数据包收发流程
网络作为 PCIe 设备,工作在物理层和数据链路层,主要由 PHY/MAC 芯片、Tx/Rx FIFO、DMA 等组成。PHY 芯片对外通过变压器与网线连接,实现 CSMA/CD、模数转换、编解码、串并转换等功能。MAC 芯片对内连接 PCI 总线,主要负责比特流于帧的转换、CRC 校验和 Packet Filtering 等功能。本文将详细介绍 Linux 内核网络子系统中,在数据链路层收发包的原理。
数据包的接收过程
设备驱动层
对于每一个网卡,无论是真实网卡还是虚拟网卡,在内核中都会对应着 net_device,都会有对应的网络设备驱动来在内核中注册和初始化,正如 Linux 网络设备驱动中所述。
|
|
可以看到这里主要调用了 pci_register_driver 来初始化网络设备。
PCI 初始化
Intel I350 网卡是 PCIe 设备,PCI 设备通过 PCI 配置空间来区分自己。当一个 PCI 设备驱动编译时,会通过宏 MODULE_DEVICE_TABLE (from include/module.h) 来导出 PCI 设备 ID,这样设备驱动就可以控制和操作设备了。内核通过这个表来将不同的 PCI 设备与不同的设备驱动对应起来。
|
|
前面我们看到 pci_register_driver 用来初始化设备驱动,这里传入的是 igbbe_driver 参数。内核使用 struct pci_driver结构来描述一个 PCI 设备,因为在系统引导的时候,PCI 设备已经被识别,当内核发现一个已经检测到的设备同驱动注册的 id_table中的信息相匹配时,它就会触发驱动的 probe函数。
|
|
PCI Probe
一旦一个设备被内核通过 PCI IDs 识别,内核将会选择合适的驱动来控制该设备。每个 PCI 驱动注册了一个 probe 函数表示该设备已经被识别和控制。一般 probe 的常见操作包括:
- Enable PCI 设备
- 申请 memory ranges 和 IO ports
- 设置 DMA Mask
- 注册 ethtool 函数
- 任何需要的 watchdog tasks
- 该设备专门的一些事情
struct net_device_ops对应的创建、初始化和注册struct net_device对应的创建、初始化和注册
|
|
网络设备初始化
struct net_device_ops
struct net_device_ops 包含了用于操作网络设备的一系列函数指针,它在 ixgbe_probe 函数中被赋值。如下所示,我们可以看到常见的 ndo_open、ndo_stop、ndo_start_xmit 等函数,还可以看到跟 SRIOV 相关的 nod_set_vf_mac,跟 tc 相关 的 nod_setup_tc,跟 bridge 相关的 ndo_fdb_add,跟 XDP 和 BPF 相关的 ndo_bpf 等等。
|
|
ethtool registration
ethtool 是在网络中广泛使用的调试工具,可以用来获取关于网络设备的众多信息,ethtool 通过 ioctl 与驱动通信。
|
|
这里可以看到一些常见的 ethtool 函数:
|
|
IRQs
当数据包通过网络到达网卡后,data frame 通过 DMA 被写到 RAM,那么接下来 NIC 怎么告诉内核去处理数据呢?
这个时候 NIC 会产生一个 interrupt request (IRQ) 来表示数据到来了,有三种常见的中断:
- MSI-X
- MSI
- 传统的 IRQs
但是当有大量数据包到来时会产生大量的 IRQs,大量的 CPU 时间被用来处理中断。为了解决这个问题,内核设计了 NAPI 机制来减少中断的产生。
|
|
|
|
NAPI
NAPI 是 Linux 上采用的一种提高网络处理效率的技术,它的核心概念就是不采用中断的方式读取数据,而代之以首先采用中断唤醒数据接收的服务程序,然后 Pol l 的方法来轮询数据。NAPI 的使用流程如下:
- NAPI 被驱动 Enable,但是默认是关闭状态
- 数据包到达 NIC 并且被 DMA 到 RAM 中
- NIC 产生 IRQ,触发了驱动中的 IRQ Handler
- 驱动通过 softirq 唤醒 NAPI 子系统,通过使用驱动注册的 Poll 函数来获取数据包
- 驱动关闭 NIC 的中断,这样可以通过驱动使用 NAPI 获取数据包而不用处理中断
- 当所有数据包都已被处理,NAPI 被 disable,IRQs 被 re-enable
- 当再次有数据包到达,重复步骤 2
对于使用 NAPI 的驱动,都会有一个 poll 函数,它会调用 netif_napi_add 方法向 NAPI 子系统注册,后面会详细介绍。
|
|
ixgbe_adapter包含 ixgbe_q_vector数组(一个 ixgbe_q_vector对应一个中断),ixgbe_q_vector包含 napi_struct
|
|
|
|
我们知道网卡可能有多队列,每个发送队列和接收队列都会对应着一个 q_vector 。仔细看下 ixgbe_alloc_q_vetor 函数的实现,可以看到 ixgbe_poll 是如何被注册的:
|
|
硬中断函数把 napi_struct加入 CPU 的 poll_list,软中断函数 net_rx_action()遍历 poll_list,执行 poll函数
打开网络设备
当一个网络设备被启动时(比如 ifconfig eth0 up),会调用 ndo_open,一般会执行以下操作:
- Allocate RX and TX queue memory
- Enable NAPI
- Register an interrupt handler
- Enable hardware interrupts
- And more
以 ixgbe_open 为例:
|
|
初始化 Ring Buffer
当前绝大多数的 NIC 会直接将收到的数据包 DMA 到 RAM,然后操作系统网络子系统可以从 RAM 中取出数据,这段空间即是 Ring Buffer。因此,驱动必须向 OS 申请一段 Memory Region,并将这段地址告知 Hardware,之后网卡就会自动将数据包 DMA 到这段 Ring Buffer 中。
当网络数据包速率较高时,一个 CPU 不能够处理所有的数据包,具体的,这段 Ring Buffer 是固定大小的空间,数据包将会被丢掉。为了解决这个问题,设计了 Receive Side Scaling (RSS) 或者说多队列网卡技术。一些网卡设备可以将接收到的数据包分发到多个 Ring Buffer 中,每个 Ring Buffer 就是一个独立的 Queue。这样允许 OS 在硬件层面就使用多个 CPU 来并行处理收到的数据包。
ixgbe 网卡支持多队列,我们可以看到其驱动在初始化时会调用 ixgbe_setup_all_rx_resources 和 ixgbe_setup_all_tx_resources 来初始化 Rx 和 Tx 的 Descriptors。
|
|
我们看到, ixgbe_adapter 的数据结构中有 rx_ring Descriptor 数组用于描述接收 Ring Buffer,类似的还有 tx_ring 和 xdp_ring。
|
|
具体看 ixgbe_ring 这个数据结构,关键字段
- next:指向在 q_vector 中的下一个
ixgbe_ring - desc:指向这个 descriptor ring 拥有的 DMA Buffer 的开始地址,这是数据在接收和发送所在的实际地址
- rx_buffer_info: 接受队列的描述信息,包括关联的 skb 和 dma 地址
- dma:表明这个 descriptor ring 指向的 DMA Buffer 的物理地址,对于 DMA 而言,其数据传输不会经过 MMU,因此需要一个真实的物理地址
- count: 这个 descriptor ring 总共有多少个 descriptor
- size: descriptor count * sizeof(ixgbe_ring)
- queue_index:用于 multiqueue 的队列管理
|
|
可以看到在 ixgbe_setup_rx_resources 会初始化该数据结构的变量,并且调用 dam_alloc_coherent 来申请 DMA Memory。
|
|
Rx Ring Buffer
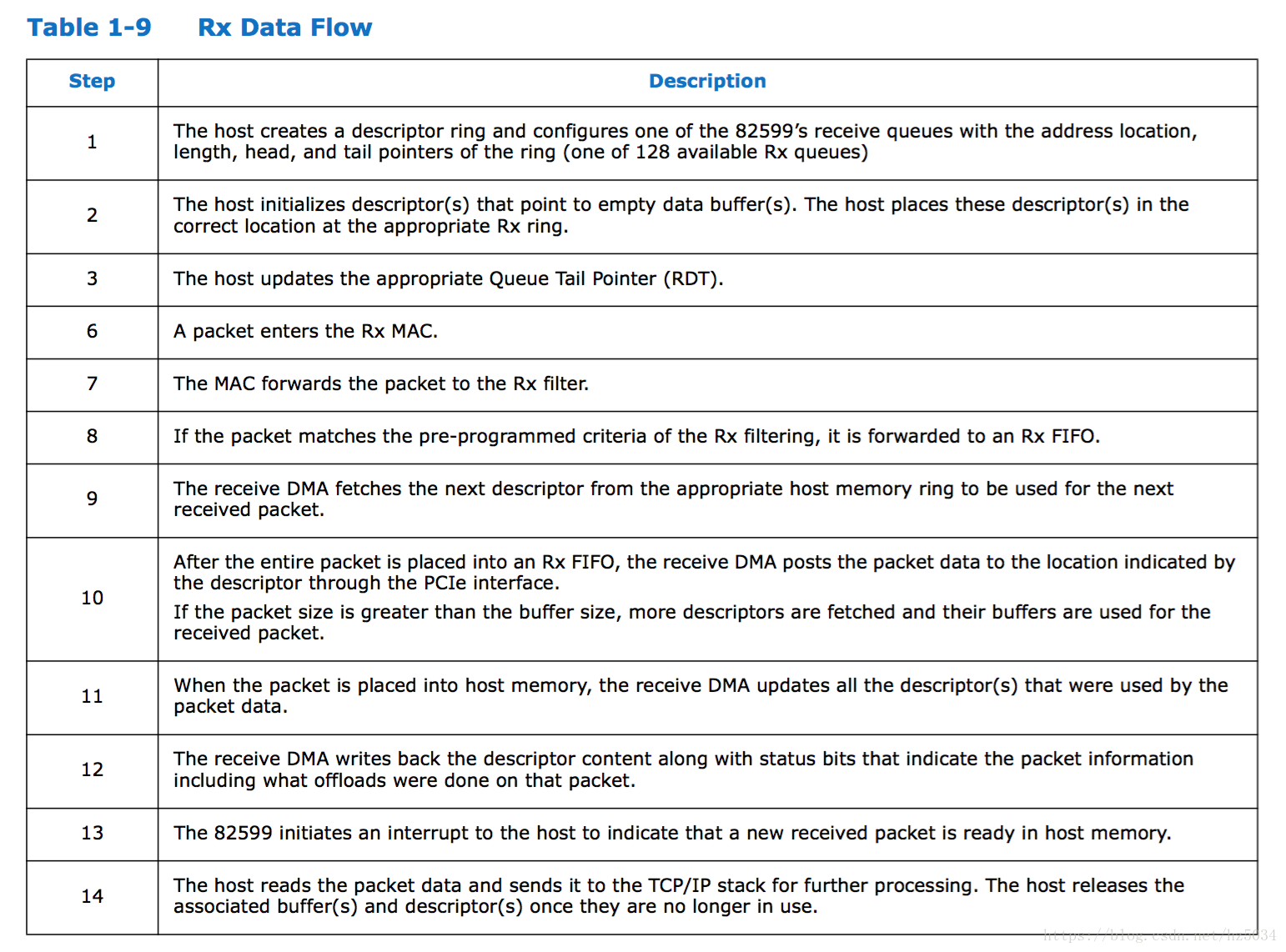
- 网卡驱动创建 rx descriptor ring(一致性 DMA 内存),将 rx descriptor ring 的总线地址写入网卡寄存器 RDBA
- 网卡驱动为每个 descriptor 分配 sk_buff 和数据缓存区,流式 DMA 映射数据缓存区,将数据缓存区的总线地址保存到 descriptor
- 网卡接收数据包,将数据包写入 Rx FIFO
- DMA 找到 rx descriptor ring 中下一个将要使用的 descriptor
- 整个数据包写入 Rx FIFO 后,DMA 通过 PCI 总线将 Rx FIFO 中的数据包复制到 descriptor 的数据缓存区
- 复制完后,网卡启动硬中断通知 CPU 数据缓存区中已经有新的数据包了,CPU 执行硬中断函数:
- NAPI(以 e1000 网卡为例):e1000_intr() -> **napi_schedule() -> **raise_softirq_irqoff(NET_RX_SOFTIRQ)
- 非 NAPI(以 dm9000 网卡为例):dm9000_interrupt() -> dm9000_rx() -> netif_rx() -> napi_schedule() -> **napi_schedule() -> **raise_softirq_irqoff(NET_RX_SOFTIRQ)
- ksoftirqd 执行软中断函数 net_rx_action():
- NAPI(以 e1000 网卡为例):net_rx_action() -> e1000_clean() -> e1000_clean_rx_irq() -> e1000_receive_skb() -> netif_receive_skb()
- 非 NAPI(以 dm9000 网卡为例):net_rx_action() -> process_backlog() -> netif_receive_skb()
- 网卡驱动通过 netif_receive_skb() 将 sk_buff 上送协议栈
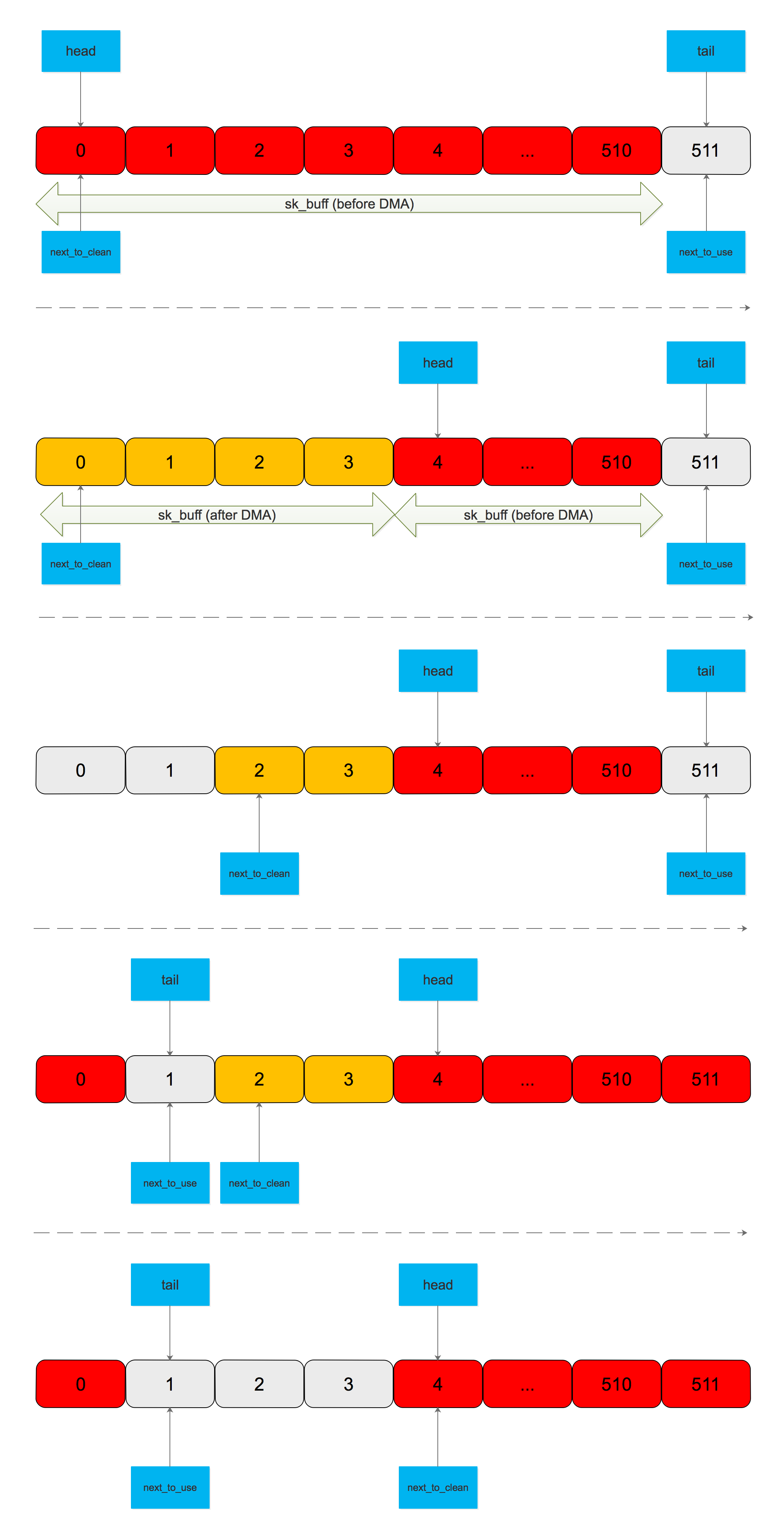
对于这段 Ring Buffer,Hardware 和 Software 会共同读写,Hardware 也就是 NIC,Software 就是驱动。
- SW 向从 next_to_use 开始的 N 个 descriptor 补充 sk_buff,next_to_use += N,tail = next_to_use(写网卡寄存器 RDT)
- HW 写 Frame 到从 head 开始的 M 个 descriptor 的 sk_buff,写完后回写 EOP(End of Packet),head += M
- SW 将从 next_to_clean 开始的 L 个 sk_buff 移出 Rx Ring Buffer 并上送协议栈,next_to_clean += L,向从 next_to_use 开始的 L 个 descriptor 补充 sk_buff,next_to_use += L,tail = next_to_use
注意:每次补充完 sk_buff 后,tail 和 next_to_use 指向同一个 sk_buff
Tx Ring Buffer
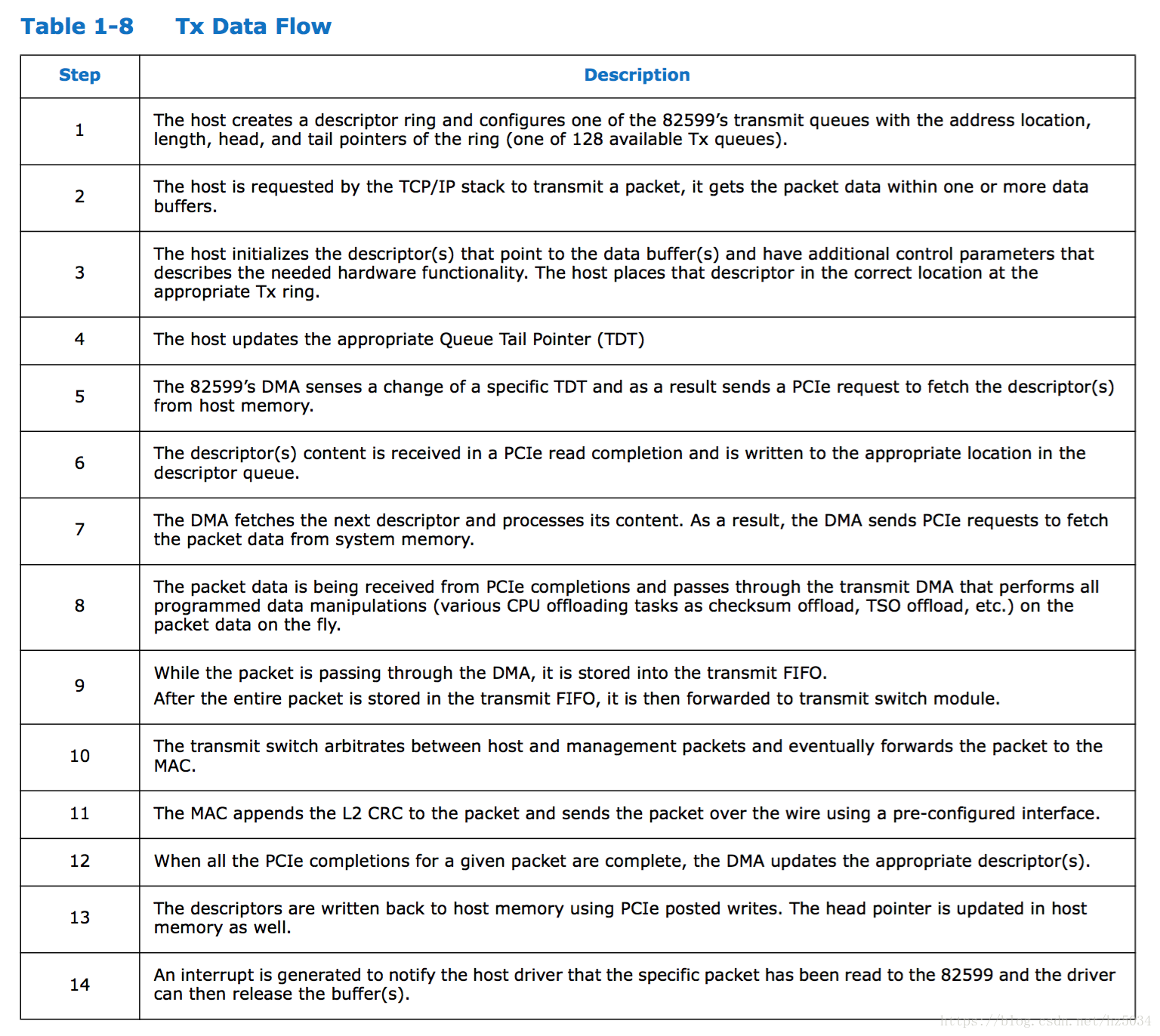
- 网卡驱动创建 tx descriptor ring(一致性 DMA 内存),将 tx descriptor ring 的总线地址写入网卡寄存器 TDBA
- 协议栈通过 dev_queue_xmit()将 sk_buff 下送网卡驱动
- 网卡驱动将 sk_buff 放入 tx descriptor ring,更新 TDT
- DMA 感知到 TDT 的改变后,找到 tx descriptor ring 中下一个将要使用的 descriptor
- DMA 通过 PCI 总线将 descriptor 的数据缓存区复制到 Tx FIFO
- 复制完后,通过 MAC 芯片将数据包发送出去
- 发送完后,网卡更新 TDH,启动硬中断通知 CPU 释放数据缓存区中的数据包
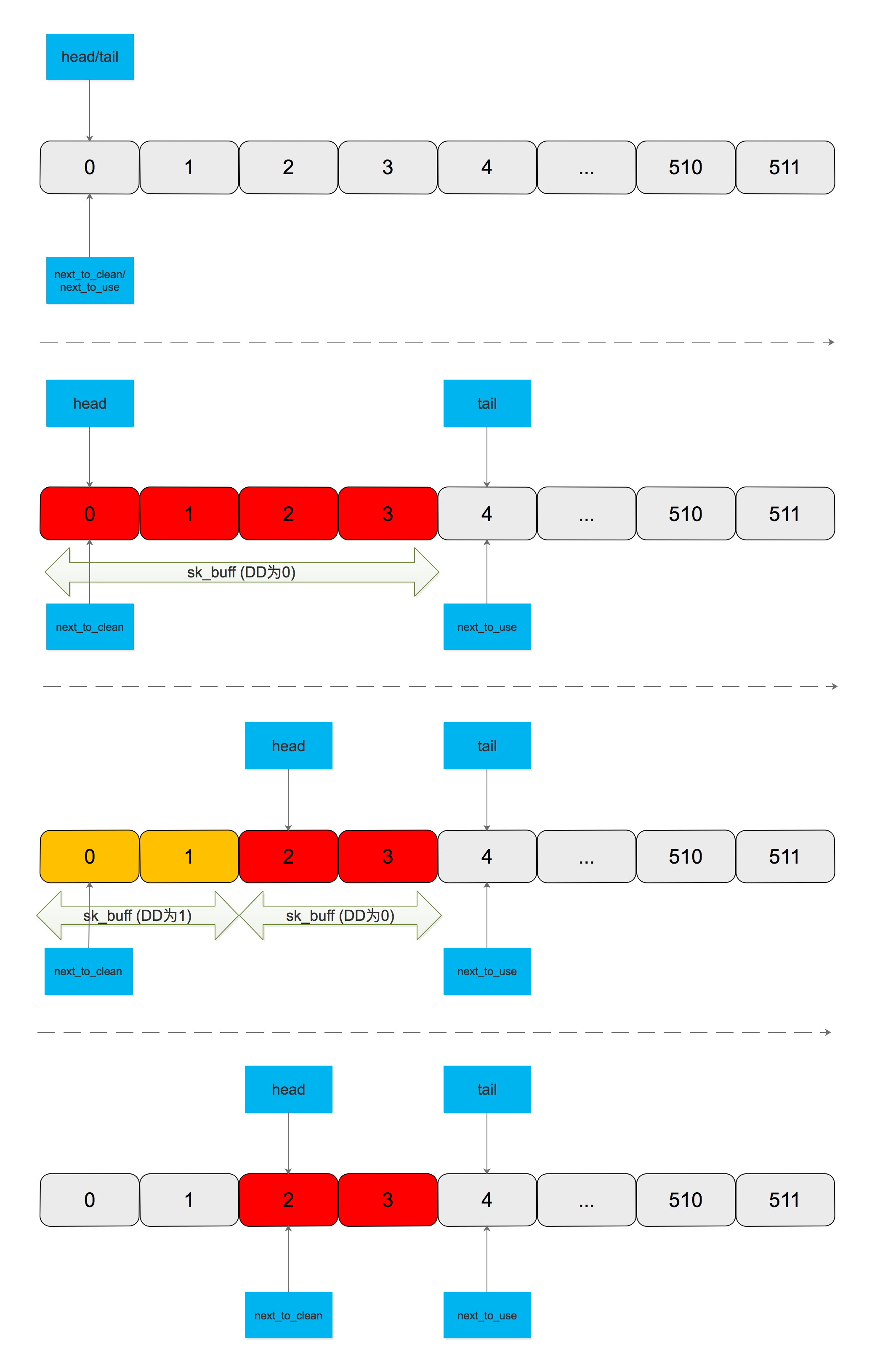
SW 将 sk_buff 挂载到从 next_to_use 开始的 N 个 descriptor,next_to_use += N,tail = next_to_use(写网卡寄存器 TDT)
HW 使用 DMA 读从 head 开始的 M 个 descriptor 的 sk_buff,发送成功后回写 DD(Descriptor Done),head += M
SW 将从 next_to_clean 的开始的 L 个 sk_buff 移出 Tx Ring Buffer 并清理,next_to_clean += L
注意:每次挂载完 sk_buff 后,tail 和 next_to_use 指向同一个 descriptor
Register interrupt handler
设备驱动需要探查驱动支持那种中断:MSI-X、MSI 或者是 L egacy Interrupt,并且根据中断类型设置 interrupt handler。关于这三种中断类型的区别可以查看 this useful wiki page 。
|
|
Enable NAPI
通过 napi_enable 来 Enable 每个 q_vector 的 NAPI:
|
|
SoftIRQs
我们知道,Linux 中断分为顶半部和底半部:
- 顶半部也即是 Interrupt Handler,处理时全程关闭中断,用于处理有实时性和硬件相关的操作,可以快速的执行完毕。
- 底半部代表中断处理中被延后执行的部分
目前 Linux 支持 softirq、tasklet 和 work queue 三种底半部机制,对于网络协议栈而言,我们只关注 softirq。对每个 CPU,都会有一个 kernel thread 用于处理软中断,也就是在 top 中看到的 ksoftirqd/0 这种进程。
|
|
可以看到 ksoftirqd 进程执行的 routine 是 __do_softirq():
|
|
__do_softirq() 的逻辑如下:
- 看当前那个 softirq 处在 pending 状态
- softirq 的时间被统计
- softirq 的执行统计数据递增
- 执行 pending 状态的 softirq 的 handler
SoftIRQ 有以下几种类型:
|
|
内核初始化期间,softirq_init会注册 TASKLET_SOFTIRQ以及 HI_SOFTIRQ相关联的处理函数。
|
|
网络子系统分两种 soft IRQ。NET_TX_SOFTIRQ和 NET_RX_SOFTIRQ,分别处理发送数据包和接收数据包。这两个 soft IRQ 在 net_dev_init函数(net/core/dev.c)中注册,收发数据包的软中断处理函数被注册为 net_rx_action和 net_tx_action。
|
|
其中 open_softirq实现为:
|
|
softnet_data
每个 CPU 都有一个队列,用于存储 incoming frame,这个数据结构即是 softnet_data。因为这是 per-cpu 的数据结构,每个 CPU 都有自己的对立,所以不同的 CPU 之间不需要锁来控制并发处理这个数据结构。
|
|
softnet_data 是在 start_kernel 中创建的,每个 cpu 一个 softnet_data 变量:
- 当收到数据包时,网络设备驱动会把自己的
napi_struct挂到 CPU 私有变量softnet_data->poll_list上 - 在软中断时,
net_rx_action会遍历 cpu 私有变量的softnet_data->poll_list,执行上面所挂的napi_struct结构的poll钩子函数,将数据包从驱动传到网络协议栈
内核初始化流程如下所示:
|
|
总结

- 数据包进入物理网卡。如果目的地址不是该网络设备,且该来网络设备没有开启 混杂模式,该包会被网络设备丢弃。
- 物理网卡将数据包通过 DMA 的方式写入到指定的内存地址,该地址由网卡驱动分配并初始化。
- 物理网卡通过硬件中断(IRQ)通知 CPU,有新的数据包到达物理网卡需要处理。
- CPU 根据中断表,调用已经注册的中断函数,这个中断函数会调到驱动程序(NIC Driver)中相应的函数
- 驱动先禁用网卡的中断,表示驱动程序已经知道内存中有数据了,告诉物理网卡下次再收到数据包直接写内存就可以了,不要再通知 CPU 了,这样可以提高效率,避免 CPU 不停的被中断。
- 启动软中断继续处理数据包。这样的原因是硬中断处理程序执行的过程中不能被中断,所以如果它执行时间过长,会导致 CPU 没法响应其它硬件的中断,于是内核引入软中断,这样可以将硬中断处理函数中耗时的部分移到软中断处理函数里面来慢慢处理。
链路层
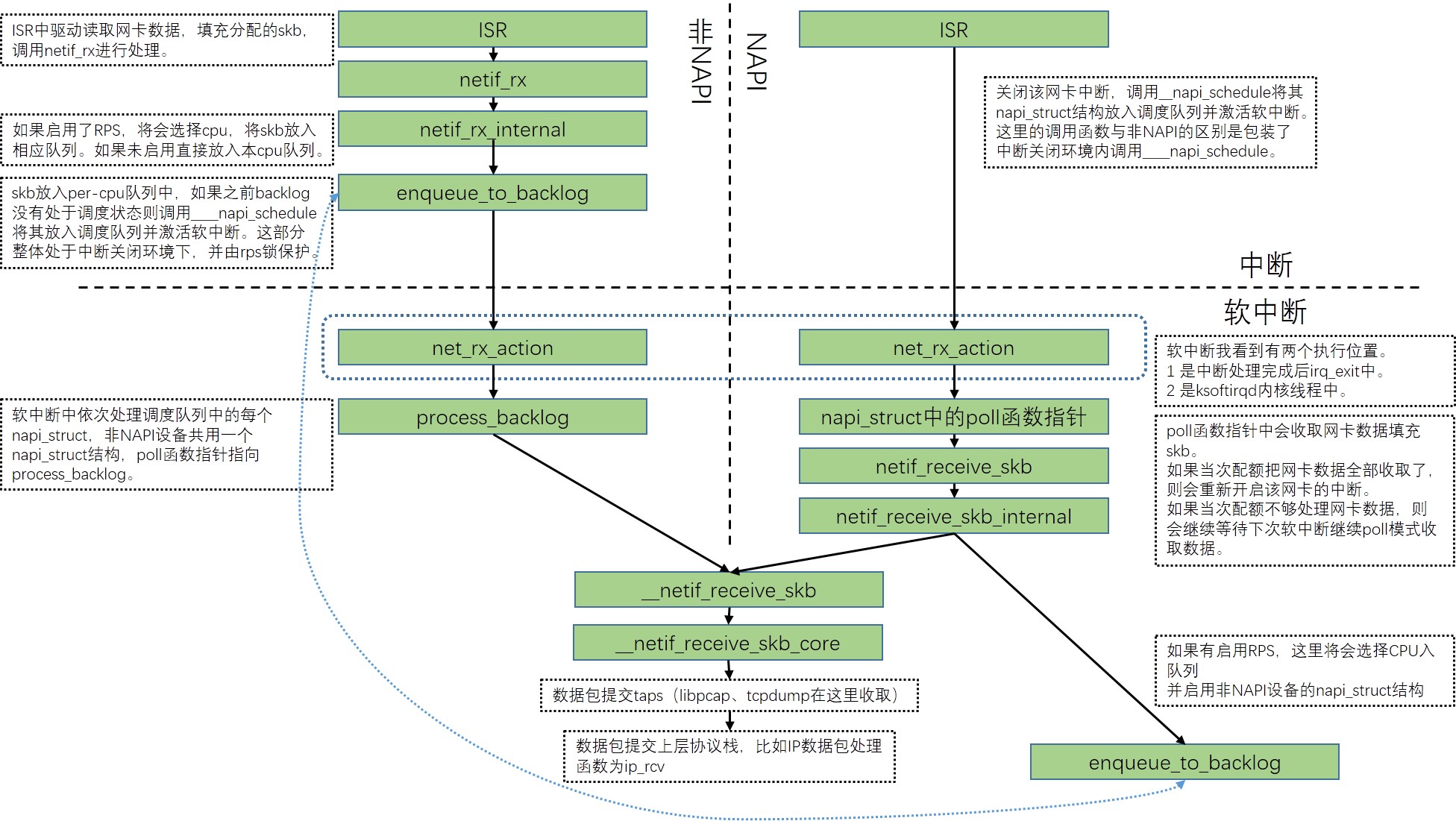
按照驱动是 NAPI 还是非 NAPI,有不同的调用路径,ksoftirqd 执行软中断函数 net_rx_action():
- NAPI(以 e1000 网卡为例):
net_rx_action() -> e1000_clean() -> e1000_clean_rx_irq() -> e1000_receive_skb() -> netif_receive_skb() - 非 NAPI(以 dm9000 网卡为例):
net_rx_action() -> process_backlog() -> netif_receive_skb()
在初始化时,默认是非 napi 的模式,poll 函数默认是: process_backlog,如下:
|
|
主流网卡都已经支持 NAPI ,所以我们主要看 NAPI 的流程:
Interrupt Handler
当数据包到达时,NIC 产生中断,驱动 interrupt handler 用于处理中断。可以看到,interrupt handler 十分简单:
- 执行 igb_write_itr 用于 更新硬件寄存器
- 执行 napi_schedule 用于唤醒 NAPI processing loop
注意,这里的 NAPI processing loop 不是在 Interrupt handler 中执行的,而是在 softirq 中执行的,interrupt handler 只是触发了他的执行。
|
|
我们具体看看 napi_schedule 做了什么,他实际是 __napi_schedule 的简单封装,这段代码首先获取了当前 CPU 上注册的 softnet_data,然后执行了 ____napi_schedule
|
|
____napi_schedule 执行逻辑包括:
- 将当前这个设备驱动的
napi->poll_list加到当前 CPU 关联的softnet_data的 poll_list 中 - 调用
__raise_softirq_irqoff来触发NET_RX_SOFTIRQ软中断,如果当前net_rx_action没有执行,将会触发其执行
|
|
net_rx_action
net_rx_action 是网络接收底半部的入口,它的执行逻辑为:
-
遍历当前 CPU 的 NAPI list,执行 NAPI
poll函数 -
当 budget 不够或者超时,则本次
net_rx_action退出,这样可以保证包处理不会占用整个 CPU -
budget 被定义为一个
NAPI polling cycle中允许处理的最大 packet number,参考 netdev_budget 解释 -
netdev_budget_usecs则为一个NAPI polling cycle中允许处理的最长时间 microseconds,设定为 2 jiffiesjiffies 记录了经过多少 tick,tick 代表的时间由 CONFIG_HZ 定义,CONFIG_HZ=200,则一个 jiffies 对应 5ms 时间
|
|
这里 napi_poll 返回的是处理的 packet number,这里我们可以看到 NAPI weight 的作用了。
|
|
当我们把 weight 设置为 64,budget 设置为 300,此次 napi polling cycle 将会停止
- ixgbe_poll 调用了最多 5 次
- 时间超过 2 jiffies
|
|
这里 NAPI 和 驱动定义的规则是:
- 如果 driver 的 poll function,比如这里的
ixgbe_poll消耗了整个 weight,那么不能改变 NAPI 的状态,将当前 napi 结构体移到 poll list 的末尾,接下来将会执行下一个 net_rx_action loop - 如果 driver 的 poll function,比如这里的
ixgbe_poll没有消耗完整个 weight,那么 driver 必须 disable NAPI (调用 napi_complete)。当下一次数据包到来时,driver 的 IRQ 调用napi_schedule时重新 enable NAPI。
NAPI Poll
|
|
可以看到,这里面最关键的函数是 ixgbe_clean_rx_irq,其他则按照驱动和 NAPI 定义的规则执行。
Rx Ring Buffer
ixgbe_clean_rx_irq
|
|
napi_gro_receive
如果开启了 GRO,napi_gro_receive 将负责处理网络数据,并将数据送到协议栈,大部分相关的逻辑在函数 dev_gro_receive 里实现。
|
|
dev_gro_receive这个函数首先检查 GRO 是否开启了,如果是,就准备做 GRO。GRO 首先遍历一个 offload filter 列表,如果高层协议认为其中一些数据属于 GRO 处理的范围,就会允许其对数据进行操作。
协议层以此方式让网络设备层知道,这个 packet 是不是当前正在处理的一个需要做 GRO 的 network flow 的一部分,而且也可以通过这种方式传递一些协议相关的信息。例如,TCP 协议需要判断是否应该将一个 ACK 包合并到其他包里。
|
|
如果协议层提示是时候 flush GRO packet 了,那就到下一步处理了。这发生在 napi_gro_complete,会进一步调用相应协议的 gro_complete 回调方法,然后调用 netif_receive_skb 将包送到协议栈。
|
|
接下来,如果协议层将这个包合并到一个已经存在的 flow,napi_gro_receive 就没什么事情需要做,因此就返回了。如果 packet 没有被合并,而且 GRO 的数量小于 MAX_GRO_SKBS( 默认是 8),就会创建一个新的 entry 加到本 CPU 的 NAPI 变量的 gro_list。
|
|
napi_skb_finish
一旦 dev_gro_receive 完成,napi_skb_finish 就会被调用,其如果一个 packet 被合并了 ,就释放不用的变量;或者调用 netif_receive_skb 将数据发送到网络协议栈。
|
|
netif_receive_skb
netif_receive_skb 及其衍生函数仍然处于 softirq 的循环中,所以这段时间仍然会算在 sitime 中
每个 NAPI 变量都会运行在相应 CPU 的软中断的上下文中。而且,触发硬中断的这个 CPU 接下来会负责执行相应的软中断处理函数来收包。换言之,同一个 CPU 既处理硬中断,又处理相应的软中断。
一些网卡(例如 Intel I350)在硬件层支持多队列。这意味着收进来的包会被通过 DMA 放到位于不同内存的队列上,而不同的队列有相应的 NAPI 变量管理软中断 poll()过程。因此, 多个 CPU 同时处理从网卡来的中断,处理收包过程。这个特性被称作 RSS(Receive Side Scaling,接收端扩展)。
RPS (Receive Packet Steering,接收包控制,接收包引导)是 RSS 的一种软件实现。因为是软件实现的,意味着任何网卡都可以使用这个功能,即便是那些只有一个接收队列的网卡。但是,因为它是软件实现的,这意味着 RPS 只能在 packet 通过 DMA 进入内存后,RPS 才能开始工作。
这意味着,RPS 并不会减少 CPU 处理硬件中断和 NAPI poll(软中断最重要的一部分)的时间,但是可以在 packet 到达内存后,将 packet 分到其他 CPU,从其他 CPU 进入协议栈。
Without RPS
如果 RPS 没启用,会调用 __netif_receive_skb,它做一些 bookkeeping 工作,进而调用 __netif_receive_skb_core,将数据移动到离协议栈更近一步。
With RPS enabled
如果 RPS 启用了,它会做一些计算,判断使用哪个 CPU 的 backlog queue,这个过程由 get_rps_cpu 函数完成。
|
|
get_rps_cpu 会考虑 RFS 和 aRFS 设置,以此选出一个合适的 CPU,通过调用 enqueue_to_backlog 将数据放到它的 backlog queue。
假如你的网卡支持 aRFS,你可以开启它并做如下配置:
- 打开并配置 RPS
- 打开并配置 RFS
- 内核中编译期间指定了 CONFIG_RFS_ACCEL 选项。Ubuntu kernel 3.13.0 是有的
- 打开网卡的 ntuple 支持。可以用 ethtool 查看当前的 ntuple 设置
- 配置 IRQ(硬中断)中每个 RX 和 CPU 的对应关系
以上配置完成后,aRFS 就会自动将 RX queue 数据移动到指定 CPU 的内存,每个 flow 的包都会到达同一个 CPU,不需要你再通过 ntuple 手动指定每个 flow 的配置了。
enqueue_to_backlog
首先从远端 CPU 的 struct softnet_data 变量获取 backlog queue 长度。如果 backlog 大于 netdev_max_backlog,或者超过了 flow limit,直接 drop,并更新 softnet_data 的 drop 统计。注意这是远端 CPU 的统计。
|
|
enqueue_to_backlog 被调用的地方很少。在基于 RPS 处理包的地方,以及 netif_rx,会调用到它。大部分驱动都不应该使用 netif_rx,而应该是用 netif_receive_skb。如果你没用到 RPS,你的驱动也没有使用 netif_rx,那增大 backlog 并不会带来益处,因为它根本没被用到。
注意:检查驱动,如果它调用了 netif_receive_skb,而且没用 RPS,那增大 netdev_max_backlog 并不会带来任何性能提升,因为没有数据包会被送到 input_pkt_queue。
如果 input_pkt_queue 足够小,而 flow limit 也还没达到(或者被禁掉了 ),那数据包将会被放到队列。这里的逻辑有点 funny,但大致可以归为为:
- 如果 backlog 是空的:如果远端 CPU NAPI 变量没有运行,并且 IPI 没有被加到队列,那就 触发一个 IPI 加到队列,然后调用
____napi_schedule进一步处理。 - 如果 backlog 非空,或者远端 CPU NAPI 变量正在运行,那就 enqueue 包 这里使用了 goto,所以代码看起来有点 tricky。
|
|
Flow limits
RPS 在不同 CPU 之间分发 packet,但是,如果一个 flow 特别大,会出现单个 CPU 被打爆,而其他 CPU 无事可做(饥饿)的状态。因此引入了 flow limit 特性,放到一个 backlog 队列的属 于同一个 flow 的包的数量不能超过一个阈值。这可以保证即使有一个很大的 flow 在大量收包 ,小 flow 也能得到及时的处理。
|
|
默认,flow limit 功能是关掉的。要打开 flow limit,需要指定一个 bitmap(类似于 RPS 的 bitmap)。
监控:由于 input_pkt_queue 打满或 flow limit 导致的丢包,在 /proc/net/softnet_stat 里面的 dropped 列计数。
调优 Tuning: Adjusting netdev_max_backlog to prevent drops 在调整这个值之前,请先阅读前面的“注意”。
如果使用了 RPS,或者驱动调用了 netif_rx,那增加 netdev_max_backlog 可以改善在 enqueue_to_backlog 里的丢包:
例如:
increase backlog to 3000 with sysctl.
|
|
默认值是 1000。
backlog 处理逻辑和设备驱动的 poll 函数类似,都是在软中断(softirq)的上下文中执行,因此受整体 budget 和处理时间的限制。
Tuning: Enabling flow limits and tuning flow limit hash table size
|
|
默认值是 4096
这只会影响新分配的 flow hash table。所以,如果你想增加 table size 的话,应该在打开 flow limit 功能之前设置这个值。
打开 flow limit 功能的方式是,在 /proc/sys/net/core/flow_limit_cpu_bitmap 中指定一 个 bitmask,和通过 bitmask 打开 RPS 的操作类似。
处理 backlog 队列:NAPI poller
每个 CPU 都有一个 backlog queue,其加入到 NAPI 变量的方式和驱动差不多,都是注册一个 poll 方法,在软中断的上下文中处理包。此外,还提供了一个 weight,这也和驱动类似 。注册发生在网络系统初始化的时候, net/core/dev.c 的 net_dev_init 函数:
|
|
backlog NAPI 变量和设备驱动 NAPI 变量的不同之处在于,它的 weight 是可以调节的,而设备驱动是 hardcode 64。
process_backlog
process_backlog 是一个循环,它会一直运行直至 weight 用完,或者 backlog 里没有数据了。
backlog queue 里的数据取出来,传递给 __netif_receive_skb。这个函数做的事情和 RPS 关闭的情况下做的事情一样。即,__netif_receive_skb 做一些 bookkeeping 工作,然后调用 __netif_receive_skb_core 将数据发送给更上面的协议层。
process_backlog 和 NAPI 之间遵循的合约,和驱动和 NAPI 之间的合约相同:
NAPI is disabled if the total weight will not be used. The poller is restarted with the call to ____napi_schedule from enqueue_to_backlog as described above.
函数返回接收完成的数据帧数量(在代码中是变量 work),net_rx_action将会从 budget(通过 net.core.netdev_budget 可以调整)里减去这个值。
__netif_receive_skb_core
__netif_receive_skb_core 完成将数据送到协议栈这一繁重工作(the heavy lifting of delivering the data)。在此之前,它会先检查是否插入了 packet tap(探测点),这些 tap 是抓包用的。例如,AF_PACKET 地址族就可以插入这些抓包指令, 一般通过 libpcap 库。
处理 tap
如果存在抓包点(tap),数据就会先到抓包点,然后才到协议层。
如果有 packet tap(通常通过 libpcap),packet 会送到那里。
|
|
packet 如何经过 pcap 可以阅读 net/packet/af_packet.c。
送到网络层
处理完 taps 之后,__netif_receive_skb_core 将数据发送到协议层。它会从数据包中取出协议信息,然后遍历注册在这个协议上的回调函数列表。可以看 __netif_receive_skb_core 函数,net/core/dev.c:
|
|
总结
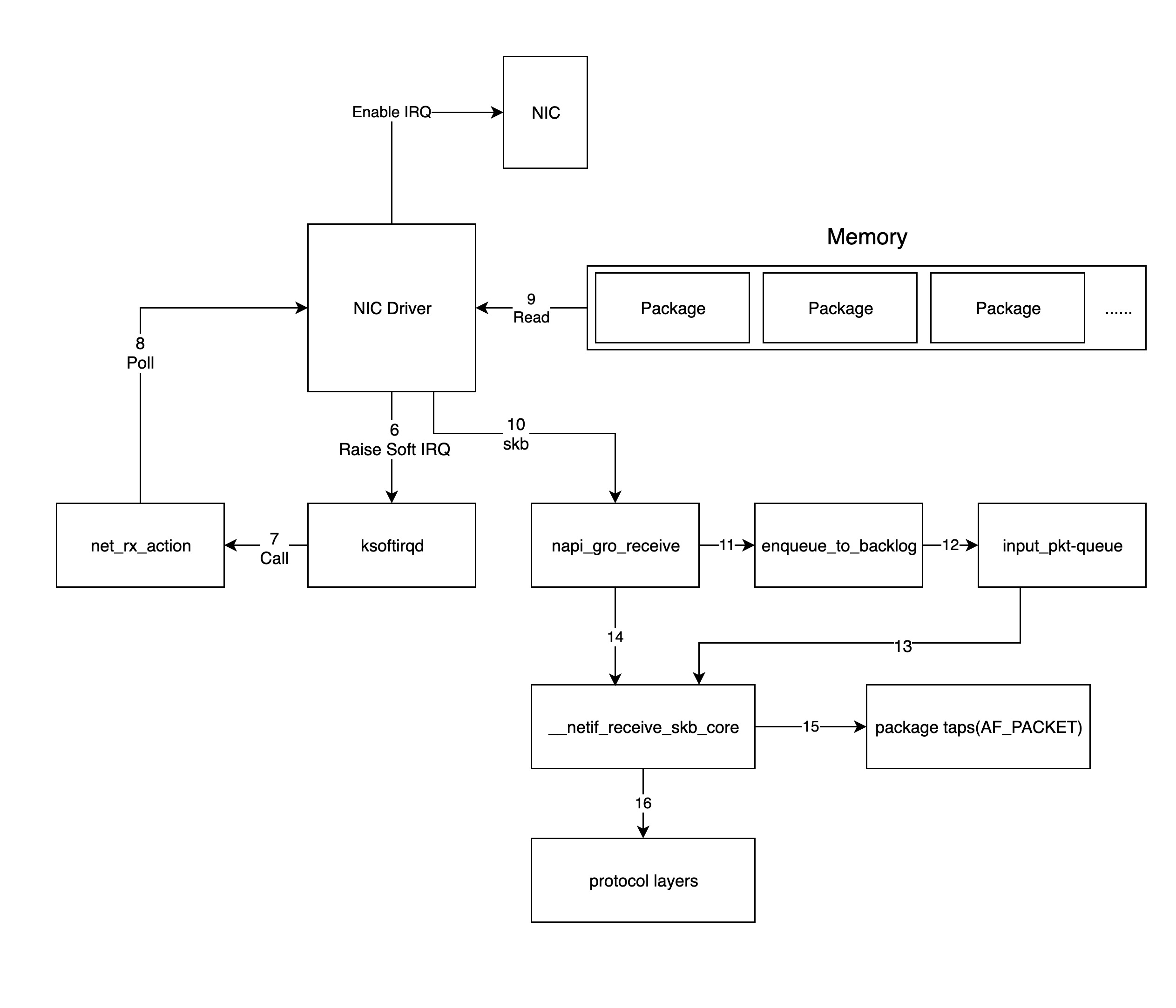
- 对于第 6 步中驱动发出的软中断,内核中的
ksoftirqd进程会调用网络模块的相应软中断所对应的处理函数,这里其实就是调用net_rx_action函数。 - 接下来
net_rx_action调用网卡驱动里的poll函数来一个个地处理数据包。 - 而
poll函数会让驱动会读取网卡写到内存中的数据包。事实上,内存中数据包的格式只有驱动知道。 - 驱动程序将内存中的数据包转换成内核网络模块能识别的
skb(socket buffer)格式,然后调用napi_gro_receive函数 napi_gro_receive会处理 GRO 相关的内容,也就是将可以合并的数据包进行合并,这样就只需要调用一次协议栈。然后判断是否开启了 RPS,如果开启了,将会调用enqueue_to_backlog。enqueue_to_backlog函数会将数据包放入input_pkt_queue结构体中,然后返回。 > Note: 如果input_pkt_queue满了的话,该数据包将会被丢弃,这个 queue 的大小可以通过net.core.netdev_max_backlog来配置- 接下来 CPU 会在软中断上下文中处理自己
input_pkt_queue里的网络数据(调用__netif_receive_skb_core函数) - 如果没开启 RPS,
napi_gro_receive会直接调用__netif_receive_skb_core函数。 - 紧接着 CPU 会根据是不是有
AF_PACKET类型的 socket(原始套接字),如果有的话,拷贝一份数据给它(tcpdump抓包就是抓的这里的包)。 - 将数据包交给内核协议栈处理。
- 当内存中的所有数据包被处理完成后(
poll函数执行完成),重新启用网卡的硬中断,这样下次网卡再收到数据的时候就会通知 CPU。
网络层
链路层与网络层接口
上面的 ptype_base 是一个 hash table,定义在 net/core/dev.c 中:
struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly;
每种协议在上面的 hash table 的一个 slot 里,添加一个过滤器到列表里。这个列表的头用如下函数获取:
|
|
添加的时候用 dev_add_pack 这个函数。这就是协议层如何注册自身,用于处理相应协议的网络数据的。
packet_type 定义如下所示:
|
|
deliver_skb 直接调用 packet_type 的 func 函数,对于 IP 层就是 ip_rcv:
|
|
协议层注册
|
|
如前所述,链路层通过 ip_rcv 将数据包 skb 从数据链路层传输到网络层,接下来我们将以 ip_rcv 为入口看网络层如何实现。
ip_rcv
可以看到,ip_rcv 函数非常简洁,它在 ip_rcv_core 做了一些校验工作之后,通过 netfilter 框架之后,将数据包传给 ip_rcv_finish。
|
|
我们看看 ip_rcv_core 的实现,主要对 IP 报文做校验:
- Internet Header Length (IHL) 必须要 > 5,IHL 表示有 IP 包 Header 多少个 32bit words
- IP version 必须是 4
- checksum 校验正确
- 包长度合理 skb-> len 必须要大于或等于 iph->total length
|
|
执行完 ip_rcv_core 之后,可以看到执行了 NF_HOOK,经过 Netfilter 之后执行 ip_rcv_finish
|
|
ip_rcv_finish
ip_route_input
dst_input
|
|
ip_forward
|
|
ip_local_deliver
|
|
ip_local_deliver_finish
这里通过 import->handler 来转交到网络层,如果是 UDP,那么就是 udp_rcv
|
|
总结
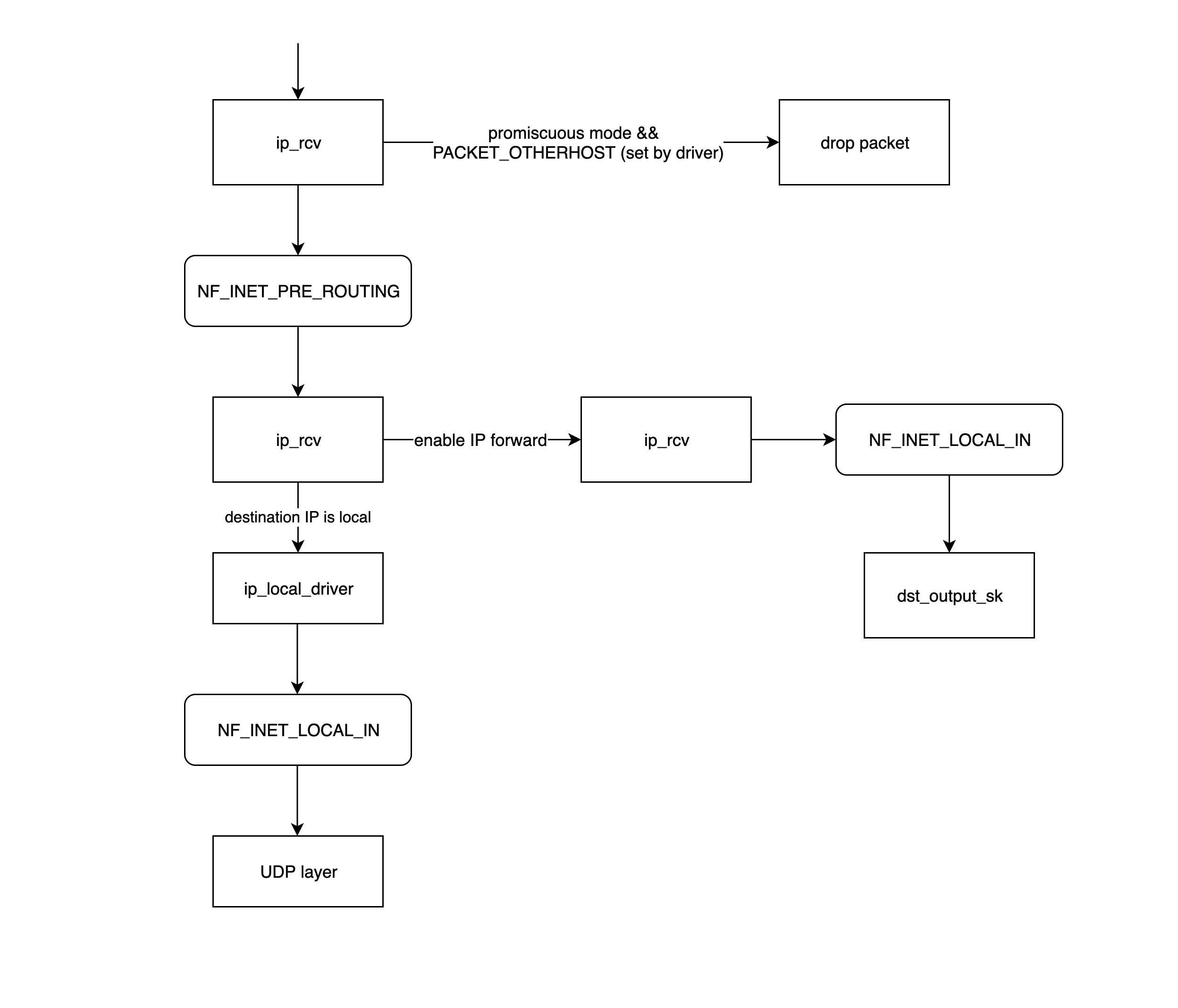
- ip_rcv:
ip_rcv函数是 IP 网络层处理模块的入口函数,该函数首先判断属否需要丢弃该数据包(目的 mac 地址不是当前网卡,并且网卡设置了混杂模式),如果需要进一步处理就然后调用注册在 netfilter 中的NF_INET_PRE_ROUTING这条链上的处理函数。 - NF_INET_PRE_ROUTING: netfilter 放在协议栈中的钩子函数,可以通过 iptables 来注入一些数据包处理函数,用来修改或者丢弃数据包,如果数据包没被丢弃,将继续往下走。 >
NF_INET_PRE_ROUTING等 netfilter 链上的处理逻辑可以通 iptables 来设置,详情请移步: https://morven.life/notes/the_knowledge_of_iptables/ - routing: 进行路由处理,如果是目的 IP 不是本地 IP,且没有开启
ip forward功能,那么数据包将被丢弃,如果开启了ip forward功能,那将进入ip_forward函数。 - ip_forward: 该函数会先调用
netfilter注册的NF_INET_FORWARD链上的相关函数,如果数据包没有被丢弃,那么将继续往后调用dst_output_sk函数。 - dst_output_sk: 该函数会调用 IP 网络层的相应函数将该数据包发送出去,这一步将会在下一章节发送数据包中详细介绍。
- ip_local_deliver: 如果上面路由处理发现发现目的 IP 是本地 IP,那么将会调用
ip_local_deliver函数,该函数先调用NF_INET_LOCAL_IN链上的相关函数,如果通过,数据包将会向下发送到 UDP 层。
传输层
网络层与传输层接口
|
|
|
|
|
|
udp_rcv
__udp4_lib_rcv
udp_queue_rcv_skb
Sk_rcvqueues_full
总结
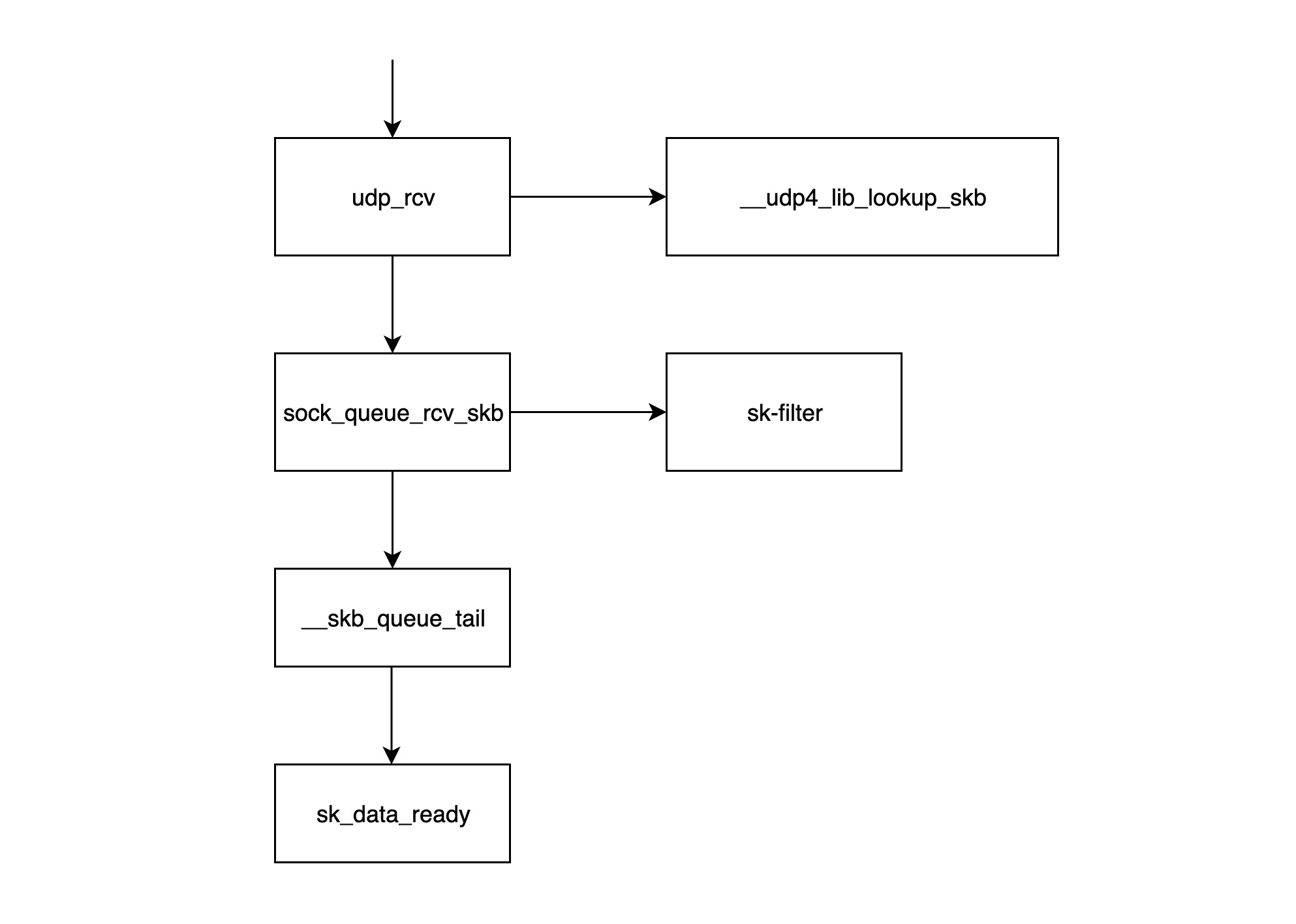
- udp_rcv: 该函数是 UDP 处理层模块的入口函数,它首先调用
__udp4_lib_lookup_skb函数,根据目的 IP 和端口找对应的socket,如果没有找到相应的socket,那么该数据包将会被丢弃,否则继续。 - sock_queue_rcv_skb: 该函数一是负责检查这个 socket 的 receive buffer 是不是满了,如果满了的话就丢弃该数据包;二是调用
sk_filter看这个包是否是满足条件的包,如果当前 socket 上设置了 filter,且该包不满足条件的话,这个数据包也将被丢弃。 - __skb_queue_tail: 该函数将数据包放入 socket 接收队列的末尾。
- sk_data_ready: 通知 socket 数据包已经准备好。
- 调用完 sk_data_ready 之后,一个数据包处理完成,等待应用层程序来读取。
Note: 上面所述的所有执行过程都在软中断的上下文中执行。
数据包的发送过程
传输层
总结
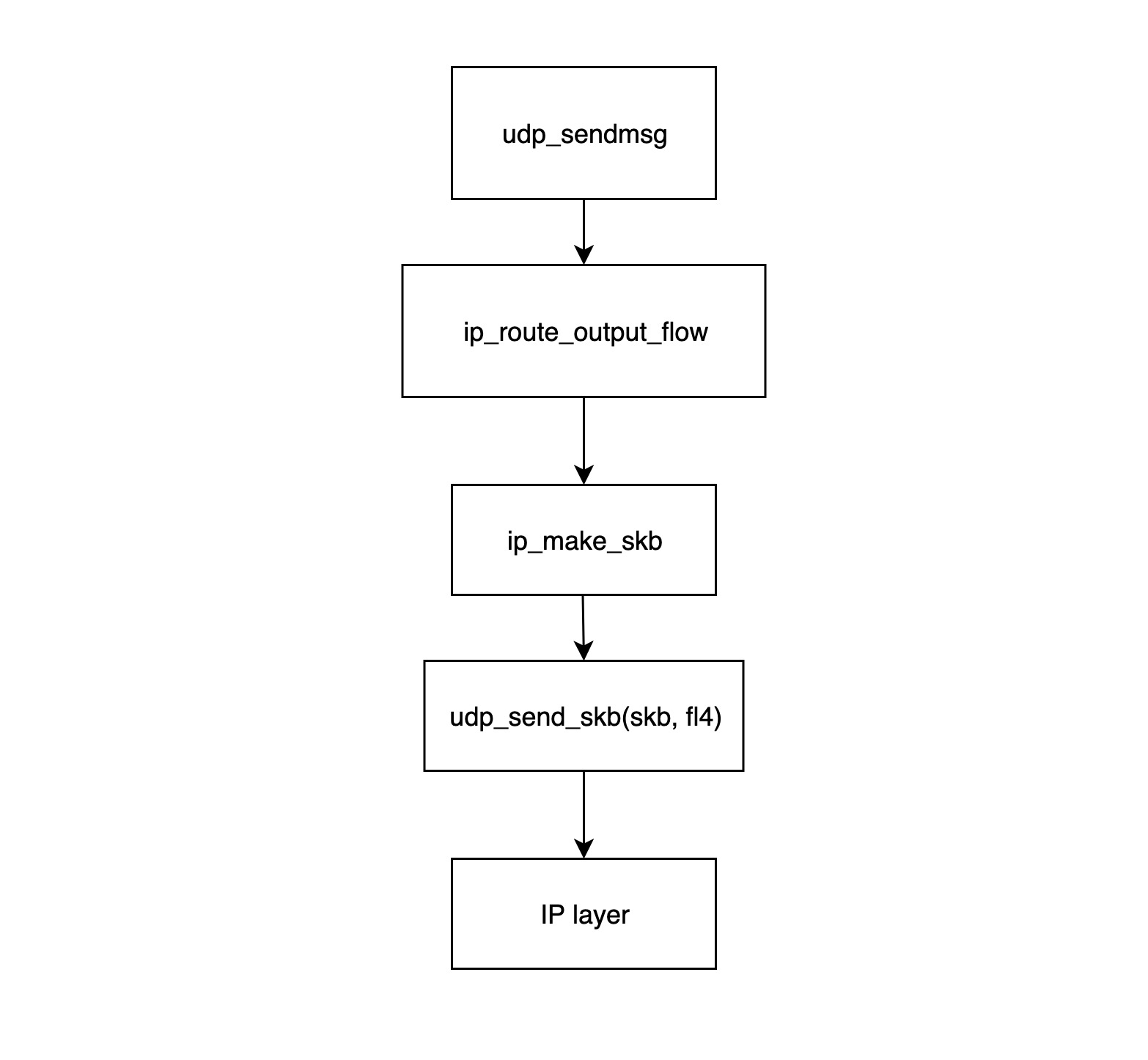
- udp_sendmsg: 该函数是 UDP 传输层模块发送数据包的入口。该函数中先调用
ip_route_output_flow获取路由信息(主要包括源 IP 和网卡),然后调用ip_make_skb构造 skb 结构体,最后将网卡的信息和该 skb 关联。 - ip_route_output_flow: 该函数主要处理路由信息,它会根据路由表和目的 IP,找到这个数据包应该从哪个设备发送出去,如果该 socket 没有绑定源 IP,该函数还会根据路由表找到一个最合适的源 IP 给它。 如果该 socket 已经绑定了源 IP,但根据路由表,从这个源 IP 对应的网卡没法到达目的地址,则该包会被丢弃,于是数据发送失败将返回错误。该函数最后会将找到的设备和源 IP 塞进 flowi4 结构体并返回给
udp_sendmsg。 - ip_make_skb: 该函数的功能是构造 skb 包,构造好的 skb 包里面已经分配了 IP 包头(包括源 IP 信息),同时该函数会调用
__ip_append_dat,如果需要分片的话,会在__ip_append_data函数中进行分片,同时还会在该函数中检查 socket 的 send buffer 是否已经用光,如果被用光的话,返回 ENOBUFS。 - udp_send_skb(skb, fl4): 该函数主要是往 skb 里面填充 UDP 的包头,同时处理 checksum,然后交给 IP 网络层层的相应函数。
网络层
总结
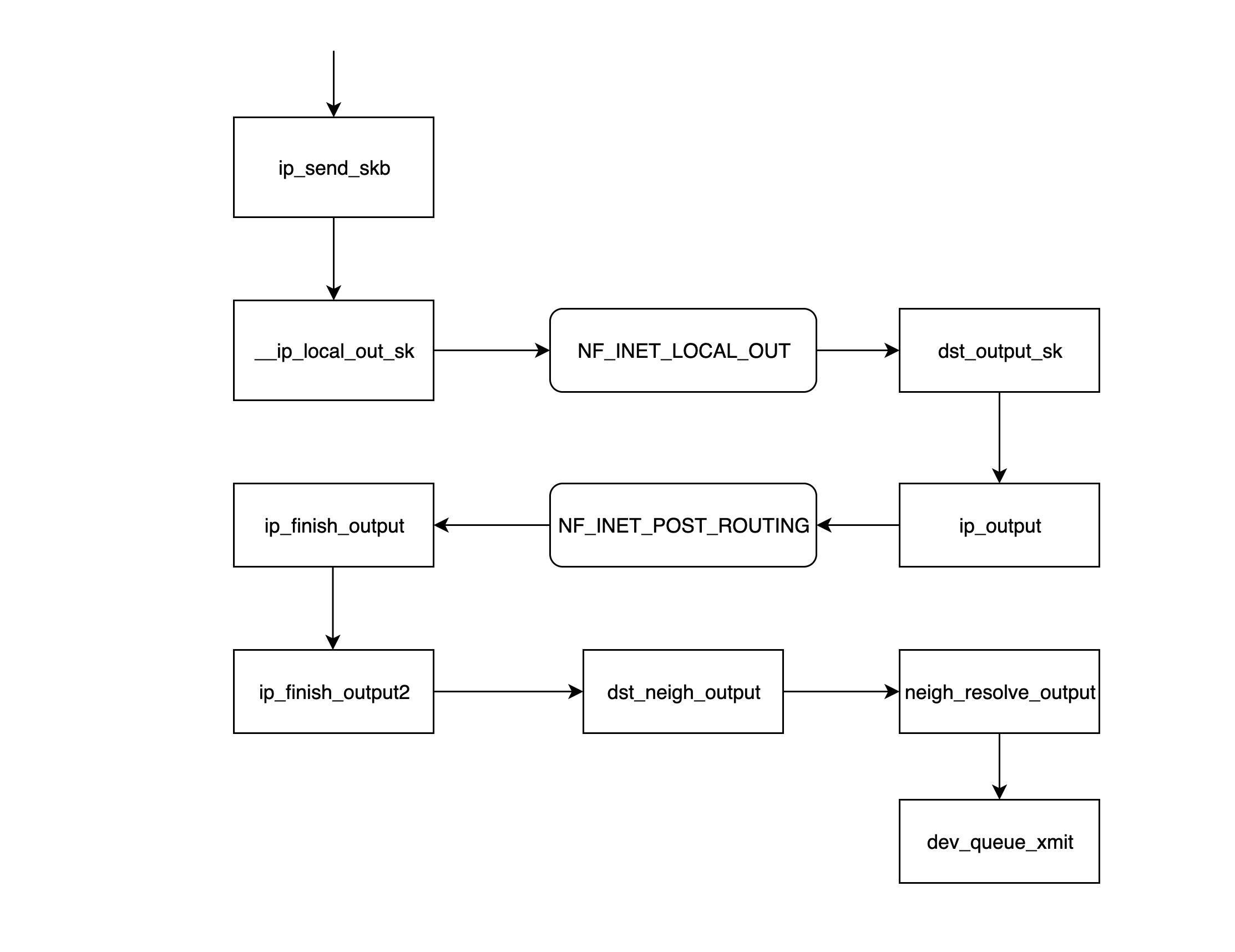
- ip_send_skb: IP 网络层模块发送数据包的入口,该函数主要是调用后面的一些列函数。
- __ip_local_out_sk: 用来设置 IP 报文头的长度和 checksum,然后调用下面 netfilter 的钩子链
NF_INET_LOCAL_OUT。 - NF_INET_LOCAL_OUT: netfilter 的钩子函数,可以通过 iptables 来配置处理函数链;如果该数据包没被丢弃,则继续往下走。
- dst_output_sk: 该函数根据 skb 里面的信息,调用相应的 output 函数
ip_output。 - ip_output: 将上一层
udp_sendmsg得到的网卡信息写入 skb,然后调用NF_INET_POST_ROUTING的钩子链。 - NF_INET_POST_ROUTING: 在这一步主要在配置了 SNAT,从而导致该 skb 的路由信息发生变化。
- ip_finish_output: 这里会判断经过了上一步后,路由信息是否发生变化,如果发生变化的话,需要重新调用
dst_output_sk(重新调用这个函数时,可能就不会再走到ip_output,而是走到被 netfilter 指定的 output 函数里,这里有可能是xfrm4_transport_output),否则接着往下走。 - ip_finish_output2: 根据目的 IP 到路由表里面找到下一跳(nexthop)的地址,然后调用
__ipv4_neigh_lookup_noref去 arp 表里面找下一跳的 neigh 信息,没找到的话会调用__neigh_create构造一个空的 neigh 结构体。 - dst_neigh_output: 该函数调用
neigh_resolve_output获取 neigh 信息,并将 neigh 信息里面的 mac 地址填到 skb 中,然后调用dev_queue_xmit发送数据包。 - neigh_resolve_output: 该函数里面会发送 arp 请求,得到下一跳的 mac 地址,然后将 mac 地址填到 skb 中并调用
dev_queue_xmit。
链路层
总结
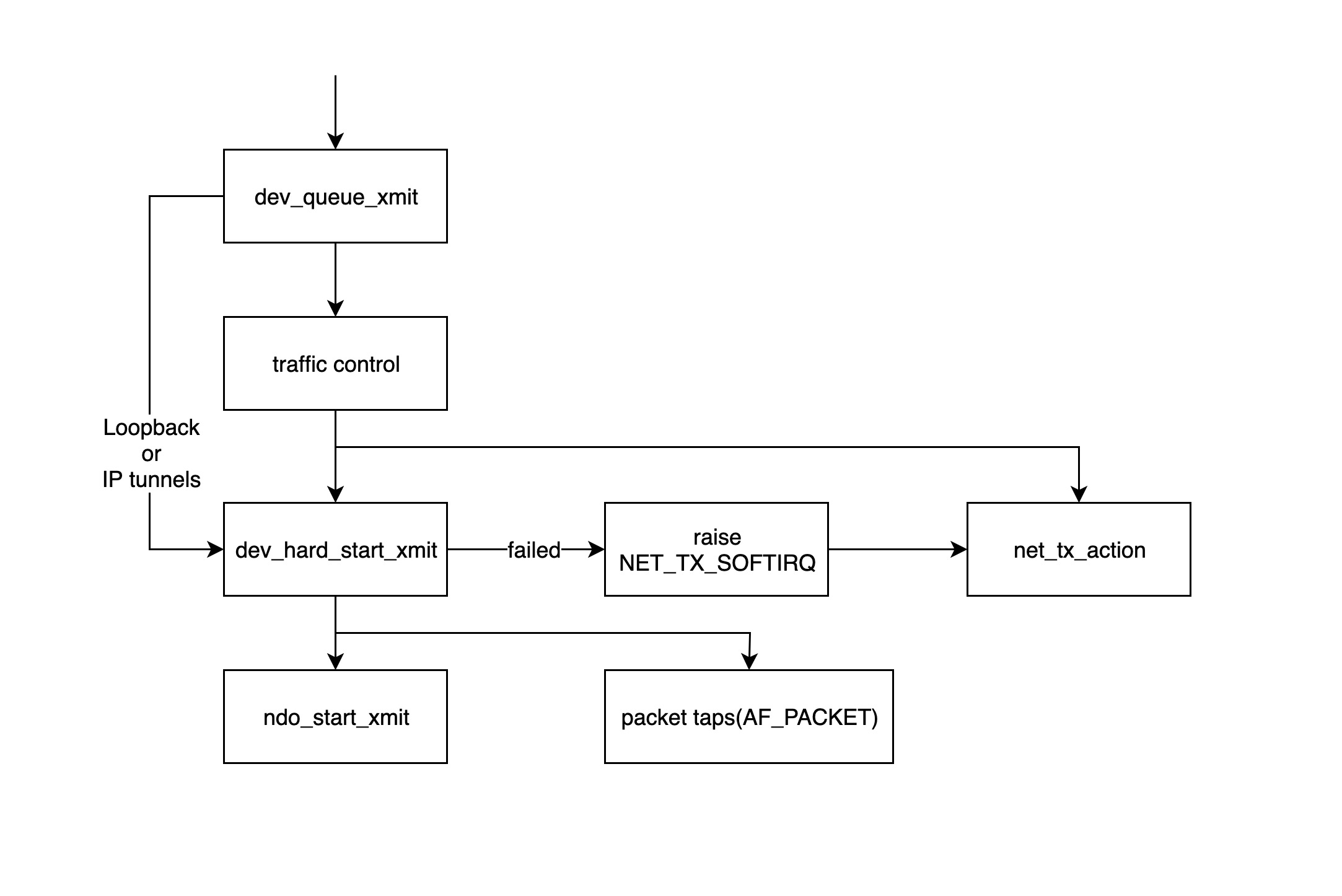
- dev_queue_xmit: 内核模块开始处理发送数据包的入口函数,该函数会先获取设备对应的 qdisc,如果没有的话(如 loopback 或者 IP tunnels),就直接调用
dev_hard_start_xmit,否则数据包将经过traffic control模块进行处理。 - traffic control:该模块主要对数据包进行过滤和排序,如果队列满了的话,数据包会被丢掉,详情请参考: http://tldp.org/HOWTO/Traffic-Control-HOWTO/intro.html
- dev_hard_start_xmit: 该函数先拷贝一份 skb 给“packet taps”(tcpdump 的数据就从来自于此),然后调用
ndo_start_xmit函数。如果dev_hard_start_xmit返回错误的话,调用它的函数会把 skb 放到一个地方,然后抛出软中断NET_TX_SOFTIRQ,然后交给软中断处理程序net_tx_action稍后重试。 - ndo_start_xmit:该函数绑定到具体驱动发送数据的处理函数。
设备驱动层
Note:
ndo_start_xmit会指向具体网卡驱动的发送数据包的函数,这一步之后,数据包发送任务就交给网络设备驱动了,不同的网络设备驱动有不同的处理方式,但是大致流程基本一致:
- 将 skb 放入网卡自己的发送队列
- 通知网卡发送数据包
- 网卡发送完成后发送中断给 CPU
- 收到中断后进行 skb 的清理工作
参考资料
- TCP/IP Architecture, Design and Implementation in Linux:Chapter 18
- Intel 82599 10G Data Sheet
- Monitoring and Tuning the Linux Networking Stack: Receiving Data
- Monitoring and Tuning the Linux Networking Stack: Sending Data
-
No backlinks found.