RDMA Advanced
RDMA 拥塞控制
RDMA 对于网络的诉求
对于支撑端到端传输的基础网络而言,低延时(微秒级)、无损(lossless)则是最重要的指标。
低延时
网络转发延时主要产生在设备节点(这里忽略了光电传输延时和数据串行延时),设备转发延时包括以下三部分:
- 存储转发延时:芯片转发流水线处理延迟,每个 hop 会产生 1 微秒左右的芯片处理延时(业界也有尝试使用 cut-through 模式,单跳延迟可以降低到 0.3 微秒左右);
- Buffer 缓存延时:当网络拥塞时,报文会被缓存起来等待转发。这时 Buffer 越大,缓存报文的时间就越长,产生的时延也会更高。对于 RDMA 网络,Buffer 并不是越大越好,需要合理选择;
- 重传延时:在 RDMA 网络里会有其他技术确保不丢包,这部分不做分析。
无损
RDMA 在无损状态下可以满速率传输,而一旦发生丢包重传,性能会急剧下降。在传统网络模式下,要想实现不丢包最主要的手段就是依赖大缓存,但如前文所说,这又与低延时矛盾了。因此,在 RDMA 网络环境中,需要实现的是较小 Buffer 下的不丢包。
在这个限制条件下,RDMA 实现无损主要是依赖基于 PFC 和 ECN 的网络流控技术。
(为什么需要无损网络:长期以来,HPC 的 RDMA 都是在 Infiniband 集群中使用,数据包丢失在此类群集中很少见,因此 RDMA Infiniband 传输层(在 NIC 上实现)的重传机制很简陋,即:go-back-N 重传,但是现在 RDMA 的使用更广泛,在其他网络中,丢包的概率大于 Infiniband 集群,一旦丢包,使用 RDMA 的 go-back-N 重传机制效率非常低,会大大降低 RDMA 的传输效率,所以要想发挥出 RDMA 真正的性能,势必要为 RDMA 搭建一套不丢包的无损网络环境,go-back-N 重传,见2.1 Infiniband RDMA and RoCE: https://blog.csdn.net/bandaoyu/article/details/115620365 )
RDMA 无损网络的关键技术
PFC
PFC(Priority-based Flow Control),基于优先级的流量控制。是一种基于队列的反压机制,通过发送Pause帧通知上游设备暂停发包来防止缓存溢出丢包。
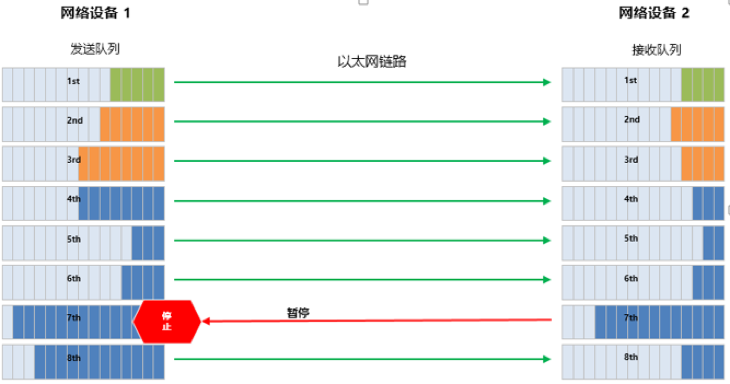
PFC 允许单独暂停和重启其中任意一条虚拟通道,同时不影响其它虚拟通道的流量。如上图所示,当队列 7 的 Buffer 消耗达到设置的 PFC 流控水线,会触发 PFC 的反压:
- 本端交换机触发发出 PFC Pause 帧,并反向发送给上游设备;
- 收到 Pause 帧的上游设备会暂停该队列报文的发送,同时将报文缓存在 Buffer 中;
- 如果上游设备的 Buffer 也达到阈值,会继续触发 Pause 帧向上游反压;
- 最终通过降低该优先级队列的发送速率来避免数据丢包;
- 当 Buffer 占用降低到恢复水线时,会发送 PFC 解除报文。
保证缓存设置
保证缓存是一个静态水线(固定的、独享的)。静态水线的利用率非常低,资源消耗却非常大。我们在实际部署时建议不分配保证缓存,以减少这部分的缓存消耗。这样,入方向报文直接使用共享缓存空间,可提高 Buffer 的利用率。
共享缓存设置
对于共享缓存的设置,需要采用更为灵活的动态水线。动态水线能根据当前空闲的 Buffer 资源,以及当前队列已使用的 Buffer 资源数量来决定能否继续申请到资源。由于系统中空闲共享 Buffer 资源与已使用的 Buffer 资源都是时刻变化的,因此阈值也处于不断变动中。相对于静态水线,动态水线能更灵活、有效的利用 Buffer 及避免造成不必要的浪费。
锐捷网络交换机支持基于动态的方式进行 Buffer 资源的分配,对共享缓存的设置分为 11 档,动态水线 alpha 值=队列可申请缓存量/剩余共享缓存量。队列的α值越大,其在共享缓存中可使用的百分数占比也就越高。
Headroom 设置
Headroom:顾名思义,就是头部空间的意思,是在 PFC 触发后,到 PFC 真正生效这一段时间,用来缓存队列报文的。Headroom 设置多大合适?这里与 4 个因素有关:
- PG 检测到触发 XOFF 水线,到构造 PFC 帧发出的时间(这里主要跟配置的检测精度以及平均队列算法相关,固定配置是固定值)
- 上游收到 PFC Pause 帧,到停止队列转发的时间(主要跟芯片处理性能有关系,交换芯片实际上是固定值)
- PFC Pause 帧在链路上的传输时间(跟 AOC 线缆/光纤距离成正比)
- 队列暂停发送后链路中报文的传输时间(跟 AOC 线缆/光纤距离成正比)
因此 Headroom 所需要的缓存大小,我们可以根据组网的架构,以及流量模型测算得出。以 100 米光纤线 + 100 G 光模块,缓存 64 字节小包,计算出所需的 Headroom 大小是 408 个 cell(cell 是缓存管理的最小单元,一个报文会占用 1 个或者多个 cell),实际测试数据也吻合。当然,考虑一定的冗余性,Headroom 设置建议比理论值稍大。
ECN 作用于主机与主机之间
ECN(Explicit Congestion Notification):显示拥塞通知。ECN 是一个非常古老的技术,只是之前使用的并不普遍,该协议机制作用于主机与主机之间。
ECN 是报文在网络设备出口(Egress port)发生拥塞并触发 ECN 水线时,使用 IP 报文头的 ECN 字段标记数据包,表明该报文遇到网络拥塞。一旦接收服务器发现报文的 ECN 被标记,立刻产生 CNP(拥塞通知报文),并将它发送给源端服务器,CNP 消息里包含了导致拥塞的 Flow 信息。源端服务器收到后,通过降低相应流发送速率,缓解网络设备拥塞,从而避免发生丢包。
DCQCN
DCQCN 全称为 Data Center Quantized Congestion Notification,是目前在 RoCEv 2 网络中使用最广泛的拥塞控制算法,它融合了 QCN 算法和 DCTCP 算法,DCQCN 只需要可以支持 WRED 和 ECN 的数据中心交换机(市面上大多数交换机都支持),其他的协议功能在端节点主机的 NICs 上实现。DCQCN 可以提供较好的公平性,实现高带宽利用率,保证低的队列缓存占用率和较少的队列缓存抖动情况。
RDMA 多路径传输
RDMA 性能优化
RDMA 监控和运维
RDMA 虚拟化
RDMA 通讯库
业界类似于 RDMA 思路
AWS EFA/SRD
EFA(Elastic Fabric Adapter,弹性互联适配器)是 AWS EC2实例的一种网络接口,EFA 性能改进主要通过三项关键技术:
- 应用程序绕过操作系统内核直接与硬件对话,这提高了应用程序性能的稳定性;
- 持续开发和调整ENA和设备驱动程序以适应新的高带宽实例类型;
- 新的以云为中心的可靠性协议层,称为SRD(Scalable Reliable Datagram,可扩展可靠数据报)。
如图8,EFA定制的操作系统旁路硬件接口增强了实例间通信的性能。借助EFA,使用消息传递接口(MPI)的高性能计算(HPC)应用程序和使用NVIDIA集体通信库(NCCL)的机器学习(ML)应用程序可以扩展到数千个CPU或GPU,并且,将获得本地HPC集群的应用程序性能以及AWS云的按需弹性和灵活性。
阿里云 eRDMA
高级技术专家详解:基于阿里云 eRDMA 的 GPU 实例如何大幅提升多机训练性能 - 知乎 (zhihu.com)
RDMA 部署
Reference
-
No backlinks found.