SHARP

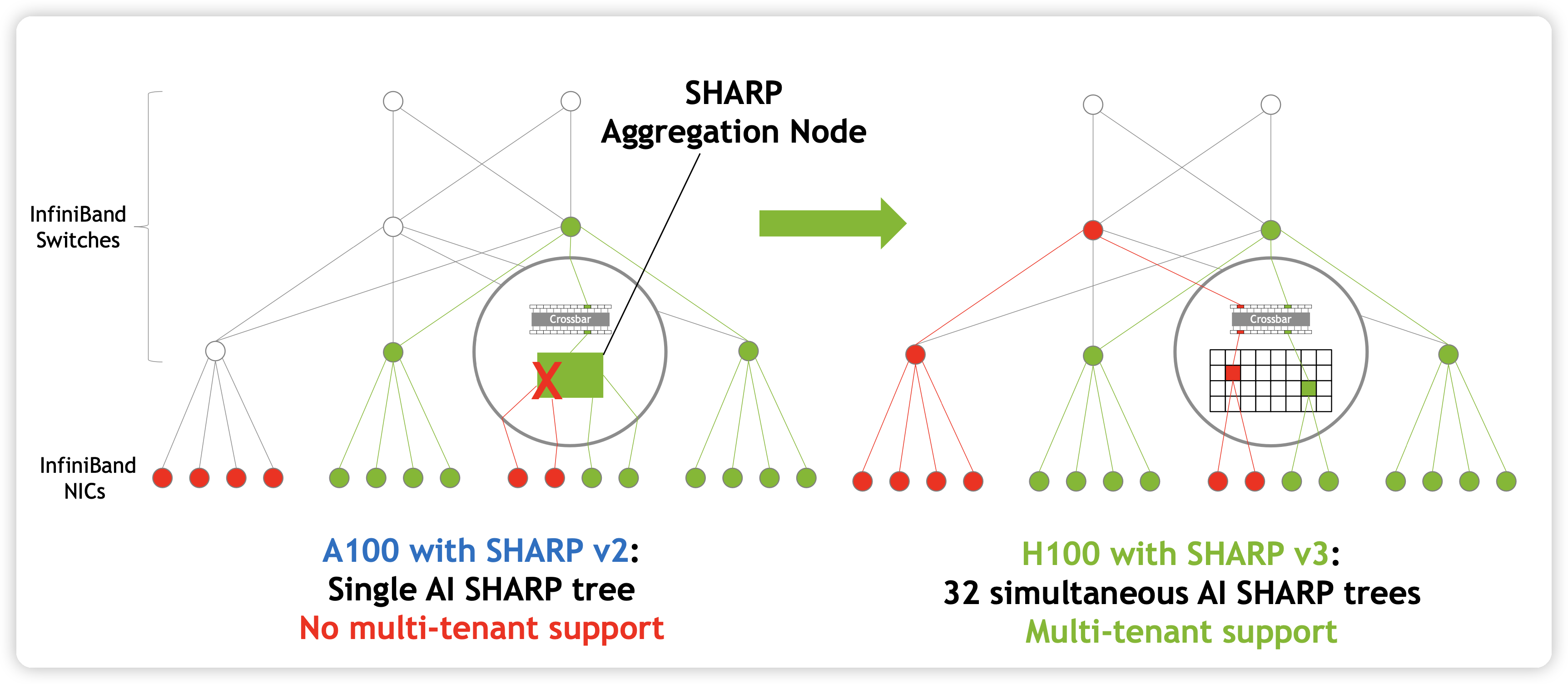
collnet 是 IB sharp,刚才聊的是 nvlink sharp,是两个东西
IB SHARP
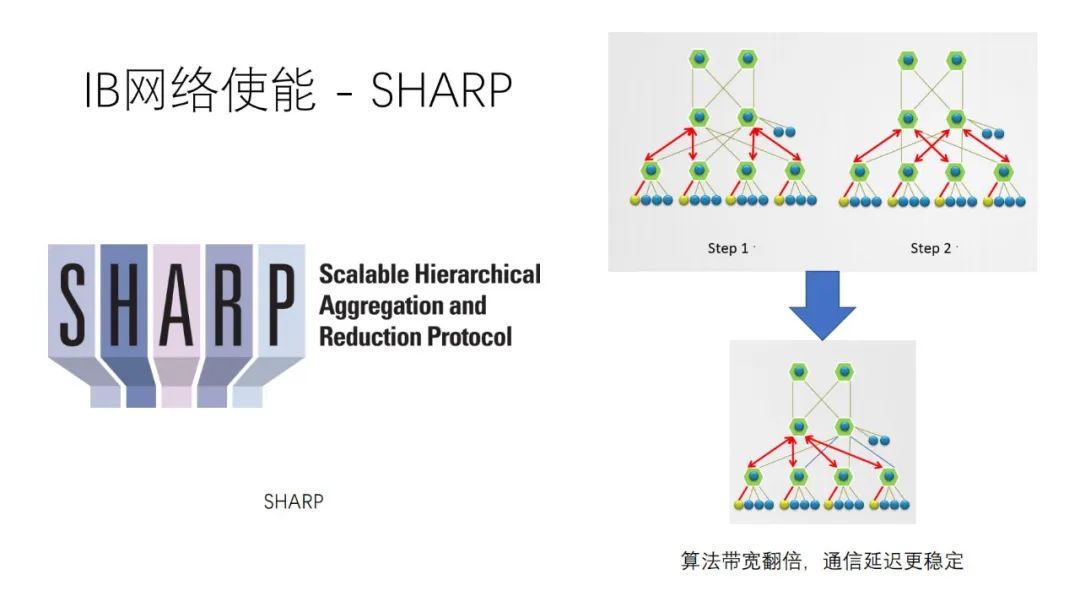
CollNet 其实不是一种算法,而是一种自定义的网络通信方式,需要加载额外的插件来使用。说下基于 SHArP 协议的,具体加载方法这个链接里有写。
目前NVIDIA官方的CollNet实现应该是只有基于SHArP的这一种,需要搭配Infiniband以及Infiniband交换机一起食用(yummy),好一个NVIDIA全家桶。怕大家没接触过SHArP,先给大家扫个盲(因为我就没接触过,研究HPC的同学倒是熟得很)。
SHArP 是一个软硬结合的通信协议,实现在了 NVIDIA Quantum HDR Switch 的 ASIC 里。它可以把从各个 node 收到的数据进行求和,并发送回去。再说的通俗一点,通过使用 SHArP,我们把求和(聚合/Reduce,随便怎么叫)的操作交由交换机完成了。这种做法,业界叫做 In-network Computing(在网计算)。用术语展开来讲,就是将计算卸载到网络中进行。
参考:
- https://docs.nvidia.com/networking/display/SHARPv261/Using+NVIDIA+SHARP+with+NVIDIA+NCCL
- https://zhuanlan.zhihu.com/p/597081795
- https://course.zhidx.com/download/detail/NDg3YWI5YjNiOTI5Y2FiYjY2MjI=
NVlink SHARP
NVLS,也就是 NVLink SHARP
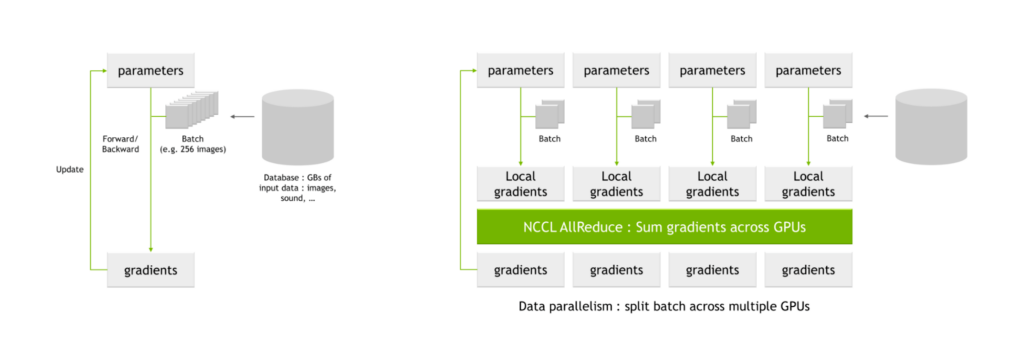
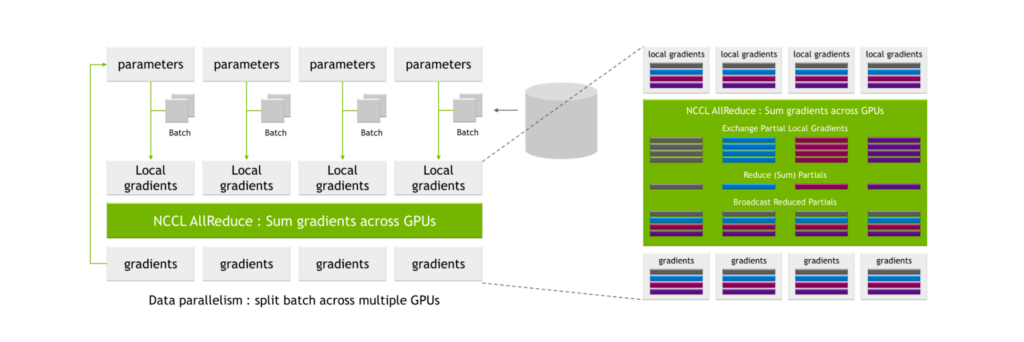
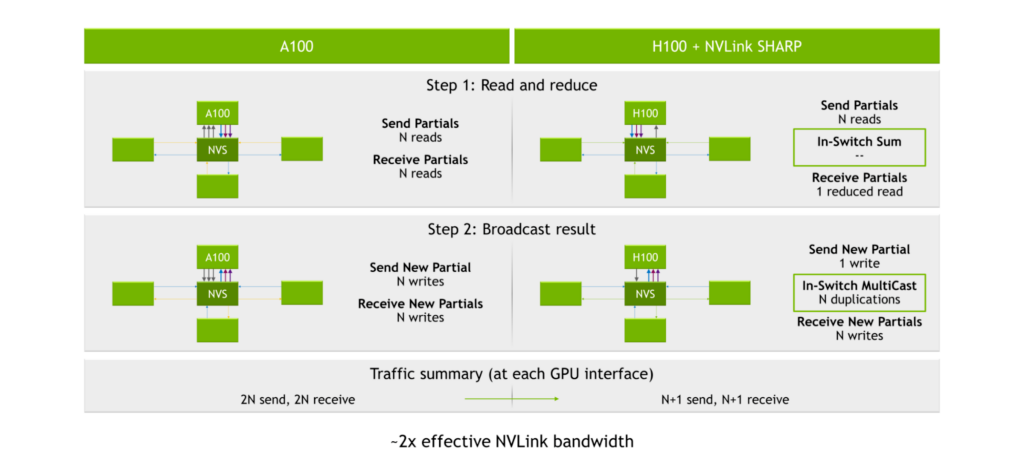
参考:
- https://github.com/NVIDIA/nccl/issues/807
- https://developer.nvidia.com/blog/upgrading-multi-gpu-interconnectivity-with-the-third-generation-nvidia-nvswitch/
NCCL 算法选择
NCCL 有多种算法,Ring, Tree, CollnetDirect, CollnetChain, NVLS, NVLSTree 还有一些 protocal, simple, LL 128 等
NCCL 会根据实际的情况计算那种算法更优,从而选择最优算法 https://github.com/NVIDIA/nccl/issues/790
-
No backlinks found.