NVIDIA GPU MIG

MIG,也就是 Multi-Instance GPU 是 NVIDIA 在 NVIDIA GTC 2020 发布的最新 Ampere 架构的 NVIDIA A100 GPU 推出的新特性。当配置为 MIG 运行状态时,A100 可以通过分出最多 7 个核心来帮助供应商提高 GPU 服务器的利用率,无需额外投入。MIG 提供了一种多用户使用隔离的 GPU 资源、提高 GPU 资源使用率的新的方式,特别适合于云服务提供商的多租户场景,保证一个租户的运行不干扰另一个租户。本文将介绍 MIG 的新特性和使用方法,以及在容器和 k8s 中使用 MIG 的方案。
MIG 技术简介
随着深度学习的广泛应用,使用 GPU 加速训练和推理越来越普遍。然而,高昂的 GPU 价格在这里成为了不可忽视的成本,有时候单个 GPU 并没有得到充分的利用,在多租户之间如何能够共享 GPU 并且互不干扰成为了一个重要课题,尤其是在云服务环境使用 GPU 的场景下。针对这个问题,有很多种解决方案,分别是软件级虚拟化 GPU 和硬件级虚拟化 GPU,而 MIG 即是硬件级虚拟化 GPU 的一种方式:
Data center managers aim to keep resource utilization high, so an ideal data center accelerator doesn’t just go big- it also efficiently accelerates many smaller workloads.
MIG 主要技术特点
- 每个 GI 独立的 SM,完全隔离的显存(包括隔离的显存,L2cache,独立的 DMA 控制器等),从而可以保证每个 GI 的 QoS
- 支持虚拟机,容器,进程层面的使用
首先看一下传统 GPU 的内部架构,MIG 的目的是使虚拟的每个 GPU 实例都拥有上面类似的架构。
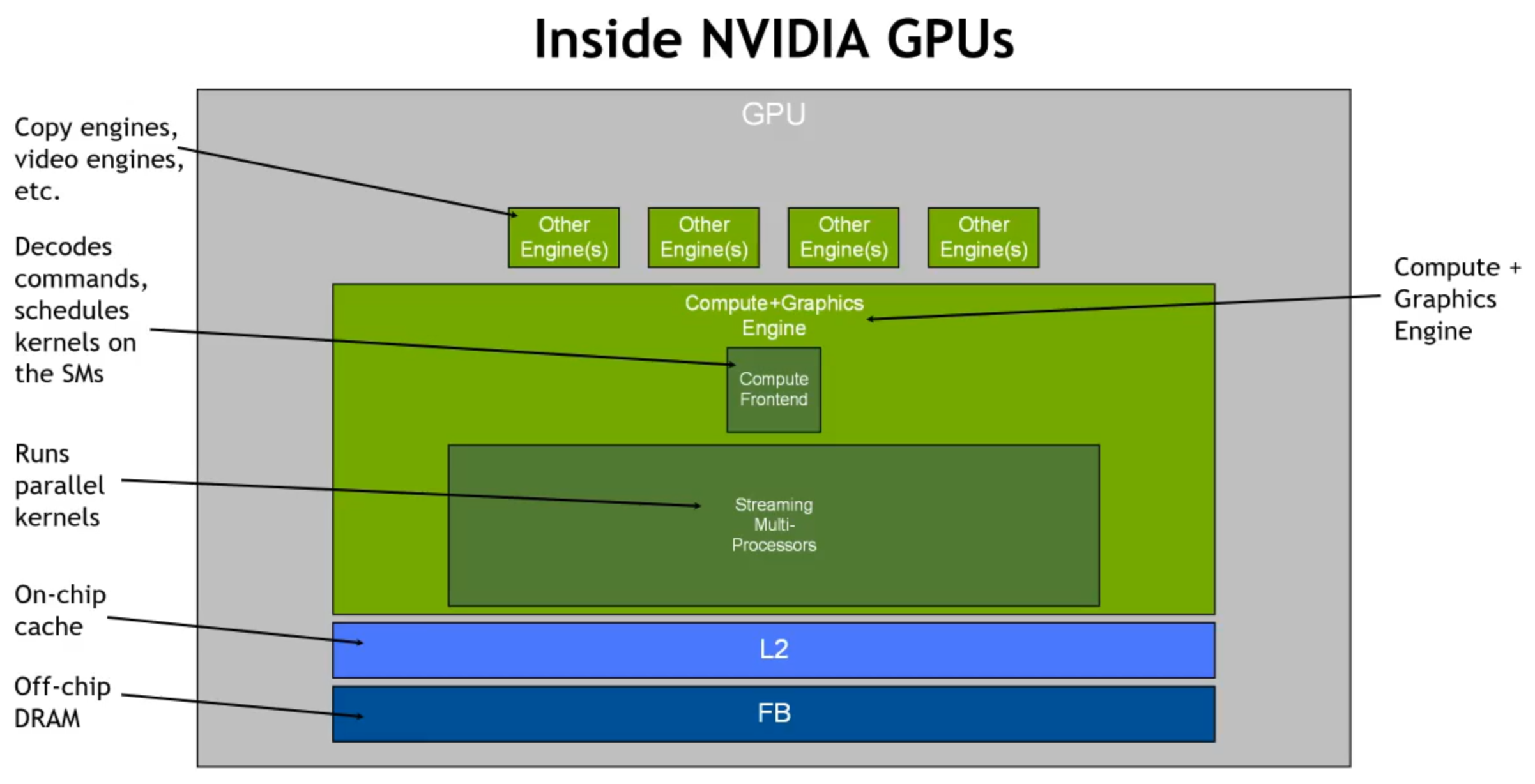
基本概念
MIG 对资源的划分可以分为两级,分别是 GPU Instance、Compute Instance
GPU Instance
MIG 功能可以将单个 GPU 划分为多个 GPU 分区,称为 GPU Insance。创建 GPU 实例可以认为是将一个大 GPU 拆分为多个较小的 GPU,每个 GPU 实例都具有专用的计算和内存资源。
每个 GPU 实例的行为就像一个较小的,功能齐全的独立 GPU,其中包括:
- 预定义数量的 GPC
- SMs
- L2 Cache
- Frame buffer
注意:在 MIG 操作模式下,每个 GPU 实例中的单个 GPC 启用了 7 个 TPC(14 个 SM),这使所有 GPU 切片具有相同的一致计算性能。
-
GPU Engine:一个 GPU Engine 是 GPU 中执行工作的组件,常用的 GPU Engine 如下,每个 Engine 都能够被独立地调度和为不同 GPU Context 执行工作
- Compute/Graphics engine that executes the compute instructions
- the copy engine (CE) that is responsible for performing DMAs
- NVDEC for video decoding
- NVENC for encoding
-
GPU Memory Slice:一个 GPU Memory Slice 是 A100 GPU Memory 的一个最小片段,包括对应的
memory controllers和cache,粗略来说一个 GPU Memory Slice 大致是总的 GPU Memory 资源的 1/8,包括 memory 的 capacity 和 bandwidth。 -
GPU SM Slice:一个 GPU SM Slice 是 A100 GPU SMs 的一个最小片段,粗略来说一个 GPU SM Slice 大致是总的 GPU SM 资源的 1/7
-
GPU Slice:一个 GPU Slice 是 A100 GPU 中集合一个
GPU Memory Slice和 一个GPU SM Slice的最小片段 -
GPU Instance:一个 GPU Instance 是 GPU Slices 和 GPU Engines (DMAs, NVDECs, etc.)的结合
Compute Instance
一个 GPU Instance 可以被划分为多个 Compute Instance,多个 Compute Instance 之间共享 Memory 和 Engine,它包含了原来 GPU Instance 里面 GPU SM slices 和 GPU Engines 的一个子集(DMAs, NVDECs, etc.):
- 默认情况下,将在每个 GPU 实例下创建一个 Compute Instances,从而公开 GPU 实例中可用的所有 GPU 计算资源。
- 可以将 GPU 实例细分为多个较小的 Compute Instances,以进一步拆分其计算资源。
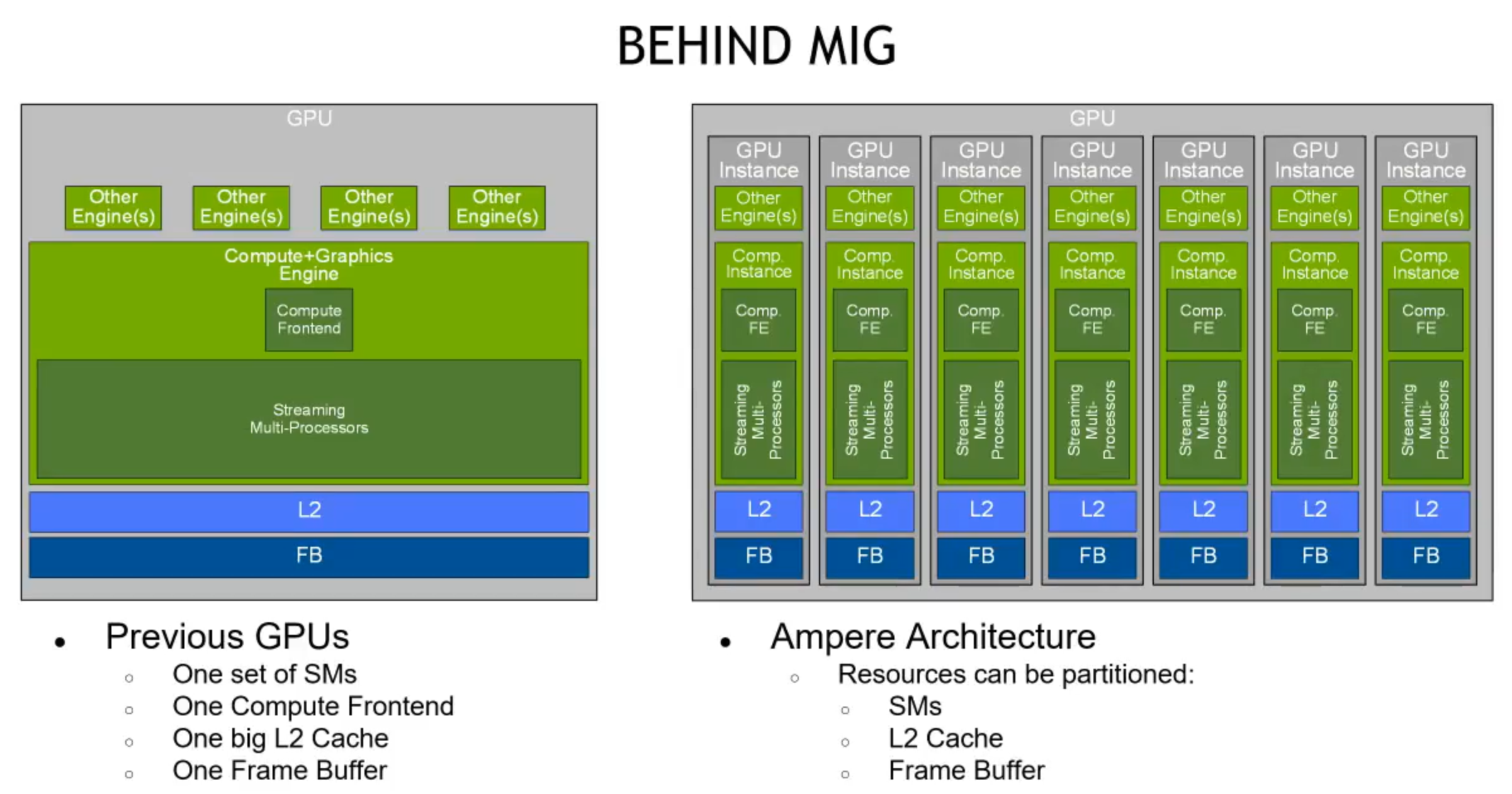
架构对比
pre-A100 GPU 每个用户独占 SM、Frame Buffer、L2 Cache。

A100 MIG 将 GPU 进行物理切割,每个虚拟 GPU instance 具有独立的 SM、L2 Cache、DRAM。
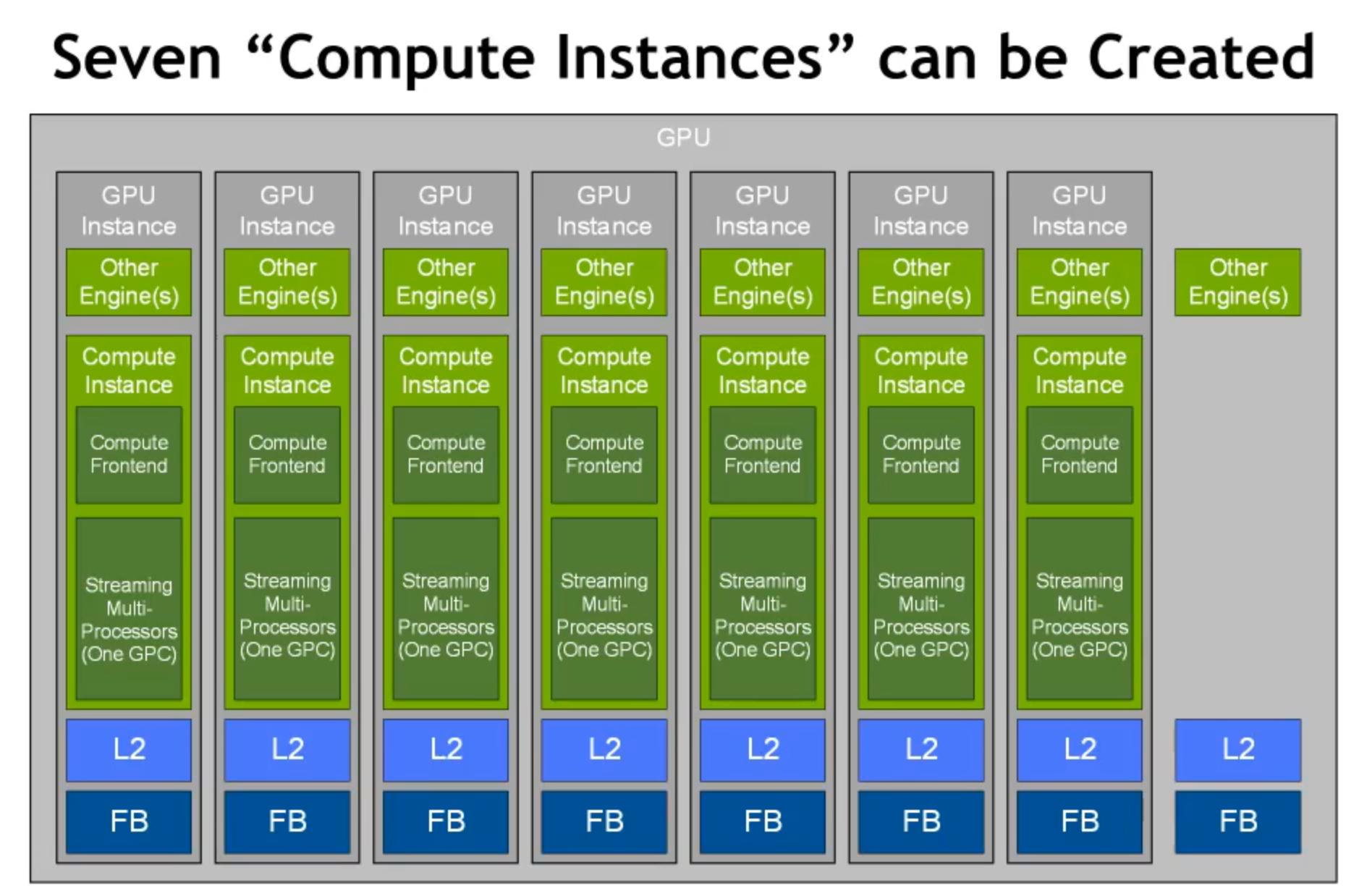
下面是 MIG 配置多个独立的 GPU Compute workloads。每个 GPC 分配固定的 CE 和 DEC。A100 中有 5 个 decoder。
当 1 个 GPU instance 中包含 2 个 Compute instance 时,2 个 Compute instance 共享 CE、DEC 和 L2、Frame Buffer。
- GPC:Graphics Processor Cluster
- TPC:Texture Processor Cluster
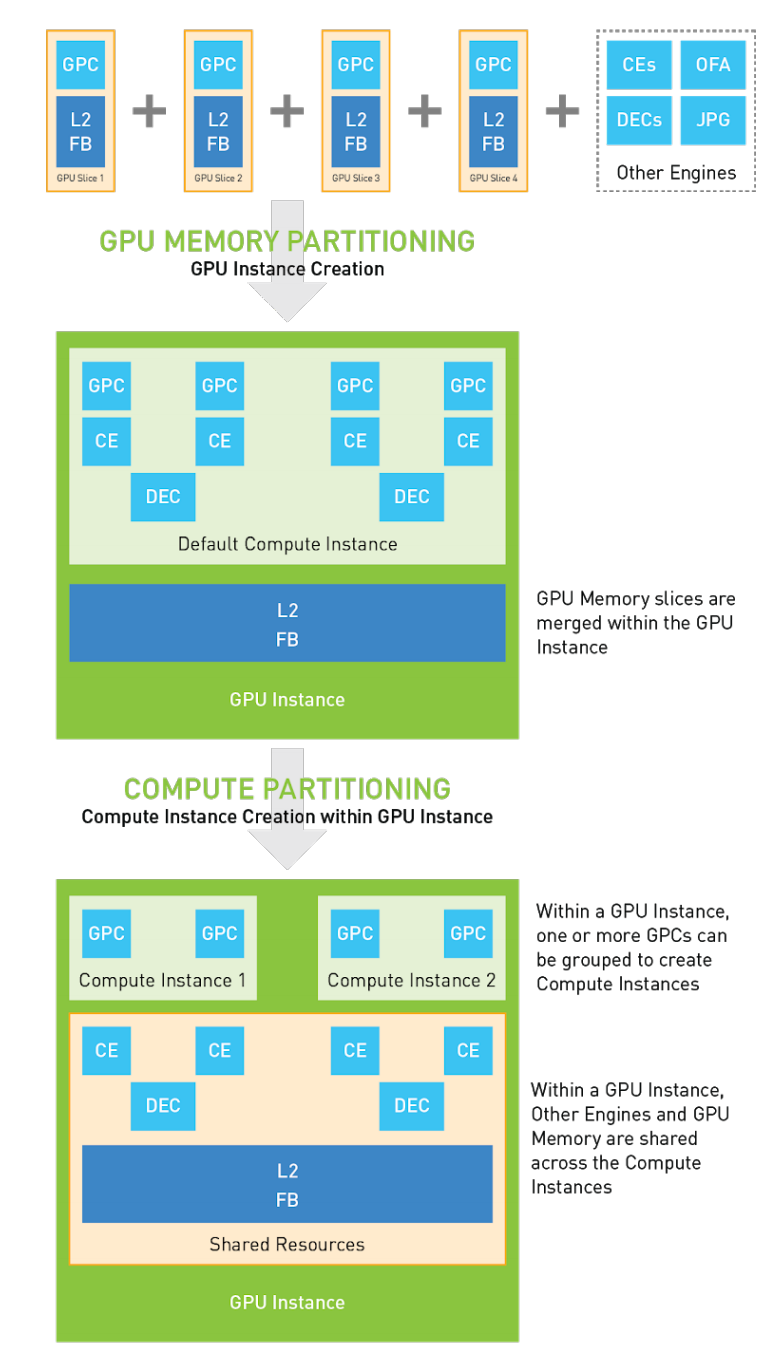
Compute instance 使多个上下文可以在 GPU 实例上同时运行。

MIG 隔离

和上一代 Volta MPS 技术的对比
MPS was designed for sharing the GPU among applications from a single user, but not for multi-user or multi-tenant use cases.
解决了 MPS 存在的 memory system resources were shared across all the applications 问题,同时继承了 Volta MPS 所有功能
| 对比项 | MPS | MIG |
|---|---|---|
| Partition Type | Logical | Physical |
| Max Partitions | 48 | 7 |
| SM Performance Isolation | Yes (by percentage, not partitioning) | Yes |
| Memory Protection | Yes | Yes |
| Memory Bandwidth QoS | No | Yes |
| Error Isolation | No | Yes |
| Cross-Partition Interop | IPC | Limited IPC |
| Reconfigure | Process Launch | When Idle |
GPU Partitioning
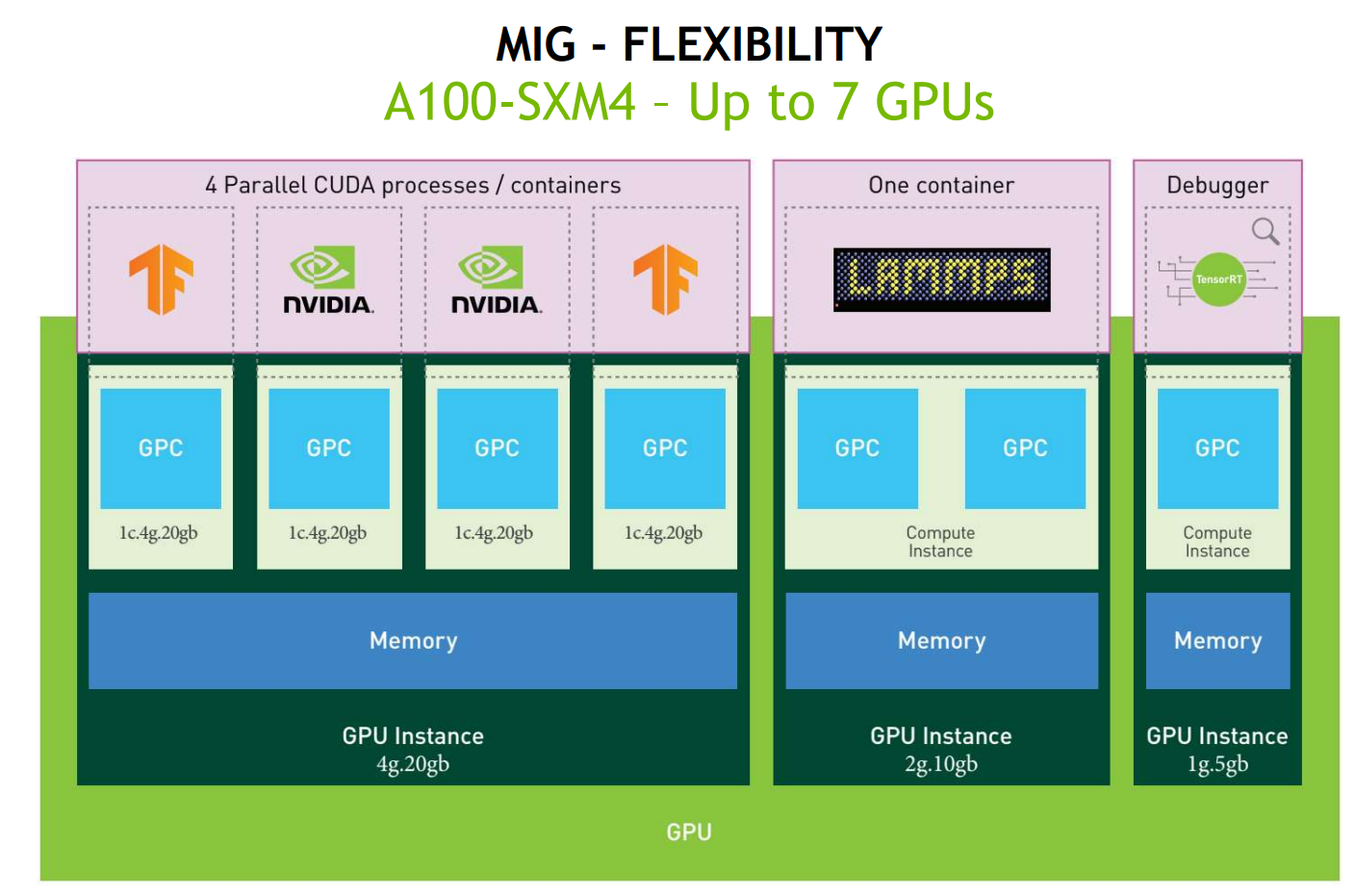
每个 GI 包括的资源不是随意定义的,NVIDIA 提供了 一系列的 GPU Instance Profiles,用户在创建 GI 时必须按照这个 Profile 来切割。我们知道,A100 总共有 8 个 GPU Memory Slice 和 7 个 SM Slice,那么切分总共有 5 种 Profile:
| Profile Name | Fraction of Memory | Fraction of SMs | Hardware Units | Number of Instances Available |
|---|---|---|---|---|
| MIG 1g.5gb | 1/8 | 1/7 | 0 NVDECs | 7 |
| MIG 2g.10gb | 2/8 | 2/7 | 1 NVDECs | 3 |
| MIG 3g.20gb | 4/8 | 3/7 | 2 NVDECs | 2 |
| MIG 4g.20gb | 4/8 | 4/7 | 2 NVDECs | 1 |
| MIG 7g.40gb | Full | 7/7 | 5 NVDECs | 1 |
注意:这里对于 A100-SXM4-40GB 总的 Memory 大小是 40GB,所以最小单位是 1g.5gb,如果对于 A100-SXM4-80GB,则最小单位是 1g.10gb。
也就是说,这几种 Profile 确定了 A100 GPU 可以被切分的方式,如下图,所有可以切分的方式只是下图从左到右选择不同的 Profile,并且两个 Profile 上下不重叠。唯一的例外是,现在 NVIDIA 不支持 (4 memory, 4 compute) 和 (4 memory, 3 compute) 的组合:

下图就是组合的一种方式:A100 GPU 被切割成了 3 个 GPU Instance,分别的大小是
- 4 memory,4 compute
- 2 memory,2 compute
- 1 memory,1 compute

下图也是组合的一种可能:

前面提到, 硬件上 NVIDIA 不支持 (4 memory, 4 compute) 和 (4 memory, 3 compute) 的组合,但是支持两个 (4 memory, 3 compute) 的组合,这里左边的一个 (4 memory, 3 compute) 是将 (4 memory, 4 compute) 示例化为一个 (4 memory, 3 compute)。如下图就将 A100 切分成两个 GPU Instance,每个 GPU Instance 都有 (4 memory, 3 compute)

或者切分成 3 个 GPU Instance:

也可以切分成下面这种 4 个 GPU Instance:

总的来说,一共有 18 种切分方法:

注意,下图中的两种切分并不相同,因为每个切分的 Instance 的 physical layout 也很重要:

MIG 技术使用
具体到 A100 卡,实际实现有两个型号,分别是
- GA100 Full GPU with 128 SMs
- A100 Tensor Core GPU with 108 SMs
本次调研中使用的卡是 108 SM 版本
驱动安装
|
|
|
|
开启 MIG 支持
查询是否开启 MIG
|
|
对于指定卡开启 mig,只有在卡空闲时才能更改 mig enable 设置
|
|
If you are using MIG inside a VM with GPU passthrough, then you may need to reboot the VM to allow the GPU to be in MIG mode as in some cases, GPU reset is not allowed via the hypervisor for security reasons. This can be seen in the following example:
重启之后
|
|
查询可分配 GI 信息
|
|
查询 GI placements
|
|
创建 GPU Instances
|
|
查询 GPU Instance
|
|
创建 Compute Instance
创建 CI 前,首先需要查询对应的 GI 支持 Profile 列表,可以发现上文创建的 ID 为 2 的 GI 可以进一步分为 3 种类型的 CI
|
|
然后进一步将 ID 为 2 的 GI 划分为两个 CI,Profile 分别是 1c.3g.20gb,2c.3g.20gb,具体命令如下
|
|
查询 Compute Instance
|
|
执行 nvidia-smi 也可以看到如下输出
|
|
执行 nvidia-smi -L 可以列出每个设备的 UUID,供后续计算时使用
|
|
删除 CPU Instance
可以使用如下命令删除 gi 实例 1 上的 ci 实例 0
|
|
使用 MIG
Bare-Metal
暂时没有拿到 bare metal 的 A100 机器,TODO
Container
前置条件
- 安装 Docker
- 安装 NVIDIA Container Toolkit:
- Nvidia-docker2 版本推荐在 v2.5.0 以上
运行容器
|
|
怀疑是 NVIDIA Docker Toolkit 版本太老
|
|
安装新版本的 NVIDIA Docker Toolkit
|
|
环境配置好后,即可通过 docker 运行容器使用 GPU:
|
|
Kubernetes
前置依赖
- NVIDIA R450+ datacenter driver: 450.80.02+
- NVIDIA Container Toolkit (nvidia-docker2): v2.5.0+
- NVIDIA k8s-device-plugin: v0.7.0+
- NVIDIA gpu-feature-discovery: v0.2.0+
None
确认 Node 上的 MIG 特性开启,此时没有创建任何 GI:
|
|
启动 Device Plugin,此时 mig-strategy 是 none:
|
|
可以看到 Node 上可以用 nvidia.com/gpu 资源数目:
|
|
部署 Pod:
|
|
Single
确认 Node 上的 MIG 特性开启后,创建大小相同的 7 个 GI,每个 GI 对应着一个 CI:
|
|
部署 Device Plugin:
|
|
这时候可以看到 Node 上面的标记 nvidia.com/gpu 变成了 7 个:
|
|
部署 discovery
|
|
运行 Pod 申请 GPU:
|
|
Mixed
确认 Node 上的 MIG 特性开启后,创建不同大小的 3 个 GI,每个 GI 对应着一个 CI:
|
|
启动 Device Plugin :
|
|
启动 Device Plugin 之后,可以看到 Node 上的有 MIG 的 resource type:
|
|
这时候启动 gpu-feature-discovery,启动策略是 mixed:
|
|
这时候查看 Node 的 label,可以看到 MIG 相关的 label 已经打上 ?
|
|
使用 kubectl 启动 Pod:
|
|
当前 TKE 的问题
- 驱动版本 和 Nvidia-container-toolkit 版本 较老,需要更新
|
|
- VM 中使用 MIG,开启 MIG 特性需要重启 VM
If you are using MIG inside a VM with GPU passthrough, then you may need to reboot the VM to allow the GPU to be in MIG mode as in some cases, GPU reset is not allowed via the hypervisor for security reasons. This can be seen in the following example:
|
|
划分 MIG 后的性能对比
整块卡的性能
| 测试项目 | 实测性能 | 官方标准性能 |
|---|---|---|
| FP32MAD | 19.436TF | 19.5 TF |
| FP64MAD | 9.690TF | 9.7 TF |
| int32mad | 19.446TF | - |
| int32add | 18.906TF | - |
| FP32GEMMTensor (矩阵大小满足最佳性能要求) | 158.426TF | 156 TF |
| FP32GEMMTensor (不满足最佳性能要求) | 68.054 TF | - |
| FP32GEMM | 19.047 TF | - |
备注
- GEMM 需要在 cuda 11.0 下重编,才能达到以上效果
- 满足最佳性能要求是的 GEMM 大小参数 9000 _ 6000 _ 6000
- 不满足最佳性能要求的 GEMM 大小参数 8997 _ 5998 _ 5998
MIG 卡的性能
为了测试各个 CI 和 GI 的性能,对 3g.20gb GI 进行进一步划分,分为 2c.3g.20gb, 1c.3g.20gb,另外两个 GI 不做进一步划分,直接在 GI 基础上创建 CI。
至此一块 GPU 卡被分为四个 CI 分别是
- MIG 1c.3g.20gb
- MIG 2c.3g.20gb
- MIG 2g.10gb
- MIG 1g.5gb
各 CI 串行执行
MIG 1c.3g.20gb
| 测试项目 | 实测性能(OPS) |
|---|---|
| FP32MAD | 2.523 T |
| FP64MAD | 1.261 T |
| INT32MAD | 2.524 T |
| INT32ADD | 2.455 T |
| FP32GEMMTensor (矩阵大小满足最佳性能要求) | 23.081 T |
| FP32GEMMTensor (不满足最佳性能要求) | 8.940 T |
| FP32GEMM | 2.476 T |
MIG 2c.3g.20gb
| 测试项目 | 实测性能(OPS) |
|---|---|
| FP32MAD | 5.046 T |
| FP64MAD | 2.521 T |
| INT32MAD | 5.049 T |
| INT32ADD | 4.908 T |
| FP32GEMMTensor (矩阵大小满足最佳性能要求) | 44.941 T |
| FP32GEMMTensor (不满足最佳性能要求) | 18.920 T |
| FP32GEMM | 4.909 T |
MIG 2g.10gb
| 测试项目 | 实测性能(OPS) |
|---|---|
| FP32MAD | 5.046 T |
| FP64MAD | 2.521 T |
| INT32MAD | 5.049 T |
| INT32ADD | 4.908 T |
| FP32GEMMTensor (矩阵大小满足最佳性能要求) | 40.151 T |
| FP32GEMMTensor (不满足最佳性能要求) | 17.514 T |
| FP32GEMM | 4.909 T |
MIG 1g.5gb
| 测试项目 | 实测性能(OPS) |
|---|---|
| FP32MAD | 2.523 T |
| FP64MAD | 1.261 T |
| INT32MAD | 2.524 T |
| INT32ADD | 2.454 T |
| FP32GEMMTensor (矩阵大小满足最佳性能要求) | 16.453 T |
| FP32GEMMTensor (不满足最佳性能要求) | 8.261 T |
| FP32GEMM | 2.476T |
备注
在串行执行 FP32MAD 任务时,1c.3g.20gb,1g.5gb 的测试任务时保持在 14.3%,2c.3g.20gb,2g.10gb 的测试任务时保持在 28.6%附近
各 CI 并行执行
统一执行 FP32MAD
| 测试项目 | 实测性能(OPS) |
|---|---|
| 1c.3g.20gb | 2.523 T |
| 2c.3g.20gb | 5.044 T |
| 2g.10gb | 5.046 T |
| 1g.5gb | 2.523 T |
统一执行 FP32GEMMTensor
| 测试项目 | 实测性能(OPS) |
|---|---|
| 1c.3g.20gb | 20.450 T |
| 2c.3g.20gb | 41.194 T |
| 2g.10gb | 39.773 T |
| 1g.5gb | 16.336 T |
备注
在并行执行 FP32MAD 任务时,SmActivity,SmOccupancy,FP32Activity 三项监控指标保持在 85.7%附近
分别执行不同类型的计算
| 测试项目 | 实测性能(OPS) |
|---|---|
| 1c.3g.20gb FP32MAD | 2.523 T |
| 2c.3g.20gb FP64MAD | 2.521 T |
| 2g.10gb INT32MAD | 5.048 T |
| 1g.5gb INT32ADD | 2.454 T |
备注
在并行执行不同计算任务时,SmActivity,SmOccupancy,FP64Activity,FP32Activity 分别为 85.7%, 78.1%, 28.5%, 57.0%
根据测试结果,验证了 CI,GI 隔离的有效性,具体结论如下
- 对比各个 MIG 上任务串行执行,以及并行执行的性能数据,可以有效验证 CI,GI 隔离的有效性
- 划分 CI,GI 存在一定的性能损失,1g.5gb 上测得的性能并不等与整张卡的 1/7,从整张卡的维度来看,存在 10%的性能损失。考虑原因,A100 卡总共有 108 SMs,但是分为 7 个 MIG 实例后,每个 MIG 实例只有 14 个 SM 14*7 = 98 SMs,有 10 个 SM 将无法使用,这 10 个 SM 的浪费就是产生性能损失的源头。
- 对比 2c.3g.20gb 2g.10gb 可以发现在 2c.3g.20gb(一个 GI 上软隔离的 CI)Tensor 计算性能比 2c.3g.20gb(完全隔离的 GI)更好一些,同时对比所有 CI 同时执行 FP32GemmTensor,可以发现同一个 GI 上的 CI 同时执行 GEMM(相比 FP32MAD,有一定的显存读写)时,两个 CI 的计算性能比单独执行时会有所下降,更接近单独 GI 的性能。即说明 2c.3g.20gb 性能强于 2g.10gb,是由于 CI 隔离不完全导致的。
A100 卡可以为后续工作带来的价值
- 每个 MIG 实例的完整隔离,可以支持多种虚拟化场景,包括虚拟机,容器
- 最小实例的基础计算能力,大约为 T4 卡的三分之一,P4 卡的一半,计算能力适中,内存带宽 1,555 GB/s 相比于 P4 卡 192 GB/s,T4 320+ GB/s,带宽足够充裕,不会成为瓶颈
- 存在离线计算和在线推理使用同一种 GPU 的可能性,打通离线,在线两个 GPU 资源池
- T4 卡的具体性能指标 16G 显存,SM 40, 8 TensorCores/SM, 64 INT32Cores/SM, 64 FP32Cores/SM,
- A100 卡的具体性能指标 40G 显存,SM 108, 4 Third-generation Tensor Cores/SM, 64 FP32 CUDA Cores/SM,
参考资料
- NVIDIA Multi-Instance GPU User Guide
- NVIDIA Ampere Architecture WhitePaper
- Design Document: Challenges Supporting MIG in Kubernetes
- User Guide: MIG Support in Kubernetes
- Github Issue: k8s device plugin Supporting MIG
- PoC: Supporting MIG in Kubernetes
- Steps to Enable MIG Support in Kubernetes
- Install NVIDIA Container Toolkit Guide
- 深度了解 NVIDIA Ampere 架构
- NVIDIA GPU A100 Ampere 架构深度解析
- https://help.didiyun.com/hc/kb/article/1414838/
-
No backlinks found.