Init
Linux 下有 3 个特殊的进程,idle 进程(PID=0PID=0), init 进程(PID=1PID=1)和 kthreadd(PID=2PID=2)
* idle 进程由系统自动创建, 运行在内核态
idle 进程其 pid=0,其前身是系统创建的第一个进程,也是唯一一个没有通过 fork 或者 kernel_thread 产生的进程。完成加载系统后,演变为进程调度、交换
* init 进程由 idle 通过 kernel_thread 创建,在内核空间完成初始化后, 加载 init 程序, 并最终用户空间
由 0 进程创建,完成系统的初始化. 是系统中所有其它用户进程的祖先进程 Linux 中的所有进程都是有 init 进程创建并运行的。首先 Linux 内核启动,然后在用户空间中启动 init 进程,再启动其他系统进程。在系统启动完成完成后,init 将变为守护进程监视系统其他进程。
* kthreadd 进程由 idle 通过 kernel_thread 创建,并始终运行在内核空间, 负责所有内核线程的调度和管理
它的任务就是管理和调度其他内核线程 kernel_thread, 会循环执行一个 kthread 的函数,该函数的作用就是运行 kthread_create_list 全局链表中维护的 kthread, 当我们调用 kernel_thread 创建的内核线程会被加入到此链表中,因此所有的内核线程都是直接或者间接的以 kthreadd 为父进程
我们下面就详解分析 1 号进程的前世(kernel_init)今生(init 进程)
Linux 系统中的 init 进程(pid=1)是除了 idle 进程(pid=0,也就是 init_task)之外另一个比较特殊的进程,它是 Linux 内核开始建立起进程概念时第一个通过 kernel_thread 产生的进程,其开始在内核态执行,然后通过一个系统调用,开始执行用户空间的/sbin/init 程序,期间 Linux 内核也经历了从内核态到用户态的特权级转变,/sbin/init 极有可能产生出了 shell,然后所有的用户进程都有该进程派生出来
1 号进程
前面我们了解到了 0 号进程是系统所有进程的先祖, 它的进程描述符 init_task 是内核静态创建的, 而它在进行初始化的时候, 通过 kernel_thread 的方式创建了两个内核线程,分别是 kernel_init 和 kthreadd,其中 kernel_init 进程号为 1
start_kernel 在其最后一个函数 rest_init 的调用中,会通过 kernel_thread 来生成一个内核进程,后者则会在新进程环境下调 用 kernel_init 函数,kernel_init 一个让人感兴趣的地方在于它会调用 run_init_process 来执行根文件系统下的 /sbin/init 等程序:
kernel_init
0 号进程创建 1 号进程的方式如下
|
|
我们发现 1 号进程的执行函数就是 kernel_init, 这个函数被定义init/main.c中,如下所示
kernel_init 函数将完成设备驱动程序的初始化,并调用 init_post 函数启动用户空间的 init 进程。
由 0 号进程创建 1 号进程(内核态),1 号内核线程负责执行内核的部分初始化工作及进行系统配置,并创建若干个用于高速缓存和虚拟主存管理的内核线程。
init 进程
随后,1 号进程调用 do_execve 运行可执行程序 init,并演变成用户态 1 号进程,即 init 进程。
init 进程是 linux 内核启动的第一个用户级进程。init 有许多很重要的任务,比如像启动 getty(用于用户登录)、实现运行级别、以及处理孤立进程。
它按照配置文件/etc/initab 的要求,完成系统启动工作,创建编号为 1 号、2 号…的若干终端注册进程 getty。
每个 getty 进程设置其进程组标识号,并监视配置到系统终端的接口线路。当检测到来自终端的连接信号时,getty 进程将通过函数 do_execve()执行注册程序 login,此时用户就可输入注册名和密码进入登录过程,如果成功,由 login 程序再通过函数 execv()执行 shell,该 shell 进程接收 getty 进程的 pid,取代原来的 getty 进程。再由 shell 直接或间接地产生其他进程。
上述过程可描述为:0 号进程->1 号内核进程->1 号用户进程(init 进程)->getty 进程->shell 进程
注意,上述过程描述中提到:1 号内核进程调用执行 init 函数并演变成 1 号用户态进程(init 进程),这里前者是 init 是函数,后者是进程。两者容易混淆,区别如下:
- kernel_init 函数在内核态运行,是内核代码
- init 进程是内核启动并运行的第一个用户进程,运行在用户态下。
- 一号内核进程调用 execve()从文件/etc/inittab 中加载可执行程序 init 并执行,这个过程并没有使用调用 do_fork(),因此两个进程都是 1 号进程。
当内核启动了自己之后(已被装入内存、已经开始运行、已经初始化了所有的设备驱动程序和数据结构等等),通过启动用户级程序 init 来完成引导进程的内核部分。因此,init 总是第一个进程(它的进程号总是 1)。
当 init 开始运行,它通过执行一些管理任务来结束引导进程,例如检查文件系统、清理/tmp、启动各种服务以及为每个终端和虚拟控制台启动 getty,在这些地方用户将登录系统。
在系统完全起来之后,init 为每个用户已退出的终端重启 getty(这样下一个用户就可以登录)。init 同样也收集孤立的进程:当一个进程启动了一个子进程并且在子进程之前终止了,这个子进程立刻成为 init 的子进程。对于各种技术方面的原因来说这是很重要的,知道这些也是有好处的,因为这便于理解进程列表和进程树图。init 的变种很少。绝大多数 Linux 发行版本使用 sysinit(由 Miguel van Smoorenburg 著),它是基于 System V 的 init 设计。UNIX 的 BSD 版本有一个不同的 init。最主要的不同在于运行级别:System V 有而 BSD 没有(至少是传统上说)。这种区别并不是主要的。在此我们仅讨论 sysvinit。 配置 init 以启动 getty:/etc/inittab 文件
关于 init 程序
1 号进程通过 execve 执行 init 程序来进入用户空间,成为 init 进程,那么这个 init 在哪里呢
内核在几个位置上来查寻 init,这几个位置以前常用来放置 init,但是 init 的最适当的位置(在 Linux 系统上)是/sbin/init。如果内核没有找到 init,它就会试着运行/bin/sh,如果还是失败了,那么系统的启动就宣告失败了。
因此 init 程序是一个可以又用户编写的进程, 如果希望看 init 程序源码的朋友,可以参见
| init 包 | 说明 | 学习链接 |
|---|---|---|
| sysvinit | 早期一些版本使用的初始化进程工具, 目前在逐渐淡出 linux 历史舞台, sysvinit 就是 system V 风格的 init 系统,顾名思义,它源于 System V 系列 UNIX。它提供了比 BSD 风格 init 系统更高的灵活性。是已经风行了几十年的 UNIX init 系统,一直被各类 Linux 发行版所采用。 | 浅析 Linux 初始化 init 系统(1):sysvinit |
| upstart | debian, Ubuntu 等系统使用的 initdaemon | 浅析 Linux 初始化 init 系统(2): UpStart |
| systemd | Systemd 是 Linux 系统中最新的初始化系统(init),它主要的设计目标是克服 sysvinit 固有的缺点,提高系统的启动速度 | 浅析 Linux 初始化 init 系统(3) Systemd |
Ubuntu 等使用 deb 包的系统可以通过 dpkg -S 查看程序所在的包

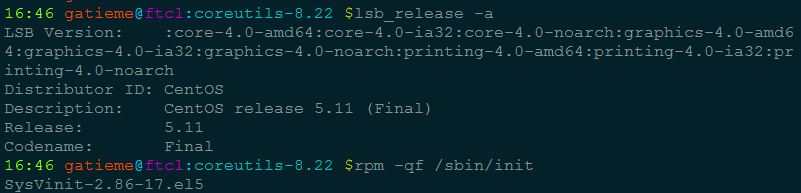
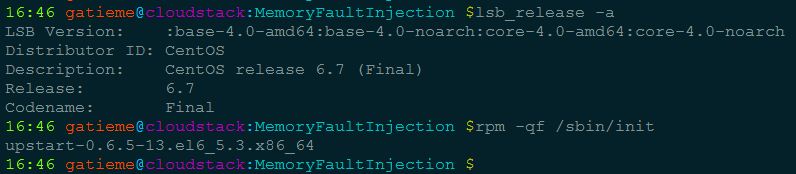
CentOS 等使用 rpm 包的系统可以通过 rpm -qf 查看系统程序所在的包
参见
附录
kernel_init_freeable 流程分析
|
|
| 执行流程 | 说明 |
|---|---|
| wait_for_completion | 实例在 kernel/sched/completion.c 中, 等待 Kernel Thread kthreadd (PID=2)创建完毕 |
| gfp_allowed_mask | __GFP_BITS_MASK;设置 bitmask, 使得 init 进程可以使用 PM 并且允许 I/O 阻塞操作 |
| set_mems_allowed(node_states[N_MEMORY]); | init 进程可以分配物理页面 |
| set_cpus_allowed_ptr | 通过设置 cpu_bit_mask, 可以限定 task 只能在特定的处理器上运行, 而 initcurrent 进程此时必然是 init 进程,设置其 cpu_all_mask 即使得 init 进程可以在任意的 cpu 上运行 |
| task_pid | 设置到目前运行进程 init 的 pid 号给cad_pid(cad_pid 是用来接收 ctrl-alt-del reboot signal 的进程, 如果设置C_A_D=1就表示可以处理来自 ctl-alt-del的动作), 最后会调用 ctrl_alt_del(void)并确认 C_A_D 是否为 1,确认完成后将执行 cad_work=deferred_cad,执行kernel_restart |
| smp_prepare_cpus | 体系结构相关的函数,实例在 arch/arm/kernel/smp.c 中,调用 smp_prepare_cpus 时,会以全局变量 setup_max_cpus 为函式参数 max_cpus,以表示在编译核心时,设定支援的最大 CPU 数量 |
| do_pre_smp_initcalls | 实例在init/main.c中, 会透过函式 do_one_initcall,执行 Symbol 中 initcall_start 与early_initcall_end 之间的函数 |
| smp_init | 实例在 kernel/smp.c 中, 函数主要是由 Bootstrap 处理器,进行 Active 多核心架构下其它的处理器. 如果发生 Online 的处理器个数(from num_online_cpus)超过在核心编译时,所设定的最大处理器个数 setup_max_cpus (from NR_CPUS),就会终止流程.如果该处理器目前属於 Present (也就是存在系统中),但尚未是 Online 的状态,就会呼叫函式 cpu_up(in kernel/cpu.c)来啟动该处理器. |
| sched_init_smp | 实例在 kernel/sched.c 中, (1), 呼叫 get_online_cpus,如果目前 CPU Hotplug Active Write 行程是自己,就直接返回.反之就把 cpu_hotplug.refcount 加 1 (表示多一个 Reader) (2),取得 Mutex Lock “sched_domains_mutex” (3),呼叫 arch_init_sched_domains,设定 scheduler domains 与 groups,参考 Linux Documentation/scheduler/sched-domains.txt 文件,一个 Scheduling Domain 会包含一个或多个 CPU Groups,排程的 Load-Balance 就会根据 Domain 中的 Groups 来做调整. (4),释放 Mutex Lock “sched_domains_mutex” (5),呼叫 put_online_cpus,如果目前 CPU Hotplug Active Writer 行程是自己,就直接返回.反之就把 cpu_hotplug.refcount 减 1,如果 cpu_hotplug.refcount 减到為 0,表示没有其他 Reader,此时如果有 CPU Hotplug Active Writer 行程在等待,就会透过 wake_up_process 唤醒该行程,以便让等待中的 Writer 可以被执行下去.(也可以参考_cpu_up 中对於函式 cpu_hotplug_begin 的说明). (6)注册 CPU Notifier cpuset_cpu_active/cpuset_cpu_inactive/update_runtime (7),呼叫 set_cpus_allowed_ptr,透过这函式可以设定 CPU bitmask,限定 Task 只能在特定的处理器上运作.在这会用参数”non_isolated_cpus”,也就是会把 init 指定给 non-isolated CPU. Linux Kernel 可以在啟动时,透过 Boot Parameters “isolcpus=“指定 CPU 编号或是范围,让这些处理器不被包含在 Linux Kernel SMP balancing/scheduling 算法内,可以在啟动后指派给特定的 Task 运作.而不在 “isolcpus=“ 指定范围内的处理器就算是 non-isolated CPU. (8),呼叫 sched_init_granularity,透过函式 update_sysctl,让 sysctl_sched_min_granularity=normalized_sysctl_sched_min_granularity,sysctl_sched_latency=normalized_sysctl_sched_latency,sysctl_sched_wakeup_granularity=normalized_sysctl_sched_wakeup_granularit |
| do_basic_setup | 实例在 init/main.c 中, 1,diaousermodehelper_init (in kernel/kmod.c),产生 khelper workqueue. 2,调用 init_tmpfs (in mm/shmem.c),对 VFS 注册 Temp FileSystem. 3,呼叫 driver_init (in drivers/base/init.c),初始化 Linux Kernel Driver System Model. 4,呼叫 init_irq_proc(in kernel/irq/proc.c),初始化 “/proc/irq”与其下的 File Nodes. 5,呼叫 do_ctors (in init/main.c),执行位於 Symbol **ctors_start 到 **ctors_end 间属於 Section “.ctors” 的 Constructor 函式. 6,透过函式 do_initcalls,执行介於 Symbol early_initcall_end 与initcall_end 之间的函式呼叫, |
| sys_open | 实例在 fs/fcntl.c 中,”SYSCALL_DEFINE1(dup, unsigned int, fildes)”,在这会连续执行两次 sys_dup,复制两个 sys_open 开啟/dev/console 所產生的档案描述 0 (也就是会多生出两个 1 与 2),只是都对应到”/dev/console”,我们在 System V streams 下的 Standard Stream 一般而言会有如下的对应 0:Standard input (stdin) 1:Standard output (stdout) 2:Standard error (stderr) (為方便大家参考,附上 Wiki URL http://en.wikipedia.org/wiki/Standard_streams ) |
| ramdisk_execute_command 与 prepare_namespace | 1,如果 ramdisk_execute_command 為 0,就设定 ramdisk_execute_command = “/init” 2,如果 sys_access 确认档案 ramdisk_execute_command 失败,就把 ramdisk_execute_command 设定為 0,然后呼叫 prepare_namespace 去 mount root FileSystem. |
| integrity_load_keys | 至此我们初始化工作完成, 文件系统也已经准备好了,那么接下来加载 load integrity keys hook |
| load_default_modules | 加载基本的模块 |
kernel_init 分析
|
|
| 执行流程 | 说明 |
|---|---|
| kernel_init_freeable | 调用 kernel_init_freeable 完成初始化工作,准备文件系统,准备模块信息 |
| async_synchronize_full | 用以同步所有非同步函式呼叫的执行,在这函数中会等待 List async_running 与 async_pending 都清空后,才会返回. Asynchronously called functions 主要设计用来加速 Linux Kernel 开机的效率,避免在开机流程中等待硬体反应延迟,影响到开机完成的时间 |
| free_initmem | free_initmem(in arch/arm/mm/init.c),释放 Linux Kernel 介於**init_begin 到 **init_end 属于 init Section 的函数的所有内存.并会把 Page 个数加到变量 totalram_pages 中,作为后续 Linux Kernel 在配置记忆体时可以使用的 Pages. (在这也可把 TCM 范围(tcm_start 到tcm_end)释放加入到总 Page 中,但 TCM 比外部记忆体有效率,适合多媒体,中断,…etc 等对效能要求高的执行需求,放到总 Page 中,成为可供一般目的配置的存储范围 |
| system_state | 设置运行状态 SYSTEM_RUNNING |
| 加载 init 进程,进入用户空间 | a,如果 ramdisk_execute_command 不為 0,就执行该命令成為 init User Process. b,如果 execute_command 不為 0,就执行该命令成為 init User Process. c,如果上述都不成立,就依序執行如下指令 run_init_process(“/sbin/init”); run_init_process(“/etc/init”); run_init_process(“/bin/init”); run_init_process(“/bin/sh”); 也就是说会按照顺序从/sbin/init, /etc/init, /bin/init 與 /bin/sh 依序执行第一个 init User Process. 如果都找不到可以執行的 init Process,就會進入 Kernel Panic.如下所示 panic(“No init found. Try passing init= option to kernel. ”“See Linux Documentation/init.txt for guidance.”); |
-
No backlinks found.