为根队列创建相应的类别
有关类别的 TC 命令的一般形式为:
|
|
可以利用下面这三个命令为根队列 1 创建三个类别,分别是 1:11、1:12 和 1:13,它们分别占用 40、40 和 20mb[t 的带宽。
|
|
parent 1:表示类别的父亲为根队列 1:classid1:11表示创建一个标识为 1:11 的类别,rate 40mbit表示系统将为该类别确保带宽 40mbit,ceil 40mbit,表示该类别的最高可占用带宽为 40mbit。
为各个类别设置过滤器
有关过滤器的 TC 命令的一般形式为:
|
|
由于需要将 WWW、E-mail、Telnet 三种流量分配到三个类别,即上述 1:11、1:12 和 1:13,因此,需要创建三个过滤器,如下面的三个命令:
|
|
protocol ip表示该过滤器应该检查报文分组的协议字段。prio 1表示它们对报文处理的优先级是相同的,对于不同优先级的过滤器,系统将按照从小到大的优先级顺序来执行过滤器,对于相同的优先级,系统将按照命令的先后顺序执行。这几个过滤器还用到了 u32 选择器(命令中 u32 后面的部分)来匹配不同的数据流。以第一个命令为例,判断的是 dport 字段,如果该字段与 Oxffff 进行与操作的结果是 8O,则flowid 1:11表示将把该数据流分配给类别 1:11。更加详细的有关 TC 的用法可以参考 TC 的手册页。
复杂的实例
在上面的例子中, 三种数据流(www、Email、Telnet)之间是互相排斥的。当某个数据流的流量没有达到配额时,其剩余的带宽并不能被其他两个数据流所借用。在这里将涉及如何使不同的数据流可以共享一定的带宽。
首先需要用到 HTB 的一个特性, 即对于一个类别中的所有子类别,它们将共享该父类别所拥有的带宽,同时,又可以使得各个子类别申请的各自带宽得到保证。这也就是说,当某个数据流的实际使用带宽没有达到其配额时,其剩余的带宽可以借给其他的数据流。而在借出的过程中,如果本数据流的数据量增大,则借出的带宽部分将收回,以保证本数据流的带宽配额。
下面考虑这样的需求,同样是三个数据流 WWW、E-mail 和 Telnet, 其中的 Telnet 独立分配 20Mbit/s 的带宽。另一方面,WWW 和 SMTP 各自分配 40Mbit/s 的带宽。同时,它们又是共享的关系,即它们可以互相借用带宽。
需要的 TC 命令如下:
|
|
这里为根队列 1 创建两个根类别,即 1:1 和 1:2,其中 1:1 对应 Telnet 数据流,1:2 对应 80Mbit 的数据流。然后,在 1:2 中,创建两个子类别 1:21 和 1:22,分别对应 WWW 和 E-mail 数据流。由于类别 1:21 和 1:22 是类别 1:2 的子类别,因此他们可以共享分配的 80Mbit 带宽。同时,又确保当需要时,自己的带宽至少有 40Mbit。
从这个例子可以看出,利用 HTB 中类别和子类别的包含关系,可以构建更加复杂的多层次类别树,从而实现的更加灵活的带宽共享和独占模式,达到企业级的带宽管理目的。
htb 示例
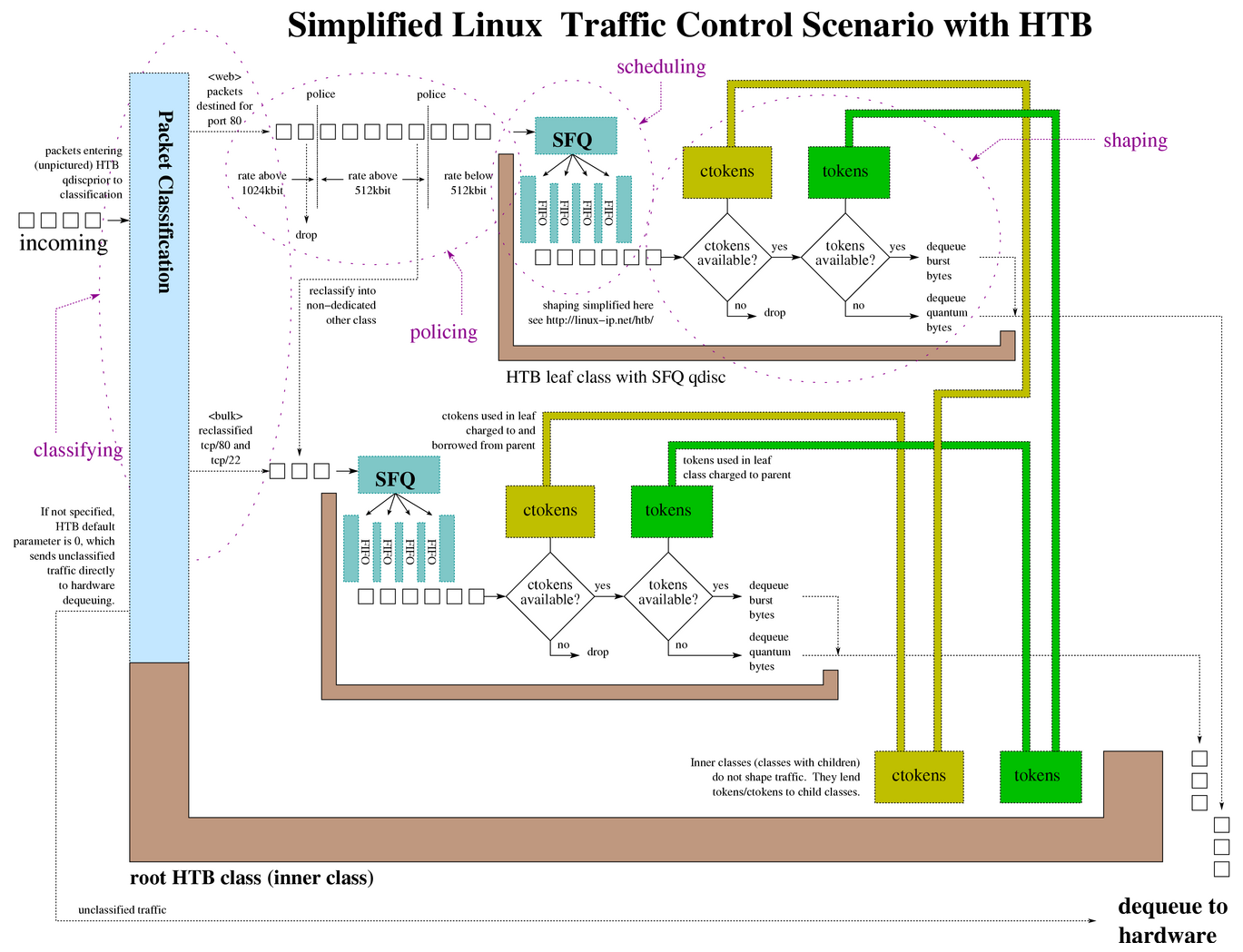
|
|
ifb 示例
|
|
参考文档
-
No backlinks found.