PCIe
PCI Express 是继 ISA 和 PCI 总线之后的第三代 I/O 总线。 由 Intel 在 2001 年的 IDF 上提出,由 PCI-SIG 认证发布后才改名为“PCI-Express”。它的主要优势就是数据传输速率高,另外还有抗干扰能力强,传输距离远,功耗低等优点。
发展历程
**注:**第一代总线一般指 ISA、EISA、VESA 和 Micro Platforms。第二代总线一般指 PCI、AGP 和 PCI-X。
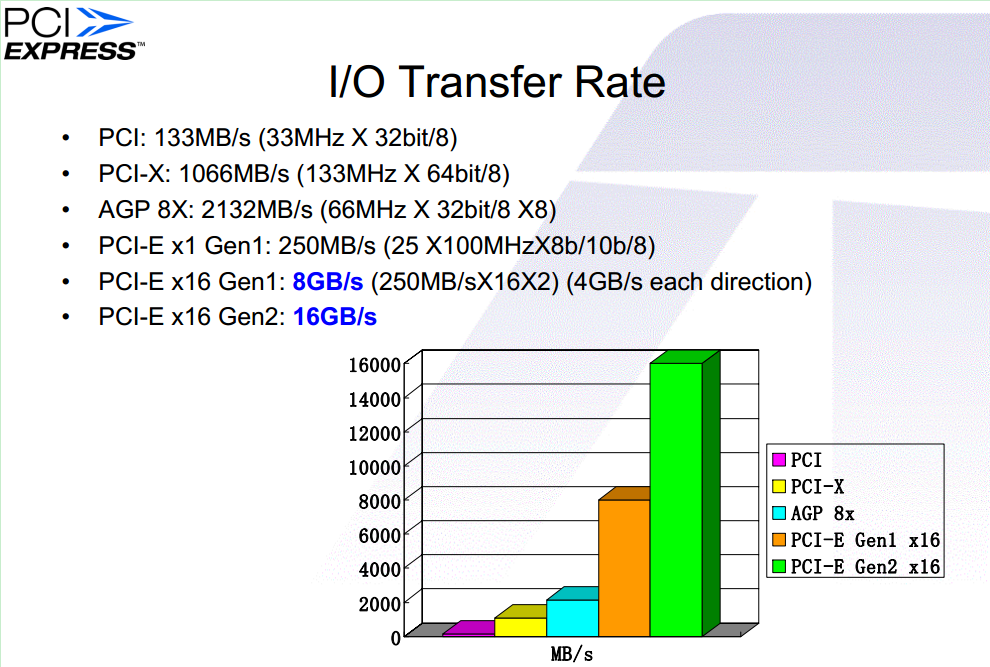
图中的 PCI-E 的传输速率指的是实际的有效传输速率,为 RAW Data 速率的 80%,因为 PCI-E(Gen1&Gen2,Gen3 中使用了新的方式,即 128b/130b)中使用了 8b/10b 编解码技术。
PCI-Express 总线的 Spec 中明确规定了 PCI-Express 的缩写为 PCIe,但很多情况下,大家为了方便常把它缩写为 PCI-E。 PCI-E 接口根据总线位宽不同而有所差异,一个 PCI Express 连接可以被配置成 x1, x2, x4, x8, x12, x16 和 x32 的数据带宽。 (x2 and x12 link widths are optional) PCI-E 各种位宽 Device 可以自由搭配使用,比如 x1 的卡可以插到 x8 的插槽中使用, x8 的卡可以插到 x16 的插槽中使用,升级方便。


一些常见的 PCI-E 设备如下图所示:

目前 PCI-E 已经更新到第四代(即 PCI-E 4.0,Gen4),很快 Gen5 也会到来:

由于 PCI-E 是从 PCI/PCI-X 继承发展而来,PCI-E 在应用层(软件上)几乎是全完兼容 PCI/PCI-X 设备的。在硬件层面上,可以借助 PCI-E to PCI/PCI-X 桥来与其完成对接。并且 PCI-E 是一种非常复杂的总线,因此学习 PCIe 的同时也必须提前对 PCI 和 PCI-X 总线有一定的了解,所以下面的连载博文将先从 PCI 和 PCI-X 总线介绍开始。但是并不会详细的介绍,而只是提一下其基本的概念,以及 PCI-E 与 PCI/PCI-X 的继承与改进的关系。
PCI 概念
PCI 是 Peripheral Component Interconnect 的缩写,它曾经是个人电脑中使用最为广泛的接口,几乎所有的主板产品上都带有这种插槽。目前该总线已经逐渐被 PCI Express 总线所取代。
PCI 即 Peripheral Component Interconnect,中文意思是“外围器件互联”,是由 PCISIG (PCI Special Interest Group)推出的一种局部并行总线标准。PCI 总线是由 ISA(Industy Standard Architecture)总线发展而来的,是一种同步的独立于处理器的 32 位或 64 位局部总线。从结构上看,PCI 是在 CPU 的供应商和原来的系统总线之间插入的一级总线,具体由一个桥接电路实现对这一层的管理,并实现上下之间的接口以协调数据的传送。从 1992 年创立规范到如今,PCI 总线已成为了计算机的一种标准总线,广泛用于当前高档微机、工作站,以及便携式微机。主要用于连接显示卡、网卡、声卡。
**注:**ISA 并行总线有 8 位和 16 位两种模式,时钟频率为 8MHz,工作频率为 33MHz/66MHz。
PCI 总线是一种树型结构,并且独立于 CPU 总线,可以和 CPU 总线并行操作。PCI 总线上可以挂接 PCI 设备和 PCI 桥,PCI 总线上只允许有一个 PCI 主设备(同一时刻),其他的均为 PCI 从设备,而且读写操作只能在主从设备之间进行,从设备之间的数据交换需要通过主设备中转。
**注:**这并不意味着所有的读写操作都需要通过北桥中转,因为 PCI 总线上的主设备和从设备属性是可以变化的。比如 Ethernet 和 SCSI 需要传输数据,可以通过一种叫做 Peer-to-Peer 的方式来完成,此时 Ethernet 或者 SCSI 则作为主机,其它的设备则为从机。具体会在后面的博文中详细介绍。

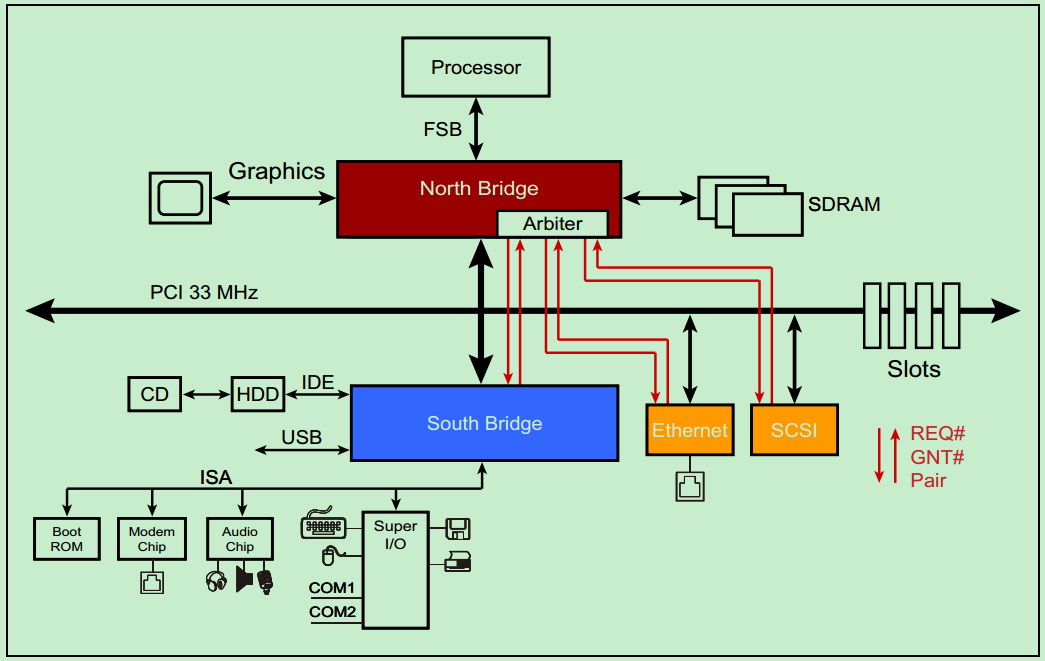
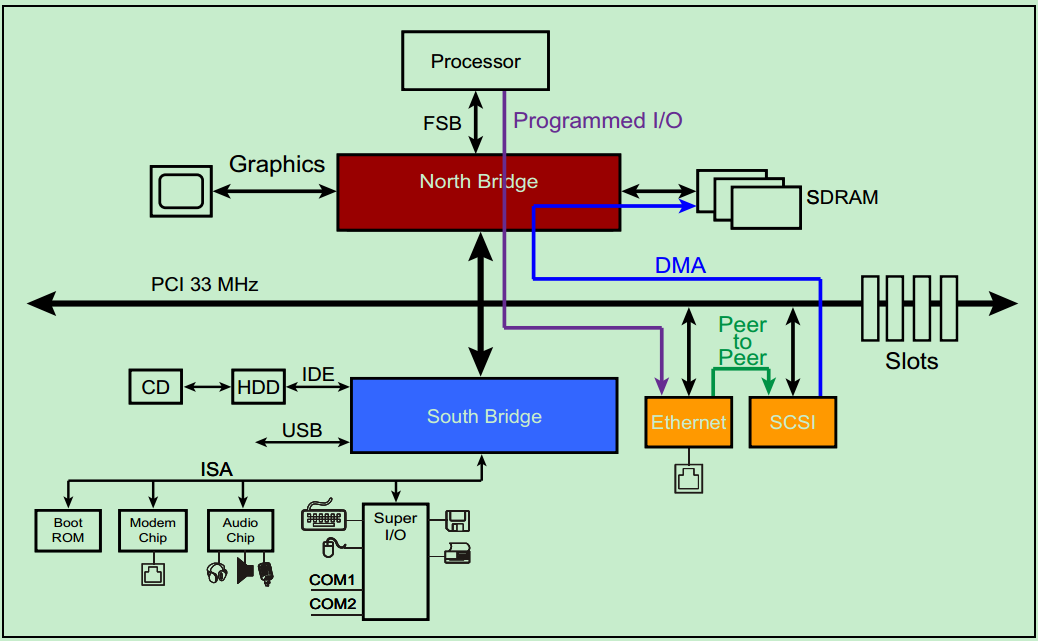
一个典型的 33MHz 的 PCI 总线系统如上图所示,处理器通过 FSB 与北桥相连接,北桥上挂载着图形加速器(显卡)、SDRAM(内存)和 PCI 总线。PCI 总线上挂载着南桥、以太网、SCSI 总线(一种老式的小型机总线)和若干个 PCI 插槽。CD 和硬盘则通过 IDE 连接至南桥,音频设备以及打印机、鼠标和键盘等也连接至南桥,此外南桥还提供若干的 USB 接口。
PCI 总线是一种共享总线,所以需要特定的仲裁器(Arbiter)来决定当前时刻的总线的控制权。一般该仲裁器位于北桥中,而仲裁器(主机)则通过一对引脚,REQ#(request) 和 GNT# (grant)来与各个从机连接。如下图所示:
需要注意的是,并不是所有的设备都有能力成为仲裁器(Arbiter)或者 initiator 。
最初的 PCI 总线的时钟频率为 33MHz,但是随着版本的更新,时钟频率也逐渐的提高。但是由于 PCI 采用的是一种 Reflected-Wave Signaling 信号模型(后面会详细的介绍),导致了时钟频率越高,总线的最大负载越少,如下图所示:
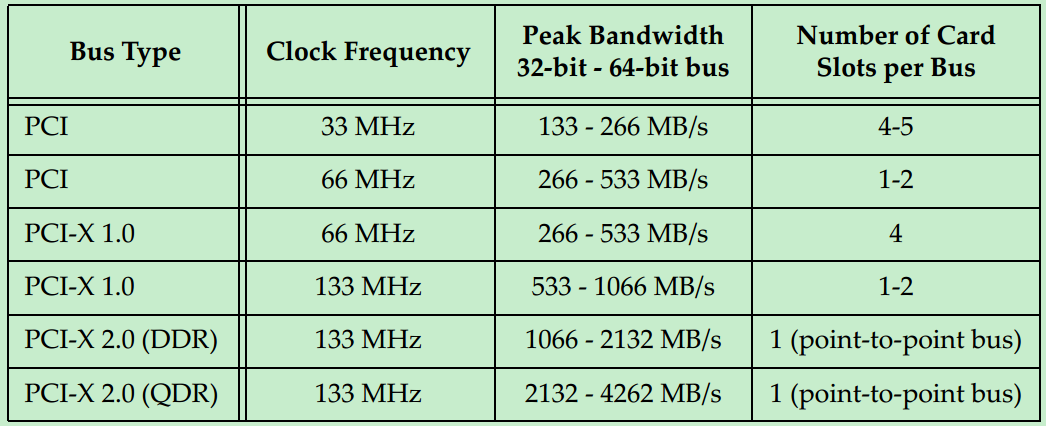
到了 PCI-X2.0 版本,整个总线就只能插一个 PCI 卡了(相当于两个 PCI 负载),为了能够在主板上提供更多的插槽,则必须通过连接多个 PCI 桥来实现(后面会详细地介绍)。
PCI 问题:并行,始终频率限制
PCIe 是从 PCI 发展过来的,PCIe 的”e”是 express 的简称,快的意思。PCIe 怎么就能比 PCI(或者 PCI-X)快呢?PCIe 在物理传输上,跟 PCI 有着本质的区别:PCI 使用并口传输数据,而 PCIe 使用的是串口传输。我 PCI 并行总线,单个时钟周期可以传输 32bit 或者 64bit,怎么就比不了你单个时钟周期传输 1 个 bit 数据的串行总线呢?
在实际时钟频率比较低的情况下,并口因为可以同时传输若干比特,速率确实比串口快。随着技术的发展,数据传输速率要求越来越快,要求时钟频率也越来越快,但是,并行总线时钟频率不是想快就能快的。
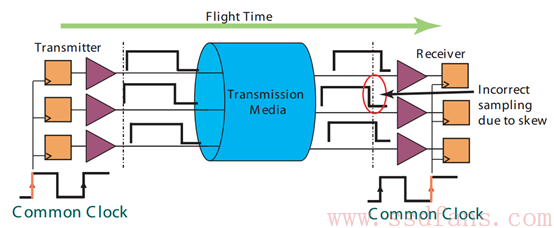
在发送端,数据在某个时钟沿传出去(左边时钟第一个上升沿),在接收端,数据在下个时钟沿(右边时钟第二个上升沿)接收。因此,要在接收端能正确采集到数据,要求时钟的周期必须大于数据传输的时间(从发送端到接收端,flight time)。受限于数据传输时间(该时间还随着数据线长度的增加而增加),因此时钟频率不能做得太高。另外,时钟信号在线上传输的时候,也会存在相位偏移(clock skew ),影响接收端的数据采集;还有,并行传输,接收端必须等最慢的那个 bit 数据到了以后,才能锁住整个数据 (signal skew)。
PCIe 使用串行总线进行数据传输就没有这些问题。它没有外部时钟信号,它的时钟信息通过 8/10 编码或者 128/130 编码嵌入在数据流,接收端可以从数据流里面恢复时钟信息,因此,它不受数据在线上传输时间的限制,你导线多长都没有问题,你数据传输频率多快也没有问题;没有外部时钟信号,自然就没有所谓的 clock skew 问题;由于是串行传输,只有一个 bit 传输,所以不存在 signal skew 问题。但是,如果使用多条 lane 传输数据(串行中又有并行,哈哈),这个问题又回来了,因为接收端同样要等最慢的那个 lane 上的数据到达才能处理整个数据。
PCI 总线是一种地址和数据复用的总线,即地址和数据占用同一组信号线 AD。PCI 总线的所有信号都与时钟信号同步,及所有的信号的变化都发生在时钟的上升沿,或者在时钟上升沿进行采样。
如下图所示,除了时钟信号 CLK 和数据地址复用信号 AD 之外,PCI 总线至少还应包括 FRAME#(用于表示一次数据传输的起始)、C/BE#(Command/Byte Enable)、IRDY#(Initiator Ready for data)、TRDY#(Target ready)、DESEL#(Device Selec,片选信号,用于选择 PCI 设备)和 GNT#(Grant)信号等。
**注:**完整的信号时序图,请参考 PCI Spec。信号名后面的#表示该信号低电平有效。
下面来介绍一个简单的例子,主机接收来自特定从机的数据。
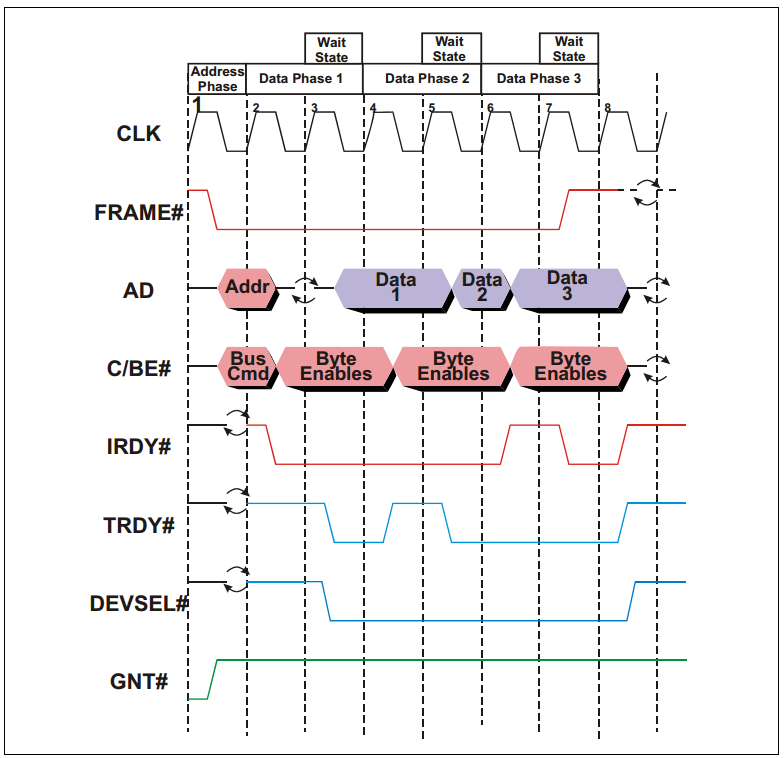
如上图所示:
1、在第一个时钟上升沿,FRAME#和 IRDY#都为 inactive,表明总线当前处于空闲状态。与此同时,某个设备的 GNT#信号处于 active,表明总线总裁器已经选定当前设备为下一个 initiator(可以理解为主机)。
2、在第二个时钟上升沿,FRAME#被 initiator 拉低,表明新的事务(Transaction)已经开始。与此同时,地址和命令被依次发送到 AD 上,总线上面的所有其他设备(从机)都会锁存这些信息,并检查地址和命令是否与自己匹配。
3、在第三个时钟上升沿,IRDY#处于 active 状态,表明主机准备就绪,可以接收数据了。AD 信号上的旋转的箭头表示 AD 信号目前处于三态状态(处于输出和输入的转换状态),即 Turn‐around cycle。需要注意的是,此时的 TRDY#应当处于 inactive 状态,以保证 Turn‐around cycle 顺利进行。
4、在第四个时钟上升沿,PCI 总线上的某个从机确认身份,并依次将 DEVSEL#信号和 TRDY#拉低,并将相应的数据输出到 AD 上。此时,FRAME#信号为 active 状态,表明这并不是最后一个数据。
5、在第五个时钟上升沿,TRDY#处于 inactive 状态,表明从机尚未就绪,因此所有的操作暂缓一个时钟周期(或者说插入了一个 Wait State)。PCI 总线最多允许 8 个这样的 Wait State。
6、在第六个时钟上升沿,从机向主机发送第二个数据。此时,FRAME#信号依旧为 active 状态,表明这并不是最后一个数据。
7、在第七个时钟上升沿,IRDY#处于 inactive 状态,表明主机尚未就绪,再次插入一个 Wait State。但是此时从机依旧可以向 AD 上发送数据。
8、在第八个时钟上升沿,AD 上的第三个数据被发送至主机,由于此时 FRAME#信号被拉高,即 inactive,表明这是本次事务(Transaction)的最后一个数据。此后,所有的控制信号均被拉高,处于 inactive 状态,AD、FRAME#和 C/BE#处于三态状态。
PCI Spec 规定了每个 PCI 总线上最多可以连接多达 32 个 PCI 设备,但是实际上却远远达不到 32 个,33MHz 的 32 位 PCI 总线一般只能连接 10 到 12 个负载。
注:如果使用插槽连接,则一个连接算两个 PCI 设备,插槽和 PCI 卡分别算作一个 PCI 设备。也就是说一个 33MHz 的 PCI 总线最多只能连接 4 到 5 个插槽即 PCI 卡。
这是因为 PCI 总线在设计的时候,为了降低功耗,采用了一种叫做 reflected‐wave signaling 的技术,如下图所示:
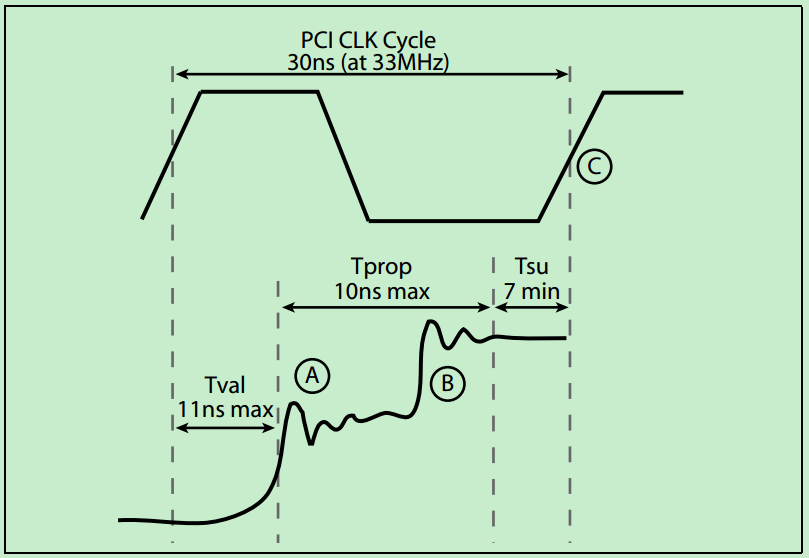
由图可知,为了降低功耗 PCI 设备的发送端采用了一种 weak transmit buffers,其只能驱动信号电平达到实际需求的一半。然后依靠反射回来的信号叠加到原本的信号上,使得信号电平达到实际的需求。当然,所有的这些过程都要求在一个时钟周期内完成,这种机制也限制了 PCI 总线频率的提高,也限制了单个 PCI 总线上的最大连接设备的数量。如果需要连接更多的 PCI 设备,则需要借助 PCI-to-PCI 桥,每个桥的内部都有隔离,这保证了每个桥又可以连接额外的 10~12 个负载。但是 PCI Spec 规定了,一个 PCI 总线系统中,最多只能有 256 个子总线。
**注:**熟悉信号完整性分析的朋友应该知道,在高速信号传输中,反射往往会导致信号的形变,使得信号质量变差,误码率变高,甚至信号收发异常,传输中断。然而,在一些特定的领域(比如 PCI 总线),合理地使用反射机制,可以达到降低功耗等效果。不过,相对于目前的很多高速串行信号,PCI 总线算是很慢的信号了,像 PCI 总线这种利用反射机制降低功耗的,几乎不可能在高速信号得到应用。
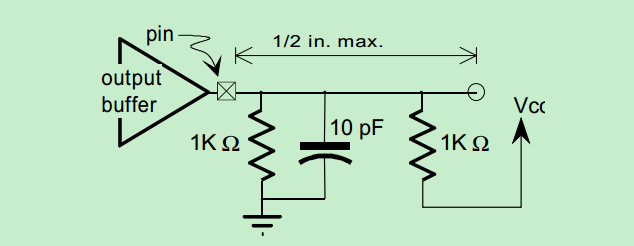
此外,PCI 总线的 Input Buffer 还没有加输入寄存器,这对信号的 Setup 时间提出了更高的要求。
一个包含 PCI-to-PCI 桥的 33MHz PCI 总线系统的架构图如下所示:

拓扑结构:总线型
计算机网络的最主要的拓扑结构有总线型拓扑、环形拓扑、树形拓扑、星形拓扑、混合型拓扑以及网状拓扑。
PCI采用的是总线型拓扑结构,一条 PCI 总线上挂着若干个 PCI 终端设备或者 PCI 桥设备,大家共享该条 PCI 总线,哪个人想说话,必须获得总线使用权,然后才能发言。下面是一个基于 PCI 的传统计算机系统:

北桥下面的那根 PCI 总线,挂载了以太网设备、SCSI 设备、南桥以及其他设备,他们共享那条总线,某个设备只有获得总线使用权才能进行数据传输。
数据传输模型
本文来简单地介绍一下 PCI Spec 规定的三种数据传输模型:Programmed I/O(PIO),Peer-to-Peer 和 DMA。
三种数据传输模型的示意图如下图所示:
Programmed I/O
PIO 在早期的 PC 中被广泛使用,因外当时的处理器的速度要远远大于任何其他外设的速度,所以 PIO 足以胜任所有的任务。举一个例子,比如说某一个 PCI 设备需要向内存(SDRAM)中写入一些数据,该 PCI 设备会向 CPU 请求一个中断,然后 CPU 首先先通过 PCI 总线把该 PCI 设备的数据读取到 CPU 内部的寄存器中,然后再把数据从内部寄存器写入到内存(SDRAM)中。
现在看来,这种传输方式的效率还是很低的。首先,每次 CPU 和 PCI 设备以及 SDRAM 通信都需要额外的时钟周期(相对于 DMA);其次,这种传输方式还需要长时间地占用 CPU,影响 CPU 的使用率。试想一下,你在用 PC 在线观看一个 1080p60 的高清视频,这需要以太网连续地向内存(SDRAM)中写入数据,如果使用 PIO 的方式的话,将难以保证数据的写入速度。随着目前的 PCI 外设速度越来越高,PIO 已经逐渐被 DMA 传输方式所取代,但是为了兼容早期的一些设备,PCI Spec 依然保留了 PIO。
DMA
DMA 是一种在传输过程中,几乎不需要 CPU 进行干预的数据传输方式。如上面的图片所示,以太网可以直接向内存(SDRAM)中写入数据,而几乎不需要 CPU 的干预。实际上,DMA 不仅仅应用于 PCI 总线系统中,它是一种更为广泛应用的数据传输方式。目前,几乎所有的 CPU,甚至是 MCU 都支持 DMA。
Peer-to-Peer
前面的文章中,我们介绍过 PCI 总线系统中的主机身份并不是固定不变的,而是可以切换的(借助仲裁器),但是同一时刻只能存在一个主机。完成 Peer-to-Peer 这一传输方式的前提是,PCI 总线系统中至少存在一个有能力成为主机的设备。在仲裁器的控制下,完成主机身份的切换,进而获得 PCI 总线的控制权,然后与总线上的其他 PCI 设备进行通信。不过,需要注意的是,在实际的系统中,Peer-to-Peer 这一传输方式却很少被使用,这是因为获得主机身份的 PCI 设备(Initiator)和另一个 PCI 设备(Target)通常采用不同的数据格式,除非他们是同一个厂家的设备。
PCI 总线使用 INTA#、INTB#、INTC#和 INTD#信号向处理器发出中断请求。这些中断请求信号为低电平有效,并与处理器的中断控制器连接。在 PCI 体系结构中,这些中断信号属于边带信号(Sideband Signals),PCI 总线规范并没有明确规定在一个处理器系统中如何使用这些信号,因为这些信号对于 PCI 总线是可选信号。所谓边带信号是指这些信号在 PCI 总线中是可选信号,而且只能在一个处理器系统的内部使用,并不能离开这个处理器环境。
**注:**PCI Spec 对边带信号的定义如下:
Any signal not part of the PCI specification that connects two or more PCI-compliant agents and has meaning only to those agents.
完整的 PCI 信号结构图如下:
中断信号与中断控制器的连接关系
PCI 总线规范没有规定 PCI 设备的 INTx 信号如何与中断控制器的 IRQ_PINx#信号相连,这为系统软件的设计带来了一定的困难,为此系统软件使用中断路由表存放 PCI 设备的 INTx 信号与中断控制器的连接关系。在 x86 处理器系统中,BIOS 可以提供这个中断路由表,而在 PowerPC 处理器中 Firmware 也可以提供这个中断路由表。
在一些简单的嵌入式处理器系统中,Firmware 并没有提供中断路由表,此时系统软件开发者需要事先了解 PCI 设备的 INTx 信号与中断控制器的连接关系。此时外部设备与中断控制器的连接关系由硬件设计人员指定。
我们假设在一个处理器系统中,共有 3 个 PCI 插槽(分别为 PCI 插槽 A、B 和 C),这些 PCI 插槽与中断控制器的 IRQ_PINx 引脚(分别为 IRQW#、IRQX#、IRQY#和 IRQZ#)可以按照下图所示的拓扑结构进行连接。
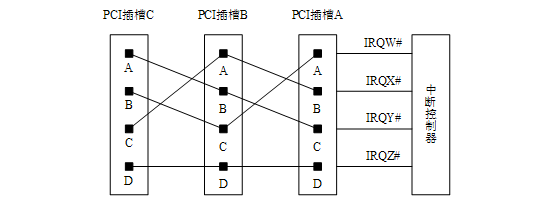
此时,PCI 插槽 A、B、C 的 INTA#、INTB#和 INTC#信号将分散连接到中断控制器的 IRQW#、IRQX#和 IRQY#信号,而所有 INTD#信号将共享一个 IRQZ#信号。采用这种连接方式时,整个处理器系统使用的中断请求信号,其负载较为均衡。而且这种连接方式保证了每一个插槽的 INTA#信号都与一根独立的 IRQx#信号对应,从而提高了 PCI 插槽中断请求的效率。
在一个处理器系统中,多数 PCI 设备仅使用 INTA#信号,很少使用 INTB#和 INTC#信号,而 INTD#信号更是极少使用。在 PCI 总线中,PCI 设备配置空间的 Interrupt Pin 寄存器记录该设备究竟使用哪个 INTx 信号。
中断信号与 PCI 总线的连接关系
在 PCI 总线中,INTx 信号属于边带信号。PCI 桥也不会处理这些边带信号。这给 PCI 设备将中断请求发向处理器带来了一些困难,特别是给挂接在 PCI 桥之下的 PCI 设备进行中断请求带来了一些麻烦。
在一些嵌入式处理器系统中,这个问题较易解决。因为嵌入式处理器系统很清楚在当前系统中存在多少个 PCI 设备,这些 PCI 设备使用了哪些中断资源。在多数嵌入式处理器系统中,PCI 设备的数量小于中断控制器提供的外部中断请求引脚数,而且在嵌入式系统中,多数 PCI 设备仅使用 INTA#信号提交中断请求。
在这类处理器系统中,可能并不含有 PCI 桥,因而 PCI 设备的中断请求信号与中断控制器的连接关系较易确定。而在这类处理器系统中,即便存在 PCI 桥,来自 PCI 桥之下的 PCI 设备的中断请求也较易处理。
在多数情况下,嵌入式处理器系统使用的 PCI 设备仅使用 INTA#信号进行中断请求,所以只要将这些 INTA#信号挂接到中断控制器的独立 IRQ_PIN#引脚上即可。这样每一个 PCI 设备都可以独占一个单独的中断引脚。
而在 x86 处理器系统中,这个问题需要 BIOS 参与来解决。在 x86 处理器系统中,有许多 PCI 插槽,处理器系统并不知道在这些插槽上将要挂接哪些 PCI 设备,而且也并不知道这些 PCI 设备到底需不需要使用所有的 INTx#信号线。因此 x86 处理器系统必须要对各种情况进行处理。
x86 处理器系统还经常使用 PCI 桥进行 PCI 总线扩展,扩展出来的 PCI 总线还可能挂接一些 PCI 插槽,这些插槽上 INTx#信号仍然需要处理。PCI 桥规范并没有要求桥片传递其下 PCI 设备的中断请求。事实上多数 PCI 桥也没有为下游 PCI 总线提供中断引脚 INTx#,管理其下游总线的 PCI 设备。但是 PCI 桥规范推荐使用下面的表建立下游 PCI 设备的 INTx 信号与上游 PCI 总线 INTx 信号之间的映射关系。
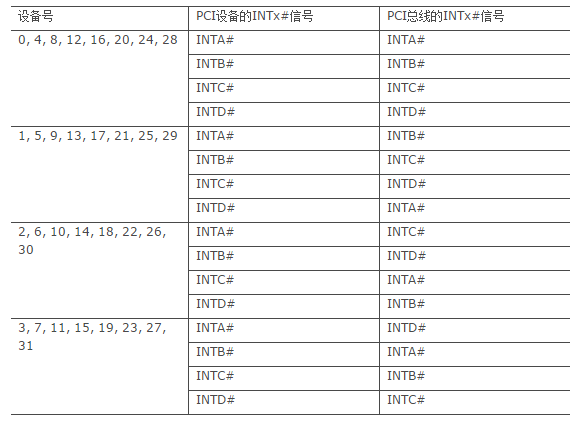
我们举例说明该表的含义。在 PCI 桥下游总线上的 PCI 设备,如果其设备号为 0,那么这个设备的 INTA#引脚将和 PCI 总线的 INTA#引脚相连;如果其设备号为 1,其 INTA#引脚将和 PCI 总线的 INTB#引脚相连;如果其设备号为 2,其 INTA#引脚将和 PCI 总线的 INTC#引脚相连;如果其设备号为 3,其 INTA#引脚将和 PCI 总线的 INTD#引脚相连。
在 x86 处理器系统中,由 BIOS 或者 APCI 表记录 PCI 总线的 INTA~D#信号与中断控制器之间的映射关系,保存这个映射关系的数据结构也被称为中断路由表。大多数 BIOS 使用表中的映射关系,这也是绝大多数 BIOS 支持的方式。如果在一个 x86 处理器系统中,PCI 桥下游总线的 PCI 设备使用的中断映射关系与此不同,那么系统软件程序员需要改动 BIOS 中的中断路由表。
BIOS 初始化代码根据中断路由表中的信息,可以将 PCI 设备使用的中断向量号写入到该 PCI 设备配置空间的 Interrupt Line register 寄存器中。
PCI 总线的错误处理
PCI 设备可以通过奇偶校检来检测到来自 AD 上的地址或者数据的错误,并通过 PERR#或者 SERR#报告错误。但是需要注意的是,PCI Spec 并未规定任何硬件层面上的错误处理或者恢复机制,因此,这些错误都只能通过软件进行处理。
PCI 总线具有 32 位数据/地址复用总线,所以其存储地址空间为 2 的 32 次方=4GB。也就是 PCI 上的所有设备共同映射到这 4GB 上,每个 PCI 设备占用唯一的一段 PCI 地址,以便于 PCI 总线统一寻址。每个 PCI 设备通过 PCI 寄存器中的基地址寄存器来指定映射的首地址。如下图所示:
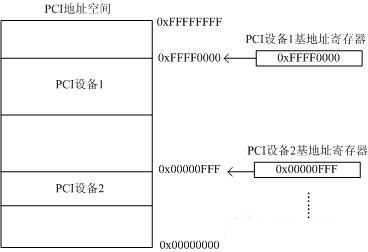
**注:**需要注意的是 PCI 的地址空间和 x86 系统中的 FSB 并不是对等的,而是具有一定的映射关系。
PCI 体系结构中,一共支持三种地址空间:Memory Address Space、I/O Address Space 和 Configuration Address Space。其中 x86 处理器可以直接访问的只有 Memory Address Space 和 I/O Address Space。而访问 Configuration Address Space 则需要通过索引 IO 寄存器来完成。
**注:**在 PCIe 中,则引入了一种新的 Configuration Address Space 访问方式:将其直接映射到了 Memory Address Space 当中。
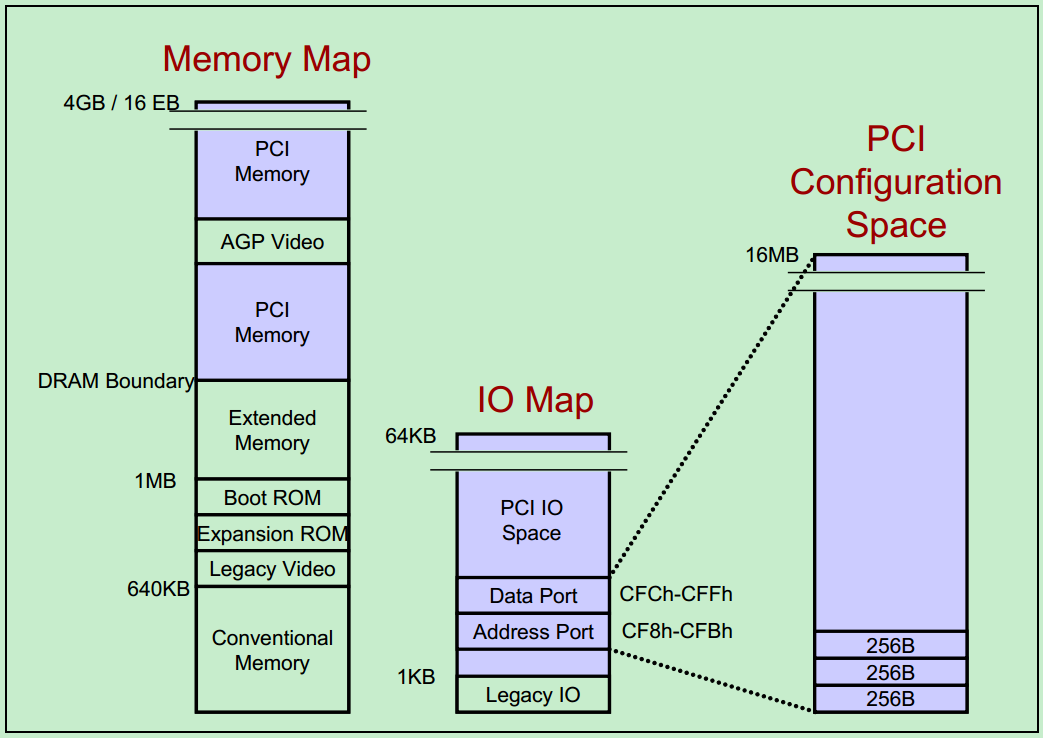
如上图所示,最左边的即为 Memory Address Space,其中包括了多个 PCI Memory、AGP Video(显卡)Memory 以及 Extended Memory、Boot ROM 等。中间的为 I/O Address Space,需要注意的是,虽然 PCI 支持 32 位的地址,但是由于 x86 的 CPU 只支持 16 位的 I/O 空间,这就限制了 PCI 的 I/O Address Space 最大只有 64KB。最右边的则为 Configuration Address Space,由于每一个 PCI 设备最多支持 8 种功能(Function),每一条 PCI 总线最多支持 32 个设备,而每一个 PCI 总线系统最多又支持 256 个子总线(通过 PCI 桥)。因此,总的 Configuration Address Space 的大小为:256 Bytes/function x 8 functions/device x 32 devices/bus x 256 buses/system = 16MB。
如图中所示,Configuration Address Space 所使用的 IO 寄存器范围为 0xCF8~0xCFF。其中 0xCF8~0xCFB 为端口地址,0xCFC~0xCFF 为配置数据。
PCIe 基础
特征
- 双单工
- 点对点
- 串行连接
- 基于 Packet 的传输协议
- Scalable Link Width
- Scalable Link Speeds
基本术语

- Link
- Lane
- Wire
- Signal
两个设备之间的 PCIe 连接,叫做一个 Link,如下图所示:

从 A 到 B,之间是个双向连接,车可以从 A 驶向 B,同时,车也可以从 B 驶向 A,各行其道。两个 PCIe 设备之间,有专门的发送和接收通道,数据可以同时往两个方向传输,PCIe spec 称这种工作模式为双单工模式(dual-simplex),可以理解为全双工模式。
SATA 是什么工作模式呢?
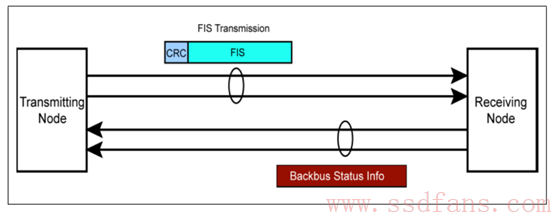
和 PCIe 一样,SATA 也有独立的发送和接收通道,但与 PCIe 工作模式不一样:同一时间,只有一条道可以进行数据传输,也就是说,你在一条道上发送数据,另外一条道上不能接收数据,反之亦然。这种工作模式应该是半双工模式。PCIe 犹如我们的手机,双方可以同时讲话,而 SATA 就是对讲机了,一个人在说话,另外一个人就只能听不能说。
Link Width 这一行,我们看到 X1,X2,X4…,这是什么意思?这是指 PCIe 连接的通道数(Lane)。就像高速一样,有单根道,有 2 根道的,有 4 根道的,不过像 8 根道或者更多道的公路不常见,但 PCIe 是可以最多 32 条道的。
速度计算
PCIe 发展到现在,从 PCIe 1.0,PCIe 2.0,到现在的 PCIe 5.0,速度一代比一代快。

这里解释下 PCIe 带宽的计算方法:
在 PCIe 1.0 版本,物理层采用 8b/10b 编码,也就是说 8 比特的数据实际在物理线路上需要传输 10 比特。与此同时,PCIe 1.0 版本中线上传输速率为 2.5 GT/s,也就是串行传输数据速率为 2.5 Gb/s。那么,在单通道的情况下,也就是 PCIe Gen 1x1,两个 PCIe 设备间 Link 每个方向传输带宽为:
$$ ThroughPut = \frac{2.5\ Gb}{ 1\ s} * \frac{8\ b}{10\ b} * \frac{1\ B}{8\ b} = 0.25 GB/s $$
如果是 16 通道,则传输带宽为单通道传输带宽乘以通道数目,也即是 4 GB/s。
PCIe 2.0 线上比特传输速率在 PCIe 1.0 的基础上翻了一倍,为 5Gb/s,物理层同样使用 8b/10b 编码,所以 PCIe Gen 2x1 的传输带宽为 0.5 GB/s。
PCIe 3.0 的线上比特传输速率没有在 PCIe 2.0 的基础上翻倍,不是 10Gb/s,而是 8Gb/s,但物理层使用的是 128b/130b 编码进行数据传输,所以在单通道的情况下,也就是 PCIe Gen 3x1,两个 PCIe 设备间 Link 传输带宽为
$$ ThroughPut = \frac{8\ Gb}{ 1\ s} * \frac{128\ b}{130\ b} * \frac{1\ B}{8\ b} = 0.985 GB/s $$
由于采用了 128/130 编码,128 比特的数据,只额外增加了 2bit 的开销,有效数据传输比率增大,虽然线上比特传输率没有翻倍,但有效数据带宽还是在 PCIe2.0 的基础上做到翻倍。
拓扑结构:树形
PCIe 则采用 树形 拓扑结构,一个简单而又典型的 PCIe 拓扑结构如下:整个 PCIe 拓扑结构是一个树形结构,Root Complex(RC)是树的根。RC 为 CPU 代言,与整个计算机系统其它部分通讯,比如 CPU 通过它访问内存,通过它访问 PCIe 系统中的设备。CPU 像皇上一样高高在上,而 RC 好比皇上身边当红的太监,皇上想叫下面的人做点事情,通过太监传达;下面的人也是通过太监,向皇上反应一些情况。不过,这个太监不寻常,它是有根(root)的。

- Root Complex:RC 的内部实现很复杂,PCIe Spec 也没有规定 RC 该做什么,还是不该做什么。我们也不需要知道那么多,只需清楚:它一般实现了一条内部 PCIe 总线(BUS 0),以及通过若干个 PCIe bridge,扩展出一些 PCIe Port
- RC 是树的根,或者主干,它为 CPU 代言,与 PCIe 系统其它部分通讯,一般为通讯的发起者
- Switch:Switch 用于扩展链路,提供更多的端口用以连接 Endpoint。Switch 扩展了 PCIe 端口,
- Upstream Port:靠近 RC 的那个端口,一个 Switch 只有一个上游端口,可以扩展出若干个下游端口。
- Downstream Port:Switch 分出来的其他端口,下游端口可以直接连接 Endpoint,也可以连接 Switch,扩展出更多的 PCIe 端口。
- 对每个 Switch 来说,它下面的 Endpoint 或者 Switch,都是归他管的:上游下来的数据,它需要甄别数据是传给它下面哪个设备,然后进行转发;下面设备向 RC 传数据,也要通过 Switch 代为转发的。因此,Switch 的作用就是扩展 PCIe 端口,并为挂在它上面的设备(endpoint 或者 switch)提供路由和转发服务。
- 每个 Switch 内部,也是有一根内部 PCIe 总线的,然后通过若干个 Bridge,扩展出若干个下游端口
- Switch 是树枝,树枝上有叶子(Endpoint),也可节外生枝,Switch 上连 Switch,归根结底,是为了连接更多的 Endpoint。 Switch 为它下面的 Endpoint 或 Switch 提供路由转发服务;
- Endpoint:这些 Endpoint 可以直接连在 RC 上,也可以通过 Switch 连到 PCIe 总线上。
- Endpoint 是树叶,诸如 SSD,网卡,显卡等等,实现某些特定功能(function)。
- PCIe Endpoint:就是 PCIe 终端设备,比如 PCIe SSD,PCIe 网卡等等
- Legacy Endpoint:接口是 PCIe,但是内部的行为却和传统的 PCI 或者 PCI-x 一样(比如支持 IO 空间)
- 我们还看到有所谓的 Bridge,用以将 PCIe 总线转换成 PCI 总线,或者反过来,不是我们要讲的重点,忽略之。PCIe 与采用总线共享式通讯方式的 PCI 不同,PCIe 采用点到点(Endpoint to Endpoint)通讯方式,每个设备独享通道带宽,速度和效率都比 PCI 好。
最后,以一个实际的计算机系统例子结束本文:

分层结构
绝大多数的总线或者接口,都是采用分层实现的。PCIe 也不例外,它的层次结构如下,PCIe 传输的数据从上到下,都是以 packet 的形式传输的,每个 packet 都是有其固定的格式的。

- Transaction Layer:创建(发送)或者解析(接收)TLP (Transaction Layer packet),流量控制,QoS,事务排序等。
- Data Link Layer:创建(发送)或者解析(接收)DLLP(Data Link Layer packet),Ack/Nak 协议(链路层检错和纠错),流控,电源管理等。
- Physical Layer:处理所有的 Packet 数据物理传输,发送端数据分发到各个 Lane 传输(stripe),接收端把各个 Lane 上的数据汇总起来(De-stripe),每个 Lane 上加扰(Scramble,目的是让 0 和 1 分布均匀,去除信道的电磁干扰 EMI)去扰(De-scramble),以及 8/10 或者 128/130 编码解码,等等。





总结上面的层次结构,如下图所示:

PCIe 地址空间
配置空间
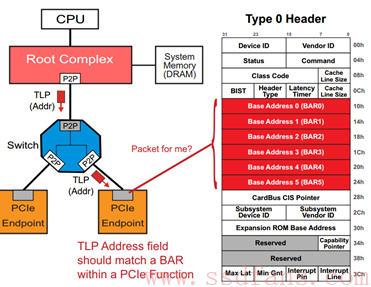
每个 PCIe 设备,有这么一段空间,Host 软件可以读取它获得该设备的一些信息,也可以通过它来配置该设备,这段空间就叫做 PCIe 的配置空间。不同于每个设备的其它空间,PCIe 设备的配置空间是协议规定好的,哪个地方放什么内容,都是有定义的。PCI 或者 PCI-X 时代就有配置空间的概念,那时的配置空间如下:
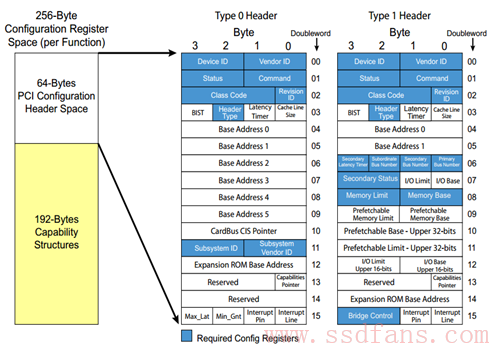
整个配置空间就是一系列寄存器的集合,其中 Type 0 是 Endpoint 的配置,Type 1 是 Bridge(PCIe 时代就是 Switch)的配置,都由两部分组成:64 Bytes 的 Header+192Bytes 的 Capability 结构,后者是设备告诉 Host 它有多牛逼,都会什么绝活。
进入 PCIe 时代,PCIe 能耐更大,192 Bytes 不足以罗列它的绝活。为了保持后向兼容,又要不把绝活落下,怎么办?很简单,我扩展后者的空间,整个配置空间由 256 Bytes 扩展成 4KB,前面 256 Bytes 保持不变:
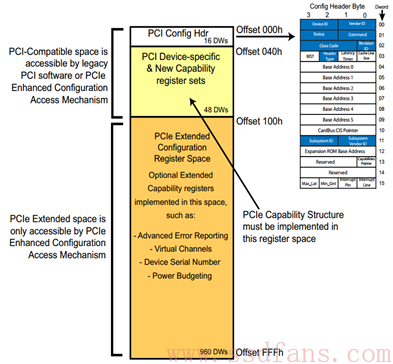
PCIe 有什么能耐(Capability)我们不看,我们先挑软柿子捏,先看看只占 64 Bytes 的 Configuration Header。
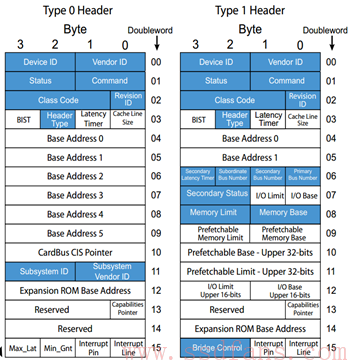
像 Device ID,Vendor ID,Class Code 和 Revision ID,是只读寄存器,PCIe 设备通过这些寄存器告诉 Host 软件,这是哪个厂家的设备、设备 ID 是多少、以及是什么类型的(网卡?显卡?桥?)设备。
其它的我们暂时不看,我们看看重要的 BAR(Base Address Register)。
对 Endpoint Configuration(Type 0),提供了最多 6 个 BAR,而对 Switch(Type 1)来说,只有 2 个。BAR 是干什么用的?
每个 PCIe 设备,都有自己的内部空间,这部分空间如果开放给 Host(软件或者 CPU)访问,那么 Host 怎样才能往这部分空间写入数据,或者读数据呢?
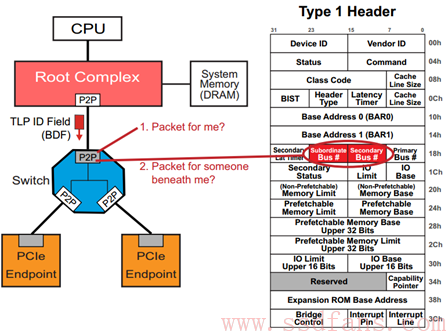
我们知道,CPU 只能直接访问 Host 内存(Memory)空间(或者 IO 空间,我们不考虑),不对 PCIe 等外设直接操作。怎么办?记得皇帝身边那个有根的太监吗?Root Complex,RC。RC 可以为 CPU 分忧。
解决办法是:CPU 如果想访问某个设备的空间,由于它不能(或者不屑)亲自跟那些 PCIe 外设打交道,因此叫太监 RC 去办。比如,如果 CPU 想读 PCIe 外设的数据,先叫 RC 通过 TLP 把数据从 PCIe 外设读到 Host 内存,然后 CPU 从 Host 内存读数据;如果 CPU 要往外设写数据,则先把数据在内存中准备好,然后叫 RC 通过 TLP 写入到 PCIe 设备。完美!
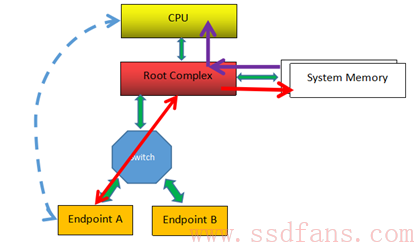
上图例子中,最左边虚线的表示 CPU 要读 Endpoint A 的数据,RC 则通过 TLP(经历 Switch)数据交互获得数据,并把它写入到系统内存中,然后 CPU 从内存中读取数据(紫色箭头所示),从而 CPU 间接完成对 PCIe 设备数据的读取。
地址空间
具体实现就是上电的时候,系统把 PCIe 设备开放的空间(系统软件可见)映射到内存空间,CPU 要访问该 PCIe 设备空间,只需访问对应的内存空间。RC 检查该内存地址,如果发现该内存空间地址是某个 PCIe 设备空间的映射,就会触发其产生 TLP,去访问对应的 PCIe 设备,读取或者写入 PCIe 设备。
一个 PCIe 设备,可能有若干个内部空间(属性可能不一样,比如有些可预读,有些不可预读)需要映射到内存空间,设备出厂时,这些空间的大小和属性都写在 Configuration BAR 寄存器里面,然后上电后,系统软件读取这些 BAR,分别为其分配对应的系统内存空间,并把相应的内存基地址写回到 BAR。(BAR 的地址其实是 PCI 总线域的地址,CPU 访问的是存储器域的地址,CPU 访问 PCIe 设备时,需要把总线域地址转换成存储器域的地址。)
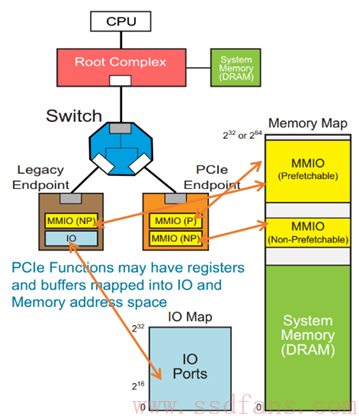
如上图例子,一个 Native PCIe Endpoint,只支持 Memory Map,它有两个不同属性的内部空间要开放给系统软件,因此,它可以分别映射到系统内存空间的两个地方;还有一个 Legacy Endpoint,它既支持 Memory Map,还支持 IO Map,它也有两个不同属性的内部空间,分别映射到系统内存空间和 IO 空间。
来个例子,看一下一个 PCIe 设备,系统软件是如何为其分配映射空间的。
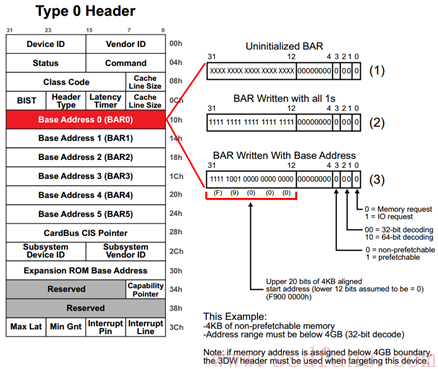
上电时,系统软件首先会读取 PCIe 设备的 BAR0,得到数据:

然后系统软件往该 BAR0 写入全 1,得到:

BAR 寄存器有些 bit 是只读的,是 PCIe 设备在出厂前就固定好的 bit,写全 1 进去,如果值保持不变,就说明这些 bit 是厂家固化好的,这些固化好的 bit 提供了这块内部空间的一些信息:
怎么解读?低 12 没变,表明该设备空间大小是 4KB(2 的 12 次方),然后低 4 位表明了该存储空间的一些属性(IO 映射还是内存映射,32bit 地址还是 64bit 地址,能否预取?做过单片机的人可能知道,有些寄存器只要一读,数据就会清掉,因此,对这样的空间,是不能预读的,因为预读会改变原来的值),这些都是 PCIe 设备在出厂前都设置好的,提供给系统软件的信息。
然后系统软件根据这些信息,在系统内存空间找到这样一块地方来映射这 4KB 的空间,把分配的基地址写入到 BAR0:
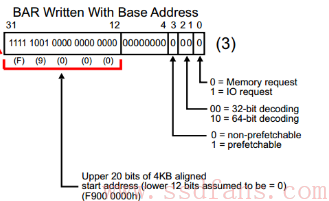
从而最终完成了该 PCIe 空间的映射。一个 PCIe 设备可能有若干个内部空间需要开放出来,系统软件依次读取 BAR1,BAR2。。。,直到 BAR5,完成所有内部空间的映射。
上面主要讲了 Endpoint 的 BAR,Switch 也有两个 BAR,今天不打算讲,下节讲 TLP 路由,再回过头来讲。继续说配置空间。
前面说每个 PCIe 设备都有一个配置空间,其实这样说是不准确的,而是每个 PCIe 设备至少有一个配置空间。一个 PCIe 设备,它可能具有多个功能(function),比如既能当硬盘,还能当网卡。每个功能对应一个配置空间。
在一个 PCIe 拓扑结构里,一条总线下面可以挂几个设备,而每个设备可以具有几个功能,如下所示:
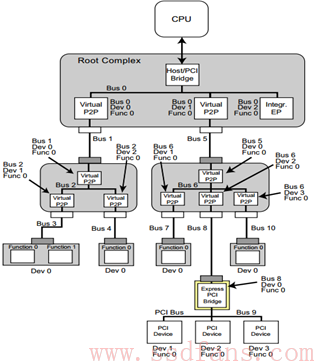
因此,在整个 PCIe 系统中,只要知道了 Bus+Device+Function,就能找到对应的 Function。寻址基本单元是功能(function),它的 ID 就由 Bus+Device+Function 组成 (BDF)。一个 PCIe 系统,可以最多有 256 条 Bus,每条 Bus 上可以挂最多 32 个 Device,而每个 Device 最多又能实现 8 个 Function,而每个 Function 对应着 4KB 的配置空间。上电的时候,这些配置空间都是需要映射到 Host 的内存空间,因此,需要占用内存空间是:256328*4KB =256MB。在这个动辄 4GB、8GB 内存的时代,256MB 算不了什么。
系统软件是如何读取 Configuration 空间呢?不能通过 BAR 中的地址,为什么?别忘了 BAR 是在 Configuration 中的,你首先要读取 Configuration,才能得到 BAR。前面不是系统为所有可能的 Configuration 预留了 256MB 内存空间吗?系统软件想访问哪个 Configuration,只需指定相应 Function 对应的内存空间地址,RC 发现这个地址是 Configuration 映射空间,就会产生相应的 Configuration Read TLP 去获得相应 Function 的 Configuration。
再回想一下前面介绍的 Configuration Read TLP 的 Header 格式:
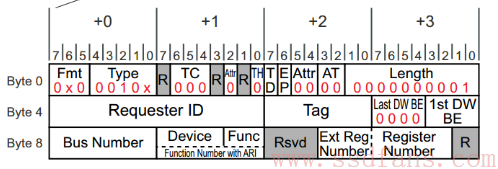
Bus Number + Device + Function 就唯一决定了目标设备; Ext Reg Number + Register Number 相当于配置空间的偏移。找到了设备,然后指定了配置空间的偏移,就能找到具体想访问的配置空间的某个位置。
结束前,强调一下,只有 RC 才能发起 Configuration 的访问请求,其他设备是不允许对别的设备进行 Configuration 读写的。
TLP
TLP 结构
Host 与 PCIe 设备之间,或者 PCIe 设备与设备之间,数据传输都是以 Packet 形式进行的。事务层根据上层(软件层或者应用层)请求(Request)的类型、目的地址和其它相关属性,把这些请求打包,产生 TLP,也就是 Transaction Layer Packet。然后这些 TLP 往下,经历数据链路层,物理层,最终到达目标设备。
根据软件层的不同请求,事务层产生四种不同的 TLP 请求:
- **Memory **
- **IO **
- **Configuration **
- **Message **
前三种分别用于访问内存空间、IO 空间、配置空间,这三种请求在 PCI 或者 PCI-X 时代就有了;最后的 Message 请求是 PCIe 新加的。在 PCI 或者 PCI-X 时代,像中断、错误以及电源管理相关信息,都是通过边带信号(sideband signal)进行传输的,但 PCIe 干掉了这些边带信号线,所有的通讯都是走带内信号,即通过 Packet 传输,因此,过去一些由边带信号线传输的数据,比如中断信息、错误信息等,现在就交由 Message 来传输了。
我们知道,一个设备的物理空间,可以通过内存映射(Memory map)的方式映射到 Host 的主存,有些空间还可以映射到 Host 的 IO 空间(如果 Host 存在 IO 空间的话)。但新的 PCIe 设备(区别于 Legacy PCIe 设备)只支持内存映射,之所以还存在访问 IO 空间的 TLP,完全是为了照顾那些老设备。以后 IO 映射的方式会逐渐取消,为减轻学习压力,我们以后看到 IO 相关的东西,大可或略之。
所有的配置空间(Configuration)的访问,都是 Host 发起的,确切的说是 RC 发起的,往往只在上电枚举和配置阶段会发起 Configuration 的访问,这样的 TLP 很重要,但不是常态; Message 也是一样,只有有中断,或者有错误等情况下,才会有 Message TLP,属非主流。PCIe 线上主流传输的是 Memory 访问相关的 TLP,Host 与 device,或者 device 与 device 之间,数据都是在彼此的 Memory 之间(抛掉 IO)交互,因此,这种 TLP 是我们最常见的。
这四种请求,如果需要对方响应的,我们叫做 Non-Posted 的 TLP;如果不期望对方给响应的,我们称之为 Posted TLP。Post,有”邮政”的意思,我们只管把信投到邮箱,能不能到达对方,就取决于邮递员了。Posted TLP,就是不指望对方回复(信能不能收到都是个问题);Non-Posted TLP,就是要求对方务必回复。
哪些 TLP 是 Posted,哪些又是 non-posted 的呢?像 Configuration 和 IO 访问,无论读写,都是 Non-posted 的,这样的请求必须得到设备的响应;Message TLP 是 Posted;Memory Read 必须是 Non-posted,我读你数据,你不返回数据(返回数据也是响应),那肯定不行的。所以,Memory Read 必须得到响应。而 Memory Write 是 Posted,我数据传给你,无需回复,这样 Host 或者 Device 可以不等对方回复,趁早把下一笔数据写下去,这样一定程度上提高了写的性能。有人会担心如果没有得到对方的响应,发送者就没有办法知道数据究竟有没有成功写入,就有丢数据的风险。虽然这个风险存在(概率很小),但数据链路层提供了 ACK/NAK 机制,一定程度上能保证 TLP 正确交互,因此能很大程度减小数据写失败的可能。
| Request Type | Non-Posted or Posted |
|---|---|
| Memory Read | Non-Posted |
| Memory Write | Posted |
| Memory Read Lock | Non-Posted |
| IO Read | Non-Posted |
| IO Write | Non-Posted |
| Configuration Read (Type 0 and Type 1) | Non-Posted |
| Configuration Write (Type 0 and Type 1) | Non-Posted |
| Message | Posted |
**所以,只要记住只有 Memory Write 和 Message 两种 TLP 是 Posted 就可以了。 **
Memory Read Lock 是历史的遗留物,Native PCIe 设备已经抛弃了这个,存在的意义完全是为了兼容 Legacy PCIe 设备。和 IO 一样,我们以后也忽略。能不看的就不看,PCIe 东西本来就多,不要被这些过时没用的东西挡着我们学习的道路。
Configuration 一栏,看到有 Type 0 和 Type 1。我们在之前的拓扑结构中,看到除了 Endpoint 之外,还有 Switch,他们都是 PCIe 设备,但配置种类不同,因此用 Type 0 和 Type 1 区分。
| Request Type | Non-Posted or Posted |
|---|---|
| Memory Read | Non-Posted |
| Memory Write | Posted |
| Configuration Read (Type 0 and Type 1) | Non-Posted |
| Configuration Write (Type 0 and Type 1) | Non-Posted |
| Message | Posted |
这样,Request TLP 是不是清爽点?
对 Non-Posted 的 Request,是一定需要对方响应的,对方是通过返回一个 Completion TLP 来作为响应的。对 Read Request,响应者通过 Completion TLP 返回请求者所需的数据,这种 Completion TLP 包含有效数据;对 Write Request(现在只有 Configuration Write 了)来说,响应者通过 Completion TLP 告诉请求者执行状态,这样的 Completion TLP 不含有效数据。
因此,PCIe 里面所有的 TLP = Request TLP + Completion TLP。
| TLP Packet Type | Abbreviated Name |
|---|---|
| Memory Read | MRd |
| Memory Write | MWr |
| Configuration Read(Type 0 and Type 1) | CfgRd0, CfgRd |
| Configuration Write(Type 0 and Type 1) | CfgWr0,CfgWr1 |
| Message Request with Data | MsgD |
| Message Request without Data | Msg |
| Completion with Data | CplD |
| Completion without Data | Cpl |
看个 Memory Read 的例子:
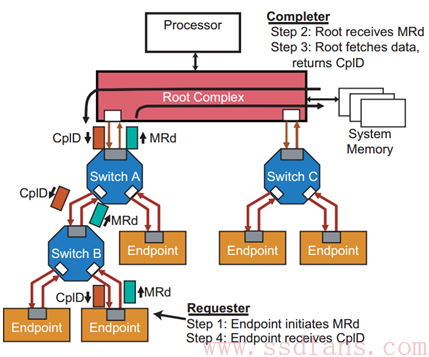
例子中,Switch B 下面的某个 Endpoint 想读 Host 内存的数据,因此,它在事务层上生成一个 Memory Read TLP,该 MRd 一路向上,翻过 B,越过 A,最终到达 RC。RC 收到该 Request,就到内存中取该 Endpoint 所需的数据,RC 通过 Completion with Data TLP(CplD)返回数据,原路返回,直到 Endpoint。
一个 TLP,最多只能携带 4KB 有效数据,因此,上例子,如果 Endpoint 需要读 16KB 的数据,RC 必须返回 4 个 CplD 给 Endpoint。注意,Endpoint 只需发 1 个 MRd 就可以了。
再看个 Memory Write 的例子:
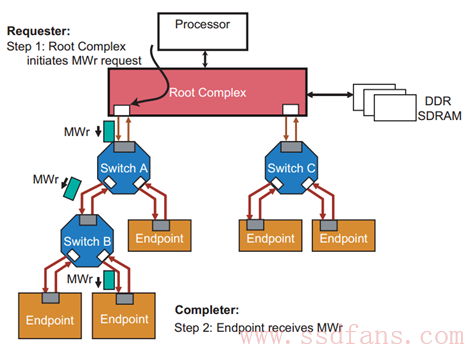
该例子中,Host 想往某个 Endpoint 写入数据,因此 RC 在其事务层生成一个 Memory Write TLP(要写的数据在该 TLP 中),翻过 A,越过 B,直到目的地。前面说过 Memory Write TLP 是 Posted 的,因此,Endpoint 收到数据后,是不需要返回 Completion TLP(如果这个时候返回 Completion TLP,反而是画蛇添足)。
同样的,由于一个 TLP 只能携带 4KB 数据,因此 Host 想往 Endpoint 上写入 16KB 数据,RC 必须发送 4 个 MWr TLP。
TLP 包结构
数据从上到下,一层一层打包,上层打包完的数据,作为下层的原始数据,再打包。就像人穿衣服一样,穿了内衣穿衬衫,穿了衬衫穿外套。
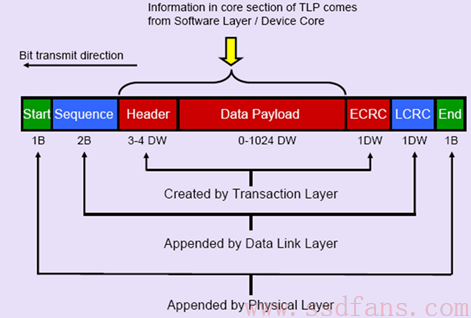
红色的是 TLP 的格式,Data 是事务层上层给的数据,事务层给它头上加个 Header,然后尾巴上再加个 CRC 校验,就构成了一个 TLP;这个 TLP 下传到数据链路层,又被数据链路层头上加了个包序列号,尾巴再加个 CRC 校验,构成一个 DLLP;然后 DLLP 下传到物理层,头上加个 Start,尾巴加个 End 符号,把这些数据分派到各个 Lane 上,然后每个 Lane 上加扰码,经 8/10 或 128/130 编码,最后通过物理传输介质传输给接收方。
接收方物理层是最先接收到这些数据的,然后执行逆操作;在数据链路层,校验序列号和 LCRC,如果没错,剥掉序列号和 LCRC,往事务层走;如果校验出差,通知对方重传;在事务层,校验 ECRC,有错,数据抛弃,没错,去掉 ECRC,获得数据。整个过程犹如脱衣睡觉,外套脱了,衬衫脱了,内衣也脱了,光溜溜钻进被窝。
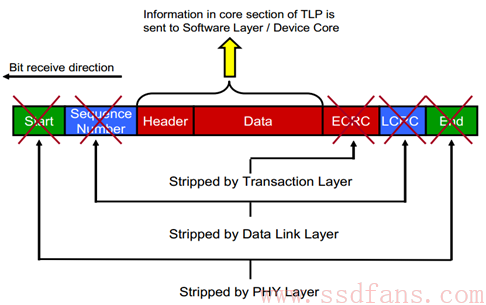
和 PCI 数据裸奔不同,PCIe 的数据是穿有衣服的。PCIe 数据以 packet 的形式传输,比起 PCI 冷冰冰的数据,PCIe 的数据是鲜活有生命的。
每个 Endpoint 都需要实现这三层,每个 Switch 的每个 Port 也是需要实现这三层的:
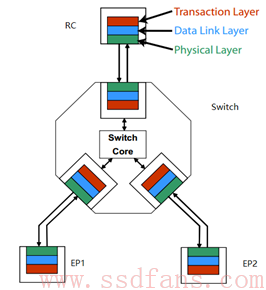
上图中,如果 RC 要与 EP1 通信,中间要经历怎样的一个过程?
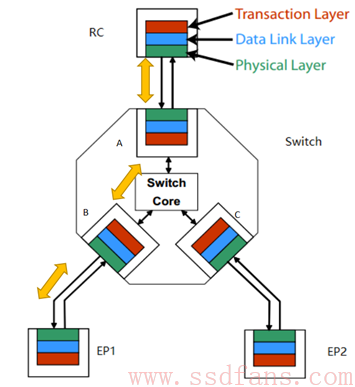
如果把前述的数据发送和接收过程,我们通俗的叫做穿衣脱衣,那么,RC 与 EP1 数据传输过程中,则存在好几次这样穿衣脱衣过程:RC 跟数据穿好衣服,发送给 Switch 的上游端口,A 为了知道该笔数据发送给谁,就需要脱掉该数据的衣服,找到里面的地址信息。衣服脱光后,Switch 发现它是往 EP1 的,又帮它换了身新衣服,发送给端口 B。B 又不嫌麻烦的脱掉它的衣服,换上新衣服,最后发送给 EP1。
Switch 的主要功能是转发数据,为什么还需要实现事务层?Switch 必须实现这三层,因为数据的目的地信息是在 TLP 中的,如果不实现这一层,就无法知道目的地址,也就无法实现数据寻址路由。
TLP 协议
无论 Request TLP,还是作为回应的 Completion TLP,它们模样都差不多:

TLP 主要由三部分组成:Header,Data 和 CRC。TLP 都是生于发送端的事务层(Transaction Layer),终于接收端的事务层。
每个 TLP 都有一个 Header,跟动物一样,没有头就活不了,所以 TLP 可以没手没脚,但不能没有头。事务层根据上层请求内容,生成 TLP Header。Header 内容包括发送者的相关信息、目标地址(该 TLP 要发给谁)、TLP 类型(前面提到的诸如 Memory read,Memory Write 之类的)、数据长度(如果有的话)等等。
Data Payload 域,用以放有效载荷数据。该域不是必须的,因为并不是每个 TLP 都必须携带数据的,比如 Memory Read TLP,它只是一个请求,数据是由目标设备通过 Completion TLP 返回的。后面我们会整理哪些 TLP 需要携带数据,哪些 TLP 不带数据的。前面也提到,一个 TLP 最大载重是 4KB,数据长度大于 4KB 的话,就需要分几个 TLP 传输。
ECRC(End to End CRC)域,它对之前的 Header 和 Data(如果有的话)生成一个 CRC,在接收端然后根据收到的 TLP,重新生成 Header 和 Data(如果有的话)的 CRC,和收到的 CRC 比较,一样则说明数据在传输过程中没有出错,否则就有错。它也是可选的,可以设置不加 CRC。
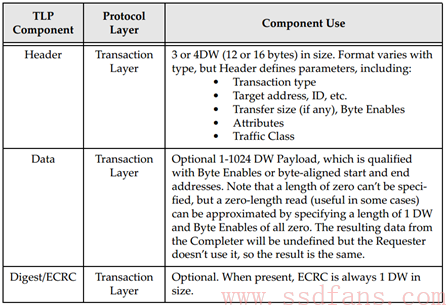
Data 域和 CRC 域没有什么好说的,有花头的是 Header 域,我们要深入其中看看。
一个 Header 大小可以是 3DW,也可以是 4DW。以 4DW 的 Header 为例,TLP 的 Header 长下面样子:
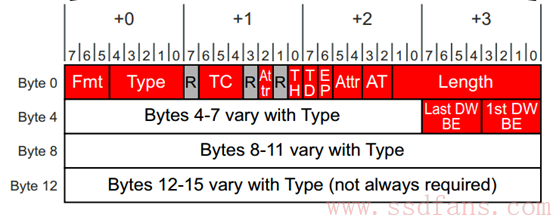
红色区域为所有 TLP Header 公共部分,所有 Header 都有这些;其它则是跟具体的 TLP 相关。
稍微解释一下:
Fmt:Format, 表明该 TLP 是否带有数据,Header 是 3DW 还是 4DW;
Type:TLP 类型,上一节提到的,Memory Read, Memory Write, Configuration Read, Configuration Write, Message 和 Completion,等等;
R: Reserved,为 0;
TC: Traffic Class,TLP 也分三六九等,优先级高的先得到服务。这里是 3 比特,说明可以分为 8 个等级,0-7,TC 默认是 0,数字越大,优先级越高;
Attr: Attrbiute, 属性,前后共三个 bit,先不说;
TH: TLP Processing Hints,先不说;
TD: TLP Digest,之前说 ECRC 可选,如果这个这个 bit 置起来,说明该 TLP 包含 ECRC,接收端应该做 CRC 校验;
EP: Poisoned data, 有毒的数据,远离,哈哈;
AT: Address Type,地址种类,先不说;
Length: Payload 数据长度,10 个 bit,最大 1024,单位 DW,所以 TLP 最大数据长度是 4KB; 该长度总是 DW 的整数倍,如果 TLP 的数据不是 DW 的整数倍(不是 4Byte 的整数倍),则需要用到下面两个域:
Last DW BE 和 1st DW BE。
我觉得,到目前为止,对于 Header,我们只需知道它大概有什么内容,没有必要记住每个域是什么。
这里重点讲讲 Fmt 和 Type,看看不同的 TLP(精简版的,Native PCIe 设备所有)其 Fmt 和 Type 应该怎样编码:
| TLP | Fmt | Type | Comment |
|---|---|---|---|
| Memory Read Request | 000=3DW,no data 001=4DW,no data | 0 0000 | 3DW 或者 4DW 是指 Header 大小,Memory Read 不带数据 |
| Memory Write Request | 010=3DW,with data 011=4DW,with data | 0 0000 | Memory Write 必须带数据 |
| Configuration Type 0 Read Request | 000=3DW,no data | 0 0100 | 读 Endpoint 的 Configuration,不带数据,Header 总是 3DW |
| Configuration Type 0 Write Request | 010=3DW,with data | 0 0100 | 写 Endpoint 的 Configuration,带数据,Header 总是 3DW |
| Configuration Type 1 Read Request | 000=3DW,no data | 0 0101 | 读 Switch 的 Configuration,不带数据,Header 总是 3DW |
| Configuration Type 1 Write Request | 010=3DW,with data | 0 0101 | 写 Switch 的 Configuration,带数据,Header 总是 3DW |
| Message Request | 001 = 4DW, no data | 1 0rrr | Message 的 Header 总是 4DW |
| Message Request with Data | 011 = 4DW, with data | 1 0rrr | Message 的 Header 总是 4DW |
| Completion | 000=3DW,no data | 0 1010 | Completion 的 Header 总是 3DW |
| Completion with Data | 010=3DW,with data | 0 1010 | Completion 的 Header 总是 3DW |
从上可以看出,Configuration 和 Completion 的 TLP(以 C 打头的 TLP),其 Header 大小总是 3 字节;Message TLP 的 Header 总是 4 字节;而 Memory 相关的 TLP 取决于地址空间的大小,地址空间小于 4GB 的,Header 大小为 3DW,大于 4GB 的,Header 大小则为 4DW。
上面介绍了几个 TLP Header 的通用部分,下面分别介绍具体 TLP 的 Header。
- Memory TLP
有两个重要的东西在前面没有提到,那就是 TLP 的源和目标,即,该 TLP 是哪里产生的,它要到哪里去,它们都包含在 Header 里面的。因为不同的 TLP 类型,寻址方式不同,因此要具体 TLP 具体来看这两个东西。
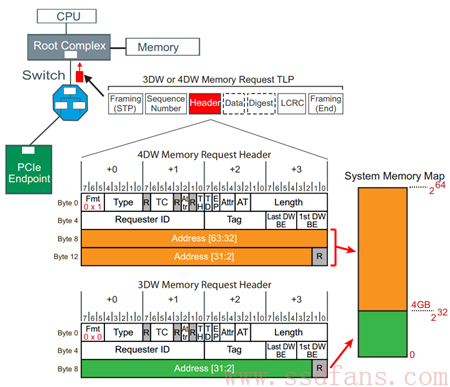
对一个 PCIe 设备来说,它开放给 Host 访问的设备空间首先会映射到 Host 的内存空间,Host 如果想访问设备的某个空间,TLP Header 当中的地址应该设置为该访问空间在 Host 内存的映射地址。如果 Host 内存空间小于 4GB,则 Memory 读写 TLP 的 Header 大小为 3DW,大于 4GB,则为 4DW。那是因为,对 4GB 内存空间,32bit 的地址用 1DW 就可以表示,该地址位于 Byte8-11;而 4GB 以上的内存空间,需要 2DW 表示地址,该地址位于 Byte8-15。
该 TLP 经过 Switch 的时候,Switch 会根据地址信息,把该 TLP 转发到目标设备。之所以能唯一的找到目标设备,那是因为不同的 Endpoint 设备空间会映射到 Host 内存空间的不同位置。
关于 TLP 路由,后面还会专门讲。
Memory TLP 的目标是通过内存地址告知的,而源是通过”Requester ID”告知。每个设备在 PCIe 系统中都有唯一的 ID,该 ID 由总线(Bus)、设备(Device)、功能(Function)三者唯一确定。这个后面也会专门讲,这里只需知道一个 PCIe 组成有唯一的 ID,不管是 RC,Switch 还是 Endpoint。
- Configuration TLP
Endpoint 和 Switch 的配置(Configuration)格式不一样,分别为 Type 0 和 Type 1 来表示。配置可以认为是一个 Endpoint 或者 Switch 的一个标准空间,这段空间在初始化时也需要映射到 Host 的内存空间。与设备的其他空间不同,该空间是标准化的,即不管哪个厂家生产的设备,都需要有这么段空间,而且哪个地方放什么东西,都是协议规定好的,Host 按协议访问这部分空间。由于每个设备 ID 唯一,而其 Configuration 又是固定好的,因此,Host 访问 PCIe 设备的配置空间,只需指定目标设备的 ID 就可以了,不需要内存地址。
下面是访问 Endpoint 的配置空间的 TLP Header (Type 0):
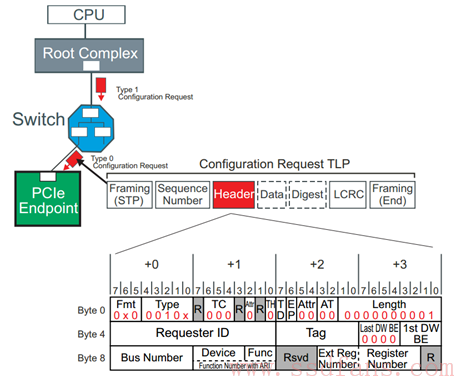
Bus Number + Device + Function 就唯一决定了目标设备; Ext Reg Number + Register Number 相当于配置空间的偏移。找到了设备,然后指定了配置空间的偏移,就能找到具体想访问的配置空间的某个位置。
- Message TLP
Message TLP 用以传输中断、错误、电源管理等信息,取代 PCI 时代的边带信号传输。Message TLP 的 Header 大小总是 4DW。
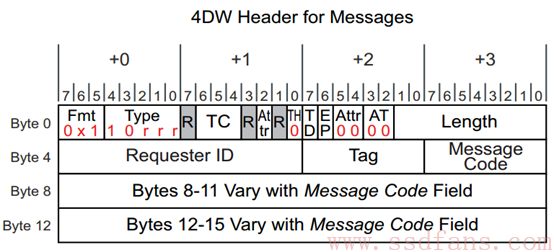
Message Code 来指定该 Message 的类型,具体如下:

不同的 Message Code,最后两个 DW 的意义也不同,这里不展开。
- Completion TLP
有 non-posted request TLP,才有 Completion TLP。有因才有果。前面看到,Requester 的 TLP 当中都有 Requester ID 和 Tag,来告诉接收者发起者是谁。那么响应者的目标地址就很简单,照抄发起者的源地址就可以了。因此,Completion TLP 的 Header 如下:
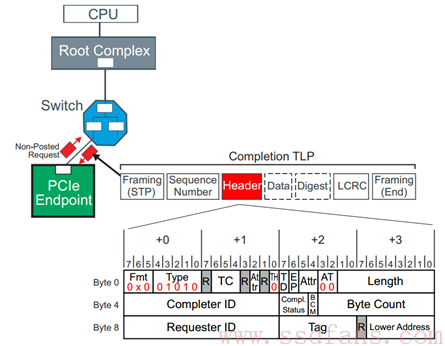
Completion TLP,一方面,可以返回请求者的数据,比如作为 Memory 或者 Configuration Read 的响应;另一方面,还可以返回该事务(Transaction)的状态,因此,在 Completion TLP 的 Header 里面有一个 Completion Status,用以返回事务状态:

TLP 路由
一个 TLP,是怎样经历千山万水,最后顺利抵达目的地呢?
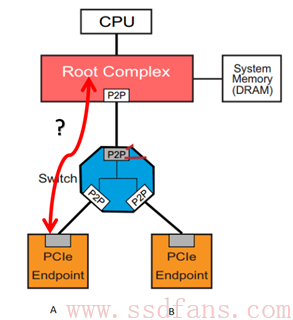
今天就以上图的简单拓扑结构为例,讨论一个 TLP 是怎样从发起者到达接收者,即 TLP 路由问题。
PCIe 共有三种路由方式:基于地址(Address)路由,基于设备 ID(Bus number + Device number + Function Number)路由,还有就是隐式(Implicit)路由。
不同类型的 TLP,其寻址方式也不同,下表总结了每种 TLP 对应的路由方式:
| TLP 类型 | 路由方式 |
|---|---|
| Memory Read/Write TLP | 地址路由 |
| Configuration Read/Write TLP | ID 路由 |
| Completion TLP | ID 路由 |
| Message TLP | 地址路由或者 ID 路由或者隐式路由 |
下面分别讲讲这几种路由方式。
地址路由
前面提到,Switch 负责路由和 TLP 的转发,而路由信息是存储在 Switch 的 Configuration 空间的,因此,很有必要先理解 Switch 的 Configuration。
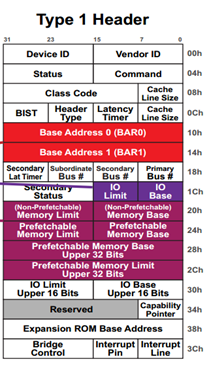
BAR0 和 BAR1 没有什么好说,跟前一节讲的 Endpoint 的 BAR 意义一样,存放 Switch 内部空间在 Host 内存空间映射基址。
Switch 有一个上游端口(靠近 RC)和若干个下游端口,每个端口其实是一个 Bridge,都是有一个 Configuration 的,每个 Configuration 描述了其下面连接设备空间映射的范围,分别由 Memory Base 和 Memory Limit 来表示。对上游端口,其 Configuration 描述的地址范围是它下游所有设备的映射空间范围,而对每个下游端口的 Configuration,描述了连接它端口设备的映射空间范围。大家看看下面这张图,理解一下我刚才说的。(Range 由 Memory Base 和 Memory Limit 限定)
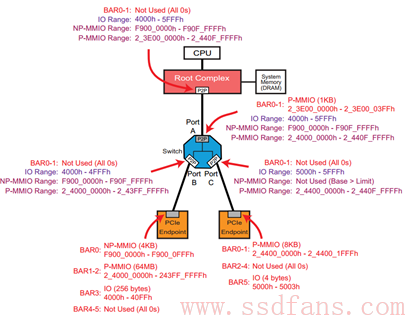
前面我们看到,Memory Read 或者 Memory Write TLP 的 Header 里面都有一个地址信息,该地址是 PCIe 设备内部空间在内存中的映射地址。

- 当一个 Endpoint 收到一个 Memory Read 或者 Memory Write TLP,它会把 TLP Header 中的地址跟它 Configuration 当中的所有 BAR 寄存器比较,如果 TLP Header 中的地址落在这些 BAR 的地址空间,那么它就认为该 TLP 是发给它的,于是接收该 TLP,否则就忽略。
- 当一个 Switch 上游端口收到一个 Memory Read 或者 Memory Write TLP,它首先把 TLP Header 中的地址跟它自己 Configuration 当中的所有 BAR 寄存器比较,如果 TLP Header 当中的地址落在这些 BAR 的地址空间,那么它就认为该 TLP 是发给它的,于是接收该 TLP(这个过程与 Endpoint 的处理方式一样);如果不是,然后看这个地址是否落在其下游设备的地址范围内(是否在 memory base 和 memory limit 之间),如果是,说明该 TLP 是发给它下游设备的,因此它要完成路由转发;如果地址不落在下游设备的地方范围内,说明该 TLP 不是发给它下面设备的,因此不接受该 TLP。
img 
img
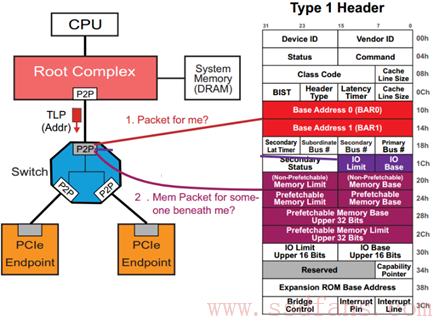
刚才的描述是针对 TLP 从 Upstream 流到 Downstream 的路由。如果是 TLP 从下游往上走呢?
它首先把 TLP Header 中的地址跟它自己 Configuration 当中的所有 BAR 寄存器比较,如果 TLP Header 当中的地址落在这些 BAR 的地址空间,那么它就认为该 TLP 是发给它的,于是接收该 TLP(跟前面描述一样);如果不是,然后看这个地址是否落在其下游设备的地址范围内(是否在 memory base 和 memory limit 之间),如果是,这个时候不是接受,而是拒绝;相反,如果地址不落在下游设备的地方范围内,Switch 则把该 TLP 传上去。
ID 路由
在一个 PCIe 拓扑结构中,由 ID = Bus number+Device number+Function Number(BDF)能唯一找到某个设备的某个功能。这种按设备 ID 号来寻址的方式叫做 ID 路由。Configuration TLP 和 Completion TLP(以 C 打头的 TLP)按 ID 路由,Message 在某些情况下也是 ID 路由。
使用 ID 路由的 TLP,其 TLP Header 中含有 BDF 信息:

当一个 Endpoint 收到一个这样的 TLP,它用自己的 ID 和收到 TLP Header 中的 BDF 比较,如果是给自己的,就收下 TLP,否则就拒绝。
如果是一个 Switch 收到这样的一个 TLP,怎么处理?我们再回头去看看 Switch 的 Configuration Header。

看三个寄存器:Subordinate Bus Number,Secondary Bus Number 和 Primary Bus Number,看下图就知道这几个寄存器是什么意思:
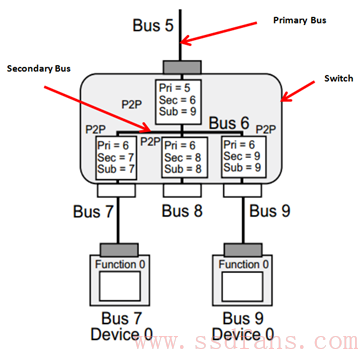
对一个 Switch 来说,每个 Port 靠近 RC(上游)的那根 Bus 叫做 Primary Bus,其 Number 写在其 Configuration Header 中的 Primary Bus Number 寄存器;每个 Port 下面的那根 Bus 叫做 Secondary Bus,其 Number 写在其 Configuration Header 中的 Secondary Bus Number 寄存器;对上游端口,Subordinate Bus 是其下游所有端口连接的 Bus 编号最大的那个 Bus,Subordinate Bus Number 写在每个 Port 的 Configuration Header 中的 Subordinate Bus Number 寄存器。
当一个 Switch 收到一个基于 ID 寻址的 TLP,首先检查 TLP 中的 BDF 是否与自己的 ID 匹配,如匹配,说明该 TLP 是给自己的,收下;否则,则检查该 TLP 中的 Bus Number 是否落在 Secondary Bus Number 和 Subordinate Bus Number 之间,如果是,说明该 TLP 是发给其下游设备的,然后转发到对应的下游端口;如果其他情况,则拒绝这些 TLP。
隐式路由
只有 Message TLP 才支持隐式路由。在 PCIe 总线中,有些 Message 是与 RC 通信的,RC 是该 TLP 的发送者或者接收者,因此没有必要明明白白的指定地址或者 ID,而是采用”你懂的”的方式进行路由,这种路由方式为隐式路由。Message TLP 还支持地址路由和 ID 路由,但以隐式路由为主。
Message TLP 的 Header 总是 4DW,如下图所示:
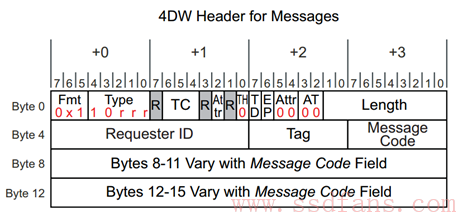
Type 字段,低三位,用 rrr 表示的,指明该 Message 的路由方式,具体如下:

当一个 Endpoint 收到一个 Message TLP,检查 TLP Header,如果是 RC 的广播 Message(011b)或者该 Message 终结于它(100b),它就接受该 Message。
当一个 Switch 收到一个 Message TLP,检查 TLP Header,如果是 RC 的广播 Message(011b),则往它每个下游端口复制该 Message 然后转发;如果该 Message 终结于它(100b),则接受该 TLP;如果下游端口收到发给 RC 的 message,往上游端口转发便是。
上面说的是 Message 使用隐式路由的情况。如果是地址路由或者 ID 路由,Message TLP 的路由跟别的 TLP 一样,不赘述。
参考资料
-
No backlinks found.