网络协议报文格式
报文格式
IP 报文格式
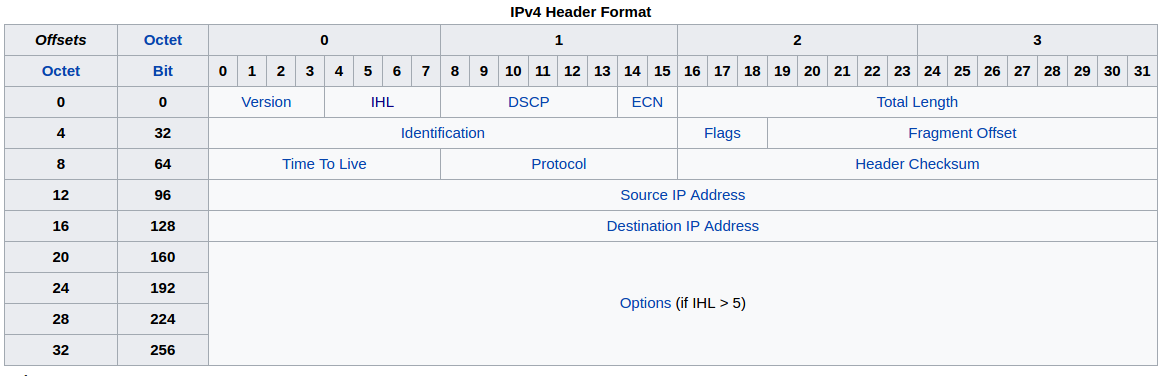
-
Version: 4 bit 指 IP 协议的版本,目前广泛使用的 IP 协议版本号为 4(IPv4)。
-
Internet Header Length(IHL): 4 bit 首部长度,单位是字(32 bit)。首部长度大小取值范围为 5-16。最小的长度为 5,也就是 20 Bytes。所以目前最常见的就是 IP 的第一个字节为 0x45。
-
Type of Service(ToS): 8 bit 服务类型。经过 RFC 2474 被定义为
Differentiated Services Code Point(DSCP),在实时数据流应用中,比如 VoIP 会用到这个部分 -
Total Length: 16 bit 总长度,代表
首部长度+数据长度,单位是字节。数据报的最大长度是$$ 2^{16}-1=65535 $$
。但是由于数据链路层的最大传递单元
MTU< 65535,所以当一个数据报封装成链路层的帧时,此数据报的总长度一定不能超过下面的数据链路层的 MTU 值,若超过就需要用到分片(Fragment Offset) -
Identification: 16 bit 标识。当数据报由于长度超过网络的 MTU 而必须分片时,这个标识字段的值就被复制到所有的数据报的标识字段中。相同的标识字段的值使分片后的各数据报片最后能正确地重装成为原来的数据报。
-
Flags: 3 bit
- bit 0: Reserved; must be zero
- bit 1: Don’t Fragment (DF),DF=1 时,表示不能分片。
- bit 2: More Fragments (MF),MF=1 时,表示后面还有分片。
-
Fragment Offset: 13 bit 片偏移。较长的 IP 数据报在分片后,某片在原分组中的相对位置(形象理解为分片后的序列)。也就是说,相对用户数据字段的起点,该片从何处开始。片偏移以 8 个字节为偏移单位。这就是说,每个分片的长度一定是 8 字节(64 位)的整数倍。
-
Time To Live(TTL): 8 bit 生存时间,数据报在网络中存活的时间,所允许通过的路由器的最大数量,没通过一个路由器,该值自动减一,如果数值为 0,路由器就可以把该数据报丢弃。
-
Protocol: 8 bit 标志此数据报携带的数据是使用协议类型(例如 TCP、UDP 等),以便使目的主机的 IP 层知道应将数据部分上交给哪个处理过程。常见的如 UDP 为 0x11,TCP 为 0x06,ICMP 为 0x01,
Internet Assigned Numbers Authority维护里一份 IP 协议序号表 -
Header Checksum: 16 bit 首部校验和。与 TCP 不同的是,这个字段只校验数据报的首部,但不包括数据部分。这是因为数据报每经过一个路由器,路由器都要重新计算一下首部校验和(一些字段,如生存时间、标志、片偏移等都可能发生变化)。不检验数据部分可减少计算的工作量。
-
Source address: 32 bit
-
Destination address: 32 bit
-
Options: 这部分经常不使用
TCP
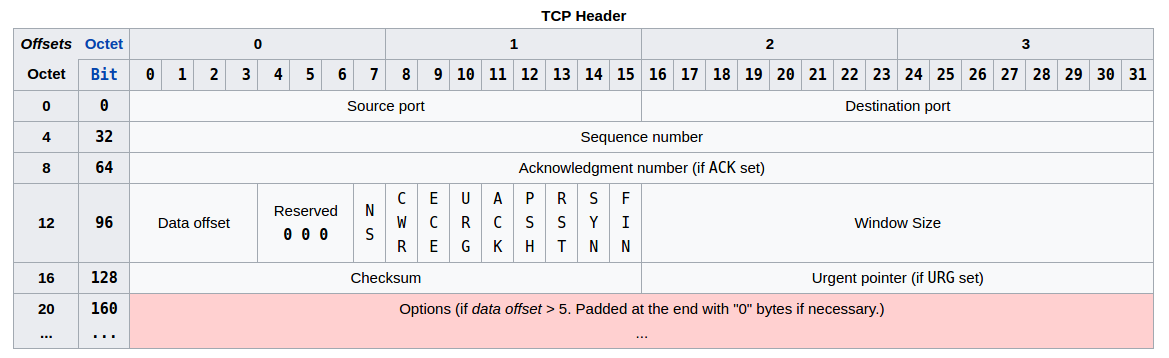
- Source port (16 bits) 标识源主机的一个应用进程端口。
- Destination port (16 bits) 标识目的主机的一个应用进程端口。
- Sequence number (32 bits)
- Acknowledgment number (32 bits)
- Data offset (4 bits) 首部长度,与 IP 数据报的首部含义同,即首部长度=0x5(0101),代表首部有 20 Bytes。首部长度大小取值范围 5(20Bytes,常规值,不附加任何可选项)-15(60B)。当首部长度不是 4 字节的整数倍时,必须利用最后的填充字段加以填充。因此数据部分永远在 4 字节的整数倍开始。
- Reserved (3 bits) 保留位,保留给将来使用,目前必须置为 0 。
- Flags (9 bits) (aka Control bits)
- NS (1 bit): ECN-nonce concealment protection
- CWR (1 bit): Congestion Window Reduced (CWR) flag is set by the sending host to indicate that it received a TCP segment with the ECE flag set and had responded in congestion control mechanism
- ECE (1 bit): ECN-Echo has a dual role, depending on the value of the SYN flag.
- URG
- ACK
- PSH
- RST
- SYN
- FIN
- Window size (16 bits) TCP 采用滑动窗口协议,此子段标志窗口的大小。表示从确认号(确认已经正确接受的数据顺序号)开始,本报文的源方可以接收的字节数,即源方接收窗口大小。窗口大小是一个 16bit 字段,因而窗口大小最大为 65535
- Checksum (16 bits)
此校验和是对
首部+数据的校验和。此处与 IP 数据报不同。这是一个强制性的字段,一定是由发送端计算和存储,并由接收端进行验证 - Urgent pointer (16 bits) 只有当 URG 标志置 1 时紧急指针才有效。紧急指针是一个正的偏移量,和顺序号字段中的值相加表示紧急数据最后一个字节的序号。 TCP 的紧急方式是发送端向另一端发送紧急数据的一种方式。
- Options (Variable 0–320 bits, divisible by 32)
- Padding
UDP

- Source port number: 16 bit 标识源主机的一个应用进程端口
- Destination port number: 16 bit 标识目的主机的一个应用进程端口。
- Length: 16 bit
总长度,
首部长度+数据长度,单位是字节(TCP 报文并没有总长度) - Checksum: 16 bit
检验 UDP
首部和数据部分的正确性
校验和的计算
IP、TCP、UDP、ICMP 等报文头部都有校验和字段,大小都是 16bit,算法也都基本一样。
- 发送数据时,为了计算数据报的校验和
- 把校验和字段置为 0
- 把需要检验的数据看成以 16 位为单位的数字组成,依次进行二进制反码求和
- 把得到的结果存入到校验和字段中
- 接收数据时,计算数据包相对简单
- 把首部看成以 16 位为单位的数字组成,依次进行二进制反码求和,包括校验和字段
- 检查计算出的校验和的结果是否为 0
- 如果为 0,说明被整除,校验和是正确的。否则校验和就是错误的,协议栈要抛弃这个数据包
虽然上面四种报文的校验和算法一样,但在作用范围存在不同:
- IP 校验和只校验 20 字节的 IP 报头;
- ICMP 校验和覆盖整个报文(ICMP 报头+ICMP 数据);
- UDP 和 TCP 校验和不仅覆盖整个报文,而且还有 12 字节的 IP 伪首部,包括源 IP 地址(4 字节)、目的 IP 地址(4 字节)、协议(2 字节,第一字节补 0)和 TCP/UDP 包长(2 字节)。
- UDP、TCP 数据报的长度可以为奇数字节,所以在计算校验和时需要在最后增加填充字节 0(注意,填充字节只是为了计算校验和,可以不被传送)。
这里还要提一点,UDP 的校验和是可选的,当校验和字段为 0 时,表明该 UDP 报文未使用校验和,接收方就不需要校验和检查了!那如果 UDP 校验和的计算结果是 0 时怎么办呢?书上有这么一句话:“如果校验和的计算结果为 0,则存入的值为全 1(65535),这在二进制反码计算中是等效的。”
什么是二进制反码求和
对一个无符号的数,先求其反码,然后从低位到高位,按位相加,有溢出则向高位进 1(跟一般的二进制加法规则一样),若最高位有进位,则向最低位进 1。
先取反后相加与先相加后取反,得到的结果是一样的! 事实上我们的编程算法里,几乎都是先相加后取反。
IP 首部校验和计算
|
|
4~13 行代码对数据按 16bit 累加求和,由于最高位的进位需要加在最低位上,所以 cksum 必须是 32bit 的 unsigned long 型,高 16bit 用于保存累加过程中的进位;另外代码 10~13 行是对 size 为奇数情况的处理!
14~16 行代码的作用是将 cksum 高 16bit 的值加到低 16bit 上,即把累加中最高位的进位加到最低位上。这里使用了 while 循环,判断 cksum 高 16bit 是否非零,因为第 16 行代码执行的时候,仍可能向 cksum 的高 16bit 进位。 有些地方是通过下面两条代码实现的:
cksum = (cksum >> 16) + (cksum & 0xffff);
cksum += (cksum >>16);
这里只进行了两次相加,即可保证相加后 cksum 的高 16 位为 0,两种方式的效果一样。事实上,上面的循环也最多执行两次!
17 行代码即对 16bit 数据累加的结果取反,得到二进制反码求和的结果,然后函数返回该值。
TCP 和 UDP 校验和
|
|
-
No backlinks found.