Terraform
Terraform 是一个 infrastructure as code 工具,可以用来 build/change/version 基础设施 (cloud and on-prem)。Terraform 通过和各个云平台的 API 操作,可以实现云上资源的变更。
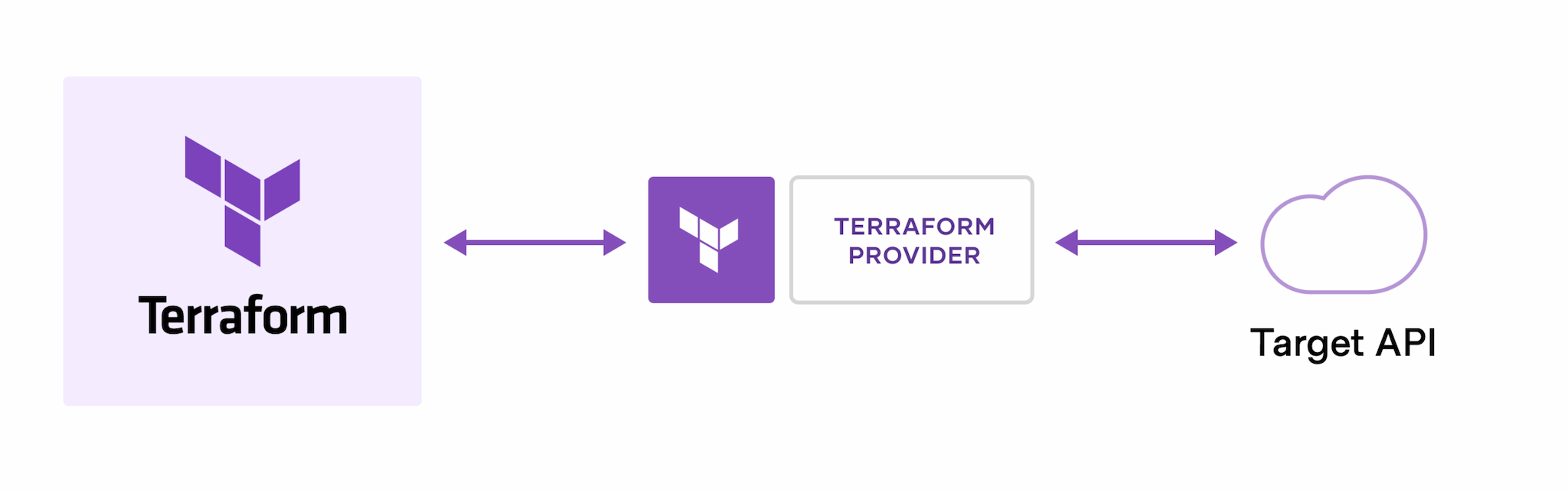
Introduction
Workflow
Terraform 的 workflow 分为三个阶段:
- write: 通过 HCL 语言定义基础设施
- plan: 执行计划,可以描述具体会创建/更新和删除那些云上资源
- apply: 通过 plan 之后,则会真正与 API 交互执行 infrastructure 的变化
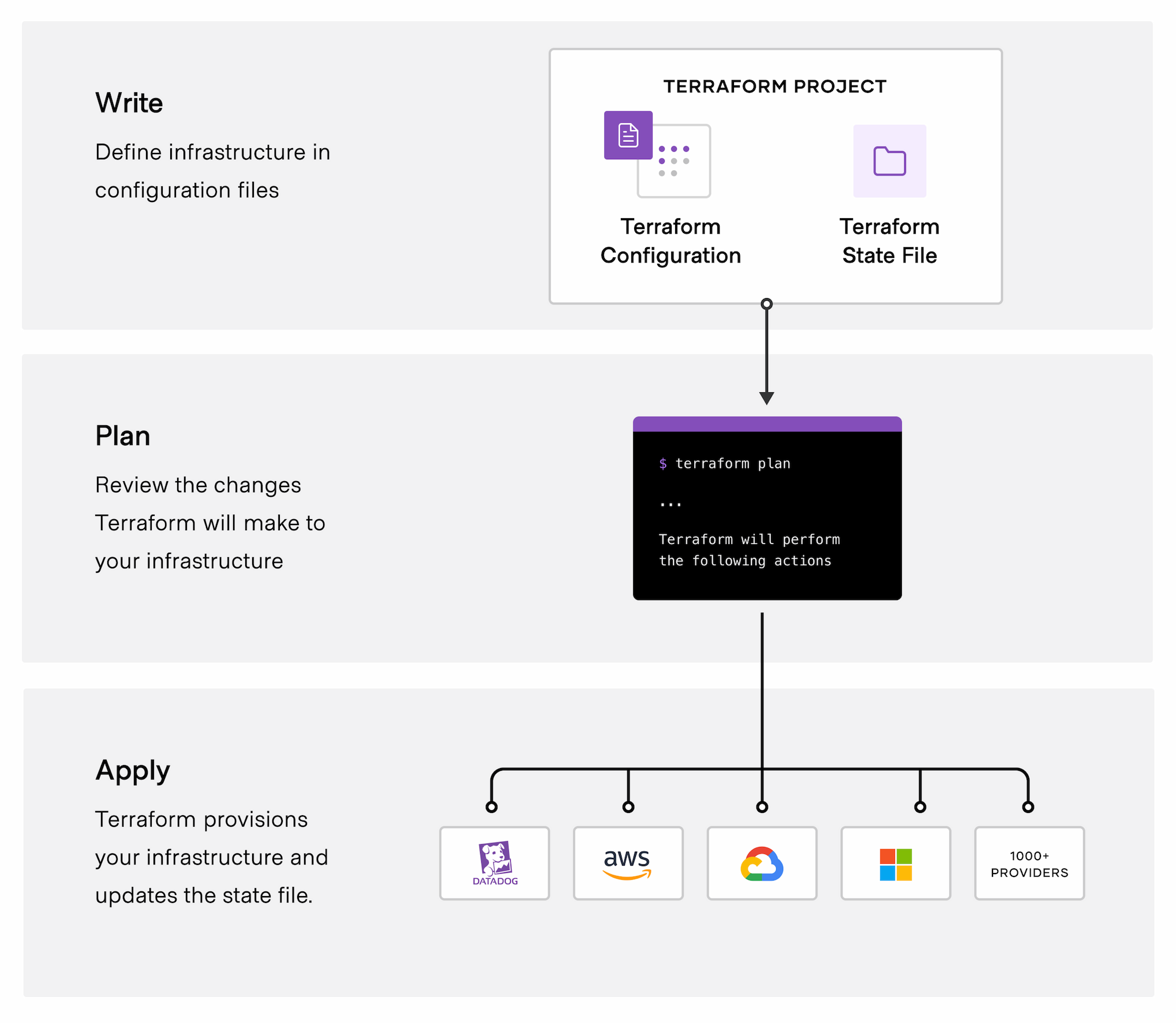
Alternatives
Terraform 的优势在于:
- Manage any infrastructure
- Track your infrastructure
- Automatic changes
- Standardize configurations
- Collaborate
Chef, Puppet, etc
https://developer.hashicorp.com/terraform/intro/vs/chef-puppet
CloudFormation, Heat, etc
Boto, Fog, etc
Custom Solutions
Terraform Language
Terraform 语言的主要目的就是声明 resource,resource 代表了基础设施的对象。其语法定义如下所示,只含有很基础的一些元素:
|
|
- Blocks: 是其他内容的容器,通常代表一些 object 的配置,每个 block 都有一个 block type,可能会有 0 个或者多个 labels,也会有一个 block body 包含任意数目的 arguments 和 nested blocks
- Arguments: 给一个 name 对应的 value
- Expressions: 代表一个 value
以下是一个 AWS 上的简单示例
|
|
Files and Directories
terraform 代码以 tf 后缀结尾,也有 tf.json 后缀结尾的 Terraform JSON 变种,此处不讨论。
A module is a collection of .tf and/or .tf.json files kept together in a directory.
module 只考虑一个目录中顶层的配置文件,目录下的 nested directory 被看作是完全独立的其他 module。module 可以通过 module calls 来显示包含其他的 modules。这些子 module 可以是本地的目录,也可以是来自于 Terraform Registry。
Root Module
Terraform always runs in the context of a single root module
Override Files
一般情况下,如果两个 tf 文件同时定义同一个 object,Terraform 会返回错误。但是 Terraform 同时也提供了一种 Override Files 的机制来允许覆盖。新的文件通常以 override.tf 命名。具体的覆盖规则可以参考 Override Files
Dependency Lock File Terraform 目前会有两种外部依赖:
- Providers: Provider 会有自己的版本
- Modules: 依赖于 remote modules,也有自己的版本
目前 Terraform 通过 .terraform.lock.hcl 文件记录当前基础设施所依赖的远程版本。具体参考 Dependency Lock File
Syntax
这里讲的仍然是 HCL 的语法,但我们只讲一些关键语法。如果读者有兴趣了解完整信息可以访问 HCL 语法规约
参数
参数赋值就是将一个值赋给一个特定的名称:
image_id = "abc123"
等号前的标识符就是参数名,等号后的表达式就是参数值。参数赋值时 Terraform 会检查类型是否匹配。参数名是确定的,参数值可以是确定的字面量硬编码,也可以是一组表达式,用以通过其他的值加以计算得出结果值。
块
一个块是包含一组其他内容的容器,例如:
resource "aws_instance" "example" {
ami = "abc123"
network_interface {
# ...
}
}
一个块有一个类型(上面的例子里类型就是 resource)。每个块类型都定义了类型关键字后面要跟多少标签,例如 resource 块规定了后面要跟两个标签——在例子里就是 aws_instance和 example。一个块类型可以规定任意多个标签,也可以没有标签,比如内嵌的 network_interface块。
在块类型及其后续标签之后,就是块体。块体必须被包含在一对花括号中间。在块体中可以进一步定义各种参数和其他的块。
Terraform 规范定义了有限多个顶级块类型,也就是可以游离于任何其他块独立定义在配置文件中的块。大部分的 Terraform 功能(例如 resource, variable, output, data 等)都是顶级块。
标识符
参数名、块类型名以及其他 Terraform 规范中定义的结构的名称,例如 resource、variable 等,都是标识符。
合法的标识符可以包含字母、数字、下划线(_)以及减号(-)。标识符首字母不可以为数字。
要了解完整的标识符规范,请访问Unicode 标识符语法。
注释
Terraform 支持三种注释:
#单行注释,其后的内容为注释//单行注释,其后的内容为注释/*和*/,多行注释,可以注释多行
默认情况下单行注释优先使用#。自动化格式整理工具会自动把//替换成#。
编码以及换行
Terraform 配置文件必须始终使用 UTF-8 编码。分隔符必须使用 ASCII 符号,其他标识符、注释以及字符串字面量均可使用非 ASCII 字符。
Terraform 兼容 Unix 风格的换行符以及 Windows 风格的换行符,但是理想状态下应使用 Unix 风格换行符。
Types
Terraform 的某些类型之间存在隐式类型转换规则,如果无法隐式转换类型,那么不同类型数据间的赋值将会报错。
Terraform 类型分为原始类型与复杂类型两大类。
原始类型
原始类型分三类:string、number、bool。
string代表一组 Unicode 字符串,例如:"hello"。number代表数字,可以为整数,也可以为小数。bool代表布尔值,要么为true,要么为false。bool值可以被用做逻辑判断。
number 和 bool 都可以和 string 进行隐式转换,当我们把 number 或 bool 类型的值赋给 string 类型的值,或是反过来时,Terraform 会自动替我们转换类型,其中:
true值会被转换为"true",反之亦然false值会被转换为"false",反之亦然15会被转换为"15",3.1415会被转换为"3.1415",反之亦然
复杂类型
复杂类型是一组值所组成的符合类型,有两类复杂类型。
一种是集合类型。一个集合包含了一组同一类型的值。集合内元素的类型成为元素类型。一个集合变量在构造时必须确定集合类型。集合内所有元素的类型必须相同。
Terraform 支持三种集合:
list(...):列表是一组值的连续集合,可以用下标访问内部元素,下标从0开始。例如名为l的list,l[0]就是第一个元素。list类型的声明可以是list(number)、list(string)、list(bool)等,括号中的类型即为元素类型。map(...):字典类型(或者叫映射类型),代表一组键唯一的键值对,键类型必须是string,值类型任意。map(number)代表键为string类型而值为number类型,其余类推。map值有两种声明方式,一种是类似{"foo": "bar", "bar": "baz"},另一种是{foo="bar", bar="baz"}。键可以不用双引号,但如果键是以数字开头则例外。多对键值对之间要用逗号分隔,也可以用换行符分隔。推荐使用=号(Terraform 代码规范中规定按等号对齐,使用等号会使得代码在格式化后更加美观)set(...):集合类型,代表一组不重复的值。
以上集合类型都支持通配类型缩写,例如 list 等价于 list(any),map 等价于 map(any),set 等价于 set(any)。any 代表支持任意的元素类型,前提是所有元素都是一个类型。例如,将 list(number) 赋给 list(any) 是合法的,list(string) 赋给 list(any) 也是合法的,但是 list 内部所有的元素必须是同一种类型的。
第二种复杂类型是结构化类型。一个结构化类型允许多个不同类型的值组成一个类型。结构化类型需要提供一个 schema 结构信息作为参数来指明元素的结构。
Terraform 支持两种结构化类型:
object(...):对象是指一组由具有名称和类型的属性所构成的符合类型,它的 schema 信息由{ <KEY>=<TYPE>, <KEY>=<TYPE>...}的形式描述,例如object({age=number, name=string}),代表由名为"age“类型为number,以及名为"name"类型为string两个属性组成的对象。赋给object类型的合法值必须含有所有属性值,但是可以拥有多余的属性(多余的属性在赋值时会被抛弃)。例如对于object({age=number,name=string})来说,{ age=18 }是一个非法值,而{ age=18, name="john", gender="male" }是一个合法值,但赋值时gender会被抛弃tuple(...):元组类似list,也是一组值的连续集合,但每个元素都有独立的类型。元组同list一样,也可以用下标访问内部元素,下标从0开始。元组 schema 用[<TYPE>, <TYPE>, ...]的形式描述。元组的元素数量必须与 schema 声明的类型数量相等,并且每个元素的类型必须与元组 schema 相应位置的类型相等。例如,tuple([string, number, bool])类型的一个合法值可以是["a", 15, true]
复杂类型也支持隐式类型转换。
Terraform 会尝试转换相似的类型,转换规则有:
object和map:如果一个map的键集合含有object规定的所有属性,那么map可以被转换为object,map里多余的键值对会被抛弃。由map->object->map的转换可能会丢失数据。tuple和list:当一个list元素的数量正好等于一个tuple声明的长度时,list可以被转换为tuple。例如:值为["18", "true", "john"]的list转换为tuple([number,bool, string])的结果为[18, true, "john"]set和tuple:当一个list或是tuple被转换为一个set,那么重复的值将被丢弃,并且值原有的顺序也将丢失。如果一个set被转换到list或是tuple,那么元素将按照以下顺序排列:如果set的元素是string,那么将按照字段顺序排列;其他类型的元素不承诺任何特定的排列顺序。
复杂类型转换时,元素类型将在可能的情况下发生隐式转换,类似上述 list 到 tuple 转换举的例子。
如果类型不匹配,Terraform 会报错,例如我们试图把 object({name = ["Kristy", "Claudia", "Mary Anne", "Stacey"], age = 12})转换到 map(string) 类型,这是不合法的,因为 name 的值为 list,无法转换为 string。
any
any 是 Terraform 中非常特殊的一种类型约束,它本身并非一个类型,而只是一个占位符。每当一个值被赋予一个由 any 约束的复杂类型时,Terraform 会尝试计算出一个最精确的类型来取代 any。
例如我们把 ["a", "b", "c"] 赋给 list(any),它在 Terraform 中实际的物理类型首先被编译成 tuple([string, string, string]),然后 Terraform 认为 tuple 和 list 相似,所以会尝试将它转换为 list(string)。然后 Terraform 发现 list(string) 符合 list(any) 的约束,所以会用 string 取代 any,于是赋值后最终的类型是 list(string)。
由于即使是 list(any),所有元素的类型也必须是一样的,所以某些类型转换到 list(any) 时会对元素进行隐式类型转换。例如将 ["a", 1, "b"] 赋给 list(any),Terraform 发现 1 可以转换到 "1",所以最终的值是 ["a", "1", "b"],最终的类型会是 list(string)。再比如我们想把 ["a", \[\], "b"] 转换成 list(any),由于 Terraform 无法找到一个一个合适的目标类型使得所有元素都能成功隐式转换过去,所以 Terraform 会报错,要求所有元素都必须是同一个类型的。
声明类型时如果不想有任何的约束,那么可以用 any:
variable "no_type_constraint" {
type = any
}
这样的话,Terraform 可以将任何类型的数据赋予它。
null
存在一种特殊值是无类型的,那就是 null。null 代表数据缺失。如果我们把一个参数设置为 null,Terraform 会认为你忘记为它赋值。如果该参数有默认值,那么 Terraform 会使用默认值;如果没有又恰巧该参数是必填字短,Terraform 会报错。null 在条件表达式中非常有用,你可以在某项条件不满足时跳过对某参数的赋值。
object 的 optional 成员
自 Terraform 1.3 开始,我们可以在 object 类型定义中使用 optional 修饰属性。
在 1.3 之前,如果一个 variable 的类型为 object,那么使用时必须传入一个结构完全相符的对象。例如:
variable "an_object" {
type = object({
a = string
b = string
c = number
})
}
如果我们想传入一个对象给 var.an_object,但不准备给 b 和 c 赋值,我们必须这样:
{
a = "a"
b = null
c = null
}
传入的对象必须完全匹配类型定义的结构,哪怕我们不想对某些属性赋值。这使得我们如果想要定义一些比较复杂,属性比较多的 object 类型时会给用户在使用上造成一些麻烦。
Terraform 1.3 允许我们为一个属性添加 optional 声明,还是用上面的例子:
variable "with_optional_attribute" {
type = object({
a = string # a required attribute
b = optional(string) # an optional attribute
c = optional(number, 127) # an optional attribute with default value
})
}
在这里我们将 b 声明为 optional,如果传入的对象没有 b,则会使用 null 作为值;c 不但声明为 optional 的,还添加了 127 作为默认值,传入的对象如果没有 c,那么会使用 127 作为它的值。
optional 修饰符有这样两个参数:
- 类型:(必填)第一个参数标明了属性的类型
- 默认值:(选填)第二个参数定义了 Terraform 在对象中没有定义该属性值时使用的默认值。默认值必须与类型参数兼容。如果没有指定默认值,Terraform 会使用
null作为默认值。
一个包含非 null 默认值的 optional 属性在模块内使用时可以确保不会读到 null 值。当用户没有设置该属性,或是显式将其设置为 null 时,Terraform 会使用默认值,所以模块内无需再次判断该属性是否为 null。
Terraform 采用自上而下的顺序来设置对象的默认值,也就是说,Terraform 会先应用 optional 修饰符中的指定的默认值,然后再为其中可能存在的内嵌对象设置默认值。
例子:带有 optional 属性和默认值的内嵌结构
下面的例子演示了一个输入变量,用来描述一个存储了静态网站内容的存储桶。该变量的类型包含了一系列的 optional 属性,包括 website,不但其自身是 optional 的,其内部包含了数个 optional 的属性以及默认值。
variable "buckets" {
type = list(object({
name = string
enabled = optional(bool, true)
website = optional(object({
index_document = optional(string, "index.html")
error_document = optional(string, "error.html")
routing_rules = optional(string)
}), {})
}))
}
以下给出一个样例 terraform.tfvars 文件,为 var.buckets 定义了三个存储桶:
production配置了一条重定向的路由规则archived使用了默认配置,但被关闭了docs使用文本文件取代了索引页和错误页
production 桶没有指定索引页和错误页,archived 桶完全忽略了网站配置。Terraform 会使用 bucket 类型约束中指定的默认值。
buckets = [
{
name = "production"
website = {
routing_rules = <<-EOT
[
{
"Condition" = { "KeyPrefixEquals": "img/" },
"Redirect" = { "ReplaceKeyPrefixWith": "images/" }
}
]
EOT
}
},
{
name = "archived"
enabled = false
},
{
name = "docs"
website = {
index_document = "index.txt"
error_document = "error.txt"
}
},
]
该配置会产生如下的 variable 值:
- 对
production和docs桶,Terraform 会将enabled设置为true。Terraform 会同时使用默认值配置website,然后使用docs中指定的值来覆盖默认值。 - 对
archived和docs桶,Terraform 会将routing_rules设置为null。当 Terraform 没有读取到optional的属性,并且属性上没有设置默认值时,Terraform 会将这些属性设置为null。 - 对于
archived桶,Terraform 会将website属性设置为buckets类型约束中定义的默认值。
tolist([
{
"enabled" = true
"name" = "production"
"website" = {
"error_document" = "error.html"
"index_document" = "index.html"
"routing_rules" = <<-EOT
[
{
"Condition" = { "KeyPrefixEquals": "img/" },
"Redirect" = { "ReplaceKeyPrefixWith": "images/" }
}
]
EOT
}
},
{
"enabled" = false
"name" = "archived"
"website" = {
"error_document" = "error.html"
"index_document" = "index.html"
"routing_rules" = tostring(null)
}
},
{
"enabled" = true
"name" = "docs"
"website" = {
"error_document" = "error.txt"
"index_document" = "index.txt"
"routing_rules" = tostring(null)
}
},
])
例子:有条件地设置一个默认属性
有时我们需要根据其他数据的值来动态决定是否要为一个 optional 参数设置值。在这种场景下,发起调用的 module 块可以使用条件表达式搭配 null 来动态地决定是否设置该参数。
还是上一个例子中的 variable "buckets" 的例子,使用下面演示的例子可以根据新输入参数 var.legacy_filenames 的值来有条件地覆盖 website 对象中 index_document 以及 error_document 的设置:
variable "legacy_filenames" {
type = bool
default = false
nullable = false
}
module "buckets" {
source = "./modules/buckets"
buckets = [
{
name = "maybe_legacy"
website = {
error_document = var.legacy_filenames ? "ERROR.HTM" : null
index_document = var.legacy_filenames ? "INDEX.HTM" : null
}
},
]
}
当 var.legacy_filenames 设置为 true 时,调用会覆盖 document 的文件名。当它的值为 false 时,调用不会指定这两个文件名,这样就会使得模块使用定义的默认值。
Variables
在前面的例子中,我们在代码中都是使用字面量硬编码的,如果我们想要在创建、修改基础设施时动态传入一些值呢?比如说在代码中定义 Provider 时用变量替代硬编码的访问密钥,或是由创建基础设施的用户来决定创建什么样尺寸的主机?我们需要的是输入变量。
如果我们把一组 Terraform 代码想像成一个函数,那么输入变量就是函数的入参。输入变量用 variable块进行定义:
variable "image_id" {
type = string
}
variable "availability_zone_names" {
type = list(string)
default = ["us-west-1a"]
}
variable "docker_ports" {
type = list(object({
internal = number
external = number
protocol = string
}))
default = [
{
internal = 8300
external = 8300
protocol = "tcp"
}
]
}
这些都是合法的输入参数定义。紧跟 variable 关键字的就是变量名。在一个 Terraform 模块(同一个文件夹中的所有 Terraform 代码文件,不包含子文件夹)中变量名必须是唯一的。我们在代码中可以通过var.<NAME> 的方式引用变量的值。有一组关键字不可以被用作输入变量的名字:
- source
- version
- providers
- count
- for_each
- lifecycle
- depends_on
- locals
输入变量只能在声明该变量的目录下的代码中使用。
输入变量块中可以定义一些属性。
类型
可以在输入变量块中通过 type定义类型,例如:
variable "name" {
type = string
}
variable "ports" {
type = list(number)
}
定义了类型的输入变量只能被赋予符合类型约束的值。
默认值
默认值定义了当 Terraform 无法获得一个输入变量得到值的时候会使用的默认值。例如:
variable "name" {
type = string
default = "John Doe"
}
当 Terraform 无法通过其他途径获得 name 的值时,var.name的值为 "John Doe"。
描述
可以在输入变量中定义一个描述,简单地向调用者描述该变量的意义和用法:
|
|
如果在执行 terraform plan或是 terraform apply时 Terraform 不知道某个输入变量的值,Terraform 会在命令行界面上提示我们为输入变量设置一个值。例如上面的输入变量代码,执行 terraform apply时:
|
|
为了使的代码的使用者能够准确理解输入变量的意义和用法,我们应该站在使用者而非代码维护者的角度编写输入变量的描述。描述并不是注释!
断言
输入变量的断言是 Terraform 0.13.0 开始引入的新功能,在过去,Terraform 只能用类型约束确保输入参数的类型是正确的,曾经有不少人试图通过奇技淫巧来实现更加复杂的变量校验断言。如今 Terraform 终于正式添加了相关的功能。
|
|
condition 参数是一个 bool 类型的参数,我们可以用一个表达式来定义如何界定输入变量是合法的。当 contidion 为 true 时输入变量合法,反之不合法。condition 表达式中只能通过 var.\引用当前定义的变量,并且它的计算不能产生错误。
假如表达式的计算产生一个错误是输入变量验证的一种判定手段,那么可以使用 can 函数来判定表达式的执行是否抛错。例如:
|
|
上述例子中,如果输入的 image_id不符合正则表达式的要求,那么 regex函数调用会抛出一个错误,这个错误会被 can函数捕获,输出 false。
condition表达式如果为 false,Terraform 会返回 error_message中定义的错误信息。error_message应该完整描述输入变量校验失败的原因,以及输入变量的合法约束条件。
在命令行输出中隐藏值
该功能于 Terraofrm v0.14.0 开始引入。
将变量设置为 sensitive 可以防止我们在配置文件中使用变量时 Terraform 在 plan 和 apply 命令的输出中展示与变量相关的值。
Terraform 仍然会将敏感数据记录在状态文件中,任何可以访问状态文件的人都可以读取到明文的敏感数据值。
声明一个变量包含敏感数据值需要将 sensitive 参数设置为 true:
|
|
任何使用了敏感变量的表达式都将被视为敏感的,因此在上面的示例中,resource “some_resource” “a”的两个参数也将在计划输出中被隐藏:
Terraform will perform the following actions:
# some_resource.a will be created
+ resource "some_resource" "a" {
+ name = (sensitive)
+ address = (sensitive)
}
Plan: 1 to add, 0 to change, 0 to destroy.
在某些情况下,我们会在嵌套块中使用敏感变量,Terraform 可能会将整个块视为敏感的。这发生在那些包含有要求值是唯一的内嵌块的资源中,公开这种内嵌块的部分内容可能会暗示兄弟块的内容。
|
|
Provider 还可以将资源属性声明为敏感属性,这将导致 Terraform 将其从常规输出中隐藏。
如果打算使用敏感值作为输出值的一部分,Terraform 将要求您将输出值本身标记为敏感值,以确认确实打算将其导出。
Terraform 可能暴露敏感变量的情况
sensitive 变量是一个以配置文件为中心的概念,值被毫无混淆地发送给 Provider。如果该值被包含在错误消息中,则 Provider 报错时可能会暴露该值。例如,即使 “foo” 是敏感值,Provider 也可能返回以下错误:"Invalid value 'foo' for field"
如果将资源属性用作、或是作为 Provider 定义的资源 ID 的一部分,则 apply 将公开该值。在下面的示例中,前缀属性已设置为 sensitive 变量,但随后该值(“jae”)作为资源 ID 的一部分公开:
|
|
禁止输入变量为空
该功能自 Terraform v1.1.0 开始被引入
输入变量的 nullable 参数控制模块调用者是否可以将 null 分配给变量。
|
|
nullable 的默认值为 true。当 nullable 为 true 时,null 是变量的有效值,并且模块代码必须始终考虑变量值为 null 的可能性。将 null 作为模块输入参数传递将覆盖输入变量上定义的默认值。
将 nullable 设置为 false 可确保变量值在模块内永远不会为空。如果 nullable 为 false 并且输入变量定义有默认值,则当模块输入参数为 null 时,Terraform 将使用默认值。
nullable 参数仅控制变量的直接值可能为 null 的情况。对于集合或对象类型的变量,例如列表或对象,调用者仍然可以在集合元素或属性中使用 null,只要集合或对象本身不为 null。
对输入变量赋值
命令行参数
对输入变量赋值有几种途径,一种是在调用 terraform plan或是 terraform apply命令时以参数的形式传入:
|
|
可以在一条命令中使用多个 -var参数。
参数文件
第二种方法是使用参数文件。参数文件的后缀名可以是 .tfvars或是 .tfvars.json。.tfvars文件使用 HCL 语法,.tfvars.json使用 JSON 语法。
以 .tfvars为例,参数文件中用 HCL 代码对需要赋值的参数进行赋值,例如:
|
|
后缀名为 .tfvars.json的文件用一个 JSON 对象来对输入变量赋值,例如:
|
|
调用 terraform 命令时,通过 -var-file参数指定要用的参数文件,例如:
|
|
|
|
有两种情况,你无需指定参数文件:
- 当前模块内有名为
terraform.tfvars或是terraform.tfvars.json的文件 - 当前模块内有一个或多个后缀名为
.auto.tfvars或是.auto.tfvars.json的文件
Terraform 会自动使用这两种自动参数文件对输入参数赋值。
环境变量
可以通过设置名为 TF_VAR_<NAME> 的环境变量为输入变量赋值,例如:
|
|
在环境变量名大小写敏感的操作系统上,Terraform 要求环境变量中的\与 Terraform 代码中定义的输入变量名大小写完全一致。
环境变量传值非常适合在自动化流水线中使用,尤其适合用来传递敏感数据,类似密码、访问密钥等。
交互界面传值
在前面介绍断言的例子中我们看到过,当我们从命令行界面执行 terraform 操作,Terraform 无法通过其他途径获取一个输入变量的值,而该变量也没有定义默认值时,Terraform 会进行最后的尝试,在交互界面上要求我们给出变量值。
输入变量赋值优先级
当上述的赋值方式同时存在时,同一个变量可能会被赋值多次。Terraform 会使用新值覆盖旧值。
Terraform 加载变量值的顺序是:
- 环境变量
terraform.tfvars文件(如果存在的话)terraform.tfvars.json文件(如果存在的话)- 所有的
.auto.tfvars或者.auto.tfvars.json文件,以字母顺序排序处理 - 通过
-var或是-var-file命令行参数传递的输入变量,按照在命令行参数中定义的顺序加载
假如以上方式均未能成功对变量赋值,那么 Terraform 会尝试使用默认值;对于没有定义默认值的变量,Terraform 会采用交互界面方式要求用户输入一个。对于某些 Terraform 命令,如果执行时带有 -input=false参数禁用了交互界面传值方式,那么就会报错。
复杂类型传值
通过参数文件传值时,可以直接使用 HCL 或是 JSON 语法对复杂类型传值,例如 list 或 map。
对于某些场景下必须使用 -var命令行参数,或是环境变量传值时,可以用单引号引用 HCL 语法的字面量来定义复杂类型,例如:
|
|
由于采用这种方法需要手工处理引号的转义,所以这种方法比较容易出错,复杂类型的传值建议尽量通过参数文件。
Outputs
我们在介绍输入变量时提到过,如果我们把一组 Terraform 代码想像成一个函数,那么输入变量就是函数的入参;函数可以有入参,也可以有返回值,同样的,Terraform 代码也可以有返回值,这就是输出值。
大部分语言的的函数只支持无返回值或是单返回值,但是 Terraform 支持多返回值。在当前模块 apply 一段 Terraform 代码,运行成功后命令行会输出代码中定义的返回值。另外我们也可以通过 terraform output命令来输出当前模块对应的状态文件中的返回值。
输出值的声明使用输出块,例如:
|
|
output关键字后紧跟的就是输出值的名称。在当前模块内的所有输出值的名字都必须是唯一的。output块内的 value参数即为输出值,它可以像是上面的例子里那样某个 resource 的输出属性,也可以是任意合法的表达式。
输出值只有在执行 terraform apply后才会被计算,光是使用 terraform plan并不会计算输出值。
Terraform 代码中无法引用本目录下定义的输出值。
output块还有一些可选的属性:
description
|
|
与输入变量的 description类似,我们不再赘述。
sensitive
一个输出值可以标记 sensitive为 true,表示该输出值含有敏感信息。被标记 sensitive 的输出值只是在执行 terraform apply命令成功后会打印""以取代真实的输出值,执行 terraform output时也会输出"",但仍然可以通过执行 terraform output -json看到实际的敏感值。
需要注意的是,标记为 sensitive 输出值仍然会被记录在状态文件中,任何有权限读取状态文件的人仍然可以读取到敏感数据。
depends_on
关于 depends_on的内容将在 resource 章节里详细介绍,所以这里我们只是粗略地介绍一下。
Terraform 会解析代码所定义的各种 data、resource,以及他们之间的依赖关系,例如,创建虚拟机时用的 image_id参数是通过 data 查询而来的,那么虚拟机实例就依赖于这个镜像的 data,Terraform 会首先创建 data,得到查询结果后,再创建虚拟机 resource。一般来说,data、resource 之间的创建顺序是由 Terraform 自动计算的,不需要代码的编写者显式指定。但有时有些依赖关系无法通过分析代码得出,这时我们可以在代码中通过 depends_on显式声明依赖关系。
一般 output 很少会需要显式依赖某些资源,但有一些特殊场景,例如在当前代码中调用一个模块(可以理解成调用另一个目录中的 Terraform 代码创建一些资源)时,调用者希望在模块资源全部创建完毕以后才继续后续的创建工作,这时我们可以为模块设计一个 output,通过 depends_on显式声明依赖关系,以确保该 output 必须在所有模块资源成功创建以后才能被读取,这样我们就可以在模块尺度上控制资源的创建顺序。
depends_on 的用法如下:
|
|
我们不鼓励针对 output 定义 depends_on,只能作为最后的手段加以应用。如果不得不针对 output 定义 depends_on,请务必通过注释说明原因,方便后人进行维护。
precondition
output 块从 Terraform v1.2.0 开始也可以包含一个 precondition 块。
output 块上的 precondition 对应于 variable 块中的 validation 块。validation 块检查输入变量值是否符合模块的要求,precondition 则确保模块的输出值满足某种要求。我们可以通过 precondition 来防止 Terraform 把一个不合法的处置值写入状态文件。我们可以在合适的场景下通过 precondition 来保护上一次 apply 留下的合法的输出值。
Terraform 在计算输出值的 value 表达式之前执行 precondition 检查,这可以防止 value 表达式中的潜在错误被激发。
Locals
有时我们会需要用一个比较复杂的表达式计算某一个值,并且反复使用之,这时我们把这个复杂表达式赋予一个局部值,然后反复引用该局部值。如果说输入变量相当于函数的入参,输出值相当于函数的返回值,那么局部值就相当于函数内定义的局部变量。
局部值通过 locals块定义,例如:
|
|
一个 locals块可以定义多个局部值,也可以定义任意多个 locals块。赋给局部值的可以是更复杂的表达式,也可以是其他 data、resource 的输出、输入变量,甚至是其他的局部值:
|
|
引用局部值的表达式是 local.<NAME> (注意,虽然局部值定义在 locals 块内,但引用是务必使用 local 而不是 locals),例如:
|
|
局部值只能在同一模块内的代码中引用。
局部值可以帮助我们避免重复复杂的表达式,提升代码的可读性,但如果过度使用也有可能增加代码的复杂度,使得代码的维护者更难理解所使用的表达式和值。适度使用局部值,仅用于反复引用同一复杂表达式的场景,未来当我们需要修改该表达式时局部值将使得修改变得相当轻松。
Resources
Resources 是 Terraform 中最重要的元素,每个 resource block 都描述了一个或者多个 infrastructure objects,比如 VPC,EC2 等。
资源语法
资源通过 resource 块定义,我们首先讲解通过 resource 块定义单个资源对象的场景。
|
|
紧跟 resource 关键字的是资源类型,在上面的例子里就是 aws_instance。后面是资源的 Local Name,例子里就是 web。Local Name 可以在同一模块内的代码里被用来引用该资源,但类型加 Local Name 的组合在当前模块内必须是唯一的,不同类型的两个资源 Local Name 可以相同。随后的花括号内的内容就是块体,创建资源所用到的各种参数的值就在块体内定义。例子中我们定义了虚拟机所使用的镜像 id 以及虚拟机的尺寸。
资源参数
不同资源定义了不同的可赋值的属性,官方文档将之称为参数(Argument),有些参数是必填的,有些参数是可选的。使用某项资源前可以通过阅读相关文档了解参数列表以及他们的含义、赋值的约束条件。
参数值可以是简单的字面量,也可以是一个复杂的表达式。
资源类型的文档
每一个 Terraform Provider 都有自己的文档,用以描述它所支持的资源类型种类,以及每种资源类型所支持的属性列表。
大部分公共的 Provider 都是通过 Terraform Registry 连带文档一起发布的。当我们在 Terraform Registry 站点上浏览一个 Provider 的页面时,我们可以点击"Documentation"链接来浏览相关文档。Provider 的文档都是版本化的,我们可以选择特定版本的 Provider 文档。
需要注意的是,Provider 文档曾经是直接托管在 terraform.io 站点上的,也就是 Terraform 核心主站的一部分,有些 Provider 的文档目前依然托管在那里,但目前 Terraform Rregistry 才是所有公共 Provider 文档的主站(唯一的例外是用来读取其他 Terraform 状态数据的内建的 terraform provider,它的文档目前不在 Terraform Registry 上)。
资源的行为
一个 resource 块声明了作者想要创建的一个确切的基础设施对象,并且设定了各项属性的值。如果我们正在编写一个新的 Terraform 代码文件,那么代码所定义的资源仅仅只在代码中存在,并没有与之对应的实际的基础设施资源存在。
对一组 Terraform 代码执行 terraform apply 可以创建、更新或者销毁实际的基础设施对象,Terraform 会制定并执行变更计划,以使得实际的基础设施符合代码的定义。
每当 Terraform 按照一个 resource 块创建了一个新的基础设施对象,这个实际的对象的 id 会被保存进 Terraform 状态中,使得将来 Terraform 可以根据变更计划对它进行更新或是销毁操作。如果一个 resource 块描述的资源在状态文件中已有记录,那么 Terraform 会比对记录的状态与代码描述的状态,如果有必要,Terraform 会制定变更计划以使得资源状态能够符合代码的描述。
这种行为适用于所有资源而无关其类型。创建、更新、销毁一个资源的细节会根据资源类型而不同,但是这个行为规则却是普适的。
访问资源输出属性
资源不但可以通过参数传值,成功创建的资源还对外输出一些通过调用 API 才能获得的只读数据,经常包含了一些我们在实际创建一个资源之前无法获知的数据,比如云主机的 id 等,官方文档将之称为属性(Attribute)。我们可以在同一模块内的代码中引用资源的属性来创建其他资源或是表达式。在表达式中引用资源属性的语法是 <RESOURCE_TYPE>.<NAME>.<ATTRIBUTE>。
要获取一个资源类型输出的属性列表,我们可以查阅对应的 Provider 文档,一般在文档中会专门记录资源的输出属性列表。
敏感的资源属性
在为资源类型定义架构时,Provider 开发着可以将某些属性标记为 sensitive,在这种情况下,Terraform 将在展示涉及该属性的计划时显示占位符标记 (sensitive) 而不是实际值。
标记为 sensitive 的 Provider 属性的行为类似于声明为 sensitive 的输入变量,Terraform 将隐藏计划中的值,还将隐藏从该值派生出的任何其他敏感值。但是,该行为存在一些限制,如 Terraform 可能暴露敏感变量。
如果使用资源属性中的敏感值作为输出值的一部分,Terraform 将要求将输出值本身标记为 sensitive,以确认确实打算将其导出。
Terraform 仍会在状态中记录敏感值,因此任何可以访问状态数据的人都可以以明文形式访问敏感值。
注意:Terraform 从 v0.15 开始将从敏感资源属性派生的值视为敏感值本身。早期版本的 Terraform 将隐藏敏感资源属性的直接值,但不会自动隐藏从敏感资源属性派生的其他值。
资源的依赖关系
我们在介绍输出值的 depends_on 的时候已经简单介绍过了依赖关系。一般来说在 Terraform 代码定义的资源之间不会有特定的依赖关系,Terraform 可以并行地对多个无依赖关系的资源执行变更,默认情况下这个并行度是 10。
然而,创建某些资源所需要的信息依赖于另一个资源创建后输出的属性,又或者必须在某些资源成功创建后才可以被创建,这时资源之间就存在依赖关系。
大部分资源间的依赖关系可以被 Terraform 自动处理,Terraform 会分析 resource 块内的表达式,根据表达式的引用链来确定资源之间的引用,进而计算出资源在创建、更新、销毁时的执行顺序。大部分情况下,我们不需要显式指定资源之间的依赖关系。
然而,有时候某些依赖关系是无法从代码中推导出来的。例如,Terraform 必须要创建一个访问控制权限资源,以及另一个需要该权限才能成功创建的资源。后者的创建依赖于前者的成功创建,然而这种依赖在代码中没有表现为数据引用关联,这种情况下,我们需要用 depends_on 来显式声明这种依赖关系。
元参数
resource 块支持几种元参数声明,这些元参数可以被声明在所有类型的 resource 块内,它们将会改变资源的行为:
- depends_on:显式声明依赖关系
- count:创建多个资源实例
- for_each:迭代集合,为集合中每一个元素创建一个对应的资源实例
- provider:指定非默认 Provider 实例
- lifecycle:自定义资源的生命周期行为
- provisioner 和 connection:在资源创建后执行一些额外的操作
下面我们将逐一讲解他们的用法。
depends_on
使用 depends_on可以显式声明资源之间哪些 Terraform 无法自动推导出的隐含的依赖关系。只有当资源间确实存在依赖关系,但是彼此间又没有数据引用的场景下才有必要使用 depends_on。
使用 depends_on的例子是这样的:
|
|
我们来分段解释一下这个场景,首先我们声明了一个 AWS IAM 角色,将角色绑定在一个主机实例配置文件上:
resource "aws_iam_role" "example" {
name = "example"
# assume_role_policy is omitted for brevity in this example. See the
# documentation for aws_iam_role for a complete example.
assume_role_policy = "..."
}
resource "aws_iam_instance_profile" "example" {
# Because this expression refers to the role, Terraform can infer
# automatically that the role must be created first.
role = aws_iam_role.example.name
}
虚拟机的声明代码中的这个赋值使得 Terraform 能够判断出虚拟机依赖于主机实例配置文件:
resource "aws_instance" "example" {
ami = "ami-a1b2c3d4"
instance_type = "t2.micro"
# Terraform can infer from this that the instance profile must
# be created before the EC2 instance.
iam_instance_profile = aws_iam_instance_profile.example
至此,Terraform 规划出的创建顺序是 IAM 角色->主机实例配置文件->主机实例。但是我们又为这个 IAM 角色添加了对 S3 存储服务的完全控制权限:
resource "aws_iam_role_policy" "example" {
name = "example"
role = aws_iam_role.example.name
policy = jsonencode({
"Statement" = [{
# This policy allows software running on the EC2 instance to
# access the S3 API.
"Action" = "s3:*",
"Effect" = "Allow",
}],
})
}
也就是说,虚拟机实例由于绑定了主机实例配置文件,从而在运行时拥有了一个 IAM 角色,而这个 IAM 角色又被赋予了 S3 的权限。但是虚拟机实例的声明代码中并没有引用 S3 权限的任何输出属性,这将导致 Terraform 无法理解他们之间存在依赖关系,进而可能会并行地创建两者,如果虚拟机实例被先创建了出来,内部的程序开始运行时,它所需要的 S3 权限却还没有创建完成,那么就将导致程序运行错误。为了确保虚拟机创建时 S3 权限一定已经存在,我们可以用 depends_on显式声明它们的依赖关系:
|
|
depends_on 的赋值必须是包含同一模块内声明的其他资源名称的列表,不允许包含其他表达式,例如不允许使用其他资源的输出属性,这是因为 Terraform 必须在计算资源间关系之前就能理解列表中的值,为了能够安全地完成表达式计算,所以限制只能使用资源实例的名称。
depends_on 只能作为最后的手段使用,如果我们使用 depends_on,我们应该用注释记录我们使用它的原因,以便今后代码的维护者能够理解隐藏的依赖关系。
count
一般来说,一个 resource 块定义了一个对应的实际基础设施资源对象。但是有时候我们希望创建多个相似的对象,比如创建一组虚拟机。Terraform 提供了两种方法实现这个目标:count与 for_each。
count参数可以是任意自然数,Terraform 会创建 count个资源实例,每一个实例都对应了一个独立的基础设施对象,并且在执行 Terraform 代码时,这些对象是被分别创建、更新或者销毁的:
resource "aws_instance" "server" {
count = 4 # create four similar EC2 instances
ami = "ami-a1b2c3d4"
instance_type = "t2.micro"
tags = {
Name = "Server ${count.index}"
}
}
我们可以在 resource 块中的表达式里使用 count 对象来获取当前的 count 索引号。count 对象只有一个属性:
count.index:代表当前对象对应的count下标索引(从 0 开始)
如果一个 resource 块定义了 count 参数,那么 Terraform 会把这种多资源实例对象与没有 count 参数的单资源实例对象区别开:
- 访问单资源实例对象:
<TYPE>.<NAME>(例如:aws_instance.server) - 访问多资源实例对象:
<TYPE>.<NAME>[<INDEX>](例如:aws_instance.server[0],aws_instance.server[1])
声明了 count或 for_each 的资源必须使用下标索引或者键来访问。
count 参数可以是任意自然数,然而与 resource 的其他参数不同,count的值在 Terraform 进行任何远程资源操作(实际的增删改查)之前必须是已知的,这也就意味着赋予 count 参数的表达式不可以引用任何其他资源的输出属性(例如由其他资源对象创建时返回的一个唯一的 ID)。count的表达式中可以引用来自 data 返回的输出属性,只要该 data 可以不依赖任何其他 resource 进行查询。
for_each
for_each是 Terraform 0.12.6 开始引入的新特性。一个 resource 块不允许同时声明 count与 for_each。for_each参数可以是一个 map 或是一个 set(string),Terraform 会为集合中每一个元素都创建一个独立的基础设施资源对象,和 count一样,每一个基础设施资源对象在执行 Terraform 代码时都是独立创建、修改、销毁的。
使用 map 的例子:
resource "azurerm_resource_group" "rg" {
for_each = {
a_group = "eastus"
another_group = "westus2"
}
name = each.key
location = each.value
}
使用 set(string)的例子:
resource "aws_iam_user" "the-accounts" {
for_each = toset( ["Todd", "James", "Alice", "Dottie"] )
name = each.key
}
我们可以在声明了 for_each参数的 resource 块内使用 each对象来访问当前的迭代器对象:
each.key:map 的键,或是 set 中的值each.value:map 的值,或是 set 中的值
如果 for_each的值是一个 set,那么 each.key和 each.value是相等的。
使用 for_each时,map 的所有键、set 的所有 string 值都必须是已知的,也就是状态文件中已有记录的值。所以有时候我们可能需要在执行 terraform apply时添加 -target参数,实现分步创建。另外,for_each所使用的键集合不能够包含或依赖非纯函数,也就是反复执行会返回不同返回值的函数,例如 uuid、bcrypt、timestamp等。
当一个 resource 声明了 for_each 时,Terraform 会把这种多资源实例对象与没有 count 参数的单资源实例对象区别开:
- 访问单资源实例对象:
<TYPE>.<NAME>(例如:aws_instance.server) - 访问多资源实例对象:
<TYPE>.<NAME>[<KEY>](例如:aws_instance.server["ap-northeast-1"],aws_instance.server["ap-northeast-2"])
声明了 count或 for_each 的资源必须使用下标索引或者键来访问。
由于 Terraform 没有用以声明 set 的字面量,所以我们有时需要使用 toset函数把 list(string)转换为 set(string):
locals {
subnet_ids = toset([
"subnet-abcdef",
"subnet-012345",
])
}
resource "aws_instance" "server" {
for_each = local.subnet_ids
ami = "ami-a1b2c3d4"
instance_type = "t2.micro"
subnet_id = each.key # note: each.key and each.value are the same for a set
tags = {
Name = "Server ${each.key}"
}
}
在这里我们用 toset 把一个 list(string)转换成了 set(string),然后赋予 for_each。在转换过程中,list 中所有重复的元素会被抛弃,只剩下不重复的元素,例如 toset(["b", "a", "b"])的结果只有 "a"和 "b",并且 set 的元素没有特定顺序。
如果我们要把一个输入变量赋予 for_each,我们可以直接定义变量的类型约束来避免显式调用 toset转换类型:
variable "subnet_ids" {
type = set(string)
}
resource "aws_instance" "server" {
for_each = var.subnet_ids
# (and the other arguments as above)
}
在 for_each 和 count 之间选择
如果创建的资源实例彼此之间几乎完全一致,那么 count比较合适。如果彼此之间的参数差异无法直接从 count的下标派生,那么使用 for_each会更加安全。
在 Terraform 引入 for_each之前,我们经常使用 count.index搭配 length函数和 list来创建多个资源实例:
variable "subnet_ids" {
type = list(string)
}
resource "aws_instance" "server" {
# Create one instance for each subnet
count = length(var.subnet_ids)
ami = "ami-a1b2c3d4"
instance_type = "t2.micro"
subnet_id = var.subnet_ids[count.index]
tags = {
Name = "Server ${count.index}"
}
}
这种实现方法是脆弱的,因为资源仍然是以他们的下标而不是实际的 string 值来区分的。如果我们从 subnet_ids列表的中间移除了一个元素,那么从该位置起后续所有的 aws_instance都会发现它们的 subnet_id发生了变化,结果就是所有后续的 aws_instance都需要更新。这种场景下如果使用 for_each就更为妥当,如果使用 for_each,那么只有被移除的 subnet_id对应的 aws_instance会被销毁。
provider
关于 provider 的定义我们在前面介绍 Provider 的章节已经提到过了,如果我们声明了同一类型 Provider 的多个实例,那么我们在创建资源时可以通过指定 provider参数选择要使用的 Provider 实例。如果没有指定 provider参数,那么 Terraform 默认使用资源类型名中第一个单词所对应的 Provider 实例,例如 google_compute_instance的默认 Provider 实例就是 google,aws_instance的默认 Provider 就是 aws。
指定 provider参数的例子:
# default configuration
provider "google" {
region = "us-central1"
}
# alternate configuration, whose alias is "europe"
provider "google" {
alias = "europe"
region = "europe-west1"
}
resource "google_compute_instance" "example" {
# This "provider" meta-argument selects the google provider
# configuration whose alias is "europe", rather than the
# default configuration.
provider = google.europe
# ...
}
provider 参数期待的赋值是 <PROVIDER> 或是 <PROVIDER>.<ALIAS>,不需要双引号。因为在 Terraform 开始计算依赖路径图时,provider 关系必须是已知的,所以除了这两种以外的表达式是不被接受的。
ifecycle
通常一个资源对象的生命周期在前面“资源的行为”一节中已经描述了,但是我们可以用 lifecycle块来定一个不一样的行为方式,例如:
resource "azurerm_resource_group" "example" {
# ...
lifecycle {
create_before_destroy = true
}
}
lifecycle 块和它的内容都属于元参数,可以被声明于任意类型的资源块内部。Terraform 支持如下几种 lifecycle:
create_before_destroy(bool):默认情况下,当 Terraform 需要修改一个由于服务端 API 限制导致无法直接升级的资源时,Terraform 会删除现有资源对象,然后用新的配置参数创建一个新的资源对象取代之。create_before_destroy参数可以修改这个行为,使得 Terraform 首先创建新对象,只有在新对象成功创建并取代老对象后再销毁老对象。这并不是默认的行为,因为许多基础设施资源需要有一个唯一的名字或是别的什么标识属性,在新老对象并存时也要符合这种约束。有些资源类型有特别的参数可以为每个对象名称添加一个随机的前缀以防止冲突。Terraform 不能默认采用这种行为,所以在使用create_before_destroy前你必须了解每一种资源类型在这方面的约束。prevent_destroy(bool):这个参数是一个保险措施,只要它被设置为true时,Terraform 会拒绝执行任何可能会销毁该基础设施资源的变更计划。这个参数可以预防意外删除关键资源,例如错误地执行了terraform destroy,或者是意外修改了资源的某个参数,导致 Terraform 决定删除并重建新的资源实例。在 resource 块内声明了prevent_destroy = true会导致无法执行terraform destroy,所以对它的使用要节制。需要注意的是,该措施无法防止我们删除 resource 块后 Terraform 删除相关资源,因为对应的prevent_destroy = true声明也被一并删除了。ignore_changes(list(string)):默认情况下,Terraform 检测到代码描述的配置与真实基础设施对象之间有任何差异时都会计算一个变更计划来更新基础设施对象,使之符合代码描述的状态。在一些非常罕见的场景下,实际的基础设施对象会被 Terraform 之外的流程所修改,这就会使得 Terraform 不停地尝试修改基础设施对象以弥合和代码之间的差异。这种情况下,我们可以通过设定ignore_changes来指示 Terraform 忽略某些属性的变更。ignore_changes的值定义了一组在创建时需要按照代码定义的值来创建,但在更新时不需要考虑值的变化的属性名,例如:
resource "aws_instance" "example" {
# ...
lifecycle {
ignore_changes = [
# Ignore changes to tags, e.g. because a management agent
# updates these based on some ruleset managed elsewhere.
tags,
]
}
}
- 你也可以忽略 map 中特定的元素,例如
tags["Name"],但是要注意的是,如果你是想忽略 map 中特定元素的变更,那么你必须首先确保 map 中含有这个元素。如果一开始 map 中并没有这个键,而后外部系统添加了这个键,那么 Terraform 还是会把它当成一次变更来处理。比较好的方法是你在代码中先为这个键创建一个占位元素来确保这个键已经存在,这样在外部系统修改了键对应的值以后 Terraform 会忽略这个变更。
resource "aws_instance" "example" {
# ...
tags = {
# Initial value for Name is overridden by our automatic scheduled
# re-tagging process; changes to this are ignored by ignore_changes
# below.
Name = "placeholder"
}
lifecycle {
ignore_changes = [
tags["Name"],
]
}
}
- 除了使用一个
list(string),也可以使用关键字"all",这时 Terraform 会忽略资源一切属性的变更,这样 Terraform 只会创建或销毁一个对象,但绝不会尝试更新一个对象。你只能在ignore_changes里忽略所属的 resource 的属性,ignore_changes不可以赋予它自身或是其他任何元参数。 replace_triggered_by(包含资源引用的列表):强制 Terraform 在引用的资源或是资源属性发生变更时替换声明该块的父资源,值为一个包含了托管资源、实例或是实例属性引用表达式的列表。当声明该块的资源声明了count或是for_each时,我们可以在表达式中使用count.index或是each.key来指定引用实例的序号。
replace_triggered_by 可以在以下几种场景中使用:
- 如果表达式指向多实例的资源声明(例如声明了
count或是for_each的资源),那么这组资源中任意实例发生变更或被替换时都将引发声明replace_triggered_by的资源被替换 - 如果表达式指向单个资源实例,那么该实例发生变更或被替换时将引发声明
replace_triggered_by的资源被替换 - 如果表达式指向单个资源实例的单个属性,那么该属性值的任何变化都将引发声明
replace_triggered_by的资源被替换
我们在 replace_triggered_by 中只能引用托管资源。这允许我们在不引发强制替换的前提下修改这些表达式。
resource "aws_appautoscaling_target" "ecs_target" {
# ...
lifecycle {
replace_triggered_by = [
# Replace `aws_appautoscaling_target` each time this instance of
# the `aws_ecs_service` is replaced.
aws_ecs_service.svc.id
]
}
}
lifecycle配置影响了 Terraform 如何构建并遍历依赖图。作为结果,lifecycle内赋值仅支持字面量,因为它的计算过程发生在 Terraform 计算的极早期。这就是说,例如 prevent_destroy、create_before_destroy的值只能是 true或者 false,ignore_changes、replace_triggered_by的列表内只能是硬编码的属性名。
Precondition 与 Postcondition
请注意,Precondition 与 Postcondition 是从 Terraform v1.2.0 开始被引入的功能。
在 lifecycle 块中声明 precondition 与 postcondition 块可以为资源、数据源以及输出值创建自定义的验证规则。
Terraform 在计算一个对象之前会首先检查该对象关联的 precondition,并且在对象计算完成后执行 postcondition 检查。Terraform 会尽可能早地执行自定义检查,但如果表达式中包含了只有在 apply 阶段才能知晓的值,那么该检查也将被推迟执行。
每一个 precondition 与 postcondition 块都需要一个 condition 参数。该参数是一个表达式,在满足条件时返回 true,否则返回 false。该表达式可以引用同一模块内的任意其他对象,只要这种引用不会产生环依赖。在 postcondition 表达式中也可以使用 self 对象引用声明 postcondition 的资源实例的属性。
如果 condition 表达式计算结果为 false,Terraform 会生成一条错误信息,包含了 error_message 表达式的内容。如果我们声明了多条 precondition 或 postcondition,Terraform 会返回所有失败条件对应的错误信息。
下面的例子演示了通过 postcondition 检测调用者是否不小心传入了错误的 AMI 参数:
data "aws_ami" "example" {
id = var.aws_ami_id
lifecycle {
# The AMI ID must refer to an existing AMI that has the tag "nomad-server".
postcondition {
condition = self.tags["Component"] == "nomad-server"
error_message = "tags[\"Component\"] must be \"nomad-server\"."
}
}
}
在 resource 或 data 块中的 lifecycle 块可以同时包含 precondition 与 postcondition 块。
- Terraform 会在计算完
count和for_each元参数后执行precondition块。这使得 Terraform 可以对每一个实例独立进行检查,并允许在表达式中使用each.key、count.index等。Terraform 还会在计算资源的参数表达式之前执行precondition检查。precondition可以用来防止参数表达式计算中的错误被激发。 - Terraform 在计算和执行对一个托管资源的变更之后执行
postcondition检查,或是在完成数据源读取后执行它关联的postcondition检查。postcondition失败会阻止其他依赖于此失败资源的其他资源的变更。
在大多数情况下,我们不建议在同一配置文件中同时包含表示同一个对象的 data 块和 resource 块。这样做会使得 Terraform 无法理解 data 块的结果会被 resource 块的变更所影响。然而,当我们需要检查一个 resource 块的结果,恰巧该结果又没有被资源直接输出时,我们可以使用 data 块并在块中直接使用 postcondition 来检查该对象。这等于告诉 Terraform 该 data 块是用来检查其他什么地方定义的对象的,从而允许 Terrform 以正确的顺序执行操作。
provisioner 和 connection
某些基础设施对象需要在创建后执行特定的操作才能正式工作。比如说,主机实例必须在上传了配置或是由配置管理工具初始化之后才能正常工作。
像这样创建后执行的操作可以使用预置器(Provisioner)。预置器是由 Terraform 所提供的另一组插件,每种预置器可以在资源对象创建后执行不同类型的操作。
使用预置器需要节制,因为他们采取的操作并非 Terraform 声明式的风格,所以 Terraform 无法对他们执行的变更进行建模和保存。
预置器也可以声明为资源销毁前执行,但会有一些限制。
作为元参数,provisioner和 connection可以声明在任意类型的 resource 块内。
举一个例子:
resource "aws_instance" "web" {
# ...
provisioner "file" {
source = "conf/myapp.conf"
destination = "/etc/myapp.conf"
connection {
type = "ssh"
user = "root"
password = var.root_password
host = self.public_ip
}
}
}
我们在 aws_instance中定义了类型为 file的预置器,该预置器可以本机文件或文件夹拷贝到目标机器的指定路径下。我们在预置器内部定义了 connection块,类型是 ssh。我们对 connection的 host赋值 self.public_ip,在这里 self代表预置器所在的母块,也就是 aws_instance.web,所以 self.public_ip代表着 aws_instance.web.public_ip,也就是创建出来的主机的公网 ip。
file类型预置器支持 ssh和 winrm两种类型的 connection。
预置器根据运行的时机分为两种类型,创建时预置器以及销毁时预置器。
创建时预置器
默认情况下,资源对象被创建时会运行预置器,在对象更新、销毁时则不会运行。预置器的默认行为时为了引导一个系统。
如果创建时预置器失败了,那么资源对象会被标记污点(我们将在介绍 terraform taint命令时详细介绍)。一个被标记污点的资源在下次执行 terraform apply命令时会被销毁并重建。Terrform 的这种设计是因为当预置器运行失败时标志着资源处于半就绪的状态。由于 Terraform 无法衡量预置器的行为,所以唯一能够完全确保资源被正确初始化的方式就是删除重建。
我们可以通过设置 on_failure参数来改变这种行为。
销毁时预置器
如果我们设置预置器的 when参数为 destroy,那么预置器会在资源被销毁时执行:
resource "aws_instance" "web" {
# ...
provisioner "local-exec" {
when = destroy
command = "echo 'Destroy-time provisioner'"
}
}
销毁时预置器在资源被实际销毁前运行。如果运行失败,Terraform 会报错,并在下次运行 terraform apply操作时重新执行预置器。在这种情况下,需要仔细关注销毁时预置器以使之能够安全地反复执行。
销毁时预置器只有在存在于代码中的情况下才会在销毁时被执行。如果一个 resource 块连带内部的销毁时预置器块一起被从代码中删除,那么被删除的预置器在资源被销毁时不会被执行。要解决这个问题,我们需要使用多个步骤来绕过这个限制:
- 修改资源声明代码,添加
count = 0参数 - 执行
terraform apply,运行删除时预置器,然后删除资源实例 - 删除 resource 块
- 重新执行
terraform apply,此时应该不会有任何变更需要执行
该限制在未来将会得到解决,但目前来说我们必须节制使用销毁时预置器。
预置器失败行为
默认情况下,预置器运行失败会导致 terraform apply执行失败。可以通过设置 on_failure参数来改变这一行为。可以设置的值为:
- continue:忽视错误,继续执行创建或是销毁
- fail:报错并终止执行变更(这是默认行为)。如果这是一个创建时预置器,则在对应资源对象上标记污点
样例:
resource "aws_instance" "web" {
# ...
provisioner "local-exec" {
command = "echo The server's IP address is ${self.private_ip}"
on_failure = continue
}
}
本地资源
虽然大部分资源类型都对应的是通过远程基础设施 API 控制的一个资源对象,但也有一些资源对象他们只存在于 Terraform 进程自身内部,用来计算生成某些结果,并将这些结果保存在状态中以备日后使用。
比如说,我们可以用 tls_private_key生成公私钥,用 tls_self_signed_cert生成自签名证书,或者是用 random_id生成随机 id。虽不像其他“真实”基础设施对象那般重要,但这些本地资源也可以成为连接其他资源有用的黏合剂。
本地资源的行为与其他类型资源是一致的,但是他们的结果数据仅存在于 Terraform 状态文件中。“销毁”这种资源只是将结果数据从状态中删除。
操作超时设置
有些资源类型提供了特殊的 timeouts 内嵌块参数,它允许我们配置我们允许操作持续多长时间,超时将被认定为失败。比如说,aws_db_instance资源允许我们分别为 create,update,delete操作设置超时时间。
超时完全由资源对应的 Provider 来处理,但支持超时设置的 Provider 一般都遵循相同的传统,那就是由一个名为 timeouts的嵌入块参数定义超时设置,timeouts块内可以分别设置不同操作的超时时间。超时时间由 string 描述,比如 "60m"代表 60 分钟,"10s"代表 10 秒,"2h"代表 2 小时。
resource "aws_db_instance" "example" {
# ...
timeouts {
create = "60m"
delete = "2h"
}
}
可配置超时的操作类别由每种支持超时设定的资源类型自行决定。大部分资源类型不支持设置超时。使用超时前请先查阅相关文档。
Data Sources
数据源允许查询或计算一些数据以供其他地方使用。使用数据源可以使得 Terraform 代码使用在 Terraform 管理范围之外的一些信息,或者是读取其他 Terraform 代码保存的状态。
每一种 Provider 都可以在定义一些资源类型的同时定义一些数据源。
使用数据源
数据源通过一种特殊的资源访问:data 资源。数据源通过 data 块声明:
|
|
一个 data 块请求 Terraform 从一个指定的数据源 aws_ami读取指定数据并且把结果输出到 Local Name 为 example的实例中。我们可以在同一模块内的代码中通过数据源名称来引用数据源,但无法从模块外部直接访问数据源。
同资源类似,一个数据源类型以及它的名称一同构成了该数据源的标识符,所以数据源类型加名称的组合在同一模块内必须是唯一的。
在 data 块体(花括号中间的内容)是传给数据源的查询条件。查询条件参数的种类取决于数据源的类型,在上述例子中,most_recent、owners和 tags都是定义查询 aws_ami数据源时使用的查询条件。
与数据源这种特殊资源不同的是,我们在上一节介绍的主要资源(使用 resource 块定义的)是一种“托管资源”。这两种资源都可以接收参数并对外输出属性,但托管资源会触发 Terraform 对基础设施对象进行增删改操作,而数据源只会触发读取操作。简单来说,我们一般说的“资源”就是特指托管资源。
数据源参数
每一种数据源资源都关联到一种外部数据源,数据源类型决定了它接收的查询参数以及输出的数据。每一种数据源类型都属于一个 Provider。大部分 data 块内的数据源参数都是由对应的数据源类型定义的,这些参数的赋值可以使用完整的 Terraform 表达式能力或其他 Terraform 语言的功能。
然而类似资源,Terraform 也为所有类型的数据源定义了一些元参数。这些元参数的限制和功能我们将在后续节当中叙述。
数据源行为
如果数据源的查询参数涉及到的表达式只引用了字面量或是在执行 terraform plan时就已知的数据(比如输入变量),那么数据源会在执行 Terraform 的"refersh"阶段时被读取,然后 Terraform 会构建变更计划。这保证了在制定变更计划时 Terraform 可以使用这些数据源的返回数据。
如果查询参数的表达式引用了那些只有执行部分执行变更计划以后才能知晓的数据,比如另一个还未被创建的托管资源的输出,那么数据源的读取操作会被推迟到"apply"阶段,任何引用该数据源输出的表达式的值在执行到数据源被读取完之前都是未知的。
本地数据源
虽然绝大多数数据源都对应了一个通过远程基础设施 API 访问的外部数据源,但是也有一些特殊的数据源仅存在于 Terraform 进程内部,计算并对外输出一些数据。
比如说,本地数据源有 template_file、local_file、aws_iam_policy_document等。
本地数据源的行为与其他数据源完全一致,但他们输出的结果数据只是临时存在于 Terraform 运行时,每次计算一个新的变更计划时这些值都会被重新计算。
数据源有着与资源一样的依赖机制,我们也可以在 data 块内设置 depends_on元参数来显式声明依赖关系,在此不再赘述。
多数据源实例
与资源一样,数据源也可以通过设置 count、for_each元参数来创建一组多个数据源实例,并且 Terraform 也会把每个数据源实例单独创建并读取相应的外部数据,对 count.index与 each的使用也是一样的,在 count与 for_each之间选择的原则也是一样的。
实例
一个数据源定义例子如下:
|
|
引用数据源数据的语法是 data.<TYPE>.<NAME>`.<ATTRIBUTE>:
resource "aws_instance" "web" {
ami = data.aws_ami.web.id
instance_type = "t1.micro"
}
Providers
Terraform 被设计成一个多云基础设施编排工具,不像 CloudFormation 那样绑定 AWS 平台,Terraform 可以同时编排各种云平台或是其他基础设施的资源。Terraform 实现多云编排的方法就是 Provider 插件机制。
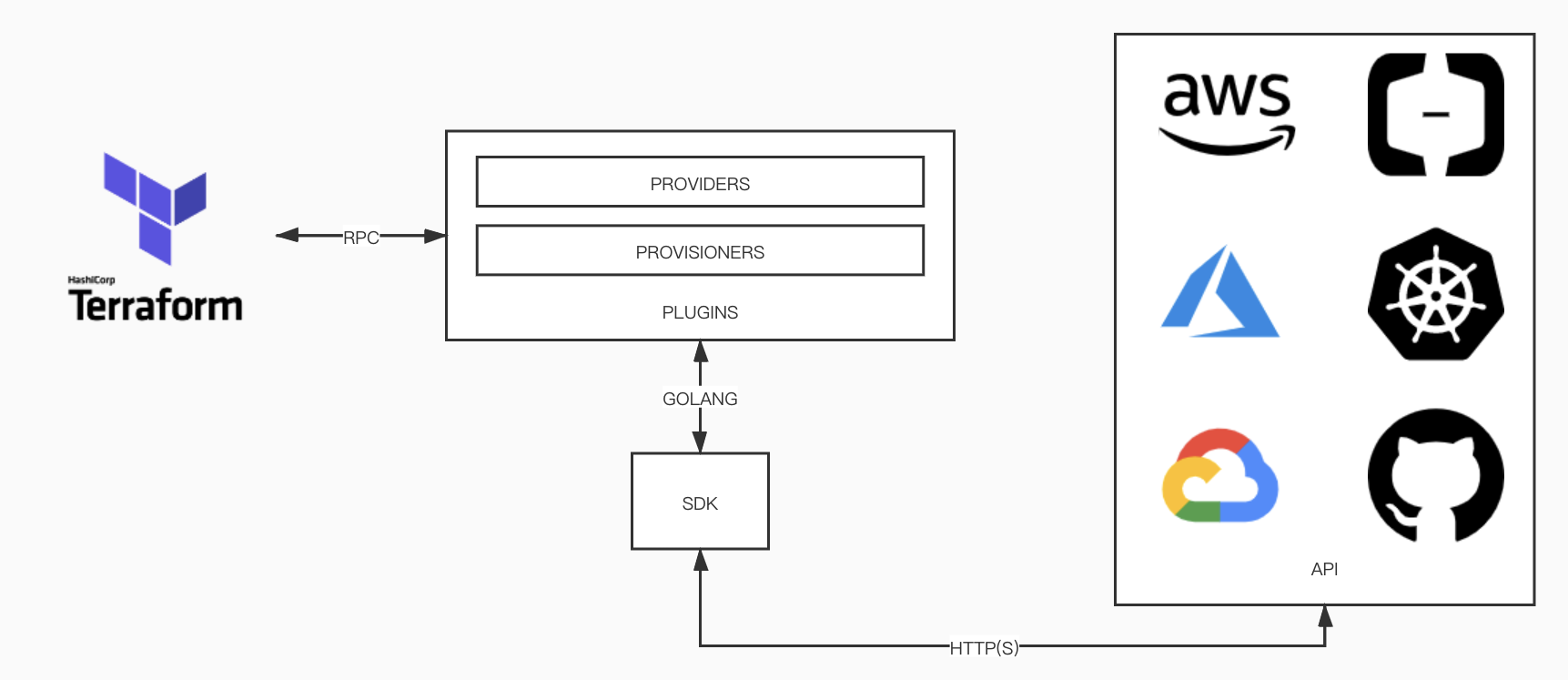
Terraform 使用的是 HashiCorp 自研的 go-plugin 库 ,本质上各个 Provider 插件都是独立的进程,与 Terraform 进程之间通过 rpc 进行调用:
- Terraform 引擎读取并分析用户编写的 Terraform 代码,形成一个由 data 与 resource 组成 Graph
- Terraform 通过 RPC 调用这些 data 与 resource 所对应的 Provider 插件
- Provider 插件的编写者根据 Terraform 所制定的插件框架来定义各种 data 和 resource,并实现相应的 CRUD 方法
- Provider 在实现这些 CRUD 方法时,可以调用目标平台提供的 SDK,或是直接通过调用 Http(s) API 来操作目标平台
Provider 的声明
一组 Terraform 代码要被执行,相关的 Provider 必须在代码中被声明。不少的 Provider 在声明时需要传入一些关键信息才能被使用。
|
|
在这段 Provider 声明中,首先在 terraform 节的 required_providers 里声明了本段代码必须要名为 ucloud 的 Provider 才可以执行,source = "ucloud/ucloud" 这一行声明了 ucloud 这个插件的源地址(Source Address)。一个源地址是全球唯一的,它指示了 Terraform 如何下载该插件。一个源地址由三部分组成:
[<HOSTNAME>/]<NAMESPACE>/<TYPE>
HostName是选填的,默认是官方的 registry.terraform.io,读者也可以构建自己私有的 Terraform 仓库。Namespace是在 Terraform 仓库内得到组织名,这代表了发布和维护插件的组织或是个人。Type是代表插件的一个短名,在特定的 HostName/Namespace下 Type必须唯一。
required_providers 中的插件声明还声明了该源码所需要的插件的版本约束,在例子里就是 version = ">=1.24.1"。Terraform 插件的版本号采用 MAJOR.MINOR.PATCH 的语义化格式,版本约束通常使用操作符和版本号表达约束条件,条件之间可以用逗号拼接,表达 AND 关联,例如 >= 1.2.0, < 2.0.0。可以采用的操作符有:
- =(或者不加=,直接使用版本号):只允许特定版本号,不允许与其他条件合并使用
- !=:不允许特定版本号
>,>=,<,<=:与特定版本号进行比较,可以是大于、大于等于、小于、小于等于~>:锁定 MAJOR 与 MINOR,允许 PATCH 号大于等于特定版本号,例如,~>0.9等价于>=0.9, <1.0,~>0.8.4等价于>=0.8.4, <0.9
Terraform 会检查当前工作环境或是插件缓存中是否存在满足版本约束的插件,如果不存在,那么 Terraform 会尝试下载。如果 Terraform 无法获得任何满足版本约束条件的插件,那么它会拒绝继续执行任何后续操作。
可以用添加后缀的方式来声明预览版,例如:1.2.0-beta。预览版只能通过"=“操作符(或是空缺操作符)后接明确的版本号的方式来指定,不可以与 >=、~>等搭配使用。
推荐使用 >= 操作符约束最低版本。如果你是在编写旨在由他人复用的模块代码时,请避免使用”~>“操作符,即使你知道模块代码与新版本插件会有不兼容。
内建 Provider
绝大多数 Provider 是以插件形式单独分发的,但是目前有一个 Provider 是内建于 Terraform 主进程中的,那就是 terraform_remote_state data source。该 Provider 由于是内建的,所以使用时不需要在 terraform 中声明 required_providers。这个内建 Provider 的源地址是 terraform.io/builtin/terraform。
多 Provider 实例
provider节声明了 ucloud这个 Provider 所需要的各项配置。在上文的代码示例中,provider "ucloud"和 required_providers中 ucloud = {...}块里的 ucloud,都是 Provider 的 Local Name,一个 Local Name 是在一个模块中对一个 Provider 的唯一的标识。
我们也可以声明多个同类型的 Provider,并给予不同的 Local Name:
terraform {
required_version = ">=0.13.5"
required_providers {
ucloudbj = {
source = "ucloud/ucloud"
version = ">=1.24.1"
}
ucloudsh = {
source = "ucloud/ucloud"
version = ">=1.24.1"
}
}
}
provider "ucloudbj" {
public_key = "your_public_key"
private_key = "your_private_key"
project_id = "your_project_id"
region = "cn-bj2"
}
provider "ucloudsh" {
public_key = "your_public_key"
private_key = "your_private_key"
project_id = "your_project_id"
region = "cn-sh2"
}
data "ucloud_security_groups" "default" {
provider = ucloudbj
type = "recommend_web"
}
data "ucloud_images" "default" {
provider = ucloudsh
availability_zone = "cn-sh2-01"
name_regex = "^CentOS 6.5 64"
image_type = "base"
}
例如上面的例子,我们声明了两个 UCloud Provider,分别定位在北京区域和上海区域。我们在接下来的 data 声明中显式指定了 provider 的 Local Name,这使得我们可以在一组配置文件中同时操作不同区域、不同账号的资源。
我们也可以使用 alias 别名来区隔同类 Provider 的不同实例:
terraform {
required_version = ">=0.13.5"
required_providers {
ucloud = {
source = "ucloud/ucloud"
version = ">=1.24.1"
}
}
}
provider "ucloud" {
public_key = "your_public_key"
private_key = "your_private_key"
project_id = "your_project_id"
region = "cn-bj2"
}
provider "ucloud" {
alias = "ucloudsh"
public_key = "your_public_key"
private_key = "your_private_key"
project_id = "your_project_id"
region = "cn-sh2"
}
data "ucloud_security_groups" "default" {
type = "recommend_web"
}
data "ucloud_images" "default" {
provider = ucloud.ucloudsh
availability_zone = "cn-sh2-01"
name_regex = "^CentOS 6.5 64"
image_type = "base"
}
和多 Local Name 相比,使用别名允许我们区分 provider 的不同实例。terraform节的 required_providers中只声明了一次 ucloud,并且在 data 中指定 provider 时传入的是 ucloud.ucloudsh。多实例 Provider 请使用别名。
每一个不带alias 属性的 provider 声明都是一个默认provider 声明。没有显式指定 provider 的 data 以及 resource 都使用默认资源名第一个单词所对应的 provider,例如,ucloud_images这个 data 对应的默认 provider 就是 ucloud,aws_instance这个 resource 对应的默认 provider 就是 aws。
假如代码中所有显式声明的 provider 都有别名,那么 Terraform 运行时会构造一个所有配置均为空值的默认 provider。假如 provider 有必填字段,并且又有资源使用了默认 provider,那么 Terraform 会抛出一个错误,抱怨默认 provider 缺失了必填字段。
Expressions
表达式用来在配置文件中进行一些计算。最简单的表达式就是字面量,比如"hello”,或者 5。Terraform 也支持一些更加复杂的表达式,比如引用其他 resource 的输出值、数学计算、布尔条件计算,以及一些内建的函数。
Terraform 配置中很多地方都可以使用表达式,但某些特定的场景下限制了可以使用的表达式的类型,例如只准使用特定数据类型的字面量,或是禁止使用 resource 的输出值。
我们在类型章节中已经基本介绍了类型以及类型相关的字面量,下面我们来介绍一些其他的表达式。
下标和属性
list 和 tuple 可以通过下标访问成员,例如 local.list[3]、var.tuple[2]。map 和 object 可以通过属性访问成员,例如 local.object.attrname、local.map.keyname。由于 map 的 key 是用户定义的,可能无法成为合法的 Terraform 标识符,所以访问 map 成员时我们推荐使用方括号:local.map["keyname"]。
引用命名值
Terraform 中定义了多种命名值,表达式中的每一个命名值都关联到一个具体的值,我们可以用单一命名值作为一个表达式,或是组合多个命名值来计算出一个新值。
命名值有如下种类:
<RESOURCE TYPE>.<NAME>:表示一个资源对象。凡是不符合后面列出的命名值模式的表达式都会被 Terraform 解释为一个托管资源。如果资源声明了count元参数,那么该表达式表示的是一个对象实例的 list。如果资源声明了for_each元参数,那么该表达式表示的是一个对象实例的 map。var.<NAME>:表示一个输入变量local.<NAME>:表示一个局部值module.<MODULE_NAME>.<OUTPUT_NAME>:表示一个模块的一个输出值data.<DATA_TYPE>.<NAME>:表示一个数据源实例。如果数据源声明了 count 元参数,那么该表达式表示的是一个数据源实例 list。如果数据源声明了 for_each 元参数,那么该表达式表示的是一个数据源实例 map。path.module:表示当前模块在文件系统中的路径path.root:表示根模块(调用 Terraform 命令行执行的代码文件所在的模块)在文件系统中的路径path.cwd:表示当前工作目录的路径。一般来说该路径等同于 path.root,但在调用 Terraform 命令行时如果指定了代码路径,那么二者将会不同。terraform.workspace:当前使用的 Workspace(我们在状态管理的"状态的隔离存储"中介绍过)
虽然这些命名表达式可以使用 .<NAME> 号来访问对象的各种属性,但实际上他们实际类型并不是我们在类型章节里提到过的 object。两者的区别在于,object 同时支持使用 .<NAME> 或者["<NAME>"]两种方式访问对象成员属性,而上述命名表达式仅支持 .<NAME>。
局部命名值
在某些特定表达式或上下文当中,有一些特殊的命名值可以被使用,他们是局部命名值。几种比较常见的局部命名值有:
count.index:表达当前 count 下标序号each.key:表达当前 for_each 迭代器实例self:在预置器中指代声明预置器的资源
命名值的依赖关系
构建资源或是模块时经常会使用含有命名值的表达式赋值,Terraform 会分析这些表达式并自动计算出对象之间的依赖关系。
引用资源输出属性
最常见的引用类型就是引用一个 resource 或 data 块定义的对象的输出属性。由于这些资源与数据源对象结构可能非常复杂,所以对它们的输出属性的引用表达式也可能非常复杂。
比如下面这个例子:
resource "aws_instance" "example" {
ami = "ami-abc123"
instance_type = "t2.micro"
ebs_block_device {
device_name = "sda2"
volume_size = 16
}
ebs_block_device {
device_name = "sda3"
volume_size = 20
}
}
aws_instance文档列出了该类型所支持的所有输入参数和内嵌块,以及对外输出的属性列表。所有这些不同的资源类型 Schema 都可以在引用中使用,如下所示:
- ami 参数可以在可以在其他地方用
aws_instance.example.ami表达式来引用 - id 属性可以用
aws_instance.example.id的表达式来引用 - 内嵌的
ebs_block_device参数可以通过后面会介绍的展开表达式(splat expression)来访问,比如我们获取所有的ebs_block_device的device_name列表:aws_instance.example.ebs_block_device[*].device_name - 在
aws_instance类型里的内嵌块并没有任何输出属性,但如果ebs_block_device添加了一个名为"id"的输出属性,那么可以用aws_instance.example.ebs_block_device[*].id表达式来访问含有所有 id 的列表 - 有时多个内嵌块会各自包含一个逻辑键来区分彼此,类似用资源名访问资源,我们也可以用内嵌块的名字来访问特定内嵌块。假如
aws_instance类型有一个假想的内嵌块类型device并规定 device 可以赋予这样的一个逻辑键,那么代码看起来就会是这样的:
device "foo" {
size = 2
}
device "bar" {
size = 4
}
我们可以使用键来访问特定块的数据,例如:aws_instance.example.device["foo"].size
要获取一个 device 名称到 device 大小的映射,可以使用 for 表达式:
{for k, device in aws_instance.example.device : k => device.size}
当一个资源声明了 count 参数,那么资源本身就成了一个资源对象列表而非单个资源。这种情况下要访问资源输出属性,要么使用展开表达式,要么使用下标索引:
aws_instance.example[*].id:返回所有 instance 的 id 列表aws_instance.example[0].id:返回第一个 instance 的 id
当一个资源声明了 for_each参数,那么资源本身就成了一个资源对象字典而非单个资源。这种情况下要访问资源的输出属性,要么使用特定键,要么使用 for表达式:
aws_instance.example["a"].id:返回"a"对应的实例的 id[for value in aws_instance.example: value.id]:返回所有 instance 的 id
注意不像使用 count,使用 for_each 的资源集合不能直接使用展开表达式,展开表达式只能适用于列表。你可以把字典转换成列表后再使用展开表达式:
values(aws_instance.example)[*].id
尚不知晓的值
当 Terraform 在计算变更计划时,有些资源输出属性无法立即求值,因为他们的值取决于远程 API 的返回值。比如说,有一个远程对象可以在创建时返回一个生成的唯一 id,Terraform 无法在创建它之前就预知这个值。
为了允许在计算变更阶段就能计算含有这种值的表达式,Terraform 使用了一个特殊的"尚不知晓(unknown value)“占位符来代替这些结果。大部分时候你不需要特意理会它们,因为 Terraform 语言会自动处理这些尚不知晓的值,比如说使两个尚不知晓的值相加得到的会是一个尚不知晓的值。
然而,有些情况下表达式中含有尚不知晓的值会有明显的影响:
count元参数不可以为尚不知晓,因为变更计划必须明确地知晓到底要维护多少个目标实例- 如果尚不知晓的值被用于数据源,那么数据源在计算变更计划阶段就无法读取,它会被推迟到执行阶段读取。这种情况下,在计划阶段该数据源的一切输出均为尚不知晓
- 如果声明 module 块时传递给模块输入变量的表达式使用了尚不知晓值,那么在模块代码中任何使用了该输入变量值的表达式的值都将是尚不知晓
- 如果模块输出值表达式中含有尚不知晓值,任何使用该模块输出值的表达式都将是尚不知晓
- Terraform 会尝试验证尚不知晓值的数据类型是否合法,但仍然有可能无法正确检查数据类型,导致执行阶段发生错误
尚不知晓值在执行 terraform plan时会被输出为”(not yet known)"。
算数和逻辑操作符
一个操作符是一种用以转换或合并一个或多个表达式的表达式。操作符要么是把两个值计算为第三个值,也就是二元操作符;要么是把一个值转换成另一个值,也就是一元操作符。
二元操作符位于两个表达式的中间,类似 1+2。一元操作符位于一个表达式的前面,类似 !true。
Terraform 语言支持一组算数和逻辑操作符,它们的功能类似于 JavaScript 或 Ruby 里的操作符功能。
当一个表达式中含有多个操作符时,它们的优先级顺序时:
!,-(负号)*,/,%+,-(减号)>,>=,<,<===,!=&&||
可以使用小括号覆盖默认优先级。如果没有小括号,高优先级操作符会被先计算,例如 1+23 会被解释成 1+(23)而不是(1+2)*3。
不同的操作符可以按它们之间相似的行为被归纳为几组,每一组操作符都期待被给予特定类型的值。Terraform 会在类型不符时尝试进行隐式类型转换,如果失败则会抛错。
算数操作符
a + b:返回a与b的和a - b:返回a与b的差a * b:返回a与b的积a / b:返回a与b的商a % b:返回a与b的模。该操作符一般仅在a与b是整数时有效-a:返回a与-1的商
相等性操作符
a == b:如果a与b类型与值都相等返回true,否则返回falsea != b:与==相反
比较操作符
a < b:如果a比b小则为true,否则为falsea > b:如果a比b大则为true,否则为falsea <= b:如果a比b小或者相等则为true,否则为falsea >= b:如果a比b大或者相等则为true,否则为false
逻辑操作符
a || b:a或b中有至少一个为true则为true,否则为falsea && b:a与比都为true则为true,否则为false!a:如果a为true则为false,如果a为false则为true
条件表达式
条件表达式是判断一个布尔表达式的结果以便于在后续两个值当中选择一个:
condition ? true_val : false_val
如果 condition 表达式为 true,那么结果是 true_value,反之则为 false_value。
一个常见的条件表达式用法是使用默认值替代非法值:
var.a != "" ? var.a : "default-a"
如果输入变量 a的值是空字符串,那么结果会是 default-a,否则返回输入变量 a的值。
条件表达式的判断条件可以使用上述的任意操作符。供选择的两个值也可以是任意类型,但它们的类型必须相同,这样 Terraform 才能判断条件表达式的输出类型。
函数调用
Terraform 支持在计算表达式时使用一些内建函数,函数调用表达式类似操作符,通用语法是:
<FUNCTION NAME>(<ARGUMENT 1>, <ARGUMENT 2>)
函数名标明了要调用的函数。每一个函数都定义了数量不等、类型不一的入参以及不同类型的返回值。
有些函数定义了不定长的入参表,例如,min函数可以接收任意多个数值类型入参,返回其中最小的数值:
min(55, 3453, 2)
展开函数入参
如果想要把列表或元组的元素作为参数传递给函数,那么我们可以使用展开符:
min([55, 2453, 2]...)
展开符使用的是三个独立的 .号组成的 ...,不是 Unicode 中的省略号 …。展开符是一种只能用在函数调用场景下的特殊语法。
有关完整的内建函数我们可能会在今后撰写相应的章节介绍。
for 表达式
for 表达式是将一种复杂类型映射成另一种复杂类型的表达式。输入类型值中的每一个元素都会被映射为一个或零个结果。
举例来说,如果 var.list是一个字符串列表,那么下面的表达式将会把列表元素全部转为大写:
[for s in var.list : upper(s)]
在这里 for表达式迭代了 var.list中每一个元素(就是 s),然后计算了 upper(s),最后构建了一个包含了所有 upper(s)结果的新元组,元组内元素顺序与源列表相同。
for表达式周围的括号类型决定了输出值的类型。上面的例子里我们使用了方括号,所以输出类型是元组。如果使用的是花括号,那么输出类型是对象,for表达式内部冒号后面应该使用以 =>符号分隔的表达式:
{for s in var.list : s => upper(s)}
该表达式返回一个对象,对象的成员属性名称就是源列表中的元素,值就是对应的大写值。
一个 for表达式还可以包含一个可选的 if子句用以过滤结果,这可能会减少返回的元素数量:
[for s in var.list : upper(s) if s != ""]
被 for 迭代的也可以是对象或者字典,这样的话迭代器就会被表示为两个临时变量:
[for k, v in var.map : length(k) + length(v)]
最后,如果返回类型是对象(使用花括号)那么表达式中可以使用 ...符号实现 group by:
{for s in var.list : substr(s, 0, 1) => s... if s != ""}
展开表达式(Splat Expression)
展开表达式提供了一种类似 for表达式的简洁表达方式。比如说 var.list包含一组对象,每个对象有一个属性 id,那么读取所有 id 的 for 表达式会是这样:
[for o in var.list : o.id]
与之等价的展开表达式是这样的:
var.list[*].id
这个特殊的 [*]符号迭代了列表中每一个元素,然后返回了它们在 .号右边的属性值。
展开表达式只能被用于列表(所以使用 for_each参数的资源不能使用展开表达式,因为它的类型是字典)。然而,如果一个展开表达式被用于一个既不是列表又不是元组的值,那么这个值会被自动包装成一个单元素的列表然后被处理。
比如说,var.single_object[*].id 等价于 [var.single_object][*].id。大部分场景下这种行为没有什么意义,但在访问一个不确定是否会定义 count参数的资源时,这种行为很有帮助,例如:
aws_instance.example[*].id
上面的表达式不论 aws_instance.example定义了 count与否都会返回实例的 id 列表,这样如果我们以后为 aws_instance.example添加了 count参数我们也不需要修改这个表达式。
遗留的旧有展开表达式
曾经存在另一种旧的展开表达式语法,它是一种比较弱化的展开表达式,现在应该尽量避免使用。
这种旧的展开表达式使用 .*而不是 [*]:
var.list.*.interfaces[0].name
要特别注意该表达式与现有的展开表达式结果不同,它的行为等价于:
[for o in var.list : o.interfaces][0].name
而现有 [*]展开表达式的行为等价于:
[for o in var.list : o.interfaces[0].name]
注意两者右方括号的位置。
dynamic 块
在顶级块,例如 resource 块当中,一般只能以类似 name = expression的形式进行一对一的赋值。大部分情况下这已经够用了,但某些资源类型包含了可重复的内嵌块,无法使用表达式循环赋值:
resource "aws_elastic_beanstalk_environment" "tfenvtest" {
name = "tf-test-name" # can use expressions here
setting {
# but the "setting" block is always a literal block
}
}
你可以用 dynamic块来动态构建重复的 setting这样的内嵌块:
resource "aws_elastic_beanstalk_environment" "tfenvtest" {
name = "tf-test-name"
application = "${aws_elastic_beanstalk_application.tftest.name}"
solution_stack_name = "64bit Amazon Linux 2018.03 v2.11.4 running Go 1.12.6"
dynamic "setting" {
for_each = var.settings
content {
namespace = setting.value["namespace"]
name = setting.value["name"]
value = setting.value["value"]
}
}
}
dynamic可以在 resource、data、provider和 provisioner块内使用。一个 dynamic块类似于 for表达式,只不过它产生的是内嵌块。它可以迭代一个复杂类型数据然后为每一个元素生成相应的内嵌块。在上面的例子里:
dynamic的标签(也就是"setting")确定了我们要生成的内嵌块种类for_each参数提供了需要迭代的复杂类型值- iterator 参数(可选)设置了用以表示当前迭代元素的临时变量名。如果没有设置 iterator,那么临时变量名默认就是
dynamic块的标签(也就是setting) labels参数(可选)是一个表示块标签的有序列表,用以按次序生成一组内嵌块。有labels参数的表达式里可以使用临时的iterator变量- 内嵌的
content块定义了要生成的内嵌块的块体。你可以在content块内部使用临时的iterator变量
由于 for_each参数可以是集合或者结构化类型,所以你可以使用 for表达式或是展开表达式来转换一个现有集合的类型。
iterator 变量(上面的例子里就是 setting)有两个属性:
key:迭代容器如果是 map,那么就是当前元素的键;迭代容器如果是 list,那么就是当前元素在 list 中的下标序号;如果是由 for_each 表达式产出的 set,那么 key 和 value 是一样的,这时我们不应该使用 key。value:当前元素的值
一个 dynamic块只能生成属于当前块定义过的内嵌块参数。无法生成诸如 lifecycle、provisioner这样的元参数,因为 Terraform 必须在确保对这些元参数求值的计算是成功的。
for_each的值必须是不为空的 map 或者 set。如果你需要根据内嵌数据结构或者多个数据结构的元素组合来声明资源实例集合,你可以使用 Terraform 表达式和函数来生成合适的值。
dynamic 块的最佳实践
过度使用 dynamic块会导致代码难以阅读以及维护,所以我们建议只在需要构造可重用的模块代码时使用 dynamic块。尽可能手写内嵌块。
字符串字面量
Terraform 有两种不同的字符串字面量。最通用的就是用一对双引号包裹的字符,比如 "hello"。在双引号之间,反斜杠 \被用来进行转义。Terraform 支持的转义符有:
| Sequence | Replacement |
|---|---|
| \n | 换行 |
| \r | 回车 |
| \t | 制表符 |
| " | 双引号 (不会截断字符串) |
| \ | 反斜杠 |
| \uNNNN | 普通字符映射平面的 Unicode 字符(NNNN 代表四位 16 进制数) |
| \UNNNNNNNN | 补充字符映射平面的 Unicode 字符(NNNNNNNN 代表八位 16 进制数) |
另一种字符串表达式被称为"heredoc"风格,是受 Unix Shell 语言启发。它可以使用自定义的分隔符更加清晰地表达多行字符串:
<<EOT
hello
world
EOT
«标记后面直到行尾组成的标识符开启了字符串,然后 Terraform 会把剩下的行都添加进字符串,直到遇到与标识符完全相等的字符串为止。在上面的例子里,EOT 就是标识符。任何字符都可以用作标识符,但传统上标识符一般以 EO 起头。上面例子里的 EOT 代表"文本的结束(end of text)"。
上面例子里的 heredoc 风格字符串要求内容必须对齐行头,这在块内声明时看起来会比较奇怪:
block {
value = <<EOT
hello
world
EOT
}
为了改进可读性,Terraform 也支持**缩进的**heredoc,只要把«改成«-:
block {
value = <<-EOT
hello
world
EOT
}
上面的例子里,Terraform 会以最靠近行头的行作为基准来调整行头缩进,得到的字符串是这样的:
hello
world
heredoc 中的反斜杠不会被解释成转义,而只会是简单的反斜杠。
双引号和 heredoc 两种字符串都支持字符串模版,模版的形式是 ${...}以及 %{...}。如果想要表达 ${或者 %{的字面量,那么可以重复第一个字符:$${和 %%{ 。
字符串模版
字符串模版允许我们在字符串中嵌入表达式,或是通过其他值动态构造字符串。
插值(Interpolation)
一个 ${...}序列被称为插值,插值计算花括号之间的表达式的值,有必要的话将之转换为字符串,然后插入字符串模版,形成最终的字符串:
"Hello, ${var.name}!"
上面的例子里,输入变量 var.name的值被访问后插入了字符串模版,产生了最终的结果,比如:"Hello, Juan!"
命令(Directive)
一个 %{...}序列被称为命令,命令可以是一个布尔表达式或者是对集合的迭代,类似条件表达式以及 for表达式。有两种命令:
if \<BOOL\> / else /endif命令根据布尔表达式的结果在两个模版中选择一个:
"Hello, %{ if var.name != "" }${var.name}%{ else }unnamed%{ endif }!"
else部分可以省略,这样如果布尔表达结果为 false 那么就会插入空字符串。
for \<NAME\> in \<COLLECTION\> / endfor命令迭代一个结构化对象或者集合,用每一个元素渲染模版,然后把它们拼接起来:
<<EOT
%{ for ip in aws_instance.example.*.private_ip }
server ${ip}
%{ endfor }
EOT
for关键字后紧跟的名字被用作代表迭代器元素的临时变量,可以用来在内嵌模版中使用。
为了在不添加额外空格和换行的前提下提升可读性,所有的模版序列都可以在首尾添加 ~符号。如果有 ~符号,那么模版序列会去除字符串左右的空白(空格以及换行)。如果 ~出现在头部,那么会去除字符串左侧的空白;如果出现在尾部,那么会去除字符串右边的空白:
<<EOT
%{ for ip in aws_instance.example.*.private_ip ~}
server ${ip}
%{ endfor ~}
EOT
上面的例子里,命令符后面的换行符被忽略了,但是 server ${ip}后面的换行符被保留了,这确保了每一个元素生成一行输出:
server 10.1.16.154
server 10.1.16.1
server 10.1.16.34
当使用模版命令时,我们推荐使用 heredoc 风格字符串,用多行模版提升可读性。双引号字符串内最好只使用插值。
Terraform 插值
Terraform 曾经只支持在表达式中使用插值,例如
resource "aws_instance" "example" {
ami = var.image_id
# ...
}
这种语法是在 Terraform 0.12 后才被支持的。在 Terrafor 0.11 及更早的版本中,这段代码只能被写成这样:
resource "aws_instance" "example" {
ami = "${var.image_id}"
# ...
}
Terraform 0.12 保持了向前兼容,所以现在这样的代码也仍然是合法的。读者们也许会在一些 Terraform 代码和文档中继续看到这样的写法,但请尽量避免继续这样书写纯插值字符串,而是直接使用表达式。
Functions
Terraform Settings
State
Terraform 将每次执行基础设施变更操作时的状态信息保存在一个状态文件中,默认情况下会保存在当前工作目录下的 terraform.tfstate文件里。例如我们在代码中声明一个 data 和一个 resource:当我们成功地执行了一次 terraform apply,创建了期望的基础设施以后,我们如果再次执行 terraform apply,生成的新的执行计划将不会包含任何变更,Terraform 会记住当前基础设施的状态,并将之与代码所描述的期望状态进行比对。第二次 apply 时,因为当前状态已经与代码描述的状态一致了,所以会生成一个空的执行计划。
data "ucloud_images" "default" {
availability_zone = "cn-sh2-01"
name_regex = "^CentOS 6.5 64"
image_type = "base"
}
resource "ucloud_vpc" "vpc" {
cidr_blocks = ["10.0.0.0/16"]
name = "my-vpc"
}
使用 terraform apply后,我们可以看到 terraform.tfstate的内容:
|
|
我们可以看到,查询到的 data 以及创建的 resource 信息都被以 json 格式保存在 tfstate 文件里。
我们前面已经说过,由于 tfstate 文件的存在,我们在 terraform apply 之后立即再次 apply 是不会执行任何变更的,那么如果我们删除了这个 tfstate 文件,然后再执行 apply 会发生什么呢?Terraform 读取不到 tfstate 文件,会认为这是我们第一次创建这组资源,所以它会再一次创建代码中描述的所有资源。更加麻烦的是,由于我们前一次创建的资源所对应的状态信息被我们删除了,所以我们再也无法通过执行 terraform destroy来销毁和回收这些资源,实际上产生了资源泄漏。所以妥善保存这个状态文件是非常重要的。
另外,如果我们对 Terraform 的代码进行了一些修改,导致生成的执行计划将会改变状态,那么在实际执行变更之前,Terraform 会复制一份当前的 tfstate 文件到同路径下的 terraform.tfstate.backup中,以防止由于各种意外导致的 tfstate 损毁。
在 Terraform 发展的极早期,HashiCorp 曾经尝试过无状态文件的方案,也就是在执行 Terraform 变更计划时,给所有涉及到的资源都打上特定的 tag,在下次执行变更时,先通过 tag 读取相关资源来重建状态信息。但因为并不是所有资源都支持打 tag,也不是所有公有云都支持多 tag,所以 Terraform 最终决定用状态文件方案。
还有一点,HashiCorp 官方从未公开过 tfstate 的格式,也就是说,HashiCorp 保留随时修改 tfstate 格式的权力。所以不要试图手动或是用自研代码去修改 tfstate,Terraform 命令行工具提供了相关的指令(我们后续会介绍到),请确保只通过命令行的指令操作状态文件。
tfstate 管理方案: backend
到目前为止我们的 tfstate 文件是保存在当前工作目录下的本地文件,假设我们的计算机损坏了,导致文件丢失,那么 tfstate 文件所对应的资源都将无法管理,而产生资源泄漏。
另外如果我们是一个团队在使用 Terraform 管理一组资源,团队成员之间要如何共享这个状态文件?能不能把 tfstate 文件签入源代码管理工具进行保存?
把 tfstate 文件签入管代码管理工具是非常错误的,这就好比把数据库签入了源代码管理工具,如果两个人同时签出了同一份 tfstate,并且对代码做了不同的修改,又同时 apply 了,这时想要把 tfstate 签入源码管理系统可能会遭遇到无法解决的冲突。
为了解决状态文件的存储和共享问题,Terraform 引入了远程状态存储机制,也就是 Backend。Backend 是一种抽象的远程存储接口,如同 Provider 一样,Backend 也支持多种不同的远程存储服务。
Terraform Remote Backend 分为两种:
- 标准:支持远程状态存储与状态锁
- 增强:在标准的基础上支持远程操作(在远程服务器上执行 plan、apply 等操作)
目前增强型 Backend 只有 Terraform Cloud 云服务一种。
状态锁是指,当针对一个 tfstate 进行变更操作时,可以针对该状态文件添加一把全局锁,确保同一时间只能有一个变更被执行。不同的 Backend 对状态锁的支持不尽相同,实现状态锁的机制也不尽相同,例如 consul backend 就通过一个.lock 节点来充当锁,一个.lockinfo 节点来描述锁对应的会话信息,tfstate 文件被保存在 backend 定义的路径节点内;s3 backend 则需要用户传入一个 Dynamodb 表来存放锁信息,而 tfstate 文件被存储在 s3 存储桶里。名为 etcd 的 backend 对应的是 etcd v2,它不支持状态锁;etcdv3 则提供了对状态锁的支持,等等等等。
Modules
创建模块
实际上所有包含 Terraform 代码文件的文件夹都是一个 Terraform 模块。我们如果直接在一个文件夹内执行 terraform apply或者 terraform plan命令,那么当前所在的文件夹就被称为根模块(root module)。我们也可以在执行 Terraform 命令时通过命令行参数指定根模块的路径。
模块结构
旨在被重用的模块与我们编写的根模块使用的是相同的 Terraform 代码和代码风格规范。一般来讲,在一个模块中,会有:
- 一个
README文件,用来描述模块的用途。文件名可以是README或者README.md,后者应采用 Markdown 语法编写。可以考虑在README中用可视化的图形来描绘创建的基础设施资源以及它们之间的关系。README中不需要描述模块的输入输出,因为工具会自动收集相关信息。如果在README中引用了外部文件或图片,请确保使用的是带有特定版本号的绝对 URL 路径以防止未来指向错误的版本 - 一个
LICENSE描述模块使用的许可协议。如果你想要公开发布一个模块,最好考虑包含一个明确的许可证协议文件,许多组织不会使用没有明确许可证协议的模块 - 一个examples 文件夹用来给出一个调用样例(可选)
- 一个
variables.tf文件,包含模块所有的输入变量。输入变量应该有明确的描述说明用途 - 一个
outputs.tf文件,包含模块所有的输出值。输出值应该有明确的描述说明用途 - 嵌入模块文件夹,出于封装复杂性或是复用代码的目的,我们可以在 modules 子目录下建立一些嵌入模块。所有包含 README 文件的嵌入模块都可以被外部用户使用;不含
README文件的模块被认为是仅在当前模块内使用的(可选) - 一个
main.tf,它是模块主要的入口点。对于一个简单的模块来说,可以把所有资源都定义在里面;如果是一个比较复杂的模块,我们可以把创建的资源分布到不同的代码文件中,但引用嵌入模块的代码还是应保留在main.tf里 - 其他定义了各种基础设施对象的代码文件(可选)
如果模块含有多个嵌入模块,那么应避免它们彼此之间的引用,由根模块负责组合它们。
由于 examples/中的代码经常会被拷贝到其他项目中进行修改,所有在 examples/代码中引用本模块时使用的引用路径应使用外部调用者可以使用的路径,而非相对路径。
一个最小化模块推荐的结构是这样的:
$ tree minimal-module/
.
├── README.md
├── main.tf
├── variables.tf
├── outputs.tf
一个更完整一些的模块结构可以是这样的:
$ tree complete-module/
.
├── README.md
├── main.tf
├── variables.tf
├── outputs.tf
├── ...
├── modules/
│ ├── nestedA/
│ │ ├── README.md
│ │ ├── variables.tf
│ │ ├── main.tf
│ │ ├── outputs.tf
│ ├── nestedB/
│ ├── .../
├── examples/
│ ├── exampleA/
│ │ ├── main.tf
│ ├── exampleB/
│ ├── .../
避免过深的模块结构
我们刚才提到可以在 modules/子目录下创建嵌入模块。Terraform 倡导"扁平"的模块结构,只应保持一层嵌入模块,防止在嵌入模块中继续创建嵌入模块。应将嵌入模块设计成易于组合的结构,使得在根模块中可以通过组合各个嵌入模块创建复杂的基础设施。
使用模块
在 Terraform 代码中引用一个模块,使用的是 module 块。
每当在代码中新增、删除或者修改一个 module 块之后,都要执行 terraform init 或是 terraform get 命令来获取模块代码并安装到本地磁盘上。
模块源
module 块定义了一个 source 参数,指定了模块的源;Terraform 目前支持如下模块源:
- 本地路径
- Terraform Registry
- GitHub
- Bitbucket
- 通用 Git、Mercurial 仓库
- HTTP 地址
- S3 buckets
- GCS buckets
我们后面会一一讲解这些模块源的使用。source 使用的是 URL 风格的参数,但某些源支持在 source 参数中通过额外参数指定模块版本。
出于消除重复代码的目的我们可以重构我们的根模块代码,将一些拥有重复模式的代码重构为可反复调用的嵌入模块,通过本地路径来引用。
许多的模块源类型都支持从当前系统环境中读取认证信息,例如环境变量或系统配置文件。我们在介绍模块源的时候会介绍到这方面的信息。
我们建议每个模块把期待被重用的基础设施声明在各自的根模块位置上,但是直接引用其他模块的嵌入模块也是可行的。
本地路径
使用本地路径可以使我们引用同一项目内定义的子模块:
module "consul" {
source = "./consul"
}
一个本地路径必须以 ./ 或者 ../ 为前缀来标明要使用的本地路径,以区别于使用 Terraform Registry 路径。
本地路径引用模块和其他源类型有一个区别,本地路径引用的模块不需要下载相关源代码,代码已经存在于本地相关路径的磁盘上了。
Terraform Registry
Registry 目前是 Terraform 官方力推的模块仓库方案,采用了 Terraform 定制的协议,支持版本化管理和使用模块。
官方提供的 公共仓库 保存和索引了大量公共模块,在这里可以很容易地搜索到各种官方和社区提供的高质量模块。
读者也可以通过 Terraform Cloud 服务维护一个私有模块仓库,或是通过实现 Terraform 模块注册协议 来实现一个私有仓库。
公共仓库的的模块可以用 <NAMESPACE>/<NAME>/<PROVIDER> 形式的源地址来引用,在公共仓库上的模块介绍页面上都包含了确切的源地址,例如:
module "consul" {
source = "hashicorp/consul/aws"
version = "0.1.0"
}
对于那些托管在其他仓库的模块,在源地址头部添加 HOSTNAME 部分,指定私有仓库的主机名:
module "consul" {
source = "app.terraform.io/example-corp/k8s-cluster/azurerm"
version = "1.1.0"
}
如果你使用的是 SaaS 版本的 Terraform Cloud,那么托管在上面的私有仓库的主机名是 app.terraform.io 。如果使用的是私有部署的 Terraform 企业版,那么托管在上面的私有仓库的主机名就是 Terraform 企业版服务的主机名。
模块仓库支持版本化。你可以在 module 块中指定模块的版本约束。
如果要引用私有仓库的模块,你需要首先通过配置命令行工具配置文件来设置访问凭证。
GitHub
Terraform 发现 source 参数的值如果是以 github.com 为前缀时,会将其自动识别为一个 GitHub 源:
module "consul" {
source = "github.com/hashicorp/example"
}
上面的例子里会自动使用 HTTPS 协议克隆仓库。如果要使用 SSH 协议,那么请使用如下的地址:
module "consul" {
source = "git@github.com:hashicorp/example.git"
}
GitHub 源的处理与后面要介绍的通用 Git 仓库是一样的,所以他们获取 git 凭证和通过 ref参数引用特定版本的方式都是一样的。如果要访问私有仓库,你需要额外配置 git 凭证。
Bitbucket
Terraform 发现 source 参数的值如果是以 bitbucket.org 为前缀时,会将其自动识别为一个 Bitbucket 源:
module "consul" {
source = "bitbucket.org/hashicorp/terraform-consul-aws"
}
这种捷径方法只针对公共仓库有效,因为 Terraform 必须访问 ButBucket API 来了解仓库使用的是 Git 还是 Mercurial 协议。
Terraform 根据仓库的类型来决定将它作为一个 Git 仓库还是 Mercurial 仓库来处理。后面的章节会介绍如何为访问仓库配置访问凭证以及指定要使用的版本号。
通用 Git 仓库
可以通过在地址开头加上特殊的 git:: 前缀来指定使用任意的 Git 仓库。在前缀后跟随的是一个合法的 Git URL。
使用 HTTPS 和 SSH 协议的例子:
module "vpc" {
source = "git::https://example.com/vpc.git"
}
module "storage" {
source = "git::ssh://username@example.com/storage.git"
}
Terraform 使用 git clone 命令安装模块代码,所以 Terraform 会使用本地 Git 系统配置,包括访问凭证。要访问私有 Git 仓库,必须先配置相应的凭证。
如果使用了 SSH 协议,那么会自动使用系统配置的 SSH 证书。通常情况下我们通过这种方法访问私有仓库,因为这样可以不需要交互式提示就可以访问私有仓库。
如果使用 HTTP/HTTPS 协议,或是其他需要用户名、密码作为凭据,你需要配置 Git 凭据存储来选择一个合适的凭据源。
默认情况下,Terraform 会克隆默认分支。可以通过 ref 参数来指定版本:
module "vpc" {
source = "git::https://example.com/vpc.git?ref=v1.2.0"
}
ref 参数会被用作 git checkout 命令的参数,可以是分支名或是 tag 名。
使用 SSH 协议时,我们更推荐 ssh:// 的地址。你也可以选择 scp 风格的语法,故意忽略 ssh:// 的部分,只留 git::,例如:
module "storage" {
source = "git::username@example.com:storage.git"
}
通用 Mercurial 仓库
可以通过在地址开头加上特殊的 hg:: 前缀来指定使用任意的 Mercurial 仓库。在前缀后跟随的是一个合法的 Mercurial URL:
module "vpc" {
source = "hg::http://example.com/vpc.hg"
}
Terraform 会通过运行 hg clone 命令从 Mercurial 仓库安装模块代码,所以 Terraform 会使用本地 Mercurial 系统配置,包括访问凭证。要访问私有 Mercurial 仓库,必须先配置相应的凭证。
如果使用了 SSH 协议,那么会自动使用系统配置的 SSH 证书。通常情况下我们通过这种方法访问私有仓库,因为这样可以不需要交互式提示就可以访问私有仓库。
类似 Git 源,我们可以通过 ref 参数指定非默认的分支或者标签来选择特定版本:
module "vpc" {
source = "hg::http://example.com/vpc.hg?ref=v1.2.0"
}
HTTP 地址
当我们使用 HTTP 或 HTTPS 地址时,Terraform 会向指定 URL 发送一个 GET 请求,期待返回另一个源地址。这种间接的方法使得 HTTP 可以成为一个更复杂的模块源地址的指示器。
然后 Terraform 会再发送一个 GET 请求到之前响应的地址上,并附加一个查询参数 terraform-get=1,这样服务器可以选择当 Terraform 来查询时可以返回一个不一样的地址。
如果相应的状态码是成功的(200 范围的成功状态码),Terraform 就会通过以下位置来获取下一个访问地址:
- 响应头部的
X-Terraform-Get值 - 如果响应内容是一个 HTML 页面,那么会检查名为
terraform-get的 html meta 元素:
<meta name="terraform-get"
content="github.com/hashicorp/example" />
不管用哪种方式返回的地址,Terraform 都会像本章提到的其他的源地址那样处理它。
如果 HTTP/HTTPS 地址需要认证凭证,可以在 HOME 文件夹下配置一个 .netrc 文件,详见相关文档
也有一种特殊情况,如果 Terraform 发现地址有着一个常见的存档文件的后缀名,那么 Terraform 会跳过 terraform-get=1 重定向的步骤,直接将响应内容作为模块代码使用。
module "vpc" {
source = "https://example.com/vpc-module.zip"
}
目前支持的后缀名有:
ziptar.bz2和tbz2tar.gz和tgztar.xz和txz
如果 HTTP 地址不以这些文件名结尾,但又的确指向模块存档文件,那么可以使用 archive 参数来强制按照这种行为处理地址:
module "vpc" {
source = "https://example.com/vpc-module?archive=zip"
}
Bucket
你可以把模块存档保存在 AWS S3 桶里,使用 s3:: 作为地址前缀,后面跟随一个 S3 对象访问地址
module "consul" {
source = "s3::https://s3-eu-west-1.amazonaws.com/examplecorp-terraform-modules/vpc.zip"
}
Terraform 识别到 s3:: 前缀后会使用 AWS 风格的认证机制访问给定地址。这使得这种源地址也可以搭配其他提供了 S3 协议兼容的对象存储服务使用,只要他们的认证方式与 AWS 相同即可。
保存在 S3 桶内的模块存档文件格式必须与上面 HTTP 源提到的支持的格式相同,Terraform 会下载并解压缩模块代码。
模块安装器会从以下位置寻找 AWS 凭证,按照优先级顺序排列:
AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY环境变量- HOME 目录下
.aws/credentials文件内的默认 profile - 如果是在 AWS EC2 主机内运行的,那么会尝试使用搭载的 IAM 主机实例配置。
GCS Bucket
你可以把模块存档保存在谷歌云 GCS 储桶里,使用 gcs:: 作为地址前缀,后面跟随一个 GCS 对象访问地址:
module "consul" {
source = "gcs::https://www.googleapis.com/storage/v1/modules/foomodule.zip"
}
模块安装器会使用谷歌云 SDK 的凭据来访问 GCS。要设置凭据,你可以:
- 通过
GOOGLE_APPLICATION_CREDENTIALS环境变量配置服务账号的密钥文件 - 如果是在谷歌云主机上运行的 Terraform,可以使用默认凭据。访问相关文档获取完整信息
- 可以使用命令行
gcloud auth application-default login设置
直接引用子文件夹中的模块
引用版本控制系统或是对象存储服务中的模块时,模块本身可能存在于存档文件的一个子文件夹内。我们可以使用特殊的 // 语法来指定 Terraform 使用存档内特定路径作为模块代码所在位置,例如:
hashicorp/consul/aws//modules/consul-clustergit::https://example.com/network.git//modules/vpchttps://example.com/network-module.zip//modules/vpcs3::https://s3-eu-west-1.amazonaws.com/examplecorp-terraform-modules/network.zip//modules/vpc
如果源地址中包含又参数,例如指定特定版本号的 ref 参数,那么把子文件夹路径放在参数之前:
git::https://example.com/network.git//modules/vpc?ref=v1.2.0
Terraform 会解压缩整个存档文件后,读取特定子文件夹。所以,对于一个存在于子文件夹中的模块来说,通过本地路径引用同一个存档内的另一个模块是安全的。
使用模块
我们刚才介绍了如何用 source 指定模块源,下面我们继续讲解如何在代码中使用一个模块。
我们可以把模块理解成类似函数,如同函数有输入参数表和输出值一样,我们之前介绍过 Terraform 代码有输入变量和输出值。我们在 module 块的块体内除了 source 参数,还可以对该模块的输入变量赋值:
|
|
在这个例子里,我们将会创建 ./app-cluster文件夹下 Terraform 声明的一系列资源,该模块的 servers 输入变量的值被我们设定成了 5。
在代码中新增、删除或是修改一个某块的 source,都需要重新运行 terraform init 命令。默认情况下,该命令不会升级已安装的模块(例如 source 未指定版本,过去安装了旧版本模块代码,那么执行 terraform init 不会自动更新到新版本);可以执行 terraform init -upgrade 来强制更新到最新版本模块。
访问模块输出值
在模块中定义的资源和数据源都是被封装的,所以模块调用者无法直接访问它们的输出属性。然而,模块可以声明一系列输出值,来选择性地输出特定的数据供模块调用者使用。
举例来说,如果 ./app-cluster 模块定义了名为 instance_ids 的输出值,那么模块的调用者可以像这样引用它:
resource "aws_elb" "example" {
# ...
instances = module.servers.instance_ids
}
其他的模块元参数
除了 source 以外,目前 Terraform 还支持在 module 块上声明其他一些可选元参数:
version:指定引用的模块版本,在后面的部分会详细介绍count和for_each:这是 Terraform 0.13 开始支持的特性,类似resource与data,我们可以创建多个module实例providers:通过传入一个map我们可以指定模块中的 Provider 配置,我们将在后面详细介绍depends_on:创建整个模块和其他资源之间的显式依赖。直到依赖项创建完毕,否则声明了依赖的模块内部所有的资源及内嵌的模块资源都会被推迟处理。模块的依赖行为与资源的依赖行为相同
除了上述元参数以外,lifecycle 参数目前还不能被用于模块,但关键字被保留以便将来实现。
模块版本约束
使用 registry 作为模块源时,可以使用 version 元参数约束使用的模块版本:
module "consul" {
source = "hashicorp/consul/aws"
version = "0.0.5"
servers = 3
}
version 元参数的格式与 Provider 版本约束的格式一致。在满足版本约束的前提下,Terraform 会使用当前已安装的最新版本的模块实例。如果当前没有满足约束的版本被安装过,那么会下载符合约束的最新的版本。
version 元参数只能配合 registry 使用,公共的或者私有的模块仓库都可以。其他类型的模块源可能支持版本化,也可能不支持。本地路径模块不支持版本化。
多实例模块
可以通过在 module 块上声明 for_each 或者 count 来创造多实例模块。在使用上 module 上的 for_each 和 count 与资源、数据源块上的使用是一样的。
# my_buckets.tf
module "bucket" {
for_each = toset(["assets", "media"])
source = "./publish_bucket"
name = "${each.key}_bucket"
}
# publish_bucket/bucket-and-cloudfront.tf
variable "name" {} # this is the input parameter of the module
resource "aws_s3_bucket" "example" {
# Because var.name includes each.key in the calling
# module block, its value will be different for
# each instance of this module.
bucket = var.name
# ...
}
resource "aws_iam_user" "deploy_user" {
# ...
}
这个例子定义了一个位于 ./publish_bucket 目录下的本地子模块,模块创建了一个 S3 存储桶,封装了桶的信息以及其他实现细节。
我们通过 for_each 参数声明了模块的多个实例,传入一个 map 或是 set 作为参数值。另外,因为我们使用了 for_each,所以在 module 块里可以使用 each 对象,例子里我们使用了 each.key。如果我们使用的是 count 参数,那么我们可以使用 count.index。
子模块里创建的资源在执行计划或 UI 中的名称会以 module.module_name[module index] 作为前缀。如果一个模块没有声明 count 或者 for_each,那么资源地址将不包含 module index。
在上面的例子里,./publish_bucket 模块包含了 aws_s3_bucket.example 资源,所以两个 S3 桶实例的名字分别是 module.bucket["assets"].aws_s3_bucket.example 以及 module.bucket["media"].aws_s3_bucket.example。
模块内的 Provider
当代码中声明了多个模块时,资源如何与 Provider 实例关联就需要特殊考虑。
每一个资源都必须关联一个 Provider 配置。不像 Terraform 其他的概念,Provider 配置在 Terraform 项目中是全局的,可以跨模块共享。Provider 配置声明只能放在根模块中。
Provider 有两种方式传递给子模块:隐式继承,或是显式通过 module 块的 providers 参数传递。
一个旨在被复用的模块不允许声明任何 provider 块,只有使用"代理 Provider"模式的情况除外,我们后面会介绍这种模式。
出于向前兼容 Terraform 0.10 及更早版本的考虑,Terraform 目前在模块代码中只用到了 Terraform 0.10 及更早版本的功能时,不会针对模块代码中声明 provider 块报错,但这是一个不被推荐的遗留模式。一个含有自己的 provider 块定义的遗留模块与 for_each、count 和 depends_on 等 0.13 引入的新特性是不兼容的。
Provider 配置被用于相关资源的所有操作,包括销毁远程资源对象以及更新状态信息等。Terraform 会在状态文件中保存针对最近用来执行所有资源变更的 Provider 配置的引用。当一个 resource 块被删除时,状态文件中的相关记录会被用来定位到相应的配置,因为原来包含 provider 参数(如果声明了的话)的 resource 块已经不存在了。
这导致了,你必须确保删除所有相关的资源配置定义以后才能删除一个 Provider 配置。如果 Terraform 发现状态文件中记录的某个资源对应的 Provider 配置已经不存在了会报错,要求你重新给出相关的 Provider 配置。
模块内的 Provider 版本限制
虽然 Provider 配置信息在模块间共享,每个模块还是得声明各自的模块需求,这样 Terraform 才能决定一个适用于所有模块配置的 Provider 版本。
为了定义这样的版本约束要求,可以在 terraform 块中使用 required_providers 块:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = ">= 2.7.0"
}
}
}
有关 Provider 的 source 和版本约束的信息我们已经在前文中有所记述,在此不再赘述。
隐式 Provider 继承
为了方便,在一些简单的代码中,一个子模块会从调用者那里自动地继承默认的 Provider 配置。这意味着显式 provider 块声明仅位于根模块中,并且下游子模块可以简单地声明使用该类型 Provider 的资源,这些资源会自动关联到根模块的 Provider 配置上。
例如,根模块可能只含有一个 provider 块和一个 module 块:
provider "aws" {
region = "us-west-1"
}
module "child" {
source = "./child"
}
子模块可以声明任意关联 aws 类型 Provider 的资源而无需额外声明 Provider 配置:
resource "aws_s3_bucket" "example" {
bucket = "provider-inherit-example"
}
当每种类型的 Provider 都只有一个实例时我们推荐使用这种方式。
要注意的是,只有 Provider 配置会被子模块继承,Provider 的 source 或是版本约束条件则不会被继承。每一个模块都必须声明各自的 Provider 需求条件,这在使用非 HashiCorp 的 Provider 时尤其重要。
显式传递 Provider
当不同的子模块需要不同的 Provider 实例,或者子模块需要的 Provider 实例与调用者自己使用的不同时,我们需要在 module 块上声明 providers 参数来传递子模块要使用的 Provider 实例。例如:
# The default "aws" configuration is used for AWS resources in the root
# module where no explicit provider instance is selected.
provider "aws" {
region = "us-west-1"
}
# An alternate configuration is also defined for a different
# region, using the alias "usw2".
provider "aws" {
alias = "usw2"
region = "us-west-2"
}
# An example child module is instantiated with the alternate configuration,
# so any AWS resources it defines will use the us-west-2 region.
module "example" {
source = "./example"
providers = {
aws = aws.usw2
}
}
module 块里的 providers 参数类似 resource 块里的 provider 参数,区别是前者接收的是一个 map 而不是单个 string,因为一个模块可能含有多个不同的 Provider。
providers 的 map 的键就是子模块中声明的 Provider 需求中的名字,值就是在当前模块中对应的 Provider 配置的名字。
如果 module 块内声明了 providers 参数,那么它将重载所有默认的继承行为,所以你需要确保给定的 map 覆盖了子模块所需要的所有 Provider。这避免了显式赋值与隐式继承混用时带来的混乱和意外。
额外的 Provider 配置(使用 alias 参数的)将永远不会被子模块隐式继承,所以必须显式通过 providers 传递。比如,一个模块配置了两个 AWS 区域之间的网络打通,所以需要配置一个源区域 Provider 和目标区域 Provider。这种情况下,根模块代码看起来是这样的:
provider "aws" {
alias = "usw1"
region = "us-west-1"
}
provider "aws" {
alias = "usw2"
region = "us-west-2"
}
module "tunnel" {
source = "./tunnel"
providers = {
aws.src = aws.usw1
aws.dst = aws.usw2
}
}
子目录 ./tunnel 必须包含像下面的例子那样声明"Provider 代理",声明模块调用者必须用这些名字传递的 Provider 配置:
provider "aws" {
alias = "src"
}
provider "aws" {
alias = "dst"
}
./tunnel 模块中的每一种资源都应该通过 provider 参数声明它使用的是 aws.src 还是 aws.dst。
Provider 代理配置块
一个 Provider 代理配置只包含 alias 参数,它就是一个模块间传递 Provider 配置的占位符,声明了模块期待显式传递的额外(带有 alias 的)Provider 配置。
需要注意的是,一个完全为空的 Provider 配置块也是合法的,但没有必要。只有在模块内需要带 alias 的 Provider 时才需要代理配置块。如果模块中只是用默认 Provider 时请不要声明代理配置块,也不要仅为了声明 Provider 版本约束而使用代理配置块。
模块元参数
在 Terraform 0.13 之前,模块在使用上存在一些限制。例如我们通过模块来创建 EC2 主机,可以这样:
module "ec2_instance" {
source = "terraform-aws-modules/ec2-instance/aws"
version = "~> 3.0"
name = "single-instance"
ami = "ami-ebd02392"
instance_type = "t2.micro"
key_name = "user1"
monitoring = true
vpc_security_group_ids = ["sg-12345678"]
subnet_id = "subnet-eddcdzz4"
tags = {
Terraform = "true"
Environment = "dev"
}
}
如果我们要创建两台这样的主机怎么办?在 Terraform 0.13 之前的版本中,由于 Module 不支持元参数,所以我们只能手动拷贝模块代码:
module "ec2_instance_0" {
source = "terraform-aws-modules/ec2-instance/aws"
version = "~> 3.0"
name = "single-instance-0"
ami = "ami-ebd02392"
instance_type = "t2.micro"
key_name = "user1"
monitoring = true
vpc_security_group_ids = ["sg-12345678"]
subnet_id = "subnet-eddcdzz4"
tags = {
Terraform = "true"
Environment = "dev"
}
}
module "ec2_instance_1" {
source = "terraform-aws-modules/ec2-instance/aws"
version = "~> 3.0"
name = "single-instance-1"
ami = "ami-ebd02392"
instance_type = "t2.micro"
key_name = "user1"
monitoring = true
vpc_security_group_ids = ["sg-12345678"]
subnet_id = "subnet-eddcdzz4"
tags = {
Terraform = "true"
Environment = "dev"
}
}
自从 Terraform 0.13 开始,模块也像资源一样,支持 count、for_each、depends_on三种元参数。比如我们可以这样:
module "ec2_instance" {
count = 2
source = "terraform-aws-modules/ec2-instance/aws"
version = "~> 3.0"
name = "single-instance-${count.index}"
ami = "ami-ebd02392"
instance_type = "t2.micro"
key_name = "user1"
monitoring = true
vpc_security_group_ids = ["sg-12345678"]
subnet_id = "subnet-eddcdzz4"
tags = {
Terraform = "true"
Environment = "dev"
}
}
要注意的是 Terraform 0.13 之后在模块上声明 depends_on,列表中也可以传入另一个模块。声明 depends_on的模块中的所有资源的创建都会发生在被依赖的模块中所有资源创建完成之后。
CommandLine
Terraform Cloud
最佳实践
参考资料
-
No backlinks found.