Linux Namespace
Linux Namespace 机制提供一种资源隔离方案,为实现基于容器的虚拟化技术提供了很好的基础,该机制类似于 Solaris 中的 zone 或 FreeBSD 中的 jail。LXC 就是利用这一特性实现了资源的隔离,不同 Container 内的进程属于不同的 Namespace,彼此透明,互不干扰。与 chroot 通过修改根目录把用户 jail 到一个特定目录下实现文件系统的隔离不同,Linux Namespace 在此基础上,提供了对 UTS、IPC、mount、PID、network、User 等的隔离机制。本文所有示例代码可以在我的 Github 中找到。
内核命名空间描述
在 Linux 内核中提供了多个 namespace,其中包括 fs (mount)、uts、network、sysv ipc 等。一个进程可以属于多个 namesapce,既然 namespace 和进程相关,那么在 task_struct 结构体中就会包含和 namespace 相关联的变量。在 task_struct结构中有一个指向 namespace 结构体的指针 nsproxy。
|
|
再看一下nsproxy是如何定义的,在 include/linux/nsproxy.h 文件中,这里一共定义了 5 个各自的命名空间结构体,在该结构体中定义了 5 个指向各个类型 namespace 的指针,由于多个进程可以使用同一个 namespace,所以 nsproxy 可以共享使用,count 字段是该结构的引用计数。
|
|
系统中有一个默认的nsproxy,init_nsproxy,该结构在 task 初始化是也会被初始,定义在 init/init_task.c
|
|
其中 init_nsproxy 的定义为:
|
|
对于 .mnt_ns 没有进行初始化,其余的 namespace 都进行了系统默认初始
命名空间的创建
Linux Namespace 有如下种类,官方文档在这里 Namespace in Operation
| 分类 | 系统调用参数 | 相关内核版本 | 作用 |
|---|---|---|---|
| Mount namespaces | CLONE_NEWNS | Linux 2.4.19 | 使进程有一个独立的挂载文件系统 |
| UTS namespaces | CLONE_NEWUTS | Linux 2.6.19 | 使进程有一个独立的 hostname 和 domainname |
| IPC namespaces | CLONE_NEWIPC | Linux 2.6.19 | 使进程有一个独立的 ipc,包括消息队列,共享内存和信号量 |
| PID namespaces | CLONE_NEWPID | Linux 2.6.24 | 使进程有一个独立的 pid 空间 |
| Network namespaces | CLONE_NEWNET | 始于 Linux 2.6.24 完成于 Linux 2.6.29 | 使进程有一个独立的网络栈 |
| User namespaces | CLONE_NEWUSER | 始于 Linux 2.6.23 完成于 Linux 3.8) | 是进程有一个独立的 user 空间 |
| Cgroup namespaces | CLONE_NEWCGROUP | 始于 Linux 4.6 | 使进程有一个独立的 cgroup 控制组 |
Linux 的每个进程都具有命名空间,可以在/proc/PID/ns 目录中看到命名空间的文件描述符。
|
|
主要是三个系统调用
clone() – 实现线程的系统调用,用来创建一个新的进程,并可以通过设计上述参数达到隔离。unshare() – 使某进程脱离某个 namespacesetns() – 把某进程加入到某个 namespace
下面还是让我们来看一些示例(以下的测试程序最好在 Linux 内核为 3.8 以上的版本中运行,我用的是 ubuntu 14.04)。
clone()系统调用
clone 的语法:
|
|
其中 flags 即可指定命名空间,使用示例:
|
|
首先,我们来看一下一个最简单的 clone()系统调用的示例:
|
|
从上面的程序,我们可以看到,这和 pthread 基本上是一样的玩法。但是,对于上面的程序,父子进程的进程空间是没有什么差别的,父进程能访问到的子进程也能。
|
|
下面, 让我们来看几个例子看看,Linux 的 Namespace 是什么样的。
UTS Namespace
下面的代码,我略去了上面那些头文件和数据结构的定义,只有最重要的部分。
|
|
运行上面的程序你会发现(需要 root 权限),子进程的 hostname 变成了 houmin。
|
|
IPC Namespace
IPC 全称 Inter-Process Communication,是 Unix/Linux 下进程间通信的一种方式,IPC 有共享内存、信号量、消息队列等方法。所以,为了隔离,我们也需要把 IPC 给隔离开来,这样,只有在同一个 Namespace 下的进程才能相互通信。如果你熟悉 IPC 的原理的话,你会知道,IPC 需要有一个全局的 ID,即然是全局的,那么就意味着我们的 Namespace 需要对这个 ID 隔离,不能让别的 Namespace 的进程看到。
要启动 IPC 隔离,我们只需要在调用 clone 时加上 CLONE_NEWIPC 参数就可以了。
|
|
首先,我们先创建一个 IPC 的 Queue(如下所示,全局的 Queue ID 是 0)
|
|
如果我们运行没有 CLONE_NEWIPC 的程序,我们会看到,在子进程中还是能看到这个全启的 IPC Queue。
|
|
但是,如果我们运行加上了 CLONE_NEWIPC 的程序,我们就会下面的结果:
|
|
我们可以看到 IPC 已经被隔离了。
PID Namespace
我们继续修改上面的程序:
|
|
运行结果如下(我们可以看到,子进程的 pid 是 1 了):
|
|
你可能会问,PID 为 1 有个毛用啊?我们知道,在传统的 UNIX 系统中,PID 为 1 的进程是 init,地位非常特殊。他作为所有进程的父进程,有很多特权(比如:屏蔽信号等),另外,其还会为检查所有进程的状态,我们知道,如果某个子进程脱离了父进程(父进程没有 wait 它),那么 init 就会负责回收资源并结束这个子进程。所以,要做到进程空间的隔离,首先要创建出 PID 为 1 的进程,最好就像 chroot 那样,把子进程的 PID 在容器内变成 1。
但是,我们会发现,在子进程的 shell 里输入 ps, top 等命令,我们还是可以看得到所有进程。说明并没有完全隔离。这是因为,像 ps, top 这些命令会去读/proc 文件系统,所以,因为/proc 文件系统在父进程和子进程都是一样的,所以这些命令显示的东西都是一样的。
所以,我们还需要对文件系统进行隔离。
Mount Namespace
下面的例程中,我们在启用了 mount namespace 并在子进程中重新 mount 了/proc 文件系统。
|
|
运行结果如下:
|
|
上面,我们可以看到只有两个进程 ,而且 pid=1 的进程是我们的/bin/bash。我们还可以看到/proc 目录下也干净了很多:
|
|
下图,我们也可以看到在子进程中的 top 命令只看得到两个进程了。
|
|
这里,多说一下。在通过 CLONE_NEWNS 创建 mount namespace 后,父进程会把自己的文件结构复制给子进程中。而子进程中新的 namespace 中的所有 mount 操作都只影响自身的文件系统,而不对外界产生任何影响。这样可以做到比较严格地隔离。
User Namespace
User Namespace 主要是用了 CLONE_NEWUSER 的参数。使用了这个参数后,内部看到的 UID 和 GID 已经与外部不同了,默认显示为 65534。那是因为容器找不到其真正的 UID 所以,设置上了最大的 UID(其设置定义在 /proc/sys/kernel/overflowuid)。
要把容器中的 uid 和真实系统的 uid 给映射在一起,需要修改 /proc/<pid>/uid_map 和 /proc/<pid>/gid_map 这两个文件。这两个文件的格式为:
ID-inside-ns ID-outside-ns length
其中:
- 第一个字段
ID-inside-ns表示在容器显示的 UID 或 GID, - 第二个字段
ID-outside-ns表示容器外映射的真实的 UID 或 GID。 - 第三个字段表示映射的范围,一般填 1,表示一一对应。
比如,把真实的 uid=1000 映射成容器内的 uid=0
|
|
再比如下面的示例:表示把 namespace 内部从 0 开始的 uid 映射到外部从 0 开始的 uid,其最大范围是无符号 32 位整形
|
|
另外,需要注意的是:
- 写这两个文件的进程需要这个 namespace 中的 CAP_SETUID (CAP_SETGID)权限(可参看Capabilities)
- 写入的进程必须是此 user namespace 的父或子的 user namespace 进程。
- 另外需要满如下条件之一:
- 父进程将 effective uid/gid 映射到子进程的 user namespace 中
- 父进程如果有 CAP_SETUID/CAP_SETGID 权限,那么它将可以映射到父进程中的任一 uid/gid
这些规则看着都烦,我们来看程序吧:
|
|
上面的程序,我们用了一个 pipe 来对父子进程进行同步,为什么要这样做?因为子进程中有一个 execv 的系统调用,这个系统调用会把当前子进程的进程空间给全部覆盖掉,我们希望在 execv 之前就做好 user namespace 的 uid/gid 的映射,这样,execv 运行的 /bin/bash 就会因为我们设置了 uid 为 0 的 inside-uid 而变成 # 号的提示符。
整个程序的运行效果如下:
|
|
虽然容器里是 root,但其实这个容器的/bin/bash 进程是以一个普通用户 hchen 来运行的。这样一来,我们容器的安全性会得到提高。
我们注意到,User Namespace 是以普通用户运行,但是别的 Namespace 需要 root 权限,那么,如果我要同时使用多个 Namespace,该怎么办呢?一般来说,我们先用一般用户创建 User Namespace,然后把这个一般用户映射成 root,在容器内用 root 来创建其它的 Namesapce。
Network Namespace
Network 的 Namespace 比较啰嗦。在 Linux 下,我们一般用 ip 命令创建 Network Namespace(Docker 的源码中,它没有用 ip 命令,而是自己实现了 ip 命令内的一些功能——是用了 Raw Socket 发些“奇怪”的数据,呵呵)。这里,我还是用 ip 命令讲解一下。
首先,我们先看个图,下面这个图基本上就是 Docker 在宿主机上的网络示意图(其中的物理网卡并不准确,因为 docker 可能会运行在一个 VM 中,所以,这里所谓的“物理网卡”其实也就是一个有可以路由的 IP 的网卡)
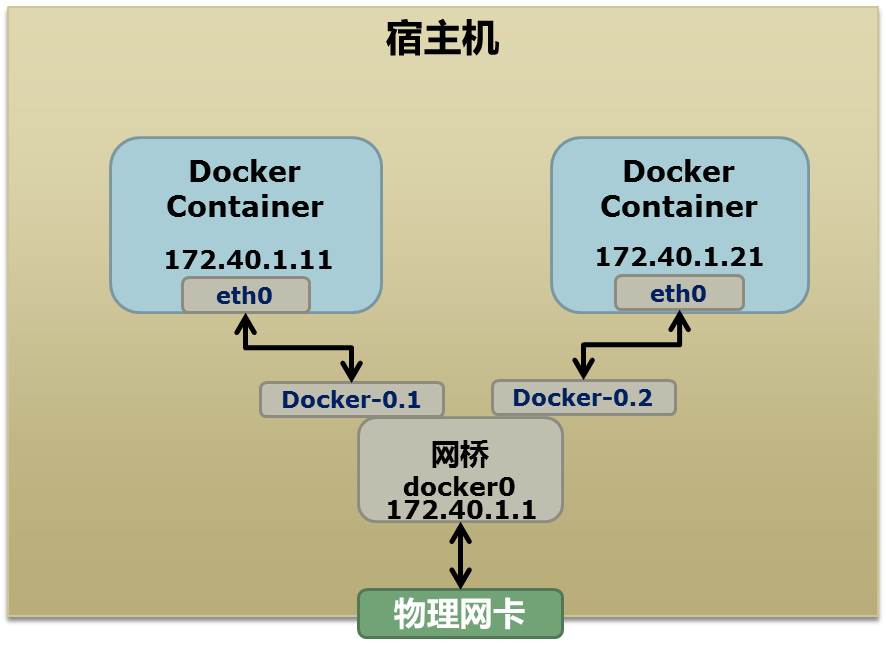
上图中,Docker 使用了一个私有网段,172.40.1.0,docker 还可能会使用 10.0.0.0 和 192.168.0.0 这两个私有网段,关键看你的路由表中是否配置了,如果没有配置,就会使用,如果你的路由表配置了所有私有网段,那么 docker 启动时就会出错了。
当你启动一个 Docker 容器后,你可以使用 ip link show 或 ip addr show 来查看当前宿主机的网络情况(我们可以看到有一个 docker0,还有一个 veth22a38e6 的虚拟网卡——给容器用的):
hchen@ubuntu:~$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state ...
link/loopback *00*:*00*:*00*:*00*:*00*:*00* brd *00*:*00*:*00*:*00*:*00*:*00*
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc ...
link/ether *00*:0c:29:b7:67:7d brd ff:ff:ff:ff:ff:ff
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 ...
link/ether 56:84:7a:fe:97:99 brd ff:ff:ff:ff:ff:ff
5: veth22a38e6: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc ...
link/ether 8e:30:2a:ac:8c:d1 brd ff:ff:ff:ff:ff:ff
那么,要做成这个样子应该怎么办呢?我们来看一组命令:
|
|
上面基本上就是 docker 网络的原理了,只不过,
- Docker 的
resolv.conf没有用这样的方式,而是用了 上篇中的 Mount Namesapce 的那种方式 - 另外,docker 是用进程的 PID 来做 Network Namespace 的名称的。
了解了这些后,你甚至可以为正在运行的 docker 容器增加一个新的网卡:
|
|
上面的示例是我们为正在运行的 docker 容器,增加一个 eth1 的网卡,并给了一个静态的可被外部访问到的 IP 地址。
这个需要把外部的“物理网卡”配置成混杂模式,这样这个 eth1 网卡就会向外通过 ARP 协议发送自己的 Mac 地址,然后外部的交换机就会把到这个 IP 地址的包转到“物理网卡”上,因为是混杂模式,所以 eth1 就能收到相关的数据,一看,是自己的,那么就收到。这样,Docker 容器的网络就和外部通了。
当然,无论是 Docker 的 NAT 方式,还是混杂模式都会有性能上的问题,NAT 不用说了,存在一个转发的开销,混杂模式呢,网卡上收到的负载都会完全交给所有的虚拟网卡上,于是就算一个网卡上没有数据,但也会被其它网卡上的数据所影响。
这两种方式都不够完美,我们知道,真正解决这种网络问题需要使用 VLAN 技术,于是 Google 的同学们为 Linux 内核实现了一个IPVLAN 的驱动,这基本上就是为 Docker 量身定制的。
Namespace 文件
上面就是目前 Linux Namespace 的玩法。 现在,我来看一下其它的相关东西。
让我们运行一下上篇中的那个 mnt 的程序(也就是 PID Namespace 中那个 mount proc 的程序),然后不要退出。
|
|
我们到另一个 shell 中查看一下父子进程的 PID:
hchen@ubuntu:~$ pstree -p 4599
pid.mnt(4599)───bash(4600)
我们可以到 proc 下(/proc//ns)查看进程的各个 namespace 的 id(内核版本需要 3.8 以上)。
下面是父进程的:
|
|
下面是子进程的:
|
|
我们可以看到,其中的 ipc、net、user 是同一个 ID,而 mnt、pid、uts 都是不一样的。如果两个进程指向的 namespace 编号相同,就说明他们在同一个 namespace 下,否则则在不同 namespace 里面。这些文件还有另一个作用,那就是,一旦这些文件被打开,只要其 fd 被占用着,那么就算 PID 所属的所有进程都已经结束,创建的 namespace 也会一直存在。比如:我们可以通过:mount -bind /proc/4600/ns/uts ~/uts 来 hold 这个 namespace。
参考资料
-
No backlinks found.